


BERT (ट्रांसफॉर्मर से द्विदिशात्मक एनकोडर प्रतिनिधित्व) के साथ AI और SEO - प्राकृतिक भाषा प्रसंस्करण (NLP) के क्षेत्र में एक मॉडल - चित्र: Xpert.Digital
🚀💬 गूगल द्वारा विकसित: BERT और NLP के लिए इसका महत्व - द्विदिशात्मक पाठ समझ क्यों महत्वपूर्ण है
🔍🗣️ BERT, जिसका पूरा नाम Bidirectional Encoder Representations from Transformers है, गूगल द्वारा विकसित प्राकृतिक भाषा प्रसंस्करण (NLP) के क्षेत्र में एक महत्वपूर्ण मॉडल है। इसने मशीनों द्वारा भाषा को समझने के तरीके में क्रांतिकारी बदलाव ला दिए हैं। पहले के मॉडल जो पाठ का विश्लेषण बाएं से दाएं या इसके विपरीत क्रम में करते थे, उनके विपरीत, BERT द्विदिशात्मक प्रसंस्करण को सक्षम बनाता है। इसका अर्थ है कि यह किसी शब्द के संदर्भ को उसके पहले और बाद के पाठ अनुक्रमों से ग्रहण करता है। यह क्षमता जटिल भाषाई संबंधों की समझ को काफी हद तक बेहतर बनाती है।.
🔍 BERT की वास्तुकला
हाल के वर्षों में, प्राकृतिक भाषा प्रसंस्करण (एनएलपी) में सबसे महत्वपूर्ण विकासों में से एक ट्रांसफ़ॉर्मर मॉडल का परिचय रहा है, जैसा कि 2017 के पीडीएफ पेपर "अटेंशन इज़ ऑल यू नीड" ( विकिपीडिया ) में वर्णित है। इस मॉडल ने मशीन अनुवाद जैसी पहले से इस्तेमाल की जाने वाली संरचनाओं को त्यागकर इस क्षेत्र में मौलिक परिवर्तन ला दिया। इसके बजाय, यह पूरी तरह से ध्यान तंत्र पर निर्भर करता है। ट्रांसफ़ॉर्मर डिज़ाइन तब से कई मॉडलों का आधार बन गया है जो भाषण निर्माण, अनुवाद और अन्य क्षेत्रों में अत्याधुनिक तकनीक का प्रतिनिधित्व करते हैं।
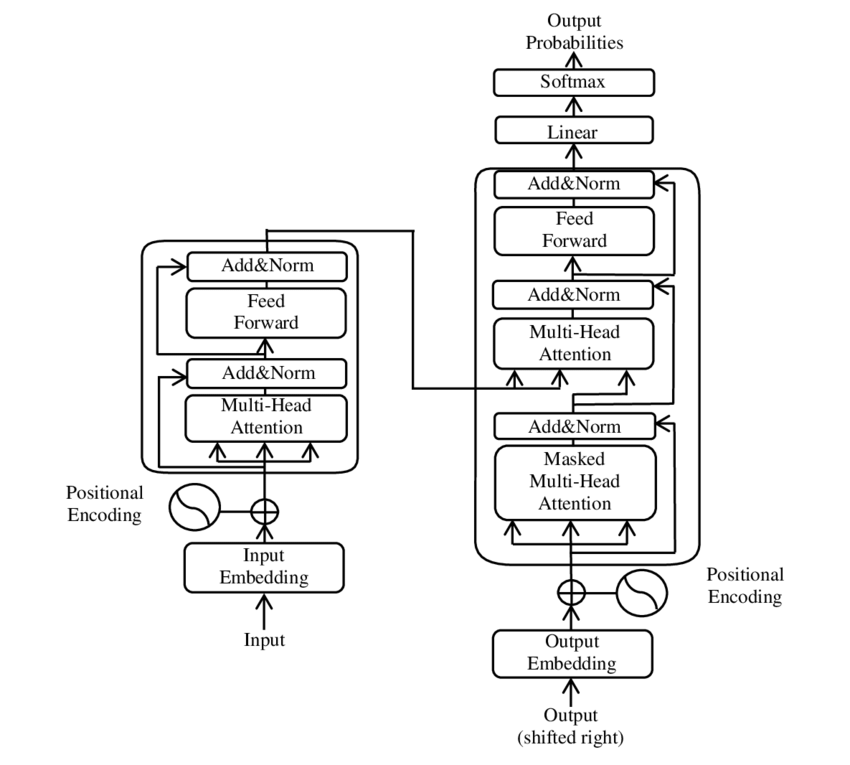
ट्रांसफॉर्मर मॉडल के मुख्य घटकों का एक चित्र – छवि: गूगल
BERT इसी ट्रांसफ़ॉर्मर आर्किटेक्चर पर आधारित है। यह आर्किटेक्चर वाक्य में शब्दों के बीच संबंधों का विश्लेषण करने के लिए तथाकथित स्व-ध्यान तंत्र का उपयोग करता है। प्रत्येक शब्द को पूरे वाक्य के संदर्भ में ध्यान दिया जाता है, जिससे वाक्यविन्यास और अर्थ संबंधी संबंधों की अधिक सटीक समझ प्राप्त होती है।.
“ध्यान ही सब कुछ है” नामक शोध पत्र के लेखक हैं:
- आशीष वासवानी (गूगल ब्रेन)
- नोआम शेज़र (गूगल ब्रेन)
- निकी परमार (गूगल रिसर्च)
- जैकब उस्ज़कोरिट (गूगल रिसर्च)
- लायन जोन्स (गूगल रिसर्च)
- एडन एन. गोमेज़ (टोरंटो विश्वविद्यालय, कार्य का कुछ हिस्सा गूगल ब्रेन में किया गया)
- लुकाज़ कैसर (गूगल ब्रेन)
- इलिया पोलोसुखिन (स्वतंत्र, पूर्व में गूगल रिसर्च में कार्यरत)
इन लेखकों ने इस शोधपत्र में प्रस्तुत ट्रांसफार्मर मॉडल के विकास में महत्वपूर्ण योगदान दिया है।.
🔄 द्विदिशात्मक प्रसंस्करण
BERT की एक प्रमुख विशेषता इसकी द्विदिशात्मक रूप से पाठ को संसाधित करने की क्षमता है। जबकि रिकरेंट न्यूरल नेटवर्क (RNN) या लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) नेटवर्क जैसे पारंपरिक मॉडल पाठ को केवल एक दिशा में संसाधित करते हैं, BERT किसी शब्द के संदर्भ का विश्लेषण दोनों दिशाओं में करता है। इससे मॉडल को अर्थ की सूक्ष्म बारीकियों को बेहतर ढंग से समझने और इस प्रकार अधिक सटीक पूर्वानुमान लगाने में मदद मिलती है।.
🕵️♂️ मुखौटा पहने हुए भाषण का प्रदर्शन
BERT का एक और नवोन्मेषी पहलू मास्क्ड लैंग्वेज मॉडल (MLM) तकनीक है। इसमें, वाक्य में से यादृच्छिक रूप से चुने गए शब्दों को छिपा दिया जाता है, और मॉडल को आसपास के संदर्भ के आधार पर इन शब्दों की भविष्यवाणी करने के लिए प्रशिक्षित किया जाता है। यह विधि BERT को वाक्य में प्रत्येक शब्द के संदर्भ और अर्थ की गहरी समझ विकसित करने के लिए बाध्य करती है।.
🚀 BERT का प्रशिक्षण और अनुकूलन
BERT दो चरणों वाली प्रशिक्षण प्रक्रिया से गुजरता है: पूर्व-प्रशिक्षण और फाइन-ट्यूनिंग।.
📚 पूर्व-प्रशिक्षण
पूर्व-प्रशिक्षण में, BERT को सामान्य भाषा पैटर्न सीखने के लिए बड़ी मात्रा में पाठ के साथ प्रशिक्षित किया जाता है। इसमें विकिपीडिया लेख और अन्य व्यापक पाठ संग्रह शामिल हैं। इस चरण के दौरान, मॉडल बुनियादी भाषाई संरचनाओं और संदर्भों को सीखता है।.
🔧 फाइन-ट्यूनिंग
पूर्व-प्रशिक्षण के बाद, BERT को विशिष्ट NLP कार्यों, जैसे कि पाठ वर्गीकरण या भावना विश्लेषण के लिए अनुकूलित किया जाता है। विशिष्ट अनुप्रयोगों के लिए इसके प्रदर्शन को अनुकूलित करने के लिए मॉडल को छोटे, कार्य-संबंधित डेटासेट के साथ प्रशिक्षित किया जाता है।.
🌍 BERT के अनुप्रयोग क्षेत्र
BERT प्राकृतिक भाषा प्रसंस्करण के कई क्षेत्रों में अत्यंत उपयोगी साबित हुआ है:
सर्च इंजन अनुकूलन
गूगल सर्च क्वेरी को बेहतर ढंग से समझने और अधिक प्रासंगिक परिणाम प्रदर्शित करने के लिए BERT का उपयोग करता है। इससे उपयोगकर्ता अनुभव में काफी सुधार होता है।.
पाठ वर्गीकरण
BERT दस्तावेजों को विषय के आधार पर वर्गीकृत कर सकता है या पाठों में निहित भाव का विश्लेषण कर सकता है।.
नामित इकाई पहचान (एनईआर)
यह मॉडल पाठों में नामित संस्थाओं, जैसे कि लोगों, स्थानों या संगठनों के नामों की पहचान और वर्गीकरण करता है।.
प्रश्न-उत्तर प्रणालियाँ
BERT का उपयोग पूछे गए प्रश्नों के सटीक उत्तर प्रदान करने के लिए किया जाता है।.
🧠 कृत्रिम बुद्धिमत्ता के भविष्य के लिए BERT का महत्व
BERT ने NLP मॉडल के लिए नए मानक स्थापित किए हैं और आगे के नवाचारों का मार्ग प्रशस्त किया है। द्विदिशात्मक प्रसंस्करण की क्षमता और भाषा संदर्भों की गहरी समझ के कारण, इसने AI अनुप्रयोगों की दक्षता और सटीकता में उल्लेखनीय वृद्धि की है।.
🔜 भविष्य के घटनाक्रम
BERT और इसी तरह के मॉडलों के आगे के विकास का लक्ष्य और भी अधिक शक्तिशाली प्रणालियाँ बनाना है। ये प्रणालियाँ अधिक जटिल भाषा संबंधी कार्यों को संभाल सकती हैं और विभिन्न नए अनुप्रयोग क्षेत्रों में उपयोग की जा सकती हैं। ऐसे मॉडलों को रोजमर्रा की तकनीकों में एकीकृत करने से कंप्यूटर के साथ हमारे संपर्क के तरीके में मौलिक परिवर्तन आ सकता है।.
🌟 कृत्रिम बुद्धिमत्ता के विकास में एक महत्वपूर्ण उपलब्धि
BERT कृत्रिम बुद्धिमत्ता के विकास में एक मील का पत्थर है और इसने मशीनों द्वारा प्राकृतिक भाषा को संसाधित करने के तरीके में क्रांतिकारी बदलाव लाया है। इसकी द्विदिशात्मक संरचना भाषाई संबंधों की गहरी समझ को सक्षम बनाती है, जिससे यह विभिन्न प्रकार के अनुप्रयोगों के लिए अपरिहार्य हो जाता है। जैसे-जैसे अनुसंधान आगे बढ़ेगा, BERT जैसे मॉडल AI प्रणालियों को बेहतर बनाने और उनके उपयोग के लिए नई संभावनाएं खोलने में महत्वपूर्ण भूमिका निभाते रहेंगे।.
📣समान विषय
- 📚 BERT का परिचय: एक अभूतपूर्व NLP मॉडल
- 🔍 BERT और NLP में द्विदिशात्मकता की भूमिका
- 🧠 ट्रांसफॉर्मर मॉडल: BERT का आधार
- 🚀 मास्क्ड लैंग्वेज मॉडलिंग: BERT की सफलता की कुंजी
- 📈 BERT अनुकूलन: पूर्व-प्रशिक्षण से लेकर फाइन-ट्यूनिंग तक
- 🌐 आधुनिक प्रौद्योगिकी में BERT के अनुप्रयोग क्षेत्र
- 🤖 कृत्रिम बुद्धिमत्ता के भविष्य पर BERT का प्रभाव
- 💡 भविष्य की संभावनाएं: BERT का और अधिक विकास
- 🏆 कृत्रिम बुद्धिमत्ता के विकास में BERT एक मील का पत्थर है
- 📰 ट्रांसफ़ॉर्मर पेपर “ध्यान ही सब कुछ है” के लेखक: BERT के पीछे के दिमाग
#️⃣ हैशटैग: #एनएलपी #आर्टिफिशियलइंटेलिजेंस #लैंग्वेजमॉडलिंग #ट्रांसफॉर्मर #मशीनलर्निंग
🎯🎯🎯 एक व्यापक सेवा पैकेज में Xpert.Digital की व्यापक, पाँच-गुना विशेषज्ञता का लाभ उठाएँ | BD, R&D, XR, PR और डिजिटल दृश्यता अनुकूलन


Xpert.Digital की व्यापक, पाँच गुना विशेषज्ञता का लाभ एक व्यापक सेवा पैकेज में उठाएँ | R&D, XR, PR और डिजिटल दृश्यता अनुकूलन - छवि: Xpert.Digital
एक्सपर्ट.डिजिटल को विभिन्न उद्योगों का गहन ज्ञान है। यह हमें ऐसी अनुकूलित रणनीतियाँ विकसित करने की अनुमति देता है जो आपके विशिष्ट बाज़ार खंड की आवश्यकताओं और चुनौतियों के अनुरूप होती हैं। बाजार के रुझानों का लगातार विश्लेषण करके और उद्योग के विकास का अनुसरण करके, हम दूरदर्शिता के साथ कार्य कर सकते हैं और नवीन समाधान पेश कर सकते हैं। अनुभव और ज्ञान के संयोजन के माध्यम से, हम अतिरिक्त मूल्य उत्पन्न करते हैं और अपने ग्राहकों को निर्णायक प्रतिस्पर्धी लाभ देते हैं।
इसके बारे में यहां अधिक जानकारी:
BERT: क्रांतिकारी 🌟 NLP तकनीक
🚀 BERT, जिसका पूरा नाम Bidirectional Encoder Representations from Transformers है, Google द्वारा विकसित एक उन्नत भाषा मॉडल है, जिसने 2018 में लॉन्च होने के बाद से प्राकृतिक भाषा प्रसंस्करण (NLP) में एक महत्वपूर्ण उपलब्धि हासिल की है। यह ट्रांसफ़ॉर्मर आर्किटेक्चर पर आधारित है, जिसने मशीनों द्वारा पाठ को समझने और संसाधित करने के तरीके में क्रांतिकारी बदलाव ला दिए हैं। लेकिन BERT को इतना खास क्या बनाता है, और इसका उपयोग किस लिए किया जाता है? इस प्रश्न का उत्तर देने के लिए, हमें BERT के तकनीकी आधार, इसकी कार्यप्रणाली और इसके अनुप्रयोगों पर गहराई से विचार करना होगा।.
📚 1. प्राकृतिक भाषा प्रसंस्करण की मूल बातें
BERT के महत्व को पूरी तरह समझने के लिए, प्राकृतिक भाषा प्रसंस्करण (NLP) के मूल सिद्धांतों की संक्षिप्त समीक्षा करना सहायक होगा। NLP कंप्यूटर और मानव भाषा के बीच परस्पर क्रिया से संबंधित है। इसका लक्ष्य मशीनों को पाठ्य डेटा का विश्लेषण, समझना और उस पर प्रतिक्रिया देना सिखाना है। BERT जैसे मॉडल के आने से पहले, मशीन भाषा प्रसंस्करण में अक्सर कई महत्वपूर्ण चुनौतियाँ थीं, विशेष रूप से मानव भाषा की अस्पष्टता, संदर्भ-निर्भरता और जटिल संरचना के कारण।.
📈 2. एनएलपी मॉडल का विकास
BERT के आने से पहले, अधिकांश NLP मॉडल तथाकथित एकदिशीय संरचना पर आधारित थे। इसका अर्थ यह था कि ये मॉडल पाठ को या तो बाएँ से दाएँ या दाएँ से बाएँ पढ़ते थे, जिसका मतलब था कि वाक्य में किसी शब्द को संसाधित करते समय वे केवल सीमित मात्रा में संदर्भ पर ही विचार कर सकते थे। इस सीमा के कारण अक्सर मॉडल वाक्य के अर्थपूर्ण संदर्भ को पूरी तरह से समझने में विफल रहते थे। इससे अस्पष्ट या संदर्भ-संवेदनशील शब्दों की सटीक व्याख्या करना कठिन हो जाता था।.
BERT से पहले NLP अनुसंधान में एक और महत्वपूर्ण विकास वर्ड2वेक मॉडल था, जिसने कंप्यूटरों को शब्दों को अर्थ संबंधी समानताओं को दर्शाने वाले वैक्टर में अनुवादित करने की अनुमति दी। हालांकि, यहां भी संदर्भ शब्द के तत्काल परिवेश तक ही सीमित था। बाद में, रिकरेंट न्यूरल नेटवर्क (RNN) और विशेष रूप से लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) मॉडल विकसित किए गए, जिससे कई शब्दों में जानकारी संग्रहीत करके पाठ अनुक्रमों को बेहतर ढंग से समझना संभव हो गया। हालांकि, इन मॉडलों की भी अपनी सीमाएं थीं, विशेष रूप से लंबे पाठों से निपटने और साथ ही दोनों दिशाओं में संदर्भ को समझने में।.
🔄 3. ट्रांसफॉर्मर आर्किटेक्चर के माध्यम से क्रांति
2017 में ट्रांसफ़ॉर्मर आर्किटेक्चर की शुरुआत के साथ एक महत्वपूर्ण उपलब्धि हासिल हुई, जो BERT का आधार है। ट्रांसफ़ॉर्मर मॉडल समानांतर पाठ प्रसंस्करण को सक्षम बनाने के लिए डिज़ाइन किए गए हैं, जो किसी शब्द के संदर्भ को उसके पहले और बाद के पाठ दोनों से ध्यान में रखते हैं। यह तथाकथित स्व-ध्यान तंत्र के माध्यम से प्राप्त किया जाता है, जो वाक्य में प्रत्येक शब्द को वाक्य के अन्य शब्दों के सापेक्ष उसके महत्व के आधार पर एक भार मान प्रदान करता है।.
पूर्व के दृष्टिकोणों के विपरीत, ट्रांसफ़ॉर्मर मॉडल एकदिशीय नहीं बल्कि द्विदिशीय होते हैं। इसका अर्थ है कि वे किसी शब्द के बाएँ और दाएँ दोनों संदर्भों से जानकारी प्राप्त कर सकते हैं ताकि शब्द और उसके अर्थ का अधिक पूर्ण और सटीक निरूपण तैयार किया जा सके।.
🧠 4. BERT: एक द्विदिशात्मक मॉडल
BERT, ट्रांसफ़ॉर्मर आर्किटेक्चर के प्रदर्शन को एक नए स्तर पर ले जाता है। यह मॉडल किसी शब्द के संदर्भ को न केवल बाएँ से दाएँ या दाएँ से बाएँ, बल्कि दोनों दिशाओं में एक साथ समझने के लिए डिज़ाइन किया गया है। इससे BERT वाक्य में किसी शब्द के संपूर्ण संदर्भ पर विचार कर पाता है, जिसके परिणामस्वरूप प्राकृतिक भाषा प्रसंस्करण कार्यों में सटीकता में उल्लेखनीय सुधार होता है।.
BERT की एक प्रमुख विशेषता इसका मास्क्ड लैंग्वेज मॉडल (MLM) का उपयोग है। BERT प्रशिक्षण के दौरान, वाक्य में यादृच्छिक रूप से चयनित शब्दों को एक मास्क से बदल दिया जाता है, और मॉडल को संदर्भ के आधार पर इन मास्क्ड शब्दों का अनुमान लगाने के लिए प्रशिक्षित किया जाता है। यह तकनीक BERT को वाक्य में शब्दों के बीच गहरे और अधिक सटीक संबंध सीखने में सक्षम बनाती है।.
इसके अतिरिक्त, BERT नेक्स्ट सेंटेंस प्रेडिक्शन (NSP) नामक एक विधि का उपयोग करता है, जिसमें मॉडल यह अनुमान लगाना सीखता है कि एक वाक्य दूसरे वाक्य के बाद आता है या नहीं। इससे BERT की लंबी टेक्स्ट को समझने और वाक्यों के बीच अधिक जटिल संबंधों को पहचानने की क्षमता में सुधार होता है।.
🌐 5. BERT का व्यावहारिक अनुप्रयोग
BERT विभिन्न प्रकार के NLP कार्यों के लिए अत्यंत उपयोगी साबित हुआ है। यहाँ इसके कुछ सबसे महत्वपूर्ण अनुप्रयोग क्षेत्र दिए गए हैं:
📊 क) पाठ वर्गीकरण
BERT के सबसे आम अनुप्रयोगों में से एक टेक्स्ट वर्गीकरण है, जहाँ टेक्स्ट को पूर्वनिर्धारित श्रेणियों में विभाजित किया जाता है। उदाहरणों में भावना विश्लेषण (जैसे, यह पहचानना कि कोई टेक्स्ट सकारात्मक है या नकारात्मक) या ग्राहक प्रतिक्रिया का वर्गीकरण शामिल है। शब्दों के संदर्भ की गहरी समझ के कारण, BERT पिछले मॉडलों की तुलना में अधिक सटीक परिणाम दे सकता है।.
❓ b) प्रश्न-उत्तर प्रणाली
BERT का उपयोग प्रश्न-उत्तर प्रणालियों में भी किया जाता है, जहाँ मॉडल पाठ से पूछे गए प्रश्नों के उत्तर निकालता है। यह क्षमता विशेष रूप से खोज इंजन, चैटबॉट और वर्चुअल असिस्टेंट जैसे अनुप्रयोगों में महत्वपूर्ण है। अपनी द्विदिशात्मक संरचना के कारण, BERT पाठ से प्रासंगिक जानकारी निकाल सकता है, भले ही प्रश्न अप्रत्यक्ष रूप से पूछा गया हो।.
🌍 ग) पाठ अनुवाद
हालांकि BERT को सीधे तौर पर अनुवाद मॉडल के रूप में डिज़ाइन नहीं किया गया है, फिर भी मशीन अनुवाद को बेहतर बनाने के लिए इसे अन्य तकनीकों के साथ मिलाकर उपयोग किया जा सकता है। वाक्य के भीतर अर्थ संबंधी संबंधों को बेहतर ढंग से समझकर, BERT अधिक सटीक अनुवाद उत्पन्न करने में मदद कर सकता है, विशेष रूप से अस्पष्ट या जटिल वाक्यांशों के मामले में।.
🏷️ d) नामित इकाई पहचान (एनईआर)
एक अन्य अनुप्रयोग क्षेत्र नेम्ड एंटिटी रिकॉग्निशन (एनईआर) है, जिसमें पाठ के भीतर नाम, स्थान या संगठन जैसी विशिष्ट संस्थाओं की पहचान करना शामिल है। बीआरईटी इस कार्य में विशेष रूप से प्रभावी साबित हुआ है क्योंकि यह वाक्य के संदर्भ को पूरी तरह से ध्यान में रखता है और इस प्रकार संस्थाओं को बेहतर ढंग से पहचान सकता है, भले ही विभिन्न संदर्भों में उनके अलग-अलग अर्थ हों।.
✂️ ई) पाठ सारांश
BERT की पाठ के संपूर्ण संदर्भ को समझने की क्षमता इसे स्वचालित पाठ सारांशीकरण के लिए एक शक्तिशाली उपकरण बनाती है। इसका उपयोग लंबे पाठ से सबसे महत्वपूर्ण जानकारी निकालने और एक संक्षिप्त सारांश बनाने के लिए किया जा सकता है।.
🌟 6. अनुसंधान और उद्योग के लिए BERT का महत्व
BERT के आगमन ने NLP अनुसंधान में एक नए युग की शुरुआत की। यह द्विदिशात्मक ट्रांसफार्मर आर्किटेक्चर की पूरी क्षमता का लाभ उठाने वाले पहले मॉडलों में से एक था, जिसने बाद के कई मॉडलों के लिए मानक स्थापित किया। अनेक कंपनियों और अनुसंधान संस्थानों ने अपने अनुप्रयोगों के प्रदर्शन को बेहतर बनाने के लिए BERT को अपने NLP पाइपलाइनों में एकीकृत किया है।.
इसके अलावा, BERT ने भाषा मॉडल के क्षेत्र में और अधिक नवाचारों का मार्ग प्रशस्त किया। उदाहरण के लिए, GPT (जेनरेटिव प्रीट्रेन्ड ट्रांसफॉर्मर) और T5 (टेक्स्ट-टू-टेक्स्ट ट्रांसफर ट्रांसफॉर्मर) जैसे मॉडल बाद में विकसित किए गए, जो समान सिद्धांतों पर आधारित हैं लेकिन विभिन्न उपयोग मामलों के लिए विशिष्ट सुधार प्रदान करते हैं।.
🚧 7. BERT की चुनौतियाँ और सीमाएँ
कई फायदों के बावजूद, BERT की कुछ चुनौतियाँ और सीमाएँ भी हैं। सबसे बड़ी बाधाओं में से एक मॉडल को प्रशिक्षित करने और लागू करने के लिए आवश्यक उच्च स्तर का कम्प्यूटेशनल प्रयास है। BERT लाखों मापदंडों वाला एक बहुत बड़ा मॉडल है, इसलिए इसे शक्तिशाली हार्डवेयर और पर्याप्त कंप्यूटिंग संसाधनों की आवश्यकता होती है, विशेष रूप से बड़े डेटासेट को संसाधित करते समय।.
एक अन्य समस्या प्रशिक्षण डेटा में मौजूद संभावित पूर्वाग्रह है। चूंकि BERT को बड़ी मात्रा में पाठ्य डेटा पर प्रशिक्षित किया जाता है, इसलिए यह कभी-कभी उस डेटा में मौजूद पूर्वाग्रहों और रूढ़ियों को प्रतिबिंबित करता है। हालांकि, शोधकर्ता इन मुद्दों की पहचान करने और उनका समाधान करने के लिए लगातार काम कर रहे हैं।.
🔍 आधुनिक वाक् प्रसंस्करण अनुप्रयोगों के लिए एक अनिवार्य उपकरण
BERT ने मशीनों द्वारा मानव भाषा को समझने के तरीके में उल्लेखनीय सुधार किया है। अपनी द्विदिशात्मक संरचना और नवीन प्रशिक्षण विधियों के साथ, यह वाक्य के भीतर शब्दों के संदर्भ को गहराई से और सटीक रूप से समझने में सक्षम है, जिससे कई NLP कार्यों में अधिक सटीकता प्राप्त होती है। चाहे पाठ वर्गीकरण हो, प्रश्न-उत्तर प्रणाली हो या इकाई पहचान, BERT ने आधुनिक प्राकृतिक भाषा प्रसंस्करण अनुप्रयोगों के लिए एक अनिवार्य उपकरण के रूप में अपनी पहचान स्थापित कर ली है।.
प्राकृतिक भाषा प्रसंस्करण के क्षेत्र में अनुसंधान निस्संदेह आगे बढ़ता रहेगा, और BERT ने कई भावी नवाचारों की नींव रखी है। मौजूदा चुनौतियों और सीमाओं के बावजूद, BERT प्रभावशाली ढंग से यह दर्शाता है कि प्रौद्योगिकी ने कम समय में कितनी प्रगति की है और भविष्य में कितने रोमांचक अवसर खुलेंगे।.
🌀 ट्रांसफ़ॉर्मर: प्राकृतिक भाषा प्रसंस्करण में एक क्रांति
हाल के वर्षों में, प्राकृतिक भाषा प्रसंस्करण (एनएलपी) में सबसे महत्वपूर्ण विकासों में से एक ट्रांसफ़ॉर्मर मॉडल का परिचय रहा है, जैसा कि 2017 के शोध पत्र "अटेंशन इज़ ऑल यू नीड" में वर्णित है। इस मॉडल ने मशीन अनुवाद जैसे अनुक्रम रूपांतरण कार्यों के लिए पहले से उपयोग की जाने वाली आवर्ती या कनवोल्यूशनल संरचनाओं को त्यागकर इस क्षेत्र में मौलिक परिवर्तन ला दिया। इसके बजाय, यह पूरी तरह से ध्यान तंत्र पर निर्भर करता है। ट्रांसफ़ॉर्मर डिज़ाइन तब से कई मॉडलों का आधार बन गया है जो वाक् निर्माण, अनुवाद और अन्य क्षेत्रों में अत्याधुनिक तकनीक का प्रतिनिधित्व करते हैं।.
🔄 ट्रांसफॉर्मर: एक प्रतिमान परिवर्तन
ट्रांसफ़ॉर्मर के आने से पहले, अनुक्रम कार्यों के लिए अधिकांश मॉडल रिकरेंट न्यूरल नेटवर्क (RNN) या लॉन्ग शॉर्ट-टर्म मेमोरी (LSTM) नेटवर्क पर आधारित थे, जो स्वाभाविक रूप से क्रमिक रूप से कार्य करते हैं। ये मॉडल इनपुट डेटा को चरण दर चरण संसाधित करते हैं, जिससे छिपी हुई अवस्थाएँ बनती हैं जो अनुक्रम के साथ आगे बढ़ती हैं। हालाँकि यह विधि प्रभावी है, लेकिन यह गणनात्मक रूप से महंगी है और इसे समानांतर करना कठिन है, विशेष रूप से लंबे अनुक्रमों के लिए। इसके अलावा, लुप्त होती ग्रेडिएंट समस्या के कारण RNN को दीर्घकालिक निर्भरताओं को सीखने में कठिनाई होती है।.
ट्रांसफॉर्मर की प्रमुख नवीनता इसके सेल्फ-अटेंशन तंत्र के उपयोग में निहित है, जो मॉडल को वाक्य में विभिन्न शब्दों के महत्व को उनकी स्थिति की परवाह किए बिना, एक दूसरे के सापेक्ष आंकने की अनुमति देता है। इससे मॉडल आरएनएन या एलएसटीएम की तुलना में अधिक प्रभावी ढंग से दूर-दूर स्थित शब्दों के बीच संबंधों को समझ पाता है, और यह कार्य क्रमिक रूप से करने के बजाय समानांतर रूप से करता है। इससे न केवल प्रशिक्षण दक्षता में सुधार होता है, बल्कि मशीन अनुवाद जैसे कार्यों में प्रदर्शन भी बेहतर होता है।.
🧩 मॉडल वास्तुकला
ट्रांसफॉर्मर में दो मुख्य घटक होते हैं: एक एनकोडर और एक डिकोडर, जिनमें से दोनों कई परतों से बने होते हैं और बहु-शीर्ष ध्यान तंत्र पर बहुत अधिक निर्भर करते हैं।.
⚙️ एनकोडर
एनकोडर में छह समान परतें होती हैं, जिनमें से प्रत्येक में दो उप-परतें होती हैं:
1. बहु-मस्तिष्क स्व-ध्यान
यह तंत्र मॉडल को प्रत्येक शब्द को संसाधित करते समय इनपुट वाक्य के विभिन्न भागों पर ध्यान केंद्रित करने की अनुमति देता है। एक ही स्थान पर ध्यान केंद्रित करने के बजाय, बहु-शीर्ष ध्यान इनपुट को कई अलग-अलग स्थानों में प्रोजेक्ट करता है, जिससे शब्दों के बीच विभिन्न प्रकार के संबंधों को समझा जा सकता है।.
2. स्थितिगत रूप से पूर्णतः जुड़े फीडफॉरवर्ड नेटवर्क
अटेंशन लेयर के बाद, प्रत्येक स्थान पर स्वतंत्र रूप से एक फुली कनेक्टेड फीडफॉरवर्ड नेटवर्क लागू किया जाता है। इससे मॉडल को प्रत्येक शब्द को संदर्भ में संसाधित करने और अटेंशन तंत्र से प्राप्त जानकारी का उपयोग करने में मदद मिलती है।.
इनपुट अनुक्रम की संरचना को संरक्षित करने के लिए, मॉडल में स्थितिगत एन्कोडिंग भी शामिल हैं। चूंकि ट्रांसफ़ॉर्मर शब्दों को क्रमिक रूप से संसाधित नहीं करता है, इसलिए ये एन्कोडिंग मॉडल को वाक्य में शब्दों के क्रम के बारे में जानकारी प्रदान करने के लिए महत्वपूर्ण हैं। स्थितिगत एन्कोडिंग को शब्द एम्बेडिंग में जोड़ा जाता है ताकि मॉडल अनुक्रम में विभिन्न स्थितियों के बीच अंतर कर सके।.
🔍 डिकोडर
एनकोडर की तरह, डिकोडर में भी छह परतें होती हैं, जिनमें से प्रत्येक में एक अतिरिक्त ध्यान तंत्र होता है जो मॉडल को आउटपुट उत्पन्न करते समय इनपुट अनुक्रम के प्रासंगिक भागों पर ध्यान केंद्रित करने की अनुमति देता है। डिकोडर भविष्य की स्थितियों पर विचार करने से रोकने के लिए मास्किंग तकनीक का भी उपयोग करता है, जिससे अनुक्रम निर्माण की स्व-प्रतिगामी प्रकृति संरक्षित रहती है।.
🧠 मल्टी-हेड अटेंशन और स्केलर प्रोडक्ट अटेंशन
ट्रांसफ़ॉर्मर का मूल तत्व मल्टी-हेड अटेंशन तंत्र है, जो सरल स्केलर प्रोडक्ट अटेंशन का ही एक विस्तार है। अटेंशन फ़ंक्शन को एक क्वेरी और कुंजी-मान युग्मों के समूह के बीच एक मैपिंग के रूप में देखा जा सकता है, जहाँ प्रत्येक कुंजी अनुक्रम में एक शब्द को दर्शाती है और मान संबंधित प्रासंगिक जानकारी को दर्शाता है।.
मल्टी-हेड अटेंशन तंत्र मॉडल को अनुक्रम के विभिन्न भागों पर एक साथ ध्यान केंद्रित करने की अनुमति देता है। इनपुट को कई उप-स्थानों में प्रोजेक्ट करके, मॉडल शब्दों के बीच संबंधों के एक समृद्ध सेट को कैप्चर कर सकता है। यह मशीन अनुवाद जैसे कार्यों के लिए विशेष रूप से उपयोगी है, जहां किसी शब्द के संदर्भ को समझने के लिए वाक्य संरचना और अर्थ संबंधी अर्थ जैसे कई अलग-अलग कारकों की आवश्यकता होती है।.
स्केलर प्रोडक्ट अटेंशन का सूत्र है:
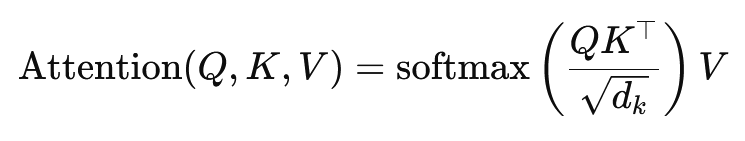
यहां, (Q) क्वेरी मैट्रिक्स है, (K) कुंजी मैट्रिक्स है, और (V) मान मैट्रिक्स है। (sqrt{d_k}) एक स्केलिंग कारक है जो स्केलर गुणनफलों को बहुत बड़ा होने से रोकता है, जिससे बहुत छोटे ग्रेडिएंट और धीमी लर्निंग हो सकती है। यह सुनिश्चित करने के लिए सॉफ्टमैक्स फ़ंक्शन का उपयोग किया जाता है कि अटेंशन वेट्स का योग एक हो।.
🚀 ट्रांसफार्मर के फायदे
ट्रांसफॉर्मर, आरएनएन और एलएसटीएम जैसे पारंपरिक मॉडलों की तुलना में कई महत्वपूर्ण लाभ प्रदान करता है:
1. समानांतरकरण
चूंकि ट्रांसफॉर्मर एक अनुक्रम के सभी टोकन को एक साथ संसाधित करता है, इसलिए इसे अत्यधिक समानांतर किया जा सकता है और इसलिए यह आरएनएन या एलएसटीएम की तुलना में प्रशिक्षण में बहुत तेज होता है, खासकर बड़े डेटासेट के साथ।.
2. दीर्घकालिक निर्भरताएँ
स्व-ध्यान तंत्र मॉडल को आरएनएन की तुलना में दूरस्थ शब्दों के बीच संबंधों को अधिक प्रभावी ढंग से समझने की अनुमति देता है, जो उनकी गणनाओं की अनुक्रमिक प्रकृति द्वारा सीमित होते हैं।.
3. स्केलेबिलिटी
यह ट्रांसफॉर्मर आरएनएन से जुड़ी प्रदर्शन संबंधी बाधाओं से प्रभावित हुए बिना बहुत बड़े डेटासेट और लंबी अनुक्रमों को आसानी से संभाल सकता है।.
🌍 अनुप्रयोग और प्रभाव
ट्रांसफ़ॉर्मर के परिचय के बाद से, यह कई तरह के एनएलपी मॉडलों का आधार बन गया है। इसका एक उल्लेखनीय उदाहरण बीआरईटी (बायडायरेक्शनल एनकोडर रिप्रेजेंटेशन्स फ्रॉम ट्रांसफ़ॉर्मर्स) है, जो प्रश्नोत्तर और टेक्स्ट वर्गीकरण सहित कई एनएलपी कार्यों में अत्याधुनिक प्रदर्शन प्राप्त करने के लिए संशोधित ट्रांसफ़ॉर्मर आर्किटेक्चर का उपयोग करता है।.
एक और महत्वपूर्ण विकास जीपीटी (जेनरेटिव प्रीट्रेन्ड ट्रांसफॉर्मर) है, जो टेक्स्ट जनरेशन के लिए ट्रांसफॉर्मर के डिकोडर-सीमित संस्करण का उपयोग करता है। जीपीटी मॉडल, जिनमें जीपीटी-3 भी शामिल है, अब कंटेंट क्रिएशन से लेकर कोड कम्प्लीशन तक कई अनुप्रयोगों में उपयोग किए जाते हैं।.
🔍 एक शक्तिशाली और लचीला मॉडल
ट्रांसफ़ॉर्मर ने एनएलपी कार्यों के प्रति हमारे दृष्टिकोण को मौलिक रूप से बदल दिया है। यह एक शक्तिशाली और लचीला मॉडल प्रदान करता है जिसे विभिन्न प्रकार की समस्याओं पर लागू किया जा सकता है। दीर्घकालिक निर्भरताओं को संभालने की इसकी क्षमता और प्रशिक्षण में इसकी दक्षता ने इसे कई आधुनिक मॉडलों के लिए पसंदीदा आर्किटेक्चरल दृष्टिकोण बना दिया है। जैसे-जैसे अनुसंधान आगे बढ़ेगा, हम ट्रांसफ़ॉर्मर में और अधिक सुधार और अनुकूलन देखेंगे, विशेष रूप से छवि और वाक् प्रसंस्करण जैसे क्षेत्रों में, जहाँ ध्यान तंत्र आशाजनक परिणाम दिखाते हैं।.
हम आपके लिए हैं - सलाह - योजना - कार्यान्वयन - परियोजना प्रबंधन
☑️ उद्योग विशेषज्ञ, 2,500 से अधिक विशेषज्ञ लेखों के साथ यहां अपने स्वयं के विशेषज्ञ.डिजिटल उद्योग केंद्र के साथ

Konrad Wolfenstein
मुझे आपके निजी सलाहकार के रूप में सेवा करने में खुशी होगी।
आप नीचे दिए गए संपर्क फ़ॉर्म को भरकर मुझसे संपर्क कर सकते हैं या बस मुझे +49 89 89 674 804 (म्यूनिख) ।
मैं हमारी संयुक्त परियोजना की प्रतीक्षा कर रहा हूं।
मुझे लिखें




एक्सपर्ट.डिजिटल - Konrad Wolfenstein
एक्सपर्ट.डिजिटल डिजिटलाइजेशन, मैकेनिकल इंजीनियरिंग, लॉजिस्टिक्स/इंट्रालॉजिस्टिक्स और फोटोवोल्टिक्स पर फोकस के साथ उद्योग का केंद्र है।
अपने 360° व्यवसाय विकास समाधान के साथ, हम नए व्यवसाय से लेकर बिक्री के बाद तक प्रसिद्ध कंपनियों का समर्थन करते हैं।
मार्केट इंटेलिजेंस, स्मार्केटिंग, मार्केटिंग ऑटोमेशन, कंटेंट डेवलपमेंट, पीआर, मेल अभियान, वैयक्तिकृत सोशल मीडिया और लीड पोषण हमारे डिजिटल टूल का हिस्सा हैं।
आप यहां अधिक जानकारी प्राप्त कर सकते हैं: www.xpert.digital - www.xpert.solar - www.xpert.plus
संपर्क में रहना











