
Une tentative d’explication de l’IA : Comment fonctionne l’intelligence artificielle – comment est-elle formée ?

Available in 27 languages 📢
Préférez Xpert.Digital sur GoogleⓘPublié le: 8 septembre 2024 / mise à jour de: 9 septembre 2024 - Auteur: Konrad Wolfenstein

Une tentative d’explication de l’IA : Comment fonctionne l’intelligence artificielle et comment est-elle formée ? – Image : Xpert.Digital
📊 De la saisie des données à la prédiction du modèle : le processus de l'IA
Comment fonctionne l’intelligence artificielle (IA) ? 🤖
Le fonctionnement de l’intelligence artificielle (IA) peut être divisé en plusieurs étapes clairement définies. Chacune de ces étapes est essentielle au résultat final fourni par l’IA. Le processus commence par la saisie des données et se termine par la prédiction du modèle et un éventuel retour d'information ou des cycles de formation supplémentaires. Ces phases décrivent le processus par lequel passent presque tous les modèles d’IA, qu’il s’agisse de simples ensembles de règles ou de réseaux neuronaux très complexes.
1. La saisie des données 📊
La base de toute intelligence artificielle réside dans les données avec lesquelles elle travaille. Ces données peuvent se présenter sous diverses formes, par exemple des images, du texte, des fichiers audio ou des vidéos. L'IA utilise ces données brutes pour reconnaître des modèles et prendre des décisions. La qualité et la quantité des données jouent ici un rôle central, car elles ont une influence significative sur le fonctionnement ultérieur du modèle.
Plus les données sont complètes et précises, mieux l’IA peut apprendre. Par exemple, lorsqu’une IA est entraînée au traitement d’images, elle a besoin d’une grande quantité de données d’image pour identifier correctement différents objets. Avec les modèles linguistiques, ce sont les données textuelles qui aident l’IA à comprendre et à générer le langage humain. La saisie des données est la première et l’une des étapes les plus importantes, car la qualité des prévisions ne peut être aussi bonne que celle des données sous-jacentes. Un principe célèbre en informatique décrit cela par l’adage « Garbage in, garbage out » : de mauvaises données conduisent à de mauvais résultats.
2. Prétraitement des données 🧹
Une fois les données saisies, elles doivent être préparées avant de pouvoir être intégrées au modèle lui-même. Ce processus est appelé prétraitement des données. L’objectif ici est de mettre les données sous une forme qui puisse être traitée de manière optimale par le modèle.
Une étape courante du prétraitement est la normalisation des données. Cela signifie que les données sont placées dans une plage de valeurs uniforme afin que le modèle les traite de manière uniforme. Un exemple serait de mettre à l'échelle toutes les valeurs de pixels d'une image dans une plage de 0 à 1 au lieu de 0 à 255.
Une autre partie importante du prétraitement est ce que l’on appelle l’extraction de caractéristiques. Certaines fonctionnalités sont extraites des données brutes qui sont particulièrement pertinentes pour le modèle. Dans le traitement d'images, par exemple, il peut s'agir de bords ou de certains motifs de couleurs, tandis que dans les textes, des mots-clés ou des structures de phrases pertinents sont extraits. Le prétraitement est crucial pour rendre le processus d’apprentissage de l’IA plus efficace et plus précis.
3. Le modèle 🧩
Le modèle est le cœur de toute intelligence artificielle. Ici, les données sont analysées et traitées sur la base d'algorithmes et de calculs mathématiques. Un modèle peut exister sous différentes formes. L’un des modèles les plus connus est le réseau neuronal, basé sur le fonctionnement du cerveau humain.
Les réseaux de neurones sont constitués de plusieurs couches de neurones artificiels qui traitent et transmettent les informations. Chaque couche prend les sorties de la couche précédente et les traite davantage. Le processus d'apprentissage d'un réseau de neurones consiste à ajuster les poids des connexions entre ces neurones afin que le réseau puisse faire des prédictions ou des classifications de plus en plus précises. Cette adaptation se produit grâce à la formation, dans laquelle le réseau accède à de grandes quantités d'échantillons de données et améliore de manière itérative ses paramètres internes (poids).
Outre les réseaux de neurones, de nombreux autres algorithmes sont également utilisés dans les modèles d’IA. Ceux-ci incluent des arbres de décision, des forêts aléatoires, des machines à vecteurs de support et bien d'autres. L'algorithme utilisé dépend de la tâche spécifique et des données disponibles.
4. La prédiction du modèle 🔍
Une fois entraîné avec les données, le modèle est capable de faire des prédictions. Cette étape est appelée prédiction du modèle. L'IA reçoit une entrée et renvoie une sortie, c'est-à-dire une prédiction ou une décision, basée sur les modèles qu'elle a appris jusqu'à présent.
Cette prédiction peut prendre différentes formes. Par exemple, dans un modèle de classification d’images, l’IA pourrait prédire quel objet est visible dans une image. Dans un modèle de langage, il pourrait prédire quel mot viendra ensuite dans une phrase. Dans les prévisions financières, l’IA pourrait prédire l’évolution du marché boursier.
Il est important de souligner que l’exactitude des prédictions dépend fortement de la qualité des données d’entraînement et de l’architecture du modèle. Un modèle formé sur des données insuffisantes ou biaisées est susceptible de faire des prédictions incorrectes.
5. Commentaires et formation (facultatif) ♻️
Une autre partie importante du travail d’une IA est le mécanisme de rétroaction. Le modèle est régulièrement vérifié et optimisé. Ce processus se produit soit pendant la formation, soit après la prédiction du modèle.
Si le modèle fait des prédictions incorrectes, il peut apprendre grâce au feedback à détecter ces erreurs et ajuster ses paramètres internes en conséquence. Cela se fait en comparant les prédictions du modèle avec les résultats réels (par exemple avec des données connues pour lesquelles les réponses correctes existent déjà). Une procédure typique dans ce contexte est ce qu'on appelle l'apprentissage supervisé, dans lequel l'IA apprend à partir de données d'exemple déjà fournies avec les bonnes réponses.
Une méthode courante de rétroaction est l’algorithme de rétropropagation utilisé dans les réseaux de neurones. Les erreurs commises par le modèle sont propagées vers l’arrière à travers le réseau pour ajuster le poids des connexions neuronales. Le modèle apprend de ses erreurs et devient de plus en plus précis dans ses prédictions.
Le rôle de la formation 🏋️♂️
Entraîner une IA est un processus itératif. Plus le modèle voit de données et plus il est entraîné souvent sur la base de ces données, plus ses prédictions deviennent précises. Cependant, il y a aussi des limites : un modèle trop entraîné peut avoir des problèmes dits de « surajustement ». Cela signifie qu'il mémorise si bien les données d'entraînement qu'il produit de moins bons résultats sur des données nouvelles et inconnues. Il est donc important d’entraîner le modèle pour qu’il généralise et fasse de bonnes prédictions même sur de nouvelles données.
En plus de la formation régulière, il existe également des procédures telles que l'apprentissage par transfert. Ici, un modèle déjà formé sur une grande quantité de données est utilisé pour une nouvelle tâche similaire. Cela permet d'économiser du temps et de la puissance de calcul car le modèle n'a pas besoin d'être formé à partir de zéro.
Tirez le meilleur parti de vos atouts 🚀
Le travail d’une intelligence artificielle repose sur une interaction complexe de différentes étapes. De la saisie des données au prétraitement, en passant par la formation du modèle, la prédiction et le feedback, de nombreux facteurs influencent la précision et l’efficacité de l’IA. Une IA bien entraînée peut apporter d’énormes avantages dans de nombreux domaines de la vie, de l’automatisation de tâches simples à la résolution de problèmes complexes. Mais il est tout aussi important de comprendre les limites et les pièges potentiels de l’IA afin de tirer le meilleur parti de ses atouts.
🤖📚 Expliqué simplement : Comment est formée une IA ?
🤖📊 Processus d'apprentissage de l'IA : capturer, lier et enregistrer
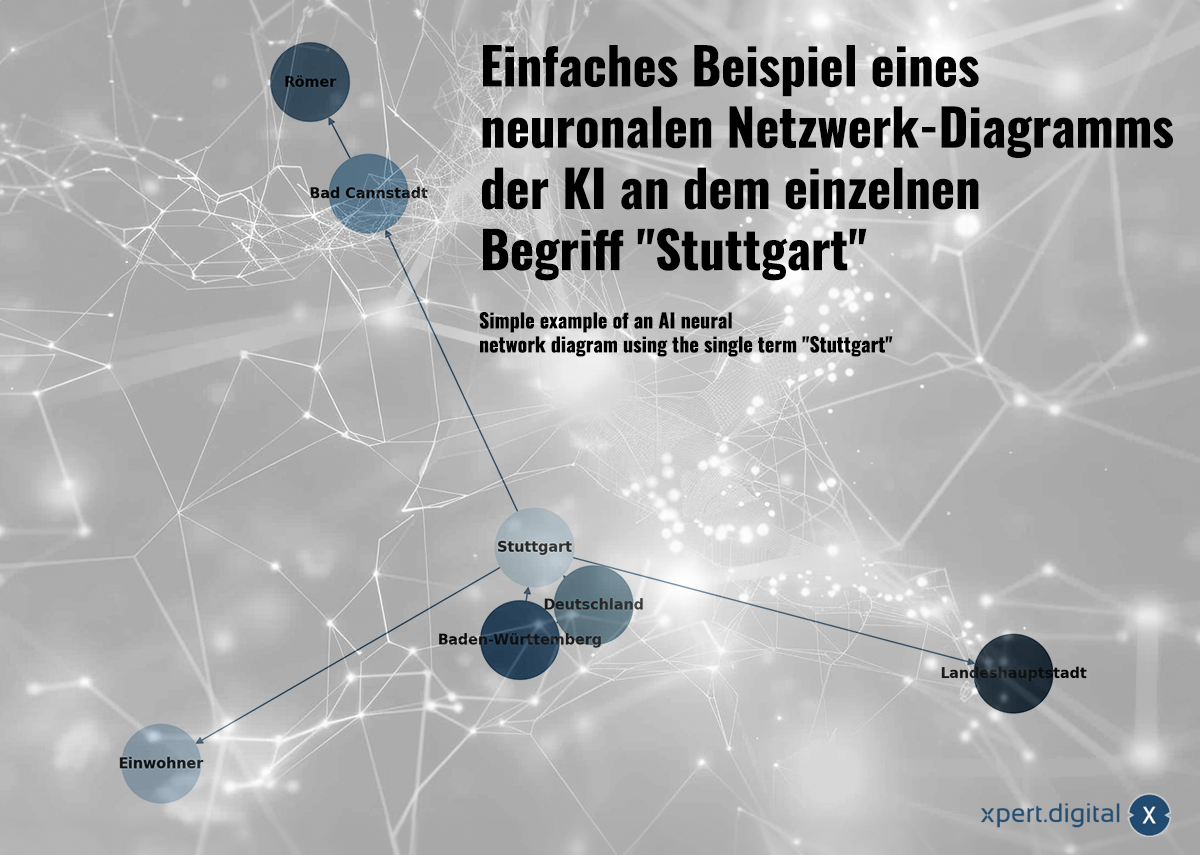
Exemple simple d'un diagramme de réseau neuronal de l'IA sur le terme individuel «Stuttgart» -image: xpert.digital
🌟 Collecter et préparer les données
La première étape du processus d’apprentissage de l’IA consiste à collecter et à préparer les données. Ces données peuvent provenir de diverses sources, comme des bases de données, des capteurs, des textes ou des images.
🌟 Données relatives (réseau neuronal)
Les données collectées sont liées les unes aux autres dans un réseau neuronal. Chaque ensemble de données est montré par des connexions dans un réseau de «neurones» (nœud). Un exemple simple avec la ville de Stuttgart pourrait ressembler à ceci:
a) Stuttgart est une ville du Bade-Wurtemberg
b) Le Bade-Wurtemberg est un État fédéral allemand
c) Stuttgart est une ville d'Allemagne
d) Stuttgart compte 633 484 habitants en 2023
e) Bad Cannstatt est un district de Stuttgart
f) Bad Cannstatt a été fondée par les Romains
g) Stuttgart est la capitale du Bade-Wurtemberg
En fonction de la taille du volume de données, les paramètres des dépenses potentielles sont créés à l'aide du modèle d'IA utilisé. A titre d'exemple : GPT-3 possède environ 175 milliards de paramètres !
🌟 Stockage et personnalisation (apprentissage)
Les données sont transmises au réseau neuronal. Ils passent par le modèle IA et sont traités via des connexions (semblables aux synapses). Les poids (paramètres) entre les neurones sont ajustés pour entraîner le modèle ou effectuer une tâche.
Contrairement aux formulaires de mémoire conventionnels tels que l'accès direct, un accès indiqué, un stockage séquentiel ou de pile, les réseaux de neurones stockent les données de manière non conventionnelle. Les «données» sont stockées dans les poids et les biais des connexions entre les neurones.
Le «stockage» réel des informations dans un réseau neuronal a lieu en adaptant les poids de connexion entre les neurones. Le modèle d'IA «apprend» en adaptant constamment ces poids et biais en fonction des données d'entrée et d'un algorithme d'apprentissage défini. Il s'agit d'un processus continu dans lequel le modèle peut faire des prédictions précises en raison des ajustements récurrents.
Le modèle d'IA peut être considéré comme un type de programmation car il est créé grâce à des algorithmes définis et des calculs mathématiques et améliore continuellement l'ajustement de ses paramètres (poids) pour faire des prédictions précises. Il s’agit d’un processus continu.
Les biais sont des paramètres supplémentaires dans les réseaux de neurones qui s'ajoutent aux valeurs d'entrée pondérées d'un neurone. Ils permettent de pondérer les paramètres (importants, moins importants, importants, etc.), rendant l'IA plus flexible et précise.
Les réseaux de neurones peuvent non seulement stocker des faits individuels, mais également reconnaître les connexions entre les données grâce à la reconnaissance de formes. L'exemple de Stuttgart illustre comment des connaissances peuvent être introduites dans un réseau de neurones, mais les réseaux de neurones n'apprennent pas par des connaissances explicites (comme dans cet exemple simple) mais par l'analyse de modèles de données. Les réseaux de neurones peuvent non seulement stocker des faits individuels, mais également apprendre les poids et les relations entre les données d'entrée.
Ce flux fournit une introduction compréhensible au fonctionnement de l’IA et des réseaux de neurones en particulier, sans plonger trop profondément dans les détails techniques. Il montre que le stockage des informations dans les réseaux de neurones ne se fait pas comme dans les bases de données traditionnelles, mais en ajustant les connexions (poids) au sein du réseau.
🤖📚 Plus détaillé : Comment est formée une IA ?
🏋️♂️ La formation d'une IA, notamment d'un modèle de machine learning, se déroule en plusieurs étapes. La formation d'une IA est basée sur l'optimisation continue des paramètres du modèle via des commentaires et des ajustements jusqu'à ce que le modèle affiche les meilleures performances sur les données fournies. Voici une explication détaillée du fonctionnement de ce processus :
1. 📊 Collecter et préparer les données
Les données sont le fondement de la formation en IA. Ils se composent généralement de milliers ou de millions d’exemples que le système doit analyser. Les exemples sont des images, des textes ou des données de séries chronologiques.
Les données doivent être nettoyées et normalisées pour éviter les sources d'erreur inutiles. Souvent, les données sont converties en fonctionnalités contenant les informations pertinentes.
2. 🔍 Définir le modèle
Un modèle est une fonction mathématique qui décrit les relations entre les données. Dans les réseaux de neurones, souvent utilisés pour l’IA, le modèle se compose de plusieurs couches de neurones connectées entre elles.
Chaque neurone effectue une opération mathématique pour traiter les données d'entrée, puis transmet un signal au neurone suivant.
3. 🔄 Initialiser les poids
Les connexions entre neurones ont des poids initialement définis de manière aléatoire. Ces poids déterminent la force avec laquelle un neurone répond à un signal.
Le but de la formation est d'ajuster ces poids afin que le modèle fasse de meilleures prédictions.
4. ➡️ Propagation vers l'avant
La passe avant transmet les données d'entrée à travers le modèle pour produire une prédiction.
Chaque couche traite les données et les transmet à la couche suivante jusqu'à ce que la dernière couche fournisse le résultat.
5. ⚖️ Calculer la fonction de perte
La fonction de perte mesure la qualité des prédictions du modèle par rapport aux valeurs réelles (les étiquettes). Une mesure courante est l’erreur entre la réponse prévue et la réponse réelle.
Plus la perte est élevée, plus la prédiction du modèle est mauvaise.
6. 🔙 Rétropropagation
Lors de la passe arrière, l'erreur est renvoyée de la sortie du modèle aux couches précédentes.
L'erreur est redistribuée aux poids des connexions et le modèle ajuste les poids pour que les erreurs deviennent plus petites.
Cela se fait en utilisant la descente de gradient : le vecteur de gradient est calculé, ce qui indique comment les poids doivent être modifiés afin de minimiser l'erreur.
7. 🔧 Mettre à jour les poids
Une fois l'erreur calculée, les poids des connexions sont mis à jour avec un petit ajustement basé sur le taux d'apprentissage.
Le taux d'apprentissage détermine dans quelle mesure les poids sont modifiés à chaque étape. Des changements trop importants peuvent rendre le modèle instable, et des changements trop petits entraînent un processus d'apprentissage lent.
8. 🔁 Répéter (Époque)
Ce processus de transmission directe, de calcul d'erreur et de mise à jour du poids est répété, souvent sur plusieurs époques (parcourant l'ensemble de l'ensemble de données), jusqu'à ce que le modèle atteigne une précision acceptable.
À chaque époque, le modèle en apprend un peu plus et ajuste davantage ses poids.
9. 📉 Validation et tests
Une fois le modèle entraîné, il est testé sur un ensemble de données validé pour vérifier dans quelle mesure il se généralise. Cela garantit non seulement qu’il a « mémorisé » les données d’entraînement, mais qu’il fait également de bonnes prédictions sur des données inconnues.
Les données de test permettent de mesurer les performances finales du modèle avant son utilisation pratique.
10. 🚀 Optimisation
Des étapes supplémentaires pour améliorer le modèle incluent le réglage des hyperparamètres (par exemple, l'ajustement du taux d'apprentissage ou de la structure du réseau), la régularisation (pour éviter le surajustement) ou l'augmentation de la quantité de données.
📊🔙 Intelligence artificielle : Rendre la boîte noire de l'IA compréhensible, compréhensible et explicable avec l'IA explicable (XAI), des cartes thermiques, des modèles de substitution ou d'autres solutions

Intelligence artificielle : Rendre la boîte noire de l'IA compréhensible, compréhensible et explicable grâce à l'IA explicable (XAI), des cartes thermiques, des modèles de substitution ou d'autres solutions - Image : Xpert.Digital
La « boîte noire » de l’intelligence artificielle (IA) représente un problème important et actuel. Même les experts sont souvent confrontés au défi de ne pas être en mesure de comprendre pleinement comment les systèmes d’IA prennent leurs décisions. Ce manque de transparence peut entraîner des problèmes importants, notamment dans des domaines critiques tels que l'économie, la politique ou la médecine. Un médecin ou un professionnel de la santé qui s’appuie sur un système d’IA pour diagnostiquer et recommander un traitement doit avoir confiance dans les décisions prises. Cependant, si la prise de décision d’une IA n’est pas suffisamment transparente, de l’incertitude et potentiellement un manque de confiance apparaissent – dans des situations où des vies humaines pourraient être en jeu.
En savoir plus ici :
Nous sommes là pour vous - conseil - planification - mise en œuvre - gestion de projet
☑️ Accompagnement des PME en stratégie, conseil, planification et mise en œuvre
☑️ Création ou réalignement de la stratégie digitale et digitalisation
☑️ Expansion et optimisation des processus de vente à l'international
☑️ Plateformes de trading B2B mondiales et numériques
☑️ Développement commercial pionnier

Konrad Wolfenstein
Je serais heureux de vous servir de conseiller personnel.
Vous pouvez me contacter en remplissant le formulaire de contact ci-dessous ou simplement m'appeler au +49 89 89 674 804 (Munich) .
J'attends avec impatience notre projet commun.
Écris moi

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital est une plateforme industrielle axée sur la numérisation, la construction mécanique, la logistique/intralogistique et le photovoltaïque.
Avec notre solution de développement commercial à 360°, nous accompagnons des entreprises de renom depuis les nouvelles affaires jusqu'à l'après-vente.
L'intelligence de marché, le smarketing, l'automatisation du marketing, le développement de contenu, les relations publiques, les campagnes de courrier électronique, les médias sociaux personnalisés et le lead nurturing font partie de nos outils numériques.
Vous pouvez en savoir plus sur : www.xpert.digital - www.xpert.solar - www.xpert.plus
Rester en contact


















