AI y SEO con BERT – Representaciones de codificador bidireccional de Transformers – Modelo en el campo del procesamiento del lenguaje natural (NLP) – Imagen: Xpert.Digital
🚀💬 Desarrollado por Google: BERT y su importancia para la PNL: por qué la comprensión bidireccional del texto es crucial
🔍🗣️ BERT, abreviatura de Representaciones de codificador bidireccional de Transformers, es un modelo importante en el campo del procesamiento del lenguaje natural (NLP) desarrollado por Google. Ha revolucionado la forma en que las máquinas entienden el lenguaje. A diferencia de los modelos anteriores que analizaban el texto secuencialmente de izquierda a derecha o viceversa, BERT permite el procesamiento bidireccional. Esto significa que captura el contexto de una palabra de la secuencia de texto anterior y posterior. Esta habilidad mejora significativamente la comprensión de contextos lingüísticos complejos.
🔍 La arquitectura de BERT
En los últimos años, uno de los avances más significativos en el campo del procesamiento del lenguaje natural (PNL) se ha producido con la introducción del modelo Transformer, como se presenta en el PDF 2017 - Attention is all you need - paper ( Wikipedia ). Este modelo cambió fundamentalmente el campo al descartar las estructuras utilizadas anteriormente, como la traducción automática. Más bien, se basa exclusivamente en mecanismos de atención. Desde entonces, el diseño del Transformer ha formado la base de muchos modelos que representan el estado del arte en diversas áreas, como la generación de lenguajes, la traducción y más.
Una ilustración de los componentes principales del modelo Transformer - Imagen: Google
BERT se basa en esta arquitectura Transformer. Esta arquitectura utiliza los llamados mecanismos de autoatención para analizar las relaciones entre las palabras de una oración. Se presta atención a cada palabra en el contexto de la oración completa, lo que resulta en una comprensión más precisa de las relaciones sintácticas y semánticas.
Los autores del artículo "La atención es todo lo que necesitas" son:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Cerebro de Google)
- Niki Parmar (investigación de Google)
- Jakob Uszkoreit (investigación de Google)
- León Jones (investigación de Google)
- Aidan N. Gomez (Universidad de Toronto, trabajo parcialmente realizado en Google Brain)
- Lukasz Káiser (Google Brain)
- Illia Polosukhin (Independiente, trabajo anterior en Google Research)
Estos autores contribuyeron significativamente al desarrollo del modelo Transformer presentado en este artículo.
🔄 Procesamiento bidireccional
Una característica destacada de BERT es su capacidad de procesamiento bidireccional. Mientras que los modelos tradicionales, como las redes neuronales recurrentes (RNN) o las redes de memoria a corto plazo (LSTM), solo procesan texto en una dirección, BERT analiza el contexto de una palabra en ambas direcciones. Esto permite que el modelo capture mejor los matices sutiles de significado y, por lo tanto, haga predicciones más precisas.
🕵️♂️ Modelado de lenguaje enmascarado
Otro aspecto innovador de BERT es la técnica del modelo de lenguaje enmascarado (MLM). Implica enmascarar palabras seleccionadas al azar en una oración y entrenar el modelo para predecir estas palabras en función del contexto circundante. Este método obliga a BERT a desarrollar una comprensión profunda del contexto y el significado de cada palabra de la oración.
🚀 Formación y personalización de BERT
BERT pasa por un proceso de formación de dos etapas: formación previa y ajuste.
📚 Pre-entrenamiento
En la capacitación previa, BERT se entrena con grandes cantidades de texto para aprender patrones generales del lenguaje. Esto incluye textos de Wikipedia y otros corpus de texto extensos. En esta fase, el modelo aprende estructuras y contextos lingüísticos básicos.
🔧 Ajuste fino
Después de la capacitación previa, BERT se personaliza para tareas específicas de PNL, como clasificación de texto o análisis de sentimientos. El modelo se entrena con conjuntos de datos más pequeños relacionados con tareas para optimizar su rendimiento para aplicaciones específicas.
🌍 Áreas de aplicación de BERT
BERT ha demostrado ser extremadamente útil en numerosas áreas del procesamiento del lenguaje natural:
Optimización de motores de búsqueda
Google utiliza BERT para comprender mejor las consultas de búsqueda y mostrar resultados más relevantes. Esto mejora enormemente la experiencia del usuario.
Clasificación de texto
BERT puede clasificar documentos por tema o analizar el estado de ánimo en los textos.
Reconocimiento de entidad nombrada (NER)
El modelo identifica y clasifica entidades nombradas en textos, como nombres de personas, lugares u organizaciones.
Sistemas de preguntas y respuestas.
BERT se utiliza para proporcionar respuestas precisas a las preguntas formuladas.
🧠 La importancia de BERT para el futuro de la IA
BERT ha establecido nuevos estándares para los modelos de PNL y ha allanado el camino para futuras innovaciones. A través de su capacidad de procesamiento bidireccional y su profunda comprensión del contexto del lenguaje, ha aumentado significativamente la eficiencia y precisión de las aplicaciones de IA.
🔜 Desarrollos futuros
Es probable que un mayor desarrollo de BERT y modelos similares tenga como objetivo crear sistemas aún más potentes. Estos podrían manejar tareas lingüísticas más complejas y usarse en una variedad de nuevas áreas de aplicación. La integración de estos modelos en las tecnologías cotidianas podría cambiar fundamentalmente la forma en que interactuamos con las computadoras.
🌟 Hito en el desarrollo de la inteligencia artificial
BERT es un hito en el desarrollo de la inteligencia artificial y ha revolucionado la forma en que las máquinas procesan el lenguaje natural. Su arquitectura bidireccional permite una comprensión más profunda de las relaciones lingüísticas, lo que la hace indispensable para una variedad de aplicaciones. A medida que avance la investigación, modelos como BERT seguirán desempeñando un papel central en la mejora de los sistemas de IA y la apertura de nuevas posibilidades para su uso.
📣 Temas similares
- 📚 Presentamos BERT: el innovador modelo de PNL
- 🔍 BERT y el papel de la bidireccionalidad en PNL
- 🧠 El modelo Transformer: piedra angular de BERT
- 🚀 Modelado de lenguaje enmascarado: la clave del éxito de BERT
- 📈 Personalización de BERT: desde el entrenamiento previo hasta el ajuste
- 🌐 Las áreas de aplicación de BERT en la tecnología moderna
- 🤖 La influencia de BERT en el futuro de la inteligencia artificial
- 💡 Perspectivas de futuro: futuros desarrollos de BERT
- 🏆 BERT como hito en el desarrollo de la IA
- 📰 Autores del artículo de Transformer “La atención es todo lo que necesitas”: las mentes detrás de BERT
#️⃣ Hashtags: #PNL #InteligenciaArtificial #Modelado de lenguaje #Transformer #MachineLearning
🎯🎯🎯 Benefíciese de la amplia experiencia quíntuple de Xpert.Digital en un paquete de servicios integral | I+D, XR, relaciones públicas y SEM


Máquina de renderizado 3D AI y XR: experiencia quíntuple de Xpert.Digital en un paquete de servicios integral, I+D XR, PR y SEM - Imagen: Xpert.Digital
Xpert.Digital tiene un conocimiento profundo de diversas industrias. Esto nos permite desarrollar estrategias a medida que se adaptan precisamente a los requisitos y desafíos de su segmento de mercado específico. Al analizar continuamente las tendencias del mercado y seguir los desarrollos de la industria, podemos actuar con previsión y ofrecer soluciones innovadoras. Mediante la combinación de experiencia y conocimiento generamos valor añadido y damos a nuestros clientes una ventaja competitiva decisiva.
Más sobre esto aquí:
BERT: Revolucionaria 🌟 tecnología PNL
🚀 BERT, abreviatura de Representaciones de codificador bidireccional de Transformers, es un modelo de lenguaje avanzado desarrollado por Google que se ha convertido en un avance significativo en el campo del procesamiento del lenguaje natural (PLN) desde su lanzamiento en 2018. Se basa en la arquitectura Transformer, que ha revolucionado la forma en que las máquinas entienden y procesan el texto. Pero, ¿qué hace exactamente a BERT tan especial y para qué se utiliza exactamente? Para responder a esta pregunta, debemos profundizar en los principios técnicos, la funcionalidad y las áreas de aplicación de BERT.
📚 1. Los fundamentos del procesamiento del lenguaje natural
Para comprender completamente el significado de BERT, resulta útil revisar brevemente los conceptos básicos del procesamiento del lenguaje natural (PNL). La PNL se ocupa de la interacción entre las computadoras y el lenguaje humano. El objetivo es enseñar a las máquinas a analizar, comprender y responder a datos de texto. Antes de la introducción de modelos como BERT, el procesamiento automático del lenguaje a menudo presentaba desafíos importantes, particularmente debido a la ambigüedad, la dependencia del contexto y la estructura compleja del lenguaje humano.
📈 2. El desarrollo de modelos de PNL
Antes de que BERT apareciera en escena, la mayoría de los modelos de PNL se basaban en las llamadas arquitecturas unidireccionales. Esto significa que estos modelos solo leen texto de izquierda a derecha o de derecha a izquierda, lo que significa que solo pueden tener en cuenta una cantidad limitada de contexto al procesar una palabra en una oración. Esta limitación a menudo hacía que los modelos no capturaran completamente el contexto semántico completo de una oración. Esto dificultó la interpretación precisa de palabras ambiguas o sensibles al contexto.
Otro desarrollo importante en la investigación de PNL antes de BERT fue el modelo word2vec, que permitía a las computadoras traducir palabras en vectores que reflejaban similitudes semánticas. Pero también aquí el contexto se limitaba al entorno inmediato de una palabra. Posteriormente, se desarrollaron modelos de redes neuronales recurrentes (RNN) y, en particular, de memoria a corto plazo (LSTM), que permitieron comprender mejor las secuencias de texto almacenando información en varias palabras. Sin embargo, estos modelos también tenían sus limitaciones, particularmente cuando se trataba de textos largos y se comprendía el contexto en ambas direcciones al mismo tiempo.
🔄 3. La revolución a través de la arquitectura Transformer
El gran avance se produjo con la introducción de la arquitectura Transformer en 2017, que constituye la base de BERT. Los modelos de transformadores están diseñados para permitir el procesamiento paralelo de texto, teniendo en cuenta el contexto de una palabra tanto del texto anterior como del siguiente. Esto se hace mediante los llamados mecanismos de autoatención, que asignan un valor de peso a cada palabra de una oración en función de su importancia en relación con las demás palabras de la oración.
A diferencia de enfoques anteriores, los modelos Transformer no son unidireccionales, sino bidireccionales. Esto significa que pueden extraer información tanto del contexto izquierdo como del derecho de una palabra, produciendo una representación más completa y precisa de la palabra y su significado.
🧠 4. BERT: Un modelo bidireccional
BERT lleva el rendimiento de la arquitectura Transformer a un nuevo nivel. El modelo está diseñado para capturar el contexto de una palabra no sólo de izquierda a derecha o de derecha a izquierda, sino en ambas direcciones simultáneamente. Esto permite a BERT considerar el contexto completo de una palabra dentro de una oración, lo que resulta en una precisión significativamente mejorada en las tareas de procesamiento del lenguaje.
Una característica central de BERT es el uso del llamado modelo de lenguaje enmascarado (MLM). En el entrenamiento de BERT, las palabras seleccionadas al azar en una oración se reemplazan con una máscara y el modelo se entrena para adivinar estas palabras enmascaradas según el contexto. Esta técnica le permite a BERT aprender relaciones más profundas y precisas entre las palabras de una oración.
Además, BERT utiliza un método llamado Predicción de la siguiente oración (NSP), donde el modelo aprende a predecir si una oración sigue a otra o no. Esto mejora la capacidad de BERT para comprender textos más largos y reconocer relaciones más complejas entre oraciones.
🌐 5. Aplicación de BERT en la práctica
BERT ha demostrado ser extremadamente útil para una variedad de tareas de PNL. Estas son algunas de las principales áreas de aplicación:
📊 a) Clasificación del texto
Uno de los usos más comunes de BERT es la clasificación de textos, donde los textos se dividen en categorías predefinidas. Ejemplos de esto incluyen el análisis de sentimientos (por ejemplo, reconocer si un texto es positivo o negativo) o la categorización de los comentarios de los clientes. BERT puede proporcionar resultados más precisos que los modelos anteriores gracias a su profunda comprensión del contexto de las palabras.
❓ b) Sistemas de preguntas y respuestas
BERT también se utiliza en sistemas de preguntas y respuestas, donde el modelo extrae respuestas a preguntas planteadas de un texto. Esta capacidad es especialmente importante en aplicaciones como motores de búsqueda, chatbots o asistentes virtuales. Gracias a su arquitectura bidireccional, BERT puede extraer información relevante de un texto, incluso si la pregunta se formula de forma indirecta.
🌍 c) Traducción de texto
Si bien BERT en sí no está diseñado directamente como modelo de traducción, puede usarse en combinación con otras tecnologías para mejorar la traducción automática. Al comprender mejor las relaciones semánticas de una oración, BERT puede ayudar a generar traducciones más precisas, especialmente para textos ambiguos o complejos.
🏷️ d) Reconocimiento de entidad nombrada (NER)
Otra área de aplicación es el reconocimiento de entidades nombradas (NER), que implica identificar entidades específicas como nombres, lugares u organizaciones en un texto. BERT ha demostrado ser particularmente eficaz en esta tarea porque tiene plenamente en cuenta el contexto de una oración, lo que la hace mejor para reconocer entidades incluso si tienen diferentes significados en diferentes contextos.
✂️ e) Resumen del texto
La capacidad de BERT para comprender el contexto completo de un texto también lo convierte en una herramienta poderosa para el resumen automático de texto. Se puede utilizar para extraer la información más importante de un texto extenso y crear un resumen conciso.
🌟 6. La importancia de BERT para la investigación y la industria
La introducción de BERT marcó el comienzo de una nueva era en la investigación de la PNL. Fue uno de los primeros modelos en aprovechar al máximo la potencia de la arquitectura Transformer bidireccional, estableciendo el listón para muchos modelos posteriores. Muchas empresas e institutos de investigación han integrado BERT en sus procesos de PNL para mejorar el rendimiento de sus aplicaciones.
Además, BERT ha allanado el camino para futuras innovaciones en el ámbito de los modelos lingüísticos. Por ejemplo, posteriormente se desarrollaron modelos como GPT (Generative Pretrained Transformer) y T5 (Text-to-Text Transfer Transformer), que se basan en principios similares pero ofrecen mejoras específicas para diferentes casos de uso.
🚧 7. Desafíos y limitaciones de BERT
A pesar de sus muchas ventajas, BERT también presenta algunos desafíos y limitaciones. Uno de los mayores obstáculos es el elevado esfuerzo computacional necesario para entrenar y aplicar el modelo. Debido a que BERT es un modelo muy grande con millones de parámetros, requiere hardware potente y recursos informáticos importantes, especialmente cuando se procesan grandes cantidades de datos.
Otro problema es el posible sesgo que puede existir en los datos de entrenamiento. Debido a que BERT está entrenado con grandes cantidades de datos de texto, a veces refleja los sesgos y estereotipos presentes en esos datos. Sin embargo, los investigadores trabajan continuamente para identificar y abordar estos problemas.
🔍 Herramienta esencial para aplicaciones modernas de procesamiento de lenguaje
BERT ha mejorado significativamente la forma en que las máquinas entienden el lenguaje humano. Con su arquitectura bidireccional y métodos de entrenamiento innovadores, es capaz de capturar de manera profunda y precisa el contexto de las palabras en una oración, lo que resulta en una mayor precisión en muchas tareas de PNL. Ya sea en clasificación de textos, sistemas de preguntas y respuestas o reconocimiento de entidades, BERT se ha consolidado como una herramienta indispensable para las aplicaciones modernas de procesamiento del lenguaje.
Sin duda, la investigación sobre el procesamiento del lenguaje natural seguirá avanzando y BERT ha sentado las bases para muchas innovaciones futuras. A pesar de los desafíos y limitaciones existentes, BERT muestra de manera impresionante hasta dónde ha llegado la tecnología en poco tiempo y qué oportunidades interesantes se abrirán aún en el futuro.
🌀 El transformador: una revolución en el procesamiento del lenguaje natural
🌟 En los últimos años, uno de los avances más significativos en el campo del procesamiento del lenguaje natural (PNL) ha sido la introducción del modelo Transformer, como se describe en el artículo de 2017 "La atención es todo lo que necesitas". Este modelo cambió fundamentalmente el campo al descartar las estructuras recurrentes o convolucionales utilizadas anteriormente para tareas de transducción de secuencias como la traducción automática. Más bien, se basa exclusivamente en mecanismos de atención. Desde entonces, el diseño del Transformer ha formado la base de muchos modelos que representan el estado del arte en diversas áreas, como la generación de lenguajes, la traducción y más.
🔄 El Transformador: Un cambio de paradigma
Antes de la introducción del Transformer, la mayoría de los modelos para tareas de secuenciación se basaban en redes neuronales recurrentes (RNN) o redes de memoria a corto plazo (LSTM), que son inherentemente secuenciales. Estos modelos procesan los datos de entrada paso a paso, creando estados ocultos que se propagan a lo largo de la secuencia. Aunque este método es eficaz, es computacionalmente costoso y difícil de paralelizar, especialmente para secuencias largas. Además, los RNN tienen dificultades para aprender dependencias a largo plazo debido al problema del llamado "gradiente de desaparición".
La innovación central del Transformer radica en el uso de mecanismos de autoatención, que permiten al modelo ponderar la importancia de diferentes palabras en una oración entre sí, independientemente de su posición. Esto permite que el modelo capture relaciones entre palabras muy espaciadas de manera más efectiva que los RNN o LSTM, y hacerlo de manera paralela en lugar de secuencialmente. Esto no sólo mejora la eficiencia de la formación, sino también el rendimiento en tareas como la traducción automática.
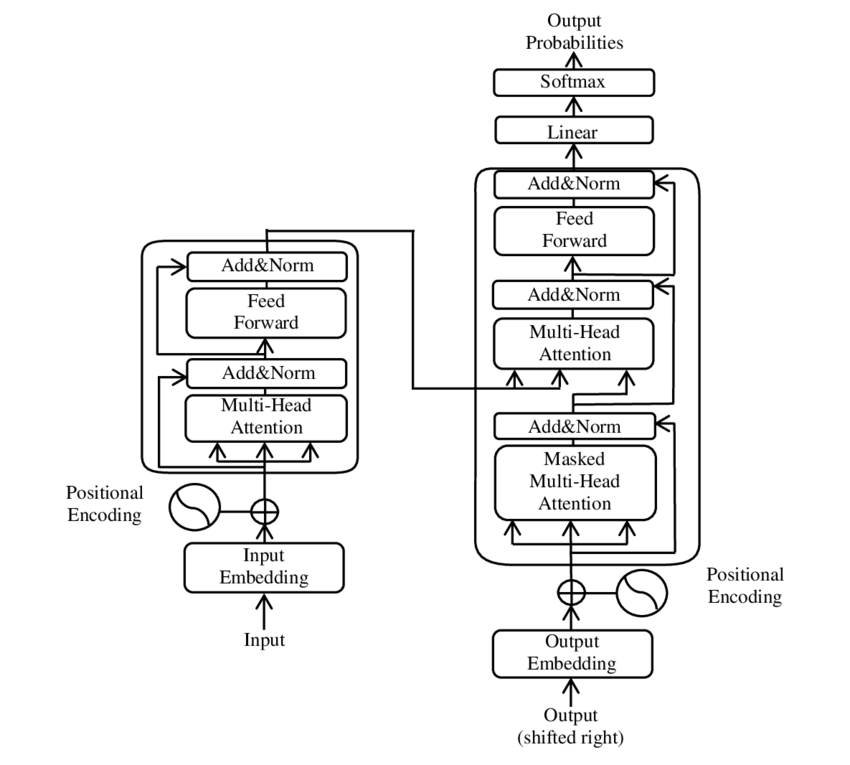
🧩 Arquitectura modelo
El Transformer consta de dos componentes principales: un codificador y un decodificador, los cuales constan de múltiples capas y dependen en gran medida de mecanismos de atención de múltiples cabezales.
⚙️ Codificador
El codificador consta de seis capas idénticas, cada una con dos subcapas:
1. Autoatención de múltiples cabezas
Este mecanismo permite que el modelo se centre en diferentes partes de la oración de entrada mientras procesa cada palabra. En lugar de calcular la atención en un solo espacio, la atención de múltiples cabezas proyecta la entrada en varios espacios diferentes, lo que permite capturar diferentes tipos de relaciones entre palabras.
2. Redes feedforward totalmente conectadas por posición
Después de la capa de atención, se aplica una red feedforward totalmente conectada de forma independiente en cada posición. Esto ayuda al modelo a procesar cada palabra en contexto y utilizar la información del mecanismo de atención.
Para preservar la estructura de la secuencia de entrada, el modelo también contiene entradas posicionales (codificaciones posicionales). Dado que Transformer no procesa las palabras de forma secuencial, estas codificaciones son cruciales para brindarle al modelo información sobre el orden de las palabras en una oración. Las entradas de posición se agregan a las incrustaciones de palabras para que el modelo pueda distinguir entre las diferentes posiciones en la secuencia.
🔍 Decodificadores
Al igual que el codificador, el decodificador también consta de seis capas, y cada capa tiene un mecanismo de atención adicional que permite que el modelo se centre en partes relevantes de la secuencia de entrada mientras genera la salida. El decodificador también utiliza una técnica de enmascaramiento para evitar que considere posiciones futuras, preservando la naturaleza autorregresiva de la generación de secuencias.
🧠 Atención de múltiples cabezales y atención de productos punto
El corazón de Transformer es el mecanismo de atención de múltiples cabezales, que es una extensión de la atención de producto escalar más simple. La función de atención puede verse como un mapeo entre una consulta y un conjunto de pares clave-valor (claves y valores), donde cada clave representa una palabra en la secuencia y el valor representa la información contextual asociada.
El mecanismo de atención de múltiples cabezales permite que el modelo se centre en diferentes partes de la secuencia al mismo tiempo. Al proyectar la entrada en múltiples subespacios, el modelo puede capturar un conjunto más rico de relaciones entre palabras. Esto es particularmente útil en tareas como la traducción automática, donde comprender el contexto de una palabra requiere muchos factores diferentes, como la estructura sintáctica y el significado semántico.
La fórmula para la atención del producto escalar es:

Aquí (Q) es la matriz de consulta, (K) es la matriz clave y (V) es la matriz de valores. El término (sqrt{d_k}) es un factor de escala que evita que los productos escalares se vuelvan demasiado grandes, lo que daría lugar a gradientes muy pequeños y un aprendizaje más lento. La función softmax se aplica para garantizar que los pesos de atención sumen uno.
🚀 Ventajas del Transformador
Transformer ofrece varias ventajas clave sobre los modelos tradicionales como RNN y LSTM:
1. Paralelización
Debido a que Transformer procesa todos los tokens en una secuencia al mismo tiempo, puede estar altamente paralelizado y, por lo tanto, es mucho más rápido de entrenar que los RNN o LSTM, especialmente en grandes conjuntos de datos.
2. Dependencias a largo plazo
El mecanismo de autoatención permite que el modelo capture relaciones entre palabras distantes de manera más efectiva que los RNN, que están limitados por la naturaleza secuencial de sus cálculos.
3. Escalabilidad
Transformer puede escalar fácilmente a conjuntos de datos muy grandes y secuencias más largas sin sufrir los cuellos de botella de rendimiento asociados con los RNN.
🌍 Aplicaciones y efectos
Desde su introducción, Transformer se ha convertido en la base de una amplia gama de modelos de PNL. Uno de los ejemplos más notables es BERT (Representaciones de codificador bidireccional de Transformers), que utiliza una arquitectura Transformer modificada para lograr lo último en muchas tareas de PNL, incluida la respuesta a preguntas y la clasificación de texto.
Otro desarrollo significativo es GPT (Generative Pretrained Transformer), que utiliza una versión limitada de decodificador del Transformer para la generación de texto. Los modelos GPT, incluido GPT-3, ahora se utilizan para una variedad de aplicaciones, desde la creación de contenido hasta la finalización de código.
🔍 Un modelo potente y flexible
Transformer ha cambiado fundamentalmente la forma en que abordamos las tareas de PNL. Proporciona un modelo potente y flexible que se puede aplicar a una variedad de problemas. Su capacidad para manejar dependencias a largo plazo y su eficiencia en la capacitación lo han convertido en el enfoque arquitectónico preferido para muchos de los modelos más modernos. A medida que avance la investigación, probablemente veremos más mejoras y ajustes en el Transformer, particularmente en áreas como el procesamiento de imágenes y lenguaje, donde los mecanismos de atención muestran resultados prometedores.
Estamos a su disposición - asesoramiento - planificación - implementación - gestión de proyectos
☑️ Experto del sector, aquí con su propio centro industrial Xpert.Digital con más de 2500 artículos especializados

Konrad Wolfenstein
Estaré encantado de servirle como su asesor personal.
Puedes contactarme completando el formulario de contacto a continuación o simplemente llámame al +49 89 89 674 804 (Múnich) .
Estoy deseando que llegue nuestro proyecto conjunto.
Escríbeme



Xpert.Digital - Konrad Wolfenstein
Xpert.Digital es un centro industrial centrado en la digitalización, la ingeniería mecánica, la logística/intralogística y la fotovoltaica.
Con nuestra solución de desarrollo empresarial de 360°, apoyamos a empresas reconocidas desde nuevos negocios hasta posventa.
Inteligencia de mercado, smarketing, automatización de marketing, desarrollo de contenidos, relaciones públicas, campañas de correo, redes sociales personalizadas y desarrollo de leads son parte de nuestras herramientas digitales.
Puede obtener más información en: www.xpert.digital - www.xpert.solar - www.xpert.plus
Mantenerse en contacto