
BERT を使用した AI と SEO – Transformers からの双方向エンコーダー表現 – 自然言語処理 (NLP) 分野のモデル

言語の選択 📢
公開:2024年10月4日 /更新:2024年10月4日 - 著者: Konrad Wolfenstein

BERT を使用した AI と SEO – Transformers からの双方向エンコーダー表現 – 自然言語処理 (NLP) 分野のモデル – 画像: Xpert.Digital
🚀💬 Google が開発: BERT と NLP におけるその重要性 - 双方向のテキスト理解が重要な理由
🔍🗣️ BERT は、Bidirectional Encoder Representations from Transformers の略で、Google によって開発された自然言語処理 (NLP) の分野の主要なモデルです。これは、機械が言語を理解する方法に革命をもたらしました。テキストを左から右、またはその逆に順番に分析する以前のモデルとは異なり、BERT は双方向の処理を可能にします。これは、前後のテキスト シーケンスの両方から単語のコンテキストをキャプチャすることを意味します。この能力により、複雑な言語文脈の理解が大幅に向上します。
🔍 BERTのアーキテクチャ
近年、自然言語処理 (NLP) の分野で最も重要な発展の 1 つは、 PDF 2017 - Attending is all you need - 論文( Wikipedia ) で紹介されているように、Transformer モデルの導入によって起こりました。このモデルは、機械翻訳など、以前に使用されていた構造を廃棄することにより、この分野を根本的に変えました。代わりに、注意メカニズムのみに依存します。それ以来、Transformer の設計は、言語生成、翻訳などのさまざまな分野で最先端を表す多くのモデルの基礎を形成してきました。
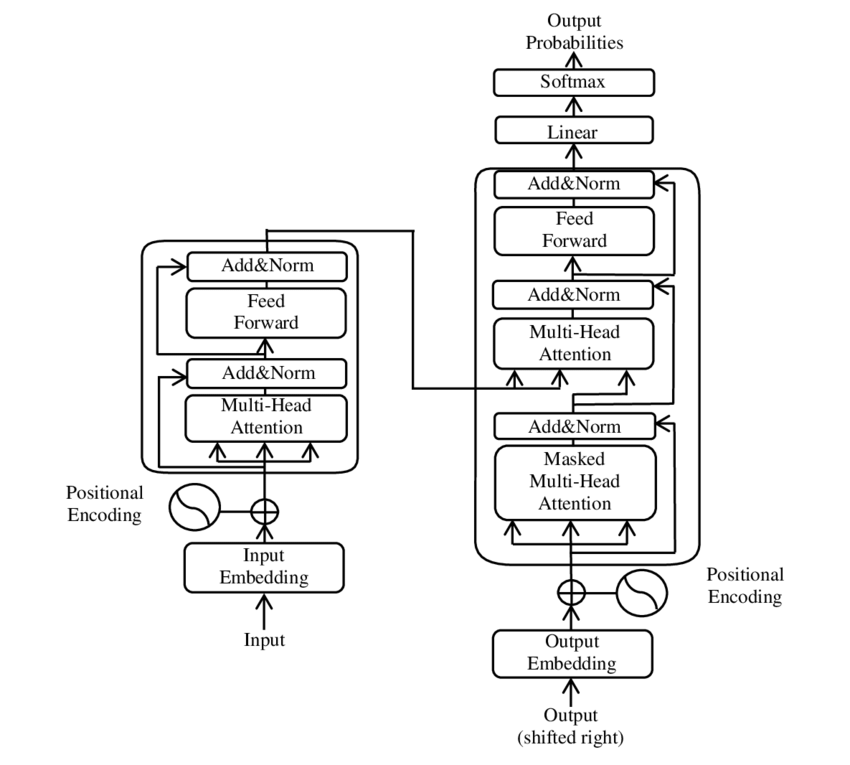
Transformer モデルの主要コンポーネントの図 - 画像: Google
BERT は、この Transformer アーキテクチャに基づいています。このアーキテクチャは、いわゆるセルフ アテンション メカニズムを使用して、文内の単語間の関係を分析します。文全体の文脈の中で各単語に注意が払われるため、構文的および意味的関係がより正確に理解されます。
論文の著者は、「注意が必要です」は次のとおりです。
- アシシュ・ヴァスワニ (Google Brain)
- ノーム・シャジーア (Google Brain)
- ニキ・パーマー (Google Research)
- ヤコブ・ウシュコーライト (Google Research)
- ライオン・ジョーンズ (Google Research)
- Aidan N. Gomez (トロント大学、研究の一部は Google Brain で行われた)
- ルカシュ・カイザー (Google Brain)
- Illia Polosukhin (独立、前職は Google Research)
これらの著者は、この論文で紹介する Transformer モデルの開発に大きく貢献しました。
🔄双方向処理
BERT の際立った機能は、双方向処理機能です。リカレント ニューラル ネットワーク (RNN) や長短期記憶 (LSTM) ネットワークなどの従来のモデルはテキストを一方向でのみ処理しますが、BERT は単語のコンテキストを両方向で分析します。これにより、モデルは意味の微妙なニュアンスをより適切に捉え、より正確な予測を行うことができます。
🕵️♂️ マスクされた言語モデリング
BERT のもう 1 つの革新的な側面は、マスク言語モデル (MLM) 技術です。これには、文内でランダムに選択された単語をマスクし、周囲のコンテキストに基づいてこれらの単語を予測するようにモデルをトレーニングすることが含まれます。この方法により、BERT は文内の各単語の文脈と意味を深く理解することができます。
🚀 BERT のトレーニングとカスタマイズ
BERT は、事前トレーニングと微調整という 2 段階のトレーニング プロセスを経ます。
📚 事前トレーニング
事前トレーニングでは、BERT は一般的な言語パターンを学習するために大量のテキストを使用してトレーニングされます。これには、Wikipedia のテキストやその他の広範なテキスト コーパスが含まれます。このフェーズでは、モデルは基本的な言語構造と文脈を学習します。
🔧 微調整
事前トレーニング後、BERT はテキスト分類や感情分析などの特定の NLP タスク用にカスタマイズされます。モデルは、特定のアプリケーションのパフォーマンスを最適化するために、より小さなタスク関連のデータセットを使用してトレーニングされます。
🌍 BERT の適用分野
BERT は、自然言語処理のさまざまな分野で非常に役立つことが証明されています。
検索エンジンの最適化
Google は検索クエリをより深く理解し、より関連性の高い結果を表示するために BERT を使用しています。これにより、ユーザー エクスペリエンスが大幅に向上します。
テキストの分類
BERT はトピックごとにドキュメントを分類したり、テキスト内の雰囲気を分析したりできます。
固有表現認識 (NER)
このモデルは、個人名、場所名、組織名など、テキスト内の名前付きエンティティを識別および分類します。
質疑応答システム
BERT は、質問に対する正確な回答を提供するために使用されます。
🧠 AI の将来における BERT の重要性
BERT は NLP モデルの新しい標準を設定し、さらなるイノベーションへの道を切り開きました。双方向の処理能力と言語コンテキストの深い理解により、AI アプリケーションの効率と精度が大幅に向上しました。
🔜今後の展開
BERT および同様のモデルのさらなる開発は、さらに強力なシステムの作成を目指すことになるでしょう。これらは、より複雑な言語タスクを処理し、さまざまな新しいアプリケーション分野で使用できる可能性があります。このようなモデルを日常のテクノロジーに統合すると、私たちがコンピューターと対話する方法が根本的に変わる可能性があります。
🌟 人工知能の開発におけるマイルストーン
BERT は人工知能の開発におけるマイルストーンであり、機械が自然言語を処理する方法に革命をもたらしました。その双方向アーキテクチャにより、言語関係をより深く理解できるため、さまざまなアプリケーションに不可欠なものとなっています。研究が進むにつれて、BERT のようなモデルは、AI システムを改善し、その使用の新たな可能性を開く上で中心的な役割を果たし続けるでしょう。
📣 類似のトピック
- 📚 BERT の紹介: 画期的な NLP モデル
- 🔍 BERT と NLP における双方向性の役割
- 🧠 Transformer モデル: BERT の基礎
- 🚀 マスクされた言語モデリング: BERT の成功の鍵
- 📈 BERTのカスタマイズ: 事前トレーニングから微調整まで
- 🌐 最新テクノロジーにおける BERT の応用分野
- 🤖 BERT が人工知能の将来に与える影響
- 💡 将来の展望: BERT のさらなる発展
- 🏆 AI 開発のマイルストーンとしての BERT
- 📰 Transformer 論文「Attending Is All You Need」の著者: BERT の背後にある考え
#️⃣ ハッシュタグ: #NLP #人工知能 #言語モデリング #トランスフォーマー #機械学習
🎯🎯🎯 包括的なサービス パッケージにおける Xpert.Digital の 5 倍の広範な専門知識を活用してください | 研究開発、XR、PR、SEM

AI & XR 3D レンダリング マシン: 包括的なサービス パッケージ、R&D XR、PR & SEM における Xpert.Digital の 5 倍の専門知識 - 画像: Xpert.Digital
Xpert.Digital は、さまざまな業界について深い知識を持っています。 これにより、お客様の特定の市場セグメントの要件と課題に正確に合わせたオーダーメイドの戦略を開発することが可能になります。 継続的に市場動向を分析し、業界の発展をフォローすることで、当社は先見性を持って行動し、革新的なソリューションを提供することができます。 経験と知識を組み合わせることで付加価値を生み出し、お客様に決定的な競争上の優位性を提供します。
詳細については、こちらをご覧ください:
BERT: 革新的な 🌟 NLP テクノロジー
🚀 BERT は、Transformers の Bidirectional Encoder Representations の略で、Google によって開発された高度な言語モデルで、2018 年の発売以来、自然言語処理 (NLP) の分野で大きな進歩となっています。これは、マシンがテキストを理解して処理する方法に革命をもたらした Transformer アーキテクチャに基づいています。しかし、BERT は正確に何が特別で、正確には何に使用されるのでしょうか?この質問に答えるには、BERT の技術原理、機能、および応用分野をさらに深く掘り下げる必要があります。
📚 1. 自然言語処理の基礎
BERT の意味を完全に理解するには、自然言語処理 (NLP) の基本を簡単に復習することが役立ちます。 NLP は、コンピューターと人間の言語の間の相互作用を扱います。目標は、テキスト データを分析し、理解し、応答できるように機械に教えることです。 BERT のようなモデルが導入される前は、特に人間の言語のあいまいさ、文脈依存性、複雑な構造により、言語の機械処理には大きな課題が生じることがよくありました。
📈 2. NLP モデルの開発
BERT が登場する前は、ほとんどの NLP モデルはいわゆる単方向アーキテクチャに基づいていました。これは、これらのモデルがテキストを左から右または右から左のどちらかのみに読み取ることを意味します。これは、文内の単語を処理するときに限られた量のコンテキストしか考慮できないことを意味します。この制限により、モデルが文の完全な意味論的コンテキストを完全には捕捉できないことがよくありました。そのため、曖昧な単語や文脈に依存した単語を正確に解釈することが困難でした。
BERT 以前の NLP 研究におけるもう 1 つの重要な発展は、word2vec モデルです。これにより、コンピューターは単語を意味上の類似性を反映するベクトルに翻訳できるようになります。しかし、ここでも文脈は単語のすぐ周囲に限定されていました。その後、リカレント ニューラル ネットワーク (RNN)、特に長短期記憶 (LSTM) モデルが開発され、複数の単語にまたがる情報を保存することでテキスト シーケンスをよりよく理解できるようになりました。ただし、これらのモデルには、特に長いテキストを処理し、同時に両方向のコンテキストを理解する場合には限界もありました。
🔄 3. Transformer アーキテクチャによる革命
2017 年に BERT の基礎となる Transformer アーキテクチャが導入されたことで画期的な進歩が起こりました。 Transformer モデルは、前後のテキストの両方からの単語のコンテキストを考慮して、テキストの並列処理を可能にするように設計されています。これは、いわゆる自己注意メカニズムによって行われ、文内の他の単語との関係での重要度に基づいて、文内の各単語に重み値を割り当てます。
以前のアプローチとは対照的に、Transformer モデルは一方向ではなく双方向です。これは、単語の左右両方のコンテキストから情報を引き出し、単語とその意味をより完全かつ正確に表現できることを意味します。
🧠 4. BERT: 双方向モデル
BERT は、Transformer アーキテクチャのパフォーマンスを新たなレベルに引き上げます。このモデルは、単語のコンテキストを左から右、または右から左だけでなく、両方向で同時にキャプチャするように設計されています。これにより、BERT は文内の単語の完全なコンテキストを考慮できるようになり、言語処理タスクの精度が大幅に向上します。
BERT の中心的な機能は、いわゆるマスク言語モデル (MLM) の使用です。 BERT のトレーニングでは、文内でランダムに選択された単語がマスクに置き換えられ、モデルはコンテキストに基づいてこれらのマスクされた単語を推測するようにトレーニングされます。この手法により、BERT は文内の単語間のより深く正確な関係を学習できるようになります。
さらに、BERT は次文予測 (NSP) と呼ばれる方法を使用し、モデルはある文が別の文に続くかどうかを予測するように学習します。これにより、BERT の長いテキストを理解し、文間のより複雑な関係を認識する能力が向上します。
🌐 5. BERT の実際の適用
BERT は、さまざまな NLP タスクに非常に役立つことが証明されています。主な応用分野の一部を次に示します。
📊 a) テキストの分類
BERT の最も一般的な用途の 1 つは、テキストを事前定義されたカテゴリに分類するテキスト分類です。この例には、感情分析 (テキストが肯定的か否定的かを認識するなど) や顧客フィードバックの分類が含まれます。 BERT は、単語のコンテキストを深く理解することで、以前のモデルよりも正確な結果を提供できます。
❓ b) 質問応答システム
BERT は質問応答システムでも使用され、モデルが提示された質問に対する回答をテキストから抽出します。この機能は、検索エンジン、チャットボット、仮想アシスタントなどのアプリケーションで特に重要です。 BERT は双方向アーキテクチャのおかげで、質問が間接的に作成されている場合でも、テキストから関連情報を抽出できます。
🌍 c) テキスト翻訳
BERT 自体は翻訳モデルとして直接設計されていませんが、他のテクノロジーと組み合わせて使用して機械翻訳を向上させることができます。 BERT は、文内の意味関係をより深く理解することで、特に曖昧または複雑な言葉遣いに対して、より正確な翻訳を生成するのに役立ちます。
🏷️ d) 固有表現認識 (NER)
もう 1 つの応用分野は固有表現認識 (NER) です。これには、テキスト内の名前、場所、組織などの特定の実体を識別することが含まれます。 BERT は、文のコンテキストを完全に考慮し、異なるコンテキストで異なる意味を持つ場合でもエンティティをよりよく認識できるため、このタスクで特に効果的であることが証明されています。
✂️ e) テキストの要約
BERT はテキストのコンテキスト全体を理解する能力があるため、自動テキスト要約のための強力なツールにもなります。長いテキストから最も重要な情報を抽出し、簡潔な要約を作成するために使用できます。
🌟 6. 研究と産業における BERT の重要性
BERT の導入により、NLP 研究の新時代が始まりました。これは、双方向トランス アーキテクチャの力を最大限に活用した最初のモデルの 1 つであり、その後の多くのモデルの基準を設定しました。多くの企業や研究機関は、アプリケーションのパフォーマンスを向上させるために BERT を NLP パイプラインに統合しています。
さらに、BERT は言語モデルの分野におけるさらなる革新への道を切り開きました。たとえば、GPT (Generative Pretrained Transformer) や T5 (Text-to-Text Transfer Transformer) などのモデルがその後開発されました。これらは同様の原理に基づいていますが、さまざまなユースケースに合わせて具体的な改善を提供します。
🚧 7. BERT の課題と限界
BERT には多くの利点がありますが、いくつかの課題と制限もあります。最大のハードルの 1 つは、モデルをトレーニングして適用するために必要な高い計算量です。 BERT は数百万のパラメータを持つ非常に大規模なモデルであるため、特に大量のデータを処理する場合には、強力なハードウェアと大量のコンピューティング リソースが必要になります。
もう 1 つの問題は、トレーニング データに存在する可能性がある潜在的なバイアスです。 BERT は大量のテキスト データでトレーニングされるため、そのデータに存在する偏見や固定観念が反映されることがあります。ただし、研究者たちはこれらの問題を特定し、対処するために継続的に取り組んでいます。
🔍 最新の言語処理アプリケーションに不可欠なツール
BERT により、機械が人間の言語を理解する方法が大幅に改善されました。双方向アーキテクチャと革新的なトレーニング方法により、文内の単語のコンテキストを深く正確に捉えることができ、多くの NLP タスクの精度が向上します。テキスト分類、質問応答システム、エンティティ認識のいずれにおいても、BERT は最新の言語処理アプリケーションに不可欠なツールとしての地位を確立しています。
自然言語処理の研究は間違いなく今後も進歩し、BERT は将来の多くのイノベーションの基礎を築きました。既存の課題や制限にもかかわらず、BERT は、テクノロジーが短期間でどれほど進歩したか、そして将来にどのようなエキサイティングな機会が開かれるかを印象的に示しています。
🌀 トランスフォーマー: 自然言語処理の革命
🌟 近年、自然言語処理 (NLP) 分野における最も重要な発展の 1 つは、2017 年の論文「attention is all you need」で説明されているように、Transformer モデルの導入です。このモデルは、機械翻訳などの配列変換タスクに以前使用されていた再帰構造または畳み込み構造を破棄することにより、この分野を根本的に変えました。代わりに、注意メカニズムのみに依存します。それ以来、Transformer の設計は、言語生成、翻訳などのさまざまな分野で最先端を表す多くのモデルの基礎を形成してきました。
🔄 トランスフォーマー: パラダイムシフト
Transformer が導入される前は、シーケンス タスクのほとんどのモデルは、本質的に逐次的であるリカレント ニューラル ネットワーク (RNN) または長短期記憶ネットワーク (LSTM) に基づいていました。これらのモデルは入力データを段階的に処理し、シーケンスに沿って伝播される隠れ状態を作成します。この方法は効果的ですが、特に長いシーケンスの場合、計算コストが高く、並列化が困難です。さらに、RNN は、いわゆる「勾配消失」問題のため、長期的な依存関係を学習することが困難です。
Transformer の中心的な革新は、セルフ アテンション メカニズムの使用にあり、これによりモデルは、位置に関係なく、文内のさまざまな単語の重要性を相互に比較して重み付けすることができます。これにより、モデルは、RNN や LSTM よりも効果的に、間隔の広い単語間の関係を取得し、それを逐次的ではなく並列的に行うことができます。これにより、トレーニングの効率が向上するだけでなく、機械翻訳などのタスクのパフォーマンスも向上します。
🧩 モデルアーキテクチャ
Transformer は、エンコーダとデコーダという 2 つの主要コンポーネントで構成されており、どちらも複数のレイヤで構成されており、マルチヘッド アテンション メカニズムに大きく依存しています。
⚙️エンコーダー
エンコーダーは 6 つの同一のレイヤーで構成され、それぞれに 2 つのサブレイヤーがあります。
1. マルチヘッドセルフアテンション
このメカニズムにより、モデルは各単語を処理するときに入力文のさまざまな部分に焦点を当てることができます。単一の空間で注意を計算する代わりに、マルチヘッド アテンションは入力をいくつかの異なる空間に投影し、単語間のさまざまなタイプの関係を捉えることができます。
2. 位置ごとに完全に接続されたフィードフォワード ネットワーク
アテンション層の後、完全に接続されたフィードフォワード ネットワークが各位置に独立して適用されます。これは、モデルがコンテキスト内で各単語を処理し、アテンション メカニズムからの情報を利用するのに役立ちます。
入力シーケンスの構造を保存するために、モデルには位置入力 (位置エンコーディング) も含まれています。 Transformer は単語を順番に処理しないため、これらのエンコーディングは、文内の単語の順序に関する情報をモデルに与える際に重要です。モデルがシーケンス内の異なる位置を区別できるように、位置入力が単語埋め込みに追加されます。
🔍 デコーダー
エンコーダーと同様に、デコーダーも 6 つのレイヤーで構成されており、各レイヤーには追加のアテンション メカニズムがあり、出力を生成する際にモデルが入力シーケンスの関連部分に焦点を当てることができます。また、デコーダはマスキング技術を使用して将来の位置を考慮しないようにし、シーケンス生成の自己回帰的な性質を維持します。
🧠 多頭注意と内積注意
Transformer の中心となるのは、より単純なドット積アテンションの拡張であるマルチヘッド アテンション メカニズムです。アテンション関数は、クエリと一連のキーと値のペア (キーと値) の間のマッピングとして見ることができます。各キーはシーケンス内の単語を表し、値は関連するコンテキスト情報を表します。
マルチヘッド アテンション メカニズムにより、モデルはシーケンスの異なる部分に同時に焦点を当てることができます。入力を複数の部分空間に投影することにより、モデルは単語間のより豊富な関係を捉えることができます。これは、単語のコンテキストを理解するために構文構造や意味論的な意味など、さまざまな要素が必要となる機械翻訳などのタスクで特に役立ちます。
ドット積アテンションの公式は次のとおりです。
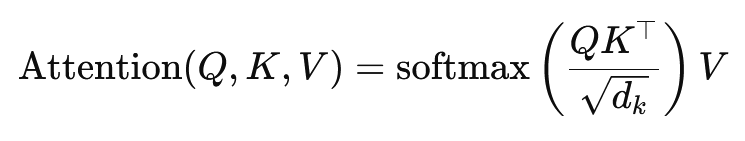
ここで (Q) はクエリ行列、(K) はキー行列、(V) は値行列です。 (sqrt{d_k}) という項は、内積が大きくなりすぎて勾配が非常に小さくなり、学習が遅くなるのを防ぐスケーリング係数です。ソフトマックス関数は、アテンションの重みの合計が 1 になるように適用されます。
🚀 変圧器の利点
Transformer は、RNN や LSTM などの従来のモデルに比べて、いくつかの重要な利点を提供します。
1. 並列化
Transformer はシーケンス内のすべてのトークンを同時に処理するため、高度に並列化することができ、特に大規模なデータ セットの場合、RNN や LSTM よりもはるかに高速にトレーニングできます。
2. 長期的な依存関係
セルフ アテンション メカニズムにより、モデルは、計算の逐次的な性質によって制限される RNN よりも効果的に、離れた単語間の関係を捕捉することができます。
3. スケーラビリティ
Transformer は、RNN に関連するパフォーマンスのボトルネックに悩まされることなく、非常に大規模なデータセットや長いシーケンスに簡単に拡張できます。
🌍 用途と効果
導入以来、Transformer は幅広い NLP モデルの基礎となっています。最も注目に値する例の 1 つは、BERT (Bidirectional Encoder Representations from Transformers) です。これは、修正された Transformer アーキテクチャを使用して、質問応答やテキスト分類などの多くの NLP タスクで最先端の機能を実現します。
もう 1 つの重要な開発は GPT (Generative Pretrained Transformer) です。これは、テキスト生成に Transformer のデコーダ限定バージョンを使用します。 GPT-3 を含む GPT モデルは、現在、コンテンツ作成からコード補完まで、さまざまなアプリケーションに使用されています。
🔍 強力で柔軟なモデル
Transformer は、NLP タスクへのアプローチ方法を根本的に変えました。さまざまな問題に適用できる強力で柔軟なモデルを提供します。長期的な依存関係を処理できる機能とトレーニング効率により、多くの最新モデルで推奨されるアーキテクチャ アプローチとなっています。研究が進むにつれて、特に画像処理や言語処理などの注意メカニズムが有望な結果を示している分野において、Transformer のさらなる改良や調整が行われる可能性があります。
私たちはあなたのために - アドバイス - 計画 - 実施 - プロジェクト管理
☑️ 業界の専門家。2,500 以上の専門記事を備えた独自の Xpert.Digital 業界ハブを備えています。

コンラッド・ウルフェンシュタイン
あなたの個人的なアドバイザーとして喜んでお手伝いさせていただきます。
以下のお問い合わせフォームにご記入いただくか、 +49 89 89 674 804 (ミュンヘン)。
私たちの共同プロジェクトを楽しみにしています。
私に書いてください

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital は、デジタル化、機械工学、物流/イントラロジスティクス、太陽光発電に重点を置いた産業のハブです。
360°の事業開発ソリューションで、新規事業からアフターセールスまで有名企業をサポートします。
マーケット インテリジェンス、マーケティング、マーケティング オートメーション、コンテンツ開発、PR、メール キャンペーン、パーソナライズされたソーシャル メディア、リード ナーチャリングは、当社のデジタル ツールの一部です。
www.xpert.digital - www.xpert.solar - www.xpert.plusをご覧ください。
連絡を取り合う




















