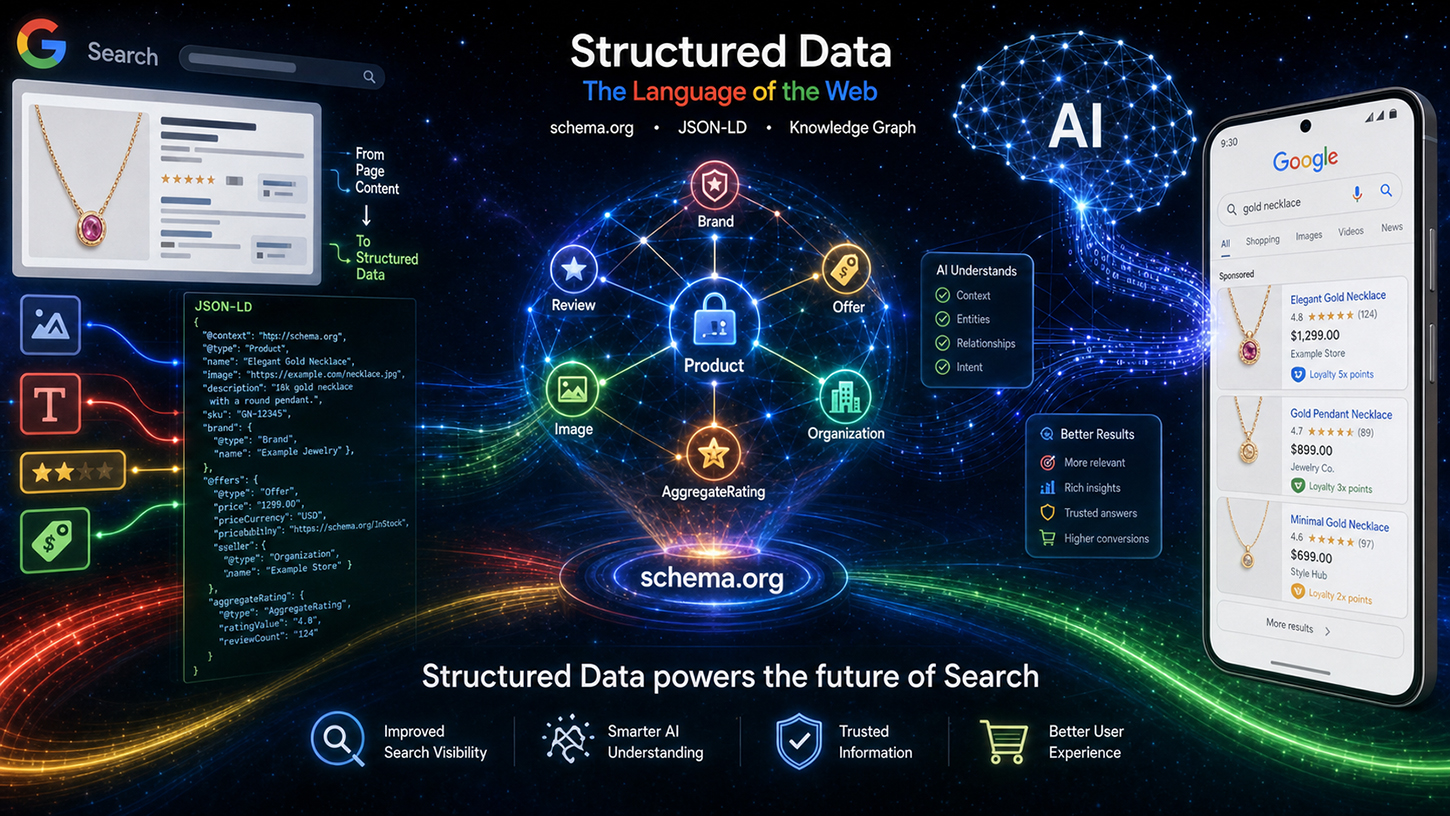
Datos estructurados (marcado) en la era de la IA con Schema.org: Lo que realmente piensan los ingenieros de Google – Imagen: Xpert.Digital
El secreto de SEO de Google: por qué la IA falla sin datos estructurados
A pesar de ChatGPT y compañía: ¿Por qué los ingenieros de Google siguen confiando plenamente en Schema.org?
Actualización de SEO: Por qué Schema.org está desplazando a Open Graph en Google
En el mundo del SEO, persiste un mito: en la era de los brillantes modelos de lenguaje de IA que comprenden sin esfuerzo incluso el texto no estructurado, los datos estructurados, como Schema.org, que requieren un mantenimiento meticuloso, se han vuelto obsoletos. Pero la realidad es muy diferente. En el evento Google Search Central Live, el ingeniero de Google Ryan Levering desmintió esta idea errónea y lo dejó meridianamente claro: el marcado estructurado no es una reliquia del pasado, sino la base fundamental de la nueva búsqueda impulsada por IA.
Desde las nuevas guías de IA hasta los agentes de compra autónomos, los modelos de lenguaje necesitan directrices precisas y legibles por máquina para evitar confusiones y operar de forma eficiente desde el punto de vista computacional. Quienes deseen mantener su visibilidad en la web moderna deben ayudar a las máquinas a comprender el contexto sin ambigüedad. Este artículo analiza la reorientación estratégica de Google, presenta innovaciones revolucionarias para el comercio electrónico y el contenido generado por el usuario, y muestra por qué el SEO técnico es ahora la ventaja competitiva decisiva en la lucha por la visibilidad en la web.
Las máquinas pueden leer la web, pero solo si les ayudas a comprenderla
El 21 de abril de 2026, tuvo lugar en Toronto el primer evento Google Search Central Live celebrado en Canadá, y no fue una reunión cualquiera del sector. Ryan Levering, ingeniero de Google Search Engineering, ofreció la que probablemente fue la presentación más técnica y estratégicamente relevante del día: «Datos estructurados, calidad e IA». Su ponencia fue mucho más que un análisis técnico; fue una clara declaración sobre el futuro de la web semántica en una era donde la inteligencia artificial asume cada vez más el papel de intermediaria entre los usuarios y la información.
Entre dos extremos: la disyuntiva equivocada
Al inicio de su presentación, Ryan Levering contrastó dos opiniones diametralmente opuestas que circulan en la comunidad SEO. Por un lado, está la convicción de que los datos estructurados son simplemente superfluos en la era de los potentes modelos de lenguaje: si los modelos de IA pueden interpretar fácilmente texto no estructurado, ¿para qué molestarse en añadir laboriosamente el marcado schema.org al código fuente? Por otro lado, algunos entusiastas defienden la idea de que los datos estructurados son el futuro de internet: un protocolo de comunicación semántica universal entre agentes de IA autónomos que sustituirá en gran medida a la web tradicional.
Levering rechazó ambos extremos y, en cambio, presentó una perspectiva matizada y con base empírica. Concluyó que ambas posturas contenían una pizca de verdad, pero ninguna describía la realidad por completo. Este matiz es característico del enfoque actual de Google sobre el tema: no se trata de dogmatismo, sino de eficiencia pragmática.
Cuatro argumentos que lo explican todo
El argumento central de Levering se resume en cuatro puntos clave, que desarrolló bajo el título "Valor de los datos estructurados". El primero es la precisión: los datos estructurados ofrecen una exactitud significativamente mayor para esquemas complejos, como precios de venta o programas de fidelización, que la extracción de texto libre basada en modelos de lenguaje natural (LLM). Los modelos de lenguaje pueden ser engañosos: completan atributos faltantes, anidan datos incorrectamente o acceden a información fuera de contexto. Al extraer precios de productos de un sitio de comercio electrónico grande con docenas de artículos similares, la tasa de error es significativamente mayor con la inferencia de IA que con un marcado estructurado bien implementado.
El segundo punto se refiere al contenido adicional: los datos estructurados suelen contener metadatos invisibles que simplemente no están presentes en el HTML generado de una página. Formatos de fecha ISO completos, identificadores estables para contenido generado por el usuario o identificadores internos de entidades: esta información existe exclusivamente en el marcado. Ningún modelo de lenguaje puede extraer lo que no está en el texto.
En tercer lugar, la eficiencia: analizar el marcado estructurado es mucho más económico que procesar un modelo de lenguaje extenso para extraer datos complejos. Google indexa miles de millones de páginas diariamente. El cálculo es sencillo: un analizador sintáctico convencional que procesa JSON-LD consume una fracción de los recursos informáticos que requiere un paso de inferencia de un modelo de lenguaje. Por lo tanto, los datos estructurados no solo son semánticamente superiores, sino que también son significativamente más eficientes desde una perspectiva empresarial. Este punto es de gran relevancia para la infraestructura de Google.
El cuarto aspecto, y quizás el más subestimado, es el enfoque: los datos estructurados resaltan explícitamente la información relevante en una página, impidiendo así que los sistemas de IA seleccionen datos irrelevantes. En una página de producto con un artículo principal, varios productos relacionados y una barra de navegación con precios, un modelo de lenguaje sin anotaciones explícitas no puede determinar con certeza a qué precio referirse. El marcado estructurado resuelve este problema mediante una asignación inequívoca.
Cómo se procesan realmente los datos estructurados
Levering también hizo transparente el flujo de procesamiento técnico. Los datos de Schema.org se procesan primero mediante una limpieza y filtrado específicos antes de ser categorizados como datos indexados, divididos en áreas como eventos, compras y reseñas. Estos datos preparados fluyen luego a dos canales de salida diferentes: por un lado, la página de resultados de búsqueda clásica (SRP) y, por otro, como contexto para los sistemas basados en IA de Google, específicamente las denominadas AI Overviews (AIO) y AI Mode (AIM). De este modo, los datos estructurados ya no son solo una herramienta de resultados enriquecidos, sino una entrada directa para las respuestas generativas de la IA. Esto representa un cambio fundamental en la importancia estratégica del marcado schema.org.
🎯🎯🎯 Centro de datos para la industria B2B como una solución casi interna


La solución casi interna: Cómo Xpert.Digital cierra las brechas operativas en el marketing y las ventas B2B – Negocios inteligentes basados en contenido - Imagen: Xpert.Digital
Xpert.Digital es un centro industrial B2B basado en datos, dirigido por Konrad Wolfenstein . La empresa actúa como una solución externa, casi interna, para socios industriales, cubriendo las brechas operativas en marketing, contenido y ventas, sin requerir recursos adicionales por parte del cliente.
Más información aquí:
Por qué los datos estructurados se están convirtiendo en la infraestructura para los agentes de IA
Compras en detalle: Envíos, fidelización y variaciones
Una parte importante de la presentación se centró en las innovaciones del comercio electrónico. Levering explicó que, según datos del Instituto Baymard, la información de envío inesperada ocupa el segundo y tercer lugar entre las razones más comunes de abandono del carrito de compra. El marcado estructurado para los servicios de envío puede solucionar directamente este problema: los comerciantes ahora pueden definir con precisión las regiones de origen y destino, las dimensiones y los pesos, los umbrales de valor del pedido, los tiempos de procesamiento y las afiliaciones a programas de fidelización directamente en el código.
El modelo de tiempos de envío que utiliza Google se divide en dos fases: el tiempo de procesamiento, es decir, el tiempo transcurrido desde la recepción del pedido hasta su entrega al transportista, y el tiempo de entrega propiamente dicho. Ambas fases pueden anotarse por separado y con gran detalle, incluyendo incluso los plazos límite para realizar pedidos y si el procesamiento se realiza también en días laborables. Los ejemplos JSON-LD correspondientes muestran cómo se puede utilizar el tipo `ShippingConditions` para definir el envío gratuito para determinados países (por ejemplo, Francia y Alemania) y los importes mínimos de pedido (por ejemplo, 50 €).
La integración de los servicios de envío con los programas de fidelización es especialmente innovadora. Mediante la propiedad `validForMemberTier`, un servicio de envío puede vincularse explícitamente a un programa de membresía y a un nivel específico. Esto permite declarar las ventajas de envío para los miembros premium directamente en el marcado, una función que antes solo se podía configurar a través de Google Merchant Center. El programa de fidelización asociado se define como un objeto `MemberProgram` dentro de la entidad `Organization`, con niveles como "Oro" o "Plata" y beneficios asociados como premios de fidelización o recompensas por puntos.
Los programas de fidelización como entidades semánticas
La introducción del marcado de programas de fidelización tiene una gran importancia económica. Las organizaciones pueden definir varios programas de membresía independientes, cada uno con diferentes niveles y beneficios diferenciados: puntos, precios para miembros, políticas de devolución, bonificaciones de envío. Esta información aparece directamente en los resultados de búsqueda de Google, como demostró Levering con ejemplos reales, incluyendo una oferta de Sephora que mostraba un descuento del 30 % para miembros directamente en el fragmento de compra. Según Levering, el siguiente paso previsto es la vinculación entre páginas mediante ID, es decir, la capacidad de enlazar las definiciones de los programas de fidelización desde otras páginas, bajo el título actual de "Abriendo camino a la vinculación entre páginas mediante @id". El objetivo: establecer referencias organizativas más sólidas entre las páginas de productos y las políticas de la empresa.
Contenido generado por el usuario: El problema del etiquetado mediante IA
Otro tema importante fue el desarrollo de esquemas para contenido generado por el usuario (UGC). Dos nuevas características son especialmente relevantes. Primero, se admiten publicaciones y republicaciones incrustadas en el marcado de foros y preguntas y respuestas, lo que permite una representación semántica más precisa de las estructuras de discusión. Segundo, y esto es de aún mayor importancia estratégica, se introduce la propiedad `so#digitalSourceType` para identificar explícitamente el contenido generado por máquinas.
Este avance responde directamente a la avalancha de contenido generado por IA en plataformas como foros y sitios de preguntas y respuestas. Los webmasters ahora pueden indicar si una publicación se generó algorítmicamente o mediante un modelo de lenguaje. Google asume implícitamente que quienes no lo especifican son autores humanos, una regla que incentiva el etiquetado transparente. La propiedad `digitalSourceType` se basa en los códigos IPTC para fuentes digitales y distingue, entre otras cosas, entre contenido generado algorítmicamente y contenido generado por modelos.
Selección de imágenes: Schema supera a Open Graph
Una actualización menos visible pero de gran impacto en la práctica afecta a la lógica de selección de imágenes de Google. El sistema se está consolidando internamente, con una jerarquía de priorización clara: el marcado Schema.org, específicamente las propiedades `primaryImageOfPage` y `mainEntity → image`, tiene prioridad. Solo después se aplica la metaetiqueta `og:image` de Open Graph. Este cambio implica que, para los administradores de sitios web, una implementación correcta de Schema.org para la imagen principal influye directamente en su visualización en los resultados de búsqueda de Google y en las vistas generales de IA, lo que supone una ventaja concreta y cuantificable.
Schema.org recibe inversiones
También cabe destacar la reinversión anunciada por Google en schema.org como especificación abierta. Se mencionaron tres medidas concretas: la publicación de estadísticas sobre la frecuencia de uso de los términos de esquema individuales (como se muestra en una diapositiva, ya se dispone de datos de prevalencia para términos individuales como `digitalSourceType`, con información sobre aproximadamente 10 000 dominios), la publicación de las reglas de validación de Google en formatos estándar legibles por máquina, como SHACL o ShEx, y una mejor compatibilidad con las reglas de ordenación. Esto es importante porque permitiría a los desarrolladores externos crear sus propias herramientas de validación basadas en los estándares de Google, independientemente de las herramientas de prueba oficiales, que a veces fallan bajo carga.
Validación: Dos herramientas, un objetivo
Levering presentó dos herramientas de validación que se complementan entre sí, pero que aplican criterios de prueba diferentes. La herramienta de prueba de resultados enriquecidos (Rich Result Test Tool) en `search.google.com/test/rich-results` acepta URL o JSON puro y comprueba si el marcado es adecuado para los resultados enriquecidos de la Búsqueda de Google; por lo tanto, se basa en los requisitos específicos de Google, no en el estándar schema.org. Por otro lado, `validator.schema.org` comprueba si el marcado cumple con schema.org, es decir, si se adhiere al vocabulario abierto, independientemente de si Google genera resultados enriquecidos a partir de él. Esto lleva a una recomendación clara para los desarrolladores web: se deben usar ambas herramientas, ya que el marcado puede cumplir con schema.org pero no ser compatible con resultados enriquecidos, y viceversa.
Panorama general: Los datos estructurados como infraestructura de IA
Al analizar el evento de Toronto en su conjunto, se evidencia un cambio que va mucho más allá de la optimización SEO tradicional. Los datos estructurados están evolucionando de una herramienta para obtener fragmentos enriquecidos a un estándar fundamental de la capa de datos para los sistemas de IA. Google AI Overviews y AI Mode utilizan activamente el marcado schema.org como contexto para la generación de respuestas y la verificación de entidades. Quienes implementan datos estructurados correctos, completos y precisos no solo mejoran sus posibilidades de obtener elementos visuales destacados en los resultados de búsqueda, sino que también posicionan su contenido como una fuente primaria confiable para las respuestas de la IA.
La mención del Protocolo de Comercio Universal (UCP) y WebMCP en este contexto no es casual. Ambos estándares de comunicación basados en agentes, cuyas versiones preliminares Google lanzó en 2026, requieren que los sitios web se describan semánticamente. Schema.org constituye la base para ello. En un mundo donde los agentes de IA actúan de forma autónoma en la web, buscando, comparando e iniciando transacciones, la legibilidad del contenido por máquinas ya no es opcional, sino un requisito indispensable para la relevancia económica. Por lo tanto, la presentación de Ryan Levering en Toronto no fue solo un informe técnico actualizado, sino un vistazo a la infraestructura de la web del futuro.
Puedes comprobarlo tú mismo en 10 segundos
Si quieres saber con qué eficacia y exhaustividad tu sitio web u otro sitio web utiliza datos estructurados, puedes usar exactamente las dos herramientas que Ryan Levering de Google (mencionadas en el texto anterior) recomendó:
Prueba de resultados enriquecidos de Google (centrada en la visibilidad en Google):
Ve a search.google.com/test/rich-results, copia la URL de cualquier artículo de xpert.digital y haz clic en "Probar URL". La herramienta te mostrará exactamente qué marcado reconoce Google en esa página y si no contiene errores.
Validador de esquemas (centrado en el cumplimiento de estándares puros):
Ve a validator.schema.orgy pega la misma URL. Allí podrás ver directamente en el código fuente, resaltado en color, qué scripts JSON-LD (datos estructurados) ha incorporado xpert.digital.
Su socio global de marketing y desarrollo empresarial
☑️ Nuestro idioma comercial es el inglés o el alemán
☑️ NUEVO: ¡Correspondencia en tu idioma nativo!

Konrad Wolfenstein
Mi equipo y yo estaremos encantados de estar disponibles para usted como su asesor personal.
Puedes contactarme rellenando el formulario de contacto aquí wolfenstein@xpert.digital:o simplemente llamándome al +49 7348 4088 965. Mi dirección de correo electrónico es
Espero con ilusión nuestro proyecto conjunto.
☑️ Apoyo a las PYMES en estrategia, consultoría, planificación e implementación
☑️ Creación o realineamiento de la estrategia digital y digitalización
☑️ Ampliación y optimización de procesos de ventas internacionales
☑️ Plataformas comerciales B2B globales y digitales
☑️ Desarrollo de negocios pioneros / Marketing / Relaciones públicas / Ferias comerciales
Soporte B2B y SaaS para SEO y GEO (búsqueda con IA) combinados: la solución todo en uno para empresas B2B


Soporte B2B y SaaS para SEO y GEO (búsqueda con IA) combinados: la solución todo en uno para empresas B2B - Imagen: Xpert.Digital
La búsqueda con inteligencia artificial lo cambia todo: cómo esta solución SaaS revolucionará su clasificación B2B para siempre.
El panorama digital para las empresas B2B está cambiando rápidamente. Impulsadas por la inteligencia artificial, las reglas de la visibilidad online se están redefiniendo. Para las empresas, siempre ha sido un reto no solo ser visibles en el mundo digital, sino también ser relevantes para los responsables de la toma de decisiones. Las estrategias tradicionales de SEO y la gestión de la presencia local (geomarketing) son complejas, requieren mucho tiempo y, a menudo, suponen una batalla contra algoritmos en constante cambio y una intensa competencia.
Pero ¿y si existiera una solución que no solo simplificara este proceso, sino que también lo hiciera más inteligente, predictivo y mucho más eficaz? Aquí es donde entra en juego la combinación de soporte B2B especializado con una potente plataforma SaaS (Software como Servicio), diseñada específicamente para las exigencias del SEO y la geolocalización en la era de la búsqueda con IA.
Esta nueva generación de herramientas ya no se basa únicamente en el análisis manual de palabras clave y estrategias de backlinks. En su lugar, aprovecha la inteligencia artificial para comprender con mayor precisión la intención de búsqueda, optimizar automáticamente los factores de posicionamiento local y realizar análisis competitivos en tiempo real. El resultado es una estrategia proactiva basada en datos que ofrece a las empresas B2B una ventaja decisiva: no solo se les encuentra, sino que se les percibe como la autoridad líder en su nicho y ubicación.
Aquí se presenta la simbiosis del soporte B2B y la tecnología SaaS impulsada por IA que transforma el SEO y el marketing GEO, y cómo su empresa puede beneficiarse de ella para crecer de manera sustentable en el espacio digital.
Más información aquí: