
AI を説明する試み: 人工知能はどのように動作し機能するのか、どのように訓練されるのでしょうか?

言語の選択 📢
公開:2024年9月8日 /更新:2024年9月9日 - 著者: Konrad Wolfenstein

AI を説明する試み: 人工知能はどのように機能し、どのように訓練されるのでしょうか? – 画像: Xpert.Digital
📊 データ入力からモデル予測まで: AI プロセス
人工知能 (AI) はどのように機能するのでしょうか? 🤖
人工知能 (AI) がどのように機能するかは、明確に定義されたいくつかのステップに分けることができます。これらの各ステップは、AI がもたらす最終結果にとって重要です。このプロセスはデータ入力で始まり、モデルの予測と可能なフィードバック、またはさらなるトレーニング ラウンドで終わります。これらのフェーズは、単純なルール セットであるか非常に複雑なニューラル ネットワークであるかに関係なく、ほぼすべての AI モデルが通過するプロセスを説明します。
1. データ入力 📊
すべての人工知能の基礎は、それが動作するデータです。このデータは、画像、テキスト、オーディオ ファイル、ビデオなど、さまざまな形式にすることができます。 AI はこの生データを使用してパターンを認識し、意思決定を行います。ここではデータの質と量が中心的な役割を果たします。これらは、後でモデルがうまく機能するかどうかに大きな影響を与えるからです。
データが広範囲かつ正確であるほど、AI はより適切に学習できます。たとえば、AI が画像処理用にトレーニングされる場合、さまざまなオブジェクトを正しく識別するには大量の画像データが必要になります。言語モデルでは、AI が人間の言語を理解して生成するのに役立つテキスト データです。予測の品質は基礎となるデータと同程度にしかならないため、データ入力は最初で最も重要なステップの 1 つです。コンピュータ サイエンスの有名な原則は、これを「ガベージ イン、ガベージ アウト」という言葉で説明しています。つまり、悪いデータは悪い結果につながります。
2. データの前処理 🧹
データを入力したら、実際のモデルに入力する前にデータを準備する必要があります。このプロセスはデータ前処理と呼ばれます。ここでの目的は、モデルによって最適に処理できる形式にデータを入れることです。
前処理の一般的なステップはデータの正規化です。これは、モデルがデータを均等に処理できるように、データが均一の値の範囲に収まることを意味します。例としては、画像のすべてのピクセル値を 0 ~ 255 ではなく 0 ~ 1 の範囲にスケールすることが挙げられます。
前処理のもう 1 つの重要な部分は、いわゆる特徴抽出です。モデルに特に関連する特定の特徴が生データから抽出されます。たとえば、画像処理ではエッジや特定のカラー パターンがこれに該当し、テキストでは関連するキーワードや文章構造が抽出されます。 AI の学習プロセスをより効率的かつ正確にするためには、前処理が重要です。
3. モデル 🧩
モデルはあらゆる人工知能の心臓部です。ここでは、アルゴリズムと数学的計算に基づいてデータが分析および処理されます。モデルはさまざまな形式で存在できます。最もよく知られているモデルの 1 つは、人間の脳の仕組みに基づいたニューラル ネットワークです。
ニューラル ネットワークは、情報を処理して伝達する人工ニューロンのいくつかの層で構成されています。各層は前の層の出力を受け取り、さらに処理します。ニューラル ネットワークの学習プロセスは、ネットワークがより正確な予測や分類を行えるように、これらのニューロン間の接続の重みを調整することで構成されます。この適応は、ネットワークが大量のサンプル データにアクセスし、内部パラメータ (重み) を繰り返し改善するトレーニングを通じて行われます。
ニューラル ネットワークに加えて、AI モデルでは他にも多くのアルゴリズムが使用されます。これらには、デシジョン ツリー、ランダム フォレスト、サポート ベクター マシンなどが含まれます。どのアルゴリズムが使用されるかは、特定のタスクと利用可能なデータによって異なります。
4. モデル予測 🔍
モデルがデータでトレーニングされると、予測ができるようになります。このステップはモデル予測と呼ばれます。 AI は入力を受け取り、これまでに学習したパターンに基づいて出力、つまり予測や決定を返します。
この予測はさまざまな形をとる可能性があります。たとえば、画像分類モデルでは、AI が画像内にどのオブジェクトが表示されるかを予測できます。言語モデルでは、文の次にどの単語が来るかを予測できます。金融予測では、AI が株式市場の動向を予測できる可能性があります。
予測の精度はトレーニング データとモデル アーキテクチャの品質に大きく依存することを強調することが重要です。不十分なデータまたは偏ったデータに基づいてトレーニングされたモデルは、誤った予測を行う可能性があります。
5. フィードバックとトレーニング (オプション) ♻️
AI の働きのもう 1 つの重要な部分は、フィードバック メカニズムです。モデルは定期的にチェックされ、さらに最適化されます。このプロセスは、トレーニング中またはモデルの予測後に発生します。
モデルが誤った予測を行った場合、フィードバックを通じて学習してこれらのエラーを検出し、それに応じて内部パラメーターを調整できます。これは、モデルの予測を実際の結果 (たとえば、正しい答えがすでに存在する既知のデータ) と比較することによって行われます。この文脈における典型的な手順は、いわゆる教師あり学習であり、AI はすでに正解が提供されているサンプル データから学習します。
フィードバックの一般的な方法は、ニューラル ネットワークで使用されるバックプロパゲーション アルゴリズムです。モデルが引き起こすエラーは、ニューロン接続の重みを調整するためにネットワークを通じて逆方向に伝播されます。モデルは間違いから学習し、予測がますます正確になります。
トレーニングの役割 🏋️♂️
AI のトレーニングは反復的なプロセスです。モデルが参照するデータが多くなり、このデータに基づいてトレーニングされる頻度が増えるほど、その予測はより正確になります。ただし、限界もあります。過度にトレーニングされたモデルには、いわゆる「過剰適合」問題が発生する可能性があります。これは、トレーニング データを非常によく記憶するため、新しい未知のデータに対してはさらに悪い結果が生成されることを意味します。したがって、新しいデータでも一般化して適切な予測ができるようにモデルをトレーニングすることが重要です。
通常のトレーニングに加えて、転移学習などの手順もあります。ここでは、大量のデータですでにトレーニングされたモデルが、新しい同様のタスクに使用されます。これにより、モデルを最初からトレーニングする必要がないため、時間と計算能力が節約されます。
あなたの強みを最大限に活かしてください🚀
人工知能の仕事は、さまざまなステップの複雑な相互作用に基づいています。データ入力、前処理、モデルのトレーニング、予測、フィードバックに至るまで、AI の精度と効率に影響を与える要素は数多くあります。よく訓練された AI は、単純なタスクの自動化から複雑な問題の解決まで、生活のさまざまな分野で多大なメリットをもたらします。しかし、AI の強みを最大限に活用するには、AI の限界と潜在的な落とし穴を理解することも同様に重要です。
🤖📚 簡単に説明すると、AI はどのように訓練されるのでしょうか?
🤖📊 AI 学習プロセス: キャプチャ、リンク、保存
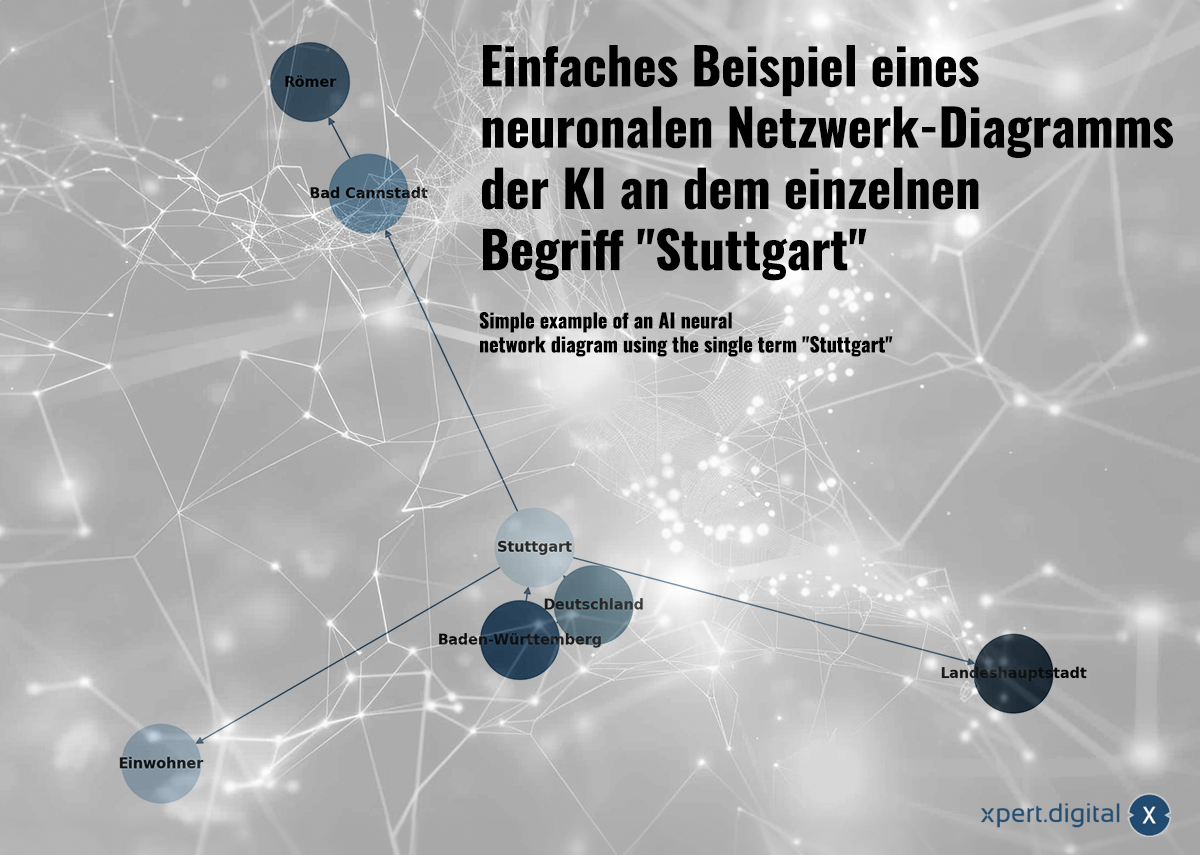
個々の用語「stuttgart」 - イメージ:xpert.digitalに関するAIのニューロンネットワーク図の簡単な例
🌟 データの収集と準備
AI 学習プロセスの最初のステップは、データを収集して準備することです。このデータは、データベース、センサー、テキスト、画像などのさまざまなソースから取得できます。
🌟 データの関連付け (ニューラルネットワーク)
収集されたデータは、ニューラルネットワークで互いに関連しています。各データパッケージは、「ニューロン」(ノード)のネットワーク内の接続によって表示されます。シュトゥットガルト市の簡単な例は、次のようになる可能性があります。
a) シュトゥットガルトはバーデン ヴュルテンベルク州の都市
b) バーデン ヴュルテンベルク州はドイツの連邦州
c) シュトゥットガルトはドイツの都市
d) シュトゥットガルトの人口は 2023 年で 633,484 人
e) バート カンシュタットはシュトゥットガルトの地区
f)バート カンシュタットはローマ人によって設立されました
g) シュトゥットガルトはバーデン ヴュルテンベルク州の州都です
データ量のサイズに応じて、使用される AI モデルを使用して潜在的な費用のパラメータが作成されます。例として、GPT-3 には約 1,750 億のパラメーターがあります。
🌟 ストレージとカスタマイズ (学習)
データはニューラル ネットワークに供給されます。これらは AI モデルを通過し、接続 (シナプスと同様) を介して処理されます。ニューロン間の重み (パラメーター) は、モデルをトレーニングしたりタスクを実行したりするために調整されます。
直接アクセス、指定アクセス、シーケンシャルまたはスタックストレージなどの従来のメモリフォームとは対照的に、ニューラルネットワークは型破りな方法でデータを保存します。 「データ」は、ニューロン間の接続の重みとバイアスに保存されます。
ニューロンネットワーク内の情報の実際の「ストレージ」は、ニューロン間の接続ウェイトを適応させることにより行われます。 AIモデルは、入力データと定義された学習アルゴリズムに基づいて、これらの重みとバイアスを絶えず適応させることにより、「学習」します。これは、繰り返し調整のためにモデルが正確な予測を行うことができる連続プロセスです。
AI モデルは、定義されたアルゴリズムと数学的計算を通じて作成され、正確な予測を行うためにパラメーター (重み) の調整を継続的に改善するため、プログラミングの一種と考えることができます。これは進行中のプロセスです。
バイアスは、ニューロンの重み付けされた入力値に追加されるニューラル ネットワークの追加パラメーターです。これらにより、パラメーターに重み付け (重要、それほど重要ではない、重要など) が可能になり、AI がより柔軟かつ正確になります。
ニューラル ネットワークは、個々の事実を保存するだけでなく、パターン認識を通じてデータ間のつながりを認識することもできます。シュトゥットガルトの例は、どのように知識をニューラル ネットワークに導入できるかを示していますが、ニューラル ネットワークは (この単純な例のように) 形式知を通じて学習するのではなく、データ パターンの分析を通じて学習します。ニューラル ネットワークは、個々の事実を保存するだけでなく、入力データ間の重みや関係を学習することもできます。
このフローでは、技術的な詳細にあまり深く立ち入ることなく、特に AI とニューラル ネットワークがどのように機能するかをわかりやすく紹介します。これは、ニューラル ネットワークへの情報の保存が、従来のデータベースのように行われるのではなく、ネットワーク内の接続 (重み) を調整することによって行われることを示しています。
🤖📚 詳細: AI はどのように訓練されるのですか?
🏋️♂️ AI、特に機械学習モデルのトレーニングは、いくつかのステップで行われます。 AI のトレーニングは、モデルが提供されたデータに対して最高のパフォーマンスを示すまで、フィードバックと調整を通じてモデル パラメーターを継続的に最適化することに基づいています。このプロセスがどのように機能するかについての詳細な説明は次のとおりです。
1. 📊 データの収集と準備
データは AI トレーニングの基盤です。通常、それらはシステムが分析するための数千または数百万の例で構成されます。例としては、画像、テキスト、時系列データなどがあります。
不要なエラーの原因を避けるために、データをクリーンアップして正規化する必要があります。多くの場合、データは関連情報を含む特徴に変換されます。
2. 🔍 モデルを定義する
モデルは、データ内の関係を記述する数学関数です。 AI によく使用されるニューラル ネットワークでは、モデルは互いに接続された複数の層のニューロンで構成されます。
各ニューロンは数学的演算を実行して入力データを処理し、信号を次のニューロンに渡します。
3. 🔄 重みを初期化する
ニューロン間の接続には、最初はランダムに設定される重みがあります。これらの重みは、ニューロンが信号にどれだけ強く反応するかを決定します。
トレーニングの目標は、モデルがより適切な予測を行えるようにこれらの重みを調整することです。
4. ➡️ 順伝播
フォワード パスは、入力データをモデルに渡して予測を生成します。
各層はデータを処理し、最後の層が結果を提供するまで次の層にデータを渡します。
5. ⚖️損失関数の計算
損失関数は、モデルの予測が実際の値 (ラベル) と比較してどの程度優れているかを測定します。一般的な尺度は、予測された応答と実際の応答の間の誤差です。
損失が大きいほど、モデルの予測は悪くなります。
6. 🔙 逆伝播
バックワード パスでは、誤差はモデルの出力から前の層にフィードバックされます。
誤差は接続の重みに再配分され、モデルは誤差が小さくなるように重みを調整します。
これは勾配降下法を使用して行われます。勾配ベクトルが計算され、誤差を最小限に抑えるために重みをどのように変更する必要があるかを示します。
7. 🔧 重みを更新する
誤差が計算された後、学習率に基づいてわずかな調整を加えて接続の重みが更新されます。
学習率によって、各ステップで重みがどの程度変更されるかが決まります。変更が大きすぎるとモデルが不安定になる可能性があり、変更が小さすぎると学習プロセスが遅くなる可能性があります。
8. 🔁 リピート (エポック)
この前方パス、誤差計算、重み更新のプロセスは、モデルが許容可能な精度に達するまで、多くの場合複数のエポックにわたって (データ セット全体を通過して) 繰り返されます。
エポックごとに、モデルはさらに学習し、重みをさらに調整します。
9. 📉 検証とテスト
モデルがトレーニングされた後、検証されたデータセットでテストされ、モデルがどの程度一般化されているかを確認します。これにより、トレーニング データを「記憶」するだけでなく、未知のデータに対して適切な予測を行うことが保証されます。
テスト データは、モデルを実際に使用する前に、モデルの最終的なパフォーマンスを測定するのに役立ちます。
10. 🚀 最適化
モデルを改善するための追加の手順には、ハイパーパラメーターの調整 (学習率やネットワーク構造の調整など)、正則化 (過剰適合を避けるため)、またはデータ量の増加が含まれます。
📊🔙 人工知能: Explainable AI (XAI)、ヒートマップ、サロゲート モデル、またはその他のソリューションを使用して、AI のブラック ボックスを理解可能、理解可能、説明可能にします

人工知能: Explainable AI (XAI)、ヒートマップ、サロゲート モデル、またはその他のソリューションを使用して、AI のブラック ボックスを理解しやすく、説明しやすくする - 画像: Xpert.Digital
人工知能 (AI) のいわゆる「ブラック ボックス」は、専門家であっても、AI システムがどのように決定を下すのかを完全に理解できないという課題に直面することがよくあります。この透明性の欠如は、特に経済、政治、医学などの重要な分野で重大な問題を引き起こす可能性があります。 AI システムを利用して診断や治療を推奨する医師や医療専門家は、下された決定に自信を持っていなければなりません。ただし、AI の意思決定が十分に透明でない場合、人命が危険にさらされる可能性がある状況で不確実性が生じ、潜在的に信頼の欠如が生じます。
詳細については、こちらをご覧ください:
私たちはあなたのために - アドバイス - 計画 - 実施 - プロジェクト管理
☑️ 戦略、コンサルティング、計画、実行における中小企業のサポート
☑️ デジタル戦略の策定または再調整とデジタル化
☑️ 海外販売プロセスの拡大と最適化
☑️ グローバルおよびデジタル B2B 取引プラットフォーム
☑️ 先駆的な事業開発

コンラッド・ウルフェンシュタイン
あなたの個人的なアドバイザーとして喜んでお手伝いさせていただきます。
以下のお問い合わせフォームにご記入いただくか、 +49 89 89 674 804 (ミュンヘン)。
私たちの共同プロジェクトを楽しみにしています。
私に書いてください

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital は、デジタル化、機械工学、物流/イントラロジスティクス、太陽光発電に重点を置いた産業のハブです。
360°の事業開発ソリューションで、新規事業からアフターセールスまで有名企業をサポートします。
マーケット インテリジェンス、マーケティング、マーケティング オートメーション、コンテンツ開発、PR、メール キャンペーン、パーソナライズされたソーシャル メディア、リード ナーチャリングは、当社のデジタル ツールの一部です。
www.xpert.digital - www.xpert.solar - www.xpert.plusをご覧ください。
連絡を取り合う


















