
KI ו- SEO עם ייצוגים מקודדים דו כיווניים משנאים - מודל בתחום עיבוד השפה הטבעית (NLP)

בחירת קול 📢
פורסם ב: 4 באוקטובר 2024 / עדכון מ: 4 באוקטובר 2024 - מחבר: קונרד וולפנשטיין

KI ו- SEO עם ייצוגים מקודדים דו כיווניים משנאים - מודל בתחום עיבוד השפה הטבעית (NLP) - תמונה: xpert.digital
🚀💬 שפותח על ידי גוגל: ברט וחשיבותו ל- NLP - מדוע ההבנה הדו -כיוונית של הטקסט היא מכריעה
Bert, קיצור של ייצוגים מקודדים דו כיווניים משנאים, הוא מודל חשוב בתחום עיבוד השפה הטבעית (NLP), שפותח על ידי גוגל. זה חולל מהפכה בדרך כיצד מכונות מבינות שפה. בניגוד למודלים קודמים שניתחו טקסטים ברצף משמאל לימין או להפך, BERT מאפשר עיבוד דו כיווני. המשמעות היא שהיא לוכדת את ההקשר של מילה מרצף הטקסט הקודם והן מרצף הטקסטים הבא. יכולת זו משפרת משמעותית את ההבנה של מערכות יחסים לשוניות מורכבות.
🔍 הארכיטקטורה של ברט
בשנים הקודמות היה אחד ההתפתחויות החשובות ביותר בתחום עיבוד השפה הטבעית (עיבוד שפה טבעית, NLP) על ידי הצגת מודל השנאי, כפי שהיה ב- PDF 2017-תשומת לב הוא כל מה שאתה צריך נייר ( Wikipedia ). מודל זה שינה את התחום באופן בסיסי על ידי דחיית המבנים ששימשו בעבר, כמו תרגום המכונה. במקום זאת, זה מסתמך רק על מנגנוני קשב. מאז, עיצוב השנאי היה הבסיס למודלים רבים המייצגים את מצב האמנות בתחומים שונים כמו ייצור שפות, תרגום ומעבר לה.
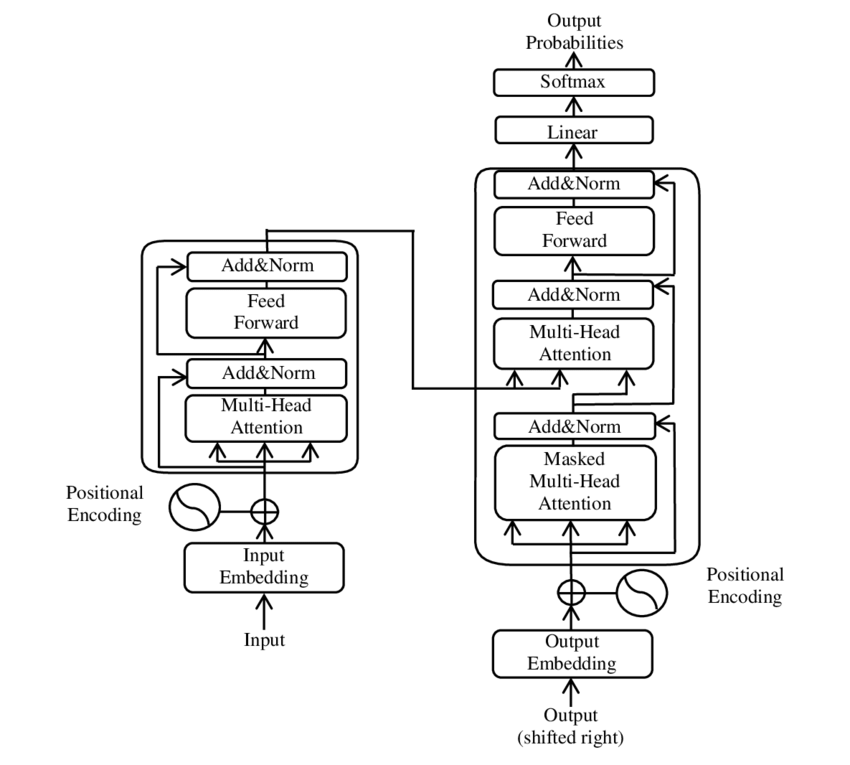
מיפוי של הרכיבים העיקריים של דימוי מודל השנאי: גוגל
ברט מבוסס על ארכיטקטורת שנאי זה. ארכיטקטורה זו משתמשת במנגנוני ציות עצמי כביכול (תחומים עצמיים) כדי לנתח קשרים בין המילים במשפט אחד. כל מילה בהקשר של המשפט כולו מוקדשת לתשומת לב, מה שמוביל להבנה מדויקת יותר של מערכות יחסים תחביריות וסמנטיות.
מחברי העיתון "תשומת הלב היא כל מה שאתה צריך" הם:
- אשיש וסוואני (גוגל מוח)
- Noam Shazeer (Google Brain)
- ניקי פרמר (מחקר גוגל)
- JAKOB USZKOREIT (Google Research)
- Llion Jones (Google Research)
- איידן נ 'גומז (אוניברסיטת טורונטו, שבוצעה בחלקם ב- Google Brain)
- Łukasz kaiser (גוגל מוח)
- Illia Polosukhin (עבודה עצמאית, קודמת על מחקר Google)
מחברים אלה תרמו משמעותית להתפתחות מודל השנאי, שהוצג במאמר זה.
🔄 עיבוד דו כיווני
מאפיין יוצא מן הכלל של ברט הוא יכולתו לעבוד עם דו כיווני. בעוד שמודלים מסורתיים כמו רשתות עצביות חוזרות ונשנות (RNNs) או רשתות זיכרון ארוכות לטווח קצר (LSTM) של רשתות של רשתות רק מעבדות טקסטים בכיוון אחד, BERT מנתח את ההקשר של מילה לשני הכיוונים. זה מאפשר למודל לתפוס טוב יותר ניואנסים עדינים ובכך לעשות תחזיות מדויקות יותר.
Modell
היבט חדשני נוסף של BERT הוא הטכנולוגיה של מודל השפה הרעילה (MLM). מילים שנבחרו באופן אקראי מוסוות במשפט אחד והמודל מאומן לחזות מילים אלה על בסיס ההקשר שמסביב. שיטה זו מאלצת את ברט לפתח הבנה עמוקה של ההקשר ואת המשמעות של כל מילה במשפט.
🚀 אימונים והתאמה של ברט
BERT עובר תהליך אימונים דו-שלבי: אימונים מקדימים וכוונון עדין.
📚 הכשרה מקדימה
בהכשרה מוקדמת, BERT מאומנת עם כמויות גדולות של טקסט כדי ללמוד דפוסי שפה כלליים. זה כולל טקסטים בוויקיפדיה וחלקים טקסטים נרחבים אחרים. בשלב זה המודל מכיר מבנים והקשרים לשוניים בסיסיים.
🔧 כוונון עדין
לאחר אימון מראש, BERT מותאם למשימות NLP ספציפיות, כגון סיווג טקסטים או ניתוח סנטימנט. המודל מאומן עם רשומות נתונים קטנות יותר הקשורות למשימות על מנת לייעל את הביצועים שלו ליישומים מסוימים.
🌍 אזורי יישום BERT
ברט הוכיח כמועיל ביותר בתחומים רבים של עיבוד שפה טבעית:
אופטימיזציה של מנועי חיפוש
גוגל משתמשת ב- BERT כדי להבין טוב יותר את שאילתות החיפוש ולהציג תוצאות רלוונטיות יותר. זה משפר משמעותית את חווית המשתמש.
סיווג טקסטים
BERT יכול לקטלג מסמכים לפי נושאים או לנתח את מצב הרוח בטקסטים.
נקרא הכרת ישויות (NER)
המודל מזהה ומסווג ישויות בשם בטקסטים כמו שמות אישיים, מקום או ארגוני.
מערכות תשובות שאלה
BERT משמש כדי לספק תשובות מדויקות לשאלות שנשאלו.
🧠 המשמעות של ברט לעתיד ה- AI
ברט קבע סטנדרטים חדשים לדגמי NLP וסלל את הדרך לחידושים נוספים. בשל יכולתו לעבד כיוון דו -כיווני והבנתו העמוקה בהקשרים בשפה, היא הגדילה משמעותית את היעילות והדיוק של יישומי AI.
🔜 התפתחויות עתידיות
פיתוח נוסף של BERT ומודלים דומים צפוי להיות מכוון ליצור מערכות חזקות עוד יותר. אלה יכולים להתמודד עם משימות קוליות מורכבות יותר ומשמשות במגוון תחומי יישום חדשים. שילוב מודלים כאלה בטכנולוגיות יומיומיות יכול לשנות באופן מהותי את האינטראקציה שלנו עם מחשבים.
🌟 אבן דרך בפיתוח בינה מלאכותית
ברט הוא אבן דרך בפיתוח בינה מלאכותית וחולל מהפכה באופן האופן שבו מכונות מעבדות שפה טבעית. הארכיטקטורה הדו -כיוונית שלה מאפשרת הבנה מעמיקה יותר של מערכות יחסים לשוניות, מה שהופך אותה לכיוון למגוון יישומים. עם מחקר מתקדם, מודלים כמו BERT ימשיכו למלא תפקיד מרכזי בשיפור מערכות AI ופתיחת הזדמנויות חדשות לשימושם.
📣 נושאים דומים
- 📚 מבוא לברט: מודל ה- NLP פורץ הדרך
- 🔍 ברט ותפקיד הדו -כיווניות ב- NLP
- 🧠 דגם השנאי: מארז אבן של ברט
- 🚀 דוגמנות קוליות רעולי פנים: המפתח של ברט להצלחה
- 📈 עיבוד BERT: מהכשרה מקדימה ועד כוונון עדין
- 🌐 תחומי היישום של ברט בטכנולוגיה מודרנית
- השפעתו של ברט על עתיד הבינה המלאכותית
- 💡 סיכויים עתידיים: התפתחויות נוספות של BERT
- 🏆 ברט כאבן דרך בפיתוח AI
- 📰 מחברי נייר השנאי "תשומת הלב היא כל מה שאתה צריך": הראשים מאחורי ברט
#טיס hashtags: #nlp #artificial Editionstz #שפה דוגמנות #transformer #maschineleslernen
🎯🎯🎯 תועלת מהמומחיות הנרחבת של חמש זמן מ- Xpert.Digital בחבילת שירות מקיפה | R&D, XR, PR & SEM

AI & XR-3D-Rendering Machine: חמש פעמים מומחיות מ- xpert.digital בחבילת שירות מקיפה, R&D XR, PR & SEM-Image: Xpert.Digital
ל- xpert.digital ידע עמוק בענפים שונים. זה מאפשר לנו לפתח אסטרטגיות התאמה המותאמות לדרישות ולאתגרים של פלח השוק הספציפי שלך. על ידי ניתוח מתמיד של מגמות שוק ורדיפת פיתוחים בתעשייה, אנו יכולים לפעול עם ראיית הנולד ולהציע פתרונות חדשניים. עם שילוב של ניסיון וידע, אנו מייצרים ערך מוסף ומעניקים ללקוחותינו יתרון תחרותי מכריע.
עוד על זה כאן:
BERT: מהפכני 🌟 טכנולוגיית NLP
Bert, קיצור של ייצוגים מקודדים דו כיווניים של רובוטריקים, הוא מודל קול מתקדם שפותח על ידי גוגל והתפתח לפריצה משמעותית בתחום עיבוד השפה הטבעית (עיבוד שפה טבעית, NLP) מאז הצגתו בשנת 2018. הוא מבוסס על ארכיטקטורת השנאי שחולל מהפכה את הדרך שמכבות מבינים ומעיבוד טקסט. אבל מה בדיוק הופך את ברט לכל כך מיוחד ולמה הוא משמש? כדי לענות על שאלה זו, עלינו להתמודד עם היסודות הטכניים, התפקוד ותחומי היישום מ- BERT.
📚 1. היסודות של עיבוד שפה טבעית
על מנת לתפוס באופן מלא את המשמעות של BERT, מועיל להגיב בקצרה ליסודות עיבוד השפה הטבעית (NLP). NLP עוסק באינטראקציה בין מחשבים לשפה אנושית. המטרה היא ללמד מכונות, לנתח נתוני טקסט, להבין ולהגיב אליהם. לפני הצגת מודלים כמו BERT, העיבוד המכני של השפה היה קשור לרוב לאתגרים ניכרים, בפרט בגלל העמימות, תלות ההקשר והמבנה המורכב של השפה האנושית.
📈 2. פיתוח דגמי NLP
לפני שברט הופיע בזירה, מרבית דגמי ה- NLP התבססו על מה שנקרא ארכיטקטורות חד כיווניות. המשמעות היא שמודלים אלה קוראים את הטקסט משמאל לימין או מימין לשמאל, מה שאומר שהם יכולים לקחת בחשבון רק כמות מוגבלת של הקשר בעת עיבוד מילה במשפט אחד. מגבלה זו הובילה לעתים קרובות לדגמים שההקשר הסמנטי המלא של משפט לא הקליט במלואו. זה עשה את הפרשנות המדויקת של מילים דו משמעיות או הרגישות להקשר.
התפתחות חשובה נוספת במחקר NLP מול BERT הייתה מודל Word2VEC, מה שאיפשר לתרגם מחשבים בווקטורים ששיקפו קווי דמיון סמנטיים. אך גם כאן ההקשר היה מוגבל לסביבה המיידית של מילה. פותחו פותחו רשתות עצביות חוזרות ונשנות (RNNs) ובמיוחד דגמי זיכרון ארוכים לטווח קצר (LSTM) שאפשרו להבין טוב יותר את רצפי הטקסט על ידי אחסון מידע על פני מספר מילים. עם זאת, למודלים אלה היו גם גבולותיהם, במיוחד כאשר הם מתמודדים עם טקסטים ארוכים וההבנה בו זמנית של ההקשר בשני הכיוונים.
🔄 3. המהפכה על ידי ארכיטקטורת השנאי
הפריצה הגיעה עם הצגת ארכיטקטורת השנאי בשנת 2017, המהווה את הבסיס ל- BERT. דגמי שנאי נועדו לאפשר עיבוד מקביל של טקסט ולקחת בחשבון את ההקשר של מילה הן מהטקסט הקודם והן מהטקסט הבא. זה קורה באמצעות מה שמכונה מנגנוני ציות עצמית (מנגנון פוסט-פוסט עצמי), המקצות ערך שקלול לכל מילה במשפט אחד, על סמך כמה זה חשוב ביחס למילים האחרות במשפט.
בניגוד לגישות קודמות, מודלי שנאי אינם חד כיווניים, אלא דו כיווניים. המשמעות היא שתוכלו לשאוב מידע משמאל וההקשר הימני של מילה על מנת ליצור ייצוג מלא ומדויק יותר של המילה ומשמעותה.
🧠 4. ברט: מודל דו כיווני
ברט מעלה את ביצועי ארכיטקטורת השנאי לרמה חדשה. הדגם נועד להקליט את ההקשר של מילה לא רק משמאל לימין או מימין לשמאל, אלא בשני הכיוונים בו זמנית. זה מאפשר ל- BERT לקחת בחשבון את ההקשר המלא של מילה בתוך משפט, מה שמוביל לשיפור משמעותי של הדיוק במקרה של עיבוד שפה.
מאפיין מרכזי של BERT הוא השימוש במודל הקולי המסווה שנקרא כל כך (מודל שפה רעול פנים, MLM). בהכשרה של ברט, מילים שנבחרו באופן אקראי מוחלפות על ידי מסכה במשפט אחד, והמודל מאומן לנחש את המילים המסכות הללו על בסיס ההקשר. טכנולוגיה זו מאפשרת לברט ללמוד קשרים עמוקים ומדויקים יותר בין המילים במשפט אחד.
בנוסף, BERT משתמשת בשיטה שנקראת Next Pent Presention (NSP) בה המודל לומד לחזות אם משפט אחד עוקב אחר אחר או לא. זה משפר את יכולתו של ברט להבין טקסטים ארוכים יותר ולהכיר בקשרים מורכבים יותר בין משפטים.
🌐 5. שימוש ב- BERT בפועל
ברט הוכיח כמועיל ביותר למגוון משימות NLP. להלן כמה מתחומי היישום החשובים ביותר:
📊 א) סיווג טקסט
אחת המטרות הנפוצות ביותר של BERT היא סיווג הטקסטים, בה טקסטים מחולקים לקטגוריות מוגדרות מראש. דוגמאות לכך הן הניתוח הסנטימנטלי (למשל הכרה אם טקסט חיובי או שלילי) או סיווג משוב הלקוחות. על ידי הבנתו העמוקה של הקשר המילים, ברט יכול לספק תוצאות מדויקות יותר מאשר מודלים קודמים.
❓ ב) מערכות תשובות שאלה
BERT משמש גם במערכות תשובות ספק בהן המודל מחלץ תשובות לשאלות מטקסט. יכולת זו חשובה במיוחד ביישומים כמו מנועי חיפוש, צ'אט בוטים או עוזרים וירטואליים. הודות לארכיטקטורה הדו -כיוונית שלה, BERT יכולה לחלץ מידע רלוונטי מטקסט, גם אם השאלה מנוסחת בעקיפין.
🌍 ג) תרגום טקסט
בעוד ש- BERT עצמה אינה מעוצבת ישירות כמודל תרגום, ניתן להשתמש בו בשילוב עם טכנולוגיות אחרות לשיפור תרגום המכונה. על ידי הבנה טובה יותר של מערכות יחסים סמנטיות במשפט אחד, ברט יכול לעזור לייצר תרגומים מדויקים, במיוחד עם ניסוחים מעורפלים או מורכבים.
🏷️ ד) זיהוי ישויות בשם (NER)
תחום יישום נוסף הוא זיהוי הישות שנקרא (NER), העוסק בזיהוי ישויות מסוימות כמו שמות, מקומות או ארגונים בטקסט. ברט הוכיח כיעיל במיוחד במשימה זו, מכיוון שהוא לוקח בחשבון לחלוטין את ההקשר של משפט ובכך יכול להכיר טוב יותר ישויות, גם אם יש להם משמעויות שונות בהקשרים שונים.
✂️ E) טקסט
היכולת של ברט להבין את כל ההקשר של טקסט הופכת אותו גם לכלי רב עוצמה לטקסט האוטומטי של הטקסט. ניתן להשתמש בו כדי לחלץ את המידע החשוב ביותר מטקסט ארוך וליצור סיכום תמציתי.
🌟 6. חשיבותו של ברט למחקר ותעשייה
הצגתו של ברט בינה עידן חדש במחקר NLP. זה היה אחד הדגמים הראשונים שהשתמשו במלואם בביצועים של ארכיטקטורת השנאי הדו -כיוונית ובכך הציבו את אבן המידה עבור דגמים רבים שלאחר מכן. חברות ומכוני מחקר רבים שילבו את BERT בצינורות ה- NLP שלהם כדי לשפר את ביצועי היישומים שלהם.
ברט סלל גם את הדרך לחידושים נוספים בתחום מודלים לשפה. לדוגמה, פותחו דגמים כמו GPT (שנאי מופרך גנאי) ו- T5 (שנאי העברת טקסט-טקסט) המבוססים על עקרונות דומים, אך מציעים שיפורים ספציפיים ליישומים שונים.
7. 7. אתגרים ומגבלות של ברט
למרות היתרונות הרבים שלו, לברט יש גם כמה אתגרים ומגבלות. אחד המכשולים הגדולים ביותר הוא מאמץ המחשוב הגבוה הנדרש לאימונים ושימוש במודל. מכיוון ש- BERT הוא מודל גדול מאוד עם מיליוני פרמטרים, הוא דורש חומרה עוצמתית ומשאבים אריתמטיים ניכרים, במיוחד בעת עיבוד כמויות גדולות של נתונים.
בעיה נוספת היא ההטיה הפוטנציאלית (הטיה), שיכולה להיות קיימת בנתוני האימונים. מכיוון ש- BERT מאומנת על כמויות גדולות של נתוני טקסט, היא לפעמים משקפת את הדעות הקדומות והסטראוטיפים הזמינים בנתונים אלה. עם זאת, החוקרים עובדים ברציפות על זיהוי והסרת בעיות אלה.
🔍 כלי חיוני ליישומי עיבוד שפות מודרניים
ברט שיפר משמעותית את האופן בו מכונות מבינות את השפה האנושית. עם הארכיטקטורה הדו -כיוונית שלה ושיטות ההדרכה החדשניות, היא מסוגלת לתפוס את הקשר של מילים במשפט אחד עמוק ומדויק, מה שמוביל לדיוק גבוה יותר במשימות NLP רבות. בין אם סיווג הטקסט, במערכות תגובה מדובר או בגילוי ישויות-ברט ביסס את עצמו ככלי חיוני ליישומי עיבוד שפות מודרניים.
המחקר בתחום עיבוד השפה הטבעית מתקדם ללא ספק, וברט הניח את הבסיס לחידושים עתידיים רבים. למרות האתגרים והגבולות הקיימים, ברט מראה בצורה מרשימה עד כמה הטכנולוגיה הגיעה תוך זמן קצר ואילו אפשרויות מרגשות ייפתחו בעתיד.
🌀 השנאי: מהפכה בתחום עיבוד השפה הטבעית
🌟 בשנים האחרונות, אחת ההתפתחויות החשובות ביותר בתחום עיבוד השפה הטבעית (עיבוד שפה טבעית, NLP) הייתה הצגת מודל השנאי, כמתואר במאמר 2017 "תשומת הלב היא כל מה שאתה צריך". מודל זה שינה את התחום באופן בסיסי על ידי דחיית מבני החוזרים או ההתפתלות ששימשו בעבר למשימות של הולכת רצף, כמו תרגום המכונה. במקום זאת, זה מסתמך רק על מנגנוני קשב. מאז, עיצוב השנאי היה הבסיס למודלים רבים המייצגים את מצב האמנות בתחומים שונים כמו ייצור שפות, תרגום ומעבר לה.
🔄 השנאי: שינוי פרדיגמה
לפני הצגת השנאי, מרבית המודלים למשימות רצף התבססו על רשתות עצביות חוזרות ונשנות (RNNs) או רשתות "זיכרון ארוך לטווח קצר" (LSTMS), אשר באופן טבעי פועלים ברצף. דגמים אלה מעבדים נתוני קלט שלב אחר שלב ויוצרים תנאים נסתרים המועברים לאורך הרצף. למרות ששיטה זו יעילה, היא מורכבת מתמטית וקשה להקביל, במיוחד עם רצפים ארוכים. בנוסף, הקשיים של RNN ללמוד תלות ארוכת טווח, מכיוון שמתרחשת הבעיה כביכול "שיפוע".
החידוש המרכזי של השנאי טמון בשימוש במנגנונים עצמיים, המאפשרים למודל למשקל את חשיבותן של מילים שונות במשפט אחד, ללא קשר למיקומם. זה מאפשר למודל לתפוס קשרים בין מילים נפרדות זה מזה בצורה יעילה יותר מ- RNN או LSTMS, וזה במקביל במקום רצף. זה לא רק משפר את יעילות האימונים, אלא גם ביצועים למשימות כמו תרגום מכונה.
🧩 ארכיטקטורת מודל
השנאי מורכב משני מרכיבים עיקריים: מקודד ומפענח, ששניהם מורכבים מכמה שכבות ותלויים מאוד במנגנוני תחנות רב ראש.
⚙️ מקודד
המקודד מורכב משש שכבות זהות, לכל אחת מהן שני מעמדות נמוכים:
1. תאורה עצמית רב ראש
מנגנון זה מאפשר למודל להתרכז בחלקים שונים בקצב הקלט בעת עיבוד כל מילה. במקום לחשב את תשומת הלב בחדר יחיד, התחנה הרב-ראשית מקרינה את הקלט למספר חדרים שונים, מה שאומר שניתן לרשום סוגים שונים של מערכות יחסים בין מילים.
2. רשתות קדימה מחוברות לחלוטין
על פי שכבת ההתקפה, רשת הזנה מחוברת לחלוטין מיושמת באופן עצמאי בכל עמדה. זה עוזר למודל לעבד כל מילה בהקשר ולהשתמש במידע ממנגנון הקשב.
על מנת לשמר את מבנה רצף הקלט, המודל מכיל גם קלט מיקום (קידוד עמדות). מכיוון שהשנאי אינו מעבד את המילים ברצף, קידומים אלה הם מכריעים על מנת לספק את המידע על המודל על סדר המילים במשפט אחד. כניסות המיקום מתווספות מפה-מיטות כך שהמודל יכול להבדיל בין המיקומים השונים ברצף.
🔍 מפענח
בדומה למקודד, המפענח מורכב גם משש שכבות, כאשר לכל שכבה יש מנגנון קשב נוסף המאפשר למודל להתרכז בחלקים רלוונטיים של רצף הקלט בזמן שהוא מייצר את התפוקה. המפענח משתמש גם בטכניקת מיסוך כדי למנוע מעמדות עתידיות לקחת בחשבון את מה שהמחבר -מדובר באופי של דור הרצף שומר.
Station תחנת מוצרים מרובת ראש ומוצרי סקלר
לב השנאי הוא מנגנון הפוסט הרב-ראש, המהווה הרחבה של תחנת המוצר הסקלרית הפשוטה יותר. ניתן לראות בפונקציית ההתקפה כמחשה בין שאילתה (שאילתה) למשפט של זוגות ערך מפתח (מפתחות וערכים), כל מפתח מייצג מילה ברצף והערך מייצג את המידע ההקשרי המשויך.
מנגנון התחנה הרב-ראשית מאפשר לדגם להתרכז בחלקים שונים של הרצף בו זמנית. על ידי השלכת הקלט למספר חדרי משנה, המודל יכול לתפוס כמות עשירה יותר של מערכות יחסים בין מילים. זה שימושי במיוחד למשימות כמו תרגום מכונה, בהן הבנת ההקשר של מילה דורשת גורמים רבים ושונים, כמו המבנה התחבירי והמשמעות הסמנטית.
הנוסחה לתחנת המוצר Scalar היא:
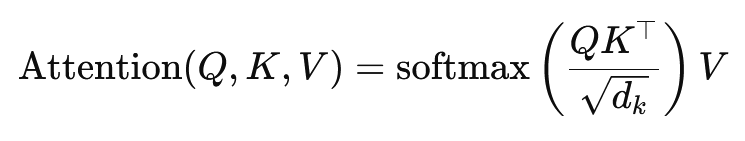
כאן (ש) Fragematrix, (k) מטריצת המפתח ו- (v) מטריצת הערך. המונח (SQRT {D_K}) הוא גורם קנה מידה המונע ממוצרי הסקלר להיות גדולים מדי, מה שיוביל לדרגת שיפוע קטנה מאוד ולמידה איטית יותר. פונקציית SoftMax משמשת כדי להבטיח שמשקלי הקשב יביאו לסכום של אחת.
🚀 יתרונות השנאי
השנאי מציע מספר יתרונות מכריעים על פני מודלים מסורתיים כמו RNNs ו- LSTMs:
1. הקבלה
מכיוון שהשנאי מעבד את כל הרצף בו זמנית, ניתן להקביל אותו מאוד ולכן הוא מהיר הרבה יותר להתאמן מאשר RNN או LSTM, במיוחד עם מערכי נתונים גדולים.
2. תלות ארוכות טווח
מנגנון העמדות העצמי מאפשר למודל לתפוס קשרים בין מילים רחוקות בצורה יעילה יותר מ- RNNs, המוגבלים על ידי האופי הרצף של החישובים שלהם.
3. מדרגיות
ניתן בקלות לקנה מידה של השנאי על רשומות נתונים גדולות מאוד ורצפים ארוכים יותר מבלי לסבול מצוואר הבקבוק של הביצועים הקשורים ל- RNS.
🌍 יישומים ואפקטים
מאז הצגתו, השנאי הפך לבסיס למגוון רחב של דגמי NLP. אחת הדוגמאות המדהימות ביותר היא BERT (ייצוג מקודד דו כיווני משנאים), המשתמשת בארכיטקטורת שנאי שונה כדי להשיג את מצב האמנות במשימות NLP רבות, כולל תשאול וסיווג טקסטים.
התפתחות משמעותית נוספת היא GPT (שנאי מגודר מראש), המשתמשת בגרסת השנאי ליצירת טקסט. דגמי GPT, כולל GPT-3, משמשים כיום ליישומים רבים, החל מיצירת תוכן ועד השלמת הקוד.
🔍 מודל חזק וגמיש
השנאי שינה באופן מהותי את האופן בו אנו מתמודדים עם משימות NLP. הוא מציע מודל רב עוצמה וגמיש שניתן ליישם על מגוון בעיות. היכולת שלו לטפל בתלות ארוכת טווח, ויעילותו באימונים הפכו אותו לגישה האדריכלית המועדפת עבור רבים מהדגמים המודרניים ביותר. עם מחקר מתקדם, ככל הנראה נראה שיפורים והתאמות נוספות לשנאי, במיוחד בתחומים כמו עיבוד דימוי ושפה, כאשר מנגנוני קשב מראים תוצאות מבטיחות.
אנחנו שם בשבילך - ייעוץ - תכנון - יישום - ניהול פרויקטים
☑️ מומחה בתעשייה, כאן עם רכזת תעשייה משלה

קונרד וולפנשטיין
אני שמח לעזור לך כיועץ אישי.
אתה יכול ליצור איתי קשר על ידי מילוי טופס יצירת הקשר למטה או פשוט להתקשר אליי בטלפון +49 89 674 804 (מינכן) .
אני מצפה לפרויקט המשותף שלנו.
כתוב לי

Xpert.digital - קונראד וולפנשטיין
Xpert.Digital הוא מוקד לתעשייה עם מיקוד, דיגיטציה, הנדסת מכונות, לוגיסטיקה/אינטרלוגיסטיקה ופוטו -וולטאים.
עם פיתרון הפיתוח העסקי של 360 ° שלנו, אנו תומכים בחברות ידועות מעסקים חדשים למכירות.
מודיעין שוק, סמוקינג, אוטומציה שיווקית, פיתוח תוכן, יחסי ציבור, קמפיינים בדואר, מדיה חברתית בהתאמה אישית וטיפוח עופרת הם חלק מהכלים הדיגיטליים שלנו.
אתה יכול למצוא עוד בכתובת: www.xpert.digital - www.xpert.solar - www.xpert.plus
שמור על קשר



















