
AI és SEO a BERT-tel – Transformers kétirányú kódolóábrázolásai – modell a természetes nyelvi feldolgozás (NLP) területén

Hangválasztás 📢
Megjelent: 2024. október 4. / Frissítés: 2024. október 4. - Szerző: Konrad Wolfenstein

AI és SEO a BERT-tel – Kétirányú kódoló ábrázolások a Transformerstől – Modell a természetes nyelvi feldolgozás (NLP) területén – Kép: Xpert.Digital
🚀💬 A Google által kifejlesztett: BERT és jelentősége az NLP számára – Miért fontos a kétirányú szövegértés
🔍🗣️ A BERT, a Transformers Bidirectional Encoder Representations rövidítése, a Google által kifejlesztett természetes nyelvi feldolgozás (NLP) egyik fő modellje. Forradalmasította azt, ahogy a gépek megértik a nyelvet. Ellentétben a korábbi modellekkel, amelyek szekvenciálisan elemeztek a szöveget balról jobbra vagy fordítva, a BERT lehetővé teszi a kétirányú feldolgozást. Ez azt jelenti, hogy mind az előző, mind a következő szövegsorozatból rögzíti egy szó kontextusát. Ez a képesség jelentősen javítja az összetett nyelvi összefüggések megértését.
🔍 A BERT architektúrája
Az elmúlt években a természetes nyelvi feldolgozás (NLP) területén az egyik legjelentősebb fejlemény a Transformer modell bevezetésével következett be, amint azt a PDF 2017 - Figyelem csak kell - papír ( Wikipédia ) bemutatja. Ez a modell alapvetően megváltoztatta a terepet azáltal, hogy elvetette a korábban használt struktúrákat, például a gépi fordítást. Ehelyett kizárólag a figyelemmechanizmusokra támaszkodik. Azóta a Transformer tervezése számos olyan modell alapját képezi, amelyek a legkorszerűbb területeket képviselik különböző területeken, például nyelvgeneráláson, fordításon és azon túl.
A Transformer modell fő összetevőinek illusztrációja - Kép: Google
A BERT ezen a Transformer architektúrán alapul. Ez az architektúra úgynevezett önfigyelő mechanizmusokat használ a mondatban lévő szavak közötti kapcsolatok elemzésére. Figyelmet fordítanak minden szóra a teljes mondat kontextusában, ami a szintaktikai és szemantikai kapcsolatok pontosabb megértését eredményezi.
A „figyelemre van szükséged” című cikk szerzői:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Lion Jones (Google Research)
- Aidan N. Gomez (Torontói Egyetem, a munka részben a Google Brainnél történt)
- Lukasz Kaiser (Google Brain)
- Illia Polosukhin (független, korábbi munkája a Google Researchnél)
Ezek a szerzők jelentősen hozzájárultak az ebben a tanulmányban bemutatott Transformer modell kidolgozásához.
🔄 Kétirányú feldolgozás
A BERT kiemelkedő tulajdonsága a kétirányú feldolgozási képesség. Míg a hagyományos modellek, például az ismétlődő neurális hálózatok (RNN) vagy a hosszú rövid távú memória (LSTM) hálózatok csak egy irányba dolgozzák fel a szöveget, a BERT mindkét irányban elemzi a szó kontextusát. Ez lehetővé teszi a modell számára, hogy jobban megragadja a jelentés finom árnyalatait, és ezáltal pontosabb előrejelzéseket készítsen.
🕵️♂️ Maszkos nyelvi modellezés
A BERT másik innovatív aspektusa a Masked Language Model (MLM) technika. Ez magában foglalja a véletlenszerűen kiválasztott szavak elfedését egy mondatban, és a modell képzését, hogy előre jelezze ezeket a szavakat a környező kontextus alapján. Ez a módszer arra kényszeríti a BERT-et, hogy mélyen megértse a mondatban szereplő egyes szavak kontextusát és jelentését.
🚀 A BERT képzése és testreszabása
A BERT két szakaszból álló képzési folyamaton megy keresztül: előképzésen és finomhangoláson.
📚 Előképzés
Az előképzésben a BERT-t nagy mennyiségű szöveggel képezik ki, hogy megtanulják az általános nyelvi mintákat. Ide tartoznak a Wikipédia szövegei és egyéb kiterjedt szövegkorpusok. Ebben a fázisban a modell megtanulja az alapvető nyelvi struktúrákat és összefüggéseket.
🔧 Finomhangolás
Az előképzés után a BERT testreszabott NLP-feladatokra, például szövegosztályozásra vagy hangulatelemzésre. A modell kisebb, feladathoz kapcsolódó adatkészletekkel van betanítva, hogy optimalizálja a teljesítményét bizonyos alkalmazásokhoz.
🌍 A BERT alkalmazási területei
A BERT rendkívül hasznosnak bizonyult a természetes nyelvi feldolgozás számos területén:
Keresőoptimalizálás
A Google a BERT segítségével jobban megérti a keresési lekérdezéseket, és relevánsabb találatokat jelenít meg. Ez nagymértékben javítja a felhasználói élményt.
Szöveg osztályozás
A BERT téma szerint kategorizálhatja a dokumentumokat, vagy elemzi a szövegek hangulatát.
Elnevezett entitás felismerés (NER)
A modell azonosítja és osztályozza a megnevezett entitásokat szövegekben, például személy-, hely- vagy szervezetneveket.
Kérdés-felelet rendszerek
A BERT arra szolgál, hogy pontos válaszokat adjon a feltett kérdésekre.
🧠 A BERT jelentősége az AI jövője szempontjából
A BERT új szabványokat állított fel az NLP-modellek számára, és megnyitotta az utat a további innovációk előtt. Kétirányú feldolgozási képessége és a nyelvi kontextus mély megértése révén jelentősen növelte az AI-alkalmazások hatékonyságát és pontosságát.
🔜 Jövőbeli fejlesztések
A BERT és a hasonló modellek további fejlesztése valószínűleg még erősebb rendszerek létrehozását célozza majd. Ezek bonyolultabb nyelvi feladatokat is kezelhetnek, és számos új alkalmazási területen használhatók. Az ilyen modellek integrálása a mindennapi technológiákba alapvetően megváltoztathatja a számítógépekkel való interakciót.
🌟 Mérföldkő a mesterséges intelligencia fejlődésében
A BERT mérföldkő a mesterséges intelligencia fejlődésében, és forradalmasította a gépek természetes nyelvi feldolgozásának módját. Kétirányú architektúrája lehetővé teszi a nyelvi kapcsolatok mélyebb megértését, így számos alkalmazáshoz nélkülözhetetlen. A kutatás előrehaladtával az olyan modellek, mint a BERT, továbbra is központi szerepet fognak játszani az AI-rendszerek fejlesztésében és új lehetőségek megnyitásában használatukra.
📣 Hasonló témák
- 📚 Bemutatkozik a BERT: Az áttörést jelentő NLP-modell
- 🔍 A BERT és a kétirányúság szerepe az NLP-ben
- 🧠 A Transformer modell: a BERT sarokköve
- 🚀 Maszkos nyelvi modellezés: a BERT kulcsa a sikerhez
- 📈 A BERT testreszabása: az előképzéstől a finomhangolásig
- 🌐 A BERT alkalmazási területei a modern technológiában
- 🤖 A BERT befolyása a mesterséges intelligencia jövőjére
- 💡 Jövőbeli kilátások: A BERT további fejlesztései
- 🏆 A BERT mérföldkő a mesterséges intelligencia fejlesztésében
- 📰 A Transformer „A figyelem minden, amire szüksége van” című dolgozat szerzői: A BERT mögött álló elmék
#️⃣ Hashtagek: #NLP #Mesterséges Intelligencia #Nyelvmodellezés #Transformer #Gépi tanulás
🎯🎯🎯 Használja ki az Xpert.Digital kiterjedt, ötszörös szakértelmét egy átfogó szolgáltatási csomagban | K+F, XR, PR és SEM

AI & XR 3D renderelő gép: Ötszörös szakértelem az Xpert.Digitaltól egy átfogó szolgáltatási csomagban, K+F XR, PR és SEM - Kép: Xpert.Digital
Az Xpert.Digital mélyreható ismeretekkel rendelkezik a különböző iparágakról. Ez lehetővé teszi számunkra, hogy személyre szabott stratégiákat dolgozzunk ki, amelyek pontosan az Ön konkrét piaci szegmensének követelményeihez és kihívásaihoz igazodnak. A piaci trendek folyamatos elemzésével és az iparági fejlemények követésével előrelátóan tudunk cselekedni és innovatív megoldásokat kínálni. A tapasztalat és a tudás ötvözésével hozzáadott értéket generálunk, és ügyfeleink számára meghatározó versenyelőnyt biztosítunk.
Bővebben itt:
BERT: Forradalmi 🌟 NLP technológia
🚀 A BERT, a Transformers Bidirectional Encoder Representations rövidítése, a Google által kifejlesztett fejlett nyelvi modell, amely 2018-as bevezetése óta jelentős áttörést jelent a Natural Language Processing (NLP) területén. A Transformer architektúrán alapul, amely forradalmasította a gépek szövegértési és feldolgozási módját. De mitől is olyan különleges a BERT, és pontosan mire használják? A kérdés megválaszolásához mélyebben kell elmélyednünk a BERT műszaki elveiben, funkcionalitásában és alkalmazási területeiben.
📚 1. A természetes nyelvi feldolgozás alapjai
A BERT jelentésének teljes megértéséhez hasznos, ha röviden áttekintjük a természetes nyelvi feldolgozás (NLP) alapjait. Az NLP a számítógépek és az emberi nyelv interakciójával foglalkozik. A cél megtanítani a gépeket szöveges adatok elemzésére, megértésére és reagálására. A BERT-hez hasonló modellek bevezetése előtt a nyelv gépi feldolgozása gyakran jelentős kihívásokat jelentett, különösen az emberi nyelv kétértelműsége, kontextusfüggősége és összetett szerkezete miatt.
📈 2. NLP modellek fejlesztése
A BERT színre lépése előtt a legtöbb NLP-modell úgynevezett egyirányú architektúrán alapult. Ez azt jelenti, hogy ezek a modellek csak balról jobbra vagy jobbról balra olvasnak szöveget, ami azt jelenti, hogy csak korlátozott mennyiségű szövegkörnyezetet tudtak figyelembe venni egy szó feldolgozása során. Ez a korlátozás gyakran azt eredményezte, hogy a modellek nem ragadták meg teljesen a mondat teljes szemantikai kontextusát. Ez megnehezítette a kétértelmű vagy kontextusérzékeny szavak pontos értelmezését.
Egy másik fontos fejlemény az NLP-kutatásban a BERT előtt a word2vec modell volt, amely lehetővé tette a számítógépek számára, hogy a szavakat szemantikai hasonlóságokat tükröző vektorokká fordítsák le. De a szövegkörnyezet itt is a szó közvetlen környezetére korlátozódott. Később kidolgozták a Recurrent Neural Networks (RNN) és különösen a Long Short-Term Memory (LSTM) modelleket, amelyek lehetővé tették a szövegsorozatok jobb megértését több szón keresztüli információ tárolásával. Azonban ezeknek a modelleknek is megvoltak a korlátai, különösen, ha hosszú szövegekkel foglalkoznak, és egyidejűleg mindkét irányban értelmezik a kontextust.
🔄 3. A forradalom a Transformer architektúrán keresztül
Az áttörést a Transformer architektúra 2017-es bevezetése hozta meg, amely a BERT alapját képezi. A transzformátor modelleket úgy tervezték, hogy lehetővé tegyék a szöveg párhuzamos feldolgozását, figyelembe véve az előző és a következő szövegből származó szó kontextusát. Ez úgynevezett önfigyelő mechanizmusokon keresztül történik, amelyek a mondat minden szavához súlyértéket rendelnek az alapján, hogy mennyire fontosak a mondat többi szavaihoz képest.
A korábbi megközelítésekkel ellentétben a Transformer modellek nem egyirányúak, hanem kétirányúak. Ez azt jelenti, hogy egy szó bal és jobb kontextusából is tudnak információt gyűjteni, így teljesebb és pontosabb képet alkotnak a szóról és jelentéséről.
🧠 4. BERT: Kétirányú modell
A BERT új szintre emeli a Transformer architektúra teljesítményét. A modellt úgy tervezték, hogy egy szó kontextusát ne csak balról jobbra vagy jobbról balra rögzítse, hanem mindkét irányban egyszerre. Ez lehetővé teszi a BERT számára, hogy a mondaton belüli szó teljes kontextusát figyelembe vegye, ami jelentősen javítja a nyelvi feldolgozási feladatok pontosságát.
A BERT központi jellemzője az úgynevezett maszkolt nyelvi modell (MLM) használata. A BERT képzése során a mondatban véletlenszerűen kiválasztott szavakat maszkkal helyettesítik, és a modellt arra tanítják, hogy a kontextus alapján kitalálja ezeket a maszkolt szavakat. Ez a technika lehetővé teszi a BERT számára, hogy mélyebb és pontosabb kapcsolatokat tanuljon meg a mondat szavai között.
Ezenkívül a BERT a Next Sentence Prediction (NSP) nevű módszert használja, ahol a modell megtanulja megjósolni, hogy egy mondat követi-e a másikat vagy sem. Ez javítja a BERT képességét a hosszabb szövegek megértésére és a mondatok közötti összetettebb kapcsolatok felismerésére.
🌐 5. A BERT alkalmazása a gyakorlatban
A BERT rendkívül hasznosnak bizonyult számos NLP-feladatnál. Íme néhány fő alkalmazási terület:
📊 a) Szöveges besorolás
A BERT egyik leggyakoribb felhasználási módja a szövegosztályozás, ahol a szövegeket előre meghatározott kategóriákra osztják. Ilyen például a hangulatelemzés (pl. annak felismerése, hogy egy szöveg pozitív vagy negatív), vagy az ügyfelek visszajelzéseinek kategorizálása. A BERT pontosabb eredményeket tud nyújtani, mint a korábbi modellek a szavak kontextusának mély megértése révén.
❓ b) Kérdés-felelet rendszerek
A BERT-et kérdés-felelet rendszerekben is használják, ahol a modell szövegből kinyeri a válaszokat a feltett kérdésekre. Ez a képesség különösen fontos az olyan alkalmazásokban, mint a keresőmotorok, a chatbotok vagy a virtuális asszisztensek. Kétirányú architektúrájának köszönhetően a BERT releváns információkat tud kinyerni egy szövegből, még akkor is, ha a kérdés közvetetten fogalmazódik meg.
🌍 c) Szövegfordítás
Bár magát a BERT-et nem közvetlenül fordítási modellnek tervezték, más technológiákkal kombinálva is használható a gépi fordítás javítására. A mondatban található szemantikai kapcsolatok jobb megértésével a BERT segíthet pontosabb fordítások generálásában, különösen kétértelmű vagy összetett megfogalmazások esetén.
🏷️ d) Elnevezett entitás felismerés (NER)
Egy másik alkalmazási terület a Named Entity Recognition (NER), amely konkrét entitások, például nevek, helyek vagy szervezetek azonosítását foglalja magában a szövegben. A BERT különösen hatékonynak bizonyult ebben a feladatban, mert teljes mértékben figyelembe veszi a mondat kontextusát, így jobban felismeri az entitásokat, még akkor is, ha a különböző kontextusokban eltérő jelentéssel bírnak.
✂️ e) Szöveges összefoglaló
A BERT azon képessége, hogy a szöveg teljes kontextusát megérti, az automatikus szövegösszegzés hatékony eszközévé is teszi. Segítségével egy hosszú szövegből kinyerhetők a legfontosabb információk, és tömör összefoglaló készíthető.
🌟 6. A BERT jelentősége a kutatás és az ipar számára
A BERT bevezetése új korszakot nyitott az NLP-kutatásban. Ez volt az első modellek egyike, amely teljes mértékben kihasználta a kétirányú transzformátor architektúra erejét, és ezzel felállította a mércét számos további modell számára. Számos vállalat és kutatóintézet integrálta a BERT-et NLP-folyamataiba, hogy javítsa alkalmazásai teljesítményét.
Ezenkívül a BERT megnyitotta az utat a további innovációk előtt a nyelvi modellek területén. Ezt követően például olyan modelleket fejlesztettek ki, mint a GPT (Generatív előképzett transzformátor) és a T5 (Text-to-Text Transfer Transformer), amelyek hasonló elveken alapulnak, de speciális fejlesztéseket kínálnak a különböző felhasználási esetekben.
🚧 7. A BERT kihívásai és korlátai
Számos előnye ellenére a BERT-nek vannak kihívásai és korlátai is. Az egyik legnagyobb akadály a modell betanításához és alkalmazásához szükséges nagy számítási erőfeszítés. Mivel a BERT egy nagyon nagy modell, több millió paraméterrel, ezért nagy teljesítményű hardvert és jelentős számítási erőforrásokat igényel, különösen nagy mennyiségű adat feldolgozásakor.
Egy másik probléma a képzési adatok esetleges torzítása. Mivel a BERT nagy mennyiségű szöveges adatra van kiképezve, időnként tükrözi az adatokban jelenlévő torzításokat és sztereotípiákat. A kutatók azonban folyamatosan dolgoznak ezen problémák azonosításán és kezelésén.
🔍 Alapvető eszköz a modern nyelvfeldolgozó alkalmazásokhoz
A BERT jelentősen javította a gépek emberi nyelv megértésének módját. Kétirányú architektúrájával és innovatív képzési módszereivel képes mélyen és pontosan megragadni a szavak szövegkörnyezetét egy mondatban, ami nagyobb pontosságot eredményez számos NLP feladatban. Legyen szó szövegosztályozásról, kérdés-felelet rendszerekről vagy entitásfelismerésről – a BERT a modern nyelvfeldolgozó alkalmazások nélkülözhetetlen eszközévé vált.
A természetes nyelvi feldolgozás kutatása kétségtelenül tovább fog fejlődni, és a BERT számos jövőbeli innováció alapjait fektette le. A meglévő kihívások és korlátok ellenére a BERT lenyűgözően megmutatja, milyen messzire jutott a technológia rövid idő alatt, és milyen izgalmas lehetőségek nyílnak meg még a jövőben.
🌀 A transzformátor: forradalom a természetes nyelvi feldolgozásban
🌟 Az elmúlt években a természetes nyelvi feldolgozás (NLP) területén az egyik legjelentősebb fejlemény a Transformer modell bevezetése volt, amint azt a 2017-es „A figyelem csak kell” című tanulmány is leírta. Ez a modell alapvetően megváltoztatta a területet azáltal, hogy elvetette a korábban használt ismétlődő vagy konvolúciós struktúrákat a szekvencia-transzdukciós feladatokhoz, például a gépi fordításhoz. Ehelyett kizárólag a figyelemmechanizmusokra támaszkodik. Azóta a Transformer tervezése számos olyan modell alapját képezi, amelyek a legkorszerűbb területeket képviselik különböző területeken, például nyelvgeneráláson, fordításon és azon túl.
🔄 A transzformátor: Paradigmaváltás
A Transformer bevezetése előtt a szekvenálási feladatok legtöbb modellje visszatérő neurális hálózatokon (RNN) vagy hosszú rövid távú memóriahálózatokon (LSTM) alapult, amelyek eredendően szekvenciálisak. Ezek a modellek lépésről lépésre dolgozzák fel a bemeneti adatokat, rejtett állapotokat hozva létre, amelyek a sorozat mentén terjednek. Bár ez a módszer hatékony, számítási szempontból költséges és nehéz párhuzamosítani, különösen hosszú sorozatok esetén. Ezenkívül az RNN-ek nehezen tanulják meg a hosszú távú függőségeket az úgynevezett „eltűnő gradiens” probléma miatt.
A Transformer központi újítása az önfigyelem mechanizmusok alkalmazásában rejlik, amelyek lehetővé teszik a modell számára, hogy a mondat különböző szavainak fontosságát egymáshoz képest súlyozza, függetlenül azok helyzetétől. Ez lehetővé teszi, hogy a modell hatékonyabban rögzítse a nagy távolságú szavak közötti kapcsolatokat, mint az RNN-ek vagy az LSTM-ek, és ezt párhuzamosan, nem pedig egymás után. Ez nem csak a képzés hatékonyságát javítja, hanem az olyan feladatok teljesítményét is, mint a gépi fordítás.
🧩 Modell architektúra
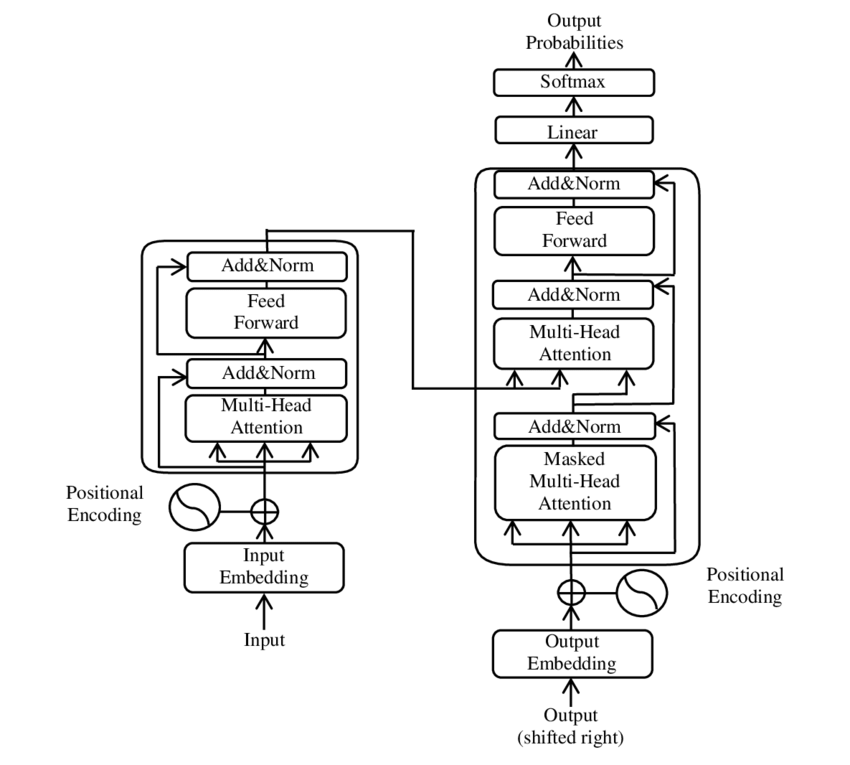
A Transformer két fő összetevőből áll: egy kódolóból és egy dekódolóból, amelyek több rétegből állnak, és nagymértékben támaszkodnak többfejes figyelemmechanizmusokra.
⚙️ Kódoló
A kódoló hat azonos rétegből áll, mindegyik két alréteggel:
1. Többfejű önfigyelés
Ez a mechanizmus lehetővé teszi a modell számára, hogy az egyes szavak feldolgozása során a bemeneti mondat különböző részeire összpontosítson. Ahelyett, hogy egyetlen térben számítaná ki a figyelmet, a többfejű figyelem több különböző térbe vetíti a bemenetet, lehetővé téve a szavak közötti különböző típusú kapcsolatok rögzítését.
2. Pozíció szerint teljesen csatlakoztatott előrecsatolt hálózatok
A figyelemréteg után egy teljesen összekapcsolt előrecsatolt hálózat kerül alkalmazásra minden pozícióban függetlenül. Ez segít a modellnek minden szót a kontextusban feldolgozni, és a figyelemmechanizmusból származó információkat hasznosítani.
A bemeneti szekvencia szerkezetének megőrzése érdekében a modell helyzeti bemeneteket (pozíciókódolásokat) is tartalmaz. Mivel a Transformer nem szekvenciálisan dolgozza fel a szavakat, ezek a kódolások kulcsfontosságúak abban, hogy a modellnek információt adjon a szavak sorrendjéről egy mondatban. A pozícióbemenetek hozzáadódnak a szóbeágyazásokhoz, így a modell képes megkülönböztetni a sorozat különböző pozícióit.
🔍 Dekóderek
A kódolóhoz hasonlóan a dekódoló is hat rétegből áll, mindegyik rétegnek van egy további figyelemmechanizmusa, amely lehetővé teszi a modell számára, hogy a bemeneti szekvencia releváns részeire összpontosítson, miközben a kimenetet generálja. A dekóder maszkolási technikát is használ, hogy megakadályozza, hogy figyelembe vegye a jövőbeli pozíciókat, megőrizve a sorozatgenerálás autoregresszív jellegét.
🧠 Többfejes figyelem és pontos termékfigyelem
A Transformer szíve a Multi-Head Attention mechanizmus, amely az egyszerűbb ponttermékekre való figyelem kiterjesztése. A figyelem függvény egy lekérdezés és kulcs-érték párok (kulcsok és értékek) halmaza közötti leképezésnek tekinthető, ahol minden kulcs egy szót jelöl a sorozatban, az érték pedig a kapcsolódó kontextuális információt.
A többfejes figyelemmechanizmus lehetővé teszi, hogy a modell egyidejűleg a sorozat különböző részeire fókuszáljon. A bemenet több altérbe történő kivetítésével a modell a szavak közötti kapcsolatok gazdagabb halmazát rögzítheti. Ez különösen hasznos olyan feladatoknál, mint például a gépi fordítás, ahol egy szó kontextusának megértéséhez sok különböző tényezőre van szükség, mint például a szintaktikai szerkezet és a szemantikai jelentés.
A pontszerű termékfigyelés képlete a következő:
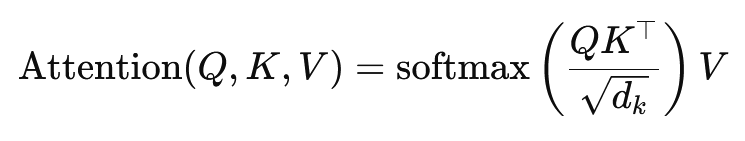
Itt (Q) a lekérdezési mátrix, (K) a kulcsmátrix és (V) az értékmátrix. A kifejezés (sqrt{d_k}) egy skálázási tényező, amely megakadályozza, hogy a pontszorzatok túl nagyok legyenek, ami nagyon kicsi színátmenetekhez és lassabb tanuláshoz vezetne. A softmax funkció alkalmazása biztosítja, hogy a figyelem súlya egyet jelentsen.
🚀 A Transformer előnyei
A Transformer számos kulcsfontosságú előnyt kínál a hagyományos modellekkel, például RNN-ekkel és LSTM-ekkel szemben:
1. Párhuzamosítás
Mivel a Transformer az összes tokent egy szekvenciában egyszerre dolgozza fel, nagymértékben párhuzamosítható, és ezért sokkal gyorsabban betanítható, mint az RNN-ek vagy az LSTM-ek, különösen nagy adatkészletek esetén.
2. Hosszú távú függőségek
Az önfigyelem mechanizmus lehetővé teszi, hogy a modell hatékonyabban rögzítse a távoli szavak közötti kapcsolatokat, mint az RNN-ek, amelyeket számításaik szekvenciális jellege korlátoz.
3. Skálázhatóság
A Transformer könnyen méretezhető nagyon nagy adathalmazokra és hosszabb sorozatokra anélkül, hogy az RNN-ekhez kapcsolódó teljesítménybeli szűk keresztmetszetek szenvednének.
🌍 Alkalmazások és effektusok
Bevezetése óta a Transformer az NLP modellek széles skálájának alapjává vált. Az egyik legfigyelemreméltóbb példa a BERT (Bidirectional Encoder Representations from Transformers), amely módosított Transformer architektúrát használ, hogy a legkorszerűbb eredményeket érje el számos NLP feladatban, beleértve a kérdések megválaszolását és a szövegosztályozást.
Egy másik jelentős fejlesztés a GPT (Generative Pretrained Transformer), amely a Transformer dekóderre korlátozott változatát használja szöveggeneráláshoz. A GPT-modelleket, beleértve a GPT-3-at is, ma már számos alkalmazáshoz használják, a tartalomkészítéstől a kódbefejezésig.
🔍 Erőteljes és rugalmas modell
A Transformer alapjaiban változtatta meg az NLP-feladatok megközelítését. Erőteljes és rugalmas modellt biztosít, amely számos problémára alkalmazható. A hosszú távú függőségek kezelésére való képessége és a képzési hatékonyság miatt a legmodernebb modellek közül sok előnyben részesített építészeti megközelítés lett. A kutatás előrehaladtával valószínűleg további fejlesztéseket és módosításokat fogunk látni a Transformerben, különösen olyan területeken, mint a kép- és nyelvfeldolgozás, ahol a figyelemmechanizmusok ígéretes eredményeket mutatnak.
Ott vagyunk Önért - tanácsadás - tervezés - kivitelezés - projektmenedzsment
☑️ Iparági szakértő, itt a saját Xpert.Digital ipari központjával, több mint 2500 szakcikkel

Konrad Wolfenstein
Szívesen szolgálok személyes tanácsadójaként.
Felveheti velem a kapcsolatot az alábbi kapcsolatfelvételi űrlap kitöltésével, vagy egyszerűen hívjon a +49 89 89 674 804 (München) .
Nagyon várom a közös projektünket.
Írj nekem

Xpert.Digital – Konrad Wolfenstein
Az Xpert.Digital egy ipari központ, amely a digitalizációra, a gépészetre, a logisztikára/intralogisztikára és a fotovoltaikára összpontosít.
360°-os üzletfejlesztési megoldásunkkal jól ismert cégeket támogatunk az új üzletektől az értékesítés utáni értékesítésig.
Digitális eszközeink részét képezik a piaci intelligencia, a marketing, a marketingautomatizálás, a tartalomfejlesztés, a PR, a levelezési kampányok, a személyre szabott közösségi média és a lead-gondozás.
További információ: www.xpert.digital - www.xpert.solar - www.xpert.plus
Maradj kapcsolatban




















