
Un tentativo di spiegare l’intelligenza artificiale: come funziona e funziona l’intelligenza artificiale – come viene addestrata?

Selezione vocale 📢
Pubblicato l'8 settembre 2024 / aggiornamento dal: 9 settembre 2024 - Autore: Konrad Wolfenstein

Un tentativo di spiegare l'intelligenza artificiale: come funziona l'intelligenza artificiale e come viene addestrata? – Immagine: Xpert.Digital
📊 Dall'input dei dati alla previsione del modello: il processo di intelligenza artificiale
Come funziona l'intelligenza artificiale (AI)? 🤖
Il funzionamento dell’intelligenza artificiale (AI) può essere suddiviso in diverse fasi chiaramente definite. Ciascuno di questi passaggi è fondamentale per il risultato finale fornito dall'intelligenza artificiale. Il processo inizia con l'immissione dei dati e termina con la previsione del modello e l'eventuale feedback o ulteriori cicli di formazione. Queste fasi descrivono il processo che attraversano quasi tutti i modelli di intelligenza artificiale, indipendentemente dal fatto che si tratti di semplici insiemi di regole o di reti neurali altamente complesse.
1. L'inserimento dei dati 📊
La base di tutta l’intelligenza artificiale sono i dati con cui lavora. Questi dati possono presentarsi in varie forme, ad esempio immagini, testo, file audio o video. L’intelligenza artificiale utilizza questi dati grezzi per riconoscere modelli e prendere decisioni. La qualità e la quantità dei dati giocano qui un ruolo centrale, perché hanno un’influenza significativa sul successivo funzionamento del modello.
Più i dati sono estesi e precisi, meglio l’intelligenza artificiale può imparare. Ad esempio, quando un’intelligenza artificiale viene addestrata per l’elaborazione delle immagini, richiede una grande quantità di dati di immagine per identificare correttamente i diversi oggetti. Con i modelli linguistici, sono i dati di testo che aiutano l’IA a comprendere e generare il linguaggio umano. L'immissione dei dati è il primo e uno dei passaggi più importanti, poiché la qualità delle previsioni può essere buona solo quanto i dati sottostanti. Un famoso principio dell’informatica lo descrive con il detto “Garbage in, garbage out”: dati errati portano a risultati errati.
2. Preelaborazione dei dati 🧹
Una volta inseriti i dati, è necessario prepararli prima di poterli inserire nel modello vero e proprio. Questo processo è chiamato preelaborazione dei dati. Lo scopo qui è mettere i dati in una forma che possa essere elaborata in modo ottimale dal modello.
Un passaggio comune nella preelaborazione è la normalizzazione dei dati. Ciò significa che i dati vengono portati in un intervallo di valori uniforme in modo che il modello li tratti in modo uniforme. Un esempio potrebbe essere quello di ridimensionare tutti i valori dei pixel di un'immagine in un intervallo compreso tra 0 e 1 anziché tra 0 e 255.
Un'altra parte importante della preelaborazione è la cosiddetta estrazione delle caratteristiche. Dai dati grezzi vengono estratte alcune caratteristiche particolarmente rilevanti per il modello. Nell'elaborazione delle immagini, ad esempio, potrebbero trattarsi di bordi o determinati modelli di colore, mentre nei testi vengono estratte parole chiave o strutture di frasi rilevanti. La preelaborazione è fondamentale per rendere il processo di apprendimento dell’IA più efficiente e preciso.
3. Il modello 🧩
Il modello è il cuore di ogni intelligenza artificiale. Qui i dati vengono analizzati ed elaborati sulla base di algoritmi e calcoli matematici. Un modello può esistere in diverse forme. Uno dei modelli più conosciuti è la rete neurale, che si basa sul funzionamento del cervello umano.
Le reti neurali sono costituite da diversi strati di neuroni artificiali che elaborano e trasmettono informazioni. Ogni livello prende gli output del livello precedente e li elabora ulteriormente. Il processo di apprendimento di una rete neurale consiste nell'adattare i pesi delle connessioni tra questi neuroni in modo che la rete possa effettuare previsioni o classificazioni sempre più accurate. Questo adattamento avviene attraverso la formazione, in cui la rete accede a grandi quantità di dati campione e migliora iterativamente i suoi parametri interni (pesi).
Oltre alle reti neurali, ci sono anche molti altri algoritmi utilizzati nei modelli di intelligenza artificiale. Questi includono alberi decisionali, foreste casuali, macchine a vettori di supporto e molti altri. L'algoritmo utilizzato dipende dall'attività specifica e dai dati disponibili.
4. Il modello di previsione 🔍
Dopo che il modello è stato addestrato con i dati, è in grado di fare previsioni. Questo passaggio è chiamato previsione del modello. L’IA riceve un input e restituisce un output, ovvero una previsione o una decisione, sulla base degli schemi che ha appreso finora.
Questa previsione può assumere diverse forme. Ad esempio, in un modello di classificazione delle immagini, l’intelligenza artificiale potrebbe prevedere quale oggetto è visibile in un’immagine. In un modello linguistico, potrebbe fare una previsione su quale parola verrà dopo in una frase. Nelle previsioni finanziarie, l’intelligenza artificiale potrebbe prevedere l’andamento del mercato azionario.
È importante sottolineare che l'accuratezza delle previsioni dipende fortemente dalla qualità dei dati di addestramento e dall'architettura del modello. Un modello addestrato su dati insufficienti o distorti è probabile che faccia previsioni errate.
5. Feedback e formazione (facoltativo) ♻️
Un'altra parte importante del lavoro di un'intelligenza artificiale è il meccanismo di feedback. Il modello viene regolarmente controllato e ulteriormente ottimizzato. Questo processo si verifica durante l'addestramento o dopo la previsione del modello.
Se il modello fa previsioni errate, può imparare attraverso il feedback a rilevare questi errori e regolare di conseguenza i suoi parametri interni. Ciò avviene confrontando le previsioni del modello con i risultati effettivi (ad esempio con dati noti per i quali esistono già le risposte corrette). Una procedura tipica in questo contesto è il cosiddetto apprendimento supervisionato, in cui l’IA impara da dati di esempio a cui sono già fornite le risposte corrette.
Un metodo comune di feedback è l'algoritmo di backpropagation utilizzato nelle reti neurali. Gli errori commessi dal modello vengono propagati all'indietro attraverso la rete per regolare i pesi delle connessioni neuronali. Il modello impara dai propri errori e diventa sempre più preciso nelle sue previsioni.
Il ruolo della formazione 🏋️♂️
L’addestramento di un’intelligenza artificiale è un processo iterativo. Più dati vede il modello e più spesso viene addestrato in base a questi dati, più accurate diventano le sue previsioni. Esistono però anche dei limiti: un modello eccessivamente addestrato può presentare problemi cosiddetti di “overfitting”. Ciò significa che memorizza i dati di addestramento così bene che produce risultati peggiori su dati nuovi e sconosciuti. È quindi importante addestrare il modello in modo che sia generalizzabile e faccia buone previsioni anche su nuovi dati.
Oltre alla formazione regolare, esistono anche procedure come il trasferimento dell'apprendimento. In questo caso, un modello già addestrato su una grande quantità di dati viene utilizzato per un compito nuovo e simile. Ciò consente di risparmiare tempo e potenza di calcolo perché il modello non deve essere addestrato da zero.
Sfrutta al massimo i tuoi punti di forza 🚀
Il lavoro di un'intelligenza artificiale si basa su una complessa interazione di vari passaggi. Dall'immissione dei dati, alla preelaborazione, all'addestramento dei modelli, alla previsione e al feedback, sono molti i fattori che influenzano l'accuratezza e l'efficienza dell'intelligenza artificiale. Un’intelligenza artificiale ben addestrata può offrire enormi vantaggi in molti ambiti della vita, dall’automazione di compiti semplici alla risoluzione di problemi complessi. Ma è altrettanto importante comprendere i limiti e le potenziali insidie dell’intelligenza artificiale per sfruttare al meglio i suoi punti di forza.
🤖📚 Spiegato in modo semplice: come viene addestrata un'IA?
🤖📊 Processo di apprendimento AI: cattura, collega e salva
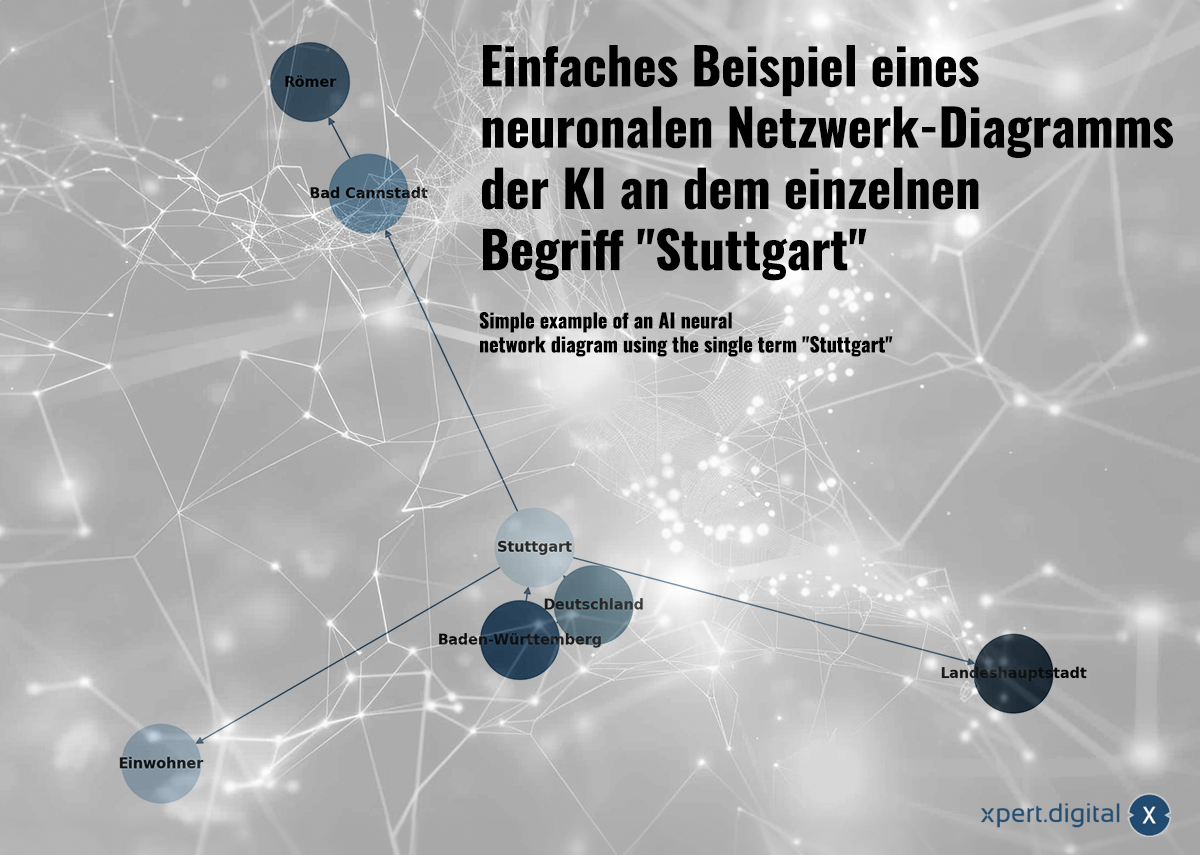
Semplice esempio di un diagramma di rete neuronale dell'IA sul termine individuale "stoccart" -image: xpert.digital
🌟 Raccogliere e preparare i dati
Il primo passo nel processo di apprendimento dell’IA è la raccolta e la preparazione dei dati. Questi dati possono provenire da varie fonti, come database, sensori, testi o immagini.
🌟 Relativi dati (Rete Neurale)
I dati raccolti sono correlati tra loro in una rete neurale. Ogni pacchetto di dati è mostrato dalle connessioni in una rete di "neuroni" (nodo). Un semplice esempio con la città di Stoccarda potrebbe apparire così:
a) Stoccarda è una città del Baden-Württemberg
b) Il Baden-Württemberg è uno stato federale della Germania
c) Stoccarda è una città della Germania
d) Stoccarda ha una popolazione di 633.484 abitanti nel 2023
e) Bad Cannstatt è un distretto di Stoccarda
f) Bad Cannstatt è stata fondata dai romani
g) Stoccarda è la capitale del Land Baden-Württemberg
A seconda della dimensione del volume di dati, i parametri per le potenziali spese vengono creati utilizzando il modello AI utilizzato. Ad esempio: GPT-3 ha circa 175 miliardi di parametri!
🌟 Archiviazione e personalizzazione (apprendimento)
I dati vengono forniti alla rete neurale. Passano attraverso il modello AI e vengono elaborati tramite connessioni (simili alle sinapsi). I pesi (parametri) tra i neuroni vengono regolati per addestrare il modello o svolgere un compito.
Contrariamente alle forme di memoria convenzionali come l'accesso diretto, l'accesso indicato, l'archiviazione sequenziale o stack, le reti neurali archiviano i dati in modo non convenzionale. I "dati" sono memorizzati nei pesi e nei pregiudizi delle connessioni tra i neuroni.
L'effettiva "archiviazione" delle informazioni in una rete neuronale avviene adattando i pesi di connessione tra i neuroni. Il modello AI "impara" adattando costantemente questi pesi e pregiudizi in base ai dati di input e a un algoritmo di apprendimento definito. Questo è un processo continuo in cui il modello può fare previsioni precise a causa di regolazioni ricorrenti.
Il modello AI può essere considerato un tipo di programmazione perché viene creato attraverso algoritmi definiti e calcoli matematici e migliora continuamente la regolazione dei suoi parametri (pesi) per fare previsioni accurate. Questo è un processo continuo.
I bias sono parametri aggiuntivi nelle reti neurali che vengono aggiunti ai valori di input ponderati di un neurone. Permettono di ponderare i parametri (importante, meno importante, importante, ecc.), rendendo l'IA più flessibile e precisa.
Le reti neurali non solo possono memorizzare fatti individuali, ma anche riconoscere le connessioni tra i dati attraverso il riconoscimento di modelli. L'esempio di Stoccarda illustra come la conoscenza può essere introdotta in una rete neurale, ma le reti neurali non apprendono attraverso la conoscenza esplicita (come in questo semplice esempio) ma attraverso l'analisi di modelli di dati. Le reti neurali non solo possono memorizzare fatti individuali, ma anche apprendere pesi e relazioni tra i dati di input.
Questo flusso fornisce un'introduzione comprensibile al funzionamento dell'intelligenza artificiale e delle reti neurali in particolare, senza immergersi troppo nei dettagli tecnici. Dimostra che l'archiviazione delle informazioni nelle reti neurali non avviene come nei database tradizionali, ma adattando le connessioni (pesi) all'interno della rete.
🤖📚 Più in dettaglio: come viene addestrata un'IA?
🏋️♂️ L'addestramento di un'intelligenza artificiale, in particolare di un modello di machine learning, avviene in più fasi. L'addestramento di un'intelligenza artificiale si basa sull'ottimizzazione continua dei parametri del modello attraverso feedback e aggiustamenti finché il modello non mostra le migliori prestazioni sui dati forniti. Ecco una spiegazione dettagliata di come funziona questo processo:
1. 📊 Raccogliere e preparare i dati
I dati sono il fondamento della formazione sull’intelligenza artificiale. Solitamente consistono in migliaia o milioni di esempi che il sistema deve analizzare. Esempi sono immagini, testi o dati di serie temporali.
I dati devono essere puliti e normalizzati per evitare inutili fonti di errore. Spesso i dati vengono convertiti in funzionalità che contengono le informazioni rilevanti.
2. 🔍Definire il modello
Un modello è una funzione matematica che descrive le relazioni tra i dati. Nelle reti neurali, spesso utilizzate per l’intelligenza artificiale, il modello è costituito da più strati di neuroni collegati tra loro.
Ogni neurone esegue un'operazione matematica per elaborare i dati di input e quindi trasmette un segnale al neurone successivo.
3. 🔄 Inizializza i pesi
Le connessioni tra i neuroni hanno pesi inizialmente impostati in modo casuale. Questi pesi determinano la forza con cui un neurone risponde a un segnale.
L'obiettivo dell'addestramento è regolare questi pesi in modo che il modello effettui previsioni migliori.
4. ➡️ Propagazione in avanti
Il passaggio in avanti fa passare i dati di input attraverso il modello per produrre una previsione.
Ogni livello elabora i dati e li passa al livello successivo finché l'ultimo livello non fornisce il risultato.
5. ⚖️ Calcola la funzione di perdita
La funzione di perdita misura quanto sono buone le previsioni del modello rispetto ai valori effettivi (le etichette). Una misura comune è l’errore tra la risposta prevista e quella effettiva.
Maggiore è la perdita, peggiore è la previsione del modello.
6. 🔙Propagazione all'indietro
Nel passaggio all'indietro, l'errore viene retroagito dall'output del modello agli strati precedenti.
L'errore viene ridistribuito sui pesi delle connessioni e il modello aggiusta i pesi in modo che gli errori diventino più piccoli.
Questo viene fatto utilizzando la discesa del gradiente: viene calcolato il vettore del gradiente, che indica come modificare i pesi per ridurre al minimo l'errore.
7. 🔧 Aggiorna i pesi
Dopo aver calcolato l'errore, i pesi delle connessioni vengono aggiornati con un piccolo aggiustamento in base alla velocità di apprendimento.
La velocità di apprendimento determina quanto i pesi vengono modificati a ogni passaggio. Cambiamenti troppo grandi possono rendere il modello instabile, mentre cambiamenti troppo piccoli portano a un processo di apprendimento lento.
8. 🔁 Ripeti (Epoca)
Questo processo di passaggio in avanti, calcolo degli errori e aggiornamento del peso viene ripetuto, spesso in più epoche (passa attraverso l'intero set di dati), finché il modello non raggiunge una precisione accettabile.
Con ogni epoca, il modello impara qualcosa in più e adegua ulteriormente i suoi pesi.
9. 📉 Validazione e test
Dopo che il modello è stato addestrato, viene testato su un set di dati convalidato per verificare quanto bene si generalizza. Ciò garantisce che non solo abbia “memorizzato” i dati di addestramento, ma faccia buone previsioni su dati sconosciuti.
I dati di test aiutano a misurare le prestazioni finali del modello prima che venga utilizzato nella pratica.
10. 🚀 Ottimizzazione
Ulteriori passaggi per migliorare il modello includono l'ottimizzazione degli iperparametri (ad esempio la regolazione della velocità di apprendimento o della struttura della rete), la regolarizzazione (per evitare un adattamento eccessivo) o l'aumento della quantità di dati.
📊🔙 Intelligenza artificiale: rendi comprensibile, comprensibile e spiegabile la scatola nera dell'intelligenza artificiale con Explainable AI (XAI), mappe di calore, modelli surrogati o altre soluzioni

Intelligenza artificiale: rendere comprensibile, comprensibile e spiegabile la scatola nera dell'intelligenza artificiale con Explainable AI (XAI), mappe di calore, modelli surrogati o altre soluzioni - Immagine: Xpert.Digital
La cosiddetta “scatola nera” dell’intelligenza artificiale (AI) rappresenta un problema significativo e attuale. Anche gli esperti si trovano spesso ad affrontare la sfida di non riuscire a comprendere appieno come i sistemi di intelligenza artificiale arrivano alle loro decisioni. Questa mancanza di trasparenza può causare problemi significativi, soprattutto in settori critici come l’economia, la politica o la medicina. Un medico o un professionista sanitario che si affida a un sistema di intelligenza artificiale per diagnosticare e consigliare la terapia deve avere fiducia nelle decisioni prese. Tuttavia, se il processo decisionale di un’intelligenza artificiale non è sufficientemente trasparente, sorgono incertezza e potenzialmente mancanza di fiducia, in situazioni in cui potrebbero essere in gioco vite umane.
Maggiori informazioni qui:
Siamo a vostra disposizione: consulenza, pianificazione, implementazione, gestione del progetto
☑️ Supporto alle PMI nella strategia, consulenza, pianificazione e implementazione
☑️ Creazione o riallineamento della strategia digitale e digitalizzazione
☑️ Espansione e ottimizzazione dei processi di vendita internazionali
☑️ Piattaforme di trading B2B globali e digitali
☑️ Sviluppo aziendale pionieristico

Konrad Wolfenstein
Sarei felice di fungere da tuo consulente personale.
Potete contattarmi compilando il modulo di contatto qui sotto o semplicemente chiamandomi al numero +49 89 89 674 804 (Monaco) .
Non vedo l'ora di iniziare il nostro progetto comune.
Scrivimi

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital è un hub per l'industria con focus su digitalizzazione, ingegneria meccanica, logistica/intralogistica e fotovoltaico.
Con la nostra soluzione di sviluppo aziendale a 360° supportiamo aziende rinomate dal nuovo business al post-vendita.
Market intelligence, smarketing, marketing automation, sviluppo di contenuti, PR, campagne email, social media personalizzati e lead nurturing fanno parte dei nostri strumenti digitali.
Potete saperne di più su: www.xpert.digital - www.xpert.solar - www.xpert.plus
Rimaniamo in contatto


















