
KI ja SEO koos Bertiga - trafode kahesuunaliste kooderi esitused - mudel loodusliku töötlemise valdkonnas (NLP)

Häälevalik 📢
Avaldatud: 4. oktoober 2024 / UPDATE FROM: 4. oktoober 2024 - Autor: Konrad Wolfenstein

KI ja SEO koos Bertiga - kahesuunaliste kooderi esitused Transformersist - mudel loomuliku keele töötlemise valdkonnas (NLP) - pilt: xpert.digital
Google'i välja töötatud: Bert ja selle tähtsus NLP jaoks - miks teksti kahesuunaline mõistmine on otsustav
🔍🗣️ Bert, mis on lühike kahesuunaliste kooderi esituste jaoks Transformersist, on oluline mudel loomuliku keele töötlemise valdkonnas (NLP), mille töötas välja Google. See on revolutsiooniks muutnud viisi, kuidas masinad keelest aru saavad. Vastupidiselt varasematele mudelitele, mis analüüsisid järjestikku vasakult paremale või vastupidi, lubab Bert kahesuunalist töötlemist. See tähendab, et see kajastab sõna konteksti nii eelmisest kui ka järgmisest tekstijärjestusest. See võime parandab oluliselt keerukate keeleliste suhete mõistmist.
🔍 Berti arhitektuur
Varasematel aastatel oli üks olulisemaid arenguid loodusliku keele töötlemise valdkonnas (loomulik keele töötlemine, NLP), tutvustades trafomudelit, nagu see oli PDF 2017-le, mida vajate kõik, mida vajate paberit ( Wikipedia ). See mudel on välja põhimõtteliselt muutnud, lükates tagasi varem kasutatud struktuurid, näiteks masina tõlke. Selle asemel tugineb see ainult tähelepanu mehhanismidele. Pärast seda on trafo kujundus olnud paljude mudelite aluseks, mis esindavad nüüdisaegset olukorda erinevates valdkondades, näiteks keele genereerimine, tõlkimine ja mujal.
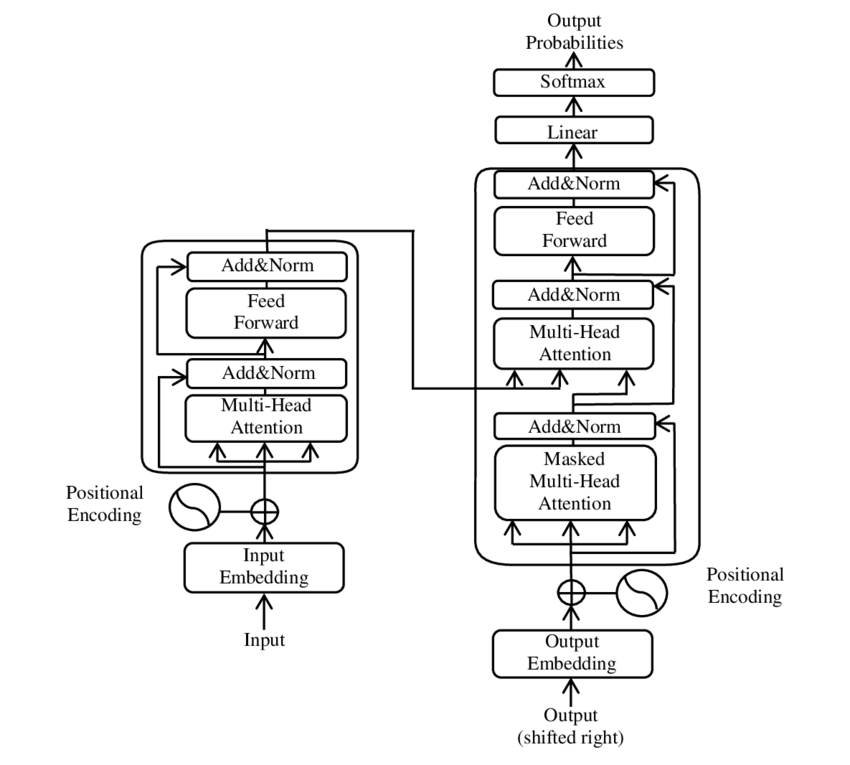
Transformeri mudelipildi põhikomponentide kaardistamine: Google
Bert põhineb sellel trafo arhitektuuril. See arhitektuur kasutab niinimetatud enesekontrolli mehhanisme (enesealuseid), et analüüsida ühe lause sõnade vahelisi seoseid. Iga sõna kogu lause kontekstis pööratakse tähelepanu, mis viib süntaktiliste ja semantiliste suhete täpsema mõistmiseni.
Paberi “Tähelepanu on kõik, mida vajate” autorid on:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Llion Jones (Google Research)
- Aidan N. Gomez (Toronto ülikool, osaliselt läbi viidud Google Brainis)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (sõltumatu, varasem töö Google Research'is)
Need autorid on selles artiklis esitatud trafomudeli väljatöötamisse märkimisväärselt aidanud.
🔄 Kahesuunaline töötlemine
Berti silmapaistev omadus on tema võime töötada kahesuunalisega. Kui sellised traditsioonilised mudelid nagu korduvad neuronaalsed võrgud (RNN) või pikad lühiajalised mäluvõrgud (LSTM) töötlevad tekste ainult ühes suunas, analüüsib BERT sõna konteksti mõlemas suunas. See võimaldab mudelil paremini jäädvustada peent nüansse ja teha seeläbi täpsemaid ennustusi.
🕵️♂️ maskeeritud hääl modelleerimine
Berti teine uuenduslik aspekt on maskeeritud keelemudeli (MLM) tehnoloogia. Juhuslikult valitud sõnad maskeeritakse ühes lauses ja mudelit koolitatakse neid sõnu ennustama ümbritseva konteksti põhjal. See meetod sunnib Berti arendama sügavat mõistmist lauses iga sõna konteksti ja tähenduse kohta.
🚀 Berti koolitamine ja kohandamine
Bert läbib kaheastmelise treeningprotsessi: koolituseelne ja peenhäälestamine.
📚 Eeltreening
Eeltreeningu ajal koolitatakse Berti suures koguses teksti, et õppida üldisi keelemustreid. See hõlmab Vikipeedia tekste ja muid ulatuslikke tekstkorpuseid. Selles etapis saab mudel tundma põhikirjulikke struktuure ja kontekste.
🔧 Peenhäälestamine
Pärast koolitust kohandatakse BERT konkreetsete NLP-ülesannete jaoks, näiteks teksti klassifitseerimise või sentimentaalse analüüsi jaoks. Mudelit koolitatakse väiksema, ülesandega seotud andmekirjetega, et optimeerida selle jõudlust teatud rakenduste jaoks.
🌍 Berti rakendusvaldkonnad
Bert on osutunud äärmiselt kasulikuks paljudes looduslike keele töötlemise valdkondades:
Otsimootori optimeerimine
Google kasutab Berti otsingupäringute paremaks mõistmiseks ja asjakohasemate tulemuste kuvamiseks. See parandab märkimisväärselt kasutajakogemust.
Tekstiklassifikatsioon
BERT saab dokumente kategoriseerida vastavalt teemadele või analüüsida tekstides meeleolu.
Nimetatud üksuse tunnustamine (närvi)
Mudel tuvastab ja klassifitseerib nimetatud üksused sellistes tekstides nagu isiklikud, kohad või organisatsioonilised nimed.
Küsimuste ja vastuste süsteemid
Berti kasutatakse esitatud küsimustele täpsete vastuste saamiseks.
🧠 Berti tähendus AI tuleviku jaoks
Bert on seadnud NLP mudelite jaoks uued standardid ja sillutanud teed edasisteks uuendusteks. Kuna see on võimeline töötlema kahesuunalist ja keele konteksti sügavat mõistmist, on see märkimisväärselt suurendanud AI -rakenduste tõhusust ja täpsust.
🔜 Edasised arengud
BERT ja sarnaste mudelite edasise arendamise eesmärk on olla veelgi võimsamate süsteemide loomine. Need võiksid hakkama keerukamate häälülesannetega ja neid kasutatakse paljudes uutes rakenduspiirkondades. Selliste mudelite integreerimine igapäevastesse tehnoloogiatesse võib põhimõtteliselt muuta meie suhtlust arvutitega.
🌟 Tehisintellekti arendamise verstapost
Bert on tehisintellekti arendamisel verstapost ja on revolutsiooniliselt muutnud masinate loomuliku keele töötlemise viisi. Selle kahesuunaline arhitektuur võimaldab sügavamat mõista keelelisi suhteid, mis muudab selle mitmesuguste rakenduste jaoks hädavajalikuks. Progressiivse uurimistöö abil mängivad sellised mudelid nagu BERT jätkuvalt keskset rolli AI -süsteemide parandamisel ja nende kasutamiseks uute võimaluste avamisel.
📣 Sarnased teemad
- 📚 Sissejuhatus BERT: murranguline NLP mudel
- 🔍 Bert ja kahesuunalisuse roll NLP -s
- 🧠 Transformeri mudel: Berti juhtumi kivi
- 🚀 Maskeeritud hääle modelleerimine: Berti edu võti
- 📈 Berti kohandamine: alates treeningust kuni peenhäälestamiseni
- 🌐 Berti rakendusalad kaasaegses tehnoloogias
- 🤖 Berti mõju tehisintellekti tulevikule
- 💡 Tulevikuväljavaated: Berti edasised arengud
- 🏆 Bert kui AI arengus verstapost
- 📰 Transformeri paberi autorid "Tähelepanu on kõik, mida vajate": Berti taga olevad pead
«
🎯🎯🎯 kasu Xpert.digital ulatuslikust, viiest kogemusest. R&D, XR, PR & SEM

AI ja XR-3D-renderdusmasin: Xpert.digital viis korda asjatundlikkust põhjalikus teeninduspaketis, R&D XR, PR & SEM-IMAGE: Xpert.digital
Xpert.digital on sügavad teadmised erinevates tööstusharudes. See võimaldab meil välja töötada kohandatud strateegiad, mis on kohandatud teie konkreetse turusegmendi nõuetele ja väljakutsetele. Analüüsides pidevalt turusuundumusi ja jätkates tööstuse arengut, saame tegutseda ettenägelikkusega ja pakkuda uuenduslikke lahendusi. Kogemuste ja teadmiste kombinatsiooni abil genereerime lisaväärtust ja anname klientidele otsustava konkurentsieelise.
Lisateavet selle kohta siin:
Bert: Revolutsiooniline 🌟 NLP tehnoloogia
🚀 Bert, mis on lühike kahesuunaliste kooderite esituste jaoks Transformersist, on täiustatud häälmudel, mille on välja töötanud Google ja mille on kujunenud oluliseks läbimurreks loodusliku keele töötlemise valdkonnas (loodusliku keele töötlemine, NLP) alates selle tutvustusest 2018. aastal. See põhineb Transformer Architecture'il, mis muutis teksti mõistmist ja töötlemist. Kuid mis teeb Berti nii eriliseks ja milleks seda kasutatakse? Sellele küsimusele vastamiseks peame tegelema Berti tehniliste põhitõdede, toimimise ja rakendusvaldkondadega.
📚 1. Loodusliku keele töötlemise põhitõed
Berti tähenduse täielikuks mõistmiseks on kasulik reageerida lühidalt loomuliku töötlemise põhitõdedele (NLP). NLP tegeleb arvutite ja inimkeele koostoimega. Eesmärk on õpetada masinaid, analüüsida tekstiandmeid, mõista ja sellele reageerida. Enne selliste mudelite nagu BERT kasutuselevõttu seostati keele mehaanilist töötlemist sageli märkimisväärsete väljakutsetega, eriti tingitud ebaselgusest, kontekstist sõltuvuse ja inimkeele keeruka struktuuri tõttu.
📈 2. NLP mudelite väljatöötamine
Enne Berti sündmuskohale ilmumist põhines enamik NLP mudeleid niinimetatud ühesuunalistel arhitektuuridel. See tähendab, et need mudelid lugesid teksti vasakult paremale või paremale vasakule, mis tähendas, et sõna töötlemisel ühes lauses võisid nad arvestada ainult piiratud koguses konteksti. See piirang viis sageli mudeliteni, mida lause täielik semantiline kontekst ei registreerinud. See tegi mitmetähenduslike või konteksti -tundlike sõnade täpse tõlgenduse.
Veel üks oluline NLP uurimistöö BERTi ees oli Word2VEC mudel, mis võimaldas arvuteid tõlkida vektorites, mis peegeldasid semantilisi sarnasusi. Kuid ka siin piirdus kontekst sõna otsese keskkonnaga. Hilisemad korduvad närvivõrgud (RNN-id) ja eriti pikad lühiajalised mälu (LSTM) mudelid, mis võimaldasid tekstijärjestusi paremini mõista, salvestades teavet mitme sõna kohta. Kuid nendel mudelitel olid oma piirid, eriti kui tegeleda pikkade tekstide ja konteksti samaaegse mõistmisega mõlemas suunas.
🔄 3. Trafo arhitektuuri revolutsioon
Läbimurre tuli Transformeri arhitektuuri kasutuselevõtuga 2017. aastal, mis on Berti aluseks. Transformerimudelid on loodud selleks, et võimaldada teksti paralleelset töötlemist ja võtta arvesse sõna konteksti nii eelmisest kui ka järgmisest tekstist. See juhtub nn enesekontrolli mehhanismide (isepostitava mehhanismi) kaudu, mis määravad igale lausele igale sõnale kaaluväärtuse, lähtudes sellest, kui oluline see on seotud lauses teistega.
Vastupidiselt varasematele lähenemisviisidele ei ole trafomudelid ühesuunalised, vaid kahesuunalised. See tähendab, et sõna ja selle tähenduse täielikuma ja täpsema kujutise loomiseks saate tõmmata teavet vasakult ja sõna paremast kontekstist.
🧠 4. Bert: kahesuunaline mudel
Bert tõstab Transformeri arhitektuuri jõudluse uuele tasemele. Mudeli eesmärk on salvestada sõna kontekst mitte ainult vasakult paremale või paremale vasakule, vaid ka korraga mõlemas suunas. See võimaldab Bertil arvesse võtta lauses sõna täielikku konteksti, mis viib keele töötlemise korral märkimisväärselt paremaks.
Berti keskne omadus on SO -nimelise maskeeritud häälemudeli (maskeeritud keelemudel, MLM) kasutamine. BERT -i koolitusel asendatakse juhuslikult valitud sõnad maskiga ühes lauses ja mudelit koolitatakse konteksti põhjal neid maskeeritud sõnu ära arvama. See tehnoloogia võimaldab Bertil õppida sügavamat ja täpsemat seost ühe lause sõnade vahel.
Lisaks kasutab Bert meetodit, mida nimetatakse järgmise lause ennustamiseks (NSP), milles mudel õpib ennustama, kas üks lause järgib teist või mitte. See parandab Berti võimet mõista pikemaid tekste ja tunnistada keerukamaid suhteid lausete vahel.
🌐 5. Berti kasutamine praktikas
Bert on osutunud eriti kasulikuks mitmesuguste NLP -ülesannete jaoks. Siin on mõned kõige olulisemad rakendusvaldkonnad:
📊 a) Teksti klassifikatsioon
Berti üks levinumaid eesmärke on teksti klassifikatsioon, kus tekstid jagunevad eelnevalt määratletud kategooriateks. Selle näited on sentimentaalne analüüs (nt teadvustamine, kas tekst on positiivne või negatiivne) või klientide tagasiside liigitamine. Sõnade konteksti sügava mõistmise kaudu võib Bert anda täpselt rohkem tulemusi kui varasemad mudelid.
❓ b) Küsimus-vastuste süsteemid
BERT-i kasutatakse ka küsimuste-vastutussüsteemides, kus mudel ekstraheerib vastused teksti küsimustele. See võime on eriti oluline sellistes rakendustes nagu otsingumootorid, vestlusbotid või virtuaalsed assistendid. Tänu oma kahesuunalisele arhitektuurile saab Bert tekstist asjakohase teabe kaevandada, isegi kui küsimus on kaudselt sõnastatud.
🌍 c) Teksti tõlge
Kuigi Bert ise pole otseselt loodud tõlkemudelina, saab seda kasutada koos teiste tehnoloogiatega masina tõlke parandamiseks. Semantiliste suhete parema mõistmise kaudu saab Bert aidata täpseid tõlkeid, eriti mitmetähenduslike või keerukate koostistega.
🏷️ D) nimega olemi äratundmine (ner)
Teine rakendusvaldkond on nimetatud üksuse äratundmine (NER), mis seisneb teatavate üksuste, näiteks nimede, kohtade või organisatsioonide tuvastamisel tekstis. Bert on osutunud eriti tõhusaks selles ülesandes, kuna see võtab täielikult arvesse lause konteksti ja suudab seega üksusi paremini ära tunda, isegi kui neil on erinevates kontekstides erinevad tähendused.
✂️ e) tekst
Berti võime mõista kogu teksti konteksti teeb sellest ka teksti automaatse teksti võimsa tööriista. Seda saab kasutada kõige olulisema teabe eraldamiseks pikast tekstist ja loomiseks lühike kokkuvõte.
🌟 6. Berti tähtsus teadusuuringute ja tööstuse jaoks
BERTi tutvustamine on kuulutanud NLP uurimistöös uut ajastut. See oli üks esimesi mudeleid, mis kasutas täielikult kahesuunalise trafo arhitektuuri jõudlust ja asetas seega mõõdupuu paljudele järgnevatele mudelitele. Paljud ettevõtted ja teadusinstituudid on oma rakenduste toimivuse parandamiseks integreerinud BERT oma NLP torustikku.
Bert sillutas teed ka edasistele uuendustele keelemudelite valdkonnas. Näiteks töötati välja sellised mudelid nagu GPT (generatiivne etteantud trafo) ja T5 (tekst-teksti ülekandetrafo), mis põhinevad sarnastel põhimõtetel, kuid pakuvad erinevate rakenduste jaoks konkreetseid parandusi.
🚧 7. Berti väljakutsed ja piirid
Vaatamata paljudele eelistele on Bertil ka mõned väljakutsed ja piirangud. Üks suurimaid takistusi on kõrge arvutitegevuse pingutus, mis on vajalik treenimiseks ja mudeli kasutamiseks. Kuna Bert on väga suur mudel, millel on miljonite parameetritega, nõuab see võimsat riistvara ja märkimisväärseid aritmeetilisi ressursse, eriti suurte andmete töötlemisel.
Teine probleem on potentsiaalne eelarvamused (eelarvamused), mis võib treeninguandmetes esineda. Kuna Berti on koolitatud suures koguses tekstiandmeid, peegeldab see mõnikord käesolevates andmetes saadaval olevaid eelarvamusi ja stereotüüpe. Teadlased töötavad aga pidevalt nende probleemide tuvastamise ja eemaldamise nimel.
🔍 Elementne tööriist kaasaegsete keeletöötlemise rakenduste jaoks
Bert on märkimisväärselt parandanud, kuidas masinad inimkeelt aru saavad. Oma kahesuunalise arhitektuuri ja uuenduslike koolitusmeetodite abil on see võimeline mõistma sõnade konteksti ühes lauses sügavalt ja täpselt, mis põhjustab paljudes NLP ülesannetes suurema täpsuse. Ükskõik, kas teksti klassifitseerimine, küsimustele reageerimise süsteemid või üksuste tuvastamine-bert on kehtestanud end hädavajaliku vahendina tänapäevaste keeletöötluse rakenduste jaoks.
Loodusliku keele töötlemise valdkonna teadusuuringud on kahtlemata edenevad ja Bert on aluse paljudele tulevastele uuendustele. Vaatamata olemasolevatele väljakutsetele ja piiridele näitab Bert muljetavaldavalt, kui kaugele on tehnoloogia lühikese aja jooksul jõudnud ja millised põnevad võimalused tulevikus avanevad.
🌀 Trafo: revolutsioon loodusliku keele töötlemise valdkonnas
🌟 Viimastel aastatel on üks olulisemaid arenguid loodusliku keele töötlemise valdkonnas (loodusliku keele töötlemine, NLP) olnud trafomudeli kasutuselevõtt, nagu on kirjeldatud 2017. aasta artiklis "Tähelepanu on kõik, mida vajate". See mudel on välja põhimõtteliselt muutnud, lükates edasi varem kasutatud korduvad või konvolutsioonistruktuurid järjestuse ülekande ülesannete jaoks, näiteks masina tõlkeks. Selle asemel tugineb see ainult tähelepanu mehhanismidele. Pärast seda on trafo kujundus olnud paljude mudelite aluseks, mis esindavad nüüdisaegset olukorda erinevates valdkondades, näiteks keele genereerimine, tõlkimine ja mujal.
🔄 Trafo: paradigma nihe
Enne trafo kasutuselevõttu põhines enamik järjestusülesannete mudeleid korduvatel neuronaalsetel võrkudel (RNN) või "Lühiajalise mälu" võrkudel (LSTMS), mis töötavad loomulikult järjestikku. Need mudelid töötlevad sisendandmete samm -sammult ja loovad peidetud tingimusi, mis edastatakse järjestusel. Kuigi see meetod on efektiivne, on see matemaatiliselt keeruline ja seda on raske paralleelne, eriti pikkade järjestuste korral. Lisaks on RNNi raskused pikaajaliste sõltuvuste õppimisel, kuna tekib niinimetatud kaduva gradiendi probleem.
Transformeri keskne uuendus seisneb iseenda mehhanismide kasutamises, mis võimaldab mudelil kaaluda erinevate sõnade olulisust ühes lauses, sõltumata nende positsioonist. See võimaldab mudelil haarata seoseid laialdaselt sõnade vahel tõhusamalt kui RNN -id või LSTM -id ja see on paralleelne, mitte järjestikuse asemel. See mitte ainult ei paranda treeningu tõhusust, vaid ka selliste ülesannete nagu masinõlkimise jõudlust.
🧩 mudeliarhitektuur
Trafo koosneb kahest põhikomponendist: kooderist ja dekoodrist, mis mõlemad koosnevad mitmest kihist ja sõltuvad tugevalt mitmepeajaama mehhanismidest.
⚙️ kodeerija
Kodeerija koosneb kuuest identsest kihist, mõlemal on kaks madalamat klassi:
1. mitmepeaga enese adoratsioon
See mehhanism võimaldab mudelil koondada iga sõna töötlemisel sisendkiiruse erinevatele osadele. Selle asemel, et arvutada tähelepanu ühes toas, projitseerib mitmepeaga jaam panuse mitmesse erinevasse ruumi, mis tähendab, et sõnadevahelisi suhteid saab registreerida.
2. täielikult ühendatud edasisuunalised võrgud
Rünnakukihi kohaselt rakendatakse igas asendis sõltumatult täielikult ühendatud edasisuunamisvõrku. See aitab mudelil töödelda iga sõna kontekstis ja kasutada tähelepanu mehhanismi teavet.
Sisendjärjestuse struktuuri säilitamiseks sisaldab mudel ka positsiooni sisendit (positsioonilise kodeeringuid). Kuna trafo ei töötle sõnu järk -järgult, on need kodeeringud üliolulised, et anda mudeliteavet sõnade järjekorra kohta ühes lauses. Asendi sisendid lisatakse voodisõnale nii, et mudel saaks eristuda järjestuses olevate erinevate positsioonide vahel.
🔍 dekodeer
Nagu kooder, koosneb ka dekoodrit kuuest kihist, iga kihiga on täiendav tähelepanu mehhanism, mis võimaldab mudelil keskenduda sisendjärjestuse asjakohastele osadele, kuni see väljundit genereerib. Dekooder kasutab ka maskeerimise tehnikat, et vältida tulevaste positsioonide arvessevõtmist, mida autor -järjestuse genereerimise autor säilitab.
🧠 Mitmepea jaam ja skalaartoodetejaam
Transformeri süda on mitmepeaga postimehhanism, mis on lihtsama skalaarse tootejaama laienemine. Rünnakufunktsiooni võib pidada illustratsiooniks päringu (päringu) ja võtmeväärtuspaaride lause (võtmed ja väärtused) vahel, iga võti tähistab järjestuses olevat sõna ja väärtus tähistab sellega seotud kontekstuaalset teavet.
Mitmepeajaama mehhanism võimaldab mudelil keskenduda korraga järjestuse erinevatele osadele. Mitmesse alaruumi sisendi projitseerimisega suudab mudel jäädvustada sõnade vahel rikkalikuma hulga seoseid. See on eriti kasulik selliste ülesannete jaoks nagu masinõlkimine, kus sõna konteksti mõistmine nõuab paljusid erinevaid tegureid, näiteks süntaktiline struktuur ja semantiline tähendus.
Scalaarse tootejaama valem on:

Siin (q) Fragmatrix, (k) võtmemaatriks ja (v) väärtuse maatriks. Mõiste (SQRT {D_K}) on skaleerimistegur, mis takistab skalaartoodete liiga suureks muutumist, mis põhjustaks väga väikeseid gradiente ja aeglasemat õppimist. Funktsiooni SoftMaxi kasutatakse selleks, et tagada tähelepanu kaal ühe summa.
🚀 Trafo eelised
Transformer pakub mitmeid olulisi eeliseid traditsiooniliste mudelitega, näiteks RNN -id ja LSTMS:
1. Paralleelne
Kuna trafo töötleb kogu jada korraga, saab seda tugevalt paralleelselt ja seetõttu on palju kiirem treenida kui RNN -id või LSTM -id, eriti suurte andmekogumite puhul.
2. pikaajalised sõltuvused
Isepostitav mehhanism võimaldab mudelil tõhusamalt suhelda kaugete sõnade vahel kui RNN-id, mida piirab nende arvutuste järjestikune olemus.
3. mastaapsus
Trafo saab hõlpsalt skaleerida väga suurte andmekirjete ja pikemate järjestuste korral, ilma et nad kannataksid RNS -iga seotud jõudluse kitsaskohtade all.
🌍 Rakendused ja mõjud
Alates selle kasutuselevõtust on trafost saanud paljude NLP -mudelite aluseks. Üks tähelepanuväärsemaid näiteid on Bert (kahesuunaline kooderi esitus Transformeritest), mis kasutab modifitseeritud trafo arhitektuuri paljudes NLP ülesannetes, sealhulgas küsitlemise ja teksti klassifikatsiooni saavutamiseks.
Veel üks oluline areng on GPT (generatiivne eelkoolitatud trafo), mis kasutab teksti genereerimiseks trafo versiooni. GPT mudeleid, sealhulgas GPT-3, kasutatakse nüüd arvukate rakenduste jaoks, alates sisu loomisest kuni koodi lõpuni.
🔍 võimas ja paindlik mudel
Transformer on NLP ülesannete lahendamise viisi põhimõtteliselt muutnud. See pakub võimsat ja paindlikku mudelit, mida saab kasutada mitmesugustele probleemidele. Tema võime ravida pikaajalisi sõltuvusi ja tõhusus treenimisel on teinud temast paljude moodsaimate mudelite eelistatud arhitektuurilise lähenemisviisi. Progressiivse uurimistöö abil näeme tõenäoliselt trafo täiendavaid parandusi ja kohandusi, eriti sellistes valdkondades nagu pildi ja keele töötlemine, kus tähelepanu mehhanismid näitavad paljulubavaid tulemusi.
Oleme teie jaoks olemas - nõuanne - planeerimine - rakendamine - projektijuhtimine
☑️ tööstusekspert, siin oma Xpert.digital tööstuskeskus üle 2500 spetsialisti panuse

Konrad Wolfenstein
Aitan teid hea meelega isikliku konsultandina.
Võite minuga ühendust võtta, täites alloleva kontaktvormi või helistage mulle lihtsalt telefonil +49 89 674 804 (München) .
Ootan meie ühist projekti.
Kirjutage mulle

Xpert.digital - Konrad Wolfenstein
Xpert.digital on tööstuse keskus, mille fookus, digiteerimine, masinaehitus, logistika/intralogistics ja fotogalvaanilised ained.
Oma 360 ° ettevõtluse arendamise lahendusega toetame hästi tuntud ettevõtteid uuest äritegevusest pärast müüki.
Turuluure, hammastamine, turunduse automatiseerimine, sisu arendamine, PR, postkampaaniad, isikupärastatud sotsiaalmeedia ja plii turgutamine on osa meie digitaalsetest tööriistadest.
Lisateavet leiate aadressilt: www.xpert.digital - www.xpert.solar - www.xpert.plus
Ühendust võtma



















