
कृत्रिम बुद्धिमत्ता को समझाने का एक प्रयास: कृत्रिम बुद्धिमत्ता कैसे काम करती है और इसे कैसे प्रशिक्षित किया जाता है?

Available in 27 languages 📢
Google पर Xpert.Digital को प्राथमिकता देंⓘप्रकाशित तिथि: 8 सितंबर, 2024 / अद्यतन तिथि: 9 सितंबर, 2024 – लेखक: Konrad Wolfenstein

कृत्रिम बुद्धिमत्ता को समझाने का एक प्रयास: कृत्रिम बुद्धिमत्ता कैसे काम करती है और इसे कैसे प्रशिक्षित किया जाता है? – चित्र: Xpert.Digital
📊 डेटा इनपुट से मॉडल भविष्यवाणी तक: एआई प्रक्रिया
कृत्रिम बुद्धिमत्ता (एआई) कैसे काम करती है? 🤖
कृत्रिम बुद्धिमत्ता (एआई) की कार्यप्रणाली को कई स्पष्ट चरणों में विभाजित किया जा सकता है। एआई द्वारा प्राप्त अंतिम परिणाम के लिए इनमें से प्रत्येक चरण महत्वपूर्ण है। प्रक्रिया डेटा इनपुट से शुरू होती है और मॉडल की भविष्यवाणी और किसी भी प्रतिक्रिया या आगे के प्रशिक्षण दौर के साथ समाप्त होती है। ये चरण उस प्रक्रिया का वर्णन करते हैं जिससे लगभग सभी एआई मॉडल गुजरते हैं, चाहे वे सरल नियम सेट हों या अत्यधिक जटिल न्यूरल नेटवर्क।.
1. डेटा इनपुट 📊
किसी भी कृत्रिम बुद्धिमत्ता का आधार वह डेटा होता है जिस पर वह काम करती है। यह डेटा विभिन्न रूपों में मौजूद हो सकता है, जैसे कि चित्र, पाठ, ऑडियो फ़ाइलें या वीडियो। एआई इस कच्चे डेटा का उपयोग पैटर्न पहचानने और निर्णय लेने के लिए करता है। डेटा की गुणवत्ता और मात्रा यहाँ महत्वपूर्ण भूमिका निभाती है, क्योंकि ये मॉडल के अंतिम प्रदर्शन को काफी हद तक प्रभावित करती हैं।.
डेटा जितना व्यापक और सटीक होगा, AI उतना ही बेहतर सीख पाएगा। उदाहरण के लिए, इमेज प्रोसेसिंग के लिए AI को प्रशिक्षित करते समय, विभिन्न वस्तुओं की सही पहचान करने के लिए उसे बड़ी मात्रा में इमेज डेटा की आवश्यकता होती है। भाषा मॉडल के लिए, टेक्स्ट डेटा ही AI को मानवीय भाषा को समझने और उत्पन्न करने में मदद करता है। डेटा इनपुट पहला और सबसे महत्वपूर्ण चरण है, क्योंकि भविष्यवाणियों की गुणवत्ता केवल अंतर्निहित डेटा पर निर्भर करती है। कंप्यूटर विज्ञान में एक प्रसिद्ध सिद्धांत इसे "गलत इनपुट, गलत आउटपुट" के रूप में वर्णित करता है - गलत डेटा से गलत परिणाम मिलते हैं।.
2. डेटा पूर्व-प्रसंस्करण 🧹
डेटा दर्ज हो जाने के बाद, इसे मॉडल में डालने से पहले तैयार करना आवश्यक है। इस प्रक्रिया को डेटा प्रीप्रोसेसिंग कहा जाता है। इसका उद्देश्य डेटा को ऐसे प्रारूप में बदलना है जिसे मॉडल बेहतर ढंग से संसाधित कर सके।.
डेटा प्रोसेसिंग के पूर्व-प्रसंस्करण में एक सामान्य चरण डेटा सामान्यीकरण है। इसका अर्थ है डेटा को मानों की एकसमान सीमा में लाना ताकि मॉडल द्वारा इसे एकसमान रूप से संसाधित किया जा सके। उदाहरण के लिए, किसी छवि के सभी पिक्सेल मानों को 0 से 255 की सीमा के बजाय 0 से 1 की सीमा में स्केल करना।.
प्रीप्रोसेसिंग का एक और महत्वपूर्ण हिस्सा फीचर एक्सट्रैक्शन है। इसमें कच्चे डेटा से उन विशिष्ट विशेषताओं को निकाला जाता है जो मॉडल के लिए विशेष रूप से प्रासंगिक होती हैं। इमेज प्रोसेसिंग में, ये किनारे या विशिष्ट रंग पैटर्न हो सकते हैं, जबकि टेक्स्ट प्रोसेसिंग में, प्रासंगिक कीवर्ड या वाक्य संरचनाएं निकाली जाती हैं। आर्टिफिशियल इंटेलिजेंस की सीखने की प्रक्रिया को अधिक कुशल और सटीक बनाने के लिए प्रीप्रोसेसिंग अत्यंत महत्वपूर्ण है।.
3. मॉडल 🧩
कृत्रिम बुद्धिमत्ता का मूल आधार मॉडल ही होता है। इसमें एल्गोरिदम और गणितीय गणनाओं के आधार पर डेटा का विश्लेषण और प्रसंस्करण किया जाता है। मॉडल कई रूपों में मौजूद हो सकते हैं। सबसे प्रसिद्ध मॉडलों में से एक न्यूरल नेटवर्क है, जो मानव मस्तिष्क की कार्यप्रणाली पर आधारित है।.
न्यूरल नेटवर्क में कृत्रिम न्यूरॉन्स की कई परतें होती हैं जो सूचना को संसाधित और आगे बढ़ाती हैं। प्रत्येक परत पिछली परत से आउटपुट लेती है और उसे आगे संसाधित करती है। न्यूरल नेटवर्क की सीखने की प्रक्रिया में इन न्यूरॉन्स के बीच कनेक्शन के भार को समायोजित करना शामिल है ताकि नेटवर्क अधिक सटीक भविष्यवाणियां या वर्गीकरण कर सके। यह समायोजन प्रशिक्षण के माध्यम से प्राप्त किया जाता है, जिसमें नेटवर्क बड़ी मात्रा में उदाहरण डेटा तक पहुंचता है और अपने आंतरिक मापदंडों (भार) में बार-बार सुधार करता है।.
न्यूरल नेटवर्क के अलावा, एआई मॉडल में कई अन्य एल्गोरिदम का उपयोग किया जाता है। इनमें डिसीजन ट्री, रैंडम फॉरेस्ट, सपोर्ट वेक्टर मशीन आदि शामिल हैं। किस एल्गोरिदम का उपयोग किया जाएगा, यह विशिष्ट कार्य और उपलब्ध डेटा पर निर्भर करता है।.
4. मॉडल का पूर्वानुमान 🔍
डेटा के साथ मॉडल को प्रशिक्षित करने के बाद, यह पूर्वानुमान लगाने में सक्षम हो जाता है। इस चरण को मॉडल पूर्वानुमान कहा जाता है। कृत्रिम बुद्धिमत्ता (AI) इनपुट प्राप्त करती है और अब तक सीखे गए पैटर्न के आधार पर आउटपुट, यानी पूर्वानुमान या निर्णय देती है।.
यह भविष्यवाणी कई रूपों में हो सकती है। उदाहरण के लिए, एक इमेज क्लासिफिकेशन मॉडल में, एआई यह अनुमान लगा सकता है कि चित्र में कौन सी वस्तु दिखाई दे रही है। एक भाषा मॉडल में, यह अनुमान लगा सकता है कि वाक्य में अगला शब्द कौन सा होगा। वित्तीय भविष्यवाणियों में, एआई यह भविष्यवाणी कर सकता है कि शेयर बाजार कैसा प्रदर्शन करेगा।.
यह बात विशेष रूप से महत्वपूर्ण है कि भविष्यवाणियों की सटीकता प्रशिक्षण डेटा की गुणवत्ता और मॉडल संरचना पर बहुत अधिक निर्भर करती है। अपर्याप्त या पक्षपातपूर्ण डेटा पर प्रशिक्षित मॉडल द्वारा गलत भविष्यवाणियां किए जाने की संभावना बहुत अधिक होती है।.
5. प्रतिक्रिया और प्रशिक्षण (वैकल्पिक) ♻️
कृत्रिम बुद्धिमत्ता (एआई) के काम करने का एक और महत्वपूर्ण पहलू फीडबैक तंत्र है। इसमें, मॉडल की नियमित रूप से जाँच की जाती है और उसे और बेहतर बनाया जाता है। यह प्रक्रिया या तो प्रशिक्षण के दौरान होती है या मॉडल की भविष्यवाणी के बाद।.
यदि मॉडल गलत अनुमान लगाता है, तो वह फीडबैक के माध्यम से इन त्रुटियों को पहचानना सीख सकता है और तदनुसार अपने आंतरिक मापदंडों को समायोजित कर सकता है। यह मॉडल के अनुमानों की तुलना वास्तविक परिणामों (जैसे, ज्ञात डेटा जिसके लिए सही उत्तर पहले से मौजूद हैं) से करके किया जाता है। इस संदर्भ में एक आम विधि को पर्यवेक्षित शिक्षण कहा जाता है, जिसमें कृत्रिम बुद्धिमत्ता (AI) ऐसे उदाहरण डेटा से सीखती है जिसमें पहले से ही सही उत्तर मौजूद होते हैं।.
न्यूरल नेटवर्क में उपयोग किया जाने वाला बैकप्रॉपैगेशन एल्गोरिदम एक सामान्य फीडबैक विधि है। इसमें, मॉडल द्वारा की गई त्रुटियों को न्यूरल कनेक्शन के भार को समायोजित करने के लिए नेटवर्क के माध्यम से पीछे की ओर प्रसारित किया जाता है। इस तरह, मॉडल अपनी गलतियों से सीखता है और अपने पूर्वानुमानों में उत्तरोत्तर अधिक सटीक होता जाता है।.
प्रशिक्षण की भूमिका 🏋️♂️
कृत्रिम बुद्धिमत्ता (एआई) को प्रशिक्षित करना एक पुनरावृत्ति प्रक्रिया है। मॉडल जितना अधिक डेटा देखता है और उस डेटा पर जितनी बार प्रशिक्षित होता है, उसकी भविष्यवाणियाँ उतनी ही सटीक होती जाती हैं। हालाँकि, इसकी भी सीमाएँ हैं: अत्यधिक प्रशिक्षित मॉडल में "ओवरफिटिंग" की समस्या उत्पन्न हो सकती है। इसका अर्थ है कि यह प्रशिक्षण डेटा को इतनी अच्छी तरह से याद कर लेता है कि नए, अज्ञात डेटा पर इसके परिणाम खराब हो जाते हैं। इसलिए, मॉडल को इस तरह से प्रशिक्षित करना महत्वपूर्ण है कि वह सामान्यीकरण कर सके, यानी नए डेटा पर भी अच्छी भविष्यवाणियाँ कर सके।.
नियमित प्रशिक्षण के अलावा, ट्रांसफर लर्निंग जैसी विधियाँ भी हैं। इसमें, एक बड़े डेटासेट पर पहले से प्रशिक्षित मॉडल का उपयोग एक नए, समान कार्य के लिए किया जाता है। इससे समय और कंप्यूटिंग शक्ति की बचत होती है, क्योंकि मॉडल को शुरू से पूरी तरह से प्रशिक्षित करने की आवश्यकता नहीं होती है।.
अपनी खूबियों का भरपूर इस्तेमाल करें 🚀
कृत्रिम बुद्धिमत्ता (एआई) का संचालन विभिन्न चरणों के जटिल अंतर्संबंध पर आधारित है। डेटा इनपुट और प्रीप्रोसेसिंग से लेकर मॉडल प्रशिक्षण, भविष्यवाणी और प्रतिक्रिया तक, कई कारक एआई की सटीकता और दक्षता को प्रभावित करते हैं। एक अच्छी तरह से प्रशिक्षित एआई जीवन के कई क्षेत्रों में अपार लाभ प्रदान कर सकता है—सरल कार्यों को स्वचालित करने से लेकर जटिल समस्याओं को हल करने तक। हालांकि, एआई की क्षमताओं का सर्वोत्तम उपयोग करने के लिए इसकी सीमाओं और संभावित कमियों को समझना भी उतना ही महत्वपूर्ण है।.
🤖📚 सरल शब्दों में: एआई को कैसे प्रशिक्षित किया जाता है?
🤖📊 एआई लर्निंग प्रक्रिया: कैप्चर करना, लिंक करना और स्टोर करना
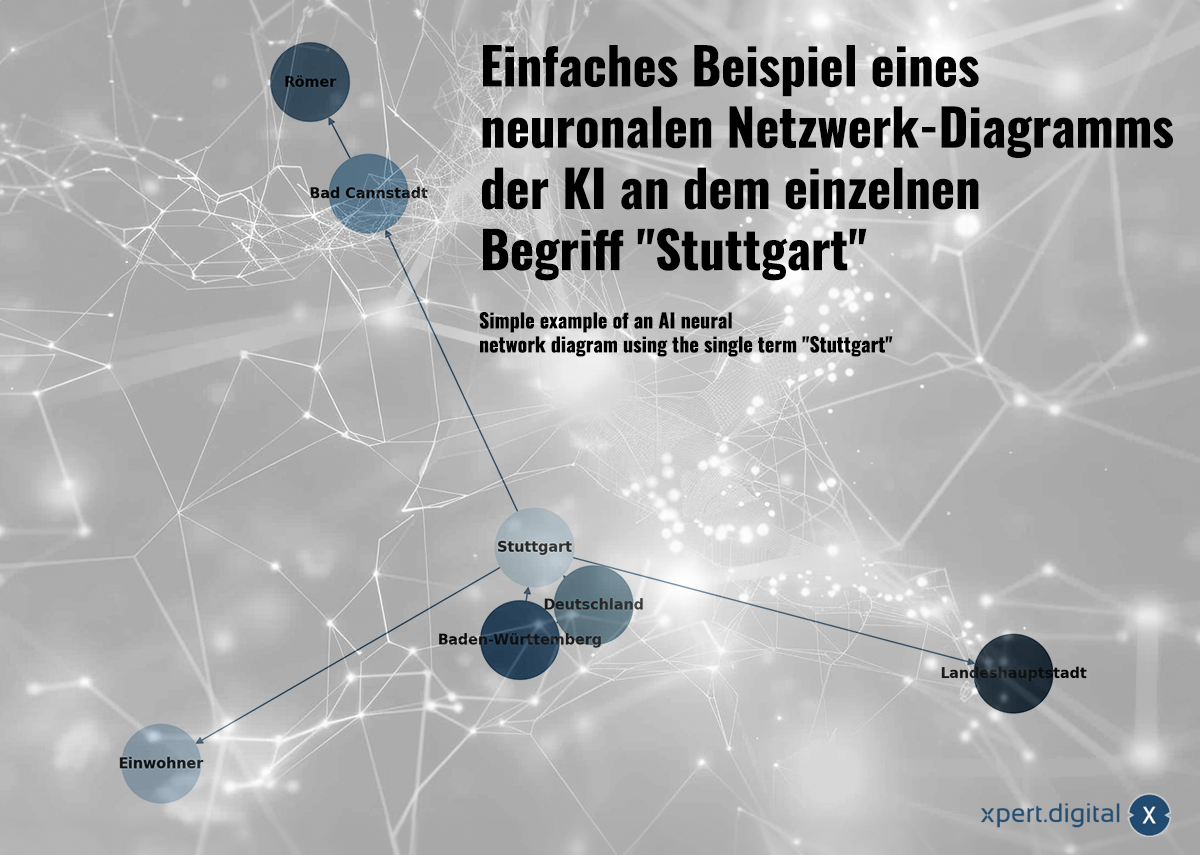
केवल एक शब्द "स्टटगार्ट" का उपयोग करके बनाए गए एआई न्यूरल नेटवर्क आरेख का एक सरल उदाहरण – चित्र: Xpert.Digital
🌟 डेटा एकत्र करें और तैयार करें
एआई सीखने की प्रक्रिया का पहला चरण डेटा एकत्र करना और उसे तैयार करना है। यह डेटा डेटाबेस, सेंसर, टेक्स्ट या छवियों जैसे विभिन्न स्रोतों से प्राप्त किया जा सकता है।.
🌟 डेटा का संबंध स्थापित करना (न्यूरल नेटवर्क)
एकत्रित डेटा को एक न्यूरल नेटवर्क में आपस में जोड़ा जाता है। प्रत्येक डेटा पैकेट को "न्यूरॉन्स" (नोड्स) के नेटवर्क में कनेक्शन द्वारा दर्शाया जाता है। स्टटगार्ट शहर का उपयोग करते हुए एक सरल उदाहरण इस प्रकार हो सकता है:
a) स्टटगार्ट, बाडेन-वुर्टेमबर्ग का एक शहर है।
b) बाडेन-वुर्टेमबर्ग जर्मनी का एक संघीय राज्य है।
c) स्टटगार्ट जर्मनी का एक शहर है।
d) 2023 में स्टटगार्ट की जनसंख्या 633,484 थी।
e) बैड कैनस्टैट, स्टटगार्ट का एक जिला है।
f) बैड कैनस्टैट की स्थापना रोमनों ने की थी।
g) स्टटगार्ट, बाडेन-वुर्टेमबर्ग की राज्य राजधानी है।
डेटा की मात्रा के आधार पर, संभावित आउटपुट के लिए पैरामीटर एआई मॉडल का उपयोग करके उत्पन्न किए जाते हैं। उदाहरण के लिए, जीपीटी-3 में लगभग 175 बिलियन पैरामीटर हैं!
🌟 बचत और अनुकूलन (सीखना)
डेटा को न्यूरल नेटवर्क में फीड किया जाता है। यह एआई मॉडल से होकर गुजरता है और न्यूरॉन्स के बीच के कनेक्शनों (सिनैप्स के समान) के माध्यम से प्रोसेस किया जाता है। न्यूरॉन्स के बीच के वेट्स (पैरामीटर) को मॉडल को ट्रेन करने या किसी कार्य को पूरा करने के लिए एडजस्ट किया जाता है।.
डायरेक्ट एक्सेस, इंडेक्स्ड एक्सेस, सीक्वेंशियल या बैच स्टोरेज जैसी पारंपरिक स्टोरेज विधियों के विपरीत, न्यूरल नेटवर्क डेटा को एक अपरंपरागत तरीके से स्टोर करते हैं। "डेटा" न्यूरॉन्स के बीच कनेक्शन के वेट और बायस में स्टोर होता है।.
न्यूरल नेटवर्क में सूचना का वास्तविक "भंडारण" न्यूरॉन्स के बीच कनेक्शन वेट को समायोजित करके होता है। एआई मॉडल इनपुट डेटा और एक परिभाषित लर्निंग एल्गोरिदम के आधार पर इन वेट और बायस को लगातार समायोजित करके "सीखता" है। यह एक सतत प्रक्रिया है जिसमें मॉडल बार-बार समायोजन करके अधिक सटीक पूर्वानुमान लगा सकता है।.
कृत्रिम बुद्धिमत्ता (एआई) मॉडल को एक प्रकार की प्रोग्रामिंग के रूप में देखा जा सकता है, क्योंकि यह परिभाषित एल्गोरिदम और गणितीय गणनाओं के माध्यम से बनाया जाता है, और सटीक पूर्वानुमान लगाने के लिए इसके मापदंडों (भारों) का समायोजन लगातार बेहतर किया जाता है। यह एक सतत प्रक्रिया है।.
न्यूरल नेटवर्क में पूर्वाग्रह (बायसेस) अतिरिक्त पैरामीटर होते हैं जिन्हें न्यूरॉन के भारित इनपुट मानों में जोड़ा जाता है। ये पैरामीटरों को भारित (महत्वपूर्ण, कम महत्वपूर्ण, आदि) करने की अनुमति देते हैं, जिससे एआई अधिक लचीला और सटीक बनता है।.
न्यूरल नेटवर्क न केवल व्यक्तिगत तथ्यों को संग्रहित कर सकते हैं, बल्कि पैटर्न पहचान के माध्यम से डेटा के बीच संबंधों को भी पहचान सकते हैं। स्टटगार्ट का उदाहरण दर्शाता है कि कैसे ज्ञान को न्यूरल नेटवर्क में डाला जा सकता है, लेकिन न्यूरल नेटवर्क स्पष्ट ज्ञान (जैसा कि इस सरल उदाहरण में है) के माध्यम से नहीं सीखते हैं, बल्कि डेटा पैटर्न के विश्लेषण के माध्यम से सीखते हैं। इसलिए, न्यूरल नेटवर्क न केवल व्यक्तिगत तथ्यों को संग्रहित कर सकते हैं, बल्कि इनपुट डेटा के बीच भार और संबंधों को भी सीख सकते हैं।.
यह प्रक्रिया तकनीकी विवरणों में अधिक गहराई से जाए बिना, कृत्रिम बुद्धिमत्ता (एआई), और विशेष रूप से तंत्रिका नेटवर्क, के कार्य करने के तरीके का एक सुगम परिचय प्रदान करती है। यह दर्शाती है कि जानकारी पारंपरिक डेटाबेस की तरह तंत्रिका नेटवर्क में संग्रहीत नहीं होती है, बल्कि नेटवर्क के भीतर कनेक्शन (भार) को समायोजित करके संग्रहीत की जाती है।.
🤖📚 अधिक विस्तार से: एआई को कैसे प्रशिक्षित किया जाता है?
🏋️♂️ किसी कृत्रिम बुद्धिमत्ता (एआई), विशेष रूप से मशीन लर्निंग मॉडल को प्रशिक्षित करने में कई चरण शामिल होते हैं। एआई प्रशिक्षण, मॉडल के मापदंडों के निरंतर अनुकूलन पर आधारित होता है, जिसमें फीडबैक और समायोजन के माध्यम से तब तक सुधार किया जाता है जब तक कि मॉडल दिए गए डेटा पर सर्वोत्तम प्रदर्शन न करने लगे। यह प्रक्रिया कैसे काम करती है, इसका विस्तृत विवरण यहाँ दिया गया है:
1. 📊 डेटा एकत्र करें और तैयार करें
डेटा कृत्रिम बुद्धिमत्ता (एआई) प्रशिक्षण का आधार है। इसमें आमतौर पर हजारों या लाखों उदाहरण होते हैं जिनका विश्लेषण सिस्टम को करना होता है। उदाहरणों में चित्र, पाठ या समय-श्रृंखला डेटा शामिल हैं।.
अनावश्यक त्रुटियों से बचने के लिए डेटा को साफ और सामान्यीकृत किया जाना चाहिए। अक्सर, डेटा को ऐसे फ़ीचर में रूपांतरित किया जाता है जिनमें प्रासंगिक जानकारी शामिल होती है।.
2. 🔍 मॉडल को परिभाषित करें
मॉडल एक गणितीय फ़ंक्शन है जो डेटा में संबंधों का वर्णन करता है। कृत्रिम बुद्धिमत्ता (एआई) में अक्सर उपयोग किए जाने वाले न्यूरल नेटवर्क में, मॉडल में न्यूरॉन्स की कई परतें होती हैं जो आपस में जुड़ी होती हैं।.
प्रत्येक न्यूरॉन इनपुट डेटा को संसाधित करने के लिए एक गणितीय क्रिया करता है और फिर अगले न्यूरॉन को एक संकेत भेजता है।.
3. 🔄 वज़न को प्रारंभ करें
न्यूरॉन्स के बीच के कनेक्शनों का भार होता है जो शुरू में यादृच्छिक रूप से निर्धारित किया जाता है। ये भार निर्धारित करते हैं कि एक न्यूरॉन किसी सिग्नल पर कितनी तीव्रता से प्रतिक्रिया करता है।.
प्रशिक्षण का लक्ष्य इन भारों को इस प्रकार समायोजित करना है ताकि मॉडल बेहतर पूर्वानुमान लगा सके।.
4. ➡️ अग्र प्रसार
फॉरवर्ड पास के दौरान, इनपुट डेटा को मॉडल द्वारा संसाधित किया जाता है ताकि पूर्वानुमान प्राप्त किया जा सके।.
प्रत्येक परत डेटा को संसाधित करती है और उसे अगली परत को भेजती है, जब तक कि अंतिम परत परिणाम प्रदान नहीं कर देती।.
5. ⚖️ हानि फलन की गणना करें
लॉस फंक्शन यह मापता है कि मॉडल की भविष्यवाणियाँ वास्तविक मानों (लेबल) से कितनी सटीक हैं। एक सामान्य माप भविष्यवाणित और वास्तविक प्रतिक्रिया के बीच की त्रुटि है।.
जितना अधिक नुकसान होगा, मॉडल की भविष्यवाणी उतनी ही खराब होगी।.
6. 🔙 बैकप्रोपैगेशन
रिवर्स इटिरेशन में, त्रुटि को मॉडल के आउटपुट से लेकर पिछली परतों तक ट्रैक किया जाता है।.
त्रुटि को कनेक्शनों के भार में पुनर्वितरित किया जाता है, और मॉडल भार को इस प्रकार समायोजित करता है कि त्रुटियां कम हो जाएं।.
यह ग्रेडिएंट डिसेंट का उपयोग करके किया जाता है: ग्रेडिएंट वेक्टर की गणना की जाती है, जो यह दर्शाता है कि त्रुटि को कम करने के लिए भार को कैसे बदला जाना चाहिए।.
7. 🔧 वज़न अपडेट करें
त्रुटि की गणना हो जाने के बाद, लर्निंग रेट के आधार पर थोड़े से समायोजन के साथ कनेक्शन के भार को अपडेट किया जाता है।.
लर्निंग रेट यह निर्धारित करता है कि प्रत्येक चरण में वेट्स में कितना बदलाव किया जाता है। बहुत अधिक बदलाव मॉडल को अस्थिर कर सकते हैं, जबकि बहुत कम बदलाव सीखने की प्रक्रिया को धीमा कर देते हैं।.
8. 🔁 दोहराएँ (युगों)
फॉरवर्ड पास, त्रुटि गणना और वेट अपडेट की यह प्रक्रिया कई बार दोहराई जाती है, अक्सर कई युगों (पूरे डेटासेट के माध्यम से पास) तक, जब तक कि मॉडल स्वीकार्य सटीकता प्राप्त नहीं कर लेता।.
प्रत्येक युग के साथ, मॉडल थोड़ा और सीखता है और अपने भार को और समायोजित करता है।.
9. 📉 सत्यापन और परीक्षण
मॉडल को प्रशिक्षित करने के बाद, इसकी सामान्यीकरण क्षमता की जाँच करने के लिए इसे एक मान्य डेटासेट पर परखा जाता है। इससे यह सुनिश्चित होता है कि इसने न केवल प्रशिक्षण डेटा को "याद" कर लिया है, बल्कि अज्ञात डेटा पर भी सटीक पूर्वानुमान लगा सकता है।.
परीक्षण डेटा मॉडल को व्यवहार में उपयोग करने से पहले उसके अंतिम प्रदर्शन को मापने में मदद करता है।.
10. 🚀 अनुकूलन
मॉडल को बेहतर बनाने के लिए आगे के चरणों में हाइपरपैरामीटर ट्यूनिंग (जैसे, लर्निंग रेट या नेटवर्क संरचना को समायोजित करना), रेगुलराइजेशन (ओवरफिटिंग से बचने के लिए), या डेटा की मात्रा बढ़ाना शामिल है।.
📊🔙 कृत्रिम बुद्धिमत्ता: व्याख्या योग्य एआई (XAI), हीटमैप, सरोगेट मॉडल या अन्य समाधानों के साथ एआई के ब्लैक बॉक्स को समझने योग्य, बोधगम्य और व्याख्या योग्य बनाना।

कृत्रिम बुद्धिमत्ता: व्याख्या योग्य एआई (XAI), हीटमैप, सरोगेट मॉडल या अन्य समाधानों के साथ एआई के ब्लैक बॉक्स को समझने योग्य, बोधगम्य और व्याख्या योग्य बनाना – चित्र: Xpert.Digital
कृत्रिम बुद्धिमत्ता (एआई) का तथाकथित "ब्लैक बॉक्स" एक महत्वपूर्ण और गंभीर समस्या है। यहां तक कि विशेषज्ञ भी अक्सर एआई प्रणालियों के निर्णय लेने के तरीके को पूरी तरह से समझने में असमर्थ होते हैं। पारदर्शिता की यह कमी विशेष रूप से अर्थशास्त्र, राजनीति और चिकित्सा जैसे महत्वपूर्ण क्षेत्रों में गंभीर समस्याएं पैदा कर सकती है। निदान और उपचार संबंधी सुझावों के लिए एआई प्रणाली पर निर्भर रहने वाले डॉक्टर या चिकित्सक को इसके निर्णयों पर पूरा भरोसा होना चाहिए। हालांकि, यदि एआई की निर्णय लेने की प्रक्रिया पर्याप्त रूप से पारदर्शी नहीं है, तो अनिश्चितता उत्पन्न होती है, जिससे अविश्वास पैदा हो सकता है - और यह उन स्थितियों में भी हो सकता है जहां मानव जीवन दांव पर लगा हो।.
इसके बारे में यहां अधिक जानकारी:
हम आपके लिए हैं - सलाह - योजना - कार्यान्वयन - परियोजना प्रबंधन
☑️ रणनीति, परामर्श, योजना और कार्यान्वयन में एसएमई का समर्थन
☑️ डिजिटल रणनीति और डिजिटलीकरण का निर्माण या पुनर्संरेखण
☑️ अंतर्राष्ट्रीय बिक्री प्रक्रियाओं का विस्तार और अनुकूलन
☑️ वैश्विक और डिजिटल B2B ट्रेडिंग प्लेटफॉर्म
☑️ पायनियर बिजनेस डेवलपमेंट

Konrad Wolfenstein
मुझे आपके निजी सलाहकार के रूप में सेवा करने में खुशी होगी।
आप नीचे दिए गए संपर्क फ़ॉर्म को भरकर मुझसे संपर्क कर सकते हैं या बस मुझे +49 89 89 674 804 (म्यूनिख) ।
मैं हमारी संयुक्त परियोजना की प्रतीक्षा कर रहा हूं।
मुझे लिखें

एक्सपर्ट.डिजिटल - Konrad Wolfenstein
एक्सपर्ट.डिजिटल डिजिटलाइजेशन, मैकेनिकल इंजीनियरिंग, लॉजिस्टिक्स/इंट्रालॉजिस्टिक्स और फोटोवोल्टिक्स पर फोकस के साथ उद्योग का केंद्र है।
अपने 360° व्यवसाय विकास समाधान के साथ, हम नए व्यवसाय से लेकर बिक्री के बाद तक प्रसिद्ध कंपनियों का समर्थन करते हैं।
मार्केट इंटेलिजेंस, स्मार्केटिंग, मार्केटिंग ऑटोमेशन, कंटेंट डेवलपमेंट, पीआर, मेल अभियान, वैयक्तिकृत सोशल मीडिया और लीड पोषण हमारे डिजिटल टूल का हिस्सा हैं।
आप यहां अधिक जानकारी प्राप्त कर सकते हैं: www.xpert.digital - www.xpert.solar - www.xpert.plus
संपर्क में रहना

















