Tehisintellekti taga olevad inimesed ja protsessid – @shutterstock | Zapp2Photo
Tehisintellektil on halb maine töökohtade hävitajana ja inimtööjõu asendajana. Mõnes valdkonnas on see tõsi, kuid teistes, eriti andmete puhastamise ja töötlemise osas, on tehisintellekt uute töökohtade loomisel teerajaja.
„Andmete märgistamine ja annoteerimine” on tehisintellektist tärkav kiiresti arenev tööstusharu. Struktureerimata andmekogumeid, mis pärinevad sellistest allikatest nagu kaamerad ja sotsiaalmeedia või struktureeritud allikatest nagu andmebaasid, märgistatakse, sildistatakse, värvitakse või tõstetakse esile, et paljastada inimeste erinevusi ja sarnasusi. Masina treenimiseks stopp-märgi tuvastamiseks astuks inimene tänavakaamera salvestusse ja sildistaks kõik fotol olevad stopp-märgid. Seejärel edastataks masinale andmed, mis identifitseerivad tuhandeid selliseid pilte. Aja jooksul, sildistatud andmete töötlemise abil, võiks süsteem stopp-märgi tuvastamisel täpsemaks muutuda. Seda tüüpi masinõpet, kus süsteem parandab täpsust rohkemate andmete vastuvõtmise teel, nimetatakse süvaõppeks.
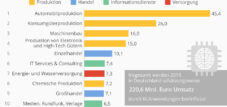
Kuna see protsess on algoritmide põhifunktsioonide täpseks täitmiseks hädavajalik, saavutab andmete märgistamise valdkond järgmise viie aasta jooksul märkimisväärse tähtsuse. 2018. aastal hinnati tehisintellekti ja masinõppe andmete ettevalmistamise turu väärtuseks 500 miljonit dollarit, mis on protsess, mis sõltub suuresti inimeste käsitsi andmete märgistamisest. Cognilytica peaks see enam kui kahekordistuma, ulatudes 2023. aastaks 1,2 miljardi dollarini. Kolmandate osapoolte pakkujad prognoosivad selle kasvu olulist suurenemist, turu suuruselt 150 miljonilt dollarilt 1 miljardi dollarini samal perioodil. Andmete märgistamine on eriti oluline tehisintellekti rakenduste jaoks, nagu objektide ja piltide tuvastamine, autonoomsed sõidukid ning teksti ja piltide märkimine.
Tehisintellektil on halb maine kui töökohtade hävitajal ja inimtöötajate asendajal. Mõnes valdkonnas on see tõsi, kuid teistes, eriti andmete puhastamise ja töötlemise osas, on tehisintellekt uute töökohtade loomisel eestvedaja.
Andmete sildistamine ja annoteerimine on tehisintellektist sündinud kiiresti arenev tööstusharu. Struktureerimata andmekogumeid, mis pärinevad sellistest allikatest nagu kaamerad ja sotsiaalmeedia andmed või struktureeritud allikatest, nagu andmebaasid, sildistatakse, tähistatakse, värvitakse või tõstetakse esile, et näidata erinevusi ja sarnasusi. Masina õpetamiseks stopp-märgi õppimiseks peab inimene minema tänava kaamerasalvestusse ja märkima fotol kõik stopp-märgid. Seejärel edastatakse masinale andmed, mis identifitseerivad tuhandeid selliseid pilte. Aja jooksul suudab süsteem sildistatud andmeid töödeldes täpsemalt tuvastada, mis on stopp-märk. Seda tüüpi masinõpet, kus süsteem muutub täpsemaks, kui sellele antakse rohkem andmeid, nimetatakse süvaõppeks.
Kuna see protsess on algoritmide jaoks hädavajalik oma põhifunktsioonide täpseks täitmiseks, peaks andmete märgistamise tööstus järgmise viie aasta jooksul hoogu koguma. 2018. aastal oli tehisintellekti ja masinõppe andmete ettevalmistamise turg, mis on protsess, mis tugineb suuresti inimestele andmete käsitsi märgistamisel, 500 miljoni dollari suurune. Cognilytica andmetel peakssee enam kui kahekordistuma, ulatudes 2023. aastaks 1,2 miljardi dollarini. Kolmandate osapoolte pakkujad ootavad selle kasvu märkimisväärset suurenemist, ulatudes samal ajal turu 150 miljonilt dollarilt 1 miljardi dollarini. Andmete märgistamine on eriti oluline tehisintellekti jaoks, mis tegeleb objektide ja piltide tuvastamise, autonoomsete sõidukite ning teksti ja piltide märkimisega.


Hoidke ühendust