
AI dan SEO dengan BERT – Bidirectional Encoder Representations from Transformers – Model di bidang pemrosesan bahasa alami (NLP)

Pemilihan suara 📢
Diterbitkan pada: 4 Oktober 2024 / Diperbarui pada: 4 Oktober 2024 – Penulis: Konrad Wolfenstein

AI dan SEO dengan BERT – Bidirectional Encoder Representations from Transformers – Model di bidang pemrosesan bahasa alami (NLP) – Gambar: Xpert.Digital
🚀💬 Dikembangkan oleh Google: BERT dan signifikansinya bagi NLP - Mengapa pemahaman teks dua arah sangat penting
🔍🗣️ BERT, singkatan dari Bidirectional Encoder Representations from Transformers, adalah model penting di bidang pemrosesan bahasa alami (NLP) yang dikembangkan oleh Google. Model ini telah merevolusi cara mesin memahami bahasa. Tidak seperti model sebelumnya yang menganalisis teks secara berurutan dari kiri ke kanan atau sebaliknya, BERT memungkinkan pemrosesan dua arah. Ini berarti BERT memahami konteks sebuah kata dari urutan teks sebelumnya dan sesudahnya. Kemampuan ini secara signifikan meningkatkan pemahaman tentang hubungan linguistik yang kompleks.
🔍 Arsitektur BERT
Dalam beberapa tahun terakhir, salah satu perkembangan paling signifikan dalam pemrosesan bahasa alami (NLP) adalah pengenalan model Transformer, seperti yang dijelaskan dalam makalah PDF tahun 2017 "Attention is all you need" ( Wikipedia ). Model ini secara fundamental mengubah bidang ini dengan meninggalkan struktur yang sebelumnya digunakan, seperti terjemahan mesin. Sebaliknya, model ini bergantung sepenuhnya pada mekanisme perhatian. Desain Transformer sejak itu menjadi dasar bagi banyak model yang mewakili teknologi terkini di berbagai bidang, termasuk pembangkitan ucapan, penerjemahan, dan lainnya.
Ilustrasi komponen utama model Transformer – Gambar: Google
BERT didasarkan pada arsitektur transformer ini. Arsitektur ini menggunakan mekanisme yang disebut self-attention untuk menganalisis hubungan antar kata dalam sebuah kalimat. Setiap kata diberi perhatian dalam konteks keseluruhan kalimat, sehingga menghasilkan pemahaman yang lebih tepat tentang hubungan sintaksis dan semantik.
Para penulis makalah “Perhatian Adalah Segalanya yang Anda Butuhkan” adalah:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Lion Jones (Penelitian Google)
- Aidan N. Gomez (Universitas Toronto, sebagian pekerjaan dilakukan di Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (Independen, sebelumnya bekerja di Google Research)
Para penulis ini telah memberikan kontribusi signifikan terhadap pengembangan model Transformer yang disajikan dalam makalah ini.
🔄 Pemrosesan dua arah
Salah satu fitur utama BERT adalah kemampuannya untuk memproses teks secara dua arah. Sementara model tradisional seperti jaringan saraf berulang (RNN) atau jaringan memori jangka pendek panjang (LSTM) hanya memproses teks dalam satu arah, BERT menganalisis konteks sebuah kata dalam kedua arah. Hal ini memungkinkan model untuk menangkap nuansa makna yang lebih halus dan dengan demikian membuat prediksi yang lebih akurat.
🕵️♂️ Pemodelan Ucapan Bertopeng
Aspek inovatif lain dari BERT adalah teknik Masked Language Model (MLM). Di sini, kata-kata yang dipilih secara acak dalam sebuah kalimat ditutupi (masked), dan model dilatih untuk memprediksi kata-kata tersebut berdasarkan konteks di sekitarnya. Metode ini memaksa BERT untuk mengembangkan pemahaman mendalam tentang konteks dan makna setiap kata dalam kalimat.
🚀 Pelatihan dan adaptasi BERT
BERT menjalani proses pelatihan dua tahap: pra-pelatihan dan penyempurnaan.
📚 Pra-Pelatihan
Pada tahap pra-pelatihan, BERT dilatih dengan sejumlah besar teks untuk mempelajari pola bahasa umum. Ini termasuk artikel Wikipedia dan korpus teks ekstensif lainnya. Selama fase ini, model mempelajari struktur dan konteks linguistik dasar.
🔧 Penyesuaian lebih lanjut
Setelah pra-pelatihan, BERT diadaptasi untuk tugas-tugas NLP spesifik, seperti klasifikasi teks atau analisis sentimen. Model ini dilatih dengan dataset yang lebih kecil dan terkait dengan tugas untuk mengoptimalkan kinerjanya untuk aplikasi tertentu.
🌍 Area aplikasi BERT
BERT telah terbukti sangat berguna di berbagai bidang pemrosesan bahasa alami:
Optimasi mesin pencari
Google menggunakan BERT untuk lebih memahami kueri pencarian dan menampilkan hasil yang lebih relevan. Hal ini secara signifikan meningkatkan pengalaman pengguna.
Klasifikasi teks
BERT dapat mengkategorikan dokumen berdasarkan topik atau menganalisis suasana hati dalam teks.
Pengenalan Entitas Bernama (NER)
Model ini mengidentifikasi dan mengklasifikasikan entitas bernama dalam teks, seperti nama orang, tempat, atau organisasi.
Sistem tanya jawab
BERT digunakan untuk memberikan jawaban yang tepat atas pertanyaan yang diajukan.
🧠 Pentingnya BERT bagi masa depan AI
BERT telah menetapkan standar baru untuk model NLP dan membuka jalan bagi inovasi lebih lanjut. Melalui kemampuannya untuk pemrosesan dua arah dan pemahaman mendalamnya tentang konteks bahasa, BERT telah secara signifikan meningkatkan efisiensi dan akurasi aplikasi AI.
🔜 Perkembangan selanjutnya
Pengembangan lebih lanjut dari BERT dan model serupa diharapkan bertujuan untuk menciptakan sistem yang lebih canggih. Sistem ini dapat menangani tugas-tugas bahasa yang lebih kompleks dan digunakan dalam berbagai bidang aplikasi baru. Mengintegrasikan model-model tersebut ke dalam teknologi sehari-hari dapat secara fundamental mengubah cara kita berinteraksi dengan komputer.
🌟 Tonggak penting dalam pengembangan kecerdasan buatan
BERT merupakan tonggak penting dalam pengembangan kecerdasan buatan dan telah merevolusi cara mesin memproses bahasa alami. Arsitektur dua arahnya memungkinkan pemahaman yang lebih mendalam tentang hubungan linguistik, menjadikannya sangat diperlukan untuk berbagai aplikasi. Seiring kemajuan penelitian, model seperti BERT akan terus memainkan peran sentral dalam meningkatkan sistem AI dan membuka kemungkinan baru untuk penggunaannya.
📣 Topik serupa
- 📚 Pengantar BERT: Model NLP yang inovatif
- 🔍 BERT dan peran bidireksionalitas dalam NLP
- 🧠 Model Transformer: Landasan BERT
- 🚀 Pemodelan Bahasa Bertopeng: Kunci Sukses BERT
- 📈 Kustomisasi BERT: Dari pra-pelatihan hingga penyempurnaan
- 🌐 Bidang aplikasi BERT dalam teknologi modern
- 🤖 Pengaruh BERT terhadap masa depan kecerdasan buatan
- 💡 Prospek masa depan: Pengembangan lebih lanjut dari BERT
- 🏆 BERT sebagai tonggak penting dalam pengembangan AI
- 📰 Para penulis makalah Transformer “Attention Is All You Need”: Para pemikir di balik BERT
#️⃣ Hashtag: #NLP #KecerdasanBuatan #PemodelanBahasa #Transformer #PembelajaranMesin
🎯🎯🎯 Manfaatkan keahlian Xpert.Digital yang luas dan berlipat ganda dalam paket layanan yang komprehensif | BD, R&D, XR, PR & Optimasi Visibilitas Digital

Manfaatkan keahlian Xpert.Digital yang luas dan lima kali lipat dalam paket layanan yang komprehensif | R&D, XR, PR & Optimalisasi Visibilitas Digital - Gambar: Xpert.Digital
Xpert.Digital memiliki pengetahuan mendalam tentang berbagai industri. Hal ini memungkinkan kami mengembangkan strategi khusus yang disesuaikan secara tepat dengan kebutuhan dan tantangan segmen pasar spesifik Anda. Dengan terus menganalisis tren pasar dan mengikuti perkembangan industri, kami dapat bertindak dengan pandangan ke depan dan menawarkan solusi inovatif. Melalui kombinasi pengalaman dan pengetahuan, kami menghasilkan nilai tambah dan memberikan pelanggan kami keunggulan kompetitif yang menentukan.
Lebih lanjut tentang itu di sini:
BERT: Teknologi NLP Revolusioner 🌟
🚀 BERT, singkatan dari Bidirectional Encoder Representations from Transformers, adalah model bahasa canggih yang dikembangkan oleh Google yang telah menjadi terobosan signifikan dalam pemrosesan bahasa alami (NLP) sejak diperkenalkan pada tahun 2018. Model ini berbasis pada arsitektur Transformer, yang merevolusi cara mesin memahami dan memproses teks. Tetapi apa sebenarnya yang membuat BERT begitu istimewa, dan untuk apa BERT digunakan? Untuk menjawab pertanyaan ini, kita perlu melihat lebih dekat dasar-dasar teknis BERT, cara kerjanya, dan aplikasinya.
📚 1. Dasar-dasar pemrosesan bahasa alami
Untuk sepenuhnya memahami signifikansi BERT, ada baiknya untuk meninjau secara singkat dasar-dasar pemrosesan bahasa alami (NLP). NLP berkaitan dengan interaksi antara komputer dan bahasa manusia. Tujuannya adalah untuk mengajari mesin menganalisis, memahami, dan menanggapi data tekstual. Sebelum diperkenalkannya model seperti BERT, pemrosesan bahasa mesin seringkali penuh dengan tantangan yang signifikan, terutama karena ambiguitas, ketergantungan konteks, dan struktur kompleks bahasa manusia.
📈 2. Pengembangan model NLP
Sebelum BERT muncul, sebagian besar model NLP didasarkan pada arsitektur yang disebut searah. Ini berarti bahwa model-model ini membaca teks dari kiri ke kanan atau dari kanan ke kiri, yang berarti mereka hanya dapat mempertimbangkan sejumlah konteks terbatas saat memproses sebuah kata dalam kalimat. Keterbatasan ini seringkali mengakibatkan model gagal menangkap sepenuhnya konteks semantik sebuah kalimat. Hal ini membuat interpretasi yang akurat terhadap kata-kata yang ambigu atau sensitif terhadap konteks menjadi sulit.
Perkembangan penting lainnya dalam penelitian NLP sebelum BERT adalah model word2vec, yang memungkinkan komputer untuk menerjemahkan kata-kata menjadi vektor yang mencerminkan kesamaan semantik. Namun, bahkan di sini, konteksnya terbatas pada lingkungan terdekat dari sebuah kata. Kemudian, Jaringan Neural Berulang (RNN) dan, khususnya, model Long Short-Term Memory (LSTM) dikembangkan, yang memungkinkan pemahaman yang lebih baik tentang urutan teks dengan menyimpan informasi di banyak kata. Namun, model-model ini juga memiliki keterbatasan, terutama ketika berurusan dengan teks panjang dan secara bersamaan memahami konteks dalam dua arah.
🔄 3. Revolusi melalui Arsitektur Transformator
Terobosan tersebut terjadi dengan diperkenalkannya arsitektur Transformer pada tahun 2017, yang menjadi dasar BERT. Model Transformer dirancang untuk memungkinkan pemrosesan teks paralel, dengan mempertimbangkan konteks sebuah kata dari teks sebelumnya dan sesudahnya. Hal ini dicapai melalui mekanisme yang disebut self-attention, yang memberikan nilai bobot pada setiap kata dalam kalimat berdasarkan kepentingannya relatif terhadap kata-kata lain dalam kalimat tersebut.
Berbeda dengan pendekatan sebelumnya, model transformer tidak searah tetapi dua arah. Ini berarti model ini dapat mengambil informasi dari konteks kiri dan kanan suatu kata untuk menciptakan representasi kata dan maknanya yang lebih lengkap dan akurat.
🧠 4. BERT: Sebuah Model Dua Arah
BERT membawa kinerja arsitektur Transformer ke tingkat yang baru. Model ini dirancang untuk menangkap konteks sebuah kata tidak hanya dari kiri ke kanan atau kanan ke kiri, tetapi dalam kedua arah secara bersamaan. Hal ini memungkinkan BERT untuk mempertimbangkan konteks lengkap sebuah kata dalam sebuah kalimat, sehingga menghasilkan peningkatan akurasi yang signifikan dalam tugas pemrosesan bahasa alami.
Salah satu fitur utama BERT adalah penggunaan apa yang disebut Model Bahasa Bertopeng (Masked Language Model/MLM). Selama pelatihan BERT, kata-kata yang dipilih secara acak dalam sebuah kalimat diganti dengan topeng, dan model dilatih untuk menebak kata-kata bertopeng ini berdasarkan konteksnya. Teknik ini memungkinkan BERT untuk mempelajari hubungan yang lebih dalam dan lebih tepat antara kata-kata dalam sebuah kalimat.
Selain itu, BERT menggunakan metode yang disebut Next Sentence Prediction (NSP), di mana model belajar memprediksi apakah satu kalimat mengikuti kalimat lainnya. Hal ini meningkatkan kemampuan BERT untuk memahami teks yang lebih panjang dan mengenali hubungan yang lebih kompleks antar kalimat.
🌐 5. Penerapan Praktis BERT
BERT telah terbukti sangat berguna untuk berbagai macam tugas NLP. Berikut adalah beberapa area aplikasi yang paling penting:
📊 a) Klasifikasi teks
Salah satu aplikasi BERT yang paling umum adalah klasifikasi teks, di mana teks dibagi ke dalam kategori yang telah ditentukan sebelumnya. Contohnya termasuk analisis sentimen (misalnya, mengenali apakah suatu teks positif atau negatif) atau kategorisasi umpan balik pelanggan. Karena pemahamannya yang mendalam tentang konteks kata, BERT dapat memberikan hasil yang lebih tepat daripada model sebelumnya.
❓ b) Sistem tanya jawab
BERT juga digunakan dalam sistem tanya jawab, di mana model tersebut mengekstrak jawaban atas pertanyaan yang diajukan dari sebuah teks. Kemampuan ini sangat penting dalam aplikasi seperti mesin pencari, chatbot, dan asisten virtual. Berkat arsitektur dua arahnya, BERT dapat mengekstrak informasi yang relevan dari sebuah teks bahkan jika pertanyaannya dirumuskan secara tidak langsung.
🌍 c) Terjemahan teks
Meskipun BERT sendiri tidak dirancang secara langsung sebagai model terjemahan, ia dapat digunakan bersama dengan teknologi lain untuk meningkatkan terjemahan mesin. Dengan lebih memahami hubungan semantik dalam sebuah kalimat, BERT dapat membantu menghasilkan terjemahan yang lebih akurat, terutama untuk frasa yang ambigu atau kompleks.
🏷️ d) Pengenalan Entitas Bernama (NER)
Bidang aplikasi lainnya adalah Pengenalan Entitas Bernama (Named Entity Recognition/NER), yang melibatkan identifikasi entitas spesifik seperti nama, tempat, atau organisasi dalam sebuah teks. BERT telah terbukti sangat efektif dalam tugas ini karena sepenuhnya mempertimbangkan konteks kalimat dan dengan demikian dapat mengenali entitas dengan lebih baik, bahkan jika entitas tersebut memiliki arti yang berbeda dalam konteks yang berbeda.
✂️ e) Ringkasan teks
Kemampuan BERT untuk memahami seluruh konteks teks juga menjadikannya alat yang ampuh untuk peringkasan teks otomatis. BERT dapat digunakan untuk mengekstrak informasi terpenting dari teks panjang dan membuat ringkasan yang ringkas.
🌟 6. Pentingnya BERT bagi penelitian dan industri
Pengenalan BERT mengantarkan era baru dalam penelitian NLP. BERT merupakan salah satu model pertama yang sepenuhnya memanfaatkan kekuatan arsitektur transformer dua arah, menetapkan standar bagi banyak model selanjutnya. Banyak perusahaan dan lembaga penelitian telah mengintegrasikan BERT ke dalam alur kerja NLP mereka untuk meningkatkan kinerja aplikasi mereka.
Selain itu, BERT membuka jalan bagi inovasi lebih lanjut di bidang model bahasa. Misalnya, model seperti GPT (Generative Pretrained Transformer) dan T5 (Text-to-Text Transfer Transformer) kemudian dikembangkan, yang didasarkan pada prinsip serupa tetapi menawarkan peningkatan spesifik untuk berbagai kasus penggunaan.
🚧 7. Tantangan dan keterbatasan BERT
Terlepas dari banyak keunggulannya, BERT juga memiliki beberapa tantangan dan keterbatasan. Salah satu kendala terbesar adalah tingginya upaya komputasi yang dibutuhkan untuk melatih dan menerapkan model tersebut. Karena BERT merupakan model yang sangat besar dengan jutaan parameter, ia membutuhkan perangkat keras yang canggih dan sumber daya komputasi yang signifikan, terutama saat memproses dataset yang besar.
Masalah lain adalah potensi bias yang mungkin ada dalam data pelatihan. Karena BERT dilatih menggunakan sejumlah besar data tekstual, terkadang model ini mencerminkan prasangka dan stereotip yang ada dalam data tersebut. Namun, para peneliti terus berupaya untuk mengidentifikasi dan mengatasi masalah ini.
🔍 Alat yang sangat diperlukan untuk aplikasi pemrosesan suara modern
BERT telah secara signifikan meningkatkan cara mesin memahami bahasa manusia. Dengan arsitektur dua arahnya dan metode pelatihan yang inovatif, BERT mampu memahami konteks kata dalam sebuah kalimat secara mendalam dan akurat, sehingga menghasilkan presisi yang lebih tinggi dalam banyak tugas NLP. Baik dalam klasifikasi teks, sistem tanya jawab, atau pengenalan entitas, BERT telah membuktikan dirinya sebagai alat yang sangat diperlukan untuk aplikasi pemrosesan bahasa alami modern.
Penelitian di bidang pemrosesan bahasa alami tidak diragukan lagi akan terus maju, dan BERT telah meletakkan dasar bagi banyak inovasi di masa depan. Terlepas dari tantangan dan keterbatasan yang ada, BERT secara mengesankan menunjukkan seberapa jauh teknologi telah berkembang dalam waktu singkat dan peluang menarik apa yang masih akan terbuka di masa depan.
🌀 Transformer: Sebuah revolusi dalam pemrosesan bahasa alami
🌟 Dalam beberapa tahun terakhir, salah satu perkembangan paling signifikan dalam pemrosesan bahasa alami (NLP) adalah pengenalan model Transformer, seperti yang dijelaskan dalam makalah tahun 2017 "Attention Is All You Need." Model ini secara fundamental mengubah bidang ini dengan menyingkirkan struktur rekuren atau konvolusional yang sebelumnya digunakan untuk tugas transduksi urutan, seperti penerjemahan mesin. Sebaliknya, model ini secara eksklusif bergantung pada mekanisme perhatian. Desain Transformer sejak itu menjadi dasar bagi banyak model yang mewakili teknologi terkini di berbagai bidang, termasuk pembangkitan ucapan, penerjemahan, dan lainnya.
🔄 Sang Transformator: Pergeseran Paradigma
Sebelum diperkenalkannya Transformer, sebagian besar model untuk tugas-tugas sekuens didasarkan pada jaringan saraf berulang (RNN) atau jaringan memori jangka pendek panjang (LSTM), yang secara inheren beroperasi secara sekuensial. Model-model ini memproses data masukan langkah demi langkah, menciptakan keadaan tersembunyi yang disebarkan sepanjang sekuens. Meskipun metode ini efektif, metode ini mahal secara komputasi dan sulit untuk diparalelkan, terutama untuk sekuens yang panjang. Selain itu, RNN kesulitan mempelajari ketergantungan jangka panjang karena masalah gradien yang menghilang (vanishing gradient problem).
Inovasi utama Transformer terletak pada penggunaan mekanisme self-attention, yang memungkinkan model untuk menimbang pentingnya kata-kata yang berbeda dalam sebuah kalimat relatif satu sama lain, terlepas dari posisinya. Hal ini memungkinkan model untuk menangkap hubungan antara kata-kata yang berjauhan secara lebih efektif daripada RNN atau LSTM, dan melakukannya secara paralel daripada berurutan. Ini tidak hanya meningkatkan efisiensi pelatihan tetapi juga kinerja dalam tugas-tugas seperti penerjemahan mesin.
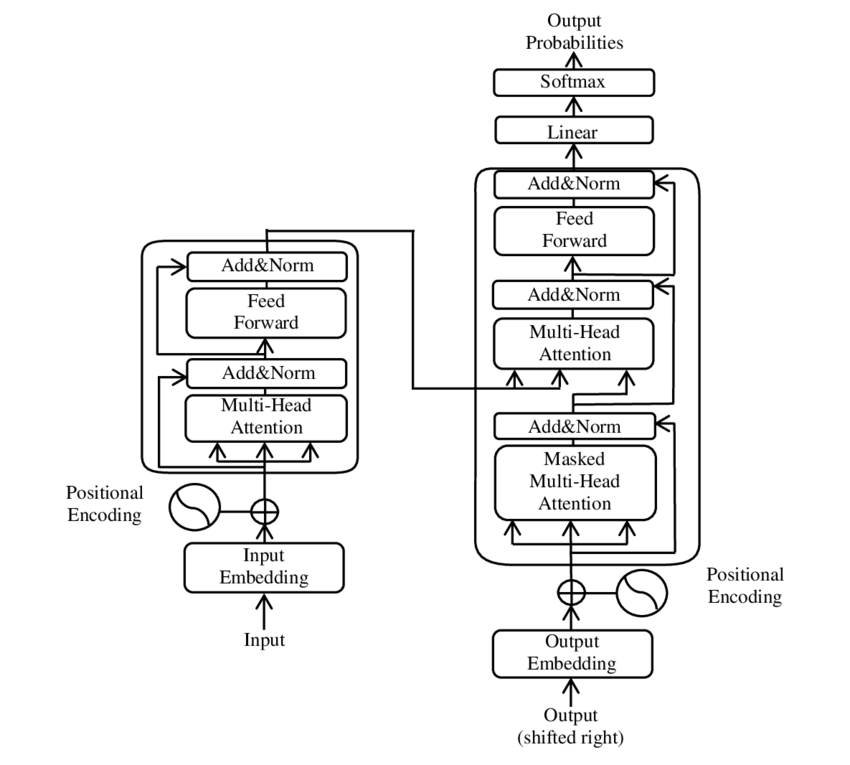
🧩 Arsitektur model
Transformator terdiri dari dua komponen utama: encoder dan decoder, yang keduanya terdiri dari beberapa lapisan dan sangat bergantung pada mekanisme perhatian multi-kepala.
⚙️ Encoder
Encoder tersebut terdiri dari enam lapisan identik, masing-masing dengan dua sublapisan:
1. Perhatian Diri Multi-Kepala
Mekanisme ini memungkinkan model untuk fokus pada bagian-bagian berbeda dari kalimat masukan saat memproses setiap kata. Alih-alih menghitung perhatian dalam satu ruang tunggal, perhatian multi-kepala memproyeksikan masukan ke beberapa ruang berbeda, sehingga menangkap berbagai jenis hubungan antar kata.
2. Jaringan feedforward yang terhubung sepenuhnya secara posisional
Setelah lapisan perhatian, jaringan feedforward yang terhubung sepenuhnya diterapkan secara independen di setiap posisi. Ini membantu model memproses setiap kata dalam konteks dan memanfaatkan informasi dari mekanisme perhatian.
Untuk mempertahankan struktur urutan input, model ini juga menyertakan pengkodean posisi. Karena transformer tidak memproses kata-kata secara berurutan, pengkodean ini sangat penting untuk memberikan informasi kepada model tentang urutan kata dalam sebuah kalimat. Pengkodean posisi ditambahkan ke embedding kata sehingga model dapat membedakan antara posisi yang berbeda dalam urutan tersebut.
🔍 Dekoder
Seperti halnya encoder, decoder juga terdiri dari enam lapisan, masing-masing dengan mekanisme perhatian tambahan yang memungkinkan model untuk fokus pada bagian-bagian relevan dari urutan input saat menghasilkan output. Decoder juga menggunakan teknik masking untuk mencegahnya mempertimbangkan posisi di masa mendatang, sehingga mempertahankan sifat autoregresif dari pembangkitan urutan.
🧠 Perhatian multi-kepala dan perhatian produk skalar
Inti dari Transformer adalah mekanisme perhatian multi-kepala, yang merupakan perluasan dari perhatian produk skalar yang lebih sederhana. Fungsi perhatian dapat dilihat sebagai pemetaan antara kueri dan sekumpulan pasangan kunci-nilai, di mana setiap kunci mewakili sebuah kata dalam urutan dan nilai mewakili informasi kontekstual yang sesuai.
Mekanisme perhatian multi-kepala memungkinkan model untuk fokus pada bagian-bagian berbeda dari urutan secara bersamaan. Dengan memproyeksikan input ke dalam beberapa subruang, model dapat menangkap serangkaian hubungan yang lebih kaya antar kata. Ini sangat berguna untuk tugas-tugas seperti penerjemahan mesin, di mana pemahaman konteks suatu kata membutuhkan banyak faktor berbeda, seperti struktur sintaksis dan makna semantik.
Rumus untuk perhatian produk skalar adalah:

Di sini, (Q) adalah matriks kueri, (K) matriks kunci, dan (V) matriks nilai. Istilah (sqrt{d_k}) adalah faktor penskalaan yang mencegah produk skalar menjadi terlalu besar, yang akan menyebabkan gradien yang sangat kecil dan pembelajaran yang lebih lambat. Fungsi softmax diterapkan untuk memastikan bahwa bobot perhatian berjumlah satu.
🚀 Keunggulan Transformator
Transformer menawarkan beberapa keunggulan penting dibandingkan model tradisional seperti RNN dan LSTM:
1. Paralelisasi
Karena transformer memproses semua token dalam sebuah urutan secara bersamaan, ia dapat diparalelkan secara tinggi dan oleh karena itu jauh lebih cepat untuk dilatih daripada RNN atau LSTM, terutama dengan dataset yang besar.
2. Ketergantungan jangka panjang
Mekanisme self-attention memungkinkan model untuk menangkap hubungan antara kata-kata yang berjauhan secara lebih efektif daripada RNN, yang dibatasi oleh sifat sekuensial dari komputasinya.
3. Skalabilitas
Transformer ini dapat dengan mudah diskalakan untuk menangani dataset yang sangat besar dan urutan yang lebih panjang tanpa mengalami hambatan kinerja yang terkait dengan RNN.
🌍 Aplikasi dan efek
Sejak diperkenalkan, Transformer telah menjadi dasar bagi berbagai macam model NLP. Salah satu contoh yang paling terkenal adalah BERT (Bidirectional Encoder Representations from Transformers), yang menggunakan arsitektur Transformer yang dimodifikasi untuk mencapai kinerja terbaik dalam banyak tugas NLP, termasuk menjawab pertanyaan dan klasifikasi teks.
Perkembangan penting lainnya adalah GPT (Generative Pretrained Transformer), yang menggunakan versi transformer dengan keterbatasan decoder untuk menghasilkan teks. Model GPT, termasuk GPT-3, kini digunakan untuk berbagai aplikasi, mulai dari pembuatan konten hingga penyelesaian kode.
🔍 Model yang andal dan fleksibel
Transformer telah secara fundamental mengubah cara kita mendekati tugas-tugas NLP. Ia menawarkan model yang ampuh dan fleksibel yang dapat diterapkan pada berbagai macam masalah. Kemampuannya untuk menangani ketergantungan jangka panjang dan efisiensinya dalam pelatihan telah menjadikannya pendekatan arsitektur pilihan untuk banyak model modern. Seiring perkembangan penelitian, kita kemungkinan akan melihat peningkatan dan adaptasi lebih lanjut dari Transformer, khususnya di bidang-bidang seperti pemrosesan gambar dan ucapan, di mana mekanisme perhatian menunjukkan hasil yang menjanjikan.
Kami siap membantu Anda - saran - perencanaan - implementasi - manajemen proyek
☑️ Pakar industri, dengan Xpert miliknya sendiri. Pusat industri digital dengan lebih dari 2.500 artikel spesialis

Konrad Wolfenstein
Saya akan dengan senang hati menjadi penasihat pribadi Anda.
Anda dapat menghubungi saya dengan mengisi formulir kontak di bawah ini atau cukup hubungi saya di +49 89 89 674 804 (Munich) .
Saya menantikan proyek bersama kita.
Menulis kepada saya

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital adalah pusat industri dengan fokus pada digitalisasi, teknik mesin, logistik/intralogistik, dan fotovoltaik.
Dengan solusi pengembangan bisnis 360°, kami mendukung perusahaan terkenal mulai dari bisnis baru hingga purna jual.
Kecerdasan pasar, pemasaran, otomasi pemasaran, pengembangan konten, PR, kampanye surat, media sosial yang dipersonalisasi, dan pemeliharaan prospek adalah bagian dari alat digital kami.
Anda dapat mengetahui lebih lanjut di: www.xpert.digital - www.xpert.solar - www.xpert.plus
Tetap berhubungan


















