


Een poging om AI uit te leggen: Hoe werkt kunstmatige intelligentie en hoe wordt deze getraind? – Afbeelding: Xpert.Digital
📊 Van data-invoer tot modelvoorspelling: het AI-proces
Hoe werkt kunstmatige intelligentie (AI)? 🤖
De werking van kunstmatige intelligentie (AI) kan worden onderverdeeld in verschillende duidelijk gedefinieerde stappen. Elk van deze stappen is cruciaal voor het uiteindelijke resultaat dat de AI levert. Het proces begint met data-invoer en eindigt met modelvoorspellingen en eventuele feedback of verdere trainingsrondes. Deze fasen beschrijven het proces dat vrijwel alle AI-modellen doorlopen, ongeacht of het gaat om eenvoudige regelsets of zeer complexe neurale netwerken.
1. De gegevensinvoer 📊
De basis van elke kunstmatige intelligentie wordt gevormd door de data waarmee het werkt. Deze data kan verschillende vormen aannemen, zoals afbeeldingen, tekst, audiobestanden of video's. De AI gebruikt deze ruwe data om patronen te herkennen en beslissingen te nemen. De kwaliteit en kwantiteit van de data spelen hierbij een cruciale rol, omdat ze een grote invloed hebben op hoe goed of slecht het model uiteindelijk zal presteren.
Hoe completer en nauwkeuriger de data, hoe beter de AI kan leren. Bijvoorbeeld, bij het trainen van een AI voor beeldverwerking is een grote hoeveelheid beelddata nodig om verschillende objecten correct te identificeren. Voor taalmodellen zijn het tekstdata die de AI helpen menselijke spraak te begrijpen en te genereren. Data-input is de eerste en een van de belangrijkste stappen, omdat de kwaliteit van de voorspellingen afhangt van de kwaliteit van de onderliggende data. Een bekend principe in de computerwetenschappen beschrijft dit met het gezegde "garbage in, garbage out"—slechte data leidt tot slechte resultaten.
2. Gegevensvoorverwerking 🧹
Nadat de gegevens zijn ingevoerd, moeten ze worden voorbereid voordat ze in het model kunnen worden ingevoerd. Dit proces wordt data-voorverwerking genoemd. Het doel hiervan is om de gegevens om te zetten naar een formaat dat het model optimaal kan verwerken.
Een veelvoorkomende stap in de voorbewerking is datanormalisatie. Dit houdt in dat de data naar een uniform bereik van waarden wordt gebracht, zodat het model de data consistent verwerkt. Een voorbeeld hiervan is het schalen van alle pixelwaarden van een afbeelding naar een bereik van 0 tot 1, in plaats van 0 tot 255.
Een ander belangrijk onderdeel van de voorbewerking is het extraheren van kenmerken. Dit houdt in dat specifieke kenmerken uit de ruwe data worden gehaald die bijzonder relevant zijn voor het model. Bij beeldverwerking kunnen dit randen of specifieke kleurpatronen zijn, terwijl bij tekstverwerking relevante trefwoorden of zinsstructuren worden geëxtraheerd. Voorbewerking is cruciaal om het leerproces van de AI efficiënter en nauwkeuriger te maken.
3. Het model 🧩
Het model vormt de kern van elke kunstmatige intelligentie. Hier worden gegevens geanalyseerd en verwerkt op basis van algoritmen en wiskundige berekeningen. Een model kan verschillende vormen aannemen. Een van de bekendste modellen is het neurale netwerk, dat gebaseerd is op de werking van het menselijk brein.
Neurale netwerken bestaan uit meerdere lagen kunstmatige neuronen die informatie verwerken en doorgeven. Elke laag neemt de uitvoer van de vorige laag en verwerkt deze verder. Het leerproces van een neuraal netwerk omvat het aanpassen van de gewichten van de verbindingen tussen deze neuronen, zodat het netwerk steeds nauwkeurigere voorspellingen of classificaties kan maken. Deze aanpassing wordt bereikt door training, waarbij het netwerk grote hoeveelheden voorbeeldgegevens verwerkt en iteratief zijn interne parameters (gewichten) verbetert.
Naast neurale netwerken worden er in AI-modellen ook veel andere algoritmen gebruikt. Denk bijvoorbeeld aan beslissingsbomen, random forests, support vector machines en nog veel meer. Welk algoritme wordt gebruikt, hangt af van de specifieke taak en de beschikbare data.
4. De modelvoorspelling 🔍
Zodra het model is getraind met data, kan het voorspellingen doen. Deze stap wordt modelvoorspelling genoemd. De AI ontvangt een invoer en geeft, op basis van de patronen die het tot nu toe heeft geleerd, een uitvoer terug, dat wil zeggen een voorspelling of beslissing.
Deze voorspelling kan verschillende vormen aannemen. In een beeldclassificatiemodel zou de AI bijvoorbeeld kunnen voorspellen welk object op een afbeelding te zien is. In een taalmodel zou het kunnen voorspellen welk woord er vervolgens in een zin komt. Bij financiële voorspellingen zou de AI kunnen voorspellen hoe de aandelenmarkt zich zal ontwikkelen.
Het is belangrijk te benadrukken dat de nauwkeurigheid van de voorspellingen sterk afhangt van de kwaliteit van de trainingsgegevens en de architectuur van het model. Een model dat is getraind op onvoldoende of vertekende gegevens zal hoogstwaarschijnlijk onjuiste voorspellingen doen.
5. Feedback en training (optioneel) ♻️
Een ander belangrijk aspect van de werking van AI is het feedbackmechanisme. Hierbij wordt het model regelmatig gecontroleerd en verder geoptimaliseerd. Dit proces vindt plaats tijdens de training of na de voorspelling van het model.
Als het model onjuiste voorspellingen doet, kan het door middel van feedback leren om deze fouten te herkennen en zijn interne parameters dienovereenkomstig aan te passen. Dit gebeurt door de voorspellingen van het model te vergelijken met de werkelijke resultaten (bijvoorbeeld met bekende gegevens waarvoor de juiste antwoorden al bestaan). Een typische methode in deze context is zogenaamd supervised learning, waarbij de AI leert van voorbeeldgegevens die de juiste antwoorden al bevatten.
Een veelgebruikte feedbackmethode is het backpropagatie-algoritme dat in neurale netwerken wordt toegepast. Hierbij worden de fouten die het model maakt, achterwaarts door het netwerk doorgegeven om de gewichten van de neurale verbindingen aan te passen. Op deze manier leert het model van zijn fouten en worden zijn voorspellingen steeds nauwkeuriger.
De rol van training 🏋️♂️
Het trainen van een AI is een iteratief proces. Hoe meer data het model te zien krijgt en hoe vaker het op die data wordt getraind, hoe nauwkeuriger de voorspellingen worden. Er zijn echter grenzen: een overgetraind model kan zogenaamde "overfitting"-problemen ontwikkelen. Dit betekent dat het de trainingsdata zo goed onthoudt dat het slechtere resultaten levert op nieuwe, onbekende data. Daarom is het belangrijk om het model zo te trainen dat het generaliseert, oftewel dat het ook goede voorspellingen kan doen op nieuwe data.
Naast reguliere training zijn er ook methoden zoals transfer learning. Hierbij wordt een model dat al getraind is op een grote dataset gebruikt voor een nieuwe, vergelijkbare taak. Dit bespaart tijd en rekenkracht, omdat het model niet volledig vanaf nul getraind hoeft te worden.
Benut je sterke punten optimaal 🚀
De werking van kunstmatige intelligentie (AI) is gebaseerd op een complex samenspel van verschillende stappen. Van data-invoer en -voorverwerking tot modeltraining, voorspelling en feedback, vele factoren beïnvloeden de nauwkeurigheid en efficiëntie van AI. Een goed getrainde AI kan enorme voordelen bieden op veel gebieden van het leven – van het automatiseren van eenvoudige taken tot het oplossen van complexe problemen. Het is echter net zo belangrijk om de beperkingen en potentiële valkuilen van AI te begrijpen om de sterke punten ervan optimaal te benutten.
🤖📚 Simpel uitgelegd: Hoe wordt een AI getraind?
🤖📊 AI-leerproces: vastleggen, koppelen en opslaan
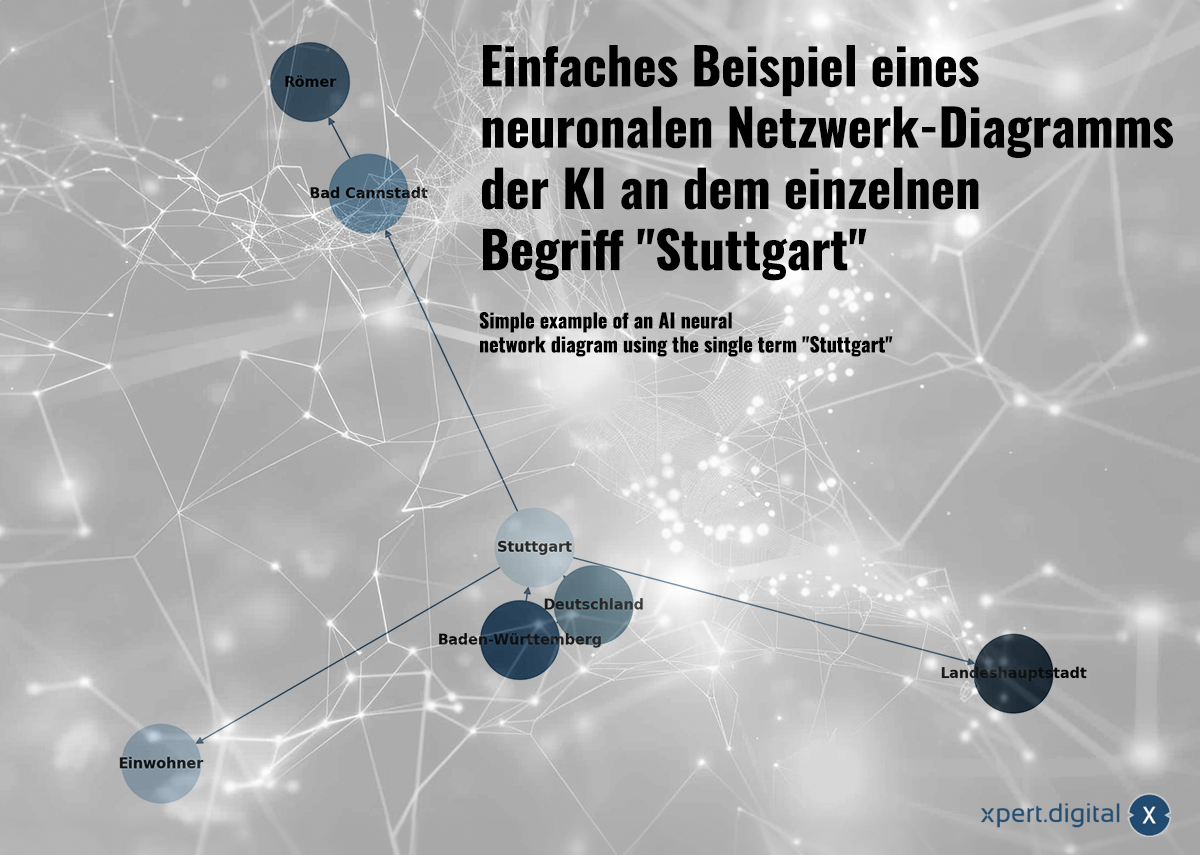
Eenvoudig voorbeeld van een diagram van een AI-neuronaal netwerk met de enkele term "Stuttgart" – Afbeelding: Xpert.Digital
🌟 Gegevens verzamelen en voorbereiden
De eerste stap in het leerproces van AI is het verzamelen en voorbereiden van de data. Deze data kan afkomstig zijn van verschillende bronnen, zoals databases, sensoren, teksten of afbeeldingen.
🌟 Gegevens relateren (Neuraal netwerk)
De verzamelde gegevens worden met elkaar verbonden in een neuraal netwerk. Elk datapakket wordt weergegeven door verbindingen in een netwerk van "neuronen" (knooppunten). Een eenvoudig voorbeeld met de stad Stuttgart zou er als volgt uit kunnen zien:
a) Stuttgart is een stad in Baden-Württemberg
b) Baden-Württemberg is een deelstaat in Duitsland
c) Stuttgart is een stad in Duitsland
d) Stuttgart had in 2023 een bevolking van 633.484
e) Bad Cannstatt is een district van Stuttgart
f) Bad Cannstatt werd gesticht door de Romeinen
g) Stuttgart is de hoofdstad van de deelstaat Baden-Württemberg
Afhankelijk van de omvang van de data worden de parameters voor mogelijke outputs gegenereerd met behulp van het AI-model. GPT-3 heeft bijvoorbeeld ongeveer 175 miljard parameters!
🌟 Opslaan en aanpassen (leren)
De data wordt ingevoerd in het neurale netwerk. Het passeert het AI-model en wordt verwerkt via verbindingen (vergelijkbaar met synapsen). De gewichten (parameters) tussen de neuronen worden aangepast om het model te trainen of een taak uit te voeren.
In tegenstelling tot conventionele opslagmethoden zoals directe toegang, geïndexeerde toegang, sequentiële of batchopslag, slaan neurale netwerken gegevens op een onconventionele manier op. De "gegevens" worden opgeslagen in de gewichten en biaswaarden van de verbindingen tussen de neuronen.
De feitelijke "opslag" van informatie in een neuraal netwerk vindt plaats door het aanpassen van de verbindingsgewichten tussen de neuronen. Het AI-model "leert" door deze gewichten en biaswaarden continu aan te passen op basis van de invoergegevens en een gedefinieerd leeralgoritme. Dit is een continu proces waarbij het model door herhaalde aanpassingen nauwkeurigere voorspellingen kan doen.
Het AI-model kan worden gezien als een vorm van programmering, omdat het wordt gecreëerd door middel van gedefinieerde algoritmen en wiskundige berekeningen, en de aanpassing van de parameters (gewichten) ervan continu wordt verbeterd om nauwkeurige voorspellingen te doen. Dit is een doorlopend proces.
Bias zijn extra parameters in neurale netwerken die worden toegevoegd aan de gewogen invoerwaarden van een neuron. Ze maken het mogelijk om de parameters te wegen (belangrijk, minder belangrijk, enz.), waardoor de AI flexibeler en nauwkeuriger wordt.
Neurale netwerken kunnen niet alleen individuele feiten opslaan, maar ook relaties tussen gegevens herkennen door middel van patroonherkenning. Het voorbeeld met Stuttgart illustreert hoe kennis aan een neuraal netwerk kan worden toegevoerd, maar neurale netwerken leren niet door expliciete kennis (zoals in dit eenvoudige voorbeeld), maar door de analyse van datap patronen. Daarom kunnen neurale netwerken niet alleen individuele feiten opslaan, maar ook gewichten en relaties tussen de invoergegevens leren.
Dit proces biedt een begrijpelijke introductie tot de werking van AI, en neurale netwerken in het bijzonder, zonder al te diep in te gaan op technische details. Het laat zien dat informatie niet in neurale netwerken wordt opgeslagen zoals in conventionele databases, maar door de verbindingen (gewichten) binnen het netwerk aan te passen.
🤖📚 In meer detail: Hoe wordt een AI getraind?
🏋️♂️ Het trainen van een AI, met name een machine learning-model, omvat verschillende stappen. AI-training is gebaseerd op de continue optimalisatie van modelparameters door middel van feedback en aanpassingen totdat het model optimaal presteert op de aangeleverde data. Hieronder volgt een gedetailleerde uitleg van hoe dit proces werkt:
1. 📊 Gegevens verzamelen en voorbereiden
Data vormt de basis van AI-training. Het bestaat doorgaans uit duizenden of miljoenen voorbeelden die het systeem moet analyseren. Voorbeelden hiervan zijn afbeeldingen, tekst of tijdreeksgegevens.
De gegevens moeten worden opgeschoond en genormaliseerd om onnodige foutbronnen te voorkomen. Vaak worden de gegevens omgezet in kenmerken die de relevante informatie bevatten.
2. 🔍 Definieer model
Een model is een wiskundige functie die de relaties in de data beschrijft. In neurale netwerken, die vaak worden gebruikt voor AI, bestaat het model uit meerdere lagen van onderling verbonden neuronen.
Elke neuron voert een wiskundige bewerking uit om de invoergegevens te verwerken en geeft vervolgens een signaal door aan de volgende neuron.
3. 🔄 Initialiseer de gewichten
De verbindingen tussen neuronen hebben gewichten die in eerste instantie willekeurig worden ingesteld. Deze gewichten bepalen hoe sterk een neuron reageert op een signaal.
Het doel van de training is om deze gewichten aan te passen, zodat het model betere voorspellingen doet.
4. ➡️ Voorwaartse propagatie
Tijdens de forward pass verwerkt het model de invoergegevens om een voorspelling te verkrijgen.
Elke laag verwerkt de gegevens en geeft deze door aan de volgende laag, totdat de laatste laag het resultaat levert.
5. ⚖️ Bereken de verliesfunctie
De verliesfunctie meet hoe goed de voorspellingen van het model overeenkomen met de werkelijke waarden (de labels). Een veelgebruikte maatstaf is de fout tussen de voorspelde en de werkelijke respons.
Hoe groter het verlies, hoe slechter de voorspelling van het model.
6. 🔙 Terugpropagatie
Bij de omgekeerde iteratie wordt de fout vanuit de uitvoer van het model teruggevoerd naar de voorgaande lagen.
De fout wordt herverdeeld over de gewichten van de verbindingen, en het model past de gewichten aan zodat de fouten kleiner worden.
Dit wordt gedaan met behulp van gradiëntdaling: de gradiëntvector wordt berekend, die aangeeft hoe de gewichten moeten worden aangepast om de fout te minimaliseren.
7. 🔧 Gewichten bijwerken
Nadat de fout is berekend, worden de gewichten van de verbindingen bijgewerkt met een kleine aanpassing op basis van de leerfrequentie.
De leerfrequentie bepaalt hoeveel de gewichten bij elke stap worden aangepast. Te grote aanpassingen kunnen het model instabiel maken, terwijl te kleine aanpassingen leiden tot een traag leerproces.
8. 🔁 Herhalen (Tijdperken)
Dit proces van forward pass, foutberekening en gewichtsupdate wordt herhaald, vaak over meerdere epochs (doorgangen door de volledige dataset), totdat het model een acceptabele nauwkeurigheid bereikt.
Met elk tijdperk leert het model iets meer en past het zijn gewichten verder aan.
9. 📉 Validatie en testen
Nadat het model is getraind, wordt het getest op een gevalideerde dataset om te controleren hoe goed het generaliseert. Dit zorgt ervoor dat het niet alleen de trainingsgegevens heeft "onthouden", maar ook goede voorspellingen doet op onbekende gegevens.
Testgegevens helpen om de uiteindelijke prestaties van het model te meten voordat het in de praktijk wordt gebruikt.
10. 🚀 Optimalisatie
Verdere stappen om het model te verbeteren zijn onder andere het afstemmen van hyperparameters (bijvoorbeeld het aanpassen van de leerfrequentie of de netwerkstructuur), regularisatie (om overfitting te voorkomen) of het vergroten van de hoeveelheid data.
📊🔙 Kunstmatige intelligentie: De 'black box' van AI begrijpelijk, inzichtelijk en verklaarbaar maken met behulp van Explainable AI (XAI), heatmaps, surrogaatmodellen of andere oplossingen


Kunstmatige intelligentie: De black box van AI begrijpelijk, inzichtelijk en verklaarbaar maken met behulp van Explainable AI (XAI), heatmaps, surrogaatmodellen of andere oplossingen – Afbeelding: Xpert.Digital
De zogenaamde "black box" van kunstmatige intelligentie (AI) vormt een significant en urgent probleem. Zelfs experts worstelen vaak met het feit dat ze niet volledig begrijpen hoe AI-systemen tot hun beslissingen komen. Dit gebrek aan transparantie kan aanzienlijke problemen veroorzaken, met name op cruciale gebieden zoals economie, politiek en geneeskunde. Een arts die voor diagnose en behandelingsadvies afhankelijk is van een AI-systeem, moet vertrouwen kunnen hebben in de genomen beslissingen. Als het besluitvormingsproces van een AI echter onvoldoende transparant is, ontstaat er onzekerheid, wat kan leiden tot een gebrek aan vertrouwen – en dat in situaties waarin mensenlevens op het spel staan.
Meer informatie vindt u hier:
Wij staan voor u klaar - Advies - Planning - Implementatie - Projectmanagement
☑️ Ondersteuning van het MKB op het gebied van strategie, advies, planning en implementatie
☑️ Opstellen of herzien van de digitale strategie en digitalisering
☑️ Uitbreiding en optimalisatie van internationale verkoopprocessen
☑️ Wereldwijde en digitale B2B-handelsplatformen
☑️ Pionier in bedrijfsontwikkeling

Konrad Wolfenstein
Ik sta graag tot uw beschikking als uw persoonlijke adviseur.
U kunt contact met mij opnemen door onderstaand contactformulier in te vullen of mij te bellen op +49 7348 4088 965 .
Ik kijk uit naar ons gezamenlijke project.
Schrijf me




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital is een platform voor de industrie, gericht op digitalisering, werktuigbouwkunde, logistiek/intralogistiek en fotovoltaïsche energie.
Met onze 360°-oplossing voor bedrijfsontwikkeling ondersteunen we gerenommeerde bedrijven van acquisitie tot aftersales.
Marktinformatie, social media marketing, marketingautomatisering, contentontwikkeling, PR, mailcampagnes, gepersonaliseerde social media en lead nurturing behoren tot onze digitale tools.
Meer informatie vindt u op: www.xpert.digital - www.xpert.solar - www.xpert.plus
Blijf in contact











