
एआई को समझाने का प्रयास: कृत्रिम बुद्धिमत्ता कैसे काम करती है और कार्य करती है - इसे कैसे प्रशिक्षित किया जाता है?

प्रकाशित: 8 सितंबर, 2024 / अद्यतन: 9 सितंबर, 2024 - लेखक: कोनराड वोल्फेंस्टीन

एआई को समझाने का प्रयास: कृत्रिम बुद्धिमत्ता कैसे काम करती है और इसे कैसे प्रशिक्षित किया जाता है? - छवि: एक्सपर्ट.डिजिटल
📊 डेटा इनपुट से लेकर मॉडल भविष्यवाणी तक: एआई प्रक्रिया
कृत्रिम बुद्धिमत्ता (एआई) कैसे काम करती है? 🤖
कृत्रिम बुद्धिमत्ता (एआई) कैसे काम करती है इसे कई स्पष्ट रूप से परिभाषित चरणों में विभाजित किया जा सकता है। इनमें से प्रत्येक चरण एआई द्वारा प्रदान किए जाने वाले अंतिम परिणाम के लिए महत्वपूर्ण है। प्रक्रिया डेटा प्रविष्टि के साथ शुरू होती है और मॉडल भविष्यवाणी और संभावित प्रतिक्रिया या आगे के प्रशिक्षण दौर के साथ समाप्त होती है। ये चरण उस प्रक्रिया का वर्णन करते हैं जिससे लगभग सभी एआई मॉडल गुजरते हैं, भले ही वे नियमों के सरल सेट हों या अत्यधिक जटिल तंत्रिका नेटवर्क हों।
1. डेटा इनपुट 📊
सभी कृत्रिम बुद्धिमत्ता का आधार वह डेटा है जिसके साथ यह काम करता है। यह डेटा विभिन्न रूपों में हो सकता है, उदाहरण के लिए चित्र, पाठ, ऑडियो फ़ाइलें या वीडियो। एआई इस कच्चे डेटा का उपयोग पैटर्न को पहचानने और निर्णय लेने के लिए करता है। डेटा की गुणवत्ता और मात्रा यहां एक केंद्रीय भूमिका निभाती है, क्योंकि मॉडल बाद में कितनी अच्छी तरह या खराब तरीके से काम करता है, इस पर उनका महत्वपूर्ण प्रभाव पड़ता है।
डेटा जितना व्यापक और सटीक होगा, एआई उतना ही बेहतर सीख सकता है। उदाहरण के लिए, जब किसी एआई को छवि प्रसंस्करण के लिए प्रशिक्षित किया जाता है, तो उसे विभिन्न वस्तुओं की सही पहचान करने के लिए बड़ी मात्रा में छवि डेटा की आवश्यकता होती है। भाषा मॉडल के साथ, यह टेक्स्ट डेटा है जो एआई को मानव भाषा को समझने और उत्पन्न करने में मदद करता है। डेटा इनपुट पहला और सबसे महत्वपूर्ण चरणों में से एक है, क्योंकि पूर्वानुमानों की गुणवत्ता केवल अंतर्निहित डेटा जितनी ही अच्छी हो सकती है। कंप्यूटर विज्ञान का एक प्रसिद्ध सिद्धांत इसे "कचरा अंदर, कचरा बाहर" कहावत के साथ वर्णित करता है - खराब डेटा से बुरे परिणाम मिलते हैं।
2. डेटा प्रीप्रोसेसिंग 🧹
एक बार डेटा दर्ज हो जाने के बाद, इसे वास्तविक मॉडल में फीड करने से पहले इसे तैयार करने की आवश्यकता होती है। इस प्रक्रिया को डेटा प्रीप्रोसेसिंग कहा जाता है। यहां उद्देश्य डेटा को ऐसे रूप में रखना है जिसे मॉडल द्वारा बेहतर ढंग से संसाधित किया जा सके।
प्रीप्रोसेसिंग में एक सामान्य कदम डेटा सामान्यीकरण है। इसका मतलब यह है कि डेटा को मूल्यों की एक समान श्रेणी में लाया जाता है ताकि मॉडल इसे समान रूप से व्यवहार करे। एक उदाहरण किसी छवि के सभी पिक्सेल मानों को 0 से 255 के बजाय 0 से 1 की सीमा तक स्केल करना होगा।
प्रीप्रोसेसिंग का एक अन्य महत्वपूर्ण हिस्सा तथाकथित फीचर निष्कर्षण है। कच्चे डेटा से कुछ विशेषताएं निकाली जाती हैं जो विशेष रूप से मॉडल के लिए प्रासंगिक होती हैं। उदाहरण के लिए, छवि प्रसंस्करण में, यह किनारे या कुछ रंग पैटर्न हो सकते हैं, जबकि ग्रंथों में, प्रासंगिक कीवर्ड या वाक्य संरचनाएं निकाली जाती हैं। एआई की सीखने की प्रक्रिया को अधिक कुशल और सटीक बनाने के लिए प्रीप्रोसेसिंग महत्वपूर्ण है।
3. मॉडल 🧩
मॉडल हर कृत्रिम बुद्धिमत्ता का दिल है। यहां एल्गोरिदम और गणितीय गणनाओं के आधार पर डेटा का विश्लेषण और प्रसंस्करण किया जाता है। एक मॉडल विभिन्न रूपों में मौजूद हो सकता है। सबसे प्रसिद्ध मॉडलों में से एक तंत्रिका नेटवर्क है, जो इस पर आधारित है कि मानव मस्तिष्क कैसे काम करता है।
तंत्रिका नेटवर्क में कृत्रिम न्यूरॉन्स की कई परतें होती हैं जो सूचनाओं को संसाधित और प्रसारित करती हैं। प्रत्येक परत पिछली परत के आउटपुट लेती है और उन्हें आगे संसाधित करती है। तंत्रिका नेटवर्क की सीखने की प्रक्रिया में इन न्यूरॉन्स के बीच कनेक्शन के वजन को समायोजित करना शामिल है ताकि नेटवर्क तेजी से सटीक भविष्यवाणियां या वर्गीकरण कर सके। यह अनुकूलन प्रशिक्षण के माध्यम से होता है, जिसमें नेटवर्क बड़ी मात्रा में नमूना डेटा तक पहुंचता है और पुनरावृत्त रूप से अपने आंतरिक मापदंडों (वजन) में सुधार करता है।
तंत्रिका नेटवर्क के अलावा, एआई मॉडल में कई अन्य एल्गोरिदम भी उपयोग किए जाते हैं। इनमें निर्णय वृक्ष, यादृच्छिक वन, समर्थन वेक्टर मशीनें और कई अन्य शामिल हैं। किस एल्गोरिदम का उपयोग किया जाता है यह विशिष्ट कार्य और उपलब्ध डेटा पर निर्भर करता है।
4. मॉडल भविष्यवाणी 🔍
मॉडल को डेटा के साथ प्रशिक्षित करने के बाद, यह भविष्यवाणी करने में सक्षम है। इस चरण को मॉडल पूर्वानुमान कहा जाता है. एआई एक इनपुट प्राप्त करता है और अब तक सीखे गए पैटर्न के आधार पर एक आउटपुट, यानी एक भविष्यवाणी या निर्णय देता है।
यह भविष्यवाणी विभिन्न रूप ले सकती है. उदाहरण के लिए, एक छवि वर्गीकरण मॉडल में, एआई भविष्यवाणी कर सकता है कि छवि में कौन सी वस्तु दिखाई दे रही है। एक भाषा मॉडल में, यह भविष्यवाणी कर सकता है कि वाक्य में अगला शब्द कौन सा आएगा। वित्तीय भविष्यवाणियों में, एआई भविष्यवाणी कर सकता है कि शेयर बाजार कैसा प्रदर्शन करेगा।
इस बात पर जोर देना महत्वपूर्ण है कि भविष्यवाणियों की सटीकता प्रशिक्षण डेटा की गुणवत्ता और मॉडल वास्तुकला पर काफी हद तक निर्भर करती है। अपर्याप्त या पक्षपाती डेटा पर प्रशिक्षित मॉडल के गलत भविष्यवाणियां करने की संभावना है।
5. प्रतिक्रिया और प्रशिक्षण (वैकल्पिक) ♻️
एआई के काम का एक अन्य महत्वपूर्ण हिस्सा फीडबैक तंत्र है। मॉडल की नियमित रूप से जाँच की जाती है और उसे और अधिक अनुकूलित किया जाता है। यह प्रक्रिया या तो प्रशिक्षण के दौरान या मॉडल भविष्यवाणी के बाद होती है।
यदि मॉडल गलत भविष्यवाणियां करता है, तो वह फीडबैक के माध्यम से इन त्रुटियों का पता लगा सकता है और तदनुसार अपने आंतरिक मापदंडों को समायोजित कर सकता है। यह वास्तविक परिणामों के साथ मॉडल भविष्यवाणियों की तुलना करके किया जाता है (उदाहरण के लिए ज्ञात डेटा के साथ जिसके लिए सही उत्तर पहले से मौजूद हैं)। इस संदर्भ में एक विशिष्ट प्रक्रिया तथाकथित पर्यवेक्षित शिक्षण है, जिसमें एआई उदाहरण डेटा से सीखता है जो पहले से ही सही उत्तरों के साथ प्रदान किया जाता है।
फीडबैक का एक सामान्य तरीका तंत्रिका नेटवर्क में उपयोग किया जाने वाला बैकप्रॉपैगेशन एल्गोरिदम है। मॉडल द्वारा की गई त्रुटियों को न्यूरॉन कनेक्शन के वजन को समायोजित करने के लिए नेटवर्क के माध्यम से पीछे की ओर प्रचारित किया जाता है। मॉडल अपनी गलतियों से सीखता है और अपनी भविष्यवाणियों में अधिक से अधिक सटीक हो जाता है।
प्रशिक्षण की भूमिका 🏋️♂️
एआई का प्रशिक्षण एक पुनरावृत्तीय प्रक्रिया है। मॉडल जितना अधिक डेटा देखता है और जितनी अधिक बार इस डेटा के आधार पर उसे प्रशिक्षित किया जाता है, उसकी भविष्यवाणियां उतनी ही सटीक हो जाती हैं। हालाँकि, इसकी भी सीमाएँ हैं: एक अत्यधिक प्रशिक्षित मॉडल में तथाकथित "ओवरफिटिंग" समस्याएँ हो सकती हैं। इसका मतलब यह है कि यह प्रशिक्षण डेटा को इतनी अच्छी तरह से याद रखता है कि यह नए, अज्ञात डेटा पर बदतर परिणाम देता है। इसलिए मॉडल को प्रशिक्षित करना महत्वपूर्ण है ताकि यह सामान्यीकरण कर सके और नए डेटा पर भी अच्छी भविष्यवाणी कर सके।
नियमित प्रशिक्षण के अलावा, स्थानांतरण शिक्षण जैसी प्रक्रियाएँ भी हैं। यहां, एक मॉडल जिसे पहले से ही बड़ी मात्रा में डेटा पर प्रशिक्षित किया गया है, उसका उपयोग एक नए, समान कार्य के लिए किया जाता है। इससे समय और कंप्यूटिंग शक्ति की बचत होती है क्योंकि मॉडल को शुरुआत से प्रशिक्षित करने की आवश्यकता नहीं होती है।
अपनी शक्तियों का अधिकतम उपयोग करें 🚀
कृत्रिम बुद्धिमत्ता का कार्य विभिन्न चरणों की जटिल अंतःक्रिया पर आधारित होता है। डेटा प्रविष्टि, प्रीप्रोसेसिंग, मॉडल प्रशिक्षण, भविष्यवाणी और फीडबैक से लेकर कई कारक हैं जो एआई की सटीकता और दक्षता को प्रभावित करते हैं। एक अच्छी तरह से प्रशिक्षित एआई जीवन के कई क्षेत्रों में भारी लाभ प्रदान कर सकता है - सरल कार्यों को स्वचालित करने से लेकर जटिल समस्याओं को हल करने तक। लेकिन एआई की शक्तियों का अधिकतम लाभ उठाने के लिए इसकी सीमाओं और संभावित नुकसानों को समझना भी उतना ही महत्वपूर्ण है।
🤖📚 सरलता से समझाया गया: एआई को कैसे प्रशिक्षित किया जाता है?
🤖📊एआई सीखने की प्रक्रिया: कैप्चर करें, लिंक करें और सेव करें
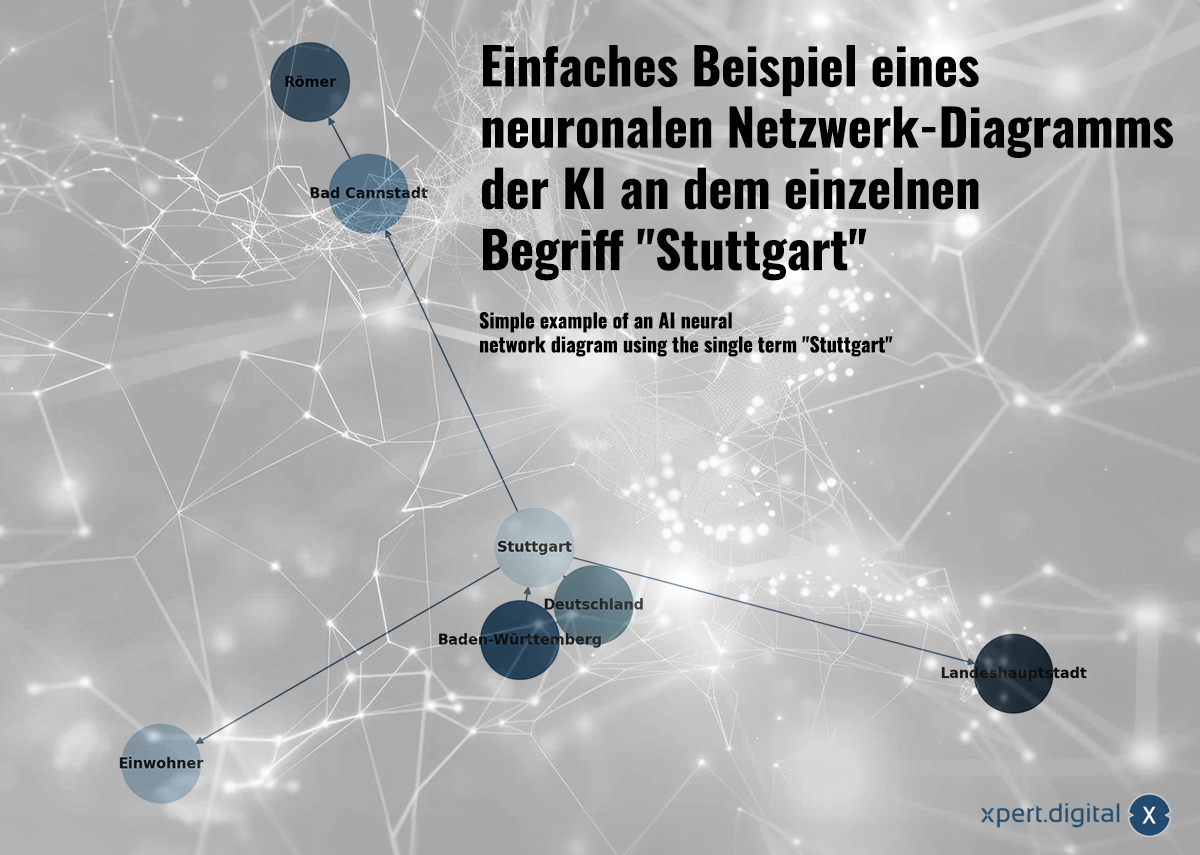
एकल शब्द "स्टटगार्ट" का उपयोग करते हुए एआई न्यूरल नेटवर्क आरेख का सरल उदाहरण - छवि: Xpert.Digital
🌟 डेटा एकत्र करें और तैयार करें
एआई सीखने की प्रक्रिया में पहला कदम डेटा एकत्र करना और तैयार करना है। यह डेटा विभिन्न स्रोतों से आ सकता है, जैसे डेटाबेस, सेंसर, टेक्स्ट या चित्र।
🌟संबंधित डेटा (तंत्रिका नेटवर्क)
एकत्रित डेटा तंत्रिका नेटवर्क में एक दूसरे से संबंधित है। प्रत्येक डेटा पैकेट को "न्यूरॉन्स" (नोड्स) के नेटवर्क में कनेक्शन द्वारा दर्शाया जाता है। स्टटगार्ट शहर का एक सरल उदाहरण इस तरह दिख सकता है:
a) स्टटगार्ट बाडेन-वुर्टेमबर्ग में एक शहर है
b) बाडेन-वुर्टेमबर्ग जर्मनी में एक संघीय राज्य है
c) स्टटगार्ट जर्मनी में एक शहर है
d) स्टटगार्ट की जनसंख्या 2023 में 633,484 है
e) बैड कैनस्टैट स्टटगार्ट का एक जिला है
f) बैड कैनस्टैट की स्थापना रोमनों द्वारा की गई थी
छ) स्टटगार्ट बाडेन-वुर्टेमबर्ग राज्य की राजधानी है
डेटा वॉल्यूम के आकार के आधार पर, उपयोग किए गए एआई मॉडल का उपयोग करके संभावित खर्चों के पैरामीटर बनाए जाते हैं। उदाहरण के तौर पर: GPT-3 में लगभग 175 बिलियन पैरामीटर हैं!
🌟 भंडारण और अनुकूलन (सीखना)
डेटा तंत्रिका नेटवर्क को खिलाया जाता है। वे एआई मॉडल से गुजरते हैं और कनेक्शन के माध्यम से संसाधित होते हैं (सिनैप्स के समान)। मॉडल को प्रशिक्षित करने या किसी कार्य को पूरा करने के लिए न्यूरॉन्स के बीच वजन (पैरामीटर) को समायोजित किया जाता है।
प्रत्यक्ष पहुंच, अनुक्रमित पहुंच, अनुक्रमिक या बैच भंडारण जैसे भंडारण के पारंपरिक रूपों के विपरीत, तंत्रिका नेटवर्क एक अपरंपरागत तरीके से डेटा संग्रहीत करते हैं। "डेटा" न्यूरॉन्स के बीच कनेक्शन के वजन और पूर्वाग्रह में संग्रहीत होता है।
तंत्रिका नेटवर्क में जानकारी का वास्तविक "भंडारण" न्यूरॉन्स के बीच कनेक्शन भार को समायोजित करके होता है। एआई मॉडल इनपुट डेटा और एक परिभाषित शिक्षण एल्गोरिदम के आधार पर इन भारों और पूर्वाग्रहों को लगातार समायोजित करके "सीखता है"। यह एक सतत प्रक्रिया है जिसमें मॉडल बार-बार समायोजन के माध्यम से अधिक सटीक भविष्यवाणियां कर सकता है।
एआई मॉडल को एक प्रकार की प्रोग्रामिंग माना जा सकता है क्योंकि यह परिभाषित एल्गोरिदम और गणितीय गणनाओं के माध्यम से बनाया गया है और सटीक भविष्यवाणियां करने के लिए अपने मापदंडों (वजन) के समायोजन में लगातार सुधार करता है। यह चलने वाली प्रक्रिया है।
पूर्वाग्रह तंत्रिका नेटवर्क में अतिरिक्त पैरामीटर हैं जो न्यूरॉन के भारित इनपुट मूल्यों में जोड़े जाते हैं। वे मापदंडों को महत्व देने (महत्वपूर्ण, कम महत्वपूर्ण, महत्वपूर्ण, आदि) की अनुमति देते हैं, जिससे एआई अधिक लचीला और सटीक हो जाता है।
तंत्रिका नेटवर्क न केवल व्यक्तिगत तथ्यों को संग्रहीत कर सकते हैं, बल्कि पैटर्न पहचान के माध्यम से डेटा के बीच कनेक्शन को भी पहचान सकते हैं। स्टटगार्ट उदाहरण दिखाता है कि ज्ञान को तंत्रिका नेटवर्क में कैसे पेश किया जा सकता है, लेकिन तंत्रिका नेटवर्क स्पष्ट ज्ञान के माध्यम से नहीं सीखते हैं (जैसा कि इस सरल उदाहरण में है) बल्कि डेटा पैटर्न के विश्लेषण के माध्यम से सीखते हैं। तंत्रिका नेटवर्क न केवल व्यक्तिगत तथ्यों को संग्रहीत कर सकते हैं, बल्कि इनपुट डेटा के बीच वजन और संबंध भी सीख सकते हैं।
यह प्रवाह एक समझने योग्य परिचय प्रदान करता है कि एआई और तंत्रिका नेटवर्क विशेष रूप से कैसे काम करते हैं, तकनीकी विवरणों में बहुत गहराई तक जाने के बिना। यह दर्शाता है कि तंत्रिका नेटवर्क में जानकारी का भंडारण पारंपरिक डेटाबेस की तरह नहीं किया जाता है, बल्कि नेटवर्क के भीतर कनेक्शन (वजन) को समायोजित करके किया जाता है।
🤖📚 अधिक विस्तृत: एआई को कैसे प्रशिक्षित किया जाता है?
🏋️♂️ एआई, विशेष रूप से मशीन लर्निंग मॉडल का प्रशिक्षण कई चरणों में होता है। एआई का प्रशिक्षण फीडबैक और समायोजन के माध्यम से मॉडल मापदंडों को लगातार अनुकूलित करने पर आधारित है जब तक कि मॉडल प्रदान किए गए डेटा पर सर्वोत्तम प्रदर्शन नहीं दिखाता। यह प्रक्रिया कैसे काम करती है इसका विस्तृत विवरण यहां दिया गया है:
1. 📊 डेटा एकत्र करें और तैयार करें
डेटा एआई प्रशिक्षण की नींव है। सिस्टम के विश्लेषण के लिए उनमें आम तौर पर हजारों या लाखों उदाहरण होते हैं। उदाहरण चित्र, पाठ या समय श्रृंखला डेटा हैं।
त्रुटि के अनावश्यक स्रोतों से बचने के लिए डेटा को साफ़ और सामान्यीकृत किया जाना चाहिए। अक्सर डेटा को उन सुविधाओं में परिवर्तित कर दिया जाता है जिनमें प्रासंगिक जानकारी होती है।
2. 🔍मॉडल को परिभाषित करें
मॉडल एक गणितीय फ़ंक्शन है जो डेटा में संबंधों का वर्णन करता है। तंत्रिका नेटवर्क में, जो अक्सर एआई के लिए उपयोग किया जाता है, मॉडल में न्यूरॉन्स की कई परतें एक साथ जुड़ी होती हैं।
प्रत्येक न्यूरॉन इनपुट डेटा को संसाधित करने के लिए एक गणितीय ऑपरेशन करता है और फिर अगले न्यूरॉन को एक सिग्नल भेजता है।
3. 🔄 वजन आरंभ करें
न्यूरॉन्स के बीच कनेक्शन में वजन होता है जो शुरू में यादृच्छिक रूप से निर्धारित होता है। ये भार निर्धारित करते हैं कि एक न्यूरॉन किसी संकेत पर कितनी दृढ़ता से प्रतिक्रिया करता है।
प्रशिक्षण का लक्ष्य इन वज़न को समायोजित करना है ताकि मॉडल बेहतर भविष्यवाणियाँ कर सके।
4. ➡️ अग्रगामी प्रसार
फॉरवर्ड पास भविष्यवाणी उत्पन्न करने के लिए मॉडल के माध्यम से इनपुट डेटा को पास करता है।
प्रत्येक परत डेटा को संसाधित करती है और इसे अगली परत तक भेजती है जब तक कि अंतिम परत परिणाम नहीं दे देती।
5. ⚖️ हानि फ़ंक्शन की गणना करें
हानि फ़ंक्शन मापता है कि वास्तविक मूल्यों (लेबल) की तुलना में मॉडल की भविष्यवाणियां कितनी अच्छी हैं। पूर्वानुमानित और वास्तविक प्रतिक्रिया के बीच त्रुटि एक सामान्य उपाय है।
नुकसान जितना अधिक होगा, मॉडल की भविष्यवाणी उतनी ही खराब होगी।
6. 🔙 बैकप्रोपेगेशन
बैकवर्ड पास में, त्रुटि को मॉडल के आउटपुट से पिछली परतों में वापस फीड किया जाता है।
त्रुटि को कनेक्शन के भार में पुनर्वितरित किया जाता है और मॉडल भार को समायोजित करता है ताकि त्रुटियां छोटी हो जाएं।
यह ग्रेडिएंट डिसेंट का उपयोग करके किया जाता है: ग्रेडिएंट वेक्टर की गणना की जाती है, जो इंगित करता है कि त्रुटि को कम करने के लिए वजन को कैसे बदला जाना चाहिए।
7. 🔧 वज़न अद्यतन करें
त्रुटि की गणना के बाद, कनेक्शन के वजन को सीखने की दर के आधार पर एक छोटे समायोजन के साथ अद्यतन किया जाता है।
सीखने की दर यह निर्धारित करती है कि प्रत्येक चरण के साथ वजन कितना बदला जाता है। बहुत बड़े परिवर्तन मॉडल को अस्थिर बना सकते हैं, और बहुत छोटे परिवर्तन सीखने की प्रक्रिया को धीमा कर सकते हैं।
8. 🔁 पुनरावृत्ति (युग)
फ़ॉरवर्ड पास, त्रुटि गणना और वज़न अपडेट की यह प्रक्रिया अक्सर कई युगों में दोहराई जाती है (संपूर्ण डेटा सेट से गुजरती है), जब तक कि मॉडल स्वीकार्य सटीकता तक नहीं पहुंच जाता।
प्रत्येक युग के साथ, मॉडल थोड़ा और सीखता है और अपने वजन को और अधिक समायोजित करता है।
9. 📉 सत्यापन एवं परीक्षण
मॉडल को प्रशिक्षित करने के बाद, यह जांचने के लिए एक मान्य डेटासेट पर परीक्षण किया जाता है कि यह कितनी अच्छी तरह सामान्यीकृत होता है। यह सुनिश्चित करता है कि इसने न केवल प्रशिक्षण डेटा को "याद" कर लिया है, बल्कि अज्ञात डेटा पर अच्छी भविष्यवाणी भी करता है।
परीक्षण डेटा व्यवहार में उपयोग किए जाने से पहले मॉडल के अंतिम प्रदर्शन को मापने में मदद करता है।
10. 🚀 अनुकूलन
मॉडल को बेहतर बनाने के लिए अतिरिक्त कदमों में हाइपरपैरामीटर ट्यूनिंग (उदाहरण के लिए सीखने की दर या नेटवर्क संरचना को समायोजित करना), नियमितीकरण (ओवरफिटिंग से बचने के लिए), या डेटा की मात्रा बढ़ाना शामिल है।
📊🔙 आर्टिफिशियल इंटेलिजेंस: एआई के ब्लैक बॉक्स को समझाने योग्य एआई (एक्सएआई), हीटमैप, सरोगेट मॉडल या अन्य समाधानों के साथ समझने योग्य, समझने योग्य और समझाने योग्य बनाएं।

आर्टिफिशियल इंटेलिजेंस: एआई के ब्लैक बॉक्स को समझाने योग्य एआई (एक्सएआई), हीटमैप, सरोगेट मॉडल या अन्य समाधानों के साथ समझने योग्य, समझने योग्य और समझाने योग्य बनाना - छवि: एक्सपर्ट.डिजिटल
कृत्रिम बुद्धिमत्ता (एआई) का तथाकथित "ब्लैक बॉक्स" एक महत्वपूर्ण और वर्तमान समस्या का प्रतिनिधित्व करता है। यहां तक कि विशेषज्ञों को भी अक्सर यह समझने में सक्षम नहीं होने की चुनौती का सामना करना पड़ता है कि एआई सिस्टम अपने निर्णयों पर कैसे पहुंचते हैं। पारदर्शिता की यह कमी महत्वपूर्ण समस्याएं पैदा कर सकती है, खासकर अर्थशास्त्र, राजनीति या चिकित्सा जैसे महत्वपूर्ण क्षेत्रों में। एक डॉक्टर या चिकित्सा पेशेवर जो निदान करने और चिकित्सा की सिफारिश करने के लिए एआई प्रणाली पर निर्भर करता है, उसे लिए गए निर्णयों पर भरोसा होना चाहिए। हालाँकि, यदि एआई की निर्णय-प्रक्रिया पर्याप्त रूप से पारदर्शी नहीं है, तो अनिश्चितता और संभावित रूप से विश्वास की कमी उत्पन्न होती है - ऐसी स्थितियों में जहां मानव जीवन खतरे में पड़ सकता है।
इसके बारे में यहां अधिक जानकारी:
हम आपके लिए हैं - सलाह - योजना - कार्यान्वयन - परियोजना प्रबंधन
☑️ रणनीति, परामर्श, योजना और कार्यान्वयन में एसएमई का समर्थन
☑️ डिजिटल रणनीति और डिजिटलीकरण का निर्माण या पुनर्संरेखण
☑️ अंतर्राष्ट्रीय बिक्री प्रक्रियाओं का विस्तार और अनुकूलन
☑️ वैश्विक और डिजिटल B2B ट्रेडिंग प्लेटफॉर्म
☑️ पायनियर बिजनेस डेवलपमेंट

कोनराड वोल्फेंस्टीन
मुझे आपके निजी सलाहकार के रूप में सेवा करने में खुशी होगी।
आप नीचे दिए गए संपर्क फ़ॉर्म को भरकर मुझसे संपर्क कर सकते हैं या बस मुझे +49 89 89 674 804 (म्यूनिख) ।
मैं हमारी संयुक्त परियोजना की प्रतीक्षा कर रहा हूं।
मुझे लिखें

एक्सपर्ट.डिजिटल - कोनराड वोल्फेंस्टीन
एक्सपर्ट.डिजिटल डिजिटलाइजेशन, मैकेनिकल इंजीनियरिंग, लॉजिस्टिक्स/इंट्रालॉजिस्टिक्स और फोटोवोल्टिक्स पर फोकस के साथ उद्योग का केंद्र है।
अपने 360° व्यवसाय विकास समाधान के साथ, हम नए व्यवसाय से लेकर बिक्री के बाद तक प्रसिद्ध कंपनियों का समर्थन करते हैं।
मार्केट इंटेलिजेंस, स्मार्केटिंग, मार्केटिंग ऑटोमेशन, कंटेंट डेवलपमेंट, पीआर, मेल अभियान, वैयक्तिकृत सोशल मीडिया और लीड पोषण हमारे डिजिटल टूल का हिस्सा हैं।
आप यहां अधिक जानकारी प्राप्त कर सकते हैं: www.xpert.digital - www.xpert.solar - www.xpert.plus
संपर्क में रहना


















