


Ein Erklärungsversuch zur KI: Wie arbeitet die Künstliche Intelligenz und wie wird sie trainiert? – Bild: Xpert.Digital
📊 Vom Dateneingang bis zur Modellvorhersage: Der KI-Prozess
Wie arbeitet eine Künstliche Intelligenz (KI)? 🤖
Die Funktionsweise einer Künstlichen Intelligenz (KI) lässt sich in mehrere, klar definierte Schritte unterteilen. Jeder dieser Schritte ist entscheidend für das Endergebnis, das die KI liefert. Dabei beginnt der Prozess bei der Dateneingabe und endet bei der Modellvorhersage und eventuellen Rückkopplung oder weiteren Trainingsrunden. Diese Phasen beschreiben den Ablauf, den fast alle KI-Modelle durchlaufen, unabhängig davon, ob es sich um einfache Regelwerke oder hochkomplexe neuronale Netzwerke handelt.
1. Der Dateninput 📊
Die Grundlage jeder Künstlichen Intelligenz sind die Daten, mit denen sie arbeitet. Diese Daten können in verschiedenen Formen vorliegen, zum Beispiel als Bilder, Texte, Audiodateien oder Videos. Die KI nutzt diese Rohdaten, um daraus Muster zu erkennen und Entscheidungen zu treffen. Die Qualität und Quantität der Daten spielen hierbei eine zentrale Rolle, denn sie beeinflussen maßgeblich, wie gut oder schlecht das Modell später funktioniert.
Je umfangreicher und genauer die Daten sind, desto besser kann die KI lernen. Wenn beispielsweise eine KI für die Bildverarbeitung trainiert wird, benötigt sie eine große Menge an Bilddaten, um verschiedene Objekte korrekt zu identifizieren. Bei Sprachmodellen sind es Textdaten, die der KI dabei helfen, menschliche Sprache zu verstehen und zu generieren. Der Dateninput ist der erste und einer der wichtigsten Schritte, da die Qualität der Vorhersagen nur so gut sein kann wie die zugrunde liegenden Daten. Ein berühmtes Prinzip in der Informatik beschreibt dies mit dem Sprichwort „Garbage in, garbage out“ – schlechte Daten führen zu schlechten Ergebnissen.
2. Die Datenvorverarbeitung 🧹
Sobald die Daten eingegeben wurden, müssen sie aufbereitet werden, bevor sie in das eigentliche Modell eingespeist werden können. Dieser Prozess wird als Datenvorverarbeitung bezeichnet. Hierbei geht es darum, die Daten in eine Form zu bringen, die vom Modell optimal verarbeitet werden kann.
Ein gängiger Schritt in der Vorverarbeitung ist die Normalisierung der Daten. Das bedeutet, dass die Daten in einen einheitlichen Wertebereich gebracht werden, damit sie vom Modell gleichmäßig behandelt werden. Ein Beispiel wäre, alle Pixelwerte eines Bildes auf einen Bereich von 0 bis 1 zu skalieren, anstatt von 0 bis 255.
Ein weiterer wichtiger Teil der Vorverarbeitung ist die sogenannte Feature-Extraktion. Dabei werden aus den Rohdaten bestimmte Merkmale (Features) herausgearbeitet, die für das Modell besonders relevant sind. Bei der Bildverarbeitung könnten das zum Beispiel Kanten oder bestimmte Farbmuster sein, während bei Texten relevante Schlüsselwörter oder Satzstrukturen extrahiert werden. Die Vorverarbeitung ist entscheidend, um den Lernprozess der KI effizienter und präziser zu gestalten.
3. Das Modell 🧩
Das Modell ist das Herzstück jeder Künstlichen Intelligenz. Hier werden die Daten analysiert und auf Basis von Algorithmen und mathematischen Berechnungen verarbeitet. Ein Modell kann in verschiedenen Formen existieren. Eines der bekanntesten Modelle ist das neuronale Netz, das sich an der Funktionsweise des menschlichen Gehirns orientiert.
Neuronale Netze bestehen aus mehreren Schichten von künstlichen Neuronen, die Informationen verarbeiten und weitergeben. Jede Schicht nimmt die Ausgaben der vorherigen Schicht und verarbeitet sie weiter. Der Lernprozess eines neuronalen Netzes besteht darin, die Gewichtungen der Verbindungen zwischen diesen Neuronen so anzupassen, dass das Netz immer genauere Vorhersagen oder Klassifizierungen treffen kann. Diese Anpassung erfolgt durch Training, bei dem das Netz auf große Mengen an Beispieldaten zugreift und seine internen Parameter (Gewichte) iterativ verbessert.
Neben neuronalen Netzen gibt es auch viele andere Algorithmen, die in KI-Modellen verwendet werden. Dazu gehören Entscheidungsbäume, Random Forests, Support Vector Machines und viele weitere. Welcher Algorithmus zum Einsatz kommt, hängt von der spezifischen Aufgabe und den zur Verfügung stehenden Daten ab.
4. Die Modellvorhersage 🔍
Nachdem das Modell mit Daten trainiert wurde, ist es in der Lage, Vorhersagen zu treffen. Dieser Schritt wird als Modellvorhersage bezeichnet. Die KI erhält eine Eingabe und gibt basierend auf den bisher gelernten Mustern eine Ausgabe, das heißt eine Vorhersage oder Entscheidung, zurück.
Diese Vorhersage kann unterschiedliche Formen annehmen. In einem Bildklassifizierungsmodell könnte die KI zum Beispiel vorhersagen, welches Objekt auf einem Bild zu sehen ist. In einem Sprachmodell könnte sie eine Vorhersage darüber treffen, welches Wort als Nächstes in einem Satz kommt. Bei finanziellen Vorhersagen könnte die KI prognostizieren, wie sich der Aktienmarkt entwickeln wird.
Es ist wichtig zu betonen, dass die Genauigkeit der Vorhersagen stark von der Qualität der Trainingsdaten und der Modellarchitektur abhängt. Ein Modell, das auf unzureichenden oder verzerrten Daten trainiert wurde, wird mit großer Wahrscheinlichkeit fehlerhafte Vorhersagen treffen.
5. Rückkopplung und Training (optional) ♻️
Ein weiterer wichtiger Bestandteil der Arbeit einer KI ist der Rückkopplungsmechanismus. Hierbei wird das Modell regelmäßig überprüft und weiter optimiert. Dieser Prozess erfolgt entweder während des Trainings oder nach der Modellvorhersage.
Falls das Modell falsche Vorhersagen macht, kann es durch Rückkopplung lernen, diese Fehler zu erkennen und seine internen Parameter entsprechend anzupassen. Dies geschieht durch den Vergleich der Modellvorhersagen mit den tatsächlichen Ergebnissen (z. B. bei bekannten Daten, für die die richtigen Antworten bereits vorhanden sind). Ein typisches Verfahren in diesem Zusammenhang ist das sogenannte überwachte Lernen, bei dem die KI aus Beispieldaten lernt, die bereits mit den richtigen Antworten versehen sind.
Eine gängige Methode der Rückkopplung ist der Backpropagation-Algorithmus, der in neuronalen Netzen verwendet wird. Dabei werden die Fehler, die das Modell macht, rückwärts durch das Netz propagiert, um die Gewichte der Neuronenverbindungen anzupassen. So lernt das Modell aus seinen Fehlern und wird immer präziser in seinen Vorhersagen.
Die Rolle des Trainings 🏋️♂️
Das Training einer KI ist ein iterativer Prozess. Je mehr Daten das Modell sieht und je öfter es auf Basis dieser Daten trainiert wird, desto genauer werden seine Vorhersagen. Allerdings gibt es auch Grenzen: Ein übermäßig trainiertes Modell kann sogenannte „Overfitting“-Probleme bekommen. Das bedeutet, dass es die Trainingsdaten so gut auswendig lernt, dass es auf neuen, unbekannten Daten schlechtere Ergebnisse liefert. Deshalb ist es wichtig, das Modell so zu trainieren, dass es generalisiert, also auch auf neuen Daten gute Vorhersagen trifft.
Zusätzlich zum regulären Training gibt es auch Verfahren wie das Transfer-Learning. Hier wird ein Modell, das bereits auf einer großen Datenmenge trainiert wurde, für eine neue, ähnliche Aufgabe verwendet. Dies spart Zeit und Rechenleistung, da das Modell nicht komplett von Grund auf neu trainiert werden muss.
Stärken optimal nutzen 🚀
Die Arbeit einer Künstlichen Intelligenz basiert auf einem komplexen Zusammenspiel verschiedener Schritte. Von der Dateneingabe über die Vorverarbeitung und das Modelltraining bis hin zur Vorhersage und Rückkopplung gibt es viele Faktoren, die die Genauigkeit und Effizienz der KI beeinflussen. Eine gut trainierte KI kann in vielen Bereichen des Lebens enorme Vorteile bieten – von der Automatisierung einfacher Aufgaben bis hin zur Lösung komplexer Probleme. Doch ebenso wichtig ist es, die Grenzen und potenziellen Fallstricke einer KI zu verstehen, um ihre Stärken optimal nutzen zu können.
🤖📚 Einfach erklärt: Wie wird eine KI trainiert?
🤖📊 KI-Lernprozess: Erfassen, Verknüpfen und Speichern
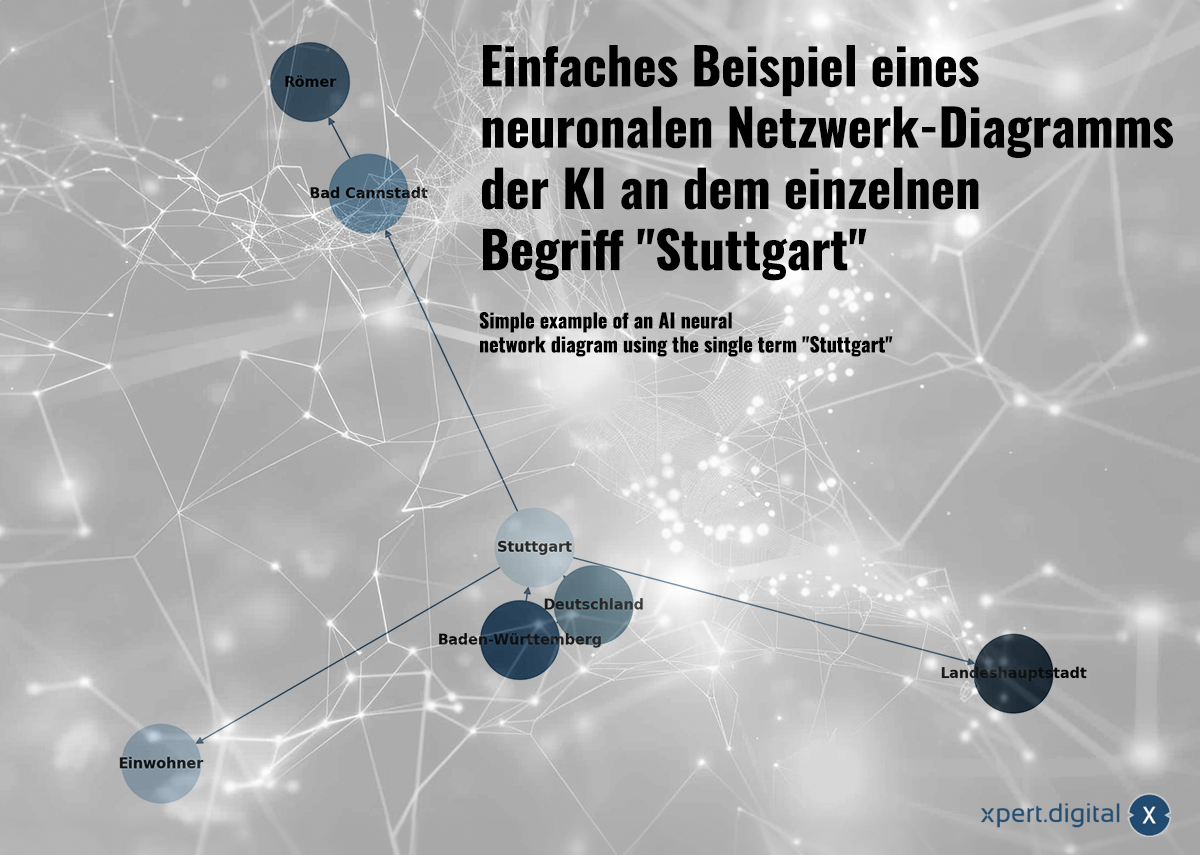
Einfaches Beispiel eines neuronalen Netzwerk-Diagramms der KI an dem einzelnen Begriff “Stuttgart” – Bild: Xpert.Digital
🌟 Daten sammeln und vorbereiten
Der erste Schritt im KI-Lernprozess ist das Sammeln und Vorbereiten der Daten. Diese Daten können aus verschiedenen Quellen stammen, z.B. aus Datenbanken, Sensoren, Texten oder Bildern.
🌟 Daten in Beziehung setzen (Neurales Netz)
Die gesammelten Daten werden in einem neuronalen Netz miteinander in Beziehung gesetzt. Jedes Datenpaket wird durch Verbindungen in einem Netz von “Neuronen” (Knoten) dargestellt. Ein einfaches Beispiel mit der Stadt Stuttgart könnte so aussehen:
a) Stuttgart ist eine Stadt in Baden-Württemberg
b) Baden-Württemberg ist ein Bundesland in Deutschland
c) Stuttgart ist eine Stadt in Deutschland
d) Stuttgart hat im Jahr 2023 eine Einwohnerzahl von 633.484
e) Bad Cannstatt ist ein Stadtbezirk von Stuttgart
f) Bad Cannstatt wurde von den Römern gegründet
g) Stuttgart ist die Landeshauptstadt von Baden-Württemberg
Je nach Größe des Datenvolumens, werden hieraus über das verwendete KI-Modell die Parameter für potenzielle Ausgaben erstellt. Als Beispiel: GPT-3 hat ca. 175 Milliarden Parameter!
🌟 Speicherung und Anpassung (Lernen)
Die Daten werden dem neuronalen Netzwerk zugeführt. Sie durchlaufen das KI-Modell und werden über Verbindungen (ähnlich wie Synapsen) verarbeitet. Dabei werden die Gewichtungen (Parameter) zwischen den Neuronen angepasst, um das Modell zu trainieren oder eine Aufgabe auszuführen.
Im Gegensatz zu herkömmlichen Speicherformen wie direktem Zugriff, indiziertem Zugriff, sequentieller oder Stapelspeicherung, speichern neuronale Netze die Daten in einer unkonventionellen Weise. Die “Daten” werden in den Gewichten und Biases der Verbindungen zwischen den Neuronen gespeichert.
Die eigentliche „Speicherung“ der Informationen in einem neuronalen Netz erfolgt durch die Anpassung der Verbindungsgewichte zwischen den Neuronen. Das KI-Modell “lernt”, indem es diese Gewichte und Biases auf Basis der Eingangsdaten und eines definierten Lernalgorithmus ständig anpasst. Dies ist ein kontinuierlicher Prozess, bei dem das Modell durch immer wiederkehrende Anpassungen präzisere Vorhersagen treffen kann.
Das KI-Modell kann als eine Art Programmierung betrachtet werden, da es durch definierte Algorithmen und mathematische Berechnungen entsteht und die Anpassung seiner Parameter (Gewichte) kontinuierlich verbessert wird, um genaue Vorhersagen zu treffen. Das ist ein fortlaufender Prozess.
Biases sind zusätzliche Parameter in neuronalen Netzwerken, die zu den gewichteten Eingabewerten eines Neurons addiert werden. Sie ermöglichen die Parameter zu gewichten (wichtig, weniger, wichtig u.a.), wodurch die KI flexibler und genauer wird.
Neuronale Netze können aber nicht nur einzelne Fakten speichern, sondern durch Mustererkennung Zusammenhänge zwischen den Daten erkennen. Das Beispiel mit Stuttgart veranschaulicht, wie Wissen in ein neuronales Netz eingebracht werden kann, aber neuronale Netze lernen nicht durch explizites Wissen (wie in diesem einfachen Beispiel), sondern durch die Analyse von Datenmustern. Neuronale Netze können also nicht nur einzelne Fakten speichern, sondern Gewichte und Beziehungen zwischen den Eingabedaten lernen.
Dieser Ablauf gibt eine verständliche Einführung, wie KI und insbesondere neuronale Netze funktionieren, ohne zu tief in technische Details einzutauchen. Es zeigt, dass die Speicherung von Informationen in neuronalen Netzen nicht wie in herkömmlichen Datenbanken erfolgt, sondern durch die Anpassung der Verbindungen (Gewichte) innerhalb des Netzwerks.
🤖📚 Detaillierter: Wie wird eine KI trainiert?
🏋️♂️ Das Training einer KI, insbesondere eines maschinellen Lernmodells, erfolgt in mehreren Schritten. Das Training einer KI basiert auf der fortlaufenden Optimierung von Modellparametern durch Rückkopplung und Anpassung, bis das Modell die beste Leistung auf den bereitgestellten Daten zeigt. Hier ist eine detaillierte Erklärung, wie dieser Prozess funktioniert:
1. 📊 Daten sammeln und vorbereiten
Daten sind die Grundlage des KI-Trainings. Sie bestehen in der Regel aus Tausenden oder Millionen von Beispielen, die das System analysieren soll. Beispiele sind Bilder, Texte, oder Zeitreihendaten.
Die Daten müssen bereinigt und normalisiert werden, um unnötige Fehlerquellen zu vermeiden. Oft werden die Daten in Features (Merkmale) umgewandelt, die die relevanten Informationen enthalten.
2. 🔍 Modell definieren
Ein Modell ist eine mathematische Funktion, die die Beziehungen in den Daten beschreibt. Bei neuronalen Netzen, die häufig für KI verwendet werden, besteht das Modell aus mehreren Schichten von Neuronen, die miteinander verbunden sind.
Jedes Neuron führt eine mathematische Operation aus, um die Eingabedaten zu verarbeiten, und gibt dann ein Signal an das nächste Neuron weiter.
3. 🔄 Gewichte initialisieren
Die Verbindungen zwischen den Neuronen haben Gewichte, die anfangs zufällig gesetzt werden. Diese Gewichte bestimmen, wie stark ein Neuron auf ein Signal reagiert.
Ziel des Trainings ist es, diese Gewichte so zu justieren, dass das Modell bessere Vorhersagen macht.
4. ➡️ Vorwärtsdurchlauf (Forward Propagation)
Beim Vorwärtsdurchlauf werden die Eingabedaten durch das Modell geleitet, um eine Vorhersage zu erhalten.
Jede Schicht verarbeitet die Daten und leitet sie an die nächste Schicht weiter, bis die letzte Schicht das Ergebnis liefert.
5. ⚖️ Verlustfunktion berechnen
Die Verlustfunktion misst, wie gut die Vorhersagen des Modells im Vergleich zu den tatsächlichen Werten (den Labels) sind. Ein gängiges Maß ist der Fehler zwischen der vorhergesagten und der tatsächlichen Antwort.
Je höher der Verlust, desto schlechter war die Vorhersage des Modells.
6. 🔙 Rückwärtsdurchlauf (Backpropagation)
Im Rückwärtsdurchlauf wird der Fehler von der Ausgabe des Modells zu den vorhergehenden Schichten zurückgeführt.
Dabei wird der Fehler auf die Gewichte der Verbindungen zurückverteilt, und das Modell passt die Gewichte so an, dass die Fehler kleiner werden.
Dies geschieht mit Hilfe des Gradientenabstiegs: Es wird der Gradientenvektor berechnet, der angibt, wie die Gewichte verändert werden sollen, um den Fehler zu minimieren.
7. 🔧 Gewichte aktualisieren
Nachdem der Fehler berechnet wurde, werden die Gewichte der Verbindungen mit einer kleinen Anpassung, basierend auf der Lernrate, aktualisiert.
Die Lernrate bestimmt, wie stark die Gewichte bei jedem Schritt geändert werden. Zu große Änderungen können das Modell instabil machen, zu kleine Änderungen führen zu einem langsamen Lernprozess.
8. 🔁 Wiederholen (Epochs)
Dieser Prozess des Vorwärtsdurchlaufs, der Fehlerberechnung und der Gewichtsaktualisierung wird wiederholt, oft über mehrere Epochen (Durchläufe durch den gesamten Datensatz), bis das Modell eine akzeptable Genauigkeit erreicht.
Bei jeder Epoche lernt das Modell etwas mehr und passt seine Gewichte weiter an.
9. 📉 Validierung und Testen
Nachdem das Modell trainiert wurde, wird es auf einem validierten Datensatz getestet, um zu prüfen, wie gut es generalisiert. Dies stellt sicher, dass es nicht nur die Trainingsdaten „auswendig gelernt“ hat, sondern auf unbekannten Daten gute Vorhersagen trifft.
Testdaten helfen dabei, die endgültige Leistung des Modells zu messen, bevor es in der Praxis verwendet wird.
10. 🚀 Optimierung
Weitere Schritte zur Verbesserung des Modells umfassen Hyperparameter-Tuning (z. B. Anpassen der Lernrate oder der Netzwerkstruktur), Regularisierung (um Overfitting zu vermeiden), oder das **Erhöhen der Datenmenge.
📊🔙 Künstliche Intelligenz: Die Black-Box der KI mit Explainable AI (XAI), Heatmaps, Surrogat Modellen oder anderen Lösungen verständlich, nachvollziehbar und erklärbar machen


Künstliche Intelligenz: Die Black-Box der KI mit Explainable AI (XAI), Heatmaps, Surrogat Modellen oder anderen Lösungen verständlich, nachvollziehbar und erklärbar machen – Bild: Xpert.Digital
Die sogenannte „Black-Box“ der Künstlichen Intelligenz (KI) stellt ein bedeutendes und aktuelles Problem dar. Selbst Experten stehen oft vor der Herausforderung, nicht vollständig nachvollziehen zu können, wie KI-Systeme zu ihren Entscheidungen gelangen. Diese Intransparenz kann besonders in kritischen Bereichen wie der Wirtschaft, Politik oder Medizin erhebliche Probleme mit sich bringen. Ein Arzt oder Mediziner, der sich bei der Diagnose und Therapieempfehlung auf ein KI-System verlässt, muss Vertrauen in die getroffenen Entscheidungen haben. Wenn jedoch die Entscheidungsfindung einer KI nicht ausreichend transparent ist, entsteht Unsicherheit und möglicherweise ein Mangel an Vertrauen – und das in Situationen, in denen Menschenleben auf dem Spiel stehen könnten.
Mehr dazu hier:
Wir sind für Sie da - Beratung - Planung - Umsetzung - Projektmanagement
☑️ KMU Support in der Strategie, Beratung, Planung und Umsetzung
☑️ Erstellung oder Neuausrichtung der Digitalstrategie und Digitalisierung
☑️ Ausbau und Optimierung der internationalen Vertriebsprozesse
☑️ Globale & Digitale B2B-Handelsplattformen
☑️ Pioneer Business Development

Konrad Wolfenstein
Gerne stehe ich Ihnen als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie unten das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 7348 4088 965 an.
Ich freue mich auf unser gemeinsames Projekt.
Schreiben Sie mir




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital ist ein Hub für die Industrie mit den Schwerpunkten, Digitalisierung, Maschinenbau, Logistik/Intralogistik und Photovoltaik.
Mit unserer 360° Business Development Lösung unterstützen wir namhafte Unternehmen vom New Business bis After Sales.
Market Intelligence, Smarketing, Marketing Automation, Content Development, PR, Mail Campaigns, Personalized Social Media und Lead Nurturing sind ein Teil unserer digitalen Werkzeuge.
Mehr finden Sie unter: www.xpert.digital - www.xpert.solar - www.xpert.plus
In Kontakt bleiben











