57 miljardi dollari suurune valearvestus – kõigist ettevõtetest hoiatab NVIDIA: tehisintellekti tööstus on vale hobuse toetanud – Pilt: Xpert.Digital
Unustage tehisintellekti hiiglased: miks tulevik on väike, detsentraliseeritud ja palju odavam
### Väikeste keelte mudelid: tõelise äriautonoomia võti ### Hüperskaleerijatelt tagasi kasutajate juurde: võimuvahetus tehisintellekti maailmas ### 57 miljardi dollari suurune viga: miks tõeline tehisintellekti revolutsioon ei toimu pilves ### Vaikne tehisintellekti revolutsioon: detsentraliseeritud tsentraliseeritu asemel ### Tehnoloogiahiiglased valel teel: tehisintellekti tulevik on lean ja lokaalne ### Hüperskaleerijatelt tagasi kasutajate juurde: võimuvahetus tehisintellekti maailmas ###
Miljardid dollarid raisatud investeeringud: miks väikesed tehisintellekti mudelid edestavad suuri
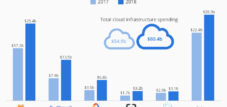
Tehisintellekti maailm seisab silmitsi maavärinaga, mille ulatus meenutab dot-com-ajastu korrektsioone. Selle murrangu keskmes on kolossaalne valearvestus: samal ajal kui tehnoloogiahiiglased nagu Microsoft, Google ja Meta investeerivad sadu miljardeid tsentraliseeritud infrastruktuuri massiivsete keelemudelite (Large Language Models, LLM) jaoks, jääb nende rakenduste tegelik turg märkimisväärselt maha. Murranguline analüüs, mille osaliselt viis läbi valdkonna liider NVIDIA ise, hindab infrastruktuuriinvesteeringute vahe 57 miljardi dollari suuruseks võrreldes tegeliku turuga, mis on vaid 5,6 miljardit dollarit – kümnekordne erinevus.
See strateegiline viga tuleneb eeldusest, et tehisintellekti tulevik peitub ainuüksi üha suuremates, arvutuslikult intensiivsemates ja tsentraalselt kontrollitavates mudelites. Nüüd on see paradigma aga kokku varisemas. Vaikne revolutsioon, mida juhivad detsentraliseeritud, väiksemad keelemudelid (väikesed keelemudelid, SLM-id), pöörab väljakujunenud korra pea peale. Need mudelid pole mitte ainult mitu korda odavamad ja tõhusamad, vaid võimaldavad ettevõtetel saavutada ka uusi autonoomia, andmete suveräänsuse ja paindlikkuse tasemeid – kaugel kulukast sõltuvusest vähestest hüperskaleerijatest. See tekst analüüsib selle mitme miljardi dollari suuruse investeeringu anatoomiat ja näitab, miks tõeline tehisintellekti revolutsioon ei toimu mitte hiiglaslikes andmekeskustes, vaid detsentraliseeritult ja lahja riistvara peal. See on lugu põhimõttelisest võimu nihkest infrastruktuuri pakkujatelt tagasi tehnoloogia kasutajatele.
Sobib selleks:


NVIDIA uuring tehisintellekti kapitali ebaõige jaotamise kohta
Kirjeldatud andmed pärinevad NVIDIA uurimistööst, mis avaldati 2025. aasta juunis. Täielik allikas on:
„Väikesed keelemudelid on agentliku tehisintellekti tulevik“
- Autorid: Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
- Väljalaskekuupäev: 2. juuni 2025 (versioon 1), viimane redaktsioon 15. september 2025 (versioon 2)
- Avaldamise asukoht: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- NVIDIA ametlik uurimisleht: https://research.nvidia.com/labs/lpr/slm-agents/
Kapitali ebaõige jaotamise peamine sõnum
Uuring dokumenteerib põhimõttelist lahknevust taristuinvesteeringute ja tegeliku turumahu vahel: 2024. aastal investeeris tööstusharu 57 miljardit dollarit pilvetaristusse, et toetada suurte keelemudelite (LLM) API teenuseid, samas kui nende teenuste tegelik turg oli vaid 5,6 miljardit dollarit. Seda kümnekordset lahknevust tõlgendatakse uuringus strateegilise valearvestuse märgina, kuna tööstusharu investeeris suuri summasid suuremahuliste mudelite tsentraliseeritud taristusse, kuigi 40–70% praegustest LLM-i töökoormustest saaks asendada väiksemate, spetsialiseeritud väikeste keelemudelitega (SLM) hinnaga 1/30 tavapärasest.
Uurimistöö kontekst ja autorlus
See uuring on NVIDIA Researchi süvaõppe efektiivsuse uurimisrühma seisukohavõtt. Juhtiv autor Peter Belcak on NVIDIA tehisintellekti uurija, kes keskendub agentipõhiste süsteemide usaldusväärsusele ja tõhususele. Artikkel tugineb kolmele sambale:
SLM-id on
- piisavalt võimas
- kirurgiliselt sobiv ja
- majanduslikult vajalik
paljude kasutusjuhtude jaoks agentiivsetes tehisintellekti süsteemides.
Teadlased rõhutavad selgesõnaliselt, et käesolevas artiklis väljendatud seisukohad on autorite seisukohad ega kajasta tingimata NVIDIA kui ettevõtte seisukohta. NVIDIA kutsub üles kriitilisele arutelule ja kohustub avaldama kogu sellega seotud kirjavahetuse kaasneval veebisaidil.
Miks detsentraliseeritud väikesed keelemudelid muudavad tsentraliseeritud infrastruktuuri iganenuks?
Tehisintellekt on pöördepunktis, mille tagajärjed meenutavad dot-com-mulli murranguid. NVIDIA uurimistöö paljastas kapitali põhimõttelise valejaotuse, mis kõigutab ettevõtte praeguse tehisintellekti strateegia alustalasid. Samal ajal kui tehnoloogiatööstus investeeris 57 miljardit dollarit tsentraliseeritud taristusse suuremahuliste keelemudelite jaoks, kasvas nende tegelik turg kõigest 5,6 miljardi dollarini. See kümnekordne lahknevus mitte ainult ei tähista nõudluse ülehindamist, vaid paljastab ka põhimõttelise strateegilise vea tehisintellekti tuleviku osas.
Halb investeering? Miljardid kulutatud tehisintellekti taristule – mida teha üleliigse võimsusega?
Numbrid räägivad enda eest. Erinevate analüüside kohaselt ulatusid 2024. aastal tehisintellekti taristule tehtavad ülemaailmsed kulutused 80–87 miljardi dollarini, kusjuures valdava enamuse moodustasid andmekeskused ja kiirendid. Microsoft teatas 80 miljardi dollari suurustest investeeringutest 2025. eelarveaastaks, Google tõstis oma prognoosi 91–93 miljardi dollarini ja Meta plaanib investeerida kuni 70 miljardit dollarit. Ainuüksi need kolm hüperskaleerijat esindavad investeeringute mahtu üle 240 miljardi dollari. McKinsey hinnangute kohaselt võivad tehisintellekti taristule tehtavad kogukulutused 2030. aastaks ulatuda 3,7–7,9 triljoni dollarini.
Seevastu nõudluse poolne reaalsus on kainestav. Ettevõtete suurkeelte mudelite turu suuruseks hinnati 2024. aastal vaid 4–6,7 miljardit dollarit, samas kui 2025. aasta prognoosid jäävad vahemikku 4,8–8 miljardit dollarit. Isegi kõige heldemad hinnangud generatiivse tehisintellekti turu kohta tervikuna jäävad 2024. aastaks vahemikku 28–44 miljardit dollarit. Põhimõtteline lahknevus on selge: infrastruktuur ehitati turu jaoks, mida sellises vormis ja ulatuses ei eksisteeri.
See valeinvesteering tuleneb üha enam valeks osutuvast eeldusest: tehisintellekti tulevik peitub üha suuremates, tsentraliseeritud mudelites. Hüperskaleerijad järgisid massilise skaleerimise strateegiat, mida ajendas veendumus, et parameetrite arv ja arvutusvõimsus olid otsustavad konkurentsitegurid. GPT-3 oma 175 miljardi parameetriga peeti 2020. aasta läbimurdeks ja GPT-4 oma üle triljoni parameetriga seadis uued standardid. Tööstusharu järgis seda loogikat pimesi ja investeeris infrastruktuuri, mis oli loodud enamiku kasutusjuhtude jaoks ülemõõduliste mudelite vajaduste jaoks.
Investeeringute struktuur illustreerib selgelt ebaõiget jaotamist. 2025. aasta teises kvartalis läks 98 protsenti tehisintellekti taristule kulutatud 82 miljardist dollarist serveritele, millest 91,8 protsenti läks GPU- ja XPU-kiirendusega süsteemidele. Hüperskaleerijad ja pilveteenuste ehitajad neelasid neist kulutustest 86,7 protsenti ehk ühe kvartali jooksul ligikaudu 71 miljardit dollarit. See kapitali koondumine ülispetsialiseeritud ja äärmiselt energiamahukasse riistvarasse massiivsete mudelite koolitamiseks ja tuletamiseks eiras olulist majanduslikku reaalsust: enamik ettevõtterakendusi ei vaja seda võimsust.
Paradigma on purunemas: tsentraliseeritud ja detsentraliseeritud
NVIDIA ise, hiljutise taristubuumi peamine kasusaaja, pakub nüüd analüüsi, mis seab selle paradigma kahtluse alla. Väikeste keelemudelite kui agendipõhise tehisintellekti tuleviku uuring väidab, et alla 10 miljardi parameetriga mudelid on enamiku tehisintellekti rakenduste jaoks mitte ainult piisavad, vaid ka operatiivselt paremad. Kolme suure avatud lähtekoodiga agentsüsteemi uuring näitas, et 40–70 protsenti suurte keelemudelite kõnedest saaks asendada spetsiaalsete väikeste mudelitega ilma jõudluse languseta.
Need leiud kõigutavad olemasoleva investeerimisstrateegia põhieeldusi. Kui MetaGPT suudab asendada 60 protsenti oma LLM-kõnedest, Open Operatori 40 protsenti ja Cradle'i 70 protsenti SLM-idega, siis on infrastruktuuri läbilaskevõime ehitatud nõudmiste jaoks, mida sellises mastaabis ei eksisteeri. Majanduslik muutus dramaatiliselt: Llama 3.1B väikekeelte mudel maksab kümme kuni kolmkümmend korda vähem opereerida kui tema suurem vaste, Llama 3.3 405B. Peenhäälestamist saab teha mõne GPU-tunni, mitte nädalate jooksul. Paljud SLM-id töötavad tarbijariistvaral, välistades täielikult pilvesõltuvused.
Strateegiline nihe on põhimõtteline. Kontroll liigub taristupakkujatelt operaatoritele. Kui eelmine arhitektuur sundis ettevõtteid sõltuvusse vähestest hüperskaleerijatest, siis detsentraliseerimine SLM-ide kaudu võimaldab uut autonoomiat. Mudelid saavad töötada lokaalselt, andmed jäävad ettevõtte siseseks, API-kulud kaovad ja tarnijaga seotus kaob. See ei ole ainult tehnoloogiline ümberkujundamine, vaid ka võimupoliitika ümberkujundamine.
Varasem panus tsentraliseeritud suuremahulistele mudelitele põhines eksponentsiaalse skaleerimisefekti eeldusel. Empiirilised andmed räägivad sellele aga üha enam vastu. 7 miljardi parameetriga Microsoft Phi-3 saavutab koodi genereerimise jõudluse, mis on võrreldav 70 miljardi parameetriga mudelitega. 9 miljardi parameetriga NVIDIA Nemotron Nano 2 edestab arutlustestides Qwen3-8B-d kuuekordse läbilaskevõimega. Efektiivsus parameetri kohta suureneb väiksemate mudelite puhul, samas kui suured mudelid aktiveerivad antud sisendi jaoks sageli vaid murdosa oma parameetritest – see on loomupärane ebaefektiivsus.
Väikeste keelemudelite majanduslik üleolek
Kulustruktuur paljastab majandusliku reaalsuse jõhkra selgusega. GPT-4 klassi mudelite treenimine on hinnanguliselt üle 100 miljoni dollari, kusjuures Gemini Ultra potentsiaalne maksumus on 191 miljonit dollarit. Isegi suurte mudelite peenhäälestamine konkreetsete domeenide jaoks võib maksta kümneid tuhandeid dollareid GPU aja arvelt. Seevastu SLM-e saab treenida ja peenhäälestada vaid mõne tuhande dollari eest, sageli ühel tipptasemel GPU-l.
Järeldamiskulud näitavad veelgi drastilisemaid erinevusi. GPT-4 maksab ligikaudu 0,03 dollarit 1000 sisendtokeni ja 0,06 dollarit 1000 väljundtokeni kohta, kokku 0,09 dollarit keskmise päringu kohta. Näiteks Mistral 7B maksab SLM-i puhul 0,0001 dollarit 1000 sisendtokeni ja 0,0003 dollarit 1000 väljundtokeni kohta ehk 0,0004 dollarit päringu kohta. See tähendab kulude vähenemist 225 korda. Miljonite päringute puhul moodustab see erinevus märkimisväärseid summasid, mis mõjutavad otseselt kasumlikkust.
Omandiõiguse kogukulu paljastab täiendavaid aspekte. 7 miljardi parameetriga mudeli isehostimine L40S GPU-dega paljasmetallist serverites maksab ligikaudu 953 dollarit kuus. Pilvepõhine peenhäälestus AWS SageMakeriga g5.2xlarge eksemplaridel maksab 1,32 dollarit tunnis, potentsiaalsed koolituskulud algavad väiksemate mudelite puhul 13 dollarist. 24/7 järelduste juurutamine maksaks ligikaudu 950 dollarit kuus. Võrreldes suurte mudelite pideva kasutamise API-kuludega, mis võivad kergesti ulatuda kümnete tuhandete dollariteni kuus, on majanduslik eelis selge.
Rakendamise kiirus on sageli alahinnatud majanduslik tegur. Kuigi suure keelemudeli peenhäälestamine võib võtta nädalaid, on suure keelemudeli mudelid kasutusvalmis tundide või mõne päevaga. Paindlikkus uutele nõuetele kiirelt reageerida, uusi võimalusi lisada või käitumist kohandada saab konkurentsieeliseks. Kiirelt arenevatel turgudel võib see ajaline erinevus olla edu ja ebaedu vahe.
Mastaabisääst on pöördumas. Traditsiooniliselt peeti mastaabisäästu hüperskaleerijate eeliseks, mis säilitavad tohutuid võimsusi ja jaotavad neid paljude klientide vahel. SLM-ide abil saavad aga isegi väiksemad organisatsioonid tõhusalt skaleerida, kuna riistvaranõuded on oluliselt madalamad. Idufirma saab piiratud eelarvega luua spetsialiseeritud SLM-i, mis oma konkreetse ülesande puhul ületab suure, üldise mudeli. Tehisintellekti arendamise demokratiseerimine on muutumas majanduslikuks reaalsuseks.
Häirete tehnilised põhitõed
SLM-e võimaldavad tehnoloogilised uuendused on sama olulised kui nende majanduslikud tagajärjed. Teadmiste destilleerimine, tehnika, mille puhul väiksem õpilasmudel neelab suurema õpetajamudeli teadmised, on osutunud väga tõhusaks. DistilBERT tihendas BERT-i edukalt ja TinyBERT järgis sarnaseid põhimõtteid. Kaasaegsed lähenemisviisid destilleerivad suurte generatiivsete mudelite, näiteks GPT-3, võimekuse oluliselt väiksemateks versioonideks, mis näitavad konkreetsetes ülesannetes võrreldavat või paremat jõudlust.
Protsess kasutab nii õpetaja mudeli pehmeid silte (tõenäosusjaotusi) kui ka algandmete kõvasid silte. See kombinatsioon võimaldab väiksemal mudelil jäädvustada nüansirikkaid mustreid, mis lihtsates sisend-väljundpaarides kaotsi läheksid. Täiustatud destilleerimistehnikad, näiteks samm-sammult destilleerimine, on näidanud, et väikesed mudelid suudavad saavutada paremaid tulemusi kui LLM-id isegi väiksema treeningandmetega. See muudab majanduslikku olukorda põhimõtteliselt: tuhandete GPU-de peal toimuvate kallite ja pikkade treeningtsüklite asemel piisab sihipärastest destilleerimisprotsessidest.
Kvantimine vähendab mudeli kaalude numbrilise esituse täpsust. 32-bitiste või 16-bitiste ujukomaarvude asemel kasutavad kvantiseeritud mudelid 8-bitiseid või isegi 4-bitiseid täisarvude esitusi. Mälunõuded vähenevad proportsionaalselt, järelduskiirus suureneb ja energiatarve langeb. Kaasaegsed kvantimistehnikad minimeerivad täpsuse kadu, jättes jõudluse sageli praktiliselt samaks. See võimaldab juurutamist servaseadmetes, nutitelefonides ja manussüsteemides, mis oleks täiesti täpsete suurte mudelite puhul võimatu.
Kärpimine eemaldab närvivõrkudest üleliigsed ühendused ja parameetrid. Sarnaselt liiga pika teksti redigeerimisega tuvastatakse ja eemaldatakse mittevajalikud elemendid. Struktureeritud kärpimine eemaldab terved neuronid või kihid, samas kui struktureerimata kärpimine eemaldab individuaalsed kaalud. Saadud võrgustruktuur on tõhusam, vajades vähem mälu ja töötlemisvõimsust, säilitades samal ajal oma põhivõimalused. Koos teiste tihendustehnikatega saavutavad kärbitud mudelid muljetavaldava efektiivsuse kasvu.
Madala astme faktoriseerimine lagundab suured kaalumaatriksid väiksemate maatriksite korrutisteks. Ühe miljonite elementidega maatriksi asemel salvestab ja töötleb süsteem kahte oluliselt väiksemat maatriksit. Matemaatiline tehe jääb ligikaudu samaks, kuid arvutuslik töömaht väheneb dramaatiliselt. See tehnika on eriti efektiivne transformaatorarhitektuurides, kus tähelepanu mehhanismid domineerivad suurte maatriksite korrutamistes. Mälu kokkuhoid võimaldab sama riistvaraeelarvega suuremaid kontekstiaknaid või partiide suurusi.
Nende tehnikate kombinatsioon tänapäevastes SLM-ides, nagu Microsoft Phi seeria, Google Gemma või NVIDIA Nemotron, näitab potentsiaali. Phi-2, millel on vaid 2,7 miljardit parameetrit, edestab koondtestides Mistral ja Llama-2 mudeleid vastavalt 7 ja 13 miljardi parameetriga ning saavutab mitmeastmelistes arutlusülesannetes parema jõudluse kui 25 korda suurem Llama-2-70B. See saavutati strateegilise andmete valiku, kvaliteetsete sünteetiliste andmete genereerimise ja uuenduslike skaleerimistehnikate abil. Sõnum on selge: suurus ei ole enam võimekuse näitaja.
Turudünaamika ja asendamispotentsiaal
Reaalsete rakenduste empiirilised leiud toetavad teoreetilisi kaalutlusi. NVIDIA analüüs MetaGPT-i, mitme agendiga tarkvaraarendusraamistiku, kohta näitas, et ligikaudu 60 protsenti LLM-päringutest on asendatavad. Nende ülesannete hulka kuuluvad mallipõhise koodi genereerimine, dokumentatsiooni loomine ja struktureeritud väljund – kõik need on valdkonnad, kus spetsialiseeritud SLM-id toimivad kiiremini ja kulutõhusamalt kui üldotstarbelised ja suuremahulised mudelid.
Töövoo automatiseerimissüsteem Open Operator demonstreerib oma 40-protsendilise asenduspotentsiaaliga, et isegi keerukates orkestreerimisstsenaariumides ei vaja paljud alamülesanded LLM-ide täielikku võimsust. Kavatsuse parsimist, mallipõhist väljundit ja marsruutimisotsuseid saab tõhusamalt käsitleda peenhäälestatud väikeste mudelite abil. Ülejäänud 60 protsenti, mis tegelikult nõuavad sügavat arutluskäiku või laia maailma tundmist, õigustab suurte mudelite kasutamist.
Cradle, graafilise kasutajaliidese automatiseerimissüsteem, näitab suurimat asenduspotentsiaali, 70 protsenti. Korduvad kasutajaliidese interaktsioonid, klõpsujärjestused ja vormide sisestamised sobivad ideaalselt SLM-idele. Ülesanded on kitsalt määratletud, varieeruvus on piiratud ja kontekstuaalse mõistmise nõuded on madalad. Spetsialiseeritud GUI-interaktsioonidele treenitud mudel ületab üldist LLM-i kiiruse, usaldusväärsuse ja kulude poolest.
Need mustrid korduvad eri rakendusvaldkondades. Klienditeeninduse vestlusrobotid KKK, dokumentide klassifitseerimise, sentimentaalsuse analüüsi, nimetatud üksuste tuvastamise, lihtsate tõlgete ja loomuliku keele andmebaasipäringute jaoks – kõik need ülesanded saavad kasu SLM-idest. Ühe uuringu kohaselt langeb tüüpilistes ettevõtte tehisintellekti juurutustes 60–80 protsenti päringutest kategooriatesse, mille jaoks SLM-id on piisavad. Sellel on märkimisväärne mõju taristu nõudlusele.
Mudeli marsruutimise kontseptsioon on muutumas üha olulisemaks. Intelligentsed süsteemid analüüsivad sissetulevaid päringuid ja marsruutivad need sobivale mudelile. Lihtsad päringud lähevad kulutõhusatele SLM-idele, samas kui keerulisi ülesandeid täidavad suure jõudlusega LLM-id. See hübriidlähenemine optimeerib kvaliteedi ja kulude tasakaalu. Varased rakendused näitavad kuni 75-protsendilist kulusäästu sama või isegi parema üldise jõudluse juures. Marsruutimise loogika ise võib olla väike masinõppemudel, mis võtab arvesse päringu keerukust, konteksti ja kasutaja eelistusi.
Täppishäälestamise teenusena platvormide levik kiirendab nende kasutuselevõttu. Ettevõtted, kellel puudub põhjalik masinõppealane kogemus, saavad luua spetsiaalseid masinõppesüsteeme (SLM), mis hõlmavad nende omandiõigusega kaitstud andmeid ja valdkonna eripärasid. Ajakulu väheneb kuudest päevadeni ja maksumus sadadest tuhandetest dollaritest tuhandeteni. See ligipääsetavus demokratiseerib tehisintellekti innovatsiooni põhimõtteliselt ja nihutab väärtusloome infrastruktuuri pakkujatelt rakenduste arendajatele.
Digitaalse transformatsiooni uus dimensioon hallatud tehisintellekti (AI) abil - platvorm ja B2B-lahendus | Xpert Consulting


Digitaalse transformatsiooni uus dimensioon hallatud tehisintellekti (AI) abil – platvorm ja B2B-lahendus | Xpert Consulting - pilt: Xpert.Digital
Siit saate teada, kuidas teie ettevõte saab kiiresti, turvaliselt ja ilma kõrgete sisenemisbarjäärideta rakendada kohandatud tehisintellekti lahendusi.
Hallatud tehisintellekti platvorm on teie igakülgne ja muretu tehisintellekti pakett. Keerulise tehnoloogia, kalli infrastruktuuri ja pikkade arendusprotsesside asemel saate spetsialiseerunud partnerilt teie vajadustele vastava võtmed kätte lahenduse – sageli juba mõne päeva jooksul.
Peamised eelised lühidalt:
⚡ Kiire teostus: Ideest rakenduseni päevade, mitte kuude jooksul. Pakume praktilisi lahendusi, mis loovad kohest väärtust.
🔒 Maksimaalne andmeturve: Teie tundlikud andmed jäävad teie kätte. Garanteerime turvalise ja nõuetele vastava töötlemise ilma andmeid kolmandate osapooltega jagamata.
💸 Finantsriski pole: maksate ainult tulemuste eest. Suured esialgsed investeeringud riist- ja tarkvarasse või personali jäävad täielikult ära.
🎯 Keskendu oma põhitegevusele: Keskendu sellele, mida sa kõige paremini oskad. Meie tegeleme sinu tehisintellekti lahenduse kogu tehnilise juurutamise, käitamise ja hooldusega.
📈 Tulevikukindel ja skaleeritav: teie tehisintellekt kasvab koos teiega. Tagame pideva optimeerimise ja skaleeritavuse ning kohandame mudeleid paindlikult uutele nõuetele.
Lisateavet selle kohta siin:
Kuidas detsentraliseeritud tehisintellekt säästab ettevõtetele miljardeid kulusid
Tsentraliseeritud arhitektuuride varjatud kulud
Ainult otsestele arvutuskuludele keskendumine alahindab tsentraliseeritud LLM-arhitektuuride kogumaksumust. API-sõltuvused loovad struktuurilisi puudusi. Iga päring tekitab kulusid, mis skaleeruvad koos kasutusega. Edukate rakenduste puhul, millel on miljoneid kasutajaid, muutuvad API-tasud domineerivaks kuluteguriks, mis vähendab marginaale. Ettevõtted on lõksus kulustruktuuris, mis kasvab proportsionaalselt eduga, ilma vastava mastaabisäästuta.
API-pakkujate hinnakõikumine kujutab endast äririski. Hinnatõusud, kvoodipiirangud või teenusetingimuste muudatused võivad rakenduse kasumlikkuse üleöö hävitada. Hiljuti suurte pakkujate poolt välja kuulutatud mahupiirangud, mis sunnivad kasutajaid oma ressursse jaotama, näitavad selle sõltuvuse haavatavust. Spetsiaalsed SLM-id välistavad selle riski täielikult.
Andmete suveräänsus ja vastavus nõuetele on muutumas üha olulisemaks. Isikuandmete kaitse üldmäärus (GDPR) Euroopas, võrreldavad eeskirjad kogu maailmas ja üha suurenevad andmete lokaliseerimise nõuded loovad keerulisi õigusraamistikke. Tundlike ettevõtteandmete saatmine välistele API-dele, mis võivad tegutseda välisriikides, kaasneb regulatiivsete ja juriidiliste riskidega. Tervishoiu-, finants- ja valitsussektoris kehtivad sageli ranged nõuded, mis välistavad või piiravad oluliselt väliste API-de kasutamist. Kohapealsed SLM-id lahendavad need probleemid põhimõtteliselt.
Intellektuaalomandiga seotud mured on reaalsed. Iga API pakkujale saadetud päring võib potentsiaalselt paljastada omandiõigusega kaitstud teavet. Äriloogika, tootearendused, klienditeave – pakkuja saaks seda kõike teoreetiliselt hankida ja kasutada. Lepingutingimused pakuvad piiratud kaitset juhuslike lekete või pahatahtlike osalejate eest. Ainus tõeliselt turvaline lahendus on mitte kunagi andmeid väliseks edastada.
Latentsus ja töökindlus kannatavad võrgusõltuvuste tõttu. Iga pilve API päring läbib interneti infrastruktuuri, mis on allutatud võrgu värinale, pakettide kadumisele ja muutuvatele edasi-tagasi aegadele. Reaalajas rakenduste, näiteks vestluspõhise tehisintellekti või juhtimissüsteemide puhul on need viivitused vastuvõetamatud. Kohalikud SLM-id vastavad millisekundites sekundite asemel, olenemata võrgutingimustest. Kasutajakogemus on märkimisväärselt paranenud.
Strateegiline sõltuvus vähestest hüperskaleerijatest koondab võimu ja tekitab süsteemseid riske. Turgu domineerivad AWS, Microsoft Azure, Google Cloud ja mõned teised. Nende teenuste katkestustel on duaalse mõjuga tuhandetele sõltuvatele rakendustele. Koondamise illusioon kaob, kui arvestada, et enamik alternatiivseid teenuseid tugineb lõppkokkuvõttes samale piiratud hulgale mudelipakkujatele. Tõeline vastupidavus nõuab mitmekesistamist, ideaaljuhul ka ettevõttesisest võimsust.
Sobib selleks:

Äärisarvutus kui strateegiline pöördepunkt
SLM-ide ja servalarvutuse lähenemine loob murrangulise dünaamika. Servaarvutuse juurutamine toob arvutused sinna, kust andmed pärinevad – IoT-anduritesse, mobiilseadmetesse, tööstuskontrolleritesse ja sõidukitesse. Latentsusaja vähenemine on dramaatiline: sekunditest millisekunditeni, pilve edasi-tagasi töötlemisest lokaalse töötlemiseni. Autonoomsete süsteemide, liitreaalsuse, tööstusautomaatika ja meditsiiniseadmete puhul on see mitte ainult soovitav, vaid ka hädavajalik.
Ribalaiuse kokkuhoid on märkimisväärne. Pidevate andmevoogude asemel pilve, kus neid töödeldakse ja tulemused tagasi saadetakse, toimub töötlemine lokaalselt. Edastatakse ainult asjakohast ja koondatud teavet. Tuhandete servaseadmetega stsenaariumides vähendab see võrguliiklust suurusjärkude võrra. Infrastruktuurikulud vähenevad, võrgu ummistust välditakse ja töökindlus suureneb.
Privaatsus on loomupäraselt kaitstud. Andmed ei lahku enam seadmest. Kaamerapildid, helisalvestised, biomeetriline teave, asukohaandmed – kõike seda saab töödelda lokaalselt ilma keskserveritesse jõudmata. See lahendab pilvepõhiste tehisintellekti lahendustega kaasnevad põhimõttelised privaatsusprobleemid. Tarbijarakenduste puhul muutub see eristavaks teguriks; reguleeritud tööstusharudes muutub see nõudeks.
Energiatõhusus paraneb mitmel tasandil. Spetsiaalsed tehisintellekti kiibid, mis on optimeeritud väikeste mudelite järeldamiseks, tarbivad murdosa andmekeskuste graafikaprotsessorite energiast. Andmeedastuse kaotamine säästab energiat võrguinfrastruktuuris. Akutoitel seadmete puhul on see muutumas põhifunktsiooniks. Nutitelefonid, kantavad seadmed, droonid ja IoT-andurid saavad täita tehisintellekti funktsioone ilma aku tööiga dramaatiliselt mõjutamata.
Võrguühenduseta funktsionaalsus loob töökindluse. Edge AI töötab ka ilma internetiühenduseta. Funktsionaalsus säilib kaugetes piirkondades, kriitilises infrastruktuuris või katastroofiolukordades. See sõltumatus võrgu kättesaadavusest on paljude rakenduste jaoks hädavajalik. Autonoomne sõiduk ei saa loota pilveühendusele ja meditsiiniseade ei tohi ebastabiilse WiFi tõttu rikki minna.
Kulumudelid nihkuvad tegevuskuludelt kapitalikuludele. Pidevate pilvekulude asemel tehakse ühekordne investeering servapidatusse. See muutub majanduslikult atraktiivseks pikaajaliste ja suuremahuliste rakenduste jaoks. Prognoositavad kulud parandavad eelarve planeerimist ja vähendavad finantsriske. Ettevõtted saavutavad taas kontrolli oma tehisintellekti taristukulude üle.
Näited demonstreerivad potentsiaali. NVIDIA ChatRTX võimaldab lokaalset LLM-järeldamist tarbijatele mõeldud GPU-del. Apple integreerib seadmesisese tehisintellekti iPhone'idesse ja iPadidesse, kusjuures väiksemad mudelid töötavad otse seadmes. Qualcomm arendab nutitelefonide jaoks spetsiaalselt servapiibriga tehisintellekti jaoks mõeldud NPU-sid. Google Coral ja sarnased platvormid on suunatud asjade internetile ja tööstusrakendustele. Turudünaamika näitab selget suundumust detsentraliseerimise suunas.
Heterogeensed tehisintellekti arhitektuurid tulevikumudelina
Tulevik ei peitu absoluutses detsentraliseerimises, vaid intelligentsetes hübriidarhitektuurides. Heterogeensed süsteemid kombineerivad rutiinsete ja latentsustundlike ülesannete jaoks servapõhiseid SLM-e pilvepõhiseid LLM-e keerukate arutlusnõuete jaoks. See täiendavus maksimeerib tõhusust, säilitades samal ajal paindlikkuse ja võimekuse.
Süsteemi arhitektuur koosneb mitmest kihist. Äärekihis pakuvad kõrgelt optimeeritud SLM-id koheseid vastuseid. Need peaksid 60–80 protsenti päringutest autonoomselt töötlema. Ebamääraste või keerukate päringute puhul, mis ei vasta kohalikele usalduskünnistele, toimub eskalatsioon uduarvutuse kihile – piirkondlikele serveritele keskmise suurusega mudelitega. Ainult tõeliselt keerulised juhtumid jõuavad tsentraalsesse pilveinfrastruktuuri suurte ja üldotstarbeliste mudelitega.
Mudelmarsruutimine on muutumas kriitiliseks komponendiks. Masinõppel põhinevad ruuterid analüüsivad päringu omadusi: teksti pikkust, keerukusnäitajaid, domeenisignaale ja kasutajaajalugu. Nende omaduste põhjal määratakse päring sobivale mudelile. Kaasaegsed ruuterid saavutavad keerukuse hindamisel üle 95% täpsuse. Nad optimeerivad pidevalt tegeliku jõudluse ja kulu-kvaliteedi kompromisside põhjal.
Täiustatud marsruutimissüsteemide risttähelepanu mehhanismid modelleerivad päringu ja mudeli interaktsioone otsesõnu. See võimaldab teha nüansirikkaid otsuseid: kas Mistral-7B on piisav või on vaja GPT-4? Kas Phi-3 saab sellega hakkama või on vaja Claude'i? Nende otsuste detailne olemus, mis on korrutatud miljonite päringute vahel, loob märkimisväärse kulude kokkuhoiu, säilitades samal ajal kasutajate rahulolu või parandades seda.
Töökoormuse iseloomustamine on ülioluline. Agentsed tehisintellekti süsteemid koosnevad orkestreerimisest, arutluskäigust, tööriistakõnedest, mäluoperatsioonidest ja väljundi genereerimisest. Kõik komponendid ei vaja sama arvutusvõimsust. Orkestreerimine ja tööriistakõned on sageli reeglipõhised või nõuavad minimaalset intelligentsust – ideaalne SLM-ide jaoks. Arutluskäik võib olla hübriidne: lihtne järeldus SLM-ide põhjal, keeruline mitmeastmeline arutluskäik LLM-ide põhjal. Mallide väljundi genereerimine kasutab SLM-e, loomingulise teksti genereerimine kasutab LLM-e.
Kogukulude (TCO) optimeerimine võtab arvesse riistvara heterogeensust. Kriitiliste LLM-töökoormuste jaoks kasutatakse tipptasemel H100 GPU-sid, keskmise hinnaklassi mudelite jaoks keskmise taseme A100 või L40S ja SLM-ide jaoks kulutõhusaid T4 või järeldustele optimeeritud kiipe. See detailsus võimaldab töökoormuse nõudeid riistvara võimalustega täpselt sobitada. Esialgsed uuringud näitavad kogukulude 40–60-protsendilist vähenemist võrreldes homogeensete tipptasemel juurutustega.
Orkestreerimine nõuab keerukaid tarkvarapakke. Kubernetese-põhised klastri haldussüsteemid koos tehisintellektil põhinevate ajastajatega, mis mõistavad mudeli omadusi, on hädavajalikud. Koormuse tasakaalustamine arvestab lisaks päringutele sekundis ka tokeni pikkust, mudeli mälumahtu ja latentsusaja eesmärke. Automaatne skaleerimine reageerib nõudluse mustritele, pakkudes lisavõimsust või vähendades skaleerimist madala kasutusastmega perioodidel.
Jätkusuutlikkus ja energiatõhusus
Tehisintellekti infrastruktuuri keskkonnamõjust on saamas keskne probleem. Ühe suure keelemudeli treenimine võib aastas tarbida sama palju energiat kui väikelinn. Tehisintellektil töötavaid andmekeskusi võib 2028. aastaks koguda 20–27 protsenti ülemaailmsest andmekeskuste energiavajadusest. Prognooside kohaselt võivad tehisintellektil põhinevad andmekeskused 2030. aastaks vajada iga treeningtsükli jaoks 8 gigavatti. Süsiniku jalajälg on võrreldav lennundustööstuse omaga.
Suurte mudelite energiamahukus suureneb ebaproportsionaalselt. Graafikaprotsessorite energiatarve on kolme aastaga kahekordistunud 400 vatilt üle 1000 vati. NVIDIA GB300 NVL72 süsteemid vajavad tohutul hulgal energiat, hoolimata uuenduslikust energiasäästu tehnoloogiast, mis vähendab tippkoormust 30 protsenti. Jahutusinfrastruktuur lisab energianõudlusele veel 30–40 protsenti. Tehisintellekti infrastruktuuri CO2-heide võib 2030. aastaks suureneda 220 miljoni tonni võrra isegi optimistlike eelduste korral võrgu dekarboniseerimise kohta.
Väikesed keelemudelid (SLM-id) pakuvad olulist efektiivsuse kasvu. Koolitamine nõuab 30–40 protsenti võrreldavate LLM-ide arvutusvõimsusest. BERT-i koolitamine maksab umbes 10 000 eurot, võrreldes GPT-4 klassi mudelite sadade miljonitega. Järeldusenergia on proportsionaalselt väiksem. SLM-päring võib tarbida 100–1000 korda vähem energiat kui LLM-päring. Miljonite päringute puhul annab see kokku tohutu kokkuhoiu.
Äärisarvutus võimendab neid eeliseid. Kohalik töötlemine kõrvaldab võrkude ja magistraalinfrastruktuuri kaudu andmeedastuseks vajaliku energia. Spetsiaalsed äärealade tehisintellekti kiibid saavutavad suurusjärkude võrra paremaid energiatõhusustegureid kui andmekeskuste graafikaprotsessorid. Nutitelefonid ja IoT-seadmed, millel on millivatised NPU-d sadade vattide serverite asemel, illustreerivad mastaabi erinevust.
Taastuvenergia kasutamine on muutumas prioriteediks. Google on pühendunud 2030. aastaks 100% süsinikuvabale energiale ja Microsoft süsinikunegatiivsusele. Energianõudluse tohutu ulatus tekitab aga väljakutseid. Isegi taastuvate energiaallikate puhul jääb alles võrgu läbilaskevõime, salvestamise ja katkendlikkuse küsimus. SLM-id vähendavad absoluutset nõudlust, muutes ülemineku rohelisele tehisintellektile teostatavamaks.
Süsinikuteadlik andmetöötlus optimeerib töökoormuse ajastamist võrgu süsiniku intensiivsuse põhjal. Treeningtsüklid käivitatakse siis, kui taastuvenergia osakaal võrgus on maksimaalne. Järeldamistaotlused suunatakse puhtama energiaga piirkondadesse. See ajaline ja geograafiline paindlikkus koos SLM-ide tõhususega võiks vähendada CO2 heitkoguseid 50–70 protsenti.
Regulatiivne maastik muutub rangemaks. ELi tehisintellekti seadus sisaldab teatud tehisintellekti süsteemide kohustuslikku keskkonnamõju hindamist. Süsinikdioksiidiheite aruandlus on muutumas standardiks. Ebaefektiivse ja energiamahuka infrastruktuuriga ettevõtted riskivad vastavusprobleemide ja mainekahjuga. SLM-ide ja servandmetöötluse kasutuselevõtt on muutumas tavalisest vajadusest hädavajalikuks.
Demokratiseerimine versus koondumine
Varasemad arengud on koondanud tehisintellekti võimu mõne võtmeisiku kätte. Domineerivad seitse suurt tegijat – Microsoft, Google, Meta, Amazon, Apple, NVIDIA ja Tesla. Need hüperskaleerijad kontrollivad infrastruktuuri, mudeleid ja üha enam kogu väärtusahelat. Nende ühendatud turukapitalisatsioon ületab 15 triljonit dollarit. Nad moodustavad peaaegu 35 protsenti S&P 500 turukapitalisatsioonist, mis on enneolematu ajaloolise tähtsusega kontsentratsioonirisk.
Sellel koondumisel on süsteemsed tagajärjed. Vähesed ettevõtted kehtestavad standardeid, defineerivad API-sid ja kontrollivad juurdepääsu. Väiksemad tegijad ja arengumaad muutuvad sõltuvaks. Riikide digitaalne suveräänsus on vaidlustatud. Euroopa, Aasia ja Ladina-Ameerika reageerivad riiklike tehisintellekti strateegiatega, kuid USA-s asuvate hüperskaleerijate domineerimine on endiselt tohutu.
Väikesed keelemudelid (SLM-id) ja detsentraliseerimine muudavad seda dünaamikat. Avatud lähtekoodiga SLM-id nagu Phi-3, Gemma, Mistral ja Llama demokratiseerivad juurdepääsu tipptasemel tehnoloogiale. Ülikoolid, idufirmad ja keskmise suurusega ettevõtted saavad arendada konkurentsivõimelisi rakendusi ilma hüperskaleerijate ressurssideta. Innovatsioonibarjäär langeb dramaatiliselt. Väike meeskond saab luua spetsialiseeritud SLM-i, mis oma nišis edestab Google'it või Microsofti.
Majanduslik tasuvus nihkub väiksemate tegijate kasuks. Kuigi õigusteaduse magistriõppe (LLM) arendus nõuab sadade miljonite suuruseid eelarveid, on SLM-id teostatavad viie- kuni kuuekohaliste summadega. Pilve demokratiseerimine võimaldab nõudmisel juurdepääsu koolitusinfrastruktuurile. Teenuste peenhäälestus vähendab keerukust. Tehisintellekti innovatsiooni sisenemistõke väheneb ülemäära kõrgelt hallatavaks.
Andmete suveräänsus saab reaalsuseks. Ettevõtted ja valitsused saavad majutada mudeleid, mis ei jõua kunagi välisserveriteni. Tundlikud andmed jäävad nende endi kontrolli alla. GDPR-i järgimine on lihtsustatud. ELi tehisintellekti seadus, mis kehtestab ranged läbipaistvuse ja vastutuse nõuded, muutub musta kasti API-de asemel patenteeritud mudelite abil paremini hallatavaks.
Innovatsiooni mitmekesisus suureneb. GPT-taoliste mudelite monokultuuri asemel tekivad tuhanded spetsialiseerunud SLM-id kindlate valdkondade, keelte ja ülesannete jaoks. See mitmekesisus on vastupidav süstemaatiliste vigade suhtes, suurendab konkurentsi ja kiirendab edusamme. Innovatsioonimaastik muutub pigem polütsentriliseks kui hierarhiliseks.
Kontsentratsiooni riskid on muutumas ilmsemaks. Sõltuvus vähestest pakkujatest loob üksikuid rikkekohti. AWS-i või Azure'i katkestused halvavad globaalseid teenuseid. Hüperskaleerija poliitilised otsused, näiteks kasutuspiirangud või piirkondlikud töösulud, omavad duaalseid efekte. Detsentraliseerimine SLM-ide kaudu vähendab neid süsteemseid riske oluliselt.
Strateegiline ümberkorraldus
Ettevõtete jaoks eeldab see analüüs põhimõttelisi strateegilisi kohandusi. Investeerimisprioriteedid nihkuvad tsentraliseeritud pilveinfrastruktuurilt heterogeensetele, hajutatud arhitektuuridele. Hüperskaleerivate API-de maksimaalse sõltuvuse asemel on eesmärk autonoomia ettevõttesiseste pilvehalduste kaudu. Oskuste arendamine keskendub mudeli peenhäälestamisele, serval juurutamisele ja hübriidorkestreerimisele.
Otsustusprotsess „ehitus versus ostmine“ on muutumas. Kui varem peeti API-juurdepääsu ostmist ratsionaalseks, siis spetsialiseeritud SLM-ide arendamine ettevõttesiseselt muutub üha atraktiivsemaks. Kolme kuni viie aasta jooksul omamise kogukulud soosivad selgelt ettevõttesiseseid mudeleid. Strateegiline kontroll, andmeturve ja kohanemisvõime lisavad täiendavaid kvalitatiivseid eeliseid.
Investorite jaoks annab see vale jaotus märku ettevaatusabinõust puhtalt infrastruktuuriga seotud tegevuste osas. Andmekeskuste REIT-id, GPU-tootjad ja hüperskaleerijad võivad kogeda ülevõimsust ja vähenevat kasutust, kui nõudlus ei realiseeru prognoositavalt. Väärtuse migratsioon toimub SLM-tehnoloogia, servapiipide, orkestreerimistarkvara ja spetsiaalsete tehisintellekti rakenduste pakkujate suunas.
Geopoliitiline mõõde on oluline. Riigid, mis seavad esikohale riikliku tehisintellekti suveräänsuse, saavad kasu SLM-i nihkest. Hiina investeerib 138 miljardit dollarit kodumaisesse tehnoloogiasse ja Euroopa investeerib InvestAI-sse 200 miljardit dollarit. Need investeeringud on tõhusamad, kui otsustavaks teguriks ei ole enam absoluutne mastaap, vaid pigem nutikad, tõhusad ja spetsialiseeritud lahendused. Mitmepolaarne tehisintellekti maailm on saamas reaalsuseks.
Regulatiivne raamistik areneb paralleelselt. Andmekaitse, algoritmiline vastutus, keskkonnastandardid – kõik see soosib detsentraliseeritud, läbipaistvaid ja tõhusaid süsteeme. Ettevõtted, kes võtavad varakult kasutusele SLM-id ja servandmetöötluse, positsioneerivad end tulevaste regulatsioonide järgimiseks soodsalt.
Talendimaastik on muutumas. Kui varem olid LLM-uuringute jaoks ressursid vaid eliitülikoolidel ja tipptehnoloogiaettevõtetel, siis nüüd saab praktiliselt iga organisatsioon LLM-e arendada. Oskuste puudust, mis takistab 87 protsendil organisatsioonidest tehisintellekti palkamast, leevendatakse väiksema keerukuse ja paremate tööriistadega. Tehisintellektiga toetatud arendusest tulenev tootlikkuse kasv võimendab seda mõju.
Tehisintellekti investeeringute investeeringutasuvuse mõõtmise viis on muutumas. Toore arvutusvõimsuse asemel on põhinäitajaks saamas efektiivsus ülesande kohta. Ettevõtted teatavad tehisintellekti algatuste keskmiseks investeeringutasuvuseks 5,9 protsenti, mis on oodatust oluliselt madalam. Põhjus peitub sageli lihtsate probleemide lahendamiseks liiga suurte ja kallite lahenduste kasutamises. Üleminek ülesannete jaoks optimeeritud SLM-idele võib seda investeeringutasuvust oluliselt parandada.
Analüüs näitab, et tööstusharu on pöördepunktis. 57 miljardi dollari suurune valeinvesteering on enamat kui lihtsalt nõudluse ülehindamine. See kujutab endast tehisintellekti arhitektuuri põhimõttelist strateegilist valearvestust. Tulevik ei kuulu tsentraliseeritud hiiglastele, vaid detsentraliseeritud, spetsialiseeritud ja tõhusatele süsteemidele. Väikesed keelemudelid ei ole suurtest keelemudelitest halvemad – need on enamiku reaalsete rakenduste jaoks paremad. Majanduslikud, tehnilised, keskkonnaalased ja strateegilised argumendid koonduvad selgele järeldusele: tehisintellekti revolutsioon saab olema detsentraliseeritud.
Võimu nihkumine teenusepakkujatelt operaatoritele, hüperskaleerijatelt rakenduste arendajatele, tsentraliseerimiselt levitamisele tähistab tehisintellekti arengus uut etappi. Need, kes selle ülemineku varakult ära tunnevad ja omaks võtavad, on võitjad. Need, kes klammerduvad vana loogika külge, riskivad sellega, et nende kallid infrastruktuurid muutuvad kasutuskõlbmatuks varaks, mille võtavad üle paindlikumad ja tõhusamad alternatiivid. 57 miljardit dollarit pole lihtsalt raisatud – see tähistab juba vananenud paradigma lõpu algust.
Teie ülemaailmne turundus- ja äriarenduspartner
☑️ Meie ärikeel on inglise või sakslane
☑️ Uus: kirjavahetus teie riigikeeles!

Konrad Wolfenstein
Mul on hea meel, et olete teile ja minu meeskonnale isikliku konsultandina kättesaadav.
Võite minuga ühendust võtta, täites siin kontaktvormi või helistage mulle lihtsalt telefonil +49 89 674 804 (München) . Minu e -posti aadress on: Wolfenstein ∂ xpert.digital
Ootan meie ühist projekti.
☑️ VKE tugi strateegia, nõuannete, planeerimise ja rakendamise alal
☑️ digitaalse strateegia loomine või ümberpaigutamine ja digiteerimine
☑️ Rahvusvaheliste müügiprotsesside laiendamine ja optimeerimine
☑️ Globaalsed ja digitaalsed B2B kauplemisplatvormid
☑️ teerajajate äriarendus / turundus / PR / mõõde
🎯🎯🎯 Saa kasu Xpert.Digitali ulatuslikust, viiest astmest koosnevast asjatundlikkusest terviklikus teenustepaketis | BD, R&D, XR, PR ja digitaalse nähtavuse optimeerimine

Saage kasu Xpert.Digitali ulatuslikust, viiekordsest asjatundlikkusest terviklikus teenustepaketis | Teadus- ja arendustegevus, XR, PR ja digitaalse nähtavuse optimeerimine - Pilt: Xpert.Digital
Xpert.digital on sügavad teadmised erinevates tööstusharudes. See võimaldab meil välja töötada kohandatud strateegiad, mis on kohandatud teie konkreetse turusegmendi nõuetele ja väljakutsetele. Analüüsides pidevalt turusuundumusi ja jätkates tööstuse arengut, saame tegutseda ettenägelikkusega ja pakkuda uuenduslikke lahendusi. Kogemuste ja teadmiste kombinatsiooni abil genereerime lisaväärtust ja anname klientidele otsustava konkurentsieelise.
Lisateavet selle kohta siin: