


AIの説明:人工知能はどのように機能し、どのように訓練されるのか? – 画像:Xpert.Digital
📊 データ入力からモデル予測まで:AIプロセス
人工知能(AI)はどのように機能するのでしょうか?🤖
人工知能(AI)の機能は、明確に定義された複数のステップに分けることができます。これらのステップはそれぞれ、AIが最終的に提供する結果に大きく影響します。プロセスはデータの入力から始まり、モデルの予測とフィードバック、あるいは追加のトレーニングラウンドで終わります。これらのフェーズは、シンプルなルールセットから非常に複雑なニューラルネットワークまで、ほぼすべてのAIモデルが経るプロセスを説明しています。.
1. データ入力📊
あらゆる人工知能の基盤となるのは、それが扱うデータです。このデータは、画像、テキスト、音声ファイル、動画など、様々な形式で存在します。AIはこれらの生データを用いてパターンを認識し、意思決定を行います。データの質と量は、モデルの最終的なパフォーマンスに大きく影響するため、ここで重要な役割を果たします。
データがより包括的かつ正確であればあるほど、AIの学習能力は向上します。例えば、画像処理用のAIを訓練する場合、様々な物体を正しく識別するためには大量の画像データが必要です。言語モデルの場合、AIが人間の音声を理解し、生成するのに役立つのはテキストデータです。データ入力は最初のステップであり、最も重要なステップの一つです。予測の質は、その基礎となるデータの品質に左右されるからです。コンピュータサイエンスの有名な原則は、「ガベージイン、ガベージアウト(Garbage in, Garbage out)」、つまり悪いデータは悪い結果をもたらすというものです。
2. データの前処理 🧹
データが入力されたら、実際のモデルに取り込む前に準備する必要があります。このプロセスはデータ前処理と呼ばれます。ここでの目標は、データをモデルが最適に処理できる形式に変換することです。
前処理における一般的なステップは、データの正規化です。これは、モデルによってデータが一貫して処理されるように、データを均一な値の範囲に収めることを意味します。例えば、画像のすべてのピクセル値を0~255ではなく0~1の範囲にスケーリングすることが挙げられます。
前処理のもう一つの重要な部分は特徴抽出です。これは、生データからモデルに特に関連性の高い特定の特徴を抽出することを意味します。画像処理ではエッジや特定の色パターンなどが、テキスト処理では関連するキーワードや文構造などが抽出されます。前処理は、AIの学習プロセスをより効率的かつ正確にするために不可欠です。
3. モデル🧩
モデルはあらゆる人工知能の中核です。ここでは、アルゴリズムと数学的計算に基づいてデータが分析・処理されます。モデルは様々な形で存在します。最もよく知られているモデルの一つは、人間の脳の働きに基づいたニューラルネットワークです。
ニューラルネットワークは、情報を処理して伝達する複数の人工ニューロン層で構成されています。各層は前の層からの出力を受け取り、さらに処理します。ニューラルネットワークの学習プロセスでは、ニューロン間の接続の重みを調整することで、ネットワークの予測や分類の精度を高めます。この調整はトレーニングによって実現されます。トレーニングでは、ネットワークは大量のサンプルデータにアクセスし、内部パラメータ(重み)を反復的に改善していきます。
AIモデルでは、ニューラルネットワーク以外にも多くのアルゴリズムが用いられています。例えば、決定木、ランダムフォレスト、サポートベクターマシンなどです。どのアルゴリズムが用いられるかは、具体的なタスクと利用可能なデータによって異なります。
4. モデル予測 🔍
モデルがデータで学習されると、予測が可能になります。このステップはモデル予測と呼ばれます。AIは入力を受け取り、これまでに学習したパターンに基づいて、予測または決定という出力を返します。
この予測は様々な形態をとることができます。例えば、画像分類モデルでは、AIは写真に写っている物体を予測できます。言語モデルでは、文中で次に来る単語を予測できます。金融予測では、AIは株式市場の動きを予測できます。
予測の精度は、トレーニングデータの品質とモデルアーキテクチャに大きく依存することを強調しておくことが重要です。不十分なデータや偏ったデータでトレーニングされたモデルは、誤った予測を行う可能性が高くなります。
5. フィードバックとトレーニング(オプション)♻️
AIの仕組みにおけるもう一つの重要な側面は、フィードバックメカニズムです。ここでは、モデルは定期的にチェックされ、さらに最適化されます。このプロセスは、トレーニング中、またはモデルの予測後に行われます。
モデルが誤った予測を行った場合、フィードバックを通じて学習し、これらの誤りを認識し、それに応じて内部パラメータを調整することができます。これは、モデルの予測と実際の結果(例えば、既に正解が存在する既知のデータ)を比較することによって行われます。この文脈における典型的な手法は、いわゆる教師あり学習であり、AIは既に正解が含まれているサンプルデータから学習します。
一般的なフィードバック手法として、ニューラルネットワークで使用されるバックプロパゲーションアルゴリズムがあります。このアルゴリズムでは、モデルが生成した誤差がネットワークを逆方向に伝播し、ニューラルネットワークの重みを調整します。このようにして、モデルは誤差から学習し、予測精度を向上させます。
トレーニングの役割🏋️♂️
AIの学習は反復的なプロセスです。モデルが扱うデータが増え、そのデータで学習する頻度が増えるほど、予測精度は向上します。しかし、限界もあります。過剰学習されたモデルは、いわゆる「過学習」の問題を引き起こす可能性があります。これは、モデルが学習データを過度に記憶してしまい、新しい未知のデータに対しては精度の低い結果を出すことを意味します。そのため、モデルを一般化するように学習させる、つまり新しいデータに対しても優れた予測ができるようにすることが重要です。
通常の学習に加えて、転移学習のような手法もあります。転移学習では、大規模なデータセットで既に学習済みのモデルを、類似した新しいタスクに使用します。これにより、モデルを最初から完全に学習する必要がないため、時間と計算能力を節約できます。
自分の強みを最大限に活用しましょう🚀
人工知能(AI)の動作は、様々なステップの複雑な相互作用に基づいています。データの入力と前処理から、モデルの学習、予測、フィードバックまで、多くの要因がAIの精度と効率に影響を与えます。適切に学習されたAIは、単純なタスクの自動化から複雑な問題の解決まで、生活の多くの分野で計り知れないメリットをもたらします。しかし、AIの強みを最大限に活用するためには、AIの限界と潜在的な落とし穴を理解することも同様に重要です。
🤖📚 簡単に説明: AI はどのようにトレーニングされるのでしょうか?
🤖📊 AI学習プロセス:キャプチャ、リンク、保存
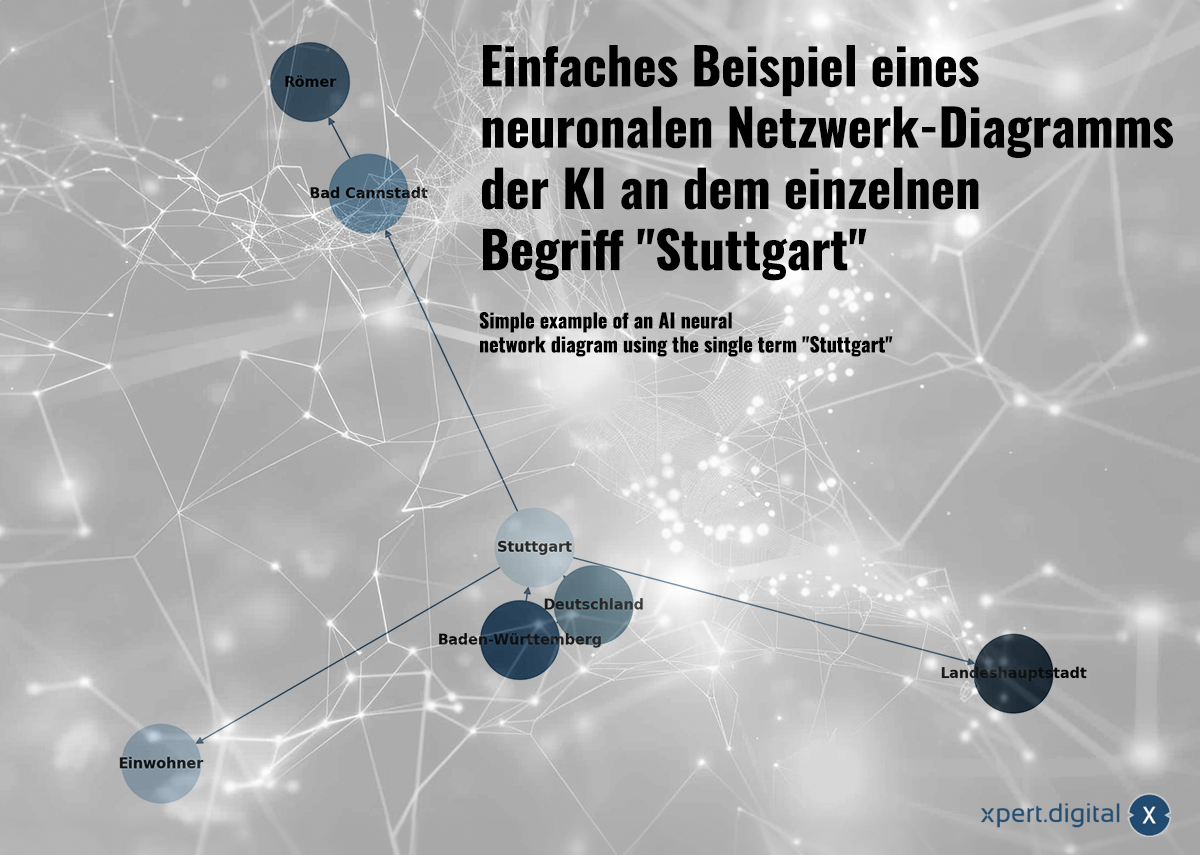
「シュトゥットガルト」という単語を使ったAIニューラルネットワーク図の簡単な例 – 画像: Xpert.Digital
🌟 データの収集と準備
AI学習プロセスの最初のステップは、データの収集と準備です。このデータは、データベース、センサー、テキスト、画像など、さまざまなソースから取得できます。
🌟 データの関係性(ニューラルネットワーク)
収集されたデータはニューラルネットワークで相互にリンクされます。各データパケットは、「ニューロン」(ノード)のネットワーク内の接続によって表現されます。シュトゥットガルト市を例に挙げると、以下のようになります。
a) シュトゥットガルトはバーデン=ヴュルテンベルク州の都市です
b) バーデン=ヴュルテンベルク州はドイツの連邦州です
c) シュトゥットガルトはドイツの都市です
d) シュトゥットガルトの人口は2023年時点で633,484人でした
e) バート・カンシュタットはシュトゥットガルトの地区です
f) バート・カンシュタットはローマ人によって設立されました
g) シュトゥットガルトはバーデン=ヴュルテンベルク州の州都です
データ量の大きさに応じて、AIモデルを用いて潜在的な出力のパラメータが生成されます。例えば、GPT-3は約1750億個のパラメータを持っています。
🌟 保存とカスタマイズ(学習)
データはニューラルネットワークに入力され、AIモデルを通過し、シナプスのような接続を介して処理されます。ニューロン間の重み(パラメータ)は、モデルの学習やタスクの実行のために調整されます。
直接アクセス、インデックスアクセス、シーケンシャルストレージ、バッチストレージといった従来のストレージ方式とは異なり、ニューラルネットワークは非伝統的な方法でデータを保存します。「データ」はニューロン間の接続における重みとバイアスに格納されます。
ニューラルネットワークにおける情報の実際の「記憶」は、ニューロン間の接続重みの調整によって行われます。AIモデルは、入力データと定義された学習アルゴリズムに基づいて、これらの重みとバイアスを継続的に調整することで「学習」します。これは継続的なプロセスであり、モデルは調整を繰り返すことでより正確な予測を行うことができます。
AIモデルは、定義されたアルゴリズムと数学的計算によって作成され、そのパラメータ(重み)の調整が継続的に改善され、正確な予測を行うため、一種のプログラミングと見なすことができます。これは継続的なプロセスです。
バイアスは、ニューラルネットワークにおける追加パラメータであり、ニューロンの重み付けされた入力値に追加されます。バイアスによりパラメータに重み付け(重要度、重要度が低いなど)が可能になり、AIの柔軟性と精度が向上します。
ニューラルネットワークは個々の事実を記憶するだけでなく、パターン認識を通じてデータ間の関係性も認識できます。シュトゥットガルトの例は、ニューラルネットワークに知識をどのように入力するかを示していますが、ニューラルネットワークは(この単純な例のように)明示的な知識を通して学習するのではなく、データパターンの分析を通して学習します。したがって、ニューラルネットワークは個々の事実を記憶するだけでなく、入力データ間の重みや関係性も学習できます。
このプロセスは、技術的な詳細に深く立ち入ることなく、AI、特にニューラルネットワークの仕組みを分かりやすく解説します。従来のデータベースのようにニューラルネットワークに情報が保存されるのではなく、ネットワーク内の接続(重み)を調整することで情報が保存されることを示しています。
🤖📚 さらに詳しく: AI はどのようにトレーニングされるのでしょうか?
🏋️♂️ AI、特に機械学習モデルのトレーニングには、複数のステップが含まれます。AIのトレーニングは、フィードバックと調整を通じてモデルパラメータを継続的に最適化し、提供されたデータに対してモデルが最適なパフォーマンスを発揮するまで行われます。このプロセスの詳細な説明は以下のとおりです。
1. 📊 データを収集して準備する
データはAIトレーニングの基盤です。通常、システムが分析する数千または数百万の例で構成されます。例としては、画像、テキスト、時系列データなどが挙げられます。
不要なエラーの原因を回避するために、データはクリーニングおよび正規化される必要があります。多くの場合、データは関連情報を含む特徴量に変換されます。
2. 🔍 モデルを定義する
モデルとは、データ内の関係性を記述する数学的な関数です。AIでよく用いられるニューラルネットワークでは、モデルは相互接続された複数のニューロン層で構成されています。
各ニューロンは数学演算を実行して入力データを処理してから、信号を次のニューロンに渡します。
3. 🔄 重みを初期化する
ニューロン間の接続には、最初にランダムに設定される重みがあります。これらの重みによって、ニューロンが信号にどの程度強く反応するかが決まります。
トレーニングの目的は、モデルがより良い予測を行えるようにこれらの重みを調整することです。
4. ➡️ 順方向伝播
フォワードパスでは、入力データがモデルによって処理され、予測が得られます。
各層はデータを処理し、最後の層が結果を返すまでそれを次の層に渡します。
5. ⚖️損失関数を計算する
損失関数は、モデルの予測値が実際の値(ラベル)とどの程度一致しているかを測定します。一般的な指標は、予測値と実際の応答値の間の誤差です。
損失が大きくなると、モデルの予測精度は悪くなります。
6. 🔙 バックプロパゲーション
逆反復では、モデルの出力から前のレイヤーまでエラーが遡って追跡されます。
誤差は接続の重みに再分配され、モデルは誤差が小さくなるように重みを調整します。
これは勾配降下法を使用して行われます。勾配ベクトルが計算され、誤差を最小限に抑えるために重みをどのように変更する必要があるかが示されます。
7. 🔧 重みを更新する
エラーが計算された後、学習率に基づいて小さな調整を加えて接続の重みが更新されます。
学習率は、各ステップで重みをどれだけ変更するかを決定します。変更が大きすぎるとモデルが不安定になる可能性があり、変更が小さすぎると学習プロセスが遅くなります。
8. 🔁 繰り返し(エポック)
このフォワードパス、エラー計算、および重み更新のプロセスは、モデルが許容可能な精度を達成するまで、多くの場合、複数のエポック(データセット全体のパス)にわたって繰り返されます。
各時代ごとに、モデルは少しずつ学習し、重みをさらに調整します。
9. 📉 検証とテスト
モデルは学習後、検証済みのデータセットを用いて一般化の精度をテストされます。これにより、モデルが学習データを「記憶」しているだけでなく、未知のデータに対しても優れた予測を行うことが保証されます。
テスト データは、モデルを実際に使用する前に、モデルの最終的なパフォーマンスを測定するのに役立ちます。
10. 🚀 最適化
モデルを改善するためのさらなる手順には、ハイパーパラメータの調整 (学習率やネットワーク構造の調整など)、正則化 (過剰適合を避けるため)、データ量の増加などがあります。
📊🔙 人工知能: Explainable AI (XAI)、ヒートマップ、サロゲート モデル、その他のソリューションを使用して、AI のブラック ボックスを理解しやすく、網羅的に説明できるようにします。


人工知能:説明可能なAI(XAI)、ヒートマップ、サロゲートモデル、その他のソリューションを使用して、AIのブラックボックスを理解しやすく、理解しやすく、説明可能にする – 画像:Xpert.Digital
人工知能(AI)のいわゆる「ブラックボックス」は、重大かつ差し迫った問題です。専門家でさえ、AIシステムがどのように意思決定に至るのかを完全に理解できないという課題に直面することがしばしばあります。この透明性の欠如は、特に経済、政治、医療といった重要な分野において、大きな問題を引き起こす可能性があります。診断や治療の推奨にAIシステムを頼る医師は、その意思決定に自信を持たなければなりません。しかし、AIの意思決定プロセスが十分に透明性を欠く場合、不確実性が生じ、人命に関わる状況において、信頼の欠如につながる可能性があります。
詳細については、こちらをご覧ください:
私たちはあなたのために - アドバイス - 計画 - 実施 - プロジェクト管理
☑️ 戦略、コンサルティング、計画、実行における中小企業のサポート
☑️ デジタル戦略の策定または再調整とデジタル化
☑️ 海外販売プロセスの拡大と最適化
☑️ グローバルおよびデジタル B2B 取引プラットフォーム
☑️ 先駆的な事業開発

Konrad Wolfenstein
あなたの個人的なアドバイザーとして喜んでお手伝いさせていただきます。
以下のお問い合わせフォームにご記入いただくか、 +49 89 89 674 804 (ミュンヘン)。
私たちの共同プロジェクトを楽しみにしています。
私に書いてください




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital は、デジタル化、機械工学、物流/イントラロジスティクス、太陽光発電に重点を置いた産業のハブです。
360°の事業開発ソリューションで、新規事業からアフターセールスまで有名企業をサポートします。
マーケット インテリジェンス、マーケティング、マーケティング オートメーション、コンテンツ開発、PR、メール キャンペーン、パーソナライズされたソーシャル メディア、リード ナーチャリングは、当社のデジタル ツールの一部です。
www.xpert.digital - www.xpert.solar - www.xpert.plusをご覧ください。
連絡を取り合う











