인공지능을 쉽게 설명해 드리겠습니다. 빅데이터와 같은 엄청난 양의 데이터를 어떻게 관리할까요? 특정 패턴을 파악하거나, 패턴에 따라 행동할 때만 가능합니다.

인공지능(AI) - 간단한 구문
개인적인 실험 하나 해볼게요. 머릿속에 특정한 이미지가 떠오릅니다. 오늘은 빨간색 캐비닛에 흰색 손잡이가 달린 모습이라고 가정해 봅시다. 당신은 어떻게 하시겠습니까?
구글 검색창에 "빨간색 캐비닛, 흰색 손잡이"를 입력합니다.

수확량? 미미함.
두 번째 시도: 구글 검색창에 "빨간색 캐비닛, 흰색 손잡이"를 입력합니다.

결과는 이미 좋아졌지만, 분명히 더 좋아질 수도 있습니다.
구글 검색을 활용하는 것은 프로그래밍의 첫걸음입니다. 검색 쿼리를 수집하고 이를 알고리즘과 코드로 변환하는 것이 신경망을 구성하는 요소입니다.
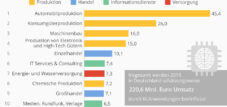
위 그림에서 볼 수 있듯이, 머신 러닝은 단기간에 구현할 수 있는 기술이 아닙니다. 많은 시간과 노력이 필요하며, 이는 개발 비용이 높은 이유를 설명해 줍니다. 하지만 인공지능은 휴가도 없고, 은퇴도 없고, 그 외의 자연적인 공백 기간도 없다는 점을 고려하면 상황은 완전히 달라집니다.
하지만 흰색 손잡이가 달린 빨간색 수납장이 내일도 여전히 유행일까요? 당신의 라이프스타일에 어울릴까요? 취향은 변합니다. 바로 이 지점에서 딥러닝이 중요한 역할을 합니다. 앞서 예시를 들었듯이, 검색을 계속할수록 AI는 사용자의 관심 주제를 기반으로 검색 행동이 어떻게 변화했는지 학습하고 인식합니다. 그리고 1년 후에는 파란색 손잡이가 달린 녹색 수납장에 관심을 가질 수도 있다는 것을 스스로 예측하는 새로운 알고리즘을 개발합니다.
끔찍한가요? 어떤 사람들에게는 그럴지도 모릅니다. 하지만 사실 그렇게 끔찍한 일은 아닙니다. 미지의 것에 대한 두려움이 우리를 속이고 있는 것이죠. 만약 사람들에게 내일 텔레비전에서 어떤 프로그램을 보면 흥미로울 것 같냐고 물어본다면, 아주 다양한 대답이 나올 겁니다. 모두 같은 대답은 아닐 거예요. 자, 그렇다면 어떤 기준으로 어떤 제안을 받아들일까요? 내용일까요, 아니면 진행자의 매력일까요?
인공지능에도 마찬가지입니다. 결과는 신경망이 얼마나 약하게 또는 강하게 "프로그래밍"되었는지에 따라 달라집니다. 핵심은 패턴 분석이며, 이는 우리가 좋은 결정을 내리는 데 도움을 주어야지 우리를 통제해서는 안 됩니다. 만약 우리가 빅데이터에서 패턴 분석을 제대로 수행하지 못한다면, 우리는 무자비하게 파멸할 것입니다. 이것이 바로 진정한 공포의 시나리오입니다.
계속 연락하세요