The $57 billion miscalculation – NVIDIA of all companies warns: The AI industry has backed the wrong horse – Image: Xpert.Digital
Forget the AI giants: Why the future is small, decentralized, and much cheaper
### Small Language Models: The Key to True Business Autonomy ### From Hyperscalers Back to Users: Power Shift in the AI World ### The $57 Billion Mistake: Why the Real AI Revolution Isn't Happening in the Cloud ### The Silent AI Revolution: Decentralized Instead of Centralized ### Tech Giants on the Wrong Track: The Future of AI Is Lean and Local ### From Hyperscalers Back to Users: Power Shift in the AI World ###
Billions of dollars wasted investment: Why small AI models are overtaking the big ones
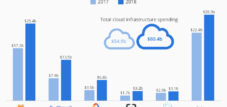
The world of artificial intelligence is facing an earthquake whose magnitude is reminiscent of the corrections of the dot-com era. At the heart of this upheaval lies a colossal miscalculation: While tech giants like Microsoft, Google, and Meta are investing hundreds of billions in centralized infrastructures for massive language models (Large Language Models, LLMs), the actual market for their application is lagging dramatically. A groundbreaking analysis, conducted in part by industry leader NVIDIA itself, quantifies the gap at $57 billion in infrastructure investments compared to a real market of only $5.6 billion—a tenfold discrepancy.
This strategic error stems from the assumption that the future of AI lies solely in ever larger, more computationally intensive, and centrally controlled models. But now this paradigm is crumbling. A quiet revolution, driven by decentralized, smaller language models (Small Language Models, SLMs), is turning the established order on its head. These models are not only many times cheaper and more efficient, but they also enable companies to achieve new levels of autonomy, data sovereignty, and agility—far removed from costly dependence on a few hyperscalers. This text analyzes the anatomy of this multi-billion-dollar misinvestment and demonstrates why the true AI revolution is taking place not in gigantic data centers, but decentrally and on lean hardware. It is the story of a fundamental power shift from the infrastructure providers back to the users of the technology.
Related to this:


NVIDIA research on AI capital misallocation
The data you described comes from an NVIDIA research paper published in June 2025. The full source is:
“Small Language Models are the Future of Agentic AI”
- Authors: Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
- Release date: June 2, 2025 (Version 1), last revision September 15, 2025 (Version 2)
- Publication location: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- Official NVIDIA Research page: https://research.nvidia.com/labs/lpr/slm-agents/
The key message regarding capital misallocation
The research documents a fundamental discrepancy between infrastructure investments and actual market volume: In 2024, the industry invested $57 billion in cloud infrastructure to support Large Language Model (LLM) API services, while the actual market for these services was only $5.6 billion. This ten-to-one discrepancy is interpreted in the study as an indication of a strategic miscalculation, as the industry invested heavily in centralized infrastructure for large-scale models, even though 40-70% of current LLM workloads could be replaced by smaller, specialized Small Language Models (SLMs) at 1/30th of the cost.
Research context and authorship
This study is a position paper from the Deep Learning Efficiency Research Group at NVIDIA Research. Lead author Peter Belcak is an AI researcher at NVIDIA focusing on the reliability and efficiency of agent-based systems. The paper argues on three pillars:
SLMs are
- sufficiently powerful
- surgically suitable and
- economically necessary
for many use cases in agentic AI systems.
The researchers explicitly emphasize that the views expressed in this paper are those of the authors and do not necessarily reflect the position of NVIDIA as a company. NVIDIA invites critical discussion and commits to publishing any related correspondence on the accompanying website.
Why decentralized small language models make the centralized infrastructure bet obsolete
Artificial intelligence is at a turning point, the implications of which are reminiscent of the upheavals of the dot-com bubble. A research paper by NVIDIA has revealed a fundamental misallocation of capital that shakes the foundations of its current AI strategy. While the technology industry invested $57 billion in centralized infrastructure for large-scale language models, the actual market for their use grew to a mere $5.6 billion. This ten-to-one discrepancy not only marks an overestimation of demand but also exposes a fundamental strategic error regarding the future of artificial intelligence.
A bad investment? Billions spent on AI infrastructure — what to do with the excess capacity?
The numbers speak for themselves. In 2024, global spending on AI infrastructure reached between $80 and $87 billion, according to various analyses, with data centers and accelerators accounting for the vast majority. Microsoft announced investments of $80 billion for fiscal year 2025, Google raised its forecast to between $91 and $93 billion, and Meta plans to invest up to $70 billion. These three hyperscalers alone represent an investment volume of over $240 billion. Total spending on AI infrastructure could reach between $3.7 and $7.9 trillion by 2030, according to McKinsey estimates.
In contrast, the reality on the demand side is sobering. The market for Enterprise Large Language Models was estimated at only $4 to $6.7 billion for 2024, with projections for 2025 ranging from $4.8 to $8 billion. Even the most generous estimates for the Generative AI market as a whole are between $28 and $44 billion for 2024. The fundamental discrepancy is clear: the infrastructure was built for a market that does not exist in this form and scope.
This misinvestment stems from an assumption that is increasingly proving false: that the future of AI lies in ever larger, centralized models. Hyperscalers pursued a strategy of massive scaling, driven by the conviction that parameter count and computing power were the decisive competitive factors. GPT-3, with 175 billion parameters, was considered a breakthrough in 2020, and GPT-4, with over a trillion parameters, set new standards. The industry blindly followed this logic and invested in an infrastructure designed for the needs of models that are oversized for most use cases.
The investment structure clearly illustrates the misallocation. In the second quarter of 2025, 98 percent of the $82 billion spent on AI infrastructure went to servers, with 91.8 percent of that going to GPU- and XPU-accelerated systems. Hyperscalers and cloud builders absorbed 86.7 percent of these expenditures, roughly $71 billion in a single quarter. This concentration of capital in highly specialized, extremely energy-intensive hardware for training and inferring massive models ignored a fundamental economic reality: most enterprise applications do not require this capacity.
The paradigm is breaking: From centralized to decentralized
NVIDIA itself, the main beneficiary of the recent infrastructure boom, is now providing the analysis that challenges this paradigm. Research on Small Language Models as the future of agent-based AI argues that models with fewer than 10 billion parameters are not only sufficient but operationally superior for the vast majority of AI applications. The study of three large open-source agent systems revealed that 40 to 70 percent of calls to large language models could be replaced by specialized small models without any performance loss.
These findings shake the fundamental assumptions of the existing investment strategy. If MetaGPT can replace 60 percent of its LLM calls, Open Operator 40 percent, and Cradle 70 percent with SLMs, then infrastructure capacity has been built for demands that don't exist on this scale. The economics shift dramatically: A Llama 3.1B Small Language Model costs ten to thirty times less to operate than its larger counterpart, Llama 3.3 405B. Fine-tuning can be accomplished in a few GPU hours instead of weeks. Many SLMs run on consumer hardware, completely eliminating cloud dependencies.
The strategic shift is fundamental. Control is moving from infrastructure providers to operators. While the previous architecture forced companies into a position of dependence on a few hyperscalers, decentralization through SLMs enables new autonomy. Models can be operated locally, data remains within the company, API costs are eliminated, and vendor lock-in is broken. This is not just a technological transformation, but a transformation of power politics.
The previous bet on centralized large-scale models was based on the assumption of exponential scaling effects. However, empirical data increasingly contradicts this. Microsoft Phi-3, with 7 billion parameters, achieves code generation performance comparable to 70-billion-parameter models. NVIDIA Nemotron Nano 2, with 9 billion parameters, outperforms Qwen3-8B in reasoning benchmarks with six times the throughput. Efficiency per parameter increases with smaller models, while large models often activate only a fraction of their parameters for a given input—an inherent inefficiency.
The economic superiority of small language models
The cost structure reveals the economic reality with brutal clarity. Training GPT-4 class models is estimated at over $100 million, with Gemini Ultra potentially costing $191 million. Even fine-tuning large models for specific domains can cost tens of thousands of dollars in GPU time. In contrast, SLMs can be trained and fine-tuned for just a few thousand dollars, often on a single high-end GPU.
The inference costs reveal even more drastic differences. GPT-4 costs approximately $0.03 per 1,000 input tokens and $0.06 per 1,000 output tokens, totaling $0.09 per average query. Mistral 7B, as an SLM example, costs $0.0001 per 1,000 input tokens and $0.0003 per 1,000 output tokens, or $0.0004 per query. This represents a cost reduction by a factor of 225. With millions of queries, this difference adds up to substantial amounts that directly impact profitability.
The total cost of ownership reveals further dimensions. Self-hosting a 7-billion-parameter model on bare-metal servers with L40S GPUs costs approximately $953 per month. Cloud-based fine-tuning with AWS SageMaker on g5.2xlarge instances costs $1.32 per hour, with potential training costs starting at $13 for smaller models. 24/7 inference deployment would cost approximately $950 per month. Compared to API costs for continuous use of large models, which can easily reach tens of thousands of dollars per month, the economic advantage becomes clear.
The speed of implementation is an often underestimated economic factor. While fine-tuning a Large Language Model can take weeks, SLMs are ready to use in hours or a few days. The agility to quickly respond to new requirements, add new capabilities, or adapt behavior becomes a competitive advantage. In fast-paced markets, this time difference can be the difference between success and failure.
The economics of scale is reversing. Traditionally, economies of scale were seen as the advantage of hyperscalers, which maintain enormous capacities and distribute them across many customers. However, with SLMs, even smaller organizations can scale efficiently because the hardware requirements are drastically lower. A startup can build a specialized SLM with a limited budget that outperforms a large, generalist model for its specific task. The democratization of AI development is becoming an economic reality.
Technical fundamentals of disruption
The technological innovations that enable SLMs are as significant as their economic implications. Knowledge distillation, a technique in which a smaller student model absorbs the knowledge of a larger teacher model, has proven highly effective. DistilBERT successfully compressed BERT, and TinyBERT followed similar principles. Modern approaches distill the capabilities of large generative models like GPT-3 into significantly smaller versions that demonstrate comparable or better performance in specific tasks.
The process utilizes both the soft labels (probability distributions) of the teacher model and the hard labels of the original data. This combination allows the smaller model to capture nuanced patterns that would be lost in simple input-output pairs. Advanced distillation techniques, such as step-by-step distillation, have shown that small models can achieve better results than LLMs even with less training data. This fundamentally shifts the economics: instead of expensive, lengthy training runs on thousands of GPUs, targeted distillation processes suffice.
Quantization reduces the precision of the numerical representation of model weights. Instead of 32-bit or 16-bit floating-point numbers, quantized models use 8-bit or even 4-bit integer representations. Memory requirements decrease proportionally, inference speed increases, and power consumption falls. Modern quantization techniques minimize the loss of accuracy, often leaving performance virtually unchanged. This enables deployment on edge devices, smartphones, and embedded systems that would be impossible with fully precise large models.
Pruning removes redundant connections and parameters from neural networks. Similar to editing an overly long text, non-essential elements are identified and eliminated. Structured pruning removes entire neurons or layers, while unstructured pruning removes individual weights. The resulting network structure is more efficient, requiring less memory and processing power, yet retains its core capabilities. Combined with other compression techniques, pruned models achieve impressive efficiency gains.
Low-rank factorization decomposes large weight matrices into products of smaller matrices. Instead of a single matrix with millions of elements, the system stores and processes two significantly smaller matrices. The mathematical operation remains approximately the same, but the computational effort is dramatically reduced. This technique is particularly effective in transformer architectures, where attention mechanisms dominate large matrix multiplications. The memory savings allow for larger context windows or batch sizes with the same hardware budget.
The combination of these techniques in modern SLMs like the Microsoft Phi series, Google Gemma, or NVIDIA Nemotron demonstrates the potential. The Phi-2, with only 2.7 billion parameters, outperforms Mistral and Llama-2 models with 7 and 13 billion parameters, respectively, in aggregated benchmarks and achieves better performance than the 25 times larger Llama-2-70B in multi-step reasoning tasks. This was achieved through strategic data selection, high-quality synthetic data generation, and innovative scaling techniques. The message is clear: size is no longer a proxy for capability.
Market dynamics and substitution potential
Empirical findings from real-world applications support the theoretical considerations. NVIDIA's analysis of MetaGPT, a multi-agent software development framework, identified that approximately 60 percent of LLM requests are replaceable. These tasks include boilerplate code generation, documentation creation, and structured output—all areas where specialized SLMs perform faster and more cost-effectively than general-purpose, large-scale models.
Open Operator, a workflow automation system, demonstrates with its 40 percent substitution potential that even in complex orchestration scenarios, many subtasks do not require the full capacity of LLMs. Intent parsing, template-based output, and routing decisions can be handled more efficiently by finely tuned, small models. The remaining 60 percent, which actually require deep reasoning or broad world knowledge, justifies the use of large models.
Cradle, a GUI automation system, exhibits the highest substitution potential at 70 percent. Repetitive UI interactions, click sequences, and form entries are ideally suited for SLMs. The tasks are narrowly defined, the variability is limited, and the requirements for contextual understanding are low. A specialized model trained on GUI interactions outperforms a generalist LLM in speed, reliability, and cost.
These patterns repeat themselves across application areas. Customer service chatbots for FAQs, document classification, sentiment analysis, named entity recognition, simple translations, natural language database queries – all these tasks benefit from SLMs. One study estimates that in typical enterprise AI deployments, 60 to 80 percent of queries fall into categories for which SLMs are sufficient. The implications for infrastructure demand are significant.
The concept of model routing is gaining importance. Intelligent systems analyze incoming queries and route them to the appropriate model. Simple queries go to cost-effective SLMs, while complex tasks are handled by high-performance LLMs. This hybrid approach optimizes the balance between quality and cost. Early implementations report cost savings of up to 75 percent with the same or even better overall performance. The routing logic itself can be a small machine learning model that takes query complexity, context, and user preferences into account.
The proliferation of fine-tuning-as-a-service platforms is accelerating adoption. Companies without deep machine learning expertise can build specialized SLMs that incorporate their proprietary data and domain specifics. The time investment is reduced from months to days, and the cost from hundreds of thousands of dollars to thousands. This accessibility fundamentally democratizes AI innovation and shifts value creation from infrastructure providers to application developers.
A new dimension of digital transformation with 'Managed AI' (Artificial Intelligence) - Platform & B2B solution | Xpert Consulting

A new dimension of digital transformation with 'Managed AI' (Artificial Intelligence) – Platform & B2B solution | Xpert Consulting - Image: Xpert.Digital
Here you will learn how your company can implement customized AI solutions quickly, securely and without high entry barriers.
A managed AI platform is your all-inclusive, worry-free solution for artificial intelligence. Instead of dealing with complex technology, expensive infrastructure, and lengthy development processes, you receive a ready-made solution tailored to your needs from a specialized partner – often within just a few days.
The key advantages at a glance:
⚡ Rapid implementation: From idea to ready-to-use application in days, not months. We deliver practical solutions that create immediate added value.
🔒 Maximum data security: Your sensitive data stays with you. We guarantee secure and compliant processing without sharing data with third parties.
💸 No financial risk: You only pay for results. High upfront investments in hardware, software, or personnel are completely eliminated.
🎯 Focus on your core business: Concentrate on what you do best. We take care of the entire technical implementation, operation, and maintenance of your AI solution.
📈 Future-proof & scalable: Your AI grows with you. We ensure continuous optimization and scalability, and flexibly adapt the models to new requirements.
More information here:
How decentralized AI saves companies billions in costs
The hidden costs of centralized architectures
Focusing solely on direct compute costs underestimates the total cost of centralized LLM architectures. API dependencies create structural disadvantages. Every request generates costs that scale with usage. For successful applications with millions of users, API fees become the dominant cost factor, eroding margins. Companies are trapped in a cost structure that grows proportionally to success, without corresponding economies of scale.
The pricing volatility of API providers poses a business risk. Price increases, quota limitations, or changes to terms of service can destroy an application's profitability overnight. The recently announced capacity restrictions by major providers, which force users to ration their resources, illustrate the vulnerability of this dependency. Dedicated SLMs eliminate this risk entirely.
Data sovereignty and compliance are gaining in importance. GDPR in Europe, comparable regulations worldwide, and increasing data localization requirements are creating complex legal frameworks. Sending sensitive corporate data to external APIs that may operate in foreign jurisdictions carries regulatory and legal risks. Healthcare, finance, and government sectors often have strict requirements that exclude or severely restrict the use of external APIs. On-premise SLMs fundamentally solve these problems.
Intellectual property concerns are real. Every request sent to an API provider potentially exposes proprietary information. Business logic, product developments, customer information – all of this could theoretically be extracted and used by the provider. Contract clauses offer limited protection against accidental leaks or malicious actors. The only truly secure solution is to never externalize data.
Latency and reliability suffer due to network dependencies. Every cloud API request traverses internet infrastructure, subject to network jitter, packet loss, and variable round-trip times. For real-time applications like conversational AI or control systems, these delays are unacceptable. Local SLMs respond in milliseconds instead of seconds, regardless of network conditions. The user experience is significantly improved.
Strategic reliance on a few hyperscalers concentrates power and creates systemic risks. AWS, Microsoft Azure, Google Cloud, and a few others dominate the market. Outages of these services have cascading effects across thousands of dependent applications. The illusion of redundancy vanishes when you consider that most alternative services ultimately rely on the same limited set of model providers. True resilience requires diversification, ideally including in-house capacity.
Related to this:

Edge computing as a strategic turning point
The convergence of SLMs and edge computing is creating a transformative dynamic. Edge deployment brings computation to where data originates – IoT sensors, mobile devices, industrial controllers, and vehicles. The latency reduction is dramatic: from seconds to milliseconds, from cloud round-trip to local processing. For autonomous systems, augmented reality, industrial automation, and medical devices, this is not only desirable but essential.
The bandwidth savings are substantial. Instead of continuous data streams to the cloud, where they are processed and results are sent back, processing takes place locally. Only relevant, aggregated information is transmitted. In scenarios with thousands of edge devices, this reduces network traffic by orders of magnitude. Infrastructure costs decrease, network congestion is avoided, and reliability increases.
Privacy is inherently protected. Data no longer leaves the device. Camera feeds, audio recordings, biometric information, location data – all of this can be processed locally without reaching central servers. This resolves fundamental privacy concerns raised by cloud-based AI solutions. For consumer applications, this becomes a differentiating factor; for regulated industries, it becomes a requirement.
Energy efficiency is improving on multiple levels. Specialized edge AI chips, optimized for inferencing small models, consume a fraction of the energy of data center GPUs. Eliminating data transmission saves energy in network infrastructure. For battery-powered devices, this is becoming a core function. Smartphones, wearables, drones, and IoT sensors can perform AI functions without dramatically impacting battery life.
Offline capability creates robustness. Edge AI also works without an internet connection. Functionality is maintained in remote regions, critical infrastructure, or disaster scenarios. This independence from network availability is essential for many applications. An autonomous vehicle cannot rely on cloud connectivity, and a medical device must not fail due to unstable Wi-Fi.
Cost models are shifting from operational to capital expenditure. Instead of continuous cloud costs, there's a one-time investment in edge hardware. This becomes economically attractive for long-lived, high-volume applications. Predictable costs improve budget planning and reduce financial risks. Companies regain control over their AI infrastructure spending.
Examples demonstrate the potential. NVIDIA ChatRTX enables local LLM inference on consumer GPUs. Apple integrates on-device AI into iPhones and iPads, with smaller models running directly on the device. Qualcomm is developing NPUs for smartphones specifically for edge AI. Google Coral and similar platforms target IoT and industrial applications. Market dynamics show a clear trend toward decentralization.
Heterogeneous AI architectures as a future model
The future lies not in absolute decentralization, but in intelligent hybrid architectures. Heterogeneous systems combine edge SLMs for routine, latency-sensitive tasks with cloud LLMs for complex reasoning requirements. This complementarity maximizes efficiency while preserving flexibility and capability.
The system architecture comprises several layers. At the edge layer, highly optimized SLMs provide immediate responses. These are expected to handle 60 to 80 percent of requests autonomously. For ambiguous or complex queries that fail to meet local confidence thresholds, escalation occurs to the fog computing layer – regional servers with mid-range models. Only truly difficult cases reach the central cloud infrastructure with large, general-purpose models.
Model routing is becoming a critical component. Machine learning-based routers analyze request characteristics: text length, complexity indicators, domain signals, and user history. Based on these features, the request is assigned to the appropriate model. Modern routers achieve over 95% accuracy in complexity estimation. They continuously optimize based on actual performance and cost-quality tradeoffs.
Cross-attention mechanisms in advanced routing systems explicitly model query-model interactions. This enables nuanced decisions: Is Mistral-7B sufficient, or is GPT-4 required? Can Phi-3 handle this, or is Claude needed? The fine-grained nature of these decisions, multiplied across millions of queries, generates substantial cost savings while maintaining or improving user satisfaction.
Workload characterization is fundamental. Agentic AI systems consist of orchestration, reasoning, tool calls, memory operations, and output generation. Not all components require the same compute capacity. Orchestration and tool calls are often rule-based or require minimal intelligence—ideal for SLMs. Reasoning can be hybrid: simple inference on SLMs, complex multi-step reasoning on LLMs. Output generation for templates uses SLMs, creative text generation uses LLMs.
Total Cost of Ownership (TCO) optimization takes hardware heterogeneity into account. High-end H100 GPUs are used for critical LLM workloads, mid-tier A100 or L40S for mid-range models, and cost-effective T4 or inference-optimized chips for SLMs. This granularity allows for precise matching of workload requirements to hardware capabilities. Initial studies show a 40 to 60 percent reduction in TCO compared to homogeneous high-end deployments.
Orchestration requires sophisticated software stacks. Kubernetes-based cluster management systems, complemented by AI-specific schedulers that understand model characteristics, are essential. Load balancing considers not only requests per second but also token lengths, model memory footprints, and latency targets. Autoscaling responds to demand patterns, provisioning additional capacity or scaling down during periods of low utilization.
Sustainability and energy efficiency
The environmental impact of AI infrastructure is becoming a central issue. Training a single large language model can consume as much energy as a small town in a year. Data centers running AI workloads could account for 20 to 27 percent of global data center energy demand by 2028. Projections estimate that by 2030, AI data centers could require 8 gigawatts for individual training runs. The carbon footprint will be comparable to that of the aviation industry.
The energy intensity of large models is increasing disproportionately. GPU power consumption has doubled from 400 to over 1000 watts in three years. NVIDIA GB300 NVL72 systems, despite innovative power-smoothing technology that reduces peak load by 30 percent, require enormous amounts of energy. Cooling infrastructure adds another 30 to 40 percent to the energy demand. Total CO2 emissions from AI infrastructure could increase by 220 million tons by 2030, even with optimistic assumptions about grid decarbonization.
Small Language Models (SLMs) offer fundamental efficiency gains. Training requires 30 to 40 percent of the computing power of comparable LLMs. BERT training costs approximately €10,000, compared to hundreds of millions for GPT-4 class models. Inference energy is proportionally lower. An SLM query can consume 100 to 1,000 times less energy than an LLM query. Over millions of queries, this adds up to enormous savings.
Edge computing amplifies these advantages. Local processing eliminates the energy required for data transmission across networks and backbone infrastructure. Specialized edge AI chips achieve energy efficiency factors orders of magnitude better than data center GPUs. Smartphones and IoT devices with milliwatt NPUs instead of hundreds of watts of servers illustrate the difference in scale.
The use of renewable energy is becoming a priority. Google is committed to 100 percent carbon-free energy by 2030, and Microsoft to carbon negativity. However, the sheer scale of energy demand presents challenges. Even with renewable sources, the question of grid capacity, storage, and intermittency remains. SLMs reduce the absolute demand, making the transition to green AI more feasible.
Carbon-aware computing optimizes workload scheduling based on grid carbon intensity. Training runs are started when the share of renewable energy in the grid is at its maximum. Inference requests are routed to regions with cleaner energy. This temporal and geographical flexibility, combined with the efficiency of SLMs, could reduce CO2 emissions by 50 to 70 percent.
The regulatory landscape is becoming more stringent. The EU AI Act includes mandatory environmental impact assessments for certain AI systems. Carbon reporting is becoming standard. Companies with inefficient, energy-intensive infrastructures risk compliance issues and reputational damage. The adoption of SLMs and edge computing is evolving from a nice-to-have to a necessity.
Democratization versus concentration
Past developments have concentrated AI power in the hands of a few key players. The Magnificent Seven – Microsoft, Google, Meta, Amazon, Apple, NVIDIA, and Tesla – dominate. These hyperscalers control infrastructure, models, and increasingly the entire value chain. Their combined market capitalization exceeds $15 trillion. They represent almost 35 percent of the S&P 500 market capitalization, a concentration risk of unprecedented historical significance.
This concentration has systemic implications. A few companies set standards, define APIs, and control access. Smaller players and developing countries become dependent. The digital sovereignty of nations is challenged. Europe, Asia, and Latin America are responding with national AI strategies, but the dominance of US-based hyperscalers remains overwhelming.
Small Language Models (SLMs) and decentralization are shifting this dynamic. Open-source SLMs like Phi-3, Gemma, Mistral, and Llama are democratizing access to state-of-the-art technology. Universities, startups, and medium-sized businesses can develop competitive applications without hyperscaler resources. The innovation barrier is lowered dramatically. A small team can create a specialized SLM that outperforms Google or Microsoft in its niche.
Economic viability is shifting in favor of smaller players. While LLM development requires budgets in the hundreds of millions, SLMs are feasible with five- to six-figure sums. Cloud democratization enables on-demand access to training infrastructure. Fine-tuning services abstract away complexity. The barrier to entry for AI innovation is decreasing from prohibitively high to manageable.
Data sovereignty becomes a reality. Companies and governments can host models that never reach external servers. Sensitive data remains under their own control. GDPR compliance is simplified. The EU AI Act, which imposes strict requirements for transparency and accountability, becomes more manageable with proprietary models instead of black-box APIs.
Innovation diversity is increasing. Instead of a monoculture of GPT-like models, thousands of specialized SLMs are emerging for specific domains, languages, and tasks. This diversity is robust against systematic errors, increases competition, and accelerates progress. The innovation landscape is becoming polycentric rather than hierarchical.
The risks of concentration are becoming evident. Dependence on a few providers creates single points of failure. Outages at AWS or Azure cripple global services. Political decisions by a hyperscaler, such as usage restrictions or regional lockouts, have cascading effects. Decentralization through SLMs fundamentally reduces these systemic risks.
The strategic realignment
For companies, this analysis implies fundamental strategic adjustments. Investment priorities are shifting from centralized cloud infrastructure to heterogeneous, distributed architectures. Instead of maximum dependence on hyperscaler APIs, the goal is autonomy through in-house SLMs. Skills development focuses on model fine-tuning, edge deployment, and hybrid orchestration.
The build-versus-buy decision is shifting. While previously purchasing API access was considered rational, developing in-house, specialized SLMs is becoming increasingly attractive. The total cost of ownership over three to five years clearly favors in-house models. Strategic control, data security, and adaptability add further qualitative advantages.
For investors, this misallocation signals caution regarding pure infrastructure plays. Data center REITs, GPU manufacturers, and hyperscalers could experience overcapacity and declining utilization if demand doesn't materialize as forecast. Value migration is occurring toward providers of SLM technology, edge AI chips, orchestration software, and specialized AI applications.
The geopolitical dimension is significant. Countries that prioritize national AI sovereignty benefit from the SLM shift. China is investing $138 billion in domestic technology, and Europe is investing $200 billion in InvestAI. These investments will be more effective when absolute scale is no longer the deciding factor, but rather smart, efficient, and specialized solutions. The multipolar AI world is becoming a reality.
The regulatory framework is evolving in parallel. Data protection, algorithmic accountability, environmental standards – all of these favor decentralized, transparent, and efficient systems. Companies that adopt SLMs and edge computing early on position themselves favorably for compliance with future regulations.
The talent landscape is transforming. While previously only elite universities and top tech companies had the resources for LLM research, now virtually any organization can develop SLMs. The skills shortage that hinders 87 percent of organizations from hiring AI is being mitigated by lower complexity and better tools. Productivity gains from AI-supported development amplify this effect.
The way we measure the ROI of AI investments is shifting. Instead of focusing on raw compute capacity, efficiency per task is becoming the core metric. Enterprises are reporting an average ROI of 5.9 percent on AI initiatives, significantly below expectations. The reason often lies in using oversized, expensive solutions for simple problems. The shift to task-optimized SLMs can dramatically improve this ROI.
The analysis reveals an industry at a turning point. The $57 billion misinvestment is more than just an overestimation of demand. It represents a fundamental strategic miscalculation about the architecture of artificial intelligence. The future belongs not to centralized giants, but to decentralized, specialized, efficient systems. Small language models are not inferior to large language models—they are superior for the vast majority of real-world applications. The economic, technical, environmental, and strategic arguments converge on a clear conclusion: The AI revolution will be decentralized.
The shift in power from providers to operators, from hyperscalers to application developers, from centralization to distribution marks a new phase in AI evolution. Those who recognize and embrace this transition early on will be the winners. Those who cling to the old logic risk their expensive infrastructures becoming stranded assets, overtaken by more agile, efficient alternatives. The $57 billion is not just wasted—it marks the beginning of the end for a paradigm that is already obsolete.
Your global marketing and business development partner
☑️ Our business language is English or German
☑️ NEW: Correspondence in your native language!

Konrad Wolfenstein
I and my team are happy to be available to you as your personal advisor.
You can contact me by filling out the contact form here wolfenstein@xpert.digital:or simply call me at +49 7348 4088 965. My email address is
I'm looking forward to our joint project.
☑️ SME support in strategy, consulting, planning and implementation
☑️ Creation or realignment of the digital strategy and digitization
☑️ Expansion and optimization of international sales processes
☑️ Global & Digital B2B trading platforms
☑️ Pioneer Business Development / Marketing / PR / Trade Fairs
🎯🎯🎯 Benefit from Xpert.Digital's extensive, five-fold expertise in one comprehensive service package | BD, R&D, XR, PR & Digital Visibility Optimization

Benefit from Xpert.Digital's extensive, five-fold expertise in a comprehensive service package | R&D, XR, PR & Digital Visibility Optimization - Image: Xpert.Digital
Xpert.Digital possesses in-depth knowledge across various industries. This allows us to develop tailored strategies precisely aligned with the requirements and challenges of your specific market segment. By continuously analyzing market trends and monitoring industry developments, we can act proactively and offer innovative solutions. The combination of experience and expertise generates added value and provides our clients with a decisive competitive advantage.
More information here: