
AI és SEO a BERT-tel – Transformers kétirányú kódolóábrázolásai – modell a természetes nyelvi feldolgozás (NLP) területén

Hangválasztás 📢
Megjelent: 2024. október 4. / Frissítve: 2024. október 4. – Szerző: Konrad Wolfenstein

MI és SEO BERT segítségével – Kétirányú kódoló reprezentációk transzformátorokból – Modell a természetes nyelvi feldolgozás (NLP) területén – Kép: Xpert.Digital
🚀💬 A Google fejlesztése: BERT és jelentősége az NLP számára - Miért kulcsfontosságú a kétirányú szövegértés?
🔍🗣️ A BERT, a Transformers kétirányú kódoló reprezentációinak rövidítése, a Google által fejlesztett jelentős modell a természetes nyelvi feldolgozás (NLP) területén. Forradalmasította a gépek nyelvi megértését. A korábbi modellekkel ellentétben, amelyek balról jobbra vagy fordítva szekvenciálisan elemezték a szöveget, a BERT kétirányú feldolgozást tesz lehetővé. Ez azt jelenti, hogy egy szó kontextusát mind az azt megelőző, mind a következő szövegszekvenciákból megragadja. Ez a képesség jelentősen javítja az összetett nyelvi kapcsolatok megértését.
🔍 A BERT architektúrája
Az utóbbi években a természetes nyelvi feldolgozás (NLP) egyik legjelentősebb fejleménye a Transformer modell bevezetése volt, amelyet a 2017-es „Attention is all you need” ( Wikipédia ) című PDF-cikk ismertet. Ez a modell alapvetően megváltoztatta a területet azáltal, hogy elvetette a korábban használt struktúrákat, például a gépi fordítást. Ehelyett kizárólag a figyelmi mechanizmusokra támaszkodik. A Transformer modell azóta számos olyan modell alapját képezte, amelyek a legmodernebb technológiákat képviselik különböző területeken, beleértve a beszédgenerálást, a fordítást és azon túl.
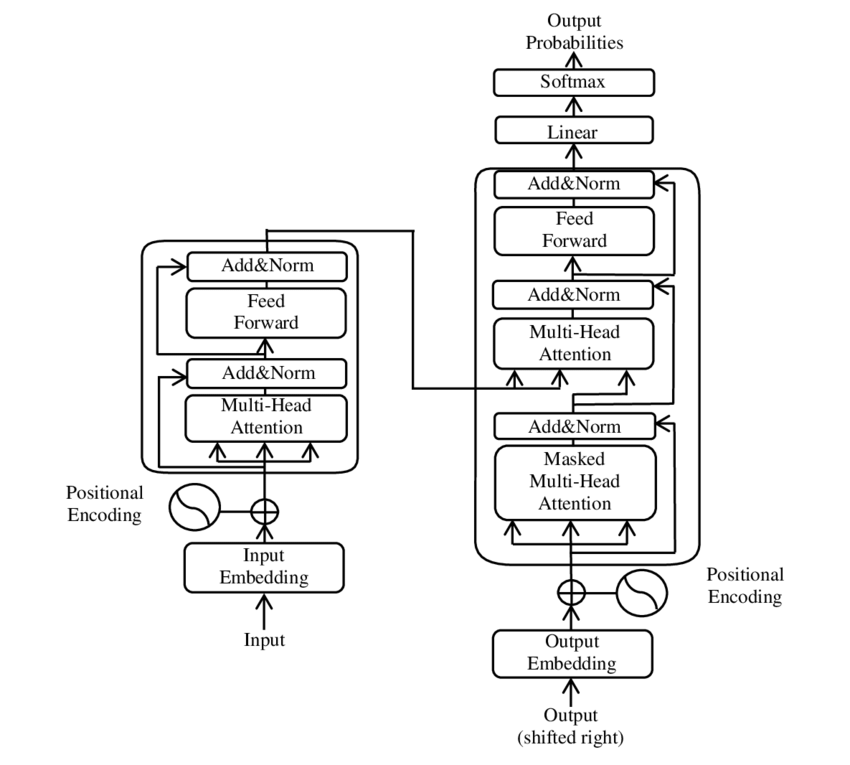
A Transformer modell főbb alkotóelemeinek illusztrációja – Kép: Google
A BERT ezen a transzformátor architektúrán alapul. Ez az architektúra úgynevezett önfigyelő mechanizmusokat használ a szavak közötti kapcsolatok elemzésére egy mondatban. Minden egyes szóra a teljes mondat kontextusában figyelünk, ami a szintaktikai és szemantikai kapcsolatok pontosabb megértéséhez vezet.
A „Csak figyelem kell” című tanulmány szerzői:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Oroszlán Jones (Google Kutatás)
- Aidan N. Gomez (Torontói Egyetem, munka részben a Google Brainnél)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (független, korábbi munka a Google Researchnél)
Ezek a szerzők jelentős mértékben hozzájárultak a cikkben bemutatott Transformer modell kidolgozásához.
🔄 Kétirányú feldolgozás
A BERT egyik kulcsfontosságú jellemzője, hogy képes a szöveg kétirányú feldolgozására. Míg a hagyományos modellek, mint például a rekurens neurális hálózatok (RNN) vagy a hosszú rövid távú memóriájú (LSTM) hálózatok, csak egy irányban dolgozzák fel a szöveget, a BERT mindkét irányban elemzi a szó kontextusát. Ez lehetővé teszi a modell számára, hogy jobban megragadja a jelentés finom árnyalatait, és így pontosabb előrejelzéseket tegyen.
🕵️♂️ Maszkos beszédmodellezés
A BERT egy másik innovatív aspektusa az álarcos nyelvi modell (MLM) technika. Itt a mondatban véletlenszerűen kiválasztott szavakat maszkolják, és a modellt arra képezik ki, hogy a környező kontextus alapján megjósolja ezeket a szavakat. Ez a módszer arra kényszeríti a BERT-et, hogy mélyrehatóan megértse a mondat minden egyes szavának kontextusát és jelentését.
🚀 A BERT képzése és adaptálása
A BERT kétlépcsős betanítási folyamaton megy keresztül: előképzésen és finomhangoláson.
📚 Előképzés
Az előképzés során a BERT-et nagy mennyiségű szöveggel képezik ki általános nyelvi minták elsajátítására. Ez magában foglalja a Wikipédia-cikkeket és más kiterjedt szöveges korpuszokat. Ebben a fázisban a modell alapvető nyelvi struktúrákat és kontextusokat tanul meg.
🔧 Finomhangolás
Az előtanítás után a BERT-et specifikus természetes nyelvi programozási feladatokhoz, például szövegosztályozáshoz vagy érzelemelemzéshez igazítják. A modellt kisebb, feladatspecifikus adathalmazokkal képezik ki, hogy optimalizálják a teljesítményét az adott alkalmazásokhoz.
🌍 A BERT alkalmazási területei
A BERT számos területen bizonyult rendkívül hasznosnak a természetes nyelvi feldolgozásban:
Keresőoptimalizálás
A Google a BERT-et használja a keresési lekérdezések jobb megértéséhez és relevánsabb találatok megjelenítéséhez. Ez jelentősen javítja a felhasználói élményt.
Szöveg osztályozása
A BERT képes témák szerint kategorizálni a dokumentumokat, vagy elemezni a szövegek hangulatát.
Megnevezett entitás felismerés (NER)
A modell azonosítja és osztályozza a szövegekben található elnevezett entitásokat, például személyek, helyek vagy szervezetek nevét.
Kérdés-válasz rendszerek
A BERT-et arra használják, hogy pontos válaszokat adjon a feltett kérdésekre.
🧠 A BERT jelentősége a mesterséges intelligencia jövője szempontjából
A BERT új mércét állított fel az NLP modellek számára, és utat nyitott a további innovációknak. Kétirányú feldolgozási képességének és a nyelvi kontextusok mélyreható megértésének köszönhetően jelentősen növelte a mesterséges intelligencia alkalmazások hatékonyságát és pontosságát.
🔜 Jövőbeli fejlemények
A BERT és hasonló modellek további fejlesztése várhatóan még hatékonyabb rendszerek létrehozását célozza majd. Ezek összetettebb nyelvi feladatokat is képesek lesznek kezelni, és számos új alkalmazási területen használhatók lesznek. Az ilyen modellek integrálása a mindennapi technológiákba alapvetően megváltoztathatja a számítógépekkel való interakciónkat.
🌟 Mérföldkő a mesterséges intelligencia fejlődésében
A BERT mérföldkő a mesterséges intelligencia fejlesztésében, és forradalmasította a gépek természetes nyelvi feldolgozásának módját. Kétirányú architektúrája lehetővé teszi a nyelvi kapcsolatok mélyebb megértését, így nélkülözhetetlenné válik számos alkalmazás számára. A kutatás előrehaladtával az olyan modellek, mint a BERT, továbbra is központi szerepet fognak játszani a mesterséges intelligencia rendszerek fejlesztésében és új lehetőségek megnyitásában a használatukhoz.
📣 Hasonló témák
- 📚 Bevezetés a BERT-be: Az úttörő NLP modell
- 🔍 BERT és a kétirányúság szerepe az NLP-ben
- 🧠 A Transformer modell: A BERT alapjai
- 🚀 Álarcos nyelvi modellezés: A BERT sikerének kulcsa
- 📈 BERT testreszabás: Az előképzéstől a finomhangolásig
- 🌐 A BERT alkalmazási területei a modern technológiában
- 🤖 A BERT hatása a mesterséges intelligencia jövőjére
- 💡 Jövőbeli kilátások: A BERT további fejlesztései
- 🏆 A BERT mérföldkő a mesterséges intelligencia fejlesztésében
- 📰 A Transformer „Attention Is All You Need” című tanulmány szerzői: A BERT mögött álló elmék
#️⃣ Hashtagek: #NLP #MesterségesIntelligencia #NyelvModellezés #Transformer #GépiTanulás
🎯🎯🎯 Profitáljon az Xpert.Digital széleskörű, ötszörös szakértelméből egy átfogó szolgáltatáscsomagban | BD, K+F, XR, PR és digitális láthatóság optimalizálása

Profitáljon az Xpert.Digital széleskörű, ötszörös szakértelméből egy átfogó szolgáltatáscsomagban | K+F, XR, PR és digitális láthatóság optimalizálása - Kép: Xpert.Digital
Az Xpert.Digital mélyreható ismeretekkel rendelkezik a különböző iparágakról. Ez lehetővé teszi számunkra, hogy személyre szabott stratégiákat dolgozzunk ki, amelyek pontosan az Ön konkrét piaci szegmensének követelményeihez és kihívásaihoz igazodnak. A piaci trendek folyamatos elemzésével és az iparági fejlemények követésével előrelátóan tudunk cselekedni és innovatív megoldásokat kínálni. A tapasztalat és a tudás ötvözésével hozzáadott értéket generálunk, és ügyfeleink számára meghatározó versenyelőnyt biztosítunk.
Bővebben itt:
BERT: Forradalmi 🌟 NLP technológia
🚀 A BERT, a Transformers kétirányú kódoló reprezentációinak rövidítése, egy Google által fejlesztett fejlett nyelvi modell, amely jelentős áttörést jelentett a természetes nyelvi feldolgozásban (NLP) a 2018-as bevezetése óta. A Transformer architektúrán alapul, amely forradalmasította a gépek szövegértését és -feldolgozását. De mi teszi pontosan a BERT-et ilyen különlegessé, és mire használják? A kérdés megválaszolásához közelebbről meg kell vizsgálnunk a BERT technikai alapjait, működését és alkalmazásait.
📚 1. A természetes nyelvi feldolgozás alapjai
A BERT jelentőségének teljes megértéséhez érdemes röviden áttekinteni a természetes nyelvi feldolgozás (NLP) alapjait. Az NLP a számítógépek és az emberi nyelv közötti interakcióval foglalkozik. Célja, hogy megtanítsa a gépeket a szöveges adatok elemzésére, megértésére és azokra való reagálásra. Az olyan modellek, mint a BERT, bevezetése előtt a gépi nyelvi feldolgozás gyakran jelentős kihívásokkal volt tele, különösen az emberi nyelv kétértelműsége, kontextusfüggősége és összetett szerkezete miatt.
📈 2. Az NLP modellek fejlesztése
A BERT megjelenése előtt a legtöbb NLP modell úgynevezett egyirányú architektúrákon alapult. Ez azt jelentette, hogy ezek a modellek balról jobbra vagy jobbról balra olvasták a szöveget, ami azt jelentette, hogy egy szó mondatban történő feldolgozásakor csak korlátozott mennyiségű kontextust tudtak figyelembe venni. Ez a korlátozás gyakran oda vezetett, hogy a modellek nem tudták teljes mértékben megragadni a mondat szemantikai kontextusát. Ez megnehezítette a kétértelmű vagy kontextusérzékeny szavak pontos értelmezését.
Az NLP-kutatás egy másik fontos fejleménye a BERT előtt a word2vec modell volt, amely lehetővé tette a számítógépek számára, hogy szavakat a szemantikai hasonlóságokat tükröző vektorokká fordítsanak. Azonban még itt is a kontextus a szó közvetlen környezetére korlátozódott. Később kifejlesztették a rekurrens neurális hálózatokat (RNN) és különösen a hosszú rövid távú memória (LSTM) modelleket, amelyek lehetővé tették a szövegszekvenciák jobb megértését azáltal, hogy több szóban tárolják az információkat. Ezeknek a modelleknek azonban megvoltak a korlátaik is, különösen hosszú szövegek kezelése és a kontextus egyidejű, mindkét irányú megértése esetén.
🔄 3. A transzformátor építészet forradalma
Az áttörést a Transformer architektúra 2017-es bevezetése hozta meg, amely a BERT alapját képezi. A Transformer modelleket úgy tervezték, hogy lehetővé tegyék a párhuzamos szövegfeldolgozást, figyelembe véve egy szó kontextusát mind az előző, mind a következő szövegben. Ezt úgynevezett önfigyelem-mechanizmusokon keresztül érik el, amelyek a mondat minden szavához súlyértéket rendelnek a mondat többi szavához viszonyított fontossága alapján.
A korábbi megközelítésekkel ellentétben a transzformátor modellek nem egyirányúak, hanem kétirányúak. Ez azt jelenti, hogy a szó bal és jobb oldali kontextusából is képesek információt meríteni, hogy a szónak és jelentésének teljesebb és pontosabb ábrázolását hozzák létre.
🧠 4. BERT: Kétirányú modell
A BERT új szintre emeli a Transformer architektúra teljesítményét. A modell úgy lett kialakítva, hogy egy szó kontextusát ne csak balról jobbra vagy jobbról balra, hanem mindkét irányban egyszerre rögzítse. Ez lehetővé teszi a BERT számára, hogy egy szó teljes kontextusát figyelembe vegye egy mondaton belül, ami jelentősen javítja a pontosságot a természetes nyelvi feldolgozási feladatokban.
A BERT egyik kulcsfontosságú jellemzője az úgynevezett Maszkolt Nyelvi Modell (MLM) használata. A BERT betanítása során a mondatban véletlenszerűen kiválasztott szavakat maszkkal helyettesítik, és a modellt arra képezik ki, hogy a kontextus alapján kitalálja ezeket az maszkolt szavakat. Ez a technika lehetővé teszi a BERT számára, hogy mélyebb és pontosabb kapcsolatokat tanuljon meg a mondatban lévő szavak között.
Ezenkívül a BERT egy Következő Mondat Előrejelzés (NSP) nevű módszert is használ, amelyben a modell megtanulja megjósolni, hogy az egyik mondat követi-e a másikat. Ez javítja a BERT azon képességét, hogy megértse a hosszabb szövegeket és felismerje a mondatok közötti összetettebb kapcsolatokat.
🌐 5. A BERT gyakorlati alkalmazása
A BERT rendkívül hasznosnak bizonyult számos NLP-feladatban. Íme néhány a legfontosabb alkalmazási területek közül:
📊 a) Szöveg osztályozása
A BERT egyik leggyakoribb alkalmazása a szövegosztályozás, ahol a szövegeket előre meghatározott kategóriákba sorolják. Ilyen például a hangulatelemzés (pl. annak felismerése, hogy egy szöveg pozitív vagy negatív), vagy az ügyfél-visszajelzések kategorizálása. A szavak kontextusának mélyreható megértése miatt a BERT pontosabb eredményeket tud szolgáltatni, mint a korábbi modellek.
❓ b) Kérdés-felelet rendszerek
A BERT-et kérdés-válasz rendszerekben is használják, ahol a modell a feltett kérdésekre válaszokat nyer ki egy szövegből. Ez a képesség különösen fontos olyan alkalmazásokban, mint a keresőmotorok, chatbotok és virtuális asszisztensek. Kétirányú architektúrájának köszönhetően a BERT releváns információkat tud kinyerni egy szövegből, még akkor is, ha a kérdés közvetett módon van megfogalmazva.
🌍 c) Szövegfordítás
Bár a BERT önmagában nem fordítási modellként lett kifejlesztve, más technológiákkal kombinálva használható a gépi fordítás javítására. A mondatokon belüli szemantikai kapcsolatok jobb megértésével a BERT pontosabb fordításokat generálhat, különösen a kétértelmű vagy összetett megfogalmazások esetén.
🏷️ d) Megnevezett entitás felismerés (NER)
Egy másik alkalmazási terület a megnevezett entitások felismerése (NER), amely konkrét entitások, például nevek, helyek vagy szervezetek azonosítását foglalja magában egy szövegben. A BERT különösen hatékonynak bizonyult ebben a feladatban, mivel teljes mértékben figyelembe veszi a mondat kontextusát, és így jobban felismeri az entitásokat, még akkor is, ha azok különböző kontextusokban eltérő jelentéssel bírnak.
✂️ e) Szöveges összefoglaló
A BERT azon képessége, hogy megérti a szöveg teljes kontextusát, hatékony eszközzé teszi az automatikus szövegösszefoglaláshoz is. Segítségével egy hosszú szövegből is kinyerhetők a legfontosabb információk, és tömör összefoglaló készíthető.
🌟 6. A BERT fontossága a kutatás és az ipar számára
A BERT bevezetése új korszakot nyitott az NLP-kutatásban. Ez volt az egyik első modell, amely teljes mértékben kihasználta a kétirányú transzformátor architektúra erejét, mércét állítva számos későbbi modell számára. Számos vállalat és kutatóintézet integrálta a BERT-et az NLP-folyamataiba, hogy javítsa alkalmazásai teljesítményét.
Továbbá a BERT további innovációkat nyitott a nyelvi modellek területén. Például olyan modelleket fejlesztettek ki, mint a GPT (Generative Pretrained Transformer) és a T5 (Text-to-Text Transfer Transformer), amelyek hasonló elveken alapulnak, de specifikus fejlesztéseket kínálnak a különböző felhasználási esetekhez.
🚧 7. A BERT kihívásai és korlátai
Számos előnye ellenére a BERT-nek vannak kihívásai és korlátai is. Az egyik legnagyobb akadály a modell betanításához és alkalmazásához szükséges nagy számítási erőfeszítés. Mivel a BERT egy nagyon nagy modell, több millió paraméterrel, nagy teljesítményű hardvert és jelentős számítási erőforrásokat igényel, különösen nagy adathalmazok feldolgozásakor.
Egy másik probléma a betanítási adatokban jelenlévő potenciális torzítás. Mivel a BERT-et nagy mennyiségű szöveges adaton tanítják, néha tükrözi az adatokban jelen lévő előítéleteket és sztereotípiákat. A kutatók azonban folyamatosan dolgoznak ezen problémák azonosításán és megoldásán.
🔍 Nélkülözhetetlen eszköz a modern beszédfeldolgozó alkalmazásokhoz
A BERT jelentősen javította a gépek emberi nyelv megértésének módját. Kétirányú architektúrájának és innovatív betanítási módszereinek köszönhetően képes mélyen és pontosan megragadni a mondatokban lévő szavak kontextusát, ami nagyobb pontosságot eredményez számos NLP-feladatban. Legyen szó szövegosztályozásról, kérdés-válasz rendszerekről vagy entitásfelismerésről, a BERT nélkülözhetetlen eszközzé vált a modern természetes nyelvi feldolgozó alkalmazások számára.
A természetes nyelvi feldolgozás területén végzett kutatások kétségtelenül tovább fognak fejlődni, és a BERT számos jövőbeli innováció alapjait rakta le. A meglévő kihívások és korlátok ellenére a BERT lenyűgözően bemutatja, hogy milyen messzire jutott a technológia rövid idő alatt, és milyen izgalmas lehetőségek nyílnak még meg a jövőben.
🌀 A Transformer: Forradalom a természetes nyelvi feldolgozásban
🌟 Az elmúlt években a természetes nyelvi feldolgozás (NLP) egyik legjelentősebb fejleménye a Transformer modell bevezetése volt, amelyet a 2017-es „Attention Is All You Need” című tanulmány ismertet. Ez a modell alapvetően megváltoztatta a területet azáltal, hogy elvetette a korábban használt rekurrens vagy konvolúciós struktúrákat a szekvenciaátviteli feladatokhoz, például a gépi fordításhoz. Ehelyett kizárólag a figyelmi mechanizmusokra támaszkodik. A Transformer modell azóta számos modell alapját képezte, amelyek a legmodernebb technológiákat képviselik különböző területeken, beleértve a beszédgenerálást, a fordítást és azon túl.
🔄 A transzformátor: Paradigmaváltás
A Transformer bevezetése előtt a szekvenciális feladatokhoz használt legtöbb modell rekurens neurális hálózatokon (RNN) vagy hosszú rövid távú memórián (LSTM) alapuló hálózatokon alapult, amelyek eredendően szekvenciálisan működnek. Ezek a modellek lépésről lépésre dolgozzák fel a bemeneti adatokat, rejtett állapotokat hozva létre, amelyek a szekvencián keresztül terjednek. Bár ez a módszer hatékony, számítási szempontból költséges és nehezen párhuzamosítható, különösen hosszú szekvenciák esetén. Továbbá az RNN-ek nehezen tanulják meg a hosszú távú függőségeket az eltűnő gradiens problémája miatt.
A Transformer legfontosabb újítása az önfigyelő mechanizmusok használata, amelyek lehetővé teszik a modell számára, hogy a mondatban lévő különböző szavak fontosságát egymáshoz képest mérlegelje, függetlenül azok pozíciójától. Ez lehetővé teszi a modell számára, hogy a széles körben elválasztott szavak közötti kapcsolatokat hatékonyabban rögzítse, mint az RNN-ek vagy az LSTM-ek, és ezt párhuzamosan, ne pedig egymás után tegye. Ez nemcsak a betanítás hatékonyságát javítja, hanem a teljesítményt olyan feladatokban is, mint a gépi fordítás.
🧩 Modellarchitektúra
A transzformátor két fő komponensből áll: egy kódolóból és egy dekódolóból, amelyek mindegyike több rétegből épül fel, és nagymértékben támaszkodik a többfejes figyelemmechanizmusokra.
⚙️ Kódoló
A kódoló hat azonos rétegből áll, amelyek mindegyikéhez két alréteg tartozik:
1. Többfejű önfigyelem
Ez a mechanizmus lehetővé teszi a modell számára, hogy az egyes szavak feldolgozása során a bemeneti mondat különböző részeire összpontosítson. Ahelyett, hogy egyetlen térben számolná a figyelmet, a többfejű figyelem több különböző térbe vetíti ki a bemenetet, ezáltal rögzítve a szavak közötti különféle kapcsolatokat.
2. Pozicionálisan teljesen összekapcsolt előrecsatolt hálózatok
A figyelem réteget követően egy teljesen összekapcsolt előrecsatolási hálózat kerül alkalmazásra, függetlenül minden pozícióban. Ez segíti a modellt abban, hogy minden szót kontextusban dolgozzon fel, és felhasználja a figyelem mechanizmusból származó információkat.
A bemeneti szekvencia szerkezetének megőrzése érdekében a modell pozíciókódolásokat is tartalmaz. Mivel az átalakító nem szekvenciálisan dolgozza fel a szavakat, ezek a kódolások kulcsfontosságúak ahhoz, hogy a modell információkat kapjon a mondatban lévő szavak sorrendjéről. A pozíciókódolásokat a szavak beágyazásához adják hozzá, hogy a modell különbséget tudjon tenni a szekvencia különböző pozíciói között.
🔍 Dekóder
A kódolóhoz hasonlóan a dekóder is hat rétegből áll, amelyek mindegyike egy további figyelemmechanizmussal rendelkezik, amely lehetővé teszi a modell számára, hogy a bemeneti szekvencia releváns részeire összpontosítson a kimenet generálása közben. A dekóder egy maszkolási technikát is alkalmaz, hogy megakadályozza a jövőbeli pozíciók figyelembevételét, így megőrzi a szekvenciagenerálás autoregresszív jellegét.
🧠 Többfejű figyelem és skaláris termékfigyelem
A Transformer magja a többfejű figyelemmechanizmus, amely az egyszerűbb skaláris szorzat figyelem kiterjesztése. A figyelemfüggvény egy lekérdezés és egy kulcs-érték párok halmaza közötti megfeleltetésként tekinthető, ahol minden kulcs egy szót jelöl a szekvenciában, az érték pedig a megfelelő kontextuális információt jelöli.
A többfejű figyelemmechanizmus lehetővé teszi a modell számára, hogy a szekvencia különböző részeire egyszerre összpontosítson. A bemenet több altérbe való kivetítésével a modell a szavak közötti kapcsolatok gazdagabb halmazát képes rögzíteni. Ez különösen hasznos olyan feladatoknál, mint a gépi fordítás, ahol egy szó kontextusának megértéséhez számos különböző tényező szükséges, például szintaktikai szerkezet és szemantikai jelentés.
A skaláris szorzatfigyelem képlete a következő:
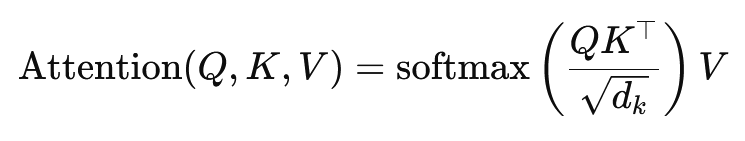
Itt (Q) a lekérdezési mátrix, (K) a kulcsmátrix és (V) az értékmátrix. Az (sqrt{d_k}) tag egy skálázási tényező, amely megakadályozza, hogy a skaláris szorzatok túl naggyá váljanak, ami nagyon kis gradiensekhez és lassabb tanuláshoz vezetne. A softmax függvényt annak biztosítására alkalmazzák, hogy a figyelmi súlyok összege egy legyen.
🚀 A transzformátor előnyei
A Transformer számos lényeges előnyt kínál a hagyományos modellekkel, például az RNN-ekkel és az LSTM-ekkel szemben:
1. Párhuzamosítás
Mivel a transzformátor egy szekvencia összes tokenjét egyszerre dolgozza fel, nagymértékben párhuzamosítható, és ezért sokkal gyorsabban tanítható, mint az RNN-ek vagy az LSTM-ek, különösen nagy adathalmazok esetén.
2. Hosszú távú függőségek
Az önfigyelő mechanizmus lehetővé teszi a modell számára, hogy hatékonyabban rögzítse a távoli szavak közötti kapcsolatokat, mint a RNN-ek, amelyeket a számításaik szekvenciális jellege korlátoz.
3. Skálázhatóság
A transzformátor könnyen skálázható nagyon nagy adathalmazokra és hosszabb szekvenciákra anélkül, hogy az RNN-ekhez kapcsolódó teljesítménybeli szűk keresztmetszetek sújtanák.
🌍 Alkalmazások és effektek
Bevezetése óta a Transformer számos NLP modell alapjává vált. Az egyik legfigyelemreméltóbb példa a BERT (Bidirectional Encoder Representations from Transformers), amely egy módosított Transformer architektúrát használ a legmodernebb teljesítmény eléréséhez számos NLP feladatban, beleértve a kérdésválaszokat és a szövegosztályozást.
Egy másik jelentős fejlesztés a GPT (Generative Pretreated Transformer), amely a transzformátor dekóder-korlátozott változatát használja szöveggeneráláshoz. A GPT modelleket, beleértve a GPT-3-at is, ma már számos alkalmazásban használják, a tartalomkészítéstől a kódkiegészítésig.
🔍 Erőteljes és rugalmas modell
A Transformer alapvetően megváltoztatta az NLP-feladatok megközelítését. Egy hatékony és rugalmas modellt kínál, amely a problémák széles skálájára alkalmazható. A hosszú távú függőségek kezelésére való képessége és a betanításban való hatékonysága tette a legmodernebb modellek számos előnyben részesített architektúrájává. A kutatás előrehaladtával valószínűleg további fejlesztéseket és adaptációkat fogunk látni a Transformer esetében, különösen olyan területeken, mint a kép- és beszédfeldolgozás, ahol a figyelmi mechanizmusok ígéretes eredményeket mutatnak.
Ott vagyunk Önért - tanácsadás - tervezés - kivitelezés - projektmenedzsment
☑️ Iparági szakértő, itt a saját Xpert.Digital ipari központjával, több mint 2500 szakcikkel

Konrad Wolfenstein
Szívesen szolgálok személyes tanácsadójaként.
Felveheti velem a kapcsolatot az alábbi kapcsolatfelvételi űrlap kitöltésével, vagy egyszerűen hívjon a +49 89 89 674 804 (München) .
Nagyon várom a közös projektünket.
Írj nekem

Xpert.Digital - Konrad Wolfenstein
Az Xpert.Digital egy ipari központ, amely a digitalizációra, a gépészetre, a logisztikára/intralogisztikára és a fotovoltaikára összpontosít.
360°-os üzletfejlesztési megoldásunkkal jól ismert cégeket támogatunk az új üzletektől az értékesítés utáni értékesítésig.
Digitális eszközeink részét képezik a piaci intelligencia, a marketing, a marketingautomatizálás, a tartalomfejlesztés, a PR, a levelezési kampányok, a személyre szabott közösségi média és a lead-gondozás.
További információ: www.xpert.digital - www.xpert.solar - www.xpert.plus
Maradj kapcsolatban


















