
Un intento de explicar la IA: ¿Cómo funciona y funciona la inteligencia artificial? ¿Cómo se entrena?

Selección de voz 📢
Publicado el: 8 de septiembre de 2024 / Actualización desde: 9 de septiembre de 2024 - Autor: Konrad Wolfenstein

Un intento de explicar la IA: ¿Cómo funciona la inteligencia artificial y cómo se entrena? – Imagen: Xpert.Digital
📊 Del ingreso de datos a la predicción del modelo: el proceso de IA
¿Cómo funciona la inteligencia artificial (IA)? 🤖
El funcionamiento de la inteligencia artificial (IA) se puede dividir en varios pasos claramente definidos. Cada uno de estos pasos es fundamental para el resultado final que ofrece la IA. El proceso comienza con la entrada de datos y termina con la predicción del modelo y posible retroalimentación o rondas de capacitación adicionales. Estas fases describen el proceso por el que pasan casi todos los modelos de IA, independientemente de si se trata de simples conjuntos de reglas o de redes neuronales muy complejas.
1. La entrada de datos 📊
La base de toda inteligencia artificial son los datos con los que trabaja. Estos datos pueden estar en diversas formas, por ejemplo, imágenes, texto, archivos de audio o vídeos. La IA utiliza estos datos sin procesar para reconocer patrones y tomar decisiones. La calidad y cantidad de los datos juegan aquí un papel central, porque tienen una influencia significativa en qué tan bien o mal funcionará el modelo posteriormente.
Cuanto más extensos y precisos sean los datos, mejor podrá aprender la IA. Por ejemplo, cuando una IA está entrenada para el procesamiento de imágenes, requiere una gran cantidad de datos de imágenes para identificar correctamente diferentes objetos. Con los modelos de lenguaje, son los datos de texto los que ayudan a la IA a comprender y generar el lenguaje humano. La entrada de datos es el primer paso y uno de los más importantes, ya que la calidad de las predicciones sólo puede ser tan buena como la de los datos subyacentes. Un principio famoso en informática describe esto con el dicho “Basura entra, basura sale”: datos incorrectos conducen a malos resultados.
2. Preprocesamiento de datos 🧹
Una vez que se han ingresado los datos, es necesario prepararlos antes de poder introducirlos en el modelo real. Este proceso se llama preprocesamiento de datos. El objetivo aquí es poner los datos en una forma que el modelo pueda procesar de manera óptima.
Un paso común en el preprocesamiento es la normalización de datos. Esto significa que los datos se colocan en un rango uniforme de valores para que el modelo los trate de manera uniforme. Un ejemplo sería escalar todos los valores de píxeles de una imagen a un rango de 0 a 1 en lugar de 0 a 255.
Otra parte importante del preprocesamiento es la llamada extracción de características. Ciertas características se extraen de los datos sin procesar que son particularmente relevantes para el modelo. En el procesamiento de imágenes, por ejemplo, pueden tratarse de bordes o determinados patrones de color, mientras que en los textos se extraen palabras clave relevantes o estructuras de frases. El preprocesamiento es crucial para que el proceso de aprendizaje de la IA sea más eficiente y preciso.
3. El modelo 🧩
El modelo es el corazón de toda inteligencia artificial. Aquí los datos se analizan y procesan en base a algoritmos y cálculos matemáticos. Un modelo puede existir en diferentes formas. Uno de los modelos más conocidos es la red neuronal, que se basa en el funcionamiento del cerebro humano.
Las redes neuronales constan de varias capas de neuronas artificiales que procesan y transmiten información. Cada capa toma los resultados de la capa anterior y los procesa aún más. El proceso de aprendizaje de una red neuronal consiste en ajustar los pesos de las conexiones entre estas neuronas para que la red pueda realizar predicciones o clasificaciones cada vez más precisas. Esta adaptación se produce mediante entrenamiento, en el que la red accede a grandes cantidades de datos de muestra y mejora iterativamente sus parámetros internos (pesos).
Además de las redes neuronales, también se utilizan muchos otros algoritmos en los modelos de IA. Estos incluyen árboles de decisión, bosques aleatorios, máquinas de vectores de soporte y muchos otros. El algoritmo que se utiliza depende de la tarea específica y de los datos disponibles.
4. La predicción del modelo 🔍
Una vez que el modelo se entrena con datos, puede hacer predicciones. Este paso se llama predicción del modelo. La IA recibe una entrada y devuelve una salida, es decir, una predicción o decisión, basada en los patrones que ha aprendido hasta ahora.
Esta predicción puede adoptar diferentes formas. Por ejemplo, en un modelo de clasificación de imágenes, la IA podría predecir qué objeto es visible en una imagen. En un modelo de lenguaje, podría hacer una predicción sobre qué palabra viene a continuación en una oración. En las predicciones financieras, la IA podría predecir cómo se comportará el mercado de valores.
Es importante enfatizar que la precisión de las predicciones depende en gran medida de la calidad de los datos de entrenamiento y la arquitectura del modelo. Es probable que un modelo entrenado con datos insuficientes o sesgados realice predicciones incorrectas.
5. Retroalimentación y capacitación (opcional) ♻️
Otra parte importante del trabajo de una IA es el mecanismo de retroalimentación. El modelo se controla y optimiza periódicamente. Este proceso ocurre durante el entrenamiento o después de la predicción del modelo.
Si el modelo hace predicciones incorrectas, puede aprender a través de la retroalimentación a detectar estos errores y ajustar sus parámetros internos en consecuencia. Esto se hace comparando las predicciones del modelo con los resultados reales (por ejemplo, con datos conocidos para los cuales ya existen respuestas correctas). Un procedimiento típico en este contexto es el llamado aprendizaje supervisado, en el que la IA aprende a partir de datos de ejemplo que ya cuentan con las respuestas correctas.
Un método común de retroalimentación es el algoritmo de retropropagación utilizado en las redes neuronales. Los errores que comete el modelo se propagan hacia atrás a través de la red para ajustar los pesos de las conexiones neuronales. El modelo aprende de sus errores y se vuelve cada vez más preciso en sus predicciones.
El papel del entrenamiento 🏋️♂️
Entrenar una IA es un proceso iterativo. Cuantos más datos vea el modelo y más a menudo se entrene en función de estos datos, más precisas serán sus predicciones. Sin embargo, también existen límites: un modelo demasiado entrenado puede tener los llamados problemas de "sobreajuste". Esto significa que memoriza tan bien los datos del entrenamiento que produce peores resultados con datos nuevos y desconocidos. Por lo tanto, es importante entrenar el modelo para que se generalice y haga buenas predicciones incluso con datos nuevos.
Además de la formación periódica, también existen procedimientos como el aprendizaje por transferencia. Aquí, un modelo que ya ha sido entrenado con una gran cantidad de datos se utiliza para una tarea nueva y similar. Esto ahorra tiempo y potencia informática porque no es necesario entrenar el modelo desde cero.
Aprovecha al máximo tus fortalezas 🚀
El trabajo de una inteligencia artificial se basa en una compleja interacción de varios pasos. Desde la entrada de datos, el preprocesamiento, el entrenamiento de modelos, la predicción y la retroalimentación, existen muchos factores que influyen en la precisión y eficiencia de la IA. Una IA bien entrenada puede proporcionar enormes beneficios en muchas áreas de la vida, desde la automatización de tareas simples hasta la resolución de problemas complejos. Pero es igualmente importante comprender las limitaciones y los posibles peligros de la IA para aprovechar al máximo sus puntos fuertes.
🤖📚 Explicado de forma sencilla: ¿Cómo se entrena una IA?
🤖📊 Proceso de aprendizaje de IA: capturar, vincular y guardar
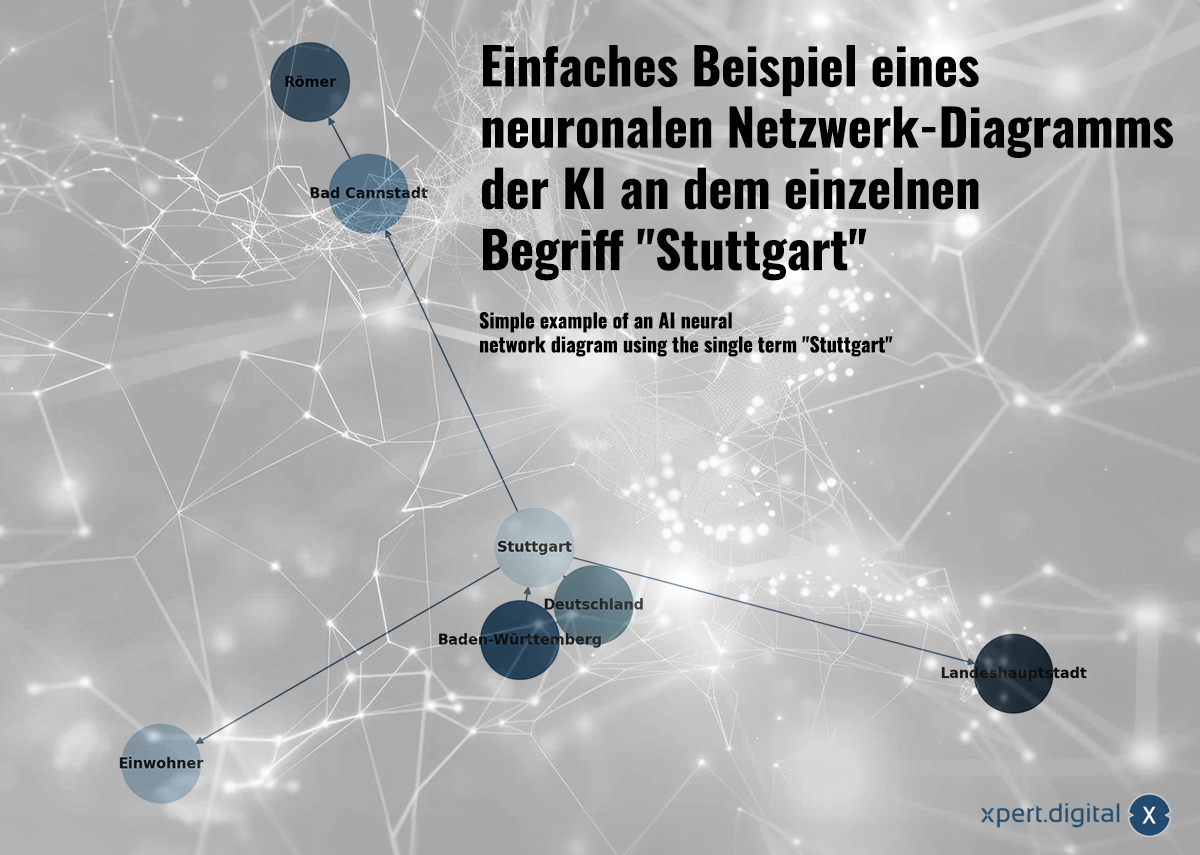
Ejemplo simple de un diagrama de red neuronal de la IA en el término individual "Stuttgart" -Image: xpert.digital
🌟 Recopilar y preparar datos
El primer paso en el proceso de aprendizaje de la IA es recopilar y preparar los datos. Estos datos pueden provenir de diversas fuentes, como bases de datos, sensores, textos o imágenes.
🌟 Relacionar datos (Red Neuronal)
Los datos recopilados están relacionados entre sí en una red neuronal. Cada paquete de datos se muestra mediante conexiones en una red de "neuronas" (nodo). Un ejemplo simple con la ciudad de Stuttgart podría verse así:
a) Stuttgart es una ciudad de Baden-Württemberg
b) Baden-Württemberg es un estado federal de Alemania
c) Stuttgart es una ciudad de Alemania
d) Stuttgart tiene una población de 633.484 en 2023
e) Bad Cannstatt es un distrito de Stuttgart
f) Bad Cannstatt fue fundada por los romanos
g) Stuttgart es la capital del estado de Baden-Württemberg
Dependiendo del tamaño del volumen de datos, los parámetros para los gastos potenciales se crean utilizando el modelo de IA utilizado. Como ejemplo: ¡GPT-3 tiene aproximadamente 175 mil millones de parámetros!
🌟 Almacenamiento y personalización (aprendizaje)
Los datos se envían a la red neuronal. Pasan por el modelo de IA y se procesan mediante conexiones (similar a las sinapsis). Los pesos (parámetros) entre las neuronas se ajustan para entrenar el modelo o realizar una tarea.
A diferencia de las formas de memoria convencionales, como el acceso directo, el acceso indicado, el almacenamiento secuencial o de la pila, las redes neuronales almacenan los datos de una manera poco convencional. Los "datos" se almacenan en los pesos y los sesgos de las conexiones entre las neuronas.
El "almacenamiento" real de la información en una red neuronal tiene lugar adaptando los pesos de conexión entre las neuronas. El modelo de IA "aprende" adaptando constantemente estos pesos y sesgos en función de los datos de entrada y un algoritmo de aprendizaje definido. Este es un proceso continuo en el que el modelo puede hacer predicciones precisas debido a ajustes recurrentes.
El modelo de IA puede considerarse un tipo de programación porque se crea mediante algoritmos definidos y cálculos matemáticos y mejora continuamente el ajuste de sus parámetros (pesos) para realizar predicciones precisas. Este es un proceso continuo.
Los sesgos son parámetros adicionales en las redes neuronales que se agregan a los valores de entrada ponderados de una neurona. Permiten ponderar los parámetros (importantes, menos importantes, importantes, etc.), haciendo que la IA sea más flexible y precisa.
Las redes neuronales no sólo pueden almacenar hechos individuales, sino también reconocer conexiones entre los datos mediante el reconocimiento de patrones. El ejemplo de Stuttgart ilustra cómo se puede introducir conocimiento en una red neuronal, pero las redes neuronales no aprenden mediante conocimiento explícito (como en este sencillo ejemplo), sino mediante el análisis de patrones de datos. Las redes neuronales no sólo pueden almacenar hechos individuales, sino también aprender pesos y relaciones entre los datos de entrada.
Este flujo proporciona una introducción comprensible a cómo funcionan la IA y las redes neuronales en particular, sin profundizar demasiado en los detalles técnicos. Muestra que el almacenamiento de información en redes neuronales no se realiza como en las bases de datos tradicionales, sino ajustando las conexiones (pesos) dentro de la red.
🤖📚 Más detallado: ¿Cómo se entrena una IA?
🏋️♂️ El entrenamiento de una IA, especialmente un modelo de aprendizaje automático, se lleva a cabo en varios pasos. El entrenamiento de una IA se basa en la optimización continua de los parámetros del modelo mediante retroalimentación y ajuste hasta que el modelo muestre el mejor rendimiento con los datos proporcionados. Aquí hay una explicación detallada de cómo funciona este proceso:
1. 📊 Recopilar y preparar datos
Los datos son la base del entrenamiento de IA. Por lo general, constan de miles o millones de ejemplos para que el sistema los analice. Algunos ejemplos son imágenes, textos o datos de series temporales.
Los datos deben limpiarse y normalizarse para evitar fuentes de error innecesarias. A menudo, los datos se convierten en características que contienen la información relevante.
2. 🔍 Definir modelo
Un modelo es una función matemática que describe las relaciones en los datos. En las redes neuronales, que se utilizan a menudo para la IA, el modelo consta de varias capas de neuronas conectadas entre sí.
Cada neurona realiza una operación matemática para procesar los datos de entrada y luego pasa una señal a la siguiente neurona.
3. 🔄 Inicializar pesos
Las conexiones entre neuronas tienen pesos que inicialmente se establecen de forma aleatoria. Estos pesos determinan con qué fuerza responde una neurona a una señal.
El objetivo del entrenamiento es ajustar estos pesos para que el modelo haga mejores predicciones.
4. ➡️ Propagación hacia adelante
El pase directo pasa los datos de entrada a través del modelo para producir una predicción.
Cada capa procesa los datos y los pasa a la siguiente capa hasta que la última capa entrega el resultado.
5. ⚖️ Calcular la función de pérdida
La función de pérdida mide qué tan buenas son las predicciones del modelo en comparación con los valores reales (las etiquetas). Una medida común es el error entre la respuesta prevista y la real.
Cuanto mayor era la pérdida, peor era la predicción del modelo.
6. 🔙 Propagación hacia atrás
En el paso hacia atrás, el error se retroalimenta desde la salida del modelo a las capas anteriores.
El error se redistribuye a los pesos de las conexiones y el modelo ajusta los pesos para que los errores sean menores.
Esto se hace mediante el descenso de gradiente: se calcula el vector de gradiente, que indica cómo se deben cambiar los pesos para minimizar el error.
7. 🔧 Actualizar pesos
Una vez calculado el error, los pesos de las conexiones se actualizan con un pequeño ajuste basado en la tasa de aprendizaje.
La tasa de aprendizaje determina cuánto cambian los pesos con cada paso. Los cambios demasiado grandes pueden hacer que el modelo sea inestable y los cambios demasiado pequeños provocan un proceso de aprendizaje lento.
8. 🔁 Repetir (Época)
Este proceso de avance, cálculo de errores y actualización de peso se repite, a menudo durante varias épocas (pasa por todo el conjunto de datos), hasta que el modelo alcanza una precisión aceptable.
Con cada época, el modelo aprende un poco más y ajusta aún más sus pesos.
9. 📉 Validación y pruebas
Una vez entrenado el modelo, se prueba en un conjunto de datos validado para comprobar qué tan bien se generaliza. Esto garantiza que no sólo haya “memorizado” los datos de entrenamiento, sino que también haga buenas predicciones sobre datos desconocidos.
Los datos de prueba ayudan a medir el rendimiento final del modelo antes de utilizarlo en la práctica.
10. 🚀 Optimización
Los pasos adicionales para mejorar el modelo incluyen el ajuste de hiperparámetros (por ejemplo, ajustar la tasa de aprendizaje o la estructura de la red), la regularización (para evitar el sobreajuste) o el aumento de la cantidad de datos.
📊🔙 Inteligencia artificial: haga que la caja negra de la IA sea comprensible, comprensible y explicable con IA explicable (XAI), mapas de calor, modelos sustitutos u otras soluciones.

Inteligencia artificial: hacer que la caja negra de la IA sea comprensible, comprensible y explicable con IA explicable (XAI), mapas de calor, modelos sustitutos u otras soluciones - Imagen: Xpert.Digital
La llamada “caja negra” de la inteligencia artificial (IA) representa un problema importante y actual. Incluso los expertos a menudo se enfrentan al desafío de no poder comprender completamente cómo los sistemas de IA toman sus decisiones. Esta falta de transparencia puede causar problemas importantes, particularmente en áreas críticas como la economía, la política o la medicina. Un médico o profesional médico que confía en un sistema de inteligencia artificial para diagnosticar y recomendar terapia debe tener confianza en las decisiones que toma. Sin embargo, si la toma de decisiones de una IA no es lo suficientemente transparente, surge incertidumbre y potencialmente falta de confianza, en situaciones en las que podrían estar en juego vidas humanas.
Más sobre esto aquí:
Estamos a su disposición - asesoramiento - planificación - implementación - gestión de proyectos
☑️ Apoyo a las PYMES en estrategia, consultoría, planificación e implementación.
☑️ Creación o realineamiento de la estrategia digital y digitalización
☑️ Ampliación y optimización de procesos de ventas internacionales
☑️ Plataformas comerciales B2B globales y digitales
☑️ Desarrollo empresarial pionero

Konrad Wolfenstein
Estaré encantado de servirle como su asesor personal.
Puedes contactarme completando el formulario de contacto a continuación o simplemente llámame al +49 89 89 674 804 (Múnich) .
Estoy deseando que llegue nuestro proyecto conjunto.
Escríbeme

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital es un centro industrial centrado en la digitalización, la ingeniería mecánica, la logística/intralogística y la fotovoltaica.
Con nuestra solución de desarrollo empresarial de 360°, apoyamos a empresas reconocidas desde nuevos negocios hasta posventa.
Inteligencia de mercado, smarketing, automatización de marketing, desarrollo de contenidos, relaciones públicas, campañas de correo, redes sociales personalizadas y desarrollo de leads son parte de nuestras herramientas digitales.
Puede obtener más información en: www.xpert.digital - www.xpert.solar - www.xpert.plus
Mantenerse en contacto


















