Menneskerne og processerne bag kunstig intelligens – @shutterstock | Zapp2Photo
Kunstig intelligens har et dårligt ry som jobdræber og erstatning for menneskelige medarbejdere. På nogle områder er dette sandt, men på andre, især inden for datarensning og -behandling, er AI førende i skabelsen af nye job.
'Datamærkning og -annotering' er en blomstrende industri, der er opstået fra AI. Ustrukturerede datasæt fra kilder som kameraer og sociale medier, eller strukturerede kilder som databaser, mærkes, tagges, farves eller fremhæves for at afsløre forskelle og ligheder mellem individer. For at træne en maskine til at genkende et stopskilt, ville en person gå ind i et gadekameras optagelser og tagge alle stopskiltene på billedet. Maskinen ville derefter blive fodret med data, der identificerer tusindvis af disse billeder. Over tid, ved at behandle de taggede data, kunne systemet blive mere præcist i at genkende, hvad et stopskilt er. Denne type maskinlæring, hvor et system forbedrer nøjagtigheden ved at modtage flere data, kaldes dyb læring.
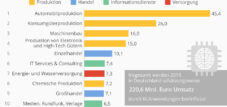
Fordi denne proces er essentiel for, at algoritmer kan udføre kernefunktioner præcist, vil datamærkningsindustrien få betydelig betydning i løbet af de næste fem år. I 2018 blev markedet for dataforberedelse af AI og maskinlæring, en proces, der er stærkt afhængig af menneskers manuelle mærkning af data, vurderet til 500 millioner dollars. Ifølge Cognilytica forventes dette at blive mere end fordoblet og nå 1,2 milliarder dollars i 2023. Tredjepartsudbydere forventer en betydelig stigning i denne vækst fra en markedsstørrelse på 150 millioner dollars til 1 milliard dollars i samme periode. Datamærkning er især vigtig for AI-applikationer såsom objekt- og billedgenkendelse, autonome køretøjer og tekst- og billedannotation.
Kunstig intelligens får et dårligt ry som jobdræber og erstatning for menneskelige medarbejdere. På nogle områder er dette sandt, men på andre, især omkring hvordan data renses og behandles, står AI i spidsen for nye job.
Datamærkning og annotering er en blomstrende industri, der er født af kunstig intelligens. Ustrukturerede datasæt fra kilder som kameraer og sociale mediedata eller strukturerede kilder, som databaser, mærkes, farves eller fremhæves for at vise forskelle og ligheder mellem personer. For at træne en maskine til at lære, hvad et stopskilt er, skal en person gå ind i kameraoptagelser af en gade og markere alle stopskiltene på billedet. Maskinen får derefter data, der identificerer tusindvis af disse billeder. Med tiden kan systemet mere præcist identificere, hvad et stopskilt er, ved at behandle de mærkede data. Denne type maskinlæring, hvor et system bliver mere præcist ved at blive fodret med flere data, kaldes dyb læring.
Da denne proces er essentiel for, at algoritmer præcist kan udføre centrale dele af sin funktion, forventes datamærkningsindustrien at tage fart i løbet af de næste fem år. I 2018 lå markedet for dataforberedelse inden for AI og maskinlæring, en proces, der i høj grad er afhængig af mennesker til manuelt at mærke data, på 500 millioner dollars. Ifølge Cognilyticaforventes dette at blive mere end fordoblet og nå 1,2 milliarder dollars i 2023. Tredjepartsudbydere forventer at se en betydelig stigning i denne vækst, der går fra 150 millioner dollars af markedet til 1 milliard dollars i samme tidsramme. Datamærkning er især vigtig for AI, der beskæftiger sig med objekt- og billedgenkendelse, autonome køretøjer og tekst- og billedannotation.


Hold kontakten