


Upaya menjelaskan AI: Bagaimana cara kerja kecerdasan buatan dan bagaimana cara melatihnya? – Gambar: Xpert.Digital
📊 Dari input data hingga prediksi model: Proses AI
Bagaimana cara kerja kecerdasan buatan (AI)? 🤖
Cara kerja kecerdasan buatan (AI) dapat dibagi menjadi beberapa langkah yang jelas. Setiap langkah ini sangat penting untuk hasil akhir yang diberikan oleh AI. Proses dimulai dengan input data dan berakhir dengan prediksi model serta umpan balik atau putaran pelatihan lebih lanjut. Fase-fase ini menggambarkan proses yang hampir semua model AI lalui, terlepas dari apakah itu berupa kumpulan aturan sederhana atau jaringan saraf yang sangat kompleks.
1. Input data 📊
Landasan dari setiap kecerdasan buatan adalah data yang digunakannya. Data ini dapat berupa berbagai bentuk, seperti gambar, teks, file audio, atau video. AI menggunakan data mentah ini untuk mengenali pola dan membuat keputusan. Kualitas dan kuantitas data memainkan peran penting di sini, karena secara signifikan memengaruhi seberapa baik atau buruk kinerja model tersebut pada akhirnya.
Semakin komprehensif dan akurat datanya, semakin baik kemampuan AI dalam belajar. Misalnya, saat melatih AI untuk pemrosesan gambar, dibutuhkan sejumlah besar data gambar untuk mengidentifikasi berbagai objek dengan benar. Untuk model bahasa, data tekslah yang membantu AI memahami dan menghasilkan ucapan manusia. Input data adalah langkah pertama dan salah satu yang terpenting, karena kualitas prediksi hanya akan sebaik data yang mendasarinya. Prinsip terkenal dalam ilmu komputer menggambarkan hal ini dengan pepatah "sampah masuk, sampah keluar"—data yang buruk menghasilkan hasil yang buruk.
2. Praproses data 🧹
Setelah data dimasukkan, data tersebut harus dipersiapkan sebelum dapat dimasukkan ke dalam model sebenarnya. Proses ini disebut pra-pemrosesan data. Tujuannya adalah untuk mengubah data ke dalam format yang dapat diproses secara optimal oleh model.
Salah satu langkah umum dalam pra-pemrosesan adalah normalisasi data. Ini berarti membawa data ke dalam rentang nilai yang seragam sehingga diperlakukan secara konsisten oleh model. Contohnya adalah menskalakan semua nilai piksel gambar ke rentang 0 hingga 1, bukan 0 hingga 255.
Bagian penting lain dari pra-pemrosesan adalah ekstraksi fitur. Ini melibatkan ekstraksi fitur spesifik dari data mentah yang sangat relevan dengan model. Dalam pemrosesan gambar, ini bisa berupa tepi atau pola warna tertentu, sedangkan dalam pemrosesan teks, kata kunci atau struktur kalimat yang relevan diekstrak. Pra-pemrosesan sangat penting untuk membuat proses pembelajaran AI lebih efisien dan tepat.
3. Model 🧩
Model adalah inti dari setiap kecerdasan buatan. Di sini, data dianalisis dan diproses berdasarkan algoritma dan perhitungan matematis. Sebuah model dapat hadir dalam berbagai bentuk. Salah satu model yang paling terkenal adalah jaringan saraf, yang didasarkan pada cara kerja otak manusia.
Jaringan saraf terdiri dari beberapa lapisan neuron buatan yang memproses dan meneruskan informasi. Setiap lapisan mengambil keluaran dari lapisan sebelumnya dan memprosesnya lebih lanjut. Proses pembelajaran jaringan saraf melibatkan penyesuaian bobot koneksi antar neuron ini sehingga jaringan dapat membuat prediksi atau klasifikasi yang semakin akurat. Penyesuaian ini dicapai melalui pelatihan, di mana jaringan mengakses sejumlah besar data contoh dan secara iteratif meningkatkan parameter internalnya (bobot).
Selain jaringan saraf, banyak algoritma lain yang digunakan dalam model AI. Ini termasuk pohon keputusan, hutan acak, mesin vektor pendukung, dan banyak lagi. Algoritma mana yang digunakan bergantung pada tugas spesifik dan data yang tersedia.
4. Prakiraan model 🔍
Setelah model dilatih dengan data, model tersebut mampu membuat prediksi. Langkah ini disebut prediksi model. AI menerima input dan, berdasarkan pola yang telah dipelajarinya sejauh ini, mengembalikan output, yaitu prediksi atau keputusan.
Prediksi ini dapat mengambil berbagai bentuk. Misalnya, dalam model klasifikasi gambar, AI dapat memprediksi objek apa yang ditampilkan dalam sebuah gambar. Dalam model bahasa, AI dapat memprediksi kata apa yang akan muncul selanjutnya dalam sebuah kalimat. Dalam prediksi keuangan, AI dapat meramalkan bagaimana kinerja pasar saham.
Penting untuk ditekankan bahwa akurasi prediksi sangat bergantung pada kualitas data pelatihan dan arsitektur model. Model yang dilatih dengan data yang tidak memadai atau bias sangat mungkin menghasilkan prediksi yang salah.
5. Umpan balik dan pelatihan (opsional) ♻️
Aspek penting lainnya dari cara kerja AI adalah mekanisme umpan balik. Di sini, model diperiksa secara berkala dan dioptimalkan lebih lanjut. Proses ini berlangsung selama pelatihan atau setelah prediksi model.
Jika model membuat prediksi yang salah, model dapat belajar melalui umpan balik untuk mengenali kesalahan ini dan menyesuaikan parameter internalnya sesuai dengan itu. Hal ini dilakukan dengan membandingkan prediksi model dengan hasil aktual (misalnya, dengan data yang sudah diketahui di mana jawaban yang benar sudah ada). Metode umum dalam konteks ini adalah apa yang disebut pembelajaran terawasi (supervised learning), di mana AI belajar dari data contoh yang sudah berisi jawaban yang benar.
Salah satu metode umpan balik yang umum adalah algoritma backpropagation yang digunakan dalam jaringan saraf. Di sini, kesalahan yang dibuat oleh model disebarkan mundur melalui jaringan untuk menyesuaikan bobot koneksi saraf. Dengan cara ini, model belajar dari kesalahannya dan menjadi semakin akurat dalam prediksinya.
Peran pelatihan 🏋️♂️
Melatih AI adalah proses iteratif. Semakin banyak data yang dilihat model dan semakin sering model tersebut dilatih pada data tersebut, semakin akurat prediksinya. Namun, ada batasnya: Model yang terlalu banyak dilatih dapat mengembangkan masalah yang disebut "overfitting". Ini berarti bahwa model tersebut menghafal data pelatihan dengan sangat baik sehingga menghasilkan hasil yang lebih buruk pada data baru yang tidak dikenal. Oleh karena itu, penting untuk melatih model sedemikian rupa sehingga dapat melakukan generalisasi, artinya model tersebut juga dapat membuat prediksi yang baik pada data baru.
Selain pelatihan reguler, ada juga metode seperti transfer learning. Di sini, model yang telah dilatih pada dataset besar digunakan untuk tugas baru yang serupa. Ini menghemat waktu dan daya komputasi, karena model tidak perlu dilatih sepenuhnya dari awal.
Manfaatkan kekuatanmu sebaik-baiknya 🚀
Cara kerja kecerdasan buatan (AI) didasarkan pada interaksi kompleks dari berbagai tahapan. Mulai dari input dan pra-pemrosesan data hingga pelatihan model, prediksi, dan umpan balik, banyak faktor yang memengaruhi akurasi dan efisiensi AI. AI yang terlatih dengan baik dapat menawarkan keuntungan besar di banyak bidang kehidupan—mulai dari mengotomatiskan tugas-tugas sederhana hingga memecahkan masalah kompleks. Namun, sama pentingnya untuk memahami keterbatasan dan potensi jebakan AI agar dapat memanfaatkan kekuatannya sebaik mungkin.
🤖📚 Penjelasan sederhana: Bagaimana cara melatih AI?
🤖📊 Proses pembelajaran AI: Tangkap, tautkan, dan simpan
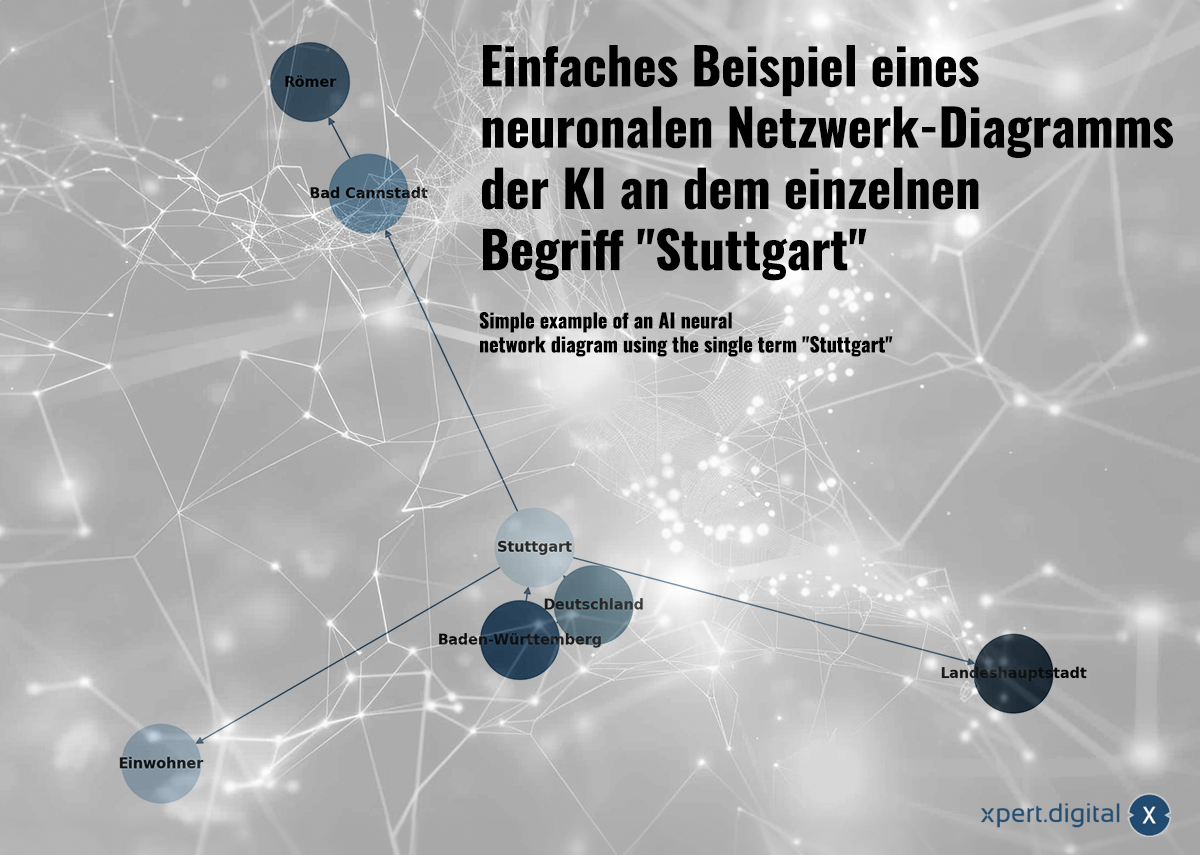
Contoh sederhana diagram jaringan saraf AI menggunakan satu istilah "Stuttgart" – Gambar: Xpert.Digital
🌟 Kumpulkan dan siapkan data
Langkah pertama dalam proses pembelajaran AI adalah mengumpulkan dan mempersiapkan data. Data ini dapat berasal dari berbagai sumber, seperti basis data, sensor, teks, atau gambar.
🌟 Hubungan antar data (Jaringan saraf)
Data yang terkumpul dihubungkan bersama dalam jaringan saraf. Setiap paket data direpresentasikan oleh koneksi dalam jaringan "neuron" (node). Contoh sederhana menggunakan kota Stuttgart dapat terlihat seperti ini:
a) Stuttgart adalah kota di Baden-Württemberg
b) Baden-Württemberg adalah negara bagian federal di Jerman
c) Stuttgart adalah kota di Jerman
d) Stuttgart memiliki populasi 633.484 jiwa pada tahun 2023
e) Bad Cannstatt adalah distrik di Stuttgart
f) Bad Cannstatt didirikan oleh bangsa Romawi
g) Stuttgart adalah ibu kota negara bagian Baden-Württemberg
Bergantung pada ukuran volume data, parameter untuk potensi keluaran dihasilkan menggunakan model AI. Misalnya, GPT-3 memiliki sekitar 175 miliar parameter!
🌟 Menyimpan dan menyesuaikan (pembelajaran)
Data dimasukkan ke dalam jaringan saraf. Data tersebut melewati model AI dan diproses melalui koneksi (mirip dengan sinapsis). Bobot (parameter) antar neuron disesuaikan untuk melatih model atau untuk melakukan suatu tugas.
Berbeda dengan metode penyimpanan konvensional seperti akses langsung, akses terindeks, penyimpanan sekuensial atau batch, jaringan saraf menyimpan data dengan cara yang tidak konvensional. "Data" tersebut disimpan dalam bobot dan bias koneksi antar neuron.
Penyimpanan informasi sebenarnya dalam jaringan saraf terjadi melalui penyesuaian bobot koneksi antar neuron. Model AI "belajar" dengan terus menyesuaikan bobot dan bias ini berdasarkan data masukan dan algoritma pembelajaran yang telah ditentukan. Ini adalah proses berkelanjutan di mana model dapat membuat prediksi yang lebih tepat melalui penyesuaian berulang.
Model AI dapat dilihat sebagai semacam pemrograman, karena dibuat melalui algoritma dan perhitungan matematis yang telah ditentukan, dan penyesuaian parameternya (bobot) terus ditingkatkan untuk membuat prediksi yang akurat. Ini adalah proses yang berkelanjutan.
Bias adalah parameter tambahan dalam jaringan saraf yang ditambahkan ke nilai input berbobot dari sebuah neuron. Bias memungkinkan parameter diberi bobot (penting, kurang penting, dll.), sehingga membuat AI lebih fleksibel dan akurat.
Jaringan saraf tidak hanya dapat menyimpan fakta individual, tetapi juga mengenali hubungan antar data melalui pengenalan pola. Contoh dengan Stuttgart menggambarkan bagaimana pengetahuan dapat dimasukkan ke dalam jaringan saraf, tetapi jaringan saraf tidak belajar melalui pengetahuan eksplisit (seperti dalam contoh sederhana ini), melainkan melalui analisis pola data. Oleh karena itu, jaringan saraf tidak hanya dapat menyimpan fakta individual, tetapi juga mempelajari bobot dan hubungan antar data masukan.
Proses ini memberikan pengantar yang mudah dipahami tentang cara kerja AI, dan jaringan saraf khususnya, tanpa terlalu深入 ke detail teknis. Ini menunjukkan bahwa informasi tidak disimpan dalam jaringan saraf seperti pada basis data konvensional, melainkan dengan menyesuaikan koneksi (bobot) di dalam jaringan.
🤖📚 Secara lebih detail: Bagaimana cara melatih AI?
🏋️♂️ Melatih AI, terutama model pembelajaran mesin, melibatkan beberapa langkah. Pelatihan AI didasarkan pada optimasi parameter model secara terus menerus melalui umpan balik dan penyesuaian hingga model berkinerja terbaik pada data yang diberikan. Berikut penjelasan rinci tentang cara kerja proses ini:
1. 📊 Kumpulkan dan siapkan data
Data adalah fondasi pelatihan AI. Biasanya terdiri dari ribuan atau jutaan contoh yang akan dianalisis oleh sistem. Contohnya termasuk gambar, teks, atau data deret waktu.
Data harus dibersihkan dan dinormalisasi untuk menghindari sumber kesalahan yang tidak perlu. Seringkali, data diubah menjadi fitur yang berisi informasi yang relevan.
2. 🔍 Definisikan model
Model adalah fungsi matematika yang menggambarkan hubungan dalam data. Dalam jaringan saraf, yang sering digunakan untuk AI, model terdiri dari beberapa lapisan neuron yang saling terhubung.
Setiap neuron melakukan operasi matematika untuk memproses data masukan dan kemudian meneruskan sinyal ke neuron berikutnya.
3. 🔄 Inisialisasi bobot
Koneksi antar neuron memiliki bobot yang awalnya ditetapkan secara acak. Bobot ini menentukan seberapa kuat neuron merespons suatu sinyal.
Tujuan dari pelatihan ini adalah untuk menyesuaikan bobot-bobot tersebut agar model dapat membuat prediksi yang lebih baik.
4. ➡️ Perambatan Maju
Selama proses pemrosesan data maju (forward pass), data masukan diproses oleh model untuk mendapatkan prediksi.
Setiap lapisan memproses data dan meneruskannya ke lapisan berikutnya hingga lapisan terakhir memberikan hasilnya.
5. ⚖️ Hitung fungsi kerugian
Fungsi kerugian mengukur seberapa baik prediksi model dibandingkan dengan nilai sebenarnya (label). Ukuran umum yang digunakan adalah kesalahan antara respons yang diprediksi dan respons sebenarnya.
Semakin tinggi kerugiannya, semakin buruk prediksi model tersebut.
6. 🔙 Backpropagation
Pada iterasi terbalik, kesalahan ditelusuri kembali dari output model ke lapisan sebelumnya.
Kesalahan tersebut didistribusikan kembali ke bobot koneksi, dan model menyesuaikan bobot sehingga kesalahan menjadi lebih kecil.
Hal ini dilakukan menggunakan penurunan gradien: Vektor gradien dihitung, yang menunjukkan bagaimana bobot harus diubah untuk meminimalkan kesalahan.
7. 🔧 Perbarui berat badan
Setelah kesalahan dihitung, bobot koneksi diperbarui dengan penyesuaian kecil berdasarkan laju pembelajaran.
Tingkat pembelajaran menentukan seberapa besar bobot diubah pada setiap langkah. Perubahan yang terlalu besar dapat membuat model tidak stabil, sedangkan perubahan yang terlalu kecil menyebabkan proses pembelajaran yang lambat.
8. 🔁 Ulangi (Zaman)
Proses penerusan data (forward pass), perhitungan kesalahan, dan pembaruan bobot ini diulang, seringkali selama beberapa epoch (pengulangan melalui seluruh dataset), hingga model mencapai akurasi yang dapat diterima.
Seiring berjalannya waktu, model tersebut belajar sedikit demi sedikit dan menyesuaikan bobotnya lebih lanjut.
9. 📉 Validasi dan Pengujian
Setelah model dilatih, model tersebut diuji pada dataset yang telah divalidasi untuk memeriksa seberapa baik kemampuan generalisasinya. Hal ini memastikan bahwa model tersebut tidak hanya "menghafal" data pelatihan, tetapi juga membuat prediksi yang baik pada data yang tidak dikenal.
Data uji membantu mengukur kinerja akhir model sebelum digunakan dalam praktik.
10. 🚀 Optimasi
Langkah selanjutnya untuk meningkatkan model meliputi penyetelan hyperparameter (misalnya, menyesuaikan laju pembelajaran atau struktur jaringan), regularisasi (untuk menghindari overfitting), atau meningkatkan jumlah data.
📊🔙 Kecerdasan Buatan: Membuat kotak hitam AI menjadi mudah dipahami, dimengerti, dan dijelaskan dengan AI yang Dapat Dijelaskan (XAI), peta panas, model pengganti, atau solusi lainnya


Kecerdasan Buatan: Membuat kotak hitam AI menjadi mudah dipahami, dimengerti, dan dijelaskan dengan AI yang Dapat Dijelaskan (XAI), peta panas, model pengganti, atau solusi lainnya – Gambar: Xpert.Digital
Yang disebut "kotak hitam" kecerdasan buatan (AI) merupakan masalah yang signifikan dan mendesak. Bahkan para ahli pun sering menghadapi tantangan karena tidak dapat sepenuhnya memahami bagaimana sistem AI mengambil keputusan. Kurangnya transparansi ini dapat menyebabkan masalah yang cukup besar, terutama di bidang-bidang kritis seperti ekonomi, politik, dan kedokteran. Seorang dokter yang bergantung pada sistem AI untuk diagnosis dan rekomendasi pengobatan harus memiliki kepercayaan pada keputusan yang dibuat. Namun, jika proses pengambilan keputusan AI tidak cukup transparan, ketidakpastian akan muncul, yang berpotensi menyebabkan kurangnya kepercayaan—dan ini dalam situasi di mana nyawa manusia bisa dipertaruhkan.
Informasi selengkapnya di sini:
Kami hadir untuk Anda - Konsultasi - Perencanaan - Implementasi - Manajemen Proyek
☑️ Dukungan UKM dalam strategi, konsultasi, perencanaan, dan implementasi
☑️ Pembuatan atau penyesuaian kembali strategi digital dan digitalisasi
☑️ Perluasan dan optimalisasi proses penjualan internasional
☑️ Platform perdagangan B2B global & digital
☑️ Pengembangan Bisnis Perintis

Konrad Wolfenstein
Saya akan dengan senang hati menjadi penasihat pribadi Anda.
Anda dapat menghubungi saya dengan mengisi formulir kontak di bawah ini atau cukup hubungi saya di +49 7348 4088 965 .
Saya sangat menantikan proyek bersama kita.
Tulis surat kepadaku




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital adalah pusat bagi industri yang berfokus pada digitalisasi, teknik mesin, logistik/intralogistik, dan fotovoltaik.
Dengan solusi Pengembangan Bisnis 360° kami, kami mendukung perusahaan-perusahaan ternama mulai dari bisnis baru hingga layanan purna jual.
Intelijen pasar, smarketing, otomatisasi pemasaran, pengembangan konten, PR, kampanye email, media sosial yang dipersonalisasi, dan pembinaan prospek adalah bagian dari alat digital kami.
Anda dapat menemukan informasi lebih lanjut di: www.xpert.digital - www.xpert.solar - www.xpert.plus
Tetaplah berhubungan











