


AI e SEO con BERT – Rappresentazioni di codificatori bidirezionali da trasformatori – Modello nel campo dell’elaborazione del linguaggio naturale (NLP) – Immagine: Xpert.Digital
🚀💬 Sviluppato da Google: BERT e la sua importanza per la PNL - Perché la comprensione bidirezionale del testo è fondamentale
🔍🗣️ BERT, acronimo di Bidirectional Encoder Representations from Transformers, è un modello significativo nel campo dell'elaborazione del linguaggio naturale (NLP) sviluppato da Google. Ha rivoluzionato il modo in cui le macchine comprendono il linguaggio. A differenza dei modelli precedenti che analizzavano il testo in sequenza da sinistra a destra o viceversa, BERT consente l'elaborazione bidirezionale. Ciò significa che coglie il contesto di una parola sia dalla sequenza di testo precedente che da quella successiva. Questa capacità migliora significativamente la comprensione di relazioni linguistiche complesse.
🔍 L'architettura di BERT
Negli ultimi anni, uno degli sviluppi più significativi nell'elaborazione del linguaggio naturale (NLP) si è verificato con l'introduzione del modello Transformer, come descritto nel documento PDF del 2017 "Attention is all you need" (Wikipedia). Questo modello ha cambiato radicalmente il settore, abbandonando le strutture precedentemente utilizzate, come la traduzione automatica. Si basa invece esclusivamente sui meccanismi di attenzione. Il design del Transformer ha da allora costituito la base per molti modelli che rappresentano lo stato dell'arte in vari campi, tra cui la generazione del parlato, la traduzione e altro ancora.
Un'illustrazione dei componenti principali del modello Transformer - Immagine: Google
BERT si basa su questa architettura di trasformazione. Questa architettura utilizza i cosiddetti meccanismi di auto-attenzione per analizzare le relazioni tra le parole in una frase. A ogni parola viene data attenzione nel contesto dell'intera frase, portando a una comprensione più precisa delle relazioni sintattiche e semantiche.
Gli autori dell'articolo "L'attenzione è tutto ciò di cui hai bisogno" sono:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (ricerca Google)
- Jakob Uszkoreit (Ricerca Google)
- Lion Jones (ricerca Google)
- Aidan N. Gomez (Università di Toronto, lavoro svolto in parte presso Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (Indipendente, precedente lavoro presso Google Research)
Questi autori hanno dato un contributo significativo allo sviluppo del modello Transformer presentato in questo articolo.
🔄 Elaborazione bidirezionale
Una caratteristica fondamentale di BERT è la sua capacità di elaborare il testo in modo bidirezionale. Mentre i modelli tradizionali come le reti neurali ricorrenti (RNN) o le reti a memoria a lungo e breve termine (LSTM) elaborano il testo in una sola direzione, BERT analizza il contesto di una parola in entrambe le direzioni. Questo permette al modello di catturare meglio le sottili sfumature di significato e quindi di formulare previsioni più accurate.
🕵️♂️ Modellazione del discorso mascherato
Un altro aspetto innovativo di BERT è la tecnica del Masked Language Model (MLM). In questo caso, parole selezionate casualmente in una frase vengono mascherate e il modello viene addestrato a predirle in base al contesto circostante. Questo metodo costringe BERT a sviluppare una comprensione approfondita del contesto e del significato di ogni parola nella frase.
🚀 Formazione e adattamento del BERT
BERT è sottoposto a un processo di formazione in due fasi: pre-formazione e messa a punto.
📚 Pre-allenamento
Nella fase di pre-addestramento, BERT viene addestrato con grandi quantità di testo per apprendere modelli linguistici generali. Questo include articoli di Wikipedia e altri corpora testuali estesi. Durante questa fase, il modello apprende strutture e contesti linguistici di base.
🔧 Messa a punto
Dopo il pre-addestramento, BERT viene adattato per specifiche attività di NLP, come la classificazione del testo o l'analisi del sentiment. Il modello viene addestrato con set di dati più piccoli, correlati all'attività, per ottimizzarne le prestazioni per applicazioni specifiche.
🌍 Aree di applicazione di BERT
BERT si è dimostrato estremamente utile in numerosi ambiti dell'elaborazione del linguaggio naturale:
Ottimizzazione dei motori di ricerca
Google utilizza BERT per comprendere meglio le query di ricerca e visualizzare risultati più pertinenti. Questo migliora significativamente l'esperienza utente.
Classificazione del testo
BERT può categorizzare i documenti in base all'argomento o analizzare il tono dei testi.
Riconoscimento di entità nominate (NER)
Il modello identifica e classifica entità denominate nei testi, come nomi di persone, luoghi o organizzazioni.
Sistemi domanda-risposta
BERT viene utilizzato per fornire risposte precise alle domande poste.
🧠 L'importanza di BERT per il futuro dell'IA
BERT ha stabilito nuovi standard per i modelli di NLP e ha aperto la strada a ulteriori innovazioni. Grazie alla sua capacità di elaborazione bidirezionale e alla sua profonda comprensione dei contesti linguistici, ha aumentato significativamente l'efficienza e l'accuratezza delle applicazioni di intelligenza artificiale.
🔜 Sviluppi futuri
Si prevede che l'ulteriore sviluppo di BERT e di modelli simili mirerà alla creazione di sistemi ancora più potenti. Questi potrebbero gestire compiti linguistici più complessi ed essere utilizzati in un'ampia varietà di nuove aree applicative. L'integrazione di tali modelli nelle tecnologie di uso quotidiano potrebbe cambiare radicalmente il nostro modo di interagire con i computer.
🌟 Pietra miliare nello sviluppo dell'intelligenza artificiale
BERT rappresenta una pietra miliare nello sviluppo dell'intelligenza artificiale e ha rivoluzionato il modo in cui le macchine elaborano il linguaggio naturale. La sua architettura bidirezionale consente una comprensione più approfondita delle relazioni linguistiche, rendendolo indispensabile per un'ampia gamma di applicazioni. Con il progredire della ricerca, modelli come BERT continueranno a svolgere un ruolo centrale nel miglioramento dei sistemi di intelligenza artificiale e nell'apertura di nuove possibilità per il loro utilizzo.
📣 Argomenti simili
- 📚 Introduzione a BERT: il modello rivoluzionario della PNL
- 🔍 BERT e il ruolo della bidirezionalità nella PNL
- 🧠 Il modello Transformer: fondamento di BERT
- 🚀 Modellazione del linguaggio mascherato: la chiave del successo di BERT
- 📈 Personalizzazione di BERT: dalla pre-formazione alla messa a punto
- 🌐 Gli ambiti di applicazione di BERT nella tecnologia moderna
- 🤖 L'influenza di BERT sul futuro dell'intelligenza artificiale
- 💡 Prospettive future: ulteriori sviluppi di BERT
- 🏆 BERT come pietra miliare nello sviluppo dell'intelligenza artificiale
- 📰 Autori del documento Transformer "L'attenzione è tutto ciò di cui hai bisogno": le menti dietro BERT
#️⃣ Hashtag: #NLP #IntelligenzaArtificiale #ModellazioneLinguistica #Trasformatore #ApprendimentoAutomatico
🎯🎯🎯 Approfitta della vasta competenza di Xpert.Digital, articolata in cinque parti, in un unico pacchetto di servizi completo | BD, R&D, XR, PR e ottimizzazione della visibilità digitale


Approfitta dell'ampia e quintuplicata competenza di Xpert.Digital in un pacchetto di servizi completo | Ottimizzazione di R&S, XR, PR e visibilità digitale - Immagine: Xpert.Digital
Xpert.Digital vanta una conoscenza approfondita di diversi settori. Questo ci consente di sviluppare strategie su misura, perfettamente in linea con le esigenze e le sfide del vostro specifico segmento di mercato. Analizzando costantemente le tendenze del mercato e monitorando gli sviluppi del settore, possiamo agire in modo proattivo e offrire soluzioni innovative. La combinazione di esperienza e competenza genera valore aggiunto e offre ai nostri clienti un decisivo vantaggio competitivo.
Maggiori informazioni qui:
BERT: Tecnologia rivoluzionaria 🌟 NLP
🚀 BERT, acronimo di Bidirectional Encoder Representations from Transformers, è un modello linguistico avanzato sviluppato da Google che ha rappresentato una svolta significativa nell'elaborazione del linguaggio naturale (NLP) sin dalla sua introduzione nel 2018. Si basa sull'architettura Transformer, che ha rivoluzionato il modo in cui le macchine comprendono ed elaborano il testo. Ma cosa rende BERT così speciale e a cosa serve? Per rispondere a questa domanda, dobbiamo esaminare più da vicino i fondamenti tecnici di BERT, il suo funzionamento e le sue applicazioni.
📚 1. Le basi dell'elaborazione del linguaggio naturale
Per comprendere appieno il significato di BERT, è utile ripassare brevemente i fondamenti dell'elaborazione del linguaggio naturale (NLP). L'NLP si occupa dell'interazione tra computer e linguaggio umano. Il suo obiettivo è insegnare alle macchine ad analizzare, comprendere e rispondere ai dati testuali. Prima dell'introduzione di modelli come BERT, l'elaborazione del linguaggio macchina presentava spesso notevoli difficoltà, in particolare a causa dell'ambiguità, della dipendenza dal contesto e della complessa struttura del linguaggio umano.
📈 2. Lo sviluppo dei modelli NLP
Prima dell'avvento di BERT, la maggior parte dei modelli di NLP si basava sulle cosiddette architetture unidirezionali. Ciò significava che questi modelli leggevano il testo da sinistra a destra o da destra a sinistra, il che significava che potevano considerare solo una quantità limitata di contesto durante l'elaborazione di una parola in una frase. Questa limitazione spesso faceva sì che i modelli non riuscissero a catturare completamente il contesto semantico di una frase. Ciò rendeva difficile l'interpretazione accurata di parole ambigue o sensibili al contesto.
Un altro importante sviluppo nella ricerca sulla PNL prima del BERT fu il modello word2vec, che consentiva ai computer di tradurre le parole in vettori che riflettevano le somiglianze semantiche. Tuttavia, anche in questo caso, il contesto era limitato all'ambiente immediatamente circostante di una parola. Successivamente, furono sviluppate le Reti Neurali Ricorrenti (RNN) e, in particolare, i modelli di Memoria a Lungo e Breve Termine (LSTM), che consentirono di comprendere meglio le sequenze di testo memorizzando informazioni su più parole. Tuttavia, questi modelli presentavano anche dei limiti, soprattutto quando si trattava di testi lunghi e si comprendeva simultaneamente il contesto in entrambe le direzioni.
🔄 3. La rivoluzione attraverso l'architettura del trasformatore
La svolta è arrivata con l'introduzione dell'architettura Transformer nel 2017, che costituisce la base di BERT. I modelli Transformer sono progettati per consentire l'elaborazione parallela del testo, tenendo conto del contesto di una parola sia nel testo precedente che in quello successivo. Ciò si ottiene attraverso i cosiddetti meccanismi di auto-attenzione, che assegnano un valore di peso a ciascuna parola in una frase in base alla sua importanza rispetto alle altre parole della frase.
A differenza degli approcci precedenti, i modelli a trasformatore non sono unidirezionali, ma bidirezionali. Ciò significa che possono ricavare informazioni sia dal contesto sinistro che da quello destro di una parola per creare una rappresentazione più completa e accurata della parola e del suo significato.
🧠 4. BERT: un modello bidirezionale
BERT porta le prestazioni dell'architettura Transformer a un nuovo livello. Il modello è progettato per catturare il contesto di una parola non solo da sinistra a destra o da destra a sinistra, ma in entrambe le direzioni simultaneamente. Ciò consente a BERT di considerare il contesto completo di una parola all'interno di una frase, con conseguente miglioramento significativo dell'accuratezza nelle attività di elaborazione del linguaggio naturale.
Una caratteristica fondamentale di BERT è l'utilizzo del cosiddetto Masked Language Model (MLM). Durante l'addestramento di BERT, parole selezionate casualmente in una frase vengono sostituite da una maschera e il modello viene addestrato a indovinare queste parole mascherate in base al contesto. Questa tecnica consente a BERT di apprendere relazioni più profonde e precise tra le parole di una frase.
Inoltre, BERT utilizza un metodo chiamato Next Sentence Prediction (NSP), in cui il modello impara a prevedere se una frase segue un'altra. Questo migliora la capacità di BERT di comprendere testi più lunghi e di riconoscere relazioni più complesse tra le frasi.
🌐 5. Applicazione pratica di BERT
BERT si è dimostrato estremamente utile per un'ampia gamma di attività di PNL. Ecco alcuni dei più importanti ambiti di applicazione:
📊 a) Classificazione del testo
Una delle applicazioni più comuni di BERT è la classificazione dei testi, in cui i testi vengono suddivisi in categorie predefinite. Alcuni esempi includono l'analisi del sentiment (ad esempio, per riconoscere se un testo è positivo o negativo) o la categorizzazione del feedback dei clienti. Grazie alla sua profonda comprensione del contesto delle parole, BERT può fornire risultati più precisi rispetto ai modelli precedenti.
❓ b) Sistemi domanda-risposta
BERT viene utilizzato anche nei sistemi di domanda-risposta, dove il modello estrae le risposte a domande poste da un testo. Questa capacità è particolarmente importante in applicazioni come motori di ricerca, chatbot e assistenti virtuali. Grazie alla sua architettura bidirezionale, BERT può estrarre informazioni rilevanti da un testo anche se la domanda è formulata indirettamente.
🌍 c) Traduzione del testo
Sebbene BERT in sé non sia progettato direttamente come modello di traduzione, può essere utilizzato in combinazione con altre tecnologie per migliorare la traduzione automatica. Comprendendo meglio le relazioni semantiche all'interno di una frase, BERT può contribuire a generare traduzioni più accurate, soprattutto in caso di formulazioni ambigue o complesse.
🏷️ d) Riconoscimento di entità nominate (NER)
Un altro ambito applicativo è il riconoscimento di entità denominate (NER), che prevede l'identificazione di entità specifiche come nomi, luoghi o organizzazioni all'interno di un testo. BERT si è dimostrato particolarmente efficace in questo ambito perché considera attentamente il contesto di una frase e può quindi riconoscere meglio le entità, anche se hanno significati diversi in contesti diversi.
✂️ e) Riepilogo del testo
La capacità di BERT di comprendere l'intero contesto di un testo lo rende anche un potente strumento per la sintesi automatica. Può essere utilizzato per estrarre le informazioni più importanti da un testo lungo e creare un riassunto conciso.
🌟 6. L'importanza del BERT per la ricerca e l'industria
L'introduzione di BERT ha inaugurato una nuova era nella ricerca NLP. È stato uno dei primi modelli a sfruttare appieno la potenza dell'architettura del trasformatore bidirezionale, definendo lo standard per molti modelli successivi. Numerose aziende e istituti di ricerca hanno integrato BERT nelle loro pipeline NLP per migliorare le prestazioni delle loro applicazioni.
Inoltre, BERT ha aperto la strada a ulteriori innovazioni nel campo dei modelli linguistici. Ad esempio, sono stati successivamente sviluppati modelli come GPT (Generative Pretrained Transformer) e T5 (Text-to-Text Transfer Transformer), basati su principi simili ma che offrono miglioramenti specifici per diversi casi d'uso.
🚧 7. Sfide e limiti di BERT
Nonostante i suoi numerosi vantaggi, BERT presenta anche alcune sfide e limitazioni. Uno dei maggiori ostacoli è l'elevato sforzo computazionale richiesto per l'addestramento e l'applicazione del modello. Poiché BERT è un modello molto ampio con milioni di parametri, richiede hardware potente e risorse di calcolo significative, soprattutto quando si elaborano grandi set di dati.
Un altro problema è il potenziale bias che può essere presente nei dati di training. Poiché BERT viene addestrato su grandi quantità di dati testuali, a volte riflette i pregiudizi e gli stereotipi presenti in tali dati. Tuttavia, i ricercatori lavorano costantemente per identificare e affrontare questi problemi.
🔍 Uno strumento indispensabile per le moderne applicazioni di elaborazione vocale
BERT ha migliorato significativamente il modo in cui le macchine comprendono il linguaggio umano. Grazie alla sua architettura bidirezionale e ai metodi di addestramento innovativi, è in grado di cogliere il contesto delle parole all'interno di una frase in modo approfondito e accurato, garantendo una maggiore precisione in molti compiti di NLP. Che si tratti di classificazione di testi, sistemi di domande e risposte o riconoscimento di entità, BERT si è affermato come uno strumento indispensabile per le moderne applicazioni di elaborazione del linguaggio naturale.
La ricerca nel campo dell'elaborazione del linguaggio naturale continuerà senza dubbio a progredire e BERT ha gettato le basi per numerose innovazioni future. Nonostante le sfide e i limiti attuali, BERT dimostra in modo impressionante quanta strada abbia fatto la tecnologia in così poco tempo e quali entusiasmanti opportunità si apriranno ancora in futuro.
🌀 The Transformer: una rivoluzione nell'elaborazione del linguaggio naturale
🌟 Negli ultimi anni, uno degli sviluppi più significativi nell'elaborazione del linguaggio naturale (NLP) è stata l'introduzione del modello Transformer, descritto nell'articolo del 2017 "Attention Is All You Need". Questo modello ha rivoluzionato il settore, abbandonando le strutture ricorrenti o convoluzionali precedentemente utilizzate per compiti di trasduzione di sequenze, come la traduzione automatica. Si basa invece esclusivamente su meccanismi attentivi. Da allora, il modello Transformer ha costituito la base per molti modelli che rappresentano lo stato dell'arte in vari campi, tra cui la generazione del parlato, la traduzione e oltre.
🔄 The Transformer: un cambio di paradigma
Prima dell'introduzione del Transformer, la maggior parte dei modelli per compiti sequenziali si basava su reti neurali ricorrenti (RNN) o reti a memoria a lungo e breve termine (LSTM), che operano intrinsecamente in modo sequenziale. Questi modelli elaborano i dati di input passo dopo passo, creando stati nascosti che vengono propagati lungo la sequenza. Sebbene questo metodo sia efficace, è computazionalmente costoso e difficile da parallelizzare, soprattutto per sequenze lunghe. Inoltre, le RNN hanno difficoltà ad apprendere dipendenze a lungo termine a causa del problema del gradiente nullo.
L'innovazione chiave del Transformer risiede nell'utilizzo di meccanismi di auto-attenzione, che consentono al modello di valutare l'importanza di diverse parole in una frase l'una rispetto all'altra, indipendentemente dalla loro posizione. Ciò consente al modello di catturare le relazioni tra parole molto distanti in modo più efficace rispetto alle reti neurali ripetute (RNN) o alle reti di traduzione automatica (LSTM), e di farlo in parallelo anziché in sequenza. Ciò non solo migliora l'efficienza dell'addestramento, ma anche le prestazioni in attività come la traduzione automatica.
🧩 Architettura del modello
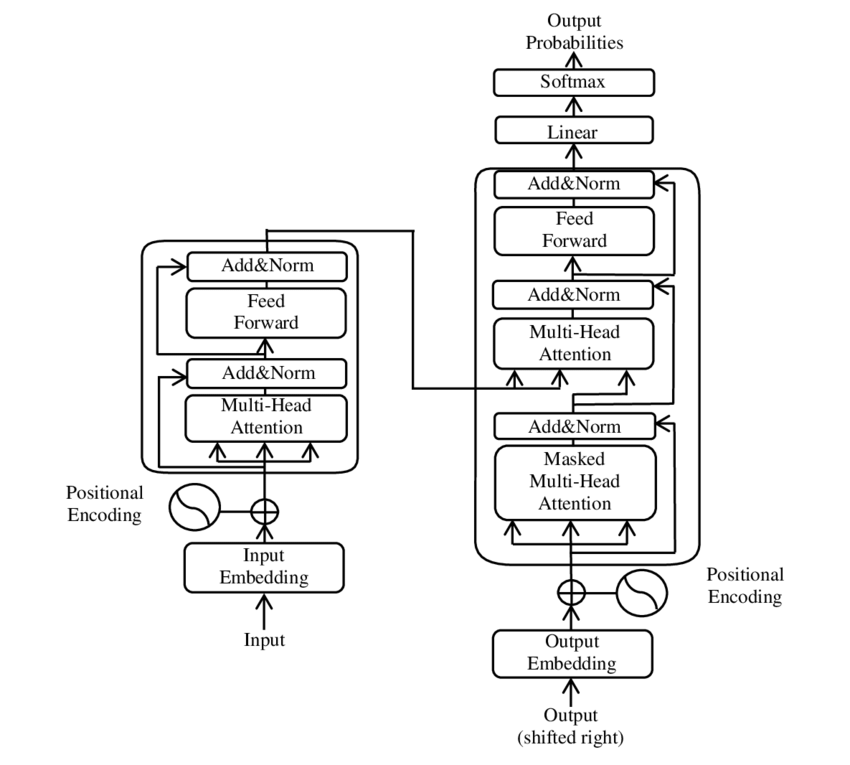
Il trasformatore è costituito da due componenti principali: un codificatore e un decodificatore, entrambi costituiti da più strati e basati in larga misura su meccanismi di attenzione multi-testa.
⚙️ Codificatore
Il codificatore è costituito da sei livelli identici, ciascuno con due sottolivelli:
1. Auto-attenzione multi-testa
Questo meccanismo consente al modello di concentrarsi su diverse parti della frase di input durante l'elaborazione di ogni parola. Invece di calcolare l'attenzione in un singolo spazio, l'attenzione multi-testa proietta l'input in diversi spazi, catturando così vari tipi di relazioni tra le parole.
2. Reti feedforward completamente connesse in modo posizionale
Dopo il livello di attenzione, una rete feedforward completamente connessa viene applicata in modo indipendente in ogni posizione. Questo aiuta il modello a elaborare ogni parola nel contesto e a utilizzare le informazioni provenienti dal meccanismo di attenzione.
Per preservare la struttura della sequenza di input, il modello include anche codifiche posizionali. Poiché il trasformatore non elabora le parole in sequenza, queste codifiche sono cruciali per fornire al modello informazioni sull'ordine delle parole in una frase. Le codifiche posizionali vengono aggiunte ai word embedding in modo che il modello possa distinguere le diverse posizioni nella sequenza.
🔍 Decodificatore
Come il codificatore, anche il decodificatore è costituito da sei livelli, ciascuno dotato di un meccanismo di attenzione aggiuntivo che consente al modello di concentrarsi sulle parti rilevanti della sequenza di input durante la generazione dell'output. Il decodificatore utilizza anche una tecnica di mascheramento per impedire di considerare posizioni future, preservando così la natura autoregressiva della generazione della sequenza.
🧠 Attenzione multi-testa e attenzione al prodotto scalare
Il cuore del Transformer è il meccanismo di attenzione multi-testa, che è un'estensione del più semplice prodotto scalare dell'attenzione. La funzione di attenzione può essere vista come una mappatura tra una query e un insieme di coppie chiave-valore, dove ogni chiave rappresenta una parola nella sequenza e il valore rappresenta le informazioni contestuali corrispondenti.
Il meccanismo di attenzione multi-testa consente al modello di concentrarsi simultaneamente su diverse parti della sequenza. Proiettando l'input in più sottospazi, il modello può catturare un insieme più ricco di relazioni tra le parole. Ciò è particolarmente utile per attività come la traduzione automatica, in cui la comprensione del contesto di una parola richiede molti fattori diversi, come la struttura sintattica e il significato semantico.
La formula per l'attenzione del prodotto scalare è:
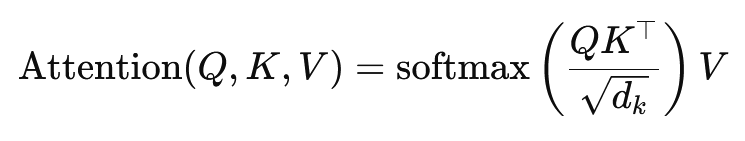
Qui, (Q) è la matrice di query, (K) la matrice delle chiavi e (V) la matrice dei valori. Il termine (sqrt{d_k}) è un fattore di scala che impedisce che i prodotti scalari diventino troppo grandi, il che porterebbe a gradienti molto piccoli e a un apprendimento più lento. La funzione softmax viene applicata per garantire che la somma dei pesi di attenzione sia pari a uno.
🚀 Vantaggi del trasformatore
Il trasformatore offre diversi vantaggi cruciali rispetto ai modelli tradizionali come RNN e LSTM:
1. Parallelizzazione
Poiché il trasformatore elabora simultaneamente tutti i token di una sequenza, può essere altamente parallelizzato ed è quindi molto più veloce da addestrare rispetto alle RNN o alle LSTM, soprattutto con set di dati di grandi dimensioni.
2. Dipendenze a lungo termine
Il meccanismo di auto-attenzione consente al modello di catturare le relazioni tra parole distanti in modo più efficace rispetto alle reti neurali ripetute (RNN), che sono limitate dalla natura sequenziale dei loro calcoli.
3. Scalabilità
Il trasformatore può essere facilmente adattato a set di dati molto grandi e sequenze più lunghe senza subire i colli di bottiglia nelle prestazioni associati alle reti neurali reattive (RNN).
🌍 Applicazioni ed effetti
Fin dalla sua introduzione, Transformer è diventato la base per un'ampia gamma di modelli di NLP. Uno degli esempi più significativi è BERT (Bidirectional Encoder Representations from Transformers), che utilizza un'architettura Transformer modificata per raggiungere prestazioni all'avanguardia in molte attività di NLP, tra cui il question answering e la classificazione del testo.
Un altro sviluppo significativo è GPT (Generative Pretrained Transformer), che utilizza una versione del trasformatore limitata al decoder per la generazione di testo. I modelli GPT, incluso GPT-3, sono ora utilizzati per numerose applicazioni, dalla creazione di contenuti al completamento del codice.
🔍 Un modello potente e flessibile
Transformer ha cambiato radicalmente il nostro approccio alle attività di PNL. Offre un modello potente e flessibile che può essere applicato a un'ampia varietà di problemi. La sua capacità di gestire dipendenze a lungo termine e la sua efficienza nell'addestramento lo hanno reso l'approccio architetturale preferito per molti dei modelli più moderni. Con il progredire della ricerca, probabilmente assisteremo a ulteriori miglioramenti e adattamenti di Transformer, in particolare in aree come l'elaborazione di immagini e parlato, dove i meccanismi attentivi mostrano risultati promettenti.
Siamo qui per te - Consulenza - Pianificazione - Implementazione - Gestione Progetti
☑️ Esperto del settore, qui con il suo hub di settore Xpert.Digital con oltre 2.500 articoli specialistici

Konrad Wolfenstein
Sarei felice di fungere da tuo consulente personale.
Puoi contattarmi compilando il modulo di contatto qui sotto oppure chiamandomi al numero +49 7348 4088 965 .
Non vedo l'ora di iniziare il nostro progetto comune.
Scrivimi




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital è un hub per l'industria focalizzato sulla digitalizzazione, l'ingegneria meccanica, la logistica/intralogistica e il fotovoltaico.
Con la nostra soluzione di sviluppo aziendale a 360° supportiamo aziende rinomate dalla fase di avvio del nuovo business fino al post-vendita.
Market intelligence, smarketing, marketing automation, sviluppo di contenuti, PR, campagne email, social media personalizzati e lead nurturing sono parte dei nostri strumenti digitali.
Per maggiori informazioni visita: www.xpert.digital - www.xpert.solar - www.xpert.plus
Rimaniamo in contatto











