AI時代の構造化データ(マークアップ)とSchema.org:Googleのエンジニアたちの本当の考え – 画像:Xpert.Digital
GoogleのSEOの秘密:構造化データなしではAIが失敗する理由
ChatGPTなどにもかかわらず、GoogleのエンジニアがSchema.orgを信頼し続ける理由
SEO最新情報:Schema.orgがGoogleでOpen Graphに取って代わりつつある理由
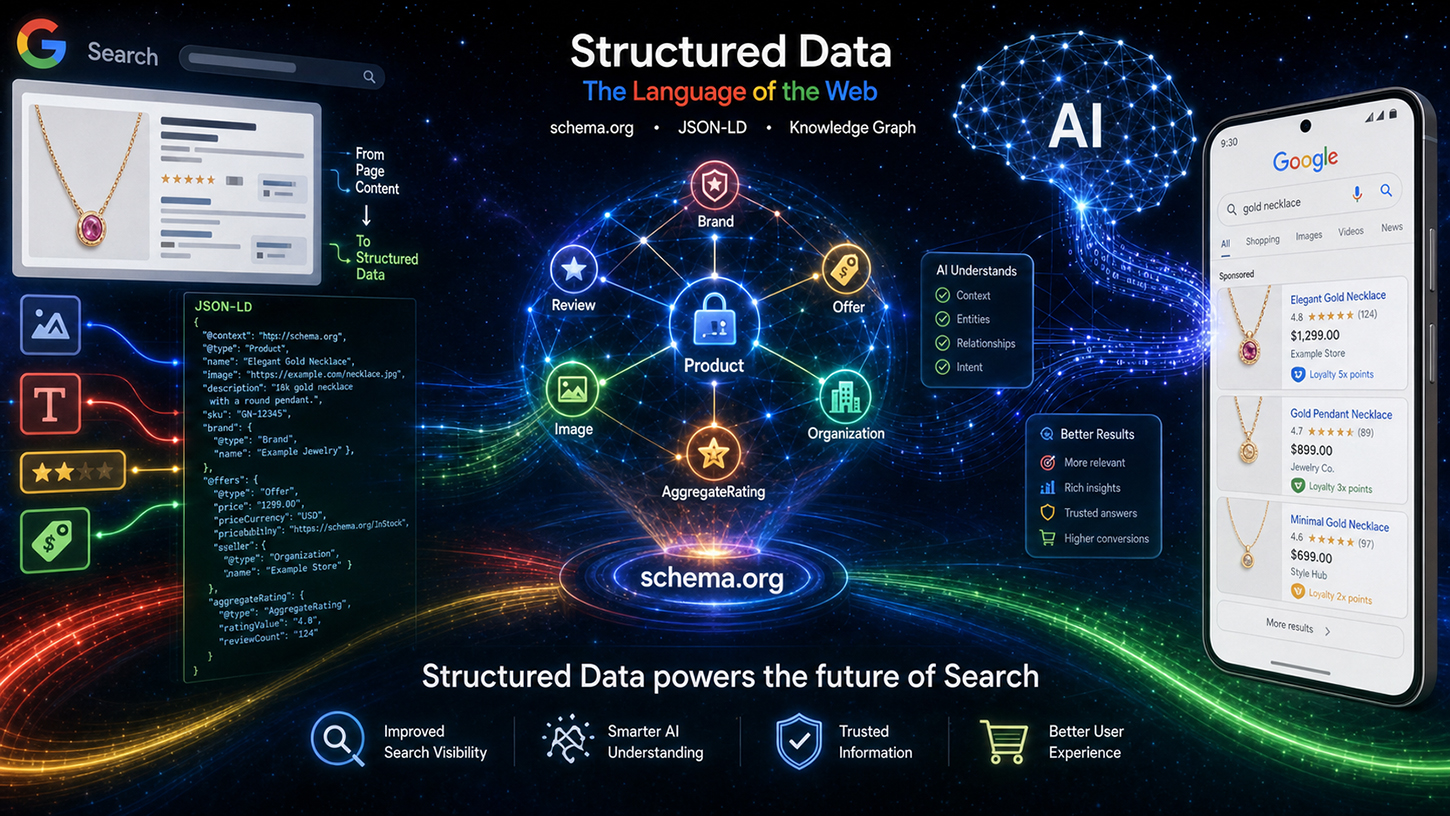
SEO業界では、ある根強い誤解が広まっています。それは、非構造化テキストさえも難なく理解できる優れたAI言語モデルが登場した今、Schema.orgのような苦労して維持されてきた構造化データはもはや時代遅れになったというものです。しかし、現実は全く異なります。Google Search Central Liveイベントで、Googleエンジニアのライアン・レバリング氏は、この誤解を払拭し、構造化マークアップは過去の遺物ではなく、新しいAI搭載検索の根本的な基盤であると明確に述べました。.
最新のAI概要から自律型ショッピングエージェントまで、言語モデルは誤作動を防ぎ、計算効率を高めるために、正確で機械可読なガイドラインを必要とします。現代のウェブ上で存在感を維持したい企業は、機械が曖昧さなく文脈を理解できるよう支援しなければなりません。本稿では、Googleの戦略的な再編を検証し、eコマースとユーザー生成コンテンツにおける革新的なイノベーションを紹介するとともに、機械による可視性獲得競争において、テクニカルSEOが決定的な競争優位性となる理由を明らかにします。.
機械はウェブを読み取ることができるが、それはあなたが理解できるように手助けした場合に限られる。
2026年4月21日、カナダで初めてとなるGoogle Search Central Liveイベントがトロントで開催されました。これは単なる業界の集まりではありませんでした。Google Search Engineeringのエンジニアであるライアン・レバリング氏は、この日最も技術的に高度で戦略的に重要なプレゼンテーション「構造化データ、品質、そしてAI」を行いました。彼のプレゼンテーションは単なる技術的なレビューにとどまらず、人工知能がユーザーと情報の間の仲介役をますます担うようになる時代における、セマンティックウェブの未来についての明確なメッセージでした。.
二つの極端な間:間違った二者択一
ライアン・レバリング氏はプレゼンテーションの冒頭で、SEOコミュニティで広まっている正反対の2つの意見を対比させた。一方では、強力な言語モデルの時代において構造化データは単に不要であるという確信がある。AIモデルが非構造化テキストを容易に解釈できるのであれば、わざわざschema.orgマークアップをソースコードに追加する必要があるだろうか?他方では、構造化データこそがインターネットの未来であり、自律型AIエージェント間の普遍的な意味論的通信プロトコルとして、従来のウェブを大きく置き換えるだろうという考えを広める熱心な支持者もいる。.
レバリング氏は両極端な見解を否定し、代わりに経験に基づいた、より繊細な視点を提示した。どちらの立場にも真実の核心が含まれているものの、どちらも現実を完全に描写しているとは言えないと結論づけた。このニュアンスは、グーグルが現在この問題に取り組む姿勢の特徴であり、教条主義ではなく、実用的効率性を重視する姿勢を示している。.
すべてを説明する4つの議論
レバリング氏の中心的な主張は、彼が「構造化データの価値」というタイトルで詳しく説明した4つの重要なポイントに要約できます。最初のポイントは精度です。構造化データは、販売価格やロイヤルティプログラムなどの複雑なスキーマに対して、自由形式のテキストからのLLMベースの抽出よりもはるかに高い精度を提供します。言語モデルは誤解を招く可能性があります。欠落した属性を補完したり、データを誤ってネストしたり、文脈から外れた情報にアクセスしたりすることがあります。数十の類似商品がある大規模なeコマースサイトから商品価格を抽出する場合、AI推論によるエラー率は、適切に実装された構造化マークアップによるエラー率よりもはるかに高くなります。.
2つ目のポイントは、追加コンテンツに関するものです。構造化データには、レンダリングされたページのHTMLには含まれていない、目に見えないメタデータが含まれていることがよくあります。完全なISO日付形式、ユーザー生成コンテンツの安定した識別子、内部エンティティIDなど、これらの情報はマークアップにのみ存在します。テキストに含まれていないものを言語モデルで抽出することはできません。.
第三に、効率性です。構造化マークアップの解析は、複雑なデータを抽出するために大規模な言語モデルを処理するよりもはるかに安価です。Googleは毎日数十億ページをインデックス化しています。計算は簡単です。JSON-LDを処理する通常のパーサーは、LLM推論ステップの計算リソースのごく一部しか消費しません。したがって、構造化データは意味的に優れているだけでなく、ビジネスの観点からもはるかに効率的です。この点は、Googleのインフラストラクチャに直接関係します。.
4つ目の、そしておそらく最も過小評価されている側面は、焦点です。構造化データは、ページ上でどの情報が関連しているかを明確に示すため、AIシステムが無関係なデータを取得してしまうのを防ぎます。メイン記事、複数の関連商品、そして価格が並んだナビゲーションバーがある商品ページでは、明示的な注釈のない言語モデルでは、どの価格を参照すべきか判断できません。構造化マークアップは、明確な割り当てによってこの問題を解決します。.
構造化データは実際にどのように処理されるのか
Leveringは、技術的な処理フローも透明化しました。Schema.orgデータは、まず特定のクリーニングとフィルタリングを経て、イベント、ショッピング、レビューなどの分野に分類されたインデックスデータとして分類されます。この準備されたデータは、2つの異なる出力チャネルに送られます。1つは従来の検索結果ページ(SRP)、もう1つはGoogleのAIベースシステム、特にいわゆるAI概要(AIO)とAIモード(AIM)のコンテキストです。このように、構造化データはもはやリッチリザルトツールではなく、生成型AI応答への直接的な入力となります。これは、schema.orgマークアップの戦略的重要性における根本的な変化を表しています。.
🎯🎯🎯 データ駆動型B2B業界ハブを準社内ソリューションとして活用


準社内ソリューション:Xpert.DigitalがB2Bマーケティングとセールスの運用上のギャップをどのように解消するか – スマートコンテンツ主導型ビジネス - 画像:Xpert.Digital
Xpert.Digitalは、 Konrad Wolfenstein が率いるデータ駆動型のB2B業界ハブです。同社は、業界パートナーにとって外部の準社内ソリューションとして機能し、クライアント側に追加のリソースを必要とせずに、マーケティング、コンテンツ、販売における運用上のギャップを埋めます。.
詳細はこちら:
構造化データがAIエージェントのインフラストラクチャになりつつある理由
ショッピングに注目:配送、ロイヤルティプログラム、バリエーション
プレゼンテーションの大部分は、eコマースにおけるイノベーションに焦点を当てたものでした。レバリング氏は、ベイマード研究所のデータによると、予想外の配送情報がショッピングカート放棄の最も一般的な理由の2位と3位を占めていると説明しました。配送サービスの構造化マークアップは、この問題に直接対処できます。販売者は、発送元と発送先の地域、寸法と重量、注文金額のしきい値、処理時間、ロイヤルティプログラムへの参加などをコード内で直接正確に定義できるようになりました。.
Googleが使用する配送時間モデルは、処理時間(注文受付から配送業者への引き渡しまでの時間)と実際の配送時間の2つのフェーズに分かれています。どちらのフェーズも、注文締め切り時間や平日も処理が行われるかどうかなど、非常に細かいレベルで個別に注釈を付けることができます。対応するJSON-LDの例では、`ShippingConditions`型を使用して、特定の国(フランスやドイツなど)への送料無料や最低注文金額(50ユーロなど)を定義する方法が示されています。.
配送サービスとロイヤルティプログラムの統合は、特に革新的な機能です。`validForMemberTier`プロパティを使用することで、配送サービスを会員プログラムおよび特定のティアに明示的にリンクできます。これにより、プレミアム会員向けの配送特典をマークアップ内で直接宣言することが可能になります。これは、これまでGoogle Merchant Centerでのみ設定可能だった機能です。関連付けられたロイヤルティプログラム自体は、`Organization`エンティティの下にある`MemberProgram`オブジェクトとして定義され、「ゴールド」や「シルバー」などのティア、およびロイヤルティ特典やポイント報酬などの関連特典が含まれます。.
意味的実体としてのロイヤルティプログラム
ロイヤルティプログラムのマークアップの導入は経済的に重要です。組織は、複数の独立した会員プログラムを定義でき、それぞれに複数の階層と差別化された特典(ポイント、会員価格、返品ポリシー、配送ボーナスなど)を設定できます。この情報は、Google検索結果に直接表示されます。Levering氏は、Sephoraのオファーでショッピングスニペットに30%の会員割引が直接表示されるなど、実際の例を用いてこのことを実証しました。Levering氏によると、ページ間IDリンク、つまり他のページからロイヤルティプログラムの定義にリンクできる機能は、現在「ページ間@idリンクの道を切り開く」と題された次の計画段階です。目標は、製品ページと企業ポリシー間の組織的な参照を強化することです。.
ユーザー生成コンテンツ:AIラベリングの問題点
もう一つの重要なトピックは、ユーザー生成コンテンツ(UGC)のスキーマタイプのさらなる開発でした。ここでは特に重要な2つの新機能があります。まず、フォーラムとQ&Aのマークアップで埋め込み投稿と再投稿がサポートされ、議論構造のより正確な意味表現が可能になりました。次に、さらに戦略的に重要な点として、機械生成コンテンツを明示的に識別するための`so#digitalSourceType`プロパティが導入されました。.
この開発は、フォーラムやQ&AサイトなどのプラットフォームにAI生成コンテンツが氾濫していることへの直接的な対応です。ウェブマスターは、投稿がアルゴリズムによって生成されたものか、言語モデルによって生成されたものかを指定できるようになりました。これを指定しない場合、Googleは暗黙のうちに人間が作成したものとみなします。これは、透明性のあるラベル付けを促すルールです。`digitalSourceType`プロパティは、デジタルソースのIPTCコードに基づいており、とりわけ、アルゴリズムによって生成されたコンテンツとモデルによって生成されたコンテンツを区別します。.
画像選択:スキーマはオープングラフに勝る
あまり注目されていないものの、実質的に効果的なアップデートとして、Googleの画像選択ロジックの変更が挙げられます。このシステムは内部的に統合され、明確な優先順位付けの階層構造が確立されました。具体的には、`primaryImageOfPage`と`mainEntity → image`というプロパティを含むSchema.orgマークアップが優先されます。その後、Open Graphの`og:image`メタタグが適用されます。この変更により、ウェブサイト運営者にとって、メイン画像の適切なSchema.org実装は、Google検索結果やAI概要における画像の表示に直接影響を与えることになり、具体的かつ測定可能なメリットとなります。.
Schema.org自体が投資を受けている
また、Googleがschema.orgをオープン仕様として再投資すると発表したことも注目に値します。具体的な対策として、以下の3点が挙げられました。個々のスキーマ用語の使用頻度に関する統計情報の公開(スライドで示されているように、`digitalSourceType`などの個々の用語については、約10,000のドメインに関する情報を含む普及データが既に利用可能です)、SHACLやShExなどの機械可読な標準形式でのGoogle独自の検証ルールの公開、および順序ルールのサポート強化です。これは、外部の開発者がGoogleの標準に基づいて独自の検証ツールを構築できるようになるため重要です。これにより、負荷がかかると時折クラッシュする公式のテストツールとは独立して開発を進めることができます。.
検証:2つのツール、1つの目標
Levering氏は、互いに補完し合うものの、異なるテスト基準を適用する2つの検証ツールを紹介しました。`search.google.com/test/rich-results`にあるRich Result Test Toolは、URLまたは純粋なJSONを受け付け、マークアップがGoogle検索のリッチリザルトに適しているかどうかをチェックします。つまり、schema.org標準自体ではなく、Google独自の要件に基づいています。一方、`validator.schema.org`は、Googleがリッチリザルトを生成するかどうかに関わらず、マークアップがschema.orgに準拠している、つまりオープンボキャブラリーに準拠しているかどうかをチェックします。このことから、Web開発者には明確な推奨事項が示されます。マークアップはschemaに準拠していてもリッチリザルトに対応していない場合があり、その逆もまた然りであるため、両方のツールを使用すべきです。.
より大きな視点:AIインフラストラクチャとしての構造化データ
トロントで開催されたイベント全体を見ると、従来のSEO最適化をはるかに超える変化が明らかになっています。構造化データは、リッチスニペットを実現するためのツールから、AIシステムの基本的なデータレイヤー標準へと進化しています。GoogleのAI概要とAIモードは、回答生成とエンティティ検証のコンテキストとしてschema.orgマークアップを積極的に活用しています。正確で完全かつ精度の高い構造化データを実装することで、検索結果で視覚的に目立つ表示を実現できる可能性が高まるだけでなく、AIによる回答の信頼できる主要情報源としての地位を確立できます。.
この文脈でユニバーサルコマースプロトコル(UCP)とWebMCPに言及するのは偶然ではない。Googleが2026年に初期バージョンをリリースしたこれらのエージェントベースの通信規格は、ウェブサイトが意味的に記述されることを要求している。Schema.orgはその基盤となっている。AIエージェントがウェブ上で自律的に動作し、検索、比較、取引を開始する世界では、コンテンツの機械可読性はもはやオプションではなく、経済的関連性の前提条件となる。したがって、トロントでのライアン・レバリング氏のプレゼンテーションは、単なる技術的なアップデート報告ではなく、次世代ウェブのインフラストラクチャを垣間見せるものだった。.
10秒で自分で確かめることができます。
自分のウェブサイトや他のウェブサイトが構造化データをどれだけ効果的かつ包括的に利用しているかを知りたい場合は、Googleのライアン・レバリング氏(上記記事で紹介)が推奨した2つのツールをそのまま使用できます。
Googleリッチリザルトテスト(Googleでの視認性に焦点を当てて):
search.google.com/test/rich-resultsにアクセスし、xpert.digital の記事の URL をコピーして、「URL をテスト」をクリックしてください。このツールは、Google がそのページで認識するマークアップの種類と、それらがエラーのないものであるかどうかを正確に表示します。
スキーマバリデーター(純粋な標準準拠に特化):
validator.schema.orgにアクセスし、同じ URL を貼り付けてください。すると、ソースコード内で色付きでハイライト表示され、xpert.digital が組み込んだ JSON-LD スクリプト(構造化データ)を直接確認できます。
グローバルマーケティングとビジネス開発のパートナー
☑️ 当社のビジネス言語は英語またはドイツ語です。
☑️ 新機能: 母国語での対応!

Konrad Wolfenstein
私と私のチームは、あなたの個人アドバイザーとして喜んでお手伝いさせていただきます。.
こちらの問い合わせフォームにご記入いただくかwolfenstein@xpert.digital。、 +49 7348 4088 965までお電話ください。メールアドレスはです
私たちの共同プロジェクトを楽しみにしています。.
☑️ 戦略、コンサルティング、計画、実装における中小企業のサポート
☑️ デジタル戦略とデジタル化の策定または再調整
☑️ 国際販売プロセスの拡大と最適化
☑️ グローバル&デジタルB2B取引プラットフォーム
☑️ パイオニア事業開発 / マーケティング / PR / 見本市
B2BサポートとSEO・GEO(AI検索)を組み合わせたSaaS:B2B企業向けのオールインワンソリューション


B2BサポートとSEO・GEO(AI検索)を組み合わせたSaaS:B2B企業向けのオールインワンソリューション - 画像:Xpert.Digital
AI 検索がすべてを変える: この SaaS ソリューションが B2B ランキングに永久的な革命を起こす方法。.
B2B企業のデジタル環境は急速に変化しています。人工知能(AI)の進化により、オンラインビジビリティのルールは塗り替えられつつあります。企業にとって、デジタルマスにおけるビジビリティを確保するだけでなく、適切な意思決定者にとって関連性のある存在であり続けることは、常に課題となっています。従来のSEO戦略や地域密着型マーケティング(ジオマーケティング)は複雑で時間がかかり、絶えず変化するアルゴリズムや熾烈な競争との戦いとなることも少なくありません。.
しかし、このプロセスを簡素化するだけでなく、よりスマートで予測性に優れ、はるかに効果的なソリューションがあったらどうでしょうか?そこで、AI検索時代のSEOとGEOのニーズに合わせて特別に設計された、専門的なB2Bサポートと強力なSaaS(Software as a Service)プラットフォームの組み合わせが役立ちます。.
この新世代ツールは、もはや手作業によるキーワード分析やバックリンク戦略だけに頼る必要はありません。人工知能(AI)を活用し、検索意図をより正確に理解し、ローカルランキング要因を自動最適化し、リアルタイムの競合分析を実施します。その結果、B2B企業は、自社のニッチ市場と地域におけるリーディングカンパニーとして認知され、認知されるだけでなく、プロアクティブでデータドリブンな戦略を策定できるようになり、決定的な優位性を獲得します。.
SEO と GEO マーケティングを変革する B2B サポートと AI を活用した SaaS テクノロジーの共生、そして企業がデジタル空間で持続的に成長するためにそこからどのように利益を得ることができるかについて説明します。.
詳細はこちら: