
IA et SEO avec BERT – Bidirectionnel Encoder Representations from Transformers – modèle dans le domaine du traitement du langage naturel (NLP)

Sélection de voix 📢
Publié le: 4 octobre 2024 / mise à jour du: 4 octobre 2024 - Auteur: Konrad Wolfenstein

IA et SEO avec BERT – Représentations d'encodeurs bidirectionnels à partir de transformateurs – Modèle dans le domaine du traitement du langage naturel (NLP) – Image : Xpert.Digital
🚀💬 Développé par Google : BERT et son importance pour la PNL - Pourquoi la compréhension bidirectionnelle des textes est cruciale
🔍🗣️ BERT, abréviation de Bidirectionnel Encoder Representations from Transformers, est un modèle majeur dans le domaine du traitement du langage naturel (NLP) développé par Google. Cela a révolutionné la façon dont les machines comprennent le langage. Contrairement aux modèles précédents qui analysaient le texte de manière séquentielle de gauche à droite ou vice versa, BERT permet un traitement bidirectionnel. Cela signifie qu'il capture le contexte d'un mot de la séquence de texte précédente et suivante. Cette capacité améliore considérablement la compréhension de contextes linguistiques complexes.
🔍 L'architecture du BERT
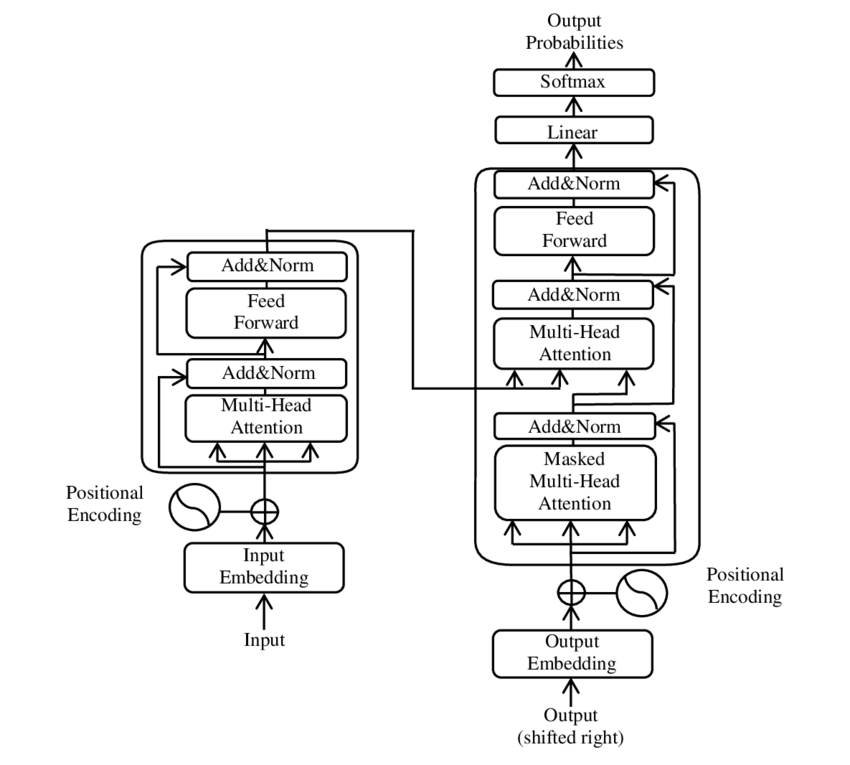
Ces dernières années, l'un des développements les plus importants dans le domaine du traitement du langage naturel (NLP) s'est produit avec l'introduction du modèle Transformer, tel que présenté dans le PDF 2017 - L'attention est tout ce dont vous avez besoin - papier ( Wikipédia ). Ce modèle a fondamentalement changé le domaine en abandonnant les structures précédemment utilisées, comme la traduction automatique. Au lieu de cela, elle repose exclusivement sur des mécanismes d’attention. Depuis lors, la conception du Transformer a constitué la base de nombreux modèles qui représentent l’état de l’art dans divers domaines tels que la génération de langues, la traduction et au-delà.
Une illustration des principaux composants du modèle Transformer – Image : Google
BERT est basé sur cette architecture Transformer. Cette architecture utilise des mécanismes dits d’auto-attention pour analyser les relations entre les mots dans une phrase. L'attention est portée à chaque mot dans le contexte de la phrase entière, ce qui permet une compréhension plus précise des relations syntaxiques et sémantiques.
Les auteurs de l'article «l'attention est tout ce dont vous avez besoin» sont:
- Ashish Vaswani (Google Cerveau)
- Noam Shazeer (Google Brain)
- Niki Parmar (Recherche Google)
- Jakob Uszkoreit (Recherche Google)
- Lion Jones (recherche Google)
- Aidan N. Gomez (Université de Toronto, travail partiellement réalisé chez Google Brain)
- Lukasz Kaiser (Google Brain)
- Illia Polosukhin (indépendant, travaux antérieurs chez Google Research)
Ces auteurs ont contribué de manière significative au développement du modèle Transformer présenté dans cet article.
🔄 Traitement bidirectionnel
Une caractéristique remarquable de BERT est sa capacité de traitement bidirectionnel. Alors que les modèles traditionnels tels que les réseaux de neurones récurrents (RNN) ou les réseaux LSTM (Long Short-Term Memory) ne traitent le texte que dans un sens, BERT analyse le contexte d'un mot dans les deux sens. Cela permet au modèle de mieux capturer les subtiles nuances de sens et donc de faire des prédictions plus précises.
🕵️♂️ Modélisation du langage masqué
Un autre aspect innovant de BERT est la technique du Masked Language Model (MLM). Cela implique de masquer des mots sélectionnés au hasard dans une phrase et d’entraîner le modèle à prédire ces mots en fonction du contexte environnant. Cette méthode oblige BERT à développer une compréhension approfondie du contexte et du sens de chaque mot de la phrase.
🚀 Formation et personnalisation du BERT
BERT passe par un processus de formation en deux étapes : pré-formation et mise au point.
📚 Pré-formation
En pré-formation, BERT est formé avec de grandes quantités de texte pour apprendre les modèles linguistiques généraux. Cela inclut les textes Wikipédia et d’autres corpus de textes étendus. Au cours de cette phase, le modèle apprend les structures et contextes linguistiques de base.
🔧 Mise au point
Après la pré-formation, BERT est personnalisé pour des tâches PNL spécifiques, telles que la classification de texte ou l'analyse des sentiments. Le modèle est entraîné avec des ensembles de données plus petits et liés aux tâches afin d'optimiser ses performances pour des applications spécifiques.
🌍 Domaines d'application du BERT
BERT s'est avéré extrêmement utile dans de nombreux domaines du traitement du langage naturel :
Optimisation des moteurs de recherche
Google utilise BERT pour mieux comprendre les requêtes de recherche et afficher des résultats plus pertinents. Cela améliore considérablement l’expérience utilisateur.
Classement du texte
BERT peut classer les documents par sujet ou analyser l'ambiance des textes.
Reconnaissance d'entité nommée (NER)
Le modèle identifie et classe les entités nommées dans les textes, telles que les noms de personnes, de lieux ou d'organisations.
Systèmes de questions et réponses
BERT est utilisé pour fournir des réponses précises aux questions posées.
🧠 L'importance du BERT pour l'avenir de l'IA
BERT a établi de nouvelles normes pour les modèles PNL et a ouvert la voie à d'autres innovations. Grâce à sa capacité de traitement bidirectionnel et à sa compréhension approfondie du contexte linguistique, il a considérablement augmenté l’efficacité et la précision des applications d’IA.
🔜 Développements futurs
Le développement ultérieur du BERT et de modèles similaires visera probablement à créer des systèmes encore plus puissants. Ceux-ci pourraient gérer des tâches linguistiques plus complexes et être utilisés dans une variété de nouveaux domaines d’application. L’intégration de tels modèles dans les technologies quotidiennes pourrait changer fondamentalement la façon dont nous interagissons avec les ordinateurs.
🌟 Jalon dans le développement de l'intelligence artificielle
BERT constitue une étape importante dans le développement de l’intelligence artificielle et a révolutionné la façon dont les machines traitent le langage naturel. Son architecture bidirectionnelle permet une compréhension plus approfondie des relations linguistiques, ce qui la rend indispensable pour une variété d'applications. À mesure que la recherche progresse, des modèles comme BERT continueront de jouer un rôle central dans l’amélioration des systèmes d’IA et dans l’ouverture de nouvelles possibilités d’utilisation.
📣 Sujets similaires
- 📚 Présentation de BERT : le modèle révolutionnaire de PNL
- 🔍 BERT et le rôle de la bidirectionnalité en PNL
- 🧠 Le modèle Transformer : pierre angulaire de BERT
- 🚀 Modélisation du langage masqué : la clé du succès de BERT
- 📈 Personnalisation du BERT : De la pré-formation à la mise au point
- 🌐 Les domaines d'application du BERT dans la technologie moderne
- 🤖 L'influence du BERT sur l'avenir de l'intelligence artificielle
- 💡 Perspectives d'avenir : nouveaux développements du BERT
- 🏆 BERT comme étape importante dans le développement de l'IA
- 📰 Auteurs de l'article Transformer « L'attention est tout ce dont vous avez besoin » : les esprits derrière BERT
#️⃣ Hashtags : #PNL #Intelligence Artificielle #Modélisation du langage #Transformer #ApprentissageMachine
🎯🎯🎯 Bénéficiez de la quintuple expertise étendue de Xpert.Digital dans une offre de services complète | R&D, XR, RP et SEM

Machine de rendu 3D AI & XR : une expertise quintuplée de Xpert.Digital dans un ensemble complet de services, R&D XR, PR & SEM - Image : Xpert.Digital
Xpert.Digital possède une connaissance approfondie de diverses industries. Cela nous permet de développer des stratégies sur mesure, adaptées précisément aux exigences et aux défis de votre segment de marché spécifique. En analysant continuellement les tendances du marché et en suivant les évolutions du secteur, nous pouvons agir avec clairvoyance et proposer des solutions innovantes. En combinant expérience et connaissances, nous générons de la valeur ajoutée et donnons à nos clients un avantage concurrentiel décisif.
En savoir plus ici :
BERT : Révolutionnaire 🌟 Technologie PNL
🚀 BERT, abréviation de Bidirectionnel Encoder Representations from Transformers, est un modèle de langage avancé développé par Google qui est devenu une avancée significative dans le domaine du traitement du langage naturel (NLP) depuis son lancement en 2018. Il est basé sur l'architecture Transformer, qui a révolutionné la façon dont les machines comprennent et traitent le texte. Mais qu’est-ce qui rend BERT si spécial et à quoi sert-il exactement ? Pour répondre à cette question, nous devons approfondir les principes techniques, les fonctionnalités et les domaines d'application de BERT.
📚 1. Les bases du traitement du langage naturel
Pour bien comprendre la signification de BERT, il est utile de revoir brièvement les bases du traitement du langage naturel (NLP). La PNL traite de l'interaction entre les ordinateurs et le langage humain. L’objectif est d’apprendre aux machines à analyser, comprendre et répondre aux données textuelles. Avant l’introduction de modèles comme BERT, le traitement automatique du langage présentait souvent des défis importants, notamment en raison de l’ambiguïté, de la dépendance au contexte et de la structure complexe du langage humain.
📈 2. Le développement des modèles PNL
Avant l’arrivée de BERT, la plupart des modèles NLP étaient basés sur des architectures dites unidirectionnelles. Cela signifie que ces modèles ne lisent le texte que de gauche à droite ou de droite à gauche, ce qui signifie qu'ils ne peuvent prendre en compte qu'un nombre limité de contexte lors du traitement d'un mot dans une phrase. Cette limitation faisait souvent que les modèles ne capturaient pas pleinement le contexte sémantique complet d'une phrase. Cela rendait difficile l’interprétation précise des mots ambigus ou sensibles au contexte.
Un autre développement important dans la recherche en PNL avant BERT était le modèle word2vec, qui permettait aux ordinateurs de traduire des mots en vecteurs reflétant des similitudes sémantiques. Mais ici aussi, le contexte se limitait à l'environnement immédiat d'un mot. Plus tard, des réseaux de neurones récurrents (RNN) et en particulier des modèles de mémoire à long terme et à court terme (LSTM) ont été développés, ce qui a permis de mieux comprendre les séquences de texte en stockant des informations sur plusieurs mots. Cependant, ces modèles avaient également leurs limites, en particulier lorsqu’il s’agissait de textes longs et de compréhension simultanée du contexte dans les deux sens.
🔄 3. La révolution grâce à l'architecture Transformer
La percée a eu lieu avec l'introduction de l'architecture Transformer en 2017, qui constitue la base de BERT. Les modèles de transformateur sont conçus pour permettre le traitement parallèle du texte, en tenant compte du contexte d'un mot du texte précédent et suivant. Cela se fait grâce à ce que l'on appelle des mécanismes d'auto-attention, qui attribuent une valeur de poids à chaque mot d'une phrase en fonction de son importance par rapport aux autres mots de la phrase.
Contrairement aux approches précédentes, les modèles Transformer ne sont pas unidirectionnels, mais bidirectionnels. Cela signifie qu'ils peuvent extraire des informations du contexte gauche et droit d'un mot, produisant ainsi une représentation plus complète et plus précise du mot et de sa signification.
🧠 4. BERT : Un modèle bidirectionnel
BERT porte les performances de l'architecture Transformer à un nouveau niveau. Le modèle est conçu pour capturer le contexte d’un mot non seulement de gauche à droite ou de droite à gauche, mais simultanément dans les deux sens. Cela permet à BERT de prendre en compte le contexte complet d'un mot dans une phrase, ce qui entraîne une précision considérablement améliorée dans les tâches de traitement linguistique.
Une caractéristique centrale de BERT est l'utilisation de ce que l'on appelle le modèle de langage masqué (MLM). Lors de la formation BERT, les mots sélectionnés au hasard dans une phrase sont remplacés par un masque et le modèle est entraîné à deviner ces mots masqués en fonction du contexte. Cette technique permet à BERT d'apprendre des relations plus profondes et plus précises entre les mots d'une phrase.
De plus, BERT utilise une méthode appelée Next Sentence Prediction (NSP), dans laquelle le modèle apprend à prédire si une phrase en suit une autre ou non. Cela améliore la capacité de BERT à comprendre des textes plus longs et à reconnaître des relations plus complexes entre les phrases.
🌐 5. Application du BERT en pratique
BERT s'est avéré extrêmement utile pour une variété de tâches de PNL. Voici quelques-uns des principaux domaines d’application :
📊 a) Classification du texte
L'une des utilisations les plus courantes de BERT est la classification de textes, où les textes sont divisés en catégories prédéfinies. Des exemples en sont l'analyse des sentiments (par exemple, reconnaître si un texte est positif ou négatif) ou la catégorisation des commentaires des clients. BERT peut fournir des résultats plus précis que les modèles précédents grâce à sa compréhension approfondie du contexte des mots.
❓ b) Systèmes de questions-réponses
BERT est également utilisé dans les systèmes de questions-réponses, où le modèle extrait les réponses aux questions posées à partir d'un texte. Cette capacité est particulièrement importante dans des applications telles que les moteurs de recherche, les chatbots ou les assistants virtuels. Grâce à son architecture bidirectionnelle, BERT peut extraire des informations pertinentes d'un texte, même si la question est formulée indirectement.
🌍 c) Traduction de texte
Bien que BERT lui-même ne soit pas directement conçu comme un modèle de traduction, il peut être utilisé en combinaison avec d'autres technologies pour améliorer la traduction automatique. En comprenant mieux les relations sémantiques dans une phrase, BERT peut aider à générer des traductions plus précises, en particulier pour les formulations ambiguës ou complexes.
🏷️ d) Reconnaissance d'entité nommée (NER)
Un autre domaine d'application est la reconnaissance d'entités nommées (NER), qui consiste à identifier des entités spécifiques telles que des noms, des lieux ou des organisations dans un texte. BERT s'est révélé particulièrement efficace dans cette tâche car il prend pleinement en compte le contexte d'une phrase, ce qui lui permet de mieux reconnaître les entités même si elles ont des significations différentes dans des contextes différents.
✂️ e) Résumé textuel
La capacité de BERT à comprendre l'ensemble du contexte d'un texte en fait également un outil puissant pour la synthèse automatique de texte. Il peut être utilisé pour extraire les informations les plus importantes d’un long texte et créer un résumé concis.
🌟 6. L'importance du BERT pour la recherche et l'industrie
L'introduction de BERT a marqué le début d'une nouvelle ère dans la recherche en PNL. Ce fut l'un des premiers modèles à tirer pleinement parti de la puissance de l'architecture bidirectionnelle du Transformer, plaçant la barre pour de nombreux modèles ultérieurs. De nombreuses entreprises et instituts de recherche ont intégré BERT dans leurs pipelines NLP pour améliorer les performances de leurs applications.
En outre, BERT a ouvert la voie à d’autres innovations dans le domaine des modèles linguistiques. Par exemple, des modèles tels que GPT (Generative Pretrained Transformer) et T5 (Text-to-Text Transfer Transformer) ont été développés par la suite, qui reposent sur des principes similaires mais offrent des améliorations spécifiques pour différents cas d'utilisation.
🚧 7. Défis et limites du BERT
Malgré ses nombreux avantages, BERT présente également certains défis et limites. L’un des plus grands obstacles est l’effort de calcul élevé requis pour former et appliquer le modèle. Le BERT étant un modèle très volumineux comportant des millions de paramètres, il nécessite un matériel puissant et des ressources informatiques importantes, notamment lors du traitement de grandes quantités de données.
Un autre problème est le biais potentiel qui peut exister dans les données de formation. Étant donné que BERT est formé sur de grandes quantités de données textuelles, il reflète parfois les préjugés et les stéréotypes présents dans ces données. Cependant, les chercheurs s’efforcent continuellement d’identifier et de résoudre ces problèmes.
🔍 Outil essentiel pour les applications de traitement du langage moderne
BERT a considérablement amélioré la façon dont les machines comprennent le langage humain. Grâce à son architecture bidirectionnelle et à ses méthodes de formation innovantes, il est capable de capturer de manière approfondie et précise le contexte des mots dans une phrase, ce qui se traduit par une plus grande précision dans de nombreuses tâches de PNL. Qu'il s'agisse de classification de textes, de systèmes de questions-réponses ou de reconnaissance d'entités, BERT s'est imposé comme un outil indispensable pour les applications modernes de traitement du langage.
La recherche sur le traitement du langage naturel continuera sans aucun doute à progresser et BERT a jeté les bases de nombreuses innovations futures. Malgré les défis et les limites existants, BERT montre de manière impressionnante à quel point la technologie a progressé en peu de temps et quelles opportunités passionnantes s'ouvriront encore à l'avenir.
🌀 The Transformer : une révolution dans le traitement du langage naturel
🌟 Ces dernières années, l'un des développements les plus importants dans le domaine du traitement du langage naturel (NLP) a été l'introduction du modèle Transformer, comme décrit dans l'article de 2017 « L'attention est tout ce dont vous avez besoin ». Ce modèle a fondamentalement changé le domaine en abandonnant les structures récurrentes ou convolutionnelles précédemment utilisées pour les tâches de transduction de séquence telles que la traduction automatique. Au lieu de cela, elle repose exclusivement sur des mécanismes d’attention. Depuis lors, la conception du Transformer a constitué la base de nombreux modèles qui représentent l’état de l’art dans divers domaines tels que la génération de langues, la traduction et au-delà.
🔄 Le Transformateur : Un changement de paradigme
Avant l'introduction du Transformer, la plupart des modèles de tâches de séquençage étaient basés sur des réseaux de neurones récurrents (RNN) ou des réseaux de mémoire à long terme (LSTM), qui sont intrinsèquement séquentiels. Ces modèles traitent les données d'entrée étape par étape, créant des états cachés qui se propagent tout au long de la séquence. Bien que cette méthode soit efficace, elle est coûteuse en termes de calcul et difficile à paralléliser, en particulier pour les longues séquences. De plus, les RNN ont du mal à apprendre les dépendances à long terme en raison du problème dit du « gradient de disparition ».
L'innovation centrale du Transformer réside dans l'utilisation de mécanismes d'auto-attention, qui permettent au modèle de pondérer l'importance des différents mots d'une phrase les uns par rapport aux autres, quelle que soit leur position. Cela permet au modèle de capturer les relations entre des mots largement espacés plus efficacement que les RNN ou les LSTM, et de le faire de manière parallèle plutôt que séquentielle. Cela améliore non seulement l’efficacité de la formation, mais également les performances sur des tâches telles que la traduction automatique.
🧩 Architecture du modèle
Le Transformer se compose de deux composants principaux : un encodeur et un décodeur, tous deux constitués de plusieurs couches et s'appuyant fortement sur des mécanismes d'attention multi-têtes.
⚙️ Encodeur
L'encodeur se compose de six couches identiques, chacune avec deux sous-couches :
1. Auto-attention multi-têtes
Ce mécanisme permet au modèle de se concentrer sur différentes parties de la phrase d'entrée lors du traitement de chaque mot. Au lieu de calculer l'attention dans un seul espace, l'attention multi-têtes projette l'entrée dans plusieurs espaces différents, permettant de capturer différents types de relations entre les mots.
2. Réseaux à réaction entièrement connectés en termes de position
Après la couche d'attention, un réseau de rétroaction entièrement connecté est appliqué indépendamment à chaque position. Cela aide le modèle à traiter chaque mot dans son contexte et à utiliser les informations du mécanisme d'attention.
Pour préserver la structure de la séquence d'entrée, le modèle contient également des entrées positionnelles (codages positionnels). Étant donné que le Transformer ne traite pas les mots de manière séquentielle, ces encodages sont cruciaux pour fournir au modèle des informations sur l'ordre des mots dans une phrase. Les entrées de position sont ajoutées aux incorporations de mots afin que le modèle puisse distinguer les différentes positions dans la séquence.
🔍 Décodeurs
Comme l'encodeur, le décodeur se compose également de six couches, chaque couche disposant d'un mécanisme d'attention supplémentaire qui permet au modèle de se concentrer sur les parties pertinentes de la séquence d'entrée tout en générant la sortie. Le décodeur utilise également une technique de masquage pour l'empêcher de prendre en compte les positions futures, préservant ainsi la nature autorégressive de la génération de séquences.
🧠 Attention multi-têtes et attention aux produits ponctuels
Le cœur du Transformer est le mécanisme d’attention multi-têtes, qui est une extension de l’attention plus simple du produit scalaire. La fonction d'attention peut être considérée comme un mappage entre une requête et un ensemble de paires clé-valeur (clés et valeurs), où chaque clé représente un mot dans la séquence et la valeur représente les informations contextuelles associées.
Le mécanisme d’attention multi-têtes permet au modèle de se concentrer simultanément sur différentes parties de la séquence. En projetant l'entrée dans plusieurs sous-espaces, le modèle peut capturer un ensemble plus riche de relations entre les mots. Ceci est particulièrement utile dans des tâches telles que la traduction automatique, où la compréhension du contexte d'un mot nécessite de nombreux facteurs différents, tels que la structure syntaxique et la signification sémantique.
La formule pour l'attention aux produits scalaires est la suivante :

Ici (Q) est la matrice de requête, (K) est la matrice clé et (V) est la matrice de valeurs. Le terme (sqrt{d_k}) est un facteur d'échelle qui empêche les produits scalaires de devenir trop grands, ce qui entraînerait de très petits gradients et un apprentissage plus lent. La fonction softmax est appliquée pour garantir que les poids d'attention totalisent un.
🚀 Avantages du Transformateur
Le Transformer offre plusieurs avantages clés par rapport aux modèles traditionnels tels que les RNN et les LSTM :
1. Parallélisation
Étant donné que le Transformer traite tous les jetons d'une séquence en même temps, il peut être hautement parallélisé et est donc beaucoup plus rapide à entraîner que les RNN ou les LSTM, en particulier sur de grands ensembles de données.
2. Dépendances à long terme
Le mécanisme d’auto-attention permet au modèle de capturer les relations entre mots distants plus efficacement que les RNN, qui sont limités par la nature séquentielle de leurs calculs.
3. Évolutivité
Le Transformer peut facilement s'adapter à de très grands ensembles de données et à des séquences plus longues sans souffrir des goulots d'étranglement de performances associés aux RNN.
🌍 Applications et effets
Depuis son introduction, le Transformer est devenu la base d'une large gamme de modèles PNL. L'un des exemples les plus notables est BERT (Bidirectionnel Encoder Representations from Transformers), qui utilise une architecture Transformer modifiée pour atteindre l'état de l'art dans de nombreuses tâches NLP, y compris la réponse aux questions et la classification de texte.
Un autre développement important est GPT (Generative Pretrained Transformer), qui utilise une version limitée par décodeur du Transformer pour la génération de texte. Les modèles GPT, y compris GPT-3, sont désormais utilisés pour diverses applications, de la création de contenu à la complétion de code.
🔍 Un modèle puissant et flexible
Le Transformer a fondamentalement changé la façon dont nous abordons les tâches de PNL. Il fournit un modèle puissant et flexible qui peut être appliqué à une variété de problèmes. Sa capacité à gérer les dépendances à long terme et l’efficacité de la formation en ont fait l’approche architecturale préférée pour bon nombre des modèles les plus modernes. À mesure que la recherche progresse, nous verrons probablement d’autres améliorations et ajustements du Transformer, en particulier dans des domaines tels que le traitement de l’image et du langage, où les mécanismes d’attention donnent des résultats prometteurs.
Nous sommes là pour vous - conseil - planification - mise en œuvre - gestion de projet
☑️ Expert du secteur, ici avec son propre hub industriel Xpert.Digital avec plus de 2 500 articles spécialisés

Konrad Wolfenstein
Je serais heureux de vous servir de conseiller personnel.
Vous pouvez me contacter en remplissant le formulaire de contact ci-dessous ou simplement m'appeler au +49 89 89 674 804 (Munich) .
J'attends avec impatience notre projet commun.
Écris moi

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital est une plateforme industrielle axée sur la numérisation, la construction mécanique, la logistique/intralogistique et le photovoltaïque.
Avec notre solution de développement commercial à 360°, nous accompagnons des entreprises de renom depuis les nouvelles affaires jusqu'à l'après-vente.
L'intelligence de marché, le smarketing, l'automatisation du marketing, le développement de contenu, les relations publiques, les campagnes de courrier électronique, les médias sociaux personnalisés et le lead nurturing font partie de nos outils numériques.
Vous pouvez en savoir plus sur : www.xpert.digital - www.xpert.solar - www.xpert.plus
Rester en contact




















