
Données structurées (balisage) à l'ère de l'IA avec Schema.org : ce que pensent vraiment les ingénieurs de Google
Xpert Pré-lancement

Available in 27 languages 📢
Préférez Xpert.Digital sur GoogleⓘPublié le : 7 mai 2026 / Mis à jour le : 7 mai 2026 – Auteur : Konrad Wolfenstein
Données structurées (balisage) à l'ère de l'IA avec Schema.org : ce que pensent vraiment les ingénieurs de Google – Image : Xpert.Digital
Le secret SEO de Google : pourquoi l’IA échoue sans données structurées
Malgré ChatGPT et consorts : pourquoi les ingénieurs de Google continuent de ne jurer que par Schema.org
Mise à jour SEO : Pourquoi Schema.org remplace désormais Open Graph sur Google
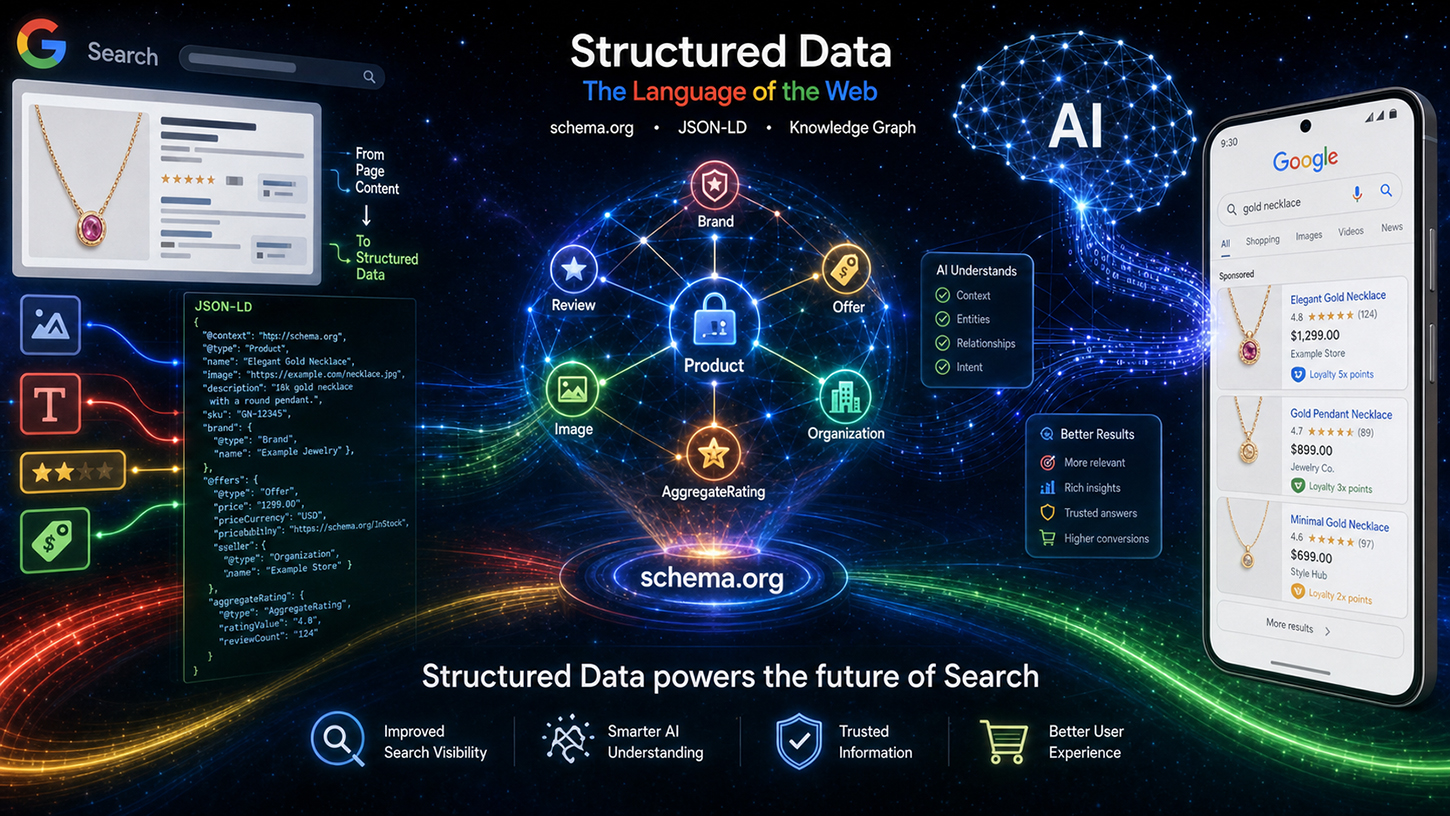
Un mythe tenace circule dans le monde du SEO : à l’ère des brillants modèles de langage d’IA capables de comprendre sans effort même les textes non structurés, les données structurées, rigoureusement maintenues, comme Schema.org, seraient tout simplement devenues obsolètes. Or, la réalité est tout autre. Lors de l’événement Google Search Central Live, l’ingénieur Google Ryan Levering a démystifié cette idée reçue et a été on ne peut plus clair : le balisage structuré n’est pas une relique du passé, mais bien la pierre angulaire de la nouvelle recherche basée sur l’IA.
Des nouvelles présentations de l'IA aux assistants d'achat autonomes, les modèles de langage ont besoin de directives précises et lisibles par machine pour éviter les erreurs et fonctionner efficacement. Ceux qui souhaitent rester visibles sur le web moderne doivent aider les machines à comprendre le contexte sans ambiguïté. Cet article examine le réalignement stratégique de Google, présente des innovations révolutionnaires pour le commerce électronique et le contenu généré par les utilisateurs, et démontre pourquoi le référencement technique est désormais un avantage concurrentiel décisif dans la course à la visibilité machine.
Les machines peuvent lire le web – mais seulement si vous les aidez à le comprendre
Le 21 avril 2026, le premier événement Google Search Central Live organisé au Canada s'est tenu à Toronto – et il ne s'agissait pas d'une simple réunion sectorielle. Ryan Levering, ingénieur chez Google Search Engineering, a présenté ce qui était sans doute la présentation la plus dense techniquement et la plus stratégiquement importante de la journée : « Données structurées, qualité et IA ». Son intervention dépassait le simple exposé technique. Il s'agissait d'une vision claire de l'avenir du Web sémantique à l'ère où l'intelligence artificielle joue un rôle de plus en plus déterminant d'intermédiaire entre les utilisateurs et l'information.
Entre deux extrêmes : le mauvais dilemme
Au début de sa présentation, Ryan Levering a opposé deux opinions diamétralement opposées qui circulent dans la communauté SEO. D'un côté, certains sont convaincus que les données structurées sont tout simplement superflues à l'ère des puissants modèles de langage : si les modèles d'IA peuvent facilement interpréter du texte non structuré, pourquoi s'embêter à ajouter laborieusement le balisage schema.org au code source ? De l'autre côté, certains fervents défenseurs de l'idée que les données structurées représentent l'avenir d'Internet – un protocole de communication sémantique universel entre agents d'IA autonomes qui remplacera en grande partie le Web traditionnel.
Levering a rejeté les deux extrêmes et a présenté une perspective nuancée et fondée sur des données empiriques. Les deux positions contenaient une part de vérité, a-t-il conclu, mais aucune ne décrivait pleinement la réalité. Cette nuance caractérise l'approche actuelle de Google sur le sujet : il ne s'agit pas de dogmatisme, mais d'efficacité pragmatique.
Quatre arguments qui expliquent tout
L'argument principal de Levering se résume en quatre points clés, qu'il a développés sous le titre « Valeur des données structurées ». Le premier point concerne la précision : les données structurées offrent une précision nettement supérieure pour les schémas complexes, tels que les prix de vente ou les programmes de fidélité, par rapport à l'extraction de données à partir de texte libre basée sur les modèles de langage. Ces modèles peuvent induire en erreur : ils peuvent compléter des attributs manquants, imbriquer incorrectement les données ou accéder à des informations hors contexte. Lors de l'extraction des prix de produits sur un grand site de commerce électronique proposant des dizaines d'articles similaires, le taux d'erreur est considérablement plus élevé avec l'inférence par IA qu'avec un balisage structuré correctement implémenté.
Le deuxième point concerne le contenu additionnel : les données structurées contiennent souvent des métadonnées invisibles, absentes du code HTML rendu. Formats de date ISO complets, identifiants stables pour le contenu généré par l’utilisateur ou identifiants d’entités internes : ces informations se trouvent exclusivement dans le balisage. Aucun modèle de langage ne peut extraire ce qui n’est pas dans le texte.
Troisièmement, l'efficacité : l'analyse syntaxique du balisage structuré est bien moins coûteuse que le traitement d'un modèle de langage complexe pour extraire des données complexes. Google indexe des milliards de pages par jour. Le calcul est simple : un analyseur syntaxique classique traitant du JSON-LD consomme une fraction des ressources de calcul nécessaires à une étape d'inférence d'un modèle de langage. Les données structurées sont donc non seulement supérieures sémantiquement, mais aussi nettement plus efficaces d'un point de vue commercial. Ce point est directement pertinent pour l'infrastructure de Google.
Le quatrième aspect, et peut-être le plus sous-estimé, est la focalisation : les données structurées mettent explicitement en évidence les informations pertinentes sur une page, empêchant ainsi les systèmes d’IA d’interpréter des données non pertinentes. Sur une page produit comportant un article principal, plusieurs produits associés et une barre de navigation affichant les prix, un modèle de langage sans annotation explicite ne peut déterminer avec certitude à quel prix se référer. Le balisage structuré résout ce problème grâce à une attribution univoque.
Comment les données structurées sont-elles réellement traitées ?
Levering a également rendu transparent le flux de traitement technique. Les données Schema.org sont d'abord nettoyées et filtrées avant d'être catégorisées comme données indexées, réparties en catégories telles que les événements, les achats et les avis. Ces données préparées sont ensuite diffusées via deux canaux : d'une part, la page de résultats de recherche classique (SRP) et, d'autre part, comme contexte pour les systèmes d'IA de Google, notamment les présentations IA (AIO) et le mode IA (AIM). Les données structurées ne servent donc plus seulement à enrichir les résultats, mais constituent une entrée directe pour les réponses génératives de l'IA. Cela représente un changement fondamental dans l'importance stratégique du balisage schema.org.
🎯🎯🎯 Plateforme B2B axée sur les données, une solution quasi interne

La solution quasi-interne : comment Xpert.Digital comble les lacunes opérationnelles du marketing et des ventes B2B – Entreprise axée sur le contenu intelligent – Image : Xpert.Digital
Xpert.Digital est une plateforme B2B axée sur les données, dirigée par Konrad Wolfenstein . L'entreprise propose aux partenaires industriels une solution externe quasi intégrée, comblant leurs lacunes opérationnelles en matière de marketing, de contenu et de ventes, sans nécessiter de ressources supplémentaires de leur côté.
Plus d'informations ici :
Pourquoi les données structurées deviennent l'infrastructure des agents d'IA
Focus sur le shopping : livraison, fidélité et variations
Une part importante de la présentation était consacrée aux innovations en matière de commerce électronique. Levering a expliqué que, selon les données du Baymard Institute, les informations de livraison inattendues figurent parmi les deuxième et troisième raisons les plus fréquentes d'abandon de panier. Le balisage structuré pour les services de livraison permet de résoudre directement ce problème : les marchands peuvent désormais définir précisément les régions d'origine et de destination, les dimensions et les poids, les seuils de valeur de commande, les délais de traitement et les affiliations aux programmes de fidélité directement dans le code.
Le modèle de délai de livraison utilisé par Google se divise en deux phases : le délai de traitement, c’est-à-dire le temps écoulé entre la réception de la commande et sa remise au transporteur, et le délai de livraison proprement dit. Ces deux phases peuvent être annotées séparément et avec une grande précision, jusqu’aux heures limites de commande et à la prise en charge des jours ouvrables. Les exemples JSON-LD correspondants montrent comment le type `ShippingConditions` peut être utilisé pour définir la livraison gratuite dans certains pays (par exemple, la France et l’Allemagne) et les montants minimums de commande (par exemple, 50 €).
L'intégration des services de livraison aux programmes de fidélité est particulièrement innovante. Grâce à la propriété `validForMemberTier`, un service de livraison peut être explicitement associé à un programme de fidélité et à un niveau spécifique. Il est ainsi possible de déclarer les avantages de livraison pour les membres premium directement dans le code HTML – une fonctionnalité auparavant configurable uniquement via Google Merchant Center. Le programme de fidélité associé est défini comme un objet `MemberProgram` au sein de l'entité `Organization`, avec des niveaux tels que « Or » ou « Argent » et des avantages associés comme des récompenses de fidélité ou des points.
Les programmes de fidélité en tant qu'entités sémantiques
L'introduction du balisage des programmes de fidélité est économiquement significative. Les entreprises peuvent définir plusieurs programmes d'adhésion indépendants, chacun avec différents niveaux et avantages : points, prix réservés aux membres, politiques de retour, bonus de livraison. Ces informations apparaissent ensuite directement dans les résultats de recherche Google, comme l'a démontré Levering avec des exemples concrets, notamment une offre Sephora affichant une réduction de 30 % pour les membres directement dans l'extrait de produit. La prochaine étape prévue, selon Levering, est le lien inter-pages par identifiant (la possibilité de créer des liens vers les définitions des programmes de fidélité depuis d'autres pages). Ce projet, intitulé pour l'instant « Ouvrir la voie au lien inter-pages par identifiant », vise à renforcer les références organisationnelles entre les pages produits et les politiques de l'entreprise.
Contenu généré par les utilisateurs : le problème de l’étiquetage par l’IA
Un autre sujet important concernait le développement des types de schémas pour le contenu généré par les utilisateurs (CGU). Deux nouvelles fonctionnalités sont particulièrement pertinentes à cet égard. Premièrement, les messages et les republications intégrés sont pris en charge dans le balisage des forums et des questions-réponses, ce qui permet une représentation sémantique plus précise des structures de discussion. Deuxièmement, et c'est là un point stratégique encore plus important, la propriété `so#digitalSourceType` est introduite pour identifier explicitement le contenu généré automatiquement.
Cette évolution répond directement à l'afflux de contenus générés par l'IA sur des plateformes comme les forums et les sites de questions-réponses. Les webmasters peuvent désormais indiquer si une publication a été générée par un algorithme ou par un modèle de langage. Ceux qui ne le précisent pas sont implicitement considérés par Google comme des auteurs humains – une règle qui encourage un étiquetage transparent. La propriété `digitalSourceType` est basée sur les codes IPTC des sources numériques et distingue, entre autres, les contenus générés par algorithme de ceux générés par modèle.
Sélection d'images : Schema surpasse Open Graph
Une mise à jour moins médiatisée, mais néanmoins efficace, concerne la logique de sélection des images de Google. Le système est désormais consolidé en interne, avec une hiérarchie de priorités claire : le balisage Schema.org, et plus précisément les propriétés `primaryImageOfPage` et `mainEntity → image`, est prioritaire. Ce n'est qu'ensuite que la balise méta `og:image` d'Open Graph intervient. Concrètement, pour les gestionnaires de sites web, une implémentation Schema.org correcte de l'image principale influe directement sur son affichage dans les résultats de recherche Google et les aperçus IA – un avantage tangible et mesurable.
Schema.org reçoit elle-même des investissements
Il convient également de souligner le réinvestissement annoncé par Google dans schema.org en tant que spécification ouverte. Trois mesures concrètes ont été mentionnées : la publication de statistiques sur la fréquence d'utilisation des différents termes du schéma (les données de prévalence, comme le montre une diapositive, sont déjà disponibles pour des termes tels que `digitalSourceType`, avec des informations sur environ 10 000 domaines), la publication des règles de validation de Google dans des formats standards lisibles par machine tels que SHACL ou ShEx, et une meilleure prise en charge des règles d'ordre. Ceci est important car cela permettrait aux développeurs externes de créer leurs propres outils de validation basés sur les standards de Google, indépendamment des outils de test officiels, qui peuvent parfois planter en cas de forte charge.
Validation : Deux outils, un objectif
Levering a présenté deux outils de validation complémentaires, mais appliquant des critères de test différents. L'outil de test des résultats enrichis (Rich Result Test Tool) disponible à l'adresse `search.google.com/test/rich-results` accepte les URL ou le JSON pur et vérifie si le balisage est adapté aux résultats enrichis de la recherche Google. Il se base donc sur les exigences spécifiques de Google, et non sur la norme schema.org elle-même. L'outil `validator.schema.org`, quant à lui, vérifie si le balisage est conforme à schema.org, c'est-à-dire s'il respecte le vocabulaire ouvert, que Google génère ou non des résultats enrichis à partir de celui-ci. Il en résulte une recommandation claire pour les développeurs web : il est conseillé d'utiliser les deux outils, car un balisage peut être conforme à schema.org sans pour autant être compatible avec les résultats enrichis, et inversement.
Vue d'ensemble : Les données structurées comme infrastructure de l'IA
L'événement de Toronto, dans son ensemble, révèle une évolution majeure qui dépasse largement le cadre du référencement naturel traditionnel. Les données structurées, initialement conçues pour générer des extraits enrichis, deviennent une norme fondamentale pour les systèmes d'IA. Les aperçus et le mode IA de Google utilisent activement le balisage schema.org comme contexte pour la génération de réponses et la vérification des entités. Les entreprises qui mettent en œuvre des données structurées correctes, complètes et précises améliorent non seulement leurs chances d'obtenir une meilleure visibilité dans les résultats de recherche, mais positionnent également leur contenu comme une source primaire fiable pour les réponses de l'IA.
L'évocation du protocole UCP (Universal Commerce Protocol) et de WebMCP dans ce contexte n'est pas fortuite. Ces deux normes de communication basées sur des agents, dont Google a publié des versions préliminaires en 2026, exigent une description sémantique des sites web. Schema.org en constitue le fondement. Dans un monde où les agents d'IA agissent de manière autonome sur le web, effectuant des recherches, des comparaisons et initiant des transactions, la lisibilité automatique du contenu n'est plus une option, mais une condition essentielle à sa pertinence économique. La présentation de Ryan Levering à Toronto n'était donc pas un simple compte rendu technique ; elle offrait un aperçu de l'infrastructure du web de demain.
Vous pouvez le découvrir par vous-même en 10 secondes
Si vous souhaitez savoir dans quelle mesure votre site web ou un autre utilise efficacement et de manière exhaustive les données structurées, vous pouvez utiliser précisément les deux outils recommandés par Ryan Levering de Google (mentionnés dans notre texte ci-dessus) :
Test des résultats enrichis Google (axé sur la visibilité Google) :
Rendez-vous sur search.google.com/test/rich-results, copiez l'URL d'un article xpert.digital et cliquez sur « Tester l'URL ». L'outil vous indiquera précisément le balisage que Google reconnaît sur cette page et s'il est exempt d'erreurs.
Validateur de schéma (axé sur la conformité aux normes pures) :
Rendez-vous sur validator.schema.orget collez la même URL. Vous pourrez alors voir directement dans le code source, mis en évidence par une couleur, les scripts JSON-LD (données structurées) intégrés par xpert.digital.
Votre partenaire mondial en marketing et développement commercial
☑️ Notre langue de travail est l'anglais ou l'allemand
☑️ NOUVEAU : Correspondance dans votre langue maternelle !

Konrad Wolfenstein
Mon équipe et moi-même sommes heureux de pouvoir vous accompagner en tant que conseiller personnel.
Vous pouvez me contacter en remplissant le formulaire de contact ici simplement m'appeler au +49 7348 4088 965. Mon adresse e-mail est [email protected]:ou
J'attends avec impatience notre projet commun.
☑️ Accompagnement des PME en matière de stratégie, de conseil, de planification et de mise en œuvre
☑️ Création ou réalignement de la stratégie numérique et de la numérisation
☑️ Expansion et optimisation des processus de vente internationaux
☑️ Plateformes de commerce B2B mondiales et numériques
☑️ Développement commercial pionnier / Marketing / Relations publiques / Salons professionnels
Assistance B2B et SaaS pour le référencement naturel et la géolocalisation (recherche IA) combinés : la solution tout-en-un pour les entreprises B2B

Assistance B2B et SaaS pour le référencement naturel et la géolocalisation (recherche IA) : la solution tout-en-un pour les entreprises B2B - Image : Xpert.Digital
La recherche par IA change tout : comment cette solution SaaS va révolutionner à jamais votre référencement B2B.
Le paysage numérique des entreprises B2B évolue à une vitesse fulgurante. Sous l'impulsion de l'intelligence artificielle, les règles de la visibilité en ligne sont redéfinies. Pour les entreprises, le défi a toujours été non seulement d'être visibles parmi la masse numérique, mais aussi d'atteindre les décideurs clés. Les stratégies de référencement traditionnelles et la gestion de la présence locale (géomarketing) sont complexes, chronophages et souvent synonymes de lutte acharnée contre des algorithmes en constante évolution et une concurrence féroce.
Et si une solution permettait non seulement de simplifier ce processus, mais aussi de le rendre plus intelligent, plus prédictif et bien plus efficace ? C’est là qu’intervient l’association d’un accompagnement B2B spécialisé et d’une plateforme SaaS (Software as a Service) performante, conçue spécifiquement pour répondre aux exigences du référencement naturel et du géoréférencement à l’ère de la recherche par IA.
Cette nouvelle génération d'outils ne repose plus uniquement sur l'analyse manuelle des mots-clés et les stratégies de backlinks. Elle exploite désormais l'intelligence artificielle pour mieux comprendre l'intention de recherche, optimiser automatiquement les facteurs de référencement local et réaliser une analyse concurrentielle en temps réel. Il en résulte une stratégie proactive et axée sur les données qui confère aux entreprises B2B un avantage décisif : elles sont non seulement visibles, mais aussi perçues comme la référence dans leur secteur et leur zone géographique.
Voici la symbiose entre le support B2B et la technologie SaaS basée sur l'IA qui transforme le référencement naturel et le marketing géolocalisé, et comment votre entreprise peut en bénéficier pour croître durablement dans l'espace numérique.
Plus d'informations ici :

















