


Tehisintellekt ja SEO BERT-iga – kahesuunalised kodeerija esitused transformaatoritest – mudel loomuliku keele töötlemise (NLP) valdkonnas – pilt: Xpert.Digital
🚀💬 Google'i arendatud: BERT ja selle tähtsus NLP jaoks – miks on kahesuunaline teksti mõistmine ülioluline
🔍🗣️ BERT, lühend sõnadest Bidirectional Encoder Representations from Transformers, on Google'i väljatöötatud oluline loomuliku keele töötlemise (NLP) mudel. See on muutnud masinate keele mõistmist. Erinevalt varasematest mudelitest, mis analüüsisid teksti järjestikku vasakult paremale või vastupidi, võimaldab BERT kahesuunalist töötlemist. See tähendab, et see haarab sõna konteksti nii eelnevast kui ka järgnevast tekstijadast. See võime parandab oluliselt keerukate keeleliste seoste mõistmist.
🔍 BERTi arhitektuur
Viimastel aastatel on loomuliku keele töötlemise (NLP) üks olulisemaid arenguid toimunud Transformeri mudeli kasutuselevõtuga, nagu on kirjeldatud 2017. aasta PDF-artiklis "Tähelepanu on kõik, mida vajate" (Wikipedia). See mudel muutis valdkonda põhjalikult, hüljates varem kasutatud struktuurid, näiteks masintõlke. Selle asemel tugineb see ainult tähelepanu mehhanismidele. Transformeri disain on sellest ajast alates olnud aluseks paljudele mudelitele, mis esindavad tipptaset erinevates valdkondades, sealhulgas kõne genereerimine, tõlkimine ja muud.
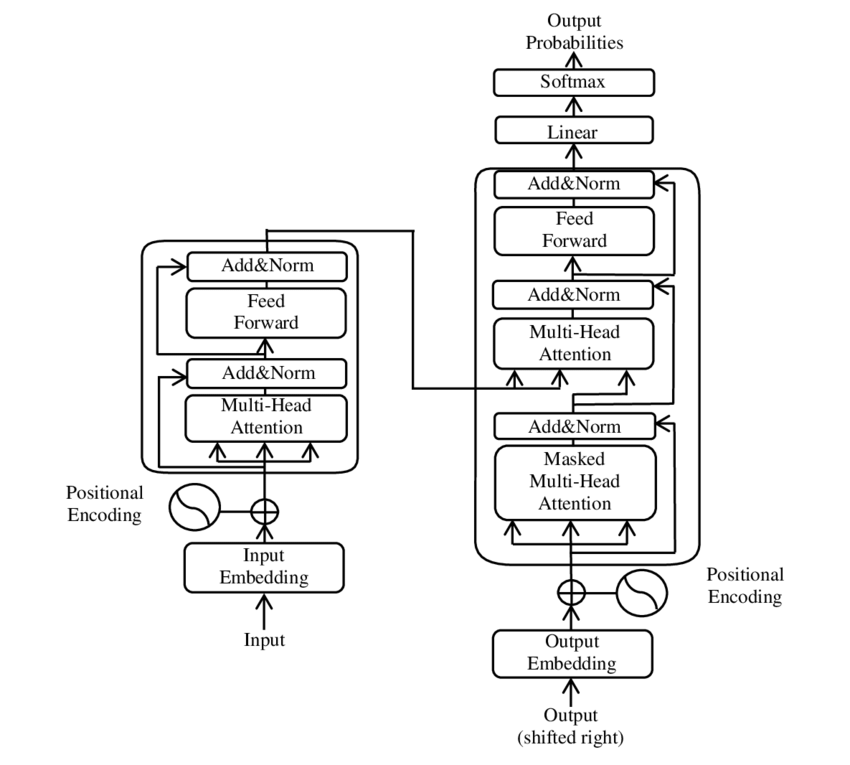
Transformeri mudeli põhikomponentide illustratsioon – Pilt: Google
BERT põhineb sellel transformeerival arhitektuuril. See arhitektuur kasutab niinimetatud enesetähelepanu mehhanisme lause sõnadevaheliste seoste analüüsimiseks. Igale sõnale pööratakse tähelepanu kogu lause kontekstis, mis viib süntaktiliste ja semantiliste seoste täpsema mõistmiseni.
Artikli „Tähelepanu on kõik, mida vajad” autorid on:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google'i uuring)
- Jakob Uszkoreit (Google'i uuring)
- Lion Jones (Google'i uuring)
- Aidan N. Gomez (Toronto Ülikool, töö osaliselt teostatud Google Brainis)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (sõltumatu, varasem töö Google Researchis)
Need autorid on andnud olulise panuse käesolevas artiklis esitatud Transformeri mudeli väljatöötamisse.
🔄 Kahesuunaline töötlemine
BERT-i põhiomadus on võime töödelda teksti kahesuunaliselt. Kui traditsioonilised mudelid, näiteks rekurrentsed närvivõrgud (RNN) või pika lühiajalise mäluga (LSTM) võrgud, töötlevad teksti ainult ühes suunas, siis BERT analüüsib sõna konteksti mõlemas suunas. See võimaldab mudelil paremini tabada tähenduse peeneid nüansse ja seega teha täpsemaid ennustusi.
🕵️♂️ Maskeeritud kõne modelleerimine
Teine BERT-i uuenduslik aspekt on maskeeritud keelemudeli (MLM) tehnika. Selle meetodi puhul maskeeritakse lauses juhuslikult valitud sõnad ja mudelit treenitakse neid sõnu ümbritseva konteksti põhjal ennustama. See meetod sunnib BERT-i arendama sügavat arusaama lause iga sõna kontekstist ja tähendusest.
🚀 BERTi koolitus ja kohandamine
BERT läbib kaheastmelise koolitusprotsessi: eelkoolitus ja peenhäälestus.
📚 Eelkoolitus
Eelkoolituse käigus treenitakse BERT-i suure hulga tekstiga, et õppida üldiseid keelemustreid. See hõlmab Vikipeedia artikleid ja muid ulatuslikke tekstikorpusi. Selle etapi jooksul õpib mudel põhilisi keelelisi struktuure ja kontekste.
🔧 Peenhäälestus
Pärast eeltreeningut kohandatakse BERT-i konkreetsete keelelise kirjanduse ülesannete jaoks, näiteks teksti klassifitseerimiseks või sentimentaalsuse analüüsiks. Mudelit treenitakse väiksemate, ülesandega seotud andmekogumitega, et optimeerida selle jõudlust konkreetsete rakenduste jaoks.
🌍 BERTi rakendusvaldkonnad
BERT on osutunud äärmiselt kasulikuks paljudes loomuliku keele töötlemise valdkondades:
Otsingumootorite optimeerimine
Google kasutab BERT-i otsingupäringute paremaks mõistmiseks ja asjakohasemate tulemuste kuvamiseks. See parandab oluliselt kasutajakogemust.
Teksti liigitamine
BERT saab dokumente teemade kaupa kategoriseerida või tekstides valitsevat meeleolu analüüsida.
Nimetatud üksuste tuvastamine (NER)
Mudel tuvastab ja liigitab tekstides nimetatud üksusi, näiteks inimeste, kohtade või organisatsioonide nimesid.
Küsimuste-vastuste süsteemid
BERT-i kasutatakse esitatud küsimustele täpsete vastuste andmiseks.
🧠 BERTi tähtsus tehisintellekti tuleviku jaoks
BERT on seadnud NLP mudelitele uued standardid ja sillutanud teed edasistele innovatsioonidele. Tänu oma kahesuunalise töötlemise võimele ja keelekontekstide sügavale mõistmisele on see oluliselt suurendanud tehisintellekti rakenduste tõhusust ja täpsust.
🔜 Tulevased arengud
BERT-i ja sarnaste mudelite edasiarendamise eesmärk on luua veelgi võimsamaid süsteeme. Need suudaksid hakkama saada keerukamate keeleülesannetega ja neid saaks kasutada paljudes uutes rakendusvaldkondades. Selliste mudelite integreerimine igapäevastesse tehnoloogiatesse võiks põhjalikult muuta seda, kuidas me arvutitega suhtleme.
🌟 Tehisintellekti arengu verstapost
BERT on tehisintellekti arengus verstapost ja on muutnud revolutsiooniliselt seda, kuidas masinad loomulikku keelt töötlevad. Selle kahesuunaline arhitektuur võimaldab keeleliste suhete sügavamat mõistmist, muutes selle asendamatuks paljude rakenduste jaoks. Uuringute edenedes mängivad sellised mudelid nagu BERT jätkuvalt keskset rolli tehisintellekti süsteemide täiustamisel ja nende kasutamiseks uute võimaluste avamisel.
📣 Sarnased teemad
- 📚 Sissejuhatus BERT-i: murranguline NLP mudel
- 🔍 BERT ja kahesuunalisuse roll NLP-s
- 🧠 Transformeri mudel: BERTi asutamine
- 🚀 Maskeeritud keele modelleerimine: BERTi edu võti
- 📈 BERT-i kohandamine: eelkoolitusest kuni peenhäälestamiseni
- 🌐 BERTi rakendusvaldkonnad tänapäevases tehnoloogias
- 🤖 BERTi mõju tehisintellekti tulevikule
- 💡 Tulevikuväljavaated: BERTi edasine areng
- 🏆 BERT kui tehisintellekti arendamise verstapost
- 📰 Transformeri artikli „Tähelepanu on kõik, mida vajad” autorid: BERTi taga olevad mõtted
#️⃣ Hashtagid: #NLP #Tehisintellekt #KeeleModelleerimine #Transformer #Masinõpe
🎯🎯🎯 Saa kasu Xpert.Digitali ulatuslikust, viiest valdkonna asjatundlikkusest ühes terviklikus teenusepaketis | BD, R&D, XR, PR ja digitaalse nähtavuse optimeerimine


Saage kasu Xpert.Digitali ulatuslikust, viiest astmest koosnevast asjatundlikkusest terviklikus teenustepaketis | Teadus- ja arendustegevus, XR, PR ja digitaalse nähtavuse optimeerimine - Pilt: Xpert.Digital
Xpert.Digitalil on põhjalikud teadmised erinevates tööstusharudes. See võimaldab meil välja töötada kohandatud strateegiaid, mis on täpselt kooskõlas teie konkreetse turusegmendi nõuete ja väljakutsetega. Turusuundumuste pideva analüüsimise ja valdkonna arengute jälgimise abil saame tegutseda ennetavalt ja pakkuda uuenduslikke lahendusi. Kogemuste ja oskusteabe kombinatsioon loob lisaväärtust ja annab meie klientidele otsustava konkurentsieelise.
Lisateavet leiate siit:
BERT: Revolutsiooniline 🌟 NLP tehnoloogia
🚀 BERT, lühend sõnadest Bidirectional Encoder Representations from Transformers, on Google'i välja töötatud täiustatud keelesuund, mis on alates selle kasutuselevõtust 2018. aastal olnud märkimisväärne läbimurre loomuliku keele töötlemises (NLP). See põhineb Transformeri arhitektuuril, mis muutis revolutsiooniliselt seda, kuidas masinad teksti mõistavad ja töötlevad. Aga mis täpselt teeb BERT-i nii eriliseks ja milleks seda kasutatakse? Sellele küsimusele vastamiseks peame lähemalt uurima BERT-i tehnilisi aluseid, toimimist ja rakendusi.
📚 1. Loomuliku keele töötlemise põhitõed
BERT-i olulisuse täielikuks mõistmiseks on kasulik lühidalt üle vaadata loomuliku keele töötlemise (NLP) põhitõed. NLP tegeleb arvutite ja inimkeele vastastikmõjuga. Selle eesmärk on õpetada masinaid tekstiandmeid analüüsima, mõistma ja neile reageerima. Enne selliste mudelite nagu BERT kasutuselevõttu oli masinkeele töötlemine sageli täis olulisi väljakutseid, eriti inimkeele mitmetähenduslikkuse, kontekstist sõltuvuse ja keeruka struktuuri tõttu.
📈 2. NLP mudelite väljatöötamine
Enne BERT-i tekkimist põhinesid enamik NLP-mudeleid niinimetatud ühesuunalistel arhitektuuridel. See tähendas, et need mudelid lugesid teksti kas vasakult paremale või paremalt vasakule, mis tähendas, et nad said lauses oleva sõna töötlemisel arvestada vaid piiratud hulga kontekstiga. See piirang tõi sageli kaasa olukorra, kus mudelid ei suutnud lause semantilist konteksti täielikult tabada. See raskendas mitmetähenduslike või kontekstitundlike sõnade täpset tõlgendamist.
Teine oluline areng NLP-uuringutes enne BERT-i oli word2vec mudel, mis võimaldas arvutitel tõlkida sõnu semantilisi sarnasusi peegeldavateks vektoriteks. Kuid isegi siin piirdus kontekst sõna vahetu ümbrusega. Hiljem töötati välja rekurrentsed närvivõrgud (RNN) ja eriti pika lühiajalise mälu (LSTM) mudelid, mis võimaldasid tekstijadasid paremini mõista, salvestades teavet mitme sõna vahel. Neil mudelitel olid aga ka omad piirangud, eriti pikkade tekstidega tegelemisel ja konteksti samaaegsel mõistmisel mõlemas suunas.
🔄 3. Revolutsioon trafoarhitektuuri kaudu
Läbimurre saabus 2017. aastal Transformeri arhitektuuri kasutuselevõtuga, mis on BERTi aluseks. Transformeri mudelid on loodud võimaldama paralleelset tekstitöötlust, võttes arvesse nii eelneva kui ka järgneva teksti sõna konteksti. See saavutatakse nn enesetähelepanu mehhanismide abil, mis määravad igale lauses olevale sõnale kaalu, mis põhineb selle olulisusel lause teiste sõnade suhtes.
Erinevalt varasematest lähenemisviisidest ei ole transformaatormudelid ühe-, vaid kahesuunalised. See tähendab, et nad saavad ammutada teavet nii sõna vasakust kui ka paremast kontekstist, et luua sõnast ja selle tähendusest terviklikum ja täpsem esitus.
🧠 4. BERT: kahesuunaline mudel
BERT viib Transformeri arhitektuuri jõudluse uuele tasemele. Mudel on loodud jäädvustama sõna konteksti mitte ainult vasakult paremale või paremalt vasakule, vaid mõlemas suunas samaaegselt. See võimaldab BERTil arvestada sõna täielikku konteksti lauses, mille tulemuseks on loomuliku keele töötlemise ülesannete oluliselt parem täpsus.
BERT-i põhijooneks on nn maskeeritud keelemudeli (MLM) kasutamine. BERT-i treenimise ajal asendatakse lauses juhuslikult valitud sõnad maskiga ja mudelit treenitakse neid maskeeritud sõnu konteksti põhjal ära arvama. See tehnika võimaldab BERT-il õppida lauses olevate sõnade vahel sügavamaid ja täpsemaid seoseid.
Lisaks kasutab BERT meetodit nimega järgmise lause ennustamine (NSP), mille abil õpib mudel ennustama, kas üks lause järgneb teisele. See parandab BERT-i võimet mõista pikemaid tekste ja ära tunda lausete vahel keerukamaid seoseid.
🌐 5. BERTi praktiline rakendamine
BERT on osutunud äärmiselt kasulikuks paljude NLP-ülesannete puhul. Siin on mõned kõige olulisemad rakendusvaldkonnad:
📊 a) Teksti liigitamine
Üks BERT-i levinumaid rakendusi on teksti klassifitseerimine, kus tekstid jagatakse eelnevalt määratletud kategooriatesse. Näideteks on sentimendianalüüs (nt teksti positiivse või negatiivse olemuse tuvastamine) või klientide tagasiside kategoriseerimine. Tänu sõnade konteksti sügavale mõistmisele suudab BERT anda täpsemaid tulemusi kui varasemad mudelid.
❓ b) Küsimuste-vastuste süsteemid
BERT-i kasutatakse ka küsimustele vastamise süsteemides, kus mudel ekstraheerib tekstist vastused esitatud küsimustele. See võimekus on eriti oluline sellistes rakendustes nagu otsingumootorid, vestlusrobotid ja virtuaalsed assistendid. Tänu oma kahesuunalisele arhitektuurile suudab BERT tekstist eraldada asjakohast teavet isegi siis, kui küsimus on sõnastatud kaudselt.
🌍 c) Teksti tõlge
Kuigi BERT ise ei ole otseselt loodud tõlkemudelina, saab seda koos teiste tehnoloogiatega kasutada masintõlke parandamiseks. Lause semantika seoste parema mõistmise abil aitab BERT luua täpsemaid tõlkeid, eriti mitmetähenduslike või keerukate fraaside puhul.
🏷️ d) Nimetatud üksuste tuvastamine (NER)
Teine rakendusvaldkond on nimetatud üksuste tuvastamine (NER), mis hõlmab tekstis konkreetsete üksuste, näiteks nimede, kohtade või organisatsioonide tuvastamist. BERT on osutunud selles ülesandes eriti tõhusaks, kuna see arvestab täielikult lause konteksti ja suudab seega üksusi paremini ära tunda, isegi kui neil on erinevates kontekstides erinev tähendus.
✂️ e) Tekstiline kokkuvõte
BERT-i võime mõista teksti kogu konteksti teeb sellest ka võimsa tööriista teksti automaatseks kokkuvõtmiseks. Seda saab kasutada pikast tekstist kõige olulisema teabe eraldamiseks ja kokkuvõtliku kokkuvõtte loomiseks.
🌟 6. BERTi tähtsus teadusuuringute ja tööstuse jaoks
BERT-i kasutuselevõtt pani aluse uuele ajastule NLP-uuringutes. See oli üks esimesi mudeleid, mis kasutas täielikult ära kahesuunalise transformaatori arhitektuuri võimsust, seades standardi paljudele järgnevatele mudelitele. Arvukad ettevõtted ja teadusasutused on integreerinud BERT-i oma NLP-torustikesse, et parandada oma rakenduste jõudlust.
Lisaks sillutas BERT teed edasistele uuendustele keelemudelite valdkonnas. Näiteks töötati hiljem välja sellised mudelid nagu GPT (Generative Pretrained Transformer) ja T5 (Text-to-Text Transfer Transformer), mis põhinevad sarnastel põhimõtetel, kuid pakuvad erinevate kasutusjuhtude jaoks spetsiifilisi täiustusi.
🚧 7. BERTi väljakutsed ja piirangud
Vaatamata paljudele eelistele on BERT-il ka mõningaid väljakutseid ja piiranguid. Üks suurimaid takistusi on mudeli treenimiseks ja rakendamiseks vajalik suur arvutusvõimsus. Kuna BERT on väga suur mudel miljonite parameetritega, vajab see võimsat riistvara ja märkimisväärseid arvutusressursse, eriti suurte andmekogumite töötlemisel.
Teine probleem on treeningandmetes esineda võiv eelarvamus. Kuna BERT-i treenitakse suure hulga tekstiandmete põhjal, peegeldab see mõnikord nendes andmetes esinevaid eelarvamusi ja stereotüüpe. Teadlased töötavad aga pidevalt nende probleemide tuvastamise ja lahendamise nimel.
🔍 Asendamatu tööriist tänapäevaste kõnetöötlusrakenduste jaoks
BERT on märkimisväärselt parandanud seda, kuidas masinad inimkeelest aru saavad. Oma kahesuunalise arhitektuuri ja uuenduslike treeningmeetoditega suudab see lauses olevate sõnade konteksti sügavuti ja täpselt haarata, mis viib suurema täpsuseni paljudes NLP-ülesannetes. Olgu tegemist teksti klassifitseerimise, küsimuste-vastuste süsteemide või üksuste tuvastamisega, BERT on ennast tõestanud kui asendamatut tööriista tänapäevastes loomuliku keele töötlemise rakendustes.
Looduskeele töötlemise valdkonna uuringud jätkavad kahtlemata edasiminekut ning BERT on loonud aluse paljudele tulevastele uuendustele. Vaatamata olemasolevatele väljakutsetele ja piirangutele näitab BERT muljetavaldavalt, kui kaugele on tehnoloogia lühikese ajaga jõudnud ja millised põnevad võimalused tulevikus veel avanevad.
🌀 Transformer: revolutsioon loomuliku keele töötlemises
🌟 Viimastel aastatel on loomuliku keele töötlemise (NLP) üks olulisemaid arenguid olnud Transformeri mudeli kasutuselevõtt, nagu on kirjeldatud 2017. aasta artiklis "Tähelepanu on kõik, mida vajate". See mudel muutis valdkonda põhjalikult, hüljates järjestuse edastamise ülesannetes, näiteks masintõlkes, varem kasutatud rekurrentsed või konvolutsioonilised struktuurid. Selle asemel tugineb see ainult tähelepanumehhanismidele. Transformeri disain on sellest ajast alates olnud aluseks paljudele mudelitele, mis esindavad tipptaset erinevates valdkondades, sealhulgas kõne genereerimine, tõlkimine ja muu selline.
🔄 Trafo: paradigma muutus
Enne Transformeri kasutuselevõttu põhinesid enamik järjestusülesannete mudeleid rekurrentsetel närvivõrkudel (RNN) või pika lühiajalise mälu (LSTM) võrkudel, mis oma olemuselt toimivad järjestikku. Need mudelid töötlevad sisendandmeid samm-sammult, luues peidetud olekuid, mis levivad mööda järjestust. Kuigi see meetod on tõhus, on see arvutuslikult kulukas ja seda on keeruline paralleelseks muuta, eriti pikkade järjestuste puhul. Lisaks on RNN-idel raskusi pikaajaliste sõltuvuste õppimisega kaduva gradiendi probleemi tõttu.
Transformeri peamine uuendus seisneb enesetähelepanu mehhanismide kasutamises, mis võimaldavad mudelil kaaluda lause eri sõnade olulisust üksteise suhtes, olenemata nende positsioonist. See võimaldab mudelil jäädvustada seoseid laialdaselt eraldatud sõnade vahel tõhusamalt kui RNN-ide või LSTM-ide puhul ning teha seda paralleelselt, mitte järjestikku. See mitte ainult ei paranda treeningu efektiivsust, vaid ka jõudlust sellistes ülesannetes nagu masintõlge.
🧩 Mudelarhitektuur
Trafo koosneb kahest põhikomponendist: kodeerijast ja dekoodrist, mis mõlemad koosnevad mitmest kihist ja tuginevad suuresti mitmepealise tähelepanu mehhanismidele.
⚙️ Kodeerija
Kodeerija koosneb kuuest identsest kihist, millest igaühel on kaks alamkihti:
1. Mitmepealine enesekeskne tähelepanu
See mehhanism võimaldab mudelil iga sõna töötlemisel keskenduda sisendlause erinevatele osadele. Tähelepanu arvutamise asemel ühes ruumis projitseerib mitmepealine tähelepanu sisendi mitmesse erinevasse ruumi, jäädvustades seeläbi mitmesuguseid sõnadevahelisi seoseid.
2. Positsiooniliselt täielikult ühendatud etteandevõrgud
Tähelepanu kihile järgneb igale positsioonile sõltumatult täielikult ühendatud edasisuunamisvõrk. See aitab mudelil iga sõna kontekstis töödelda ja tähelepanu mehhanismilt saadud teavet kasutada.
Sisendjada struktuuri säilitamiseks sisaldab mudel ka positsioonilisi kodeeringuid. Kuna teisendaja ei töötle sõnu järjestikku, on need kodeeringud üliolulised, et anda mudelile teavet lause sõnajärje kohta. Positsioonilised kodeeringud lisatakse sõnade manustamisele, et mudel saaks eristada järjestuses olevaid erinevaid positsioone.
🔍 Dekooder
Nagu kodeerija, koosneb ka dekooder kuuest kihist, millest igaühel on täiendav tähelepanumehhanism, mis võimaldab mudelil väljundi genereerimise ajal keskenduda sisendjada asjakohastele osadele. Dekooder kasutab ka maskeerimistehnikat, et vältida tulevaste positsioonide arvestamist, säilitades seeläbi jada genereerimise autoregressiivse olemuse.
🧠 Mitmepealine tähelepanu ja skalaarne toote tähelepanu
Transformeri tuumaks on mitmepealine tähelepanumehhanism, mis on lihtsama skalaarprodukti tähelepanumehhanismi laiendus. Tähelepanufunktsiooni võib vaadelda kui päringu ja võtme-väärtuse paaride komplekti vahelist vastendust, kus iga võti esindab järjestuses ühte sõna ja väärtus esindab vastavat kontekstuaalset teavet.
Mitmepealine tähelepanumehhanism võimaldab mudelil keskenduda samaaegselt järjestuse erinevatele osadele. Sisendi projitseerimisega mitmesse alamruumi suudab mudel jäädvustada rikkalikuma hulga sõnadevahelisi seoseid. See on eriti kasulik selliste ülesannete puhul nagu masintõlge, kus sõna konteksti mõistmine nõuab paljusid erinevaid tegureid, näiteks süntaktilist struktuuri ja semantilist tähendust.
Skalaarse korrutise tähelepanu valem on:
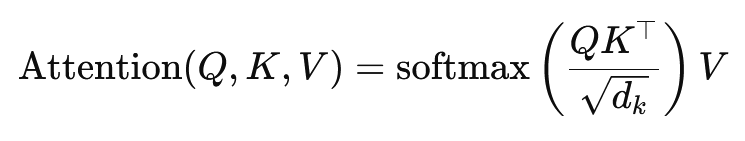
Siin on (Q) päringumaatriks, (K) võtmemaatriks ja (V) väärtusmaatriks. Termin (sqrt{d_k}) on skaleerimistegur, mis hoiab ära skalaarkorrutiste liiga suureks muutumise, mis tooks kaasa väga väikesed gradientid ja aeglasema õppimise. Softmax-funktsiooni rakendatakse tagamaks, et tähelepanu kaalud moodustavad ühe.
🚀 Trafo eelised
Transformeril on traditsiooniliste mudelite, näiteks RNN-ide ja LSTM-ide ees mitmeid olulisi eeliseid:
1. Paralleliseerimine
Kuna transformaator töötleb kõiki jada märke samaaegselt, saab seda tugevalt paralleelseks muuta ja seetõttu on seda palju kiirem treenida kui RNN-e või LSTM-e, eriti suurte andmekogumite puhul.
2. Pikaajalised sõltuvused
Enesetähelepanu mehhanism võimaldab mudelil jäädvustada kaugete sõnade vahelisi seoseid tõhusamalt kui RNN-idel, mida piirab nende arvutuste järjestikune olemus.
3. Skaleeritavus
Trafo saab hõlpsasti skaleerida väga suurte andmekogumite ja pikemate järjestuste jaoks, ilma et see kannataks RNN-idega seotud jõudlusprobleemide all.
🌍 Rakendused ja efektid
Alates selle kasutuselevõtust on Transformerist saanud paljude NLP-mudelite alus. Üks tähelepanuväärsemaid näiteid on BERT (Bidirectional Encoder Representations from Transformers), mis kasutab modifitseeritud Transformeri arhitektuuri, et saavutada tipptasemel jõudlus paljudes NLP-ülesannetes, sealhulgas küsimustele vastamisel ja teksti klassifitseerimisel.
Teine oluline areng on GPT (Generative Pretrained Transformer), mis kasutab teksti genereerimiseks transformaatori dekoodriga piiratud versiooni. GPT mudeleid, sealhulgas GPT-3, kasutatakse nüüd arvukates rakendustes, alates sisu loomisest kuni koodi valmimiseni.
🔍 Võimas ja paindlik mudel
Transformer on põhjalikult muutnud meie lähenemist NLP-ülesannetele. See pakub võimsat ja paindlikku mudelit, mida saab rakendada väga erinevate probleemide lahendamiseks. Selle võime toime tulla pikaajaliste sõltuvustega ja selle tõhusus treenimisel on teinud sellest eelistatud arhitektuurilise lähenemisviisi paljude kõige kaasaegsemate mudelite jaoks. Uuringute edenedes näeme tõenäoliselt Transformeri edasisi täiustusi ja kohandusi, eriti sellistes valdkondades nagu pildi- ja kõnetöötlus, kus tähelepanu mehhanismid näitavad paljulubavaid tulemusi.
Oleme teie jaoks olemas - Konsultatsioon - Planeerimine - Teostus - Projektijuhtimine
☑️ Valdkonnaekspert, siin oma Xpert.Digital valdkonnakeskusega, kus on üle 2500 erialase artikli

Konrad Wolfenstein
Mul oleks hea meel olla teie isiklik nõustaja.
Võite minuga ühendust võtta, täites alloleva kontaktvormi või helistades mulle numbril +49 7348 4088 965 .
Ootan põnevusega meie ühist projekti.
Kirjuta mulle




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital on tööstuskeskus, mis keskendub digitaliseerimisele, masinaehitusele, logistikale/siselogistikale ja fotogalvaanikale.
Meie 360° äriarenduslahendusega toetame tuntud ettevõtteid alates uutest klientidest kuni järelmüügini.
Turu-uuring, s-turundus, turunduse automatiseerimine, sisu loomine, suhtekorraldus, meilikampaaniad, personaalne sotsiaalmeedia ja müügivihjete haldamine on osa meie digitaalsetest tööriistadest.
Lisateavet leiate aadressilt: www.xpert.digital - www.xpert.solar - www.xpert.plus
Hoidke ühendust











