
ניסיון להסביר את ה- AI: כיצד פועל בינה מלאכותית ועבודה - כיצד הוא מאומן?

בחירת קול 📢
פורסם בתאריך: 8 בספטמבר 2024 / עדכון מ: 9 בספטמבר 2024 - מחבר: קונרד וולפנשטיין

ניסיון להסביר את ה- AI: כיצד עובד בינה מלאכותית ואיך היא מאומנת? - תמונה: xpert.digital
📊 מקלט נתונים לתחזית המודל: תהליך ה- AI
כיצד עובד בינה מלאכותית (AI)? 🤖
ניתן לחלק את הפונקציונליות של הבינה המלאכותית (AI) למספר צעדים מוגדרים בבירור. כל אחד מהצעדים הללו הוא קריטי לתוצאה הסופית ש- AI מספק. התהליך מתחיל בעת כניסה לנתונים ומסתיים בתחזית המודל ובכל משוב או סבבי אימונים אחרים. שלבים אלה מתארים את התהליך שעובר כמעט על כל דגמי ה- AI, ללא קשר אם מדובר בתקנות פשוטות או רשתות עצביות מורכבות ביותר.
1. קלט הנתונים 📊
הבסיס של כל בינה מלאכותית הוא הנתונים איתם הם עובדים. נתונים אלה יכולים להיות זמינים בצורות שונות, למשל כתמונות, טקסטים, קבצי שמע או קטעי וידאו. ה- AI משתמש בנתונים גולמיים אלה כדי לזהות דפוסים ולקבל החלטות. האיכות והכמות של הנתונים ממלאים כאן תפקיד מרכזי, מכיוון שהם משפיעים באופן משמעותי עד כמה המודל עובד טוב או רע אחר כך.
ככל שהנתונים נרחבים יותר ויותר מדויקים, כך ה- AI יכול ללמוד טוב יותר. לדוגמה, אם AI מאומן לעיבוד תמונות, הוא זקוק לכמות גדולה של נתוני תמונה כדי לזהות נכון אובייקטים שונים. עם דגמים קוליים, נתוני טקסטים הם שעוזרים ל- AI להבין ולייצר שפה אנושית. קלט הנתונים הוא הראשון ואחד הצעדים החשובים ביותר, מכיוון שאיכות התחזיות יכולה להיות טובה רק כמו הנתונים הבסיסיים. עיקרון מפורסם במדעי המחשב מתאר זאת באמירה "זבל פנימה, זבל החוצה" - נתונים ירודים מובילים לתוצאות רעות.
2. הנתונים העיבוד המקדים 🧹
ברגע שהנתונים הוזנו, עליהם להיות מוכנים לפני שניתן יהיה להאכיל אותם למודל בפועל. תהליך זה מכונה עיבוד מקדים לנתונים. מדובר על הכנסת הנתונים לצורה שניתן לעבד בצורה אופטימלית על ידי המודל.
צעד נפוץ בעיבוד המקדים הוא נורמליזציה של הנתונים. המשמעות היא שהנתונים מובאים לאזור ערך אחיד כך שמתייחסים אליהם באופן שווה על ידי המודל. דוגמא אחת היא לגדול את כל ערכי הפיקסלים של תמונה לאזור בין 0 ל -1 במקום 0 עד 255.
חלק חשוב נוסף בעיבוד המקדים הוא מיצוי התכונות שנקרא. תכונות מסוימות (תכונות) נבדקות מהנתונים הגולמיים הרלוונטיים במיוחד עבור הדגם. במקרה של עיבוד תמונה, זה יכול להיות, למשל, קצוות או דפוסי צבע מסוימים, ואילו עם טקסטים מילות מפתח רלוונטיות או מבני משפט. עיבוד ראשוני הוא חיוני בכדי להפוך את תהליך הלמידה של ה- AI ליעיל ומדויק יותר.
3. הדגם 🧩
המודל הוא ליבו של כל בינה מלאכותית. כאן הנתונים מנותחים ומעובדים על בסיס אלגוריתמים וחישובים מתמטיים. מודל יכול להתקיים בצורות שונות. אחד הדגמים הידועים ביותר הוא הרשת העצבית המבוססת על תפקוד המוח האנושי.
רשתות עצביות מורכבות מכמה שכבות של נוירונים מלאכותיים המעבדים מידע. כל שכבה לוקחת את הוצאות השכבה הקודמת ומעבדת אותה עוד יותר. תהליך הלמידה של רשת עצבית הוא להתאים את משקולות החיבורים בין נוירונים אלה באופן שהרשת יכולה לערוך תחזיות מדויקות יותר ויותר או לבצע סיווגים. הסתגלות זו נעשית על ידי אימונים, בה הרשת ניגשת לכמויות גדולות של נתוני מדגם והפרמטרים הפנימיים שלה (משקולות) משתפרת באופן איטרטיבי.
בנוסף לרשתות עצביות, ישנם גם אלגוריתמים רבים אחרים המשמשים במודלים של AI. זה כולל עצי החלטה, יערות אקראיים, מכונות וקטוריות תומכות ורבות נוספות. באיזה אלגוריתם משתמשים תלוי במשימה הספציפית ובנתונים הזמינים.
4. תחזית המודל 🔍
לאחר שהמודל הוכשר עם נתונים, הוא מסוגל לחזות. שלב זה מכונה תחזית מודל. ה- AI מקבל קלט ומחזיר בעיה על סמך הדפוסים שלמדת עד כה, כלומר חיזוי או החלטה.
חיזוי זה יכול ללבוש צורות שונות. במודל סיווג תמונה, למשל, ה- AI יכול לחזות איזה אובייקט ניתן לראות בתמונה. במודל שפה היא יכולה לחזות איזו מילה באה לאחר מכן במשפט אחד. במקרה של תחזיות פיננסיות, ה- AI יכול לחזות כיצד יתפתח שוק המניות.
חשוב להדגיש כי דיוק התחזיות תלוי מאוד באיכות נתוני ההדרכה ובארכיטקטורת המודל. מודל שהוכשר על נתונים לא מספקים או מעוותים, ככל הנראה, יעשה תחזיות שגויות.
5. פרישה והדרכה (אופציונלי) ♻️
חלק חשוב נוסף בעבודה של AI הוא מנגנון המשוב. הדגם נבדק באופן קבוע ומותאם עוד יותר. תהליך זה מתרחש במהלך האימונים או על פי תחזית המודל.
אם המודל מביא תחזיות שגויות, הוא יכול ללמוד לזהות שגיאות אלה על ידי משוב ולהתאים את הפרמטרים הפנימיים שלו בהתאם. זה נעשה על ידי השוואה בין תחזיות המודל לתוצאות בפועל (למשל עבור נתונים ידועים שעבורם התשובות הנכונות כבר זמינות). תהליך אופייני בהקשר זה הוא הלמידה המונחת כל כך, בה ה- AI לומד מנתוני מדגם שכבר מסופקים עם התשובות הנכונות.
שיטת משוב נפוצה היא אלגוריתם ההתפשטות האחורי, המשמש ברשתות עצביות. השגיאות שהמודל עושה מופצות לאחור דרך הרשת על מנת להתאים את משקולות תרכובות העצב. באופן זה, המודל לומד מהטעויות שלו והופך לדייק יותר ויותר בתחזיותיו.
תפקיד האימונים
הכשרה של AI היא תהליך איטרטיבי. ככל שהמודל רואה יותר נתונים ולעיתים קרובות הוא מאומן על בסיס נתונים אלה, כך תחזיותיו מדויקות יותר. עם זאת, ישנם גם גבולות: מודל מיומן מדי יכול לקבל בעיות "התאמת יתר" כביכול. המשמעות היא שהיא לומדת את נתוני ההדרכה כל כך טוב שהיא מספקת תוצאות גרועות יותר על נתונים חדשים ולא ידועים. לכן חשוב לאמן את המודל בצורה כזו שהוא יכלל, כלומר גם מביא תחזיות טובות לגבי נתונים חדשים.
בנוסף לאימונים רגילים, ישנם גם נהלים כמו למידת העברה. כאן משמש מודל שכבר הוכשר על כמות גדולה של נתונים למשימה חדשה ודומה. זה חוסך כוח ומחשוב זמן, מכיוון שהמודל אינו צריך להיות מאומן לחלוטין מאפס.
השתמש בחוזקות בצורה אופטימלית 🚀
עבודת הבינה המלאכותית מבוססת על אינטראקציה מורכבת של צעדים שונים. החל מהזנת נתונים לעיבוד ראשוני ואימוני מודל לחיזוי ומשוב, ישנם גורמים רבים המשפיעים על הדיוק והיעילות של AI. AI מיומן היטב יכול להציע יתרונות אדירים בתחומי חיים רבים - מאוטומציה של משימות פשוטות ועד פתרון בעיות מורכבות. אך חשוב לא פחות להבין את הגבולות והמלכודות הפוטנציאליות של AI על מנת שיוכלו להשתמש בצורה אופטימלית את חוזקותיהם.
🤖📚 פשוט הסביר: איך AI מאומן?
🤖📊 תהליך למידה AI: לכידה, קישור ושמור
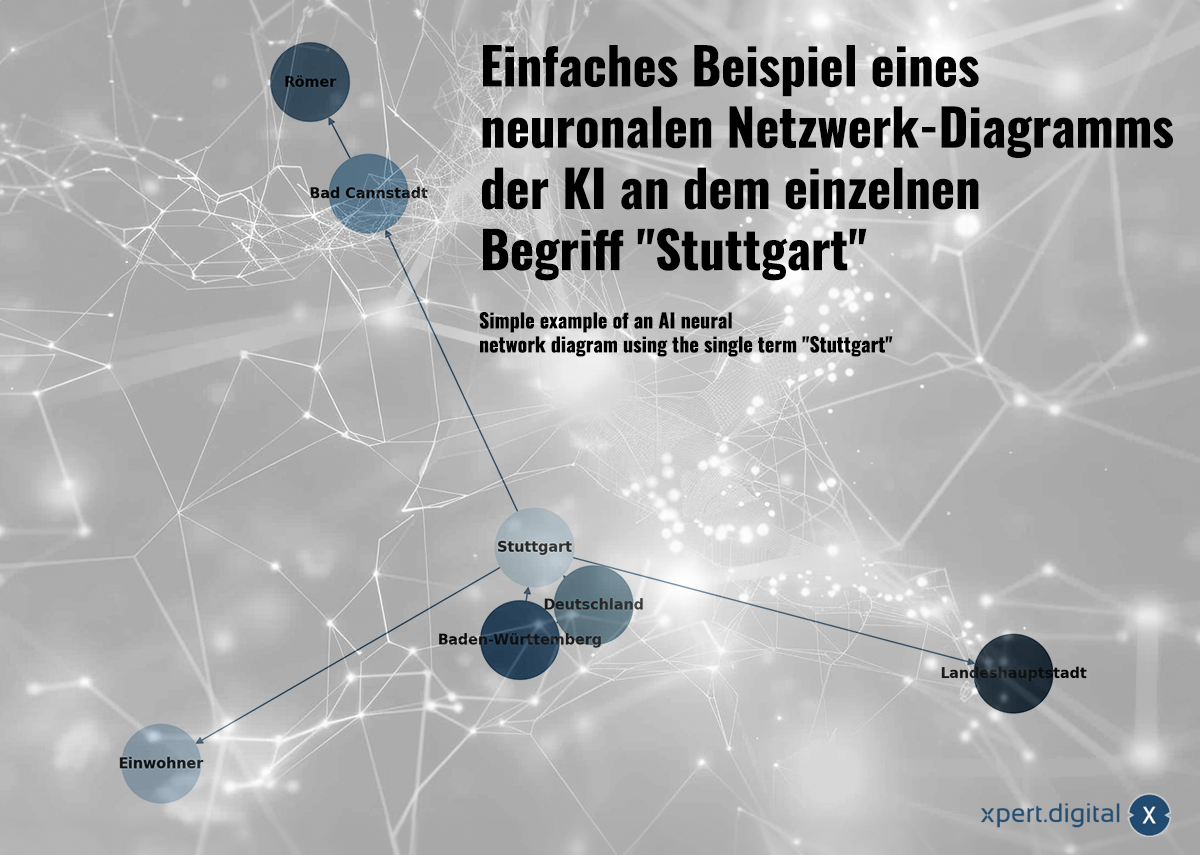
דוגמה פשוטה לתרשים רשת עצבי של ה- AI במונח האינדיבידואלי "Stuttgart" -Image: xpert.digital
🌟 אסוף והכין נתונים
השלב הראשון בתהליך הלמידה של AI הוא לאסוף ולהכין את הנתונים. נתונים אלה יכולים להגיע ממקורות שונים, למשל. ממאגרי מידע, חיישנים, טקסטים או תמונות.
🌟 קשר נתונים (רשת עצבית)
הנתונים שנאספו קשורים זה לזה ברשת עצבית. כל חבילת נתונים מוצגת על ידי חיבורים ברשת של "נוירונים" (צומת). דוגמה פשוטה לעיר שטוטגרט יכולה להיראות כך:
א) שטוטגרט היא עיר בבאדן-וורטברג
ב) באדן-וירטמברג היא מדינה פדרלית בגרמניה
ג) שטוטגרט היא עיר בגרמניה
ד) לשטוטגרט אוכלוסייה של 633,484
ה)
רע קאן
הוא מחוז של שטוטגרט באדן-וורטברג
תלוי בגודל נפח הנתונים, הפרמטרים למהדורות פוטנציאליות נוצרים מכך באמצעות מודל ה- AI המשמש. כדוגמה: ל- GPT-3 יש כ- 175 מיליארד פרמטרים!
🌟 אחסון והתאמה (למידה)
הנתונים מסופקים לרשת העצבית. הם עוברים את מודל ה- AI ומעובדים באמצעות חיבורים (בדומה לסינפסות). המשקלים (הפרמטרים) מותאמים בין הנוירונים כדי לאמן את המודל או לבצע משימה.
בניגוד לצורות זיכרון קונבנציונאליות כגון גישה ישירה, ציון גישה, אחסון רצף או ערימה, רשתות עצביות מאחסנות את הנתונים בצורה לא שגרתית. "הנתונים" מאוחסנים במשקולות ובהטיות של החיבורים בין הנוירונים.
"האחסון" של המידע ברשת עצבית מתרחש על ידי התאמת משקולות החיבור בין הנוירונים. מודל ה- AI "לומד" על ידי התאמה מתמדת משקולות והטיות אלה על סמך נתוני הקלט ואלגוריתם למידה מוגדר. זהו תהליך רציף בו המודל יכול לבצע תחזיות מדויקות בגלל התאמות חוזרות ונשנות.
ניתן לראות במודל AI כסוג של תכנות, מכיוון שהוא נובע מאלגוריתמים מוגדרים וחישובים מתמטיים והתאמת הפרמטרים שלו (משקולות) משופרת ברציפות על מנת לבצע תחזיות מדויקות. זהו תהליך מתמשך.
הטיות הן פרמטרים נוספים ברשתות עצביות המתווספות לערכי הקלט המשוקללים של נוירון. הם מאפשרים את הפרמטרים למשקל (חשוב, פחות, חשוב, בין היתר), מה שהופך את ה- AI לגמיש ומדויק יותר.
רשתות עצביות יכולות לא רק לחסוך עובדות בודדות, אלא גם לזהות קשרים בין הנתונים על ידי זיהוי תבניות. הדוגמה עם שטוטגרט ממחישה כיצד ניתן להכניס ידע לרשת עצבית, אך רשתות עצביות אינן לומדות באמצעות ידע מפורש (כמו בדוגמה פשוטה זו), אלא על ידי ניתוח דפוסי נתונים. רשתות עצביות יכולות אפוא לא רק לאחסן עובדות בודדות, אלא גם ללמוד משקולות ויחסים בין נתוני הקלט.
תהליך זה מספק מבוא מובן כיצד רשתות AI ובמיוחד רשתות עצביות פועלות מבלי לטבול אותם יותר מדי בפרטים טכניים. זה מראה כי אחסון מידע ברשתות עצביות אינו מתרחש כמו במאגרי מידע קונבנציונליים, אלא על ידי התאמת התרכובות (המשקולות) ברשת.
🤖📚 מפורט יותר: כיצד מאמן AI?
🏋️alובת האימונים של AI, במיוחד מודל למידה מכני, מתרחש בכמה שלבים. אימון AI מבוסס על אופטימיזציה רציפה של פרמטרי המודל באמצעות משוב והתאמה עד שהמודל מציג את הביצועים הטובים ביותר בנתונים המסופקים. להלן הסבר מפורט כיצד עובד תהליך זה:
1. 📊 אסוף והכין נתונים
נתונים הם הבסיס לאימוני AI. הם בדרך כלל מורכבים מאלפי או מיליוני דוגמאות לניתוח המערכת. דוגמאות לכך הן תמונות, טקסטים או נתוני סדרות זמן.
יש להתאים ולנרמל את הנתונים על מנת להימנע ממקורות שגיאה מיותרים. הנתונים מומרים לרוב לתכונות (תכונות) המכילות את המידע הרלוונטי.
2. 🔍 הגדר מודל
מודל הוא פונקציה מתמטית המתארת מערכות יחסים בנתונים. ברשתות עצביות המשמשות לרוב ל- AI, המודל מורכב מכמה שכבות של נוירונים המחוברים זה לזה.
כל נוירון מבצע פעולה מתמטית לעיבוד נתוני הקלט ואז להעביר אות לנוירון הבא.
3. 🔄 אתחול משקולות
לחיבורים בין הנוירונים יש משקולות המוגדרות בתחילה באופן אקראי. משקולות אלה קובעות עד כמה נוירון מגיב לאות.
מטרת האימונים היא להתאים את המשקולות הללו בצורה כזו שהמודל מביא תחזיות טובות יותר.
4. ➡️ ריצה קדימה (התפשטות קדימה)
במקרה של הפעלת קדימה, נתוני הקלט מונחים על ידי המודל לקבלת חיזוי.
כל שכבה מעבדת את הנתונים ומעבירה אותם לשכבה הבאה עד שהשכבה האחרונה מספקת את התוצאה.
5. ⚖️ חישוב פונקציית אובדן
פונקציית האובדן מודדת עד כמה טוב התחזיות של המודל מושוות לערכים בפועל (התוויות). מדד נפוץ הוא הטעות בין התשובה החזויה לתשובה בפועל.
ככל שההפסד גבוה יותר, כך התחזית של המודל גרוע יותר.
6. 🔙 ריצה לאחור (התפשטות אחורה)
בריצה לאחור, השגיאה מיוחסת מפלט הדגם לשכבות הקודמות.
השגיאה מופצת למשקולות החיבורים, והמודל מתאים את המשקולות כך שהשגיאות יהיו קטנות יותר.
זה קורה בעזרת ירידת השיפוע: וקטור השיפוע מחושב, מה שמציין כיצד יש לשנות את המשקולות כדי למזער את השגיאה.
7. 🔧 עדכן משקולות
לאחר חישוב השגיאה, משקולות החיבורים מתעדכנות בהתאמה קטנה על בסיס קצב הלמידה.
קצב הלמידה קובע כמה המשקולות משתנות בכל שלב. שינויים גדולים מדי יכולים להפוך את המודל לא יציב ושינויים קטנים מדי מובילים לתהליך למידה איטי.
8. 🔁 חזור (תקופות)
תהליך זה של ריצת קדימה, חישוב השגיאות ועדכון המשקל חוזר על עצמו, לעיתים קרובות על פני מספר תקופות (הפעל את כל מערך הנתונים) עד שהמודל ישיג דיוק מקובל.
עם כל תקופה, המודל לומד קצת יותר ומתאים את משקולותיו עוד יותר.
9. 📉 אימות ובדיקה
לאחר הכשרת המודל הוא נבדק ברשומת נתונים מאומתת כדי לבדוק עד כמה הוא הכלל. זה מבטיח שזה לא רק "שינן" את נתוני ההדרכה, אלא גם מביא תחזיות טובות לגבי נתונים לא ידועים.
נתוני הבדיקה עוזרים למדידת הביצועים הסופיים של המודל לפני שהוא משמש בפועל.
10. 🚀 אופטימיזציה
שלבים נוספים לשיפור המודל כוללים כוונון היפר -פרמטר (למשל התאמת קצב הלמידה או מבנה הרשת), סדירות (כדי להימנע מהתאמת יתר), או ** הגדלת כמות הנתונים.
📊🔙 בינה מלאכותית: הקופסה השחורה של ה- AI עם AI (XAI) הניתן להסבר, מפות חום, מודלים של פונדקאט או פתרונות אחרים הופכים אותו למובן, מובן ומיוחד

בינה מלאכותית: הקופסה השחורה של ה- AI עם AI (XAI) הניתן להסבר, מפות חום, מודלים של פונדקאט או פתרונות אחרים מובנים, מובנים וניתנים להסבר: xpert.digital
מה שמכונה "הקופסה השחורה" של בינה מלאכותית (AI) היא בעיה חשובה ומעודכנת. אפילו מומחים לעיתים קרובות מתמודדים עם האתגר של אי יכולת להבין היטב כיצד מערכות AI יכולות לקבל את החלטותיהם. אי -טרנספורמציה זו עלולה לגרום לבעיות משמעותיות, במיוחד בתחומים קריטיים כמו עסקים, פוליטיקה או רפואה. רופא או רופא הנשען על מערכת AI במהלך האבחנה והמלצת הטיפול חייבים להיות אמון בהחלטות שהתקבלו. עם זאת, אם ההחלטה - קבלת AI אינה שקופה מספיק, אי וודאות ואולי חוסר אמון מתעורר - וכי במצבים בהם חיי אדם יכולים להיות על כף המאזניים.
עוד על זה כאן:
אנחנו שם בשבילך - ייעוץ - תכנון - יישום - ניהול פרויקטים
☑️ תמיכה ב- SME באסטרטגיה, ייעוץ, תכנון ויישום
☑️ יצירה או התאמה מחדש של האסטרטגיה הדיגיטלית והדיגיטציה
☑️ הרחבה ואופטימיזציה של תהליכי המכירה הבינלאומיים
Platforms פלטפורמות מסחר B2B גלובליות ודיגיטליות
פיתוח עסקי חלוץ

קונרד וולפנשטיין
אני שמח לעזור לך כיועץ אישי.
אתה יכול ליצור איתי קשר על ידי מילוי טופס יצירת הקשר למטה או פשוט להתקשר אליי בטלפון +49 89 674 804 (מינכן) .
אני מצפה לפרויקט המשותף שלנו.
כתוב לי

Xpert.digital - קונראד וולפנשטיין
Xpert.Digital הוא מוקד לתעשייה עם מיקוד, דיגיטציה, הנדסת מכונות, לוגיסטיקה/אינטרלוגיסטיקה ופוטו -וולטאים.
עם פיתרון הפיתוח העסקי של 360 ° שלנו, אנו תומכים בחברות ידועות מעסקים חדשים למכירות.
מודיעין שוק, סמוקינג, אוטומציה שיווקית, פיתוח תוכן, יחסי ציבור, קמפיינים בדואר, מדיה חברתית בהתאמה אישית וטיפוח עופרת הם חלק מהכלים הדיגיטליים שלנו.
אתה יכול למצוא עוד בכתובת: www.xpert.digital - www.xpert.solar - www.xpert.plus
שמור על קשר

















