
Upaya untuk menjelaskan AI: Bagaimana cara kerja dan fungsi kecerdasan buatan – bagaimana cara melatihnya?

Pemilihan suara 📢
Diterbitkan pada: 8 September 2024 / Pembaruan dari: 9 September 2024 - Penulis: Konrad Wolfenstein

Upaya untuk menjelaskan AI: Bagaimana cara kerja kecerdasan buatan dan bagaimana cara melatihnya? – Gambar: Xpert.Digital
📊 Dari input data hingga prediksi model: Proses AI
Bagaimana cara kerja kecerdasan buatan (AI)? 🤖
Cara kerja kecerdasan buatan (AI) dapat dibagi menjadi beberapa langkah yang jelas. Masing-masing langkah ini sangat penting untuk hasil akhir yang diberikan oleh AI. Prosesnya dimulai dengan entri data dan diakhiri dengan prediksi model dan kemungkinan umpan balik atau putaran pelatihan lebih lanjut. Fase-fase ini menggambarkan proses yang dilalui hampir semua model AI, terlepas dari apakah model tersebut merupakan kumpulan aturan sederhana atau jaringan saraf yang sangat kompleks.
1. Masukan datanya 📊
Dasar dari semua kecerdasan buatan adalah data yang digunakannya. Data tersebut bisa dalam berbagai bentuk, misalnya gambar, teks, file audio atau video. AI menggunakan data mentah ini untuk mengenali pola dan membuat keputusan. Kualitas dan kuantitas data memainkan peran sentral di sini, karena keduanya memiliki pengaruh yang signifikan terhadap seberapa baik atau buruknya model tersebut bekerja nantinya.
Semakin luas dan tepat datanya, semakin baik kemampuan AI untuk belajar. Misalnya, ketika AI dilatih untuk pemrosesan gambar, AI memerlukan sejumlah besar data gambar untuk mengidentifikasi berbagai objek dengan benar. Dengan model bahasa, data tekslah yang membantu AI memahami dan menghasilkan bahasa manusia. Input data adalah langkah pertama dan salah satu langkah terpenting, karena kualitas prediksi hanya akan sebaik data yang mendasarinya. Prinsip terkenal dalam ilmu komputer menjelaskan hal ini dengan pepatah “Sampah masuk, sampah keluar” – data yang buruk akan menghasilkan hasil yang buruk.
2. Pemrosesan awal data 🧹
Setelah data dimasukkan, data tersebut perlu dipersiapkan sebelum dapat dimasukkan ke dalam model sebenarnya. Proses ini disebut prapemrosesan data. Tujuannya disini adalah untuk memasukkan data ke dalam bentuk yang dapat diolah secara optimal oleh model.
Langkah umum dalam prapemrosesan adalah normalisasi data. Artinya data dibawa ke dalam rentang nilai yang seragam sehingga model memperlakukannya secara merata. Contohnya adalah menskalakan semua nilai piksel suatu gambar ke kisaran 0 hingga 1, bukan 0 hingga 255.
Bagian penting lainnya dari prapemrosesan adalah apa yang disebut ekstraksi fitur. Fitur-fitur tertentu diambil dari data mentah yang sangat relevan dengan model. Dalam pemrosesan gambar, misalnya, ini bisa berupa tepian atau pola warna tertentu, sedangkan dalam teks, kata kunci atau struktur kalimat yang relevan diekstraksi. Pemrosesan awal sangat penting untuk membuat proses pembelajaran AI lebih efisien dan tepat.
3. Modelnya 🧩
Model adalah jantung dari setiap kecerdasan buatan. Di sini data dianalisis dan diolah berdasarkan algoritma dan perhitungan matematis. Sebuah model bisa ada dalam berbagai bentuk. Salah satu model yang paling terkenal adalah jaringan saraf, yang didasarkan pada cara kerja otak manusia.
Jaringan saraf terdiri dari beberapa lapisan neuron buatan yang memproses dan meneruskan informasi. Setiap lapisan mengambil keluaran dari lapisan sebelumnya dan memprosesnya lebih lanjut. Proses pembelajaran jaringan saraf terdiri dari penyesuaian bobot koneksi antar neuron sehingga jaringan dapat membuat prediksi atau klasifikasi yang semakin akurat. Adaptasi ini terjadi melalui pelatihan, di mana jaringan mengakses data sampel dalam jumlah besar dan secara berulang meningkatkan parameter internalnya (bobot).
Selain jaringan saraf, banyak juga algoritma lain yang digunakan dalam model AI. Ini termasuk pohon keputusan, hutan acak, mesin vektor pendukung dan banyak lainnya. Algoritme mana yang digunakan bergantung pada tugas spesifik dan data yang tersedia.
4. Prediksi model 🔍
Setelah model dilatih dengan data, model mampu membuat prediksi. Langkah ini disebut prediksi model. AI menerima masukan dan mengembalikan keluaran, yaitu prediksi atau keputusan, berdasarkan pola yang telah dipelajarinya selama ini.
Prediksi ini bisa bermacam-macam bentuknya. Misalnya, dalam model klasifikasi gambar, AI dapat memprediksi objek mana yang terlihat dalam suatu gambar. Dalam model bahasa, ia dapat membuat prediksi kata mana yang muncul berikutnya dalam sebuah kalimat. Dalam prediksi keuangan, AI dapat memprediksi bagaimana kinerja pasar saham.
Penting untuk ditekankan bahwa keakuratan prediksi sangat bergantung pada kualitas data pelatihan dan arsitektur model. Model yang dilatih dengan data yang tidak memadai atau bias kemungkinan besar akan menghasilkan prediksi yang salah.
5. Umpan balik dan pelatihan (opsional) ♻️
Bagian penting lainnya dari kerja AI adalah mekanisme umpan balik. Model ini diperiksa secara berkala dan dioptimalkan lebih lanjut. Proses ini terjadi selama pelatihan atau setelah prediksi model.
Jika model membuat prediksi yang salah, model dapat belajar melalui umpan balik untuk mendeteksi kesalahan ini dan menyesuaikan parameter internalnya. Hal ini dilakukan dengan membandingkan prediksi model dengan hasil sebenarnya (misalnya dengan data yang diketahui namun sudah ada jawaban yang benar). Prosedur khas dalam konteks ini adalah apa yang disebut pembelajaran terawasi, di mana AI belajar dari contoh data yang sudah diberikan dengan jawaban yang benar.
Metode umpan balik yang umum adalah algoritma propagasi mundur yang digunakan dalam jaringan saraf. Kesalahan yang dibuat model disebarkan mundur melalui jaringan untuk menyesuaikan bobot koneksi neuron. Model ini belajar dari kesalahannya dan menjadi semakin tepat dalam prediksinya.
Peran pelatihan 🏋️♂️
Melatih AI adalah proses yang berulang. Semakin banyak data yang dilihat model dan semakin sering model dilatih berdasarkan data ini, semakin akurat prediksinya. Namun, ada juga batasannya: model yang terlalu terlatih dapat mengalami apa yang disebut masalah “overfitting”. Artinya, ia mengingat data pelatihan dengan sangat baik sehingga memberikan hasil yang lebih buruk pada data baru yang tidak diketahui. Oleh karena itu, penting untuk melatih model agar dapat menggeneralisasi dan membuat prediksi yang baik bahkan pada data baru.
Selain pelatihan reguler, ada juga prosedur seperti transfer learning. Di sini, model yang telah dilatih pada data dalam jumlah besar digunakan untuk tugas baru yang serupa. Hal ini menghemat waktu dan daya komputasi karena model tidak harus dilatih dari awal.
Manfaatkan kekuatan Anda semaksimal mungkin 🚀
Pekerjaan kecerdasan buatan didasarkan pada interaksi kompleks dari berbagai langkah. Mulai dari entri data, prapemrosesan, pelatihan model, prediksi, dan umpan balik, ada banyak faktor yang memengaruhi akurasi dan efisiensi AI. AI yang terlatih dapat memberikan manfaat besar di banyak bidang kehidupan - mulai dari mengotomatisasi tugas-tugas sederhana hingga memecahkan masalah yang kompleks. Namun, memahami keterbatasan dan potensi kelemahan AI juga penting untuk memanfaatkan kelebihannya.
🤖📚 Dijelaskan secara sederhana: Bagaimana AI dilatih?
🤖📊 Proses pembelajaran AI: tangkap, tautkan, dan simpan
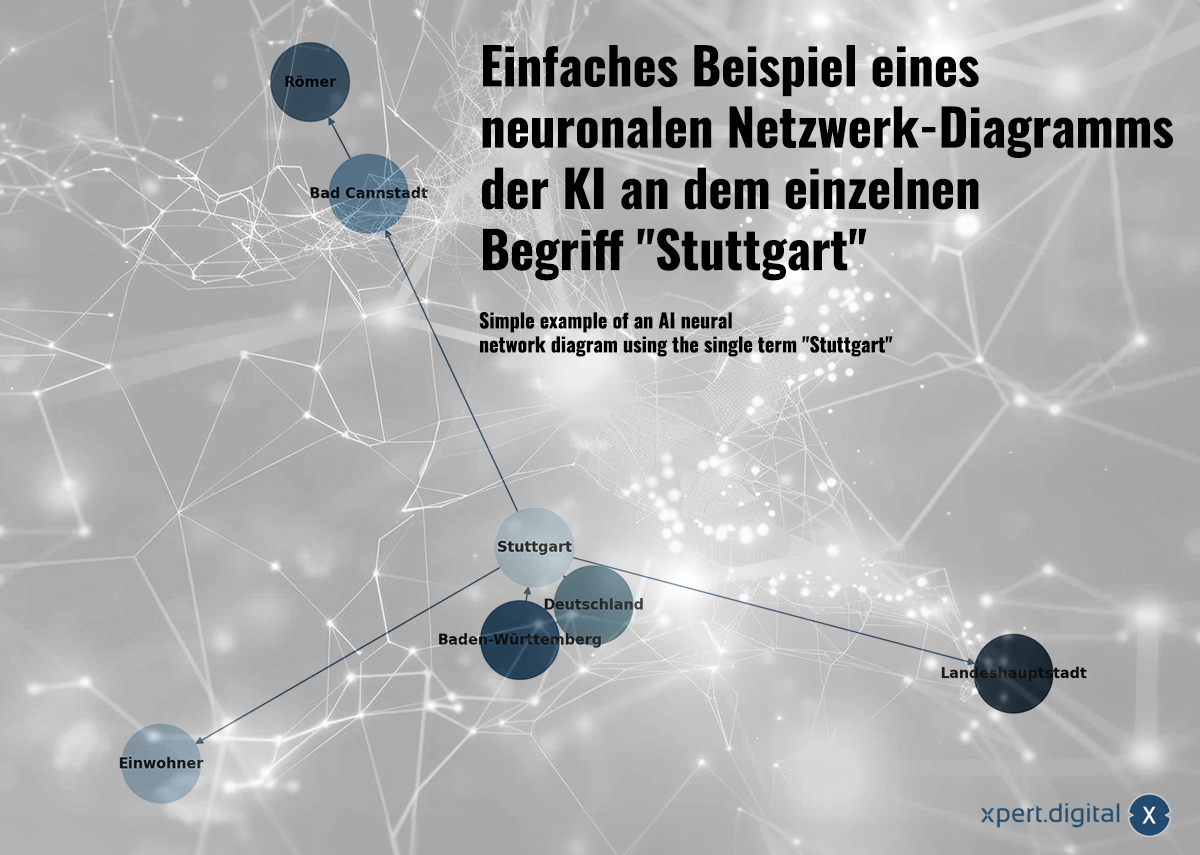
Contoh sederhana dari diagram jaringan neuron AI pada istilah individu "stuttgart" -image: xpert.digital
🌟 Kumpulkan dan siapkan data
Langkah pertama dalam proses pembelajaran AI adalah mengumpulkan dan menyiapkan data. Data ini bisa berasal dari berbagai sumber, seperti database, sensor, teks atau gambar.
🌟 Data terkait (Jaringan Syaraf Tiruan)
Data yang dikumpulkan saling terkait satu sama lain dalam jaringan saraf. Setiap paket data ditunjukkan oleh koneksi dalam jaringan "neuron" (node). Contoh sederhana dengan kota Stuttgart bisa terlihat seperti ini:
a) Stuttgart adalah sebuah kota di Baden-Württemberg
b) Baden-Württemberg adalah sebuah negara federal di Jerman
c) Stuttgart adalah sebuah kota di Jerman
d) Stuttgart mempunyai populasi 633.484 jiwa pada tahun 2023
e) Bad Cannstatt adalah sebuah distrik di Stuttgart
f) Bad Cannstatt didirikan oleh orang Romawi
g) Stuttgart adalah ibu kota negara bagian Baden-Württemberg
Bergantung pada ukuran volume data, parameter potensi pengeluaran dibuat menggunakan model AI yang digunakan. Sebagai contoh: GPT-3 memiliki sekitar 175 miliar parameter!
🌟 Penyimpanan dan penyesuaian (pembelajaran)
Data diumpankan ke jaringan saraf. Mereka melalui model AI dan diproses melalui koneksi (mirip dengan sinapsis). Bobot (parameter) antar neuron disesuaikan untuk melatih model atau melaksanakan tugas.
Berbeda dengan bentuk memori konvensional seperti akses langsung, akses yang ditunjukkan, penyimpanan berurutan atau tumpukan, jaringan saraf menyimpan data dengan cara yang tidak konvensional. "Data" disimpan dalam bobot dan bias koneksi antara neuron.
"Penyimpanan" sebenarnya dari informasi dalam jaringan neuron terjadi dengan mengadaptasi bobot koneksi antara neuron. Model AI “belajar” dengan terus mengadaptasi bobot dan bias ini berdasarkan data input dan algoritma pembelajaran yang ditentukan. Ini adalah proses berkelanjutan di mana model dapat membuat prediksi yang tepat karena penyesuaian berulang.
Model AI dapat dianggap sebagai jenis pemrograman karena dibuat melalui algoritma yang ditentukan dan perhitungan matematis dan terus meningkatkan penyesuaian parameternya (bobot) untuk membuat prediksi yang akurat. Ini adalah proses yang berkelanjutan.
Bias adalah parameter tambahan dalam jaringan saraf yang ditambahkan ke nilai masukan tertimbang suatu neuron. Mereka memungkinkan parameter diberi bobot (penting, kurang penting, penting, dll.), membuat AI lebih fleksibel dan akurat.
Jaringan saraf tidak hanya dapat menyimpan fakta individual, tetapi juga mengenali hubungan antar data melalui pengenalan pola. Contoh Stuttgart mengilustrasikan bagaimana pengetahuan dapat dimasukkan ke dalam jaringan saraf, namun jaringan saraf tidak belajar melalui pengetahuan eksplisit (seperti dalam contoh sederhana ini) tetapi melalui analisis pola data. Jaringan saraf tidak hanya dapat menyimpan fakta individual, tetapi juga mempelajari bobot dan hubungan antara data masukan.
Alur ini memberikan pengenalan yang dapat dipahami tentang cara kerja AI dan jaringan saraf pada khususnya, tanpa mendalami detail teknisnya. Hal ini menunjukkan bahwa penyimpanan informasi pada jaringan syaraf tiruan tidak dilakukan seperti pada database tradisional, melainkan dengan mengatur koneksi (bobot) di dalam jaringan.
🤖📚 Lebih detail: Bagaimana AI dilatih?
🏋️♂️ Pelatihan AI, khususnya model pembelajaran mesin, dilakukan dalam beberapa langkah. Pelatihan AI didasarkan pada pengoptimalan parameter model secara terus-menerus melalui umpan balik dan penyesuaian hingga model menunjukkan performa terbaik berdasarkan data yang diberikan. Berikut adalah penjelasan rinci tentang cara kerja proses ini:
1. 📊 Mengumpulkan dan menyiapkan data
Data adalah dasar dari pelatihan AI. Mereka biasanya terdiri dari ribuan atau jutaan contoh untuk dianalisis oleh sistem. Contohnya adalah gambar, teks, atau data deret waktu.
Data harus dibersihkan dan dinormalisasi untuk menghindari sumber kesalahan yang tidak perlu. Seringkali data diubah menjadi fitur yang berisi informasi yang relevan.
2. 🔍 Tentukan modelnya
Model adalah fungsi matematika yang menggambarkan hubungan dalam data. Dalam jaringan saraf, yang sering digunakan untuk AI, modelnya terdiri dari beberapa lapisan neuron yang terhubung bersama.
Setiap neuron melakukan operasi matematika untuk memproses data masukan dan kemudian meneruskan sinyal ke neuron berikutnya.
3. 🔄 Inisialisasi bobot
Koneksi antar neuron memiliki bobot yang awalnya ditetapkan secara acak. Bobot ini menentukan seberapa kuat neuron merespons suatu sinyal.
Tujuan pelatihan adalah untuk menyesuaikan bobot tersebut sehingga model dapat membuat prediksi yang lebih baik.
4. ➡️ Propagasi Maju
Forward pass meneruskan data masukan melalui model untuk menghasilkan prediksi.
Setiap lapisan memproses data dan meneruskannya ke lapisan berikutnya hingga lapisan terakhir memberikan hasilnya.
5. ⚖️ Hitung fungsi kerugian
Fungsi kerugian mengukur seberapa baik prediksi model dibandingkan dengan nilai sebenarnya (label). Ukuran yang umum adalah kesalahan antara respons yang diprediksi dan respons aktual.
Semakin tinggi kerugiannya, semakin buruk prediksi model tersebut.
6. 🔙 Propagasi mundur
Dalam backward pass, kesalahan diumpankan kembali dari keluaran model ke lapisan sebelumnya.
Kesalahan didistribusikan kembali ke bobot koneksi dan model menyesuaikan bobot sehingga kesalahan menjadi lebih kecil.
Hal ini dilakukan dengan menggunakan penurunan gradien: vektor gradien dihitung, yang menunjukkan bagaimana bobot harus diubah untuk meminimalkan kesalahan.
7. 🔧 Perbarui bobot
Setelah kesalahan dihitung, bobot koneksi diperbarui dengan sedikit penyesuaian berdasarkan kecepatan pembelajaran.
Kecepatan pemelajaran menentukan seberapa besar perubahan bobot pada setiap langkah. Perubahan yang terlalu besar dapat membuat model tidak stabil, dan perubahan yang terlalu kecil menyebabkan lambatnya proses pembelajaran.
8. 🔁 Ulangi (Epoch)
Proses penerusan ke depan, penghitungan kesalahan, dan pembaruan bobot ini diulangi, sering kali selama beberapa periode (melewati seluruh kumpulan data), hingga model mencapai akurasi yang dapat diterima.
Pada setiap periode, model belajar lebih banyak dan menyesuaikan bobotnya lebih lanjut.
9. 📉 Validasi dan pengujian
Setelah model dilatih, model tersebut diuji pada kumpulan data yang divalidasi untuk memeriksa seberapa baik model tersebut digeneralisasi. Hal ini memastikan bahwa ia tidak hanya “menghafal” data pelatihan, namun juga membuat prediksi yang baik pada data yang tidak diketahui.
Data pengujian membantu mengukur performa akhir model sebelum digunakan dalam praktik.
10. 🚀 Optimasi
Langkah-langkah tambahan untuk menyempurnakan model mencakup penyetelan hyperparameter (misalnya menyesuaikan kecepatan pembelajaran atau struktur jaringan), regularisasi (untuk menghindari overfitting), atau meningkatkan jumlah data.
📊🔙 Kecerdasan buatan: Jadikan kotak hitam AI dapat dimengerti, dipahami, dan dijelaskan dengan AI yang Dapat Dijelaskan (XAI), peta panas, model pengganti, atau solusi lainnya

Kecerdasan buatan: Menjadikan kotak hitam AI dapat dimengerti, dipahami, dan dijelaskan dengan AI yang Dapat Dijelaskan (XAI), peta panas, model pengganti, atau solusi lainnya - Gambar: Xpert.Digital
Apa yang disebut “kotak hitam” kecerdasan buatan (AI) mewakili masalah yang signifikan dan terkini. Bahkan para ahli sering kali dihadapkan pada tantangan karena tidak dapat sepenuhnya memahami bagaimana sistem AI mengambil keputusan. Kurangnya transparansi dapat menyebabkan permasalahan yang signifikan, khususnya di bidang-bidang penting seperti ekonomi, politik atau kedokteran. Seorang dokter atau profesional medis yang mengandalkan sistem AI untuk mendiagnosis dan merekomendasikan terapi harus yakin dengan keputusan yang diambil. Namun, jika pengambilan keputusan yang dilakukan oleh AI tidak cukup transparan, ketidakpastian dan kemungkinan kurangnya kepercayaan akan muncul - dalam situasi yang dapat membahayakan nyawa manusia.
Lebih lanjut tentang itu di sini:
Kami siap membantu Anda - saran - perencanaan - implementasi - manajemen proyek
☑️ Dukungan UKM dalam strategi, konsultasi, perencanaan dan implementasi
☑️ Penciptaan atau penataan kembali strategi digital dan digitalisasi
☑️ Perluasan dan optimalisasi proses penjualan internasional
☑️ Platform perdagangan B2B Global & Digital
☑️ Pelopor Pengembangan Bisnis

Konrad Wolfenstein
Saya akan dengan senang hati menjadi penasihat pribadi Anda.
Anda dapat menghubungi saya dengan mengisi formulir kontak di bawah ini atau cukup hubungi saya di +49 89 89 674 804 (Munich) .
Saya menantikan proyek bersama kita.
Menulis kepada saya

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital adalah pusat industri dengan fokus pada digitalisasi, teknik mesin, logistik/intralogistik, dan fotovoltaik.
Dengan solusi pengembangan bisnis 360°, kami mendukung perusahaan terkenal mulai dari bisnis baru hingga purna jual.
Kecerdasan pasar, pemasaran, otomasi pemasaran, pengembangan konten, PR, kampanye surat, media sosial yang dipersonalisasi, dan pemeliharaan prospek adalah bagian dari alat digital kami.
Anda dapat mengetahui lebih lanjut di: www.xpert.digital - www.xpert.solar - www.xpert.plus
Tetap berhubungan


















