Errore di calcolo da 57 miliardi di dollari – NVIDIA, tra tutte le aziende, avverte: l’industria dell’intelligenza artificiale ha puntato sul cavallo sbagliato – Immagine: Xpert.Digital
Dimenticate i giganti dell'intelligenza artificiale: perché il futuro è piccolo, decentralizzato e molto più economico
### Modelli di linguaggio di piccole dimensioni: la chiave per una vera autonomia aziendale ### Dagli hyperscaler agli utenti: cambiamento di potere nel mondo dell'intelligenza artificiale ### L'errore da 57 miliardi di dollari: perché la vera rivoluzione dell'intelligenza artificiale non sta avvenendo nel cloud ### La rivoluzione silenziosa dell'intelligenza artificiale: decentralizzata anziché centralizzata ### I giganti della tecnologia sono sulla strada sbagliata: il futuro dell'intelligenza artificiale è snello e locale ### Dagli hyperscaler agli utenti: cambiamento di potere nel mondo dell'intelligenza artificiale ###
Miliardi di dollari di investimenti sprecati: perché i piccoli modelli di intelligenza artificiale stanno superando quelli grandi
Il mondo dell'intelligenza artificiale sta affrontando un terremoto la cui portata ricorda le correzioni dell'era delle dot-com. Al centro di questo sconvolgimento c'è un colossale errore di calcolo: mentre giganti della tecnologia come Microsoft, Google e Meta investono centinaia di miliardi in infrastrutture centralizzate per modelli linguistici di grandi dimensioni (Large Language Models, LLM), il mercato effettivo per la loro applicazione è in netto ritardo. Un'analisi rivoluzionaria, condotta in parte dalla stessa NVIDIA, leader del settore, quantifica il divario in 57 miliardi di dollari di investimenti infrastrutturali rispetto a un mercato reale di soli 5,6 miliardi di dollari: una discrepanza di dieci volte.
Questo errore strategico deriva dal presupposto che il futuro dell'IA risieda esclusivamente in modelli sempre più grandi, computazionalmente più intensivi e controllati centralmente. Ma ora questo paradigma sta crollando. Una rivoluzione silenziosa, guidata da modelli linguistici decentralizzati e più piccoli (Small Language Models, SLM), sta capovolgendo l'ordine costituito. Questi modelli non solo sono molto più economici ed efficienti, ma consentono anche alle aziende di raggiungere nuovi livelli di autonomia, sovranità dei dati e agilità, ben lontani dalla costosa dipendenza da pochi hyperscaler. Questo testo analizza l'anatomia di questo investimento errato multimiliardario e dimostra perché la vera rivoluzione dell'IA non si sta verificando in giganteschi data center, ma in modo decentralizzato e su hardware snello. È la storia di un fondamentale spostamento di potere dai fornitori di infrastrutture agli utenti della tecnologia.
Correlato a questo:


Ricerca NVIDIA sull'errata allocazione del capitale AI
I dati descritti provengono da un documento di ricerca NVIDIA pubblicato nel giugno 2025. La fonte completa è:
“I modelli di linguaggio di piccole dimensioni sono il futuro dell’intelligenza artificiale agentiva”
- Autori: Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
- Data di rilascio: 2 giugno 2025 (versione 1), ultima revisione 15 settembre 2025 (versione 2)
- Posizione di pubblicazione: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- Pagina ufficiale di NVIDIA Research: https://research.nvidia.com/labs/lpr/slm-agents/
Il messaggio chiave riguardante l'errata allocazione del capitale
La ricerca documenta una discrepanza fondamentale tra gli investimenti infrastrutturali e il volume effettivo del mercato: nel 2024, il settore ha investito 57 miliardi di dollari in infrastrutture cloud per supportare i servizi API Large Language Model (LLM), mentre il mercato effettivo per questi servizi ammontava a soli 5,6 miliardi di dollari. Questa discrepanza di dieci a uno è interpretata nello studio come un'indicazione di un errore di calcolo strategico, poiché il settore ha investito massicciamente in infrastrutture centralizzate per modelli su larga scala, nonostante il 40-70% degli attuali carichi di lavoro LLM potrebbe essere sostituito da Small Language Model (SLM) più piccoli e specializzati a 1/30 del costo.
Contesto della ricerca e paternità
Questo studio è un documento di posizione del Deep Learning Efficiency Research Group di NVIDIA Research. L'autore principale, Peter Belcak, è un ricercatore di intelligenza artificiale presso NVIDIA, specializzato in affidabilità ed efficienza dei sistemi basati su agenti. Il documento si basa su tre pilastri:
Gli SLM sono
- sufficientemente potente
- chirurgicamente adatto e
- economicamente necessario
per molti casi d'uso nei sistemi di intelligenza artificiale agentiva.
I ricercatori sottolineano esplicitamente che le opinioni espresse in questo articolo sono quelle degli autori e non riflettono necessariamente la posizione di NVIDIA come azienda. NVIDIA invita alla discussione critica e si impegna a pubblicare qualsiasi corrispondenza correlata sul sito web allegato.
Perché i modelli linguistici decentralizzati di piccole dimensioni rendono obsoleta la scommessa sull'infrastruttura centralizzata
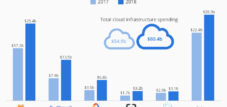
L'intelligenza artificiale si trova a un punto di svolta, le cui implicazioni ricordano gli sconvolgimenti della bolla delle dot-com. Una ricerca di NVIDIA ha rivelato una fondamentale errata allocazione del capitale che scuote le fondamenta dell'attuale strategia di intelligenza artificiale. Mentre l'industria tecnologica ha investito 57 miliardi di dollari in infrastrutture centralizzate per modelli linguistici su larga scala, il mercato effettivo per il loro utilizzo è cresciuto fino a soli 5,6 miliardi di dollari. Questa discrepanza di dieci a uno non solo segna una sovrastima della domanda, ma evidenzia anche un errore strategico fondamentale riguardo al futuro dell'intelligenza artificiale.
Un cattivo investimento? Miliardi spesi in infrastrutture di intelligenza artificiale: cosa fare con la capacità in eccesso?
I numeri parlano da soli. Nel 2024, la spesa globale per le infrastrutture di intelligenza artificiale ha raggiunto una cifra compresa tra 80 e 87 miliardi di dollari, secondo diverse analisi, con data center e acceleratori che rappresentano la stragrande maggioranza. Microsoft ha annunciato investimenti per 80 miliardi di dollari per l'anno fiscale 2025, Google ha alzato le sue previsioni a una cifra compresa tra 91 e 93 miliardi di dollari e Meta prevede di investire fino a 70 miliardi di dollari. Questi tre hyperscaler da soli rappresentano un volume di investimenti di oltre 240 miliardi di dollari. La spesa totale per le infrastrutture di intelligenza artificiale potrebbe raggiungere una cifra compresa tra 3,7 e 7,9 trilioni di dollari entro il 2030, secondo le stime di McKinsey.
Al contrario, la realtà dal lato della domanda è sconfortante. Il mercato dei modelli linguistici aziendali di grandi dimensioni è stato stimato in soli 4-6,7 miliardi di dollari per il 2024, con proiezioni per il 2025 che vanno da 4,8 a 8 miliardi di dollari. Anche le stime più generose per il mercato dell'IA generativa nel suo complesso si attestano tra 28 e 44 miliardi di dollari per il 2024. La discrepanza fondamentale è evidente: l'infrastruttura è stata costruita per un mercato che non esiste in questa forma e portata.
Questo investimento errato deriva da un presupposto che si sta rivelando sempre più falso: che il futuro dell'IA risieda in modelli sempre più grandi e centralizzati. Gli hyperscaler hanno perseguito una strategia di scalabilità massiva, spinti dalla convinzione che il numero di parametri e la potenza di calcolo fossero i fattori competitivi decisivi. GPT-3, con 175 miliardi di parametri, è stato considerato una svolta nel 2020, e GPT-4, con oltre mille miliardi di parametri, ha stabilito nuovi standard. Il settore ha seguito ciecamente questa logica e ha investito in un'infrastruttura progettata per le esigenze di modelli sovradimensionati per la maggior parte dei casi d'uso.
La struttura degli investimenti illustra chiaramente l'errata allocazione. Nel secondo trimestre del 2025, il 98% degli 82 miliardi di dollari spesi per l'infrastruttura di intelligenza artificiale è stato destinato ai server, di cui il 91,8% a sistemi accelerati da GPU e XPU. Gli hyperscaler e i cloud builder hanno assorbito l'86,7% di queste spese, circa 71 miliardi di dollari in un solo trimestre. Questa concentrazione di capitale in hardware altamente specializzato ed estremamente dispendioso in termini energetici per l'addestramento e l'inferenza di modelli di grandi dimensioni ha ignorato una realtà economica fondamentale: la maggior parte delle applicazioni aziendali non richiede questa capacità.
Il paradigma si sta rompendo: da centralizzato a decentralizzato
La stessa NVIDIA, principale beneficiaria del recente boom infrastrutturale, sta ora fornendo un'analisi che sfida questo paradigma. La ricerca sui Small Language Models come futuro dell'IA basata su agenti sostiene che i modelli con meno di 10 miliardi di parametri non solo sono sufficienti, ma sono anche operativamente superiori per la stragrande maggioranza delle applicazioni di IA. Lo studio di tre grandi sistemi di agenti open source ha rivelato che dal 40 al 70% delle chiamate a modelli di linguaggio di grandi dimensioni potrebbe essere sostituito da piccoli modelli specializzati senza alcuna perdita di prestazioni.
Questi risultati scuotono i presupposti fondamentali dell'attuale strategia di investimento. Se MetaGPT può sostituire il 60% delle sue chiamate LLM, Open Operator il 40% e Cradle il 70% con SLM, allora la capacità infrastrutturale è stata costruita per richieste che non esistono su questa scala. L'economia cambia radicalmente: un modello Small Language Llama 3.1B costa da dieci a trenta volte meno da gestire rispetto alla sua controparte più grande, Llama 3.3 405B. La messa a punto può essere eseguita in poche ore di GPU invece che in settimane. Molti SLM funzionano su hardware consumer, eliminando completamente le dipendenze dal cloud.
Il cambiamento strategico è fondamentale. Il controllo si sta spostando dai fornitori di infrastrutture agli operatori. Mentre l'architettura precedente costringeva le aziende a una posizione di dipendenza da pochi hyperscaler, la decentralizzazione attraverso gli SLM consente una nuova autonomia. I modelli possono essere gestiti localmente, i dati rimangono all'interno dell'azienda, i costi delle API vengono eliminati e il lock-in del fornitore viene eliminato. Questa non è solo una trasformazione tecnologica, ma una trasformazione delle politiche di potere.
La precedente scommessa sui modelli centralizzati su larga scala si basava sul presupposto di effetti di scalabilità esponenziali. Tuttavia, i dati empirici contraddicono sempre più questa ipotesi. Microsoft Phi-3, con 7 miliardi di parametri, raggiunge prestazioni di generazione del codice paragonabili a modelli da 70 miliardi di parametri. NVIDIA Nemotron Nano 2, con 9 miliardi di parametri, supera Qwen3-8B nei benchmark di ragionamento con un throughput sei volte superiore. L'efficienza per parametro aumenta con modelli più piccoli, mentre i modelli di grandi dimensioni spesso attivano solo una frazione dei loro parametri per un dato input, un'inefficienza intrinseca.
La superiorità economica dei modelli linguistici di piccole dimensioni
La struttura dei costi rivela la realtà economica con brutale chiarezza. L'addestramento di modelli di classe GPT-4 è stimato in oltre 100 milioni di dollari, con un costo potenziale di Gemini Ultra di 191 milioni di dollari. Anche la messa a punto di modelli di grandi dimensioni per domini specifici può costare decine di migliaia di dollari in termini di tempo GPU. Al contrario, gli SLM possono essere addestrati e messi a punto per poche migliaia di dollari, spesso su una singola GPU di fascia alta.
I costi di inferenza rivelano differenze ancora più drastiche. GPT-4 costa circa 0,03 dollari per 1.000 token di input e 0,06 dollari per 1.000 token di output, per un totale di 0,09 dollari per query media. Mistral 7B, come esempio di SLM, costa 0,0001 dollari per 1.000 token di input e 0,0003 dollari per 1.000 token di output, ovvero 0,0004 dollari per query. Ciò rappresenta una riduzione dei costi di un fattore 225. Con milioni di query, questa differenza si traduce in importi sostanziali che incidono direttamente sulla redditività.
Il costo totale di proprietà rivela ulteriori dimensioni. L'auto-hosting di un modello da 7 miliardi di parametri su server bare-metal con GPU L40S costa circa 953 dollari al mese. Il fine-tuning basato su cloud con AWS SageMaker su istanze g5.2xlarge costa 1,32 dollari all'ora, con potenziali costi di formazione a partire da 13 dollari per i modelli più piccoli. L'implementazione dell'inferenza 24 ore su 24, 7 giorni su 7, costerebbe circa 950 dollari al mese. Rispetto ai costi delle API per l'uso continuativo di modelli di grandi dimensioni, che possono facilmente raggiungere decine di migliaia di dollari al mese, il vantaggio economico diventa evidente.
La velocità di implementazione è un fattore economico spesso sottovalutato. Mentre la messa a punto di un Large Language Model può richiedere settimane, gli SLM sono pronti all'uso in poche ore o giorni. L'agilità nel rispondere rapidamente a nuovi requisiti, aggiungere nuove funzionalità o adattare il comportamento diventa un vantaggio competitivo. In mercati in rapida evoluzione, questa differenza di tempo può fare la differenza tra successo e fallimento.
L'economia di scala si sta invertendo. Tradizionalmente, le economie di scala erano viste come un vantaggio per gli hyperscaler, che mantengono enormi capacità e le distribuiscono tra numerosi clienti. Tuttavia, con gli SLM, anche le organizzazioni più piccole possono scalare in modo efficiente perché i requisiti hardware sono drasticamente inferiori. Una startup può costruire un SLM specializzato con un budget limitato, che supera in prestazioni un modello più ampio e generalista per il suo compito specifico. La democratizzazione dello sviluppo dell'intelligenza artificiale sta diventando una realtà economica.
Fondamenti tecnici della disruption
Le innovazioni tecnologiche che consentono gli SLM sono tanto significative quanto le loro implicazioni economiche. La distillazione della conoscenza, una tecnica in cui un modello studente più piccolo assorbe le conoscenze di un modello insegnante più grande, si è dimostrata altamente efficace. DistilBERT ha compresso con successo BERT e TinyBERT ha seguito principi simili. Gli approcci moderni distillano le capacità di grandi modelli generativi come GPT-3 in versioni significativamente più piccole che dimostrano prestazioni comparabili o migliori in compiti specifici.
Il processo utilizza sia le etichette soft (distribuzioni di probabilità) del modello teacher sia le etichette hard dei dati originali. Questa combinazione consente al modello più piccolo di catturare pattern sfumati che andrebbero persi in semplici coppie input-output. Tecniche di distillazione avanzate, come la distillazione step-by-step, hanno dimostrato che i modelli di piccole dimensioni possono ottenere risultati migliori rispetto ai modelli LLM anche con meno dati di training. Questo cambia radicalmente l'economia: invece di costosi e lunghi training su migliaia di GPU, sono sufficienti processi di distillazione mirati.
La quantizzazione riduce la precisione della rappresentazione numerica dei pesi del modello. Invece di numeri in virgola mobile a 32 o 16 bit, i modelli quantizzati utilizzano rappresentazioni di interi a 8 o persino 4 bit. I requisiti di memoria diminuiscono proporzionalmente, la velocità di inferenza aumenta e il consumo energetico diminuisce. Le moderne tecniche di quantizzazione riducono al minimo la perdita di accuratezza, spesso lasciando le prestazioni praticamente invariate. Ciò consente l'implementazione su dispositivi edge, smartphone e sistemi embedded, cosa che sarebbe impossibile con modelli di grandi dimensioni completamente precisi.
La potatura rimuove connessioni e parametri ridondanti dalle reti neurali. Analogamente alla modifica di un testo eccessivamente lungo, gli elementi non essenziali vengono identificati ed eliminati. La potatura strutturata rimuove interi neuroni o livelli, mentre la potatura non strutturata rimuove singoli pesi. La struttura di rete risultante è più efficiente, richiede meno memoria e potenza di elaborazione, pur mantenendo le sue funzionalità principali. In combinazione con altre tecniche di compressione, i modelli potati raggiungono notevoli guadagni di efficienza.
La fattorizzazione di basso rango scompone matrici di peso elevato in prodotti di matrici più piccole. Invece di una singola matrice con milioni di elementi, il sistema memorizza ed elabora due matrici significativamente più piccole. L'operazione matematica rimane approssimativamente la stessa, ma lo sforzo computazionale è drasticamente ridotto. Questa tecnica è particolarmente efficace nelle architetture a trasformatore, dove i meccanismi di attenzione dominano le moltiplicazioni di matrici di grandi dimensioni. Il risparmio di memoria consente finestre di contesto o batch di dimensioni maggiori con lo stesso budget hardware.
La combinazione di queste tecniche nei moderni SLM come la serie Microsoft Phi, Google Gemma o NVIDIA Nemotron ne dimostra il potenziale. Il Phi-2, con soli 2,7 miliardi di parametri, supera i modelli Mistral e Llama-2 con rispettivamente 7 e 13 miliardi di parametri nei benchmark aggregati e raggiunge prestazioni migliori rispetto al Llama-2-70B, 25 volte più grande, nei compiti di ragionamento multi-step. Questo risultato è stato ottenuto attraverso una selezione strategica dei dati, la generazione di dati sintetici di alta qualità e tecniche di scaling innovative. Il messaggio è chiaro: le dimensioni non sono più un indicatore di capacità.
Dinamiche di mercato e potenziale di sostituzione
I risultati empirici derivanti da applicazioni reali supportano le considerazioni teoriche. L'analisi di MetaGPT, un framework di sviluppo software multi-agente, condotta da NVIDIA, ha rilevato che circa il 60% delle richieste LLM è sostituibile. Queste attività includono la generazione di codice boilerplate, la creazione di documentazione e l'output strutturato, tutte aree in cui gli SLM specializzati funzionano in modo più rapido ed economico rispetto ai modelli generici su larga scala.
Open Operator, un sistema di automazione del flusso di lavoro, dimostra con il suo potenziale di sostituzione del 40% che, anche in scenari di orchestrazione complessi, molte sottoattività non richiedono la piena capacità dei LLM. L'analisi degli intenti, l'output basato su template e le decisioni di routing possono essere gestiti in modo più efficiente da modelli di piccole dimensioni e finemente ottimizzati. Il restante 60%, che in realtà richiede un ragionamento approfondito o una vasta conoscenza del mondo, giustifica l'uso di modelli di grandi dimensioni.
Cradle, un sistema di automazione GUI, presenta il più alto potenziale di sostituzione, pari al 70%. Interazioni ripetitive con l'interfaccia utente, sequenze di clic e inserimenti di moduli sono ideali per gli SLM. Le attività sono definite in modo rigoroso, la variabilità è limitata e i requisiti di comprensione contestuale sono bassi. Un modello specializzato, addestrato sulle interazioni GUI, supera un LLM generalista in termini di velocità, affidabilità e costi.
Questi modelli si ripetono in tutti gli ambiti applicativi. Chatbot per il servizio clienti per FAQ, classificazione di documenti, analisi del sentiment, riconoscimento di entità denominate, traduzioni semplici, query di database in linguaggio naturale: tutte queste attività traggono vantaggio dagli SLM. Uno studio stima che nelle tipiche implementazioni di intelligenza artificiale aziendale, dal 60 all'80% delle query rientri in categorie per le quali gli SLM sono sufficienti. Le implicazioni per la domanda di infrastrutture sono significative.
Il concetto di routing basato su modelli sta acquisendo sempre più importanza. I sistemi intelligenti analizzano le query in arrivo e le indirizzano al modello appropriato. Le query semplici vengono indirizzate a SLM economicamente vantaggiosi, mentre le attività complesse vengono gestite da LLM ad alte prestazioni. Questo approccio ibrido ottimizza l'equilibrio tra qualità e costi. Le prime implementazioni riportano risparmi sui costi fino al 75% con prestazioni complessive invariate o addirittura migliori. La logica di routing stessa può essere un piccolo modello di apprendimento automatico che tiene conto della complessità delle query, del contesto e delle preferenze dell'utente.
La proliferazione di piattaforme di fine-tuning-as-a-service ne sta accelerando l'adozione. Le aziende prive di competenze approfondite in ambito di machine learning possono creare SLM specializzati che incorporano dati proprietari e specifiche di dominio. L'investimento di tempo si riduce da mesi a giorni e il costo da centinaia di migliaia di dollari a migliaia di dollari. Questa accessibilità democratizza radicalmente l'innovazione nell'intelligenza artificiale e sposta la creazione di valore dai fornitori di infrastrutture agli sviluppatori di applicazioni.
Una nuova dimensione della trasformazione digitale con 'Managed AI' (Intelligenza Artificiale) - Piattaforma e soluzione B2B | Xpert Consulting

Una nuova dimensione della trasformazione digitale con 'Managed AI' (Intelligenza Artificiale) – Piattaforma e soluzione B2B | Xpert Consulting - Immagine: Xpert.Digital
Qui scoprirai come la tua azienda può implementare soluzioni di intelligenza artificiale personalizzate in modo rapido, sicuro e senza elevate barriere all'ingresso.
Una piattaforma di intelligenza artificiale gestita è la soluzione completa e senza pensieri per l'intelligenza artificiale. Invece di dover gestire tecnologie complesse, infrastrutture costose e lunghi processi di sviluppo, riceverai una soluzione pronta all'uso, su misura per le tue esigenze, da un partner specializzato, spesso entro pochi giorni.
I principali vantaggi in sintesi:
⚡ Implementazione rapida: dall'idea all'applicazione pronta all'uso in pochi giorni, non mesi. Forniamo soluzioni pratiche che creano un valore aggiunto immediato.
🔒 Massima sicurezza dei dati: i tuoi dati sensibili restano con te. Garantiamo un'elaborazione sicura e conforme alle normative, senza condividere i dati con terze parti.
💸 Nessun rischio finanziario: paghi solo per i risultati. Gli elevati investimenti iniziali in hardware, software o personale vengono completamente eliminati.
🎯 Concentrati sul tuo core business: concentrati su ciò che sai fare meglio. Ci occupiamo dell'intera implementazione tecnica, del funzionamento e della manutenzione della tua soluzione di intelligenza artificiale.
📈 A prova di futuro e scalabile: la tua IA cresce con te. Garantiamo ottimizzazione e scalabilità continue e adattiamo i modelli in modo flessibile alle nuove esigenze.
Maggiori informazioni qui:
Come l'intelligenza artificiale decentralizzata fa risparmiare miliardi di dollari alle aziende
I costi nascosti delle architetture centralizzate
Concentrarsi esclusivamente sui costi di elaborazione diretti sottostima il costo totale delle architetture LLM centralizzate. Le dipendenze dalle API creano svantaggi strutturali. Ogni richiesta genera costi che aumentano con l'utilizzo. Per le applicazioni di successo con milioni di utenti, le commissioni API diventano il fattore di costo dominante, erodendo i margini. Le aziende sono intrappolate in una struttura dei costi che cresce proporzionalmente al successo, senza corrispondenti economie di scala.
La volatilità dei prezzi dei fornitori di API rappresenta un rischio per l'azienda. Aumenti di prezzo, limitazioni di quota o modifiche ai termini di servizio possono distruggere la redditività di un'applicazione da un giorno all'altro. Le restrizioni di capacità recentemente annunciate dai principali fornitori, che costringono gli utenti a razionare le proprie risorse, illustrano la vulnerabilità di questa dipendenza. Gli SLM dedicati eliminano completamente questo rischio.
La sovranità e la conformità dei dati stanno acquisendo sempre più importanza. Il GDPR in Europa, normative analoghe a livello mondiale e i crescenti requisiti di localizzazione dei dati stanno creando quadri giuridici complessi. L'invio di dati aziendali sensibili ad API esterne che potrebbero operare in giurisdizioni straniere comporta rischi normativi e legali. I settori sanitario, finanziario e governativo hanno spesso requisiti rigorosi che escludono o limitano fortemente l'uso di API esterne. Gli SLM on-premise risolvono sostanzialmente questi problemi.
I problemi di proprietà intellettuale sono reali. Ogni richiesta inviata a un fornitore di API espone potenzialmente informazioni proprietarie. Logica aziendale, sviluppi di prodotto, informazioni sui clienti: tutto questo potrebbe teoricamente essere estratto e utilizzato dal fornitore. Le clausole contrattuali offrono una protezione limitata contro fughe di notizie accidentali o malintenzionati. L'unica soluzione veramente sicura è non esternalizzare mai i dati.
Latenza e affidabilità risentono delle dipendenze di rete. Ogni richiesta API cloud attraversa l'infrastruttura Internet, soggetta a jitter di rete, perdita di pacchetti e tempi di andata e ritorno variabili. Per applicazioni in tempo reale come l'intelligenza artificiale conversazionale o i sistemi di controllo, questi ritardi sono inaccettabili. Gli SLM locali rispondono in millisecondi anziché in secondi, indipendentemente dalle condizioni della rete. L'esperienza utente è notevolmente migliorata.
Affidarsi strategicamente a pochi hyperscaler concentra il potere e crea rischi sistemici. AWS, Microsoft Azure, Google Cloud e pochi altri dominano il mercato. Le interruzioni di questi servizi hanno effetti a cascata su migliaia di applicazioni dipendenti. L'illusione di ridondanza svanisce se si considera che la maggior parte dei servizi alternativi si basa in ultima analisi sullo stesso insieme limitato di fornitori modello. La vera resilienza richiede diversificazione, idealmente includendo capacità interna.
Correlato a questo:

L'edge computing come punto di svolta strategico
La convergenza tra SLM ed edge computing sta creando una dinamica trasformativa. L'implementazione edge porta l'elaborazione là dove i dati hanno origine: sensori IoT, dispositivi mobili, controller industriali e veicoli. La riduzione della latenza è drastica: da secondi a millisecondi, dal round-trip nel cloud all'elaborazione locale. Per i sistemi autonomi, la realtà aumentata, l'automazione industriale e i dispositivi medici, questo non è solo auspicabile, ma essenziale.
Il risparmio di larghezza di banda è sostanziale. Invece di flussi di dati continui verso il cloud, dove vengono elaborati e i risultati vengono inviati, l'elaborazione avviene localmente. Vengono trasmesse solo le informazioni rilevanti e aggregate. In scenari con migliaia di dispositivi edge, questo riduce il traffico di rete di ordini di grandezza. I costi infrastrutturali diminuiscono, si evita la congestione della rete e si aumenta l'affidabilità.
La privacy è intrinsecamente protetta. I dati non lasciano più il dispositivo. Feed delle telecamere, registrazioni audio, informazioni biometriche, dati sulla posizione: tutto questo può essere elaborato localmente senza raggiungere server centrali. Questo risolve i problemi fondamentali di privacy sollevati dalle soluzioni di intelligenza artificiale basate sul cloud. Per le applicazioni consumer, questo diventa un fattore di differenziazione; per i settori regolamentati, diventa un requisito.
L'efficienza energetica sta migliorando su più livelli. I chip AI edge specializzati, ottimizzati per l'inferenza di modelli di piccole dimensioni, consumano una frazione dell'energia delle GPU dei data center. L'eliminazione della trasmissione dati consente di risparmiare energia nell'infrastruttura di rete. Per i dispositivi alimentati a batteria, questa sta diventando una funzione fondamentale. Smartphone, dispositivi indossabili, droni e sensori IoT possono svolgere funzioni di intelligenza artificiale senza influire drasticamente sulla durata della batteria.
La funzionalità offline garantisce robustezza. L'intelligenza artificiale edge funziona anche senza connessione internet. La funzionalità è garantita anche in aree remote, infrastrutture critiche o scenari di emergenza. Questa indipendenza dalla disponibilità della rete è essenziale per molte applicazioni. Un veicolo autonomo non può fare affidamento sulla connettività cloud e un dispositivo medico non deve guastarsi a causa di una connessione Wi-Fi instabile.
I modelli di costo si stanno spostando dalle spese operative a quelle in conto capitale. Invece di costi cloud continui, si assiste a un investimento una tantum in hardware edge. Questo diventa economicamente interessante per applicazioni di lunga durata e ad alto volume. La prevedibilità dei costi migliora la pianificazione del budget e riduce i rischi finanziari. Le aziende riprendono il controllo sulla spesa per le infrastrutture di intelligenza artificiale.
Gli esempi ne dimostrano il potenziale. NVIDIA ChatRTX consente l'inferenza LLM locale sulle GPU consumer. Apple integra l'intelligenza artificiale on-device in iPhone e iPad, con modelli più piccoli che vengono eseguiti direttamente sul dispositivo. Qualcomm sta sviluppando NPU per smartphone specificamente per l'intelligenza artificiale edge. Google Coral e piattaforme simili si rivolgono all'IoT e alle applicazioni industriali. Le dinamiche di mercato mostrano una chiara tendenza verso la decentralizzazione.
Architetture di intelligenza artificiale eterogenee come modello futuro
Il futuro non risiede nella decentralizzazione assoluta, ma in architetture ibride intelligenti. I sistemi eterogenei combinano SLM edge per attività di routine sensibili alla latenza con LLM cloud per esigenze di ragionamento complesse. Questa complementarietà massimizza l'efficienza preservando flessibilità e capacità.
L'architettura del sistema comprende diversi livelli. A livello edge, SLM altamente ottimizzati forniscono risposte immediate. Si prevede che gestiscano autonomamente dal 60 all'80% delle richieste. Per query ambigue o complesse che non soddisfano le soglie di confidenza locali, si verifica un'escalation al livello di fog computing, ovvero server regionali con modelli di fascia media. Solo i casi veramente complessi raggiungono l'infrastruttura cloud centrale con modelli di grandi dimensioni e di uso generale.
Il routing basato sui modelli sta diventando una componente critica. I router basati sull'apprendimento automatico analizzano le caratteristiche della richiesta: lunghezza del testo, indicatori di complessità, segnali di dominio e cronologia dell'utente. In base a queste caratteristiche, la richiesta viene assegnata al modello appropriato. I router moderni raggiungono una precisione superiore al 95% nella stima della complessità. Ottimizzano costantemente in base alle prestazioni effettive e al compromesso tra costi e qualità.
I meccanismi di cross-attention nei sistemi di routing avanzati modellano esplicitamente le interazioni query-modello. Ciò consente decisioni più articolate: Mistral-7B è sufficiente o è necessario GPT-4? Phi-3 è in grado di gestirlo o è necessario Claude? La natura dettagliata di queste decisioni, moltiplicata su milioni di query, genera notevoli risparmi sui costi, mantenendo o migliorando al contempo la soddisfazione dell'utente.
La caratterizzazione del carico di lavoro è fondamentale. I sistemi di intelligenza artificiale agentica consistono in orchestrazione, ragionamento, chiamate di strumenti, operazioni di memoria e generazione di output. Non tutti i componenti richiedono la stessa capacità di calcolo. L'orchestrazione e le chiamate di strumenti sono spesso basate su regole o richiedono un'intelligenza minima, ideale per gli SLM. Il ragionamento può essere ibrido: semplice inferenza sugli SLM, ragionamento complesso a più fasi sugli LLM. La generazione di output per i template utilizza gli SLM, la generazione di testo creativo utilizza gli LLM.
L'ottimizzazione del costo totale di proprietà (TCO) tiene conto dell'eterogeneità dell'hardware. Le GPU H100 di fascia alta vengono utilizzate per i carichi di lavoro LLM critici, le GPU A100 o L40S di fascia media per i modelli di fascia media e i chip T4 o ottimizzati per l'inferenza più economici per gli SLM. Questa granularità consente di abbinare con precisione i requisiti del carico di lavoro alle capacità hardware. Studi iniziali mostrano una riduzione del TCO dal 40 al 60% rispetto a implementazioni omogenee di fascia alta.
L'orchestrazione richiede stack software sofisticati. I sistemi di gestione dei cluster basati su Kubernetes, integrati da scheduler specifici per l'intelligenza artificiale che comprendono le caratteristiche del modello, sono essenziali. Il bilanciamento del carico considera non solo le richieste al secondo, ma anche la lunghezza dei token, l'impronta di memoria del modello e gli obiettivi di latenza. L'autoscaling risponde ai modelli di domanda, fornendo capacità aggiuntiva o riducendola durante i periodi di basso utilizzo.
Sostenibilità ed efficienza energetica
L'impatto ambientale delle infrastrutture di intelligenza artificiale sta diventando una questione centrale. Addestrare un singolo modello linguistico di grandi dimensioni può consumare la stessa quantità di energia di una piccola città in un anno. Entro il 2028, i data center che gestiscono carichi di lavoro di intelligenza artificiale potrebbero rappresentare dal 20 al 27% della domanda energetica globale dei data center. Le proiezioni stimano che entro il 2030, i data center di intelligenza artificiale potrebbero richiedere 8 gigawatt per i singoli cicli di addestramento. L'impronta di carbonio sarà paragonabile a quella dell'industria aeronautica.
L'intensità energetica dei modelli di grandi dimensioni sta aumentando in modo sproporzionato. Il consumo energetico delle GPU è raddoppiato, passando da 400 a oltre 1000 watt in tre anni. I sistemi NVIDIA GB300 NVL72, nonostante l'innovativa tecnologia di livellamento della potenza che riduce il carico di picco del 30%, richiedono enormi quantità di energia. L'infrastruttura di raffreddamento aggiunge un ulteriore 30-40% al fabbisogno energetico. Le emissioni totali di CO2 derivanti dalle infrastrutture di intelligenza artificiale potrebbero aumentare di 220 milioni di tonnellate entro il 2030, anche con ipotesi ottimistiche sulla decarbonizzazione della rete.
I Small Language Model (SLM) offrono guadagni di efficienza fondamentali. L'addestramento richiede dal 30 al 40% della potenza di calcolo di LLM comparabili. L'addestramento di BERT costa circa 10.000 euro, rispetto alle centinaia di milioni dei modelli di classe GPT-4. L'energia di inferenza è proporzionalmente inferiore. Una query SLM può consumare da 100 a 1.000 volte meno energia di una query LLM. Su milioni di query, questo si traduce in enormi risparmi.
L'edge computing amplifica questi vantaggi. L'elaborazione locale elimina l'energia necessaria per la trasmissione dei dati attraverso le reti e l'infrastruttura backbone. I chip AI edge specializzati raggiungono fattori di efficienza energetica di ordini di grandezza migliori rispetto alle GPU dei data center. Smartphone e dispositivi IoT con NPU da milliwatt invece di server da centinaia di watt illustrano la differenza di scala.
L'uso di energie rinnovabili sta diventando una priorità. Google si è impegnata a raggiungere il 100% di energia carbon-free entro il 2030, mentre Microsoft si è impegnata a ridurre le emissioni di carbonio. Tuttavia, l'enorme portata della domanda energetica presenta delle sfide. Anche con le fonti rinnovabili, permane la questione della capacità della rete, dello stoccaggio e dell'intermittenza. Gli SLM riducono la domanda assoluta, rendendo più fattibile la transizione verso l'intelligenza artificiale verde.
Il calcolo carbon-aware ottimizza la pianificazione del carico di lavoro in base all'intensità di carbonio della rete. Le sessioni di training vengono avviate quando la quota di energia rinnovabile nella rete è al massimo. Le richieste di inferenza vengono indirizzate alle regioni con energia più pulita. Questa flessibilità temporale e geografica, unita all'efficienza degli SLM, potrebbe ridurre le emissioni di CO2 dal 50 al 70%.
Il panorama normativo sta diventando più stringente. La legge UE sull'intelligenza artificiale (IA) prevede valutazioni obbligatorie dell'impatto ambientale per alcuni sistemi di intelligenza artificiale. La rendicontazione delle emissioni di carbonio sta diventando uno standard. Le aziende con infrastrutture inefficienti e ad alto consumo energetico rischiano problemi di conformità e danni alla reputazione. L'adozione di SLM e edge computing si sta evolvendo da un optional a una necessità.
Democratizzazione contro concentrazione
Gli sviluppi passati hanno concentrato il potere dell'intelligenza artificiale nelle mani di pochi attori chiave. I Magnifici Sette – Microsoft, Google, Meta, Amazon, Apple, NVIDIA e Tesla – dominano. Questi hyperscaler controllano infrastrutture, modelli e, sempre più, l'intera catena del valore. La loro capitalizzazione di mercato combinata supera i 15.000 miliardi di dollari. Rappresentano quasi il 35% della capitalizzazione di mercato dell'indice S&P 500, un rischio di concentrazione di portata storica senza precedenti.
Questa concentrazione ha implicazioni sistemiche. Poche aziende stabiliscono standard, definiscono API e controllano gli accessi. I player più piccoli e i paesi in via di sviluppo diventano dipendenti. La sovranità digitale delle nazioni è messa a dura prova. Europa, Asia e America Latina stanno rispondendo con strategie nazionali di intelligenza artificiale, ma il predominio degli hyperscaler con sede negli Stati Uniti rimane schiacciante.
Gli Small Language Model (SLM) e la decentralizzazione stanno modificando questa dinamica. Gli SLM open source come Phi-3, Gemma, Mistral e Llama stanno democratizzando l'accesso a tecnologie all'avanguardia. Università, startup e medie imprese possono sviluppare applicazioni competitive senza dover ricorrere a risorse hyperscaler. La barriera all'innovazione si abbassa drasticamente. Un piccolo team può creare un SLM specializzato che supera Google o Microsoft nella sua nicchia.
La redditività economica si sta spostando a favore degli operatori più piccoli. Mentre lo sviluppo di LLM richiede budget nell'ordine di centinaia di milioni, gli SLM sono realizzabili con cifre a cinque o sei cifre. La democratizzazione del cloud consente l'accesso on-demand all'infrastruttura formativa. La messa a punto dei servizi elimina la complessità. La barriera all'ingresso per l'innovazione nell'intelligenza artificiale si sta riducendo da proibitiva a gestibile.
La sovranità dei dati diventa realtà. Aziende e governi possono ospitare modelli che non raggiungono mai server esterni. I dati sensibili rimangono sotto il loro controllo. La conformità al GDPR è semplificata. L'AI Act dell'UE, che impone rigorosi requisiti di trasparenza e responsabilità, diventa più gestibile con modelli proprietari anziché con API "black-box".
La diversità dell'innovazione è in aumento. Invece di una monocultura di modelli simili a GPT, stanno emergendo migliaia di SLM specializzati per domini, linguaggi e attività specifici. Questa diversità è resistente agli errori sistematici, aumenta la concorrenza e accelera il progresso. Il panorama dell'innovazione sta diventando policentrico anziché gerarchico.
I rischi della concentrazione stanno diventando evidenti. La dipendenza da pochi provider crea singoli punti di errore. Le interruzioni di AWS o Azure paralizzano i servizi globali. Le decisioni politiche di un hyperscaler, come restrizioni di utilizzo o blocchi regionali, hanno effetti a cascata. La decentralizzazione tramite SLM riduce sostanzialmente questi rischi sistemici.
Il riallineamento strategico
Per le aziende, questa analisi implica cambiamenti strategici fondamentali. Le priorità di investimento si stanno spostando da infrastrutture cloud centralizzate ad architetture eterogenee e distribuite. Invece di una dipendenza massima dalle API hyperscaler, l'obiettivo è l'autonomia attraverso SLM interni. Lo sviluppo delle competenze si concentra sulla messa a punto dei modelli, sull'implementazione edge e sull'orchestrazione ibrida.
La scelta tra costruire e acquistare sta cambiando. Mentre in precedenza l'acquisto dell'accesso alle API era considerato razionale, lo sviluppo interno di SLM specializzati sta diventando sempre più interessante. Il costo totale di proprietà nell'arco di tre-cinque anni favorisce chiaramente i modelli interni. Controllo strategico, sicurezza dei dati e adattabilità aggiungono ulteriori vantaggi qualitativi.
Per gli investitori, questa errata allocazione segnala cautela riguardo alle attività puramente infrastrutturali. I REIT dei data center, i produttori di GPU e gli hyperscaler potrebbero riscontrare una sovracapacità e un calo dell'utilizzo se la domanda non si materializzerà come previsto. Si sta verificando una migrazione di valore verso i fornitori di tecnologia SLM, chip di intelligenza artificiale edge, software di orchestrazione e applicazioni di intelligenza artificiale specializzate.
La dimensione geopolitica è significativa. I paesi che danno priorità alla sovranità nazionale dell'IA beneficiano del passaggio al modello SLM. La Cina sta investendo 138 miliardi di dollari in tecnologia nazionale e l'Europa 200 miliardi di dollari in InvestAI. Questi investimenti saranno più efficaci quando la scala assoluta non sarà più il fattore decisivo, ma piuttosto soluzioni intelligenti, efficienti e specializzate. Il mondo multipolare dell'IA sta diventando realtà.
Il quadro normativo si sta evolvendo parallelamente. Protezione dei dati, responsabilità algoritmica, standard ambientali: tutti questi fattori favoriscono sistemi decentralizzati, trasparenti ed efficienti. Le aziende che adottano tempestivamente SLM ed edge computing si posizionano favorevolmente per la conformità alle normative future.
Il panorama dei talenti si sta trasformando. Mentre in precedenza solo le università d'élite e le principali aziende tecnologiche disponevano delle risorse per la ricerca LLM, ora praticamente qualsiasi organizzazione può sviluppare SLM. La carenza di competenze che impedisce all'87% delle organizzazioni di assumere personale di IA viene mitigata da una minore complessità e da strumenti migliori. I guadagni di produttività derivanti dallo sviluppo supportato dall'IA amplificano questo effetto.
Il modo in cui misuriamo il ROI degli investimenti in intelligenza artificiale sta cambiando. Invece di concentrarsi sulla pura capacità di calcolo, l'efficienza per attività sta diventando la metrica fondamentale. Le aziende segnalano un ROI medio del 5,9% sulle iniziative di intelligenza artificiale, significativamente al di sotto delle aspettative. Il motivo risiede spesso nell'utilizzo di soluzioni sovradimensionate e costose per problemi semplici. Il passaggio a SLM ottimizzati per attività può migliorare notevolmente questo ROI.
L'analisi rivela un settore a un punto di svolta. L'investimento errato di 57 miliardi di dollari è più di una semplice sovrastima della domanda. Rappresenta un errore di calcolo strategico fondamentale sull'architettura dell'intelligenza artificiale. Il futuro non appartiene ai giganti centralizzati, ma a sistemi decentralizzati, specializzati ed efficienti. I modelli linguistici di piccole dimensioni non sono inferiori ai modelli linguistici di grandi dimensioni: sono superiori per la stragrande maggioranza delle applicazioni del mondo reale. Le argomentazioni economiche, tecniche, ambientali e strategiche convergono verso una conclusione chiara: la rivoluzione dell'intelligenza artificiale sarà decentralizzata.
Il passaggio di potere dai fornitori agli operatori, dagli hyperscaler agli sviluppatori di applicazioni, dalla centralizzazione alla distribuzione segna una nuova fase nell'evoluzione dell'IA. Chi riconoscerà e accoglierà questa transizione per tempo sarà il vincitore. Chi si aggrappa alla vecchia logica rischia che le proprie costose infrastrutture diventino risorse inutilizzate, superate da alternative più agili ed efficienti. I 57 miliardi di dollari non sono solo sprecati, ma segnano l'inizio della fine di un paradigma già obsoleto.
Il tuo partner globale per il marketing e lo sviluppo aziendale
☑️ La nostra lingua aziendale è l'inglese o il tedesco
☑️ NOVITÀ: Corrispondenza nella tua lingua madre!

Konrad Wolfenstein
Io e il mio team saremo lieti di essere a tua disposizione come tuo consulente personale.
Puoi contattarmi compilando il modulo di contatto qui wolfenstein@xpert.digital:o semplicemente chiamandomi al numero +49 7348 4088 965. Il mio indirizzo email è
Non vedo l'ora di iniziare il nostro progetto comune.
☑️ Supporto alle PMI in strategia, consulenza, pianificazione e implementazione
☑️ Creazione o riallineamento della strategia digitale e digitalizzazione
☑️ Espansione e ottimizzazione dei processi di vendita internazionali
☑️ Piattaforme di trading B2B globali e digitali
☑️ Sviluppo aziendale pionieristico / Marketing / PR / Fiere
🎯🎯🎯 Approfitta della vasta competenza di Xpert.Digital, articolata in cinque parti, in un unico pacchetto di servizi completo | BD, R&D, XR, PR e ottimizzazione della visibilità digitale

Approfitta dell'ampia e quintuplicata competenza di Xpert.Digital in un pacchetto di servizi completo | Ottimizzazione di R&S, XR, PR e visibilità digitale - Immagine: Xpert.Digital
Xpert.Digital vanta una conoscenza approfondita di diversi settori. Questo ci consente di sviluppare strategie su misura, perfettamente in linea con le esigenze e le sfide del vostro specifico segmento di mercato. Analizzando costantemente le tendenze del mercato e monitorando gli sviluppi del settore, possiamo agire in modo proattivo e offrire soluzioni innovative. La combinazione di esperienza e competenza genera valore aggiunto e offre ai nostri clienti un decisivo vantaggio competitivo.
Maggiori informazioni qui: