
Veröffentlicht am: 15. April 2025 / Update vom: 15. April 2025 – Verfasser: Konrad Wolfenstein

KI-Suche Ranking: Die KI-Modelle von Perplexity Sonar sind führend in der KI-Suchlandschaft – Bild: Xpert.Digital
Sonar-Reasoning-Pro-High: Perplexitys Sprung an die Spitze der KI-Suche
KI-Suchsysteme im Wandel: Perplexitys Meilenstein in der Entwicklung
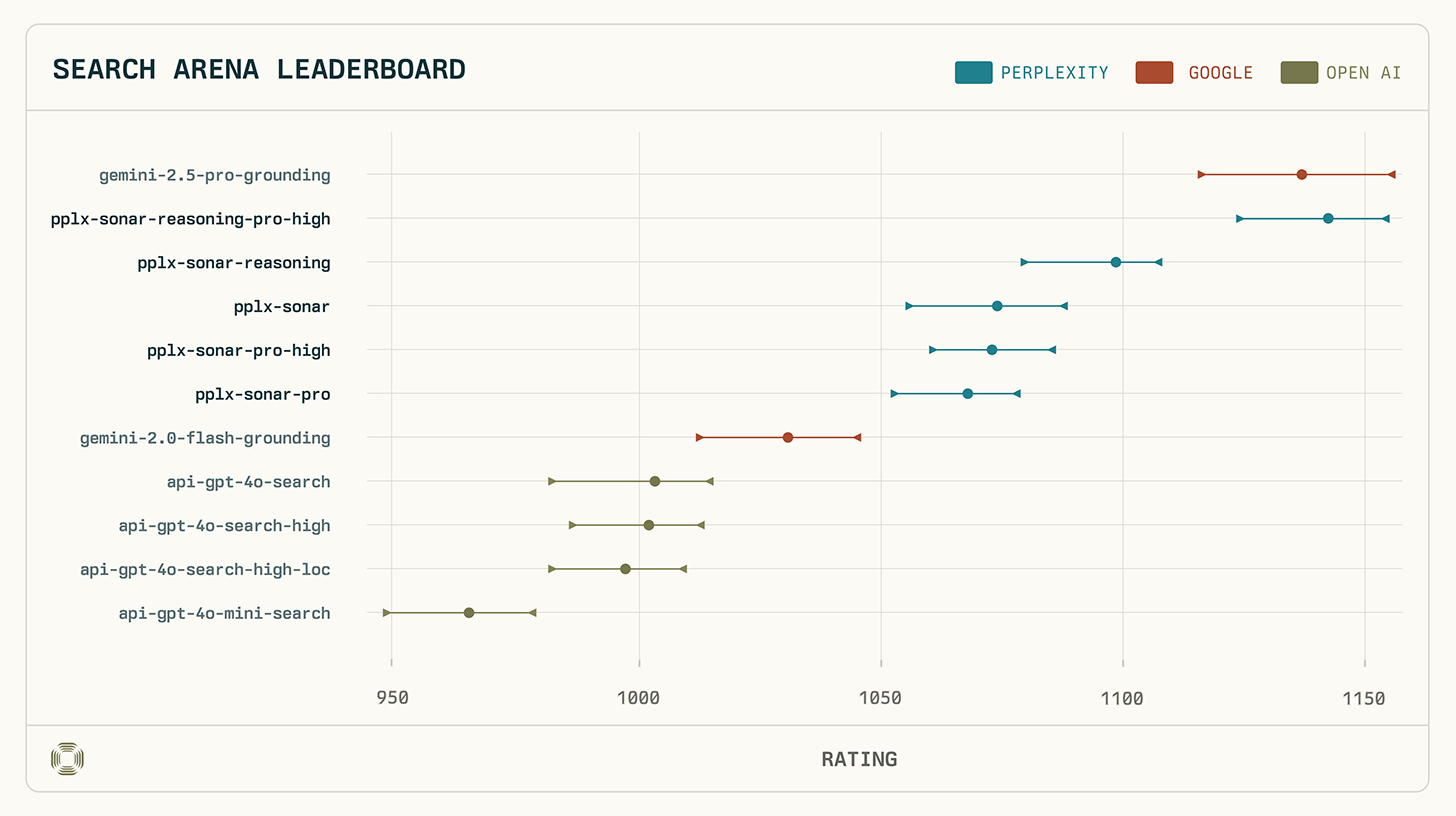
Perplexitys Sonar-Modelle haben in der neuesten LM Search Arena Evaluation beeindruckende Ergebnisse erzielt, wobei Sonar-Reasoning-Pro-High nach Googles Gemini-2.5-Pro-Grounding führend mit führend ist. Diese Bewertung stellt einen bedeutenden Meilenstein in der Evolution von KI-Suchsystemen dar und unterstreicht Perplexitys führende Position in diesem wettbewerbsintensiven Bereich.
Passend dazu:

Die LM Search Arena Evaluation
Die LM Search Arena ist eine neuartige Evaluationsplattform, die von LM Arena entwickelt wurde, um suchverstärkte KI-Systeme basierend auf menschlichen Präferenzen zu bewerten. Im Gegensatz zu früheren Benchmarks wie SimpleQA, die sich auf enge faktische Genauigkeit konzentrierten, evaluiert die Search Arena, wie Modelle bei realen Nutzeranfragen in Bereichen wie Programmierung, Schreiben, Recherche und Empfehlungen abschneiden.
Die Bewertung fand zwischen dem 18. März und dem 13. April 2025 statt und sammelte über 10.000 menschliche Präferenzstimmen für 11 Modelle. Benutzer wurden aufgefordert, Anfragen zu stellen und anschließend zu bewerten, welche Modellantwort ihre Informationsbedürfnisse besser erfüllte.
Herausragende Leistung der Sonar-Modelle
KI-Suche Rangliste: Herausragende Leistung der Sonar-Modelle – Bild: Perplexity
Perplexitys Sonar-Reasoning-Pro-High erreichte einen Arena-Score von 1136 (±21/−19), was statistisch gleichwertig mit Googles Gemini-2.5-Pro-Grounding (1142 +14/-17) ist und somit eine gemeinsame Spitzenposition bedeutet. Besonders bemerkenswert ist, dass bei direkten Vergleichen Sonar-Reasoning-Pro-High Gemini-2.5-Pro-Grounding in 53% der Fälle übertraf.
Die Dominanz von Perplexity in der Evaluation wird durch folgende Rangliste verdeutlicht:
- Gemini-2.5-Pro-Grounding (1142 Punkte)
- Sonar-Reasoning-Pro-High (1136 Punkte)
- Sonar-Reasoning (1097 Punkte)
- Sonar (1072 Punkte)
- Sonar-Pro-High (1071 Punkte)
- Sonar-Pro (1066 Punkte)
Alle Perplexity-Modelle belegten die oberen Ränge und übertrafen dabei deutlich andere bewertete Modelle von Google (Gemini-2.0-Flash-Grounding) und OpenAI (GPT-4o Search).
Schlüsselfaktoren für den Erfolg
Die Search Arena identifizierte drei Faktoren, die stark mit der menschlichen Präferenz korrelierten:
Umfassendere Antworten
Längere Antworten wurden von Nutzern bevorzugt (Koeffizient 0,255, p<0,05). Die Sonar-Modelle liefern ausführliche, detaillierte Informationen zu einer Vielzahl von Themen, was zu einer höheren Nutzerzufriedenheit führt.
Überlegenheit bei Quellenangaben
Eine höhere Anzahl an Zitaten korrelierte stark mit der Nutzerpräferenz (Koeffizient 0,234, p<0,05). Die Sonar-Modelle führen eine tiefere Suche durch und zitieren im Durchschnitt 2-3 Mal mehr Quellen als vergleichbare Gemini-Modelle. Diese umfassende Quellennutzung stellt sicher, dass die bereitgestellten Informationen gut belegt und vertrauenswürdig sind.
Nutzung diverser Quellen
Die Evaluation zeigte, dass Zitate aus Community-Webquellen besonders geschätzt wurden. Die Sonar-Modelle zeichnen sich durch die effektive Nutzung verschiedener Quellen aus, darunter auch YouTube, Community-Plattformen und autoritative Quellen.
Kontrollexperimente bestätigten diese Erkenntnisse und zeigten, dass die Suchtiefe ein wesentlicher Leistungsunterschied zwischen den Modellen ist. Wenn für Zitate kontrolliert wurde, konvergierten die Modellrankings, was darauf hindeutet, dass die Suchtiefe ein entscheidender Differenzierungsfaktor ist.
Passend dazu:

Die Technologie hinter Sonar
Das Sonar-Modell von Perplexity basiert auf Llama 3.3 70B und wurde speziell für die Optimierung der Antwortqualität und Benutzererfahrung weiterentwickelt. Es wurde darauf trainiert, die Faktentreue und Lesbarkeit von Antworten zu verbessern.
Geschwindigkeit und Leistung
Sonar wird von der Cerebras-Inferenzinfrastruktur angetrieben und liefert Antworten mit beeindruckender Geschwindigkeit – 1200 Token pro Sekunde, was eine nahezu sofortige Antwortgenerierung ermöglicht. Diese Geschwindigkeit ist fast 10-mal schneller als bei vergleichbaren Modellen wie Gemini 2.0 Flash.
Benutzerpräferenz und Leistungsvergleich
Umfangreiche A/B-Tests zeigten, dass Sonar Modelle wie GPT-4o mini und Claude 3.5 Haiku deutlich übertrifft und sogar die Leistung von Spitzenmodellen wie GPT-4o und Claude 3.5 Sonnet erreicht oder übertrifft, was die Nutzerzufriedenheit angeht.
Sonar API: Zugänglichkeit für Entwickler
Perplexity bietet seine Sonar-Technologie auch über APIs an, was Entwicklern ermöglicht, KI-gestützte Suchfunktionen in ihre Anwendungen zu integrieren. Es gibt zwei Hauptversionen der API:
Sonar API
Die Standard-Sonar-API ist leichtgewichtig, kostengünstig, schnell und einfach zu bedienen. Sie wurde für Unternehmen konzipiert, die unkomplizierte Frage-Antwort-Funktionen benötigen und auf Geschwindigkeit optimiert sind.
Sonar Pro API
Für Unternehmen, die fortschrittlichere Funktionen benötigen, bietet die Sonar Pro API die Möglichkeit, komplexere, mehrstufige Anfragen zu bearbeiten. Sie generiert im Durchschnitt doppelt so viele Quellenangaben pro Suche wie die Standard-Version und verfügt über ein größeres Kontextfenster für längere und nuanciertere Suchanfragen.
Die Preisstruktur spiegelt diese Unterschiede wider: Standard-Sonar kostet 5 $ pro 1.000 Suchen plus 1 $ pro 750.000 Wörter (Eingabe und Ausgabe kombiniert). Sonar Pro behält die gleichen 5 $ pro 1.000 Suchen bei, berechnet aber 3 $ pro 750.000 Eingabewörter und 15 $ pro 750.000 generierte Wörter.
Von Faktoren der Genauigkeit bis zur Nutzerorientierung: Perplexitys Sonar überzeugt
Die herausragenden Ergebnisse in der LM Search Arena Evaluation bestätigen, dass Perplexitys Sonar-Modelle zu den führenden KI-Suchsystemen gehören. Durch die Kombination von Faktentreue, umfangreichen Quellenangaben und tiefer Suchfähigkeit bieten sie eine überlegene Benutzererfahrung.
Diese Erfolge unterstreichen Perplexitys Position als Innovator im Bereich der KI-gestützten Suche und Informationsbereitstellung. Die kontinuierliche Verbesserung der Modelle basierend auf Nutzerfeedback deutet auf weiteres Potenzial für zukünftige Entwicklungen hin.
Für Perplexity-Nutzer bedeuten diese Ergebnisse, dass sie Zugang zu erstklassiger Genauigkeit, umfassender Quellenattribution und hochwertigen Antworten zu einer breiten Palette von Themen haben. Pro-Nutzer können weiterhin von diesen leistungsstarken Modellen profitieren, indem sie Sonar als ihr Standardmodell in den Einstellungen festlegen.
Das starke Abschneiden von Sonar in der Search Arena Evaluation unterstreicht nicht nur die technologische Kompetenz von Perplexity, sondern zeigt auch den Weg für die Zukunft der KI-Suche auf: genauer, umfassender und mit einem tieferen Verständnis für die Informationsbedürfnisse der Nutzer.
Passend dazu:
Ihr AI-Transformation, AI-Integration und AI-Plattform Branchenexperte
☑️ Unsere Geschäftssprache ist Englisch oder Deutsch
☑️ NEU: Schriftverkehr in Ihrer Landessprache!

Konrad Wolfenstein
Gerne stehe ich Ihnen und mein Team als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie hier das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 89 89 674 804 (München) an. Meine E-Mail Adresse lautet: wolfenstein∂xpert.digital
Ich freue mich auf unser gemeinsames Projekt.








