
Dati strutturati (markup) nell'era dell'IA con Schema.org: cosa ne pensano davvero gli ingegneri di Google
Pre-release di Xpert

Available in 27 languages 📢
Preferisco Xpert.Digital su GoogleⓘPubblicato il: 7 maggio 2026 / Aggiornato il: 7 maggio 2026 – Autore: Konrad Wolfenstein
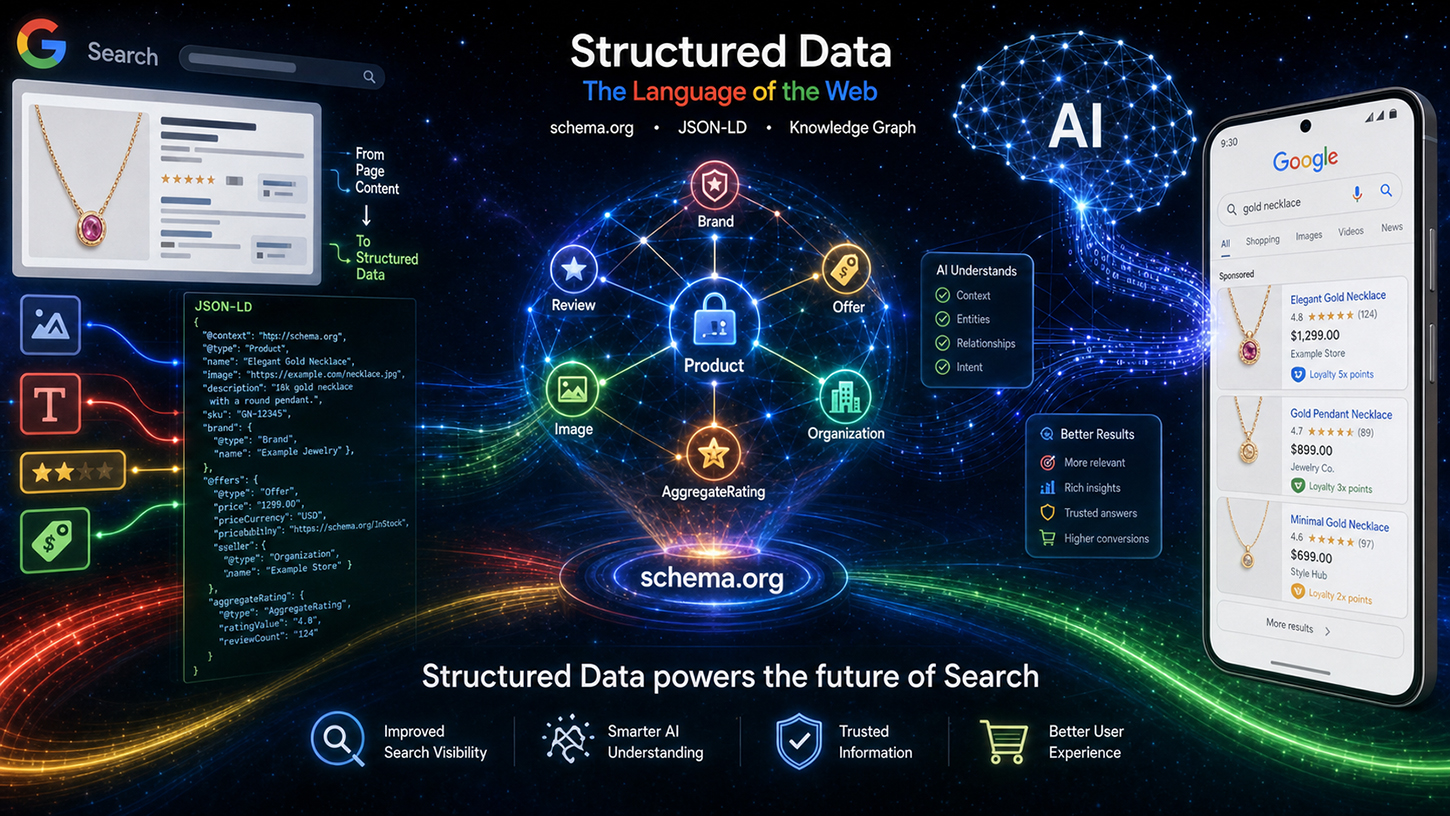
Dati strutturati (markup) nell'era dell'IA con Schema.org: cosa ne pensano davvero gli ingegneri di Google – Immagine: Xpert.Digital
Il segreto SEO di Google: perché l'IA fallisce senza dati strutturati
Nonostante ChatGPT e simili: perché gli ingegneri di Google continuano a giurare fedeltà a Schema.org
Aggiornamento SEO: perché Schema.org sta soppiantando Open Graph su Google
Nel mondo della SEO circola un mito persistente: nell'era dei brillanti modelli linguistici basati sull'intelligenza artificiale, capaci di comprendere senza sforzo anche testi non strutturati, i dati strutturati, meticolosamente gestiti come Schema.org, sono semplicemente diventati obsoleti. Ma la realtà è ben diversa. All'evento Google Search Central Live, l'ingegnere di Google Ryan Levering ha sfatato questo equivoco, chiarendo inequivocabilmente che il markup strutturato non è una reliquia del passato, bensì la spina dorsale fondamentale della nuova ricerca basata sull'intelligenza artificiale.
Dalle nuove panoramiche basate sull'intelligenza artificiale agli agenti di shopping autonomi, i modelli linguistici necessitano di linee guida precise e leggibili dalle macchine per evitare allucinazioni e operare in modo computazionalmente efficiente. Chi desidera rimanere visibile sul web moderno deve aiutare le macchine a comprendere il contesto senza ambiguità. Questo articolo esamina il riallineamento strategico di Google, presenta innovazioni rivoluzionarie per l'e-commerce e i contenuti generati dagli utenti e mostra perché la SEO tecnica è ormai il vantaggio competitivo decisivo nella battaglia per la visibilità delle macchine.
Le macchine possono leggere il web, ma solo se le aiutiamo a comprenderlo
Il 21 aprile 2026 si è tenuto a Toronto il primo evento Google Search Central Live in Canada, e non si è trattato di un normale incontro di settore. Ryan Levering, ingegnere del team Google Search Engineering, ha tenuto quella che è stata probabilmente la presentazione più densa di informazioni tecniche e strategicamente significativa della giornata: "Dati strutturati, qualità e intelligenza artificiale". La sua presentazione è stata molto più di una semplice analisi tecnica. Si è trattato di una chiara dichiarazione sul futuro del web semantico in un'era in cui l'intelligenza artificiale sta assumendo un ruolo sempre più importante di intermediario tra utenti e informazioni.
Tra due estremi: l'aut aut sbagliato
All'inizio della sua presentazione, Ryan Levering ha messo a confronto due opinioni diametralmente opposte che circolano nella comunità SEO. Da un lato, c'è la convinzione che i dati strutturati siano semplicemente superflui nell'era dei potenti modelli linguistici: se i modelli di intelligenza artificiale possono facilmente interpretare il testo non strutturato, perché preoccuparsi di aggiungere faticosamente il markup schema.org al codice sorgente? Dall'altro lato, alcuni entusiasti sostengono che i dati strutturati siano il futuro di Internet: un protocollo di comunicazione semantica universale tra agenti di intelligenza artificiale autonomi che sostituirà in gran parte il web tradizionale.
Levering respinse entrambi gli estremi, proponendo invece una prospettiva più sfumata e basata su dati empirici. Entrambe le posizioni, concluse, contenevano un fondo di verità, ma nessuna delle due descriveva appieno la realtà. Questa sfumatura è caratteristica dell'attuale approccio di Google all'argomento: non si tratta di dogmatismo, bensì di efficienza pragmatica.
Quattro argomenti che spiegano tutto
L'argomentazione centrale di Levering può essere riassunta in quattro punti chiave, che ha approfondito nella sezione intitolata "Il valore dei dati strutturati". Il primo punto riguarda la precisione: i dati strutturati offrono un'accuratezza significativamente maggiore per schemi complessi come i prezzi di vendita o i programmi fedeltà rispetto all'estrazione da testo libero basata su modelli linguistici. I modelli linguistici possono essere fuorvianti: riempiono gli attributi mancanti, annidano i dati in modo errato o accedono alle informazioni fuori contesto. Quando si estraggono i prezzi dei prodotti da un grande sito di e-commerce con decine di articoli simili, il tasso di errore è significativamente più elevato con l'inferenza basata sull'IA rispetto a un markup strutturato implementato correttamente.
Il secondo punto riguarda i contenuti aggiuntivi: i dati strutturati spesso contengono metadati invisibili che semplicemente non sono presenti nell'HTML renderizzato di una pagina. Formati data ISO completi, identificatori stabili per i contenuti generati dagli utenti o ID di entità interni: queste informazioni esistono esclusivamente nel markup. Nessun modello linguistico può estrarre ciò che non è presente nel testo.
In terzo luogo, l'efficienza: l'analisi sintattica del markup strutturato è molte volte più economica rispetto all'elaborazione di un modello linguistico di grandi dimensioni per estrarre dati complessi. Google indicizza miliardi di pagine ogni giorno. Il calcolo è semplice: un normale parser che elabora JSON-LD consuma una frazione delle risorse di calcolo di una fase di inferenza LLM. I dati strutturati non sono quindi solo semanticamente superiori, ma sono anche significativamente più efficienti dal punto di vista aziendale. Questo punto è di diretta rilevanza per l'infrastruttura di Google.
Il quarto aspetto, e forse il più sottovalutato, è la focalizzazione: i dati strutturati evidenziano esplicitamente quali informazioni sono rilevanti in una pagina, impedendo così ai sistemi di intelligenza artificiale di acquisire dati irrilevanti. In una pagina prodotto con un articolo principale, diversi prodotti correlati e una barra di navigazione piena di prezzi, un modello linguistico senza annotazioni esplicite non può essere certo a quale prezzo fare riferimento. Il markup strutturato risolve questo problema attraverso un'assegnazione univoca.
Come vengono effettivamente elaborati i dati strutturati
L'utilizzo di Levering ha inoltre reso trasparente il flusso di elaborazione tecnica. I dati Schema.org vengono prima elaborati attraverso specifiche operazioni di pulizia e filtraggio, prima di essere categorizzati come dati indicizzati e suddivisi in aree come eventi, shopping e recensioni. Questi dati elaborati confluiscono quindi in due diversi canali di output: da un lato, la classica pagina dei risultati di ricerca (SRP), e dall'altro, come contesto per i sistemi di intelligenza artificiale di Google, in particolare le cosiddette AI Overviews (AIO) e AI Mode (AIM). I dati strutturati non sono quindi più solo uno strumento per arricchire i risultati, ma un input diretto per le risposte generative dell'intelligenza artificiale. Ciò rappresenta un cambiamento fondamentale nell'importanza strategica del markup Schema.org.
🎯🎯🎯 Hub B2B basato sui dati come soluzione quasi interna

La soluzione quasi interna: come Xpert.Digital colma le lacune operative nel marketing e nelle vendite B2B – Smart Content-Driven Business - Immagine: Xpert.Digital
Xpert.Digital è un hub industriale B2B basato sui dati, guidato da Konrad Wolfenstein . L'azienda funge da soluzione esterna, quasi interna, per i partner industriali, colmando le lacune operative in marketing, contenuti e vendite, senza richiedere risorse aggiuntive al cliente.
Maggiori informazioni qui:
Perché i dati strutturati stanno diventando l'infrastruttura per gli agenti di intelligenza artificiale
Shopping sotto i riflettori: spedizioni, programmi fedeltà e varianti
Una parte significativa della presentazione si è concentrata sulle innovazioni nell'e-commerce. Levering ha spiegato che, secondo i dati del Baymard Institute, le informazioni di spedizione inaspettate si classificano al secondo e terzo posto tra le cause più comuni di abbandono del carrello. Il markup strutturato per i servizi di spedizione può risolvere direttamente questo problema: i commercianti possono ora definire con precisione, direttamente nel codice, le regioni di origine e di destinazione, le dimensioni e i pesi, le soglie di valore dell'ordine, i tempi di elaborazione e le affiliazioni ai programmi fedeltà.
Il modello di tempi di spedizione utilizzato da Google è suddiviso in due fasi: il tempo di gestione, ovvero il tempo che intercorre tra la ricezione dell'ordine e la consegna al corriere, e il tempo di consegna effettivo. Entrambe le fasi possono essere annotate separatamente e con un elevato livello di dettaglio, fino ad arrivare agli orari limite per gli ordini e all'eventuale elaborazione anche nei giorni feriali. Gli esempi JSON-LD corrispondenti mostrano come il tipo `ShippingConditions` possa essere utilizzato per definire la spedizione gratuita per determinati paesi (ad esempio, Francia e Germania) e valori minimi d'ordine (ad esempio, 50 €).
L'integrazione dei servizi di spedizione con i programmi fedeltà è particolarmente innovativa. Utilizzando la proprietà `validForMemberTier`, un servizio di spedizione può essere esplicitamente collegato a un programma fedeltà e a uno specifico livello. Ciò consente di dichiarare i vantaggi di spedizione per i membri premium direttamente nel markup, una funzionalità che in precedenza era configurabile solo tramite Google Merchant Center. Il programma fedeltà associato è definito come un oggetto `MemberProgram` all'interno dell'entità `Organization`, con livelli come "Gold" o "Silver" e vantaggi associati come premi fedeltà o punti premio.
Programmi fedeltà come entità semantiche
L'introduzione di un sistema di markup per i programmi fedeltà ha un impatto economico significativo. Le aziende possono definire diversi programmi di adesione indipendenti, ognuno con vari livelli e vantaggi differenziati: punti, prezzi riservati ai membri, politiche di reso, bonus di spedizione. Queste informazioni vengono poi visualizzate direttamente nei risultati di ricerca di Google, come dimostrato da Levering con esempi concreti, tra cui un'offerta di Sephora che mostrava uno sconto del 30% per i membri direttamente nello snippet di acquisto. Il collegamento tra ID di pagina, ovvero la possibilità di creare link alle definizioni dei programmi fedeltà da altre pagine, è, secondo Levering, il prossimo passo previsto, attualmente intitolato "Aprire la strada al collegamento tra ID di pagina". L'obiettivo: creare riferimenti organizzativi più solidi tra le pagine dei prodotti e le politiche aziendali.
Contenuti generati dagli utenti: il problema dell'etichettatura tramite IA
Un altro tema importante è stato l'ulteriore sviluppo dei tipi di schema per i contenuti generati dagli utenti (UGC). Due nuove funzionalità sono particolarmente rilevanti in questo contesto. In primo luogo, i post incorporati e le ripubblicazioni sono supportati nel markup dei forum e delle sezioni Domande e Risposte, consentendo una rappresentazione semantica più accurata delle strutture di discussione. In secondo luogo, e questo riveste un'importanza strategica ancora maggiore, viene introdotta la proprietà `so#digitalSourceType` per identificare esplicitamente i contenuti generati automaticamente.
Questo sviluppo rappresenta una risposta diretta all'ondata di contenuti generati dall'intelligenza artificiale su piattaforme come forum e siti di domande e risposte. I webmaster possono ora dichiarare se un post è stato generato algoritmicamente o tramite un modello linguistico. Chi non specifica questa informazione viene implicitamente considerato da Google come autore umano, una regola che incentiva un'etichettatura trasparente. La proprietà `digitalSourceType` si basa sui codici IPTC per le fonti digitali e distingue, tra le altre cose, tra contenuti generati algoritmicamente e contenuti generati da modelli.
Selezione delle immagini: Schema batte Open Graph
Un aggiornamento meno evidente ma di grande efficacia pratica riguarda la logica di selezione delle immagini di Google. Il sistema è in fase di consolidamento interno, con una chiara gerarchia di priorità: il markup Schema.org, in particolare le proprietà `primaryImageOfPage` e `mainEntity → image`, ha la precedenza. Solo successivamente viene aggiunto il meta tag `og:image` di Open Graph. Questa modifica significa che, per i gestori di siti web, un'implementazione corretta di Schema.org per l'immagine principale influisce direttamente sulla sua visualizzazione nei risultati di ricerca di Google e nelle panoramiche AI: un vantaggio concreto e misurabile.
Schema.org stesso riceve investimenti
Degno di nota è anche l'annuncio di Google di voler reinvestire in schema.org come specifica aperta. Sono state menzionate tre misure concrete: la pubblicazione di statistiche sulla frequenza d'uso dei singoli termini dello schema (i dati sulla prevalenza, come mostrato in una diapositiva, sono già disponibili per singoli termini come `digitalSourceType` con informazioni su circa 10.000 domini), la pubblicazione delle regole di validazione di Google in formati standard leggibili automaticamente come SHACL o ShEx e un supporto migliorato per le regole di ordinamento. Questo è significativo perché consentirebbe agli sviluppatori esterni di creare i propri strumenti di validazione basati sugli standard di Google, indipendentemente dagli strumenti di test ufficiali, che a volte si bloccano sotto carico.
Validazione: due strumenti, un unico obiettivo
Levering ha presentato due strumenti di validazione complementari, ma che applicano criteri di test differenti. Il Rich Result Test Tool, disponibile all'indirizzo `search.google.com/test/rich-results`, accetta URL o JSON puro e verifica se il markup è adatto ai Rich Result di Google; si basa quindi sui requisiti specifici di Google, non sullo standard schema.org in sé. Il validator.schema.org, invece, verifica se il markup è conforme a schema.org, ovvero se aderisce al vocabolario aperto, indipendentemente dal fatto che Google generi o meno risultati avanzati. Questo porta a una chiara raccomandazione per gli sviluppatori web: entrambi gli strumenti dovrebbero essere utilizzati, perché un markup può essere conforme a schema.org ma non essere in grado di generare risultati avanzati, e viceversa.
Il quadro generale: i dati strutturati come infrastruttura per l'intelligenza artificiale
Osservando l'evento di Toronto nel suo complesso, emerge un cambiamento evidente che va ben oltre la tradizionale ottimizzazione SEO. I dati strutturati si stanno evolvendo da strumento per ottenere rich snippet a standard fondamentale per il livello dati dei sistemi di intelligenza artificiale. Le panoramiche sull'IA e la modalità IA di Google utilizzano attivamente il markup schema.org come contesto per la generazione di risposte e la verifica delle entità. Chi implementa dati strutturati corretti, completi e precisi non solo migliora le proprie possibilità di ottenere visibilità nei risultati di ricerca, ma posiziona anche i propri contenuti come una fonte primaria affidabile per le risposte dell'IA.
La menzione dell'Universal Commerce Protocol (UCP) e di WebMCP in questo contesto non è casuale. Entrambi gli standard di comunicazione basati su agenti, le cui prime versioni sono state rilasciate da Google nel 2026, richiedono che i siti web siano descritti semanticamente. Schema.org ne costituisce la base. In un mondo in cui gli agenti di intelligenza artificiale agiscono autonomamente sul web, effettuando ricerche, confrontando e avviando transazioni, la leggibilità automatica dei contenuti non è più un'opzione, ma un prerequisito per la rilevanza economica. La presentazione di Ryan Levering a Toronto non è stata quindi solo un aggiornamento tecnico, ma uno sguardo all'infrastruttura del web del futuro.
Puoi scoprirlo tu stesso in 10 secondi
Se vuoi sapere quanto bene e in modo completo il tuo sito web o quello di altri utilizza i dati strutturati, puoi usare esattamente i due strumenti consigliati da Ryan Levering di Google (citato nel testo precedente):
Test dei risultati avanzati di Google (con particolare attenzione alla visibilità su Google):
Vai su search.google.com/test/rich-results, copia l'URL di un qualsiasi articolo di xpert.digital e fai clic su "Verifica URL". Lo strumento ti mostrerà esattamente quali markup Google riconosce su quella pagina e se sono privi di errori.
Validatore di schemi (focalizzato sulla pura conformità agli standard):
Vai su validator.schema.orge incolla lo stesso URL. Qui puoi vedere direttamente nel codice sorgente, evidenziato a colori, quali script JSON-LD (dati strutturati) sono stati incorporati da xpert.digital.
Il tuo partner globale per il marketing e lo sviluppo aziendale
☑️ La nostra lingua aziendale è l'inglese o il tedesco
☑️ NOVITÀ: Corrispondenza nella tua lingua madre!

Konrad Wolfenstein
Io e il mio team saremo lieti di essere a tua disposizione come tuo consulente personale.
Puoi contattarmi compilando il modulo di contatto qui semplicemente chiamandomi al numero +49 7348 4088 965. Il mio indirizzo email è [email protected]:o
Non vedo l'ora di iniziare il nostro progetto comune.
☑️ Supporto alle PMI in strategia, consulenza, pianificazione e implementazione
☑️ Creazione o riallineamento della strategia digitale e digitalizzazione
☑️ Espansione e ottimizzazione dei processi di vendita internazionali
☑️ Piattaforme di trading B2B globali e digitali
☑️ Sviluppo aziendale pionieristico / Marketing / PR / Fiere
Supporto B2B e SaaS per SEO e GEO (ricerca AI) combinati: la soluzione all-in-one per le aziende B2B

Supporto B2B e SaaS per SEO e GEO (ricerca AI) combinati: la soluzione all-in-one per le aziende B2B - Immagine: Xpert.Digital
La ricerca basata sull'intelligenza artificiale cambia tutto: come questa soluzione SaaS rivoluzionerà per sempre il tuo posizionamento B2B.
Il panorama digitale per le aziende B2B sta subendo rapidi cambiamenti. Grazie all'intelligenza artificiale, le regole della visibilità online vengono riscritte. Per le aziende, è sempre stata una sfida non solo essere visibili nel mercato digitale, ma anche essere rilevanti per i decision maker più competenti. Le strategie SEO tradizionali e la gestione della presenza locale (geo-marketing) sono complesse, richiedono molto tempo e spesso rappresentano una lotta contro algoritmi in continua evoluzione e una concorrenza agguerrita.
Ma cosa succederebbe se esistesse una soluzione che non solo semplificasse questo processo, ma lo rendesse anche più intelligente, predittivo e molto più efficace? È qui che entra in gioco la combinazione di un supporto B2B specializzato con una potente piattaforma SaaS (Software as a Service), specificamente progettata per le esigenze di SEO e GEO nell'era della ricerca basata sull'intelligenza artificiale.
Questa nuova generazione di strumenti non si basa più esclusivamente sull'analisi manuale delle parole chiave e sulle strategie di backlink. Sfrutta invece l'intelligenza artificiale per comprendere con maggiore precisione l'intento di ricerca, ottimizzare automaticamente i fattori di ranking locali ed eseguire analisi competitive in tempo reale. Il risultato è una strategia proattiva basata sui dati che offre alle aziende B2B un vantaggio decisivo: non solo vengono trovate, ma vengono percepite come l'autorità leader nella loro nicchia e posizione geografica.
Ecco la simbiosi tra supporto B2B e tecnologia SaaS basata sull'intelligenza artificiale che trasforma il marketing SEO e GEO, e come la tua azienda può trarne vantaggio per crescere in modo sostenibile nello spazio digitale.
Maggiori informazioni qui:

















