נתונים הם המרכיב המכריע בבינה מלאכותית גנרית – על חשיבותם של נתונים עבור בינה מלאכותית – תמונה: Xpert.Digital
🌟🔍 איכות וגיוון: מדוע נתונים חיוניים לבינה מלאכותית גנרית
🌐📊 חשיבות הנתונים עבור בינה מלאכותית גנרטיבית
נתונים הם עמוד השדרה של הטכנולוגיה המודרנית וממלאים תפקיד מכריע בפיתוח ותפעול של בינה מלאכותית גנרטיבית. בינה מלאכותית גנרטיבית, המכונה גם בינה מלאכותית המסוגלת ליצור תוכן (כגון טקסט, תמונות, מוזיקה ואפילו סרטונים), היא כיום אחד התחומים החדשניים והדינמיים ביותר של פיתוח טכנולוגי. אבל מה מאפשר את הפיתוח הזה? התשובה פשוטה: נתונים.
📈💡 נתונים: לב ליבה של בינה מלאכותית גנרטיבית
נתונים הם במובנים רבים לב ליבה של בינה מלאכותית גנרטיבית. ללא כמויות עצומות של נתונים באיכות גבוהה, האלגוריתמים המפעילים מערכות אלו לא יוכלו ללמוד או להתפתח. סוג ואיכות הנתונים המשמשים לאימון מודלים אלו קובעים באופן משמעותי את יכולתם לייצר תוצאות יצירתיות ושימושיות.
כדי להבין מדוע נתונים כה חשובים, עלינו לבחון כיצד פועלות מערכות בינה מלאכותית גנרטיבית. מערכות אלו מאומנות באמצעות למידת מכונה, ובפרט למידה עמוקה. למידה עמוקה היא תת-קבוצה של למידת מכונה המסתמכת על רשתות עצביות מלאכותיות המבוססות על אופן פעולת המוח האנושי. רשתות אלו מוזנות כמויות אדירות של נתונים, מהן הן יכולות לזהות דפוסים וקשרים וללמוד.
📝📚 יצירת טקסט באמצעות בינה מלאכותית גנרטיבית: דוגמה פשוטה
דוגמה פשוטה היא יצירת טקסט באמצעות בינה מלאכותית גנרטיבית. אם בינה מלאכותית רוצה להיות מסוגלת לכתוב טקסטים משכנעים, עליה תחילה לנתח כמות עצומה של נתונים לשוניים. ניתוח נתונים זה מאפשר לבינה המלאכותית להבין ולשכפל את המבנה, הדקדוק, הסמנטיקה והאמצעים הסגנוניים של השפה האנושית. ככל שהנתונים מגוונים ומקיפים יותר, כך הבינה המלאכותית יכולה להבין ולשחזר טוב יותר סגנונות וניואנסים שונים של שפה.
🧹🏗️ איכות והכנת נתונים
אבל זה לא רק עניין של כמות הנתונים; גם האיכות היא קריטית. נתונים באיכות גבוהה הם נקיים, מתוחזקים היטב ומייצגים את מה שהבינה המלאכותית אמורה ללמוד. לדוגמה, לא יהיה זה מועיל במיוחד לאמן בינה מלאכותית מבוססת טקסט עם נתונים המכילים בעיקר מידע שגוי או שגוי. חשוב לא פחות לוודא שהנתונים נטולי הטיה. הטיה בנתוני האימון יכולה לגרום לבינה המלאכותית לייצר תוצאות מוטות או לא מדויקות, דבר שיכול להיות בעייתי במקרי שימוש רבים, במיוחד בתחומים רגישים כמו בריאות או משפט.
היבט חשוב נוסף הוא גיוון הנתונים. בינה מלאכותית גנרטיבית נהנית ממגוון רחב של מקורות נתונים. זה מבטיח שהמודלים יהיו ישימים יותר באופן כללי ויכולים להגיב למגוון הקשרים ומקרי שימוש. לדוגמה, בעת אימון מודל גנרטיבי להפקת טקסט, הנתונים צריכים להגיע מז'אנרים, סגנונות ותקופות שונים. זה נותן לבינה מלאכותית את היכולת להבין וליצור מגוון רחב של סגנונות ופורמטים של כתיבה.
מלבד חשיבות הנתונים עצמם, גם תהליך הכנת הנתונים הוא קריטי. לעתים קרובות יש צורך לעבד נתונים לפני אימון בינה מלאכותית כדי למקסם את התועלת שלהם. זה כולל משימות כגון ניקוי הנתונים, הסרת כפילויות, תיקון שגיאות ונרמול הנתונים. תהליך הכנת נתונים שבוצע בקפידה משפר משמעותית את ביצועי מודל הבינה המלאכותית.
🖼️🖥️ יצירת תמונות באמצעות בינה מלאכותית גנרטיבית
תחום חשוב אחד שבו בינה מלאכותית גנרטיבית וחשיבותם של נתונים הופכות בולטות במיוחד הוא יצירת תמונות. טכניקות כמו רשתות יריבות גנרטיביות (GANs) חוללו מהפכה בשיטות המסורתיות של יצירת תמונות. רשתות GAN מורכבות משתי רשתות עצביות מתחרות: גנרטור ומבחין. הגנרטור יוצר תמונות, והמבחין מעריך האם תמונות אלו אמיתיות (ממערכת נתונים של אימון) או נוצרות (על ידי הגנרטור). באמצעות תחרות זו, הגנרטור משתפר ללא הרף עד שהוא יכול לייצר תמונות ריאליסטיות באופן מטעה. גם כאן, נתוני תמונה נרחבים ומגוונים נחוצים כדי לאפשר לגנרטור ליצור תמונות ריאליסטיות ומפורטות ביותר.
🎶🎼 קומפוזיציה מוזיקלית ובינה מלאכותית יצירתית
חשיבות הנתונים משתרעת גם על תחום המוזיקה. בינה מלאכותית מוזיקלית גנרטיבית משתמשת במאגרי מידע גדולים של יצירות מוזיקליות כדי ללמוד את המבנים והדפוסים האופייניים לסגנונות מוזיקליים ספציפיים. בעזרת נתונים אלה, בינה מלאכותית יכולה להלחין יצירות מוזיקליות חדשות הדומות מבחינה סגנונית ליצירותיהם של מלחינים אנושיים. זה פותח אפשרויות מרגשות בתעשיית המוזיקה, כגון פיתוח יצירות חדשות או הפקה מוזיקלית מותאמת אישית.
📽️🎬 הפקת וידאו ובינה מלאכותית גנרטורים
נתונים הם גם בעלי ערך רב בהפקת וידאו. מודלים גנרטיביים מסוגלים ליצור סרטונים שנראים מציאותיים וחדשניים. ניתן להשתמש בבינה מלאכותית זו כדי ליצור אפקטים מיוחדים לסרטים או כדי ליצור סצנות חדשות למשחקי וידאו. הנתונים הבסיסיים יכולים להכיל מיליוני קטעי וידאו המכילים סצנות, נקודות מבט ודפוסי תנועה שונים.
🎨🖌️ אמנות ובינה מלאכותית יצירתית
תחום נוסף שנהנה מבינה מלאכותית גנרטיבית ומחשיבותם של נתונים הוא אמנות. מודלים אמנותיים של בינה מלאכותית יוצרים יצירות אמנות מרשימות, בהשראת אמני העבר או מציגים סגנונות אמנותיים חדשים לחלוטין. מערכות אלו מאומנות על מערכי נתונים המכילים יצירות של אמנים ותקופות שונות כדי ללכוד מגוון רחב של סגנונות וטכניקות אמנותיות.
🔒🌍 אתיקה והגנת מידע
אתיקה ממלאת גם תפקיד מכריע בכל הנוגע לנתונים ובינה מלאכותית גנרית. מכיוון שמודלים אלה משתמשים לעתים קרובות בכמויות גדולות של נתונים אישיים או רגישים, יש להתייחס לחששות בנוגע להגנה על נתונים. חיוני שהנתונים ייעשה בהם שימוש הוגן ושקוף ושפרטיותם של אנשים תהיה מוגנת. חברות ומוסדות מחקר חייבים להבטיח שהם מטפלים בנתונים באחריות וכי מערכות הבינה המלאכותית שהם מפתחים עומדות בסטנדרטים אתיים.
לסיכום, נתונים הם המרכיב המכריע בפיתוח ובהצלחתה של בינה מלאכותית גנרטיבית. הם לא רק חומר הגלם שממנו מערכות אלו שואבות את הידע שלהן, אלא גם המפתח למימוש מלוא הפוטנציאל שלהן במגוון רחב של יישומים. איסוף, עיבוד ושימוש קפדניים בנתונים מבטיחים שמערכות בינה מלאכותית גנרטיביות יהיו לא רק חזקות וגמישות יותר, אלא גם בטוחות מבחינה אתית. המסע של בינה מלאכותית גנרטיבית עדיין בשלביו הראשונים, ותפקידם של הנתונים ימשיך להיות בעל חשיבות מרכזית.
📣 נושאים דומים
- 📊 מהות הנתונים עבור בינה מלאכותית גנרית
- 📈 איכות וגיוון נתונים: המפתח להצלחה בבינה מלאכותית
- 🎨 יצירתיות מלאכותית: בינה מלאכותית גנרטיבית באמנות ועיצוב
- 📝 יצירת טקסט מבוסס נתונים באמצעות בינה מלאכותית גנרטורים
- 🎬 מהפכה בהפקת וידאו הודות לבינה מלאכותית גנרטבית
- 🎶 יצירת בינה מלאכותית גנרטיבית: עתיד המוזיקה
- 🧐 שיקולים אתיים בשימוש בנתונים למטרות בינה מלאכותית
- 👾 רשתות יריבות גנריות: מקוד לאמנות
- 🧠 למידה עמוקה וחשיבותם של נתונים באיכות גבוהה
- 🔍 תהליך הכנת הנתונים עבור בינה מלאכותית גנרטיבית
#️⃣ האשטגים: #נתונים #בינה מלאכותית_גנרטיבית #אתיקה #יצירת טקסט #יצירתיות
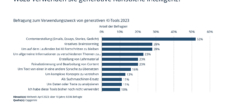
💡🤖 ראיון עם פרופ' ריינהרד הקל על חשיבות הנתונים עבור בינה מלאכותית

ריינהרד הקל, פרופסור למידת מכונה - תמונה: אסטריד אקרט / TUM
📊💻 נתונים מהווים את הבסיס לבינה מלאכותית. לצורך אימון משתמשים בנתונים זמינים בחינם מהאינטרנט, אשר עוברים סינון כבד.
- קשה להימנע מהטיות במהלך האימון. לכן, המודלים מנסים לספק תשובות מאוזנות ולהימנע ממונחים בעייתיים.
- הדיוק של מודלים של בינה מלאכותית משתנה בהתאם לאזור היישום, כאשר כל פרט רלוונטי בין היתר באבחון מחלות.
- הגנה על מידע וניידות נתונים הן אתגרים בהקשר הרפואי.
הנתונים שלנו נאספים כעת בכל מקום באינטרנט ומשמשים גם לאימון מודלים של שפה גדולה כמו ChatGPT. אבל כיצד מאמנים בינה מלאכותית (AI), כיצד מבטיחים שלא יתעוררו עיוותים, מה שנקרא הטיות, במודלים, וכיצד מכבדים את הגנת המידע? ריינהרד הקל, פרופסור ללמידת מכונה באוניברסיטה הטכנית של מינכן (TUM), מספק תשובות לשאלות אלו. מחקרו מתמקד במודלים של שפה גדולה ובטכניקות הדמיה רפואית.
🔍🤖 איזה תפקיד ממלאים נתונים באימון מערכות בינה מלאכותית?
מערכות בינה מלאכותית משתמשות בנתונים כדוגמאות לאימון. מודלים גדולים של שפה כמו ChatGPT יכולים לענות רק על שאלות בנושאים עליהם אומנו.
רוב המידע המשמש לאימון מודלים כלליים של שפה זמין בחינם באינטרנט. ככל שיהיו יותר נתוני אימון זמינים עבור שאלה נתונה, כך התוצאות טובות יותר. לדוגמה, אם ישנם טקסטים רבים באיכות גבוהה המתארים מושגים מתמטיים עבור בינה מלאכותית שנועדה לסייע בבעיות מתמטיות, נתוני האימון יהיו טובים בהתאם. עם זאת, בחירת הנתונים הנוכחית כרוכה בסינון קפדני מאוד. מתוך כמות הנתונים העצומה הזמינים, רק הנתונים האיכותיים נאספים ומשמשים לאימון.
📉🧠 כיצד מוודאים שהבינה המלאכותית לא מייצרת, למשל, סטריאוטיפים גזעניים או סקסיסטיים, מה שנקרא הטיות, בעת בחירת נתונים?
קשה מאוד לפתח שיטה שאינה מסתמכת על סטריאוטיפים קלאסיים ופועלת בצורה אובייקטיבית והוגנת. לדוגמה, מניעת עיוות של התוצאות עקב צבע עור היא קלה יחסית. עם זאת, כאשר מעורב גם מגדר, עלולים להיווצר מצבים שבהם לא ניתן עוד למודל לפעול באופן אובייקטיבי לחלוטין הן ביחס לצבע העור והן למגדר בו זמנית.
לכן, רוב מודלי השפה מנסים לספק תשובות מאוזנות לשאלות פוליטיות, למשל, ולהאיר נקודות מבט מרובות. כאשר מתבססים על תוכן תקשורתי, ניתנת עדיפות לכלי תקשורת העומדים בקריטריונים של איכות עיתונאית. יתר על כן, בעת סינון נתונים, ננקטת זהירות כדי להבטיח שמילים מסוימות, כגון מילים גזעניות או סקסיסטיות, לא יופיעו.
🌐📚 בחלק מהשפות יש הרבה תוכן מקוון, בעוד שבאחרות יש פחות משמעותית. כיצד זה משפיע על איכות התוצאות?
רוב האינטרנט הוא באנגלית. זו הסיבה שמודלים גדולים של שפות עובדים בצורה הטובה ביותר באנגלית. עם זאת, יש גם הרבה תוכן זמין בגרמנית. עבור שפות פחות נפוצות ועבורן יש פחות טקסטים, יש פחות נתוני אימון, ולכן המודלים מתפקדים פחות טוב.
ניתן בקלות לראות עד כמה מודלים של שפה יכולים לשמש בשפות ספציפיות, שכן הם פועלים לפי מה שנקרא חוקי קנה מידה. זה כרוך בבדיקה האם מודל שפה מסוגל לחזות את המילה הבאה. ככל שיותר נתוני אימון זמינים, כך המודל משתפר. אבל הוא לא רק משתפר באופן מתמיד; השיפור שלו גם צפוי. ניתן לייצג זאת ביעילות על ידי משוואה מתמטית.
💉👨⚕️ כמה מדויקת צריכה להיות בינה מלאכותית בפועל?
זה תלוי מאוד ביישום הספציפי. לדוגמה, עם תמונות שעברו עיבוד לאחר מכן באמצעות בינה מלאכותית, לא משנה אם כל שערה נמצאת במקום הנכון. לעתים קרובות, מספיק אם התמונה הסופית נראית טוב. באופן דומה, עם מודלים שפה גדולים, חשוב שהשאלות יענו בצורה נכונה; לא תמיד חשוב לדעת האם פרטים חסרים או שגויים. מלבד מודלים שפה, אני עורך גם מחקר בתחום עיבוד תמונה רפואית. כאן, חיוני שכל פרט ופרט בתמונה שנוצרת יהיה מדויק. אם אני משתמש בבינה מלאכותית לאבחונים, היא חייבת להיות נכונה לחלוטין.
🛡️📋 חוסר הגנת מידע נדון לעתים קרובות בהקשר של בינה מלאכותית. כיצד ניתן להבטיח הגנה על מידע אישי, במיוחד בהקשר רפואי?
רוב היישומים הרפואיים משתמשים בנתוני מטופלים אנונימיים. הסכנה האמיתית טמונה בעובדה שישנם מצבים שבהם עדיין ניתן להסיק מסקנות מנתונים אלה. לדוגמה, גיל או מין ניתנים לעיתים קרובות לקביעה באמצעות סריקות MRI או CT. לכן, מידע מסוים שנראה אנונימי כלול בתוך הנתונים. לכן חיוני ליידע את המטופלים על כך כראוי.
⚠️📊 אילו קשיים נוספים קיימים באימון בינה מלאכותית בהקשר רפואי?
אתגר מרכזי טמון באיסוף נתונים המשקפים מגוון רחב של מצבים ותרחישים. בינה מלאכותית פועלת בצורה הטובה ביותר כאשר הנתונים עליהם היא מיושמת דומים לנתוני האימון. עם זאת, הנתונים משתנים מבית חולים לבית חולים, למשל, מבחינת הרכב המטופלים או הציוד המשמש לייצור הנתונים. כדי לפתור בעיה זו, ישנן שתי אפשרויות: או שנצליח לשפר את האלגוריתמים, או שעלינו לייעל את הנתונים שלנו כך שניתן יהיה ליישם אותם בצורה יעילה יותר במצבים אחרים.
👨🏫🔬 אודותיי:
פרופסור ריינהרד הקל עורך מחקר בתחום למידת מכונה. הוא עובד על פיתוח אלגוריתמים ויסודות תיאורטיים ללמידה עמוקה. אחד ממוקדי עבודתו הוא עיבוד תמונה רפואית. הוא גם מפתח פתרונות אחסון נתוני DNA וחוקר את השימוש ב-DNA כטכנולוגיית מידע דיגיטלית.
הוא גם חבר במכון למדעי הנתונים של מינכן ובמרכז מינכן ללמידת מכונה.
אנחנו כאן בשבילכם - ייעוץ - תכנון - יישום - ניהול פרויקטים
☑️ מומחה בתעשייה, כאן עם מרכז תעשייה משלו Xpert.Digital הכולל מעל 2,500 מאמרים מקצועיים

Konrad Wolfenstein
אשמח לשמש כיועץ האישי שלך.
ניתן ליצור איתי קשר על ידי מילוי טופס יצירת הקשר למטה או פשוט להתקשר אליי למספר 49 7348 4088 965+ .
אני מצפה בקוצר רוח לפרויקט המשותף שלנו.
כתבו לי




אקספרט.דיגיטל - Konrad Wolfenstein
Xpert.Digital הוא מרכז לתעשייה המתמקד בדיגיטציה, הנדסת מכונות, לוגיסטיקה/תוך-לוגיסטיקה ופוטו-וולטאית.
עם פתרון פיתוח עסקי 360° שלנו, אנו תומכים בחברות ידועות, החל מעסקים חדשים ועד לשירותי לאחר המכירה.
מודיעין שוק, שיווק סמיילי, אוטומציה שיווקית, פיתוח תוכן, יחסי ציבור, קמפיינים בדואר, מדיה חברתית מותאמת אישית וטיפוח לידים הם חלק מהכלים הדיגיטליים שלנו.
ניתן למצוא מידע נוסף בכתובות הבאות: www.xpert.digital - www.xpert.solar - www.xpert.plus
שמור על קשר