
Strukturovaná data (značkování) ve věku umělé inteligence se Schema.org: Co si inženýři Googlu skutečně myslí
Předběžné vydání Xpertu

Available in 27 languages 📢
Preferujte Xpert.Digital na GoogluⓘPublikováno: 7. května 2026 / Aktualizováno: 7. května 2026 – Autor: Konrad Wolfenstein
Strukturovaná data (značkování) ve věku umělé inteligence se Schema.org: Co si inženýři Googlu skutečně myslí – Obrázek: Xpert.Digital
Tajemství SEO od Googlu: Proč umělá inteligence selhává bez strukturovaných dat
Navzdory ChatGPT a spol.: Proč inženýři Googlu nadále přísahají na Schema.org
Aktualizace SEO: Proč Schema.org nyní nahrazuje Open Graph na Googlu
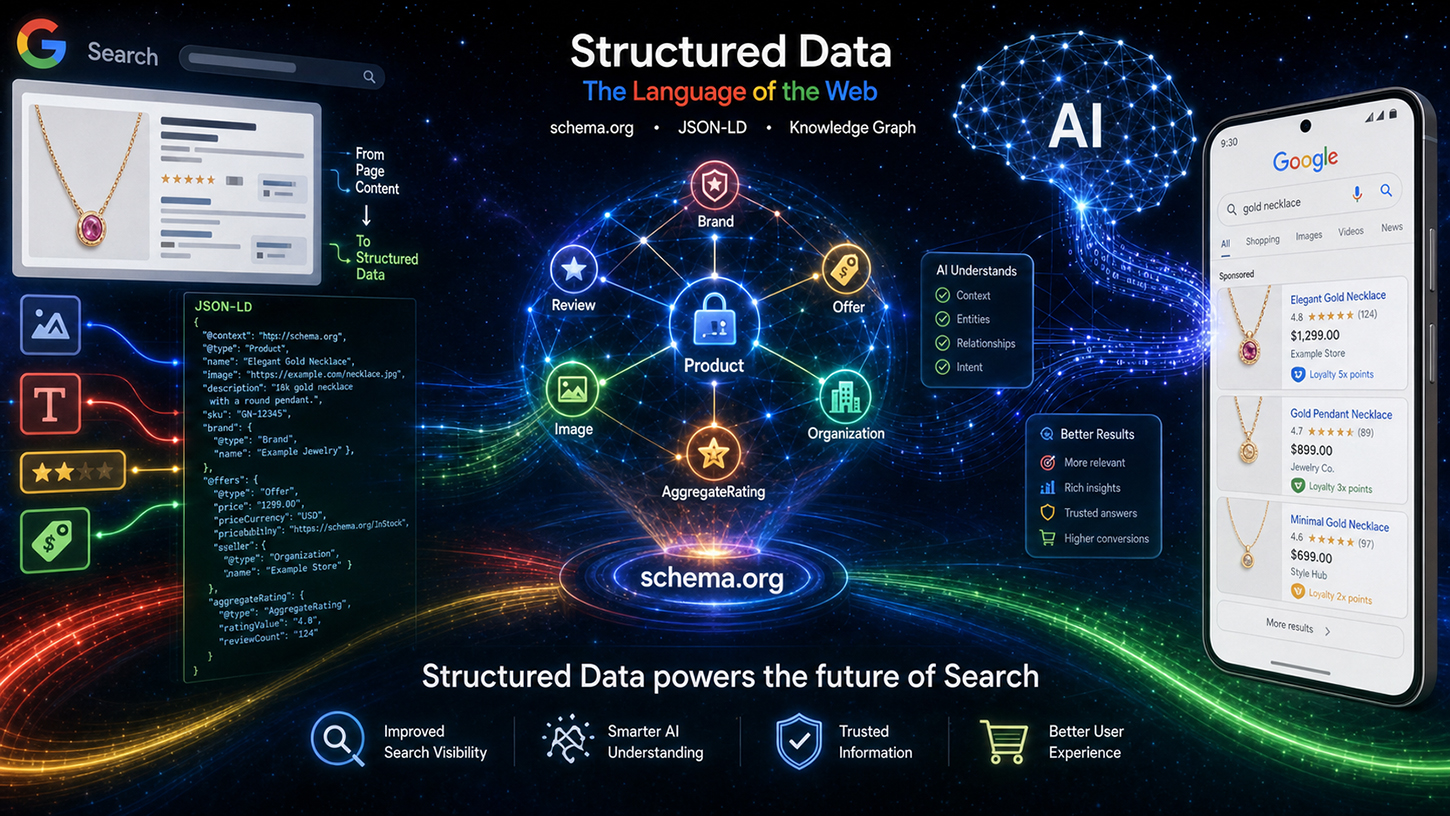
Ve světě SEO koluje přetrvávající mýtus: Ve věku brilantních jazykových modelů umělé inteligence, které bez námahy rozumí i nestrukturovanému textu, se pečlivě udržovaná strukturovaná data, jako je Schema.org, jednoduše stala zastaralými. Realita je však zcela jiná. Na akci Google Search Central Live inženýr Googlu Ryan Levering tento omyl vyvrátil a jednoznačně uvedl: Strukturované značkování není přežitkem minulosti, ale spíše základní páteří nového vyhledávání poháněného umělou inteligencí.
Od nových přehledů umělé inteligence až po autonomní nákupní agenty, jazykové modely potřebují přesné, strojově čitelné pokyny, aby se zabránilo halucinacím a aby fungovaly výpočetně efektivně. Ti, kdo chtějí zůstat viditelní na moderním webu, musí strojům pomoci pochopit kontext bez dvojznačnosti. Tento článek zkoumá strategickou změnu zaměření Googlu, představuje revoluční inovace pro elektronické obchodování a uživatelsky generovaný obsah a ukazuje, proč je technické SEO nyní rozhodující konkurenční výhodou v boji o viditelnost pro stroje.
Stroje dokážou číst web – ale jen pokud jim pomůžete mu porozumět
21. dubna 2026 se v Torontu konala první živá akce Google Search Central na kanadské půdě – a nebylo to obyčejné setkání z oboru. Ryan Levering, inženýr ze společnosti Google Search Engineering, přednesl pravděpodobně technicky nejnabitější a strategicky nejvýznamnější prezentaci dne: „Strukturovaná data, kvalita a umělá inteligence“. Jeho prezentace byla více než jen technický přehled. Bylo to jasné prohlášení o budoucnosti sémantického webu v době, kdy umělá inteligence stále více přebírá roli prostředníka mezi uživateli a informacemi.
Mezi dvěma extrémy: Špatný buď-anebo
Ryan Levering na začátku své prezentace postavil do kontrastu dva diametrálně odlišné názory kolující v SEO komunitě. Na jedné straně panuje přesvědčení, že strukturovaná data jsou v době výkonných jazykových modelů jednoduše nadbytečná: Pokud modely umělé inteligence dokáží snadno interpretovat nestrukturovaný text, proč se obtěžovat s pracným přidáváním značek schema.org do zdrojového kódu? Na druhou stranu někteří nadšenci šíří myšlenku, že strukturovaná data jsou budoucností internetu – univerzálním sémantickým komunikačním protokolem mezi autonomními agenty umělé inteligence, který do značné míry nahradí tradiční web.
Levering odmítl oba extrémy a místo toho představil nuancovanou, empiricky podloženou perspektivu. Oba postoje obsahovaly zrnko pravdy, došel k závěru, ale ani jeden plně nepopisoval realitu. Tato nuance je charakteristická pro současný přístup Googlu k tomuto tématu: nejde o dogma, ale o pragmatickou efektivitu.
Čtyři argumenty, které vysvětlují vše
Leveringův ústřední argument lze shrnout do čtyř klíčových bodů, které rozvedl pod názvem „Hodnota strukturovaných dat“. Prvním bodem je přesnost: Strukturovaná data poskytují výrazně vyšší přesnost pro složitá schémata, jako jsou prodejní ceny nebo věrnostní programy, než extrakce z volného textu založená na LLM. Jazykové modely mohou být zavádějící – doplňují chybějící atributy, nesprávně vnořují data nebo přistupují k informacím mimo kontext. Při extrakci cen produktů z velkého e-commerce webu s desítkami podobných položek je míra chyb výrazně vyšší s využitím umělé inteligence než s čistě implementovaným, strukturovaným značkováním.
Druhý bod se týká dodatečného obsahu: Strukturovaná data často obsahují neviditelná metadata, která jednoduše nejsou přítomna ve vykresleném HTML stránky. Kompletní formáty data ISO, stabilní identifikátory pro uživatelsky generovaný obsah nebo interní ID entit – tyto informace existují výhradně ve značkovacím kódu. Žádný jazykový model nedokáže extrahovat to, co není v textu.
Za třetí, efektivita: Parsování strukturovaného kódu je mnohonásobně levnější než zpracování velkého jazykového modelu za účelem extrakce složitých dat. Google denně indexuje miliardy stránek. Výpočet je jednoduchý: Běžný parser zpracovávající JSON-LD spotřebuje zlomek výpočetních zdrojů oproti kroku inference LLM. Strukturovaná data jsou proto nejen sémanticky lepší – jsou také výrazně efektivnější z obchodního hlediska. Tento bod má přímý význam pro infrastrukturu Googlu.
Čtvrtým a možná nejvíce podceňovaným aspektem je zaměření: Strukturovaná data explicitně zvýrazňují, které informace jsou na stránce relevantní, a tím zabraňují systémům umělé inteligence v zachycování irelevantních dat. Na stránce produktu s hlavním článkem, několika souvisejícími produkty a navigační lištou plnou cen si jazykový model bez explicitní anotace nemůže být jistý, na kterou cenu se má odkazovat. Strukturované značkování tento problém řeší jednoznačným přiřazením.
Jak se strukturovaná data skutečně zpracovávají
Díky Leveringu byl proces technického zpracování transparentní. Data Schema.org jsou nejprve zpracována specifickým čištěním a filtrováním, než jsou zařazena do kategorií indexovaných dat – rozdělena do oblastí, jako jsou události, nakupování a recenze. Tato připravená data pak proudí do dvou různých výstupních kanálů: na jedné straně na klasickou stránku s výsledky vyhledávání (SRP) a na druhé straně jako kontext pro systémy Google založené na umělé inteligenci, konkrétně tzv. AI Overviews (AIO) a AI Mode (AIM). Strukturovaná data tak již nejsou jen nástrojem pro bohaté výsledky, ale přímým vstupem pro generativní reakce umělé inteligence. To představuje zásadní posun ve strategickém významu značení schema.org.
🎯🎯🎯 Datově řízené centrum pro B2B průmysl jako kvazi-interní řešení

Kvazi-interní řešení: Jak Xpert.Digital uzavírá provozní mezery v marketingu a prodeji B2B – Smart Content-Driven Business - Obrázek: Xpert.Digital
Xpert.Digital je datově orientované B2B centrum pro průmysl, které vede Konrad Wolfenstein . Společnost funguje jako externí, kvazi-interní řešení pro průmyslové partnery a odstraňuje provozní mezery v marketingu, obsahu a prodeji – aniž by vyžadovala další zdroje na straně klienta.
Více informací zde:
Proč se strukturovaná data stávají infrastrukturou pro agenty umělé inteligence
Nakupování v centru pozornosti: Doprava, věrnostní program a varianty
Významná část prezentace se zaměřila na inovace v elektronickém obchodování. Levering vysvětlil, že podle údajů Baymardova institutu se neočekávané informace o dopravě umístily na druhém a třetím místě mezi nejčastějšími důvody opuštění nákupního košíku. Strukturované značkování pro přepravní služby může tento problém přímo řešit: Obchodníci nyní mohou přímo v kódu přesně definovat regiony odeslání a určení, rozměry a hmotnosti, prahové hodnoty objednávky, doby zpracování a příslušnost k věrnostním programům.
Model doby dodání, který Google používá, je rozdělen do dvou fází: doby zpracování, tj. doby od přijetí objednávky do předání dopravci, a skutečné doby doručení. Obě fáze lze anotovat samostatně a s vysokou granularitou – až po uzávěrku objednávek a to, zda zpracování probíhá i ve všední dny. Odpovídající příklady JSON-LD ukazují, jak lze typ `ShippingConditions` použít k definování dopravy zdarma pro určité země (např. Francie a Německo) a minimální hodnoty objednávky (např. 50 €).
Obzvláště inovativní je integrace přepravních služeb s věrnostními programy. Pomocí vlastnosti `validForMemberTier` lze přepravní službu explicitně propojit s členským programem a konkrétní úrovní. To umožňuje deklarovat výhody dopravy pro prémiové členy přímo v kódu – funkce, kterou bylo dříve možné konfigurovat pouze prostřednictvím služby Google Merchant Center. Samotný přidružený věrnostní program je definován jako objekt `MemberProgram` v rámci entity `Organization` s úrovněmi jako „Gold“ nebo „Silver“ a souvisejícími výhodami, jako jsou věrnostní odměny nebo bodové odměny.
Věrnostní programy jako sémantické entity
Zavedení značkování věrnostních programů je ekonomicky významné. Organizace si mohou definovat více nezávislých členských programů, každý s několika úrovněmi a diferencovanými výhodami – body, členské ceny, podmínky vrácení zboží, bonusy za dopravu. Tyto informace se pak zobrazují přímo ve výsledcích vyhledávání Google, jak Levering demonstroval na příkladech z reálného světa, včetně nabídky Sephory, která zobrazovala 30% členskou slevu přímo v nákupním úryvku. Propojení ID napříč stránkami, tedy možnost odkazovat na definice věrnostních programů z jiných stránek, je podle Leveringa dalším plánovaným krokem, v současné době s názvem „Proklestování cesty pro propojení @id napříč stránkami“. Cílem: silnější organizační odkazy mezi stránkami produktů a firemními politikami.
Uživatelsky generovaný obsah: Problém označování pomocí umělé inteligence
Dalším důležitým tématem byl další vývoj typů schémat pro uživatelsky generovaný obsah (UGC). Dvě nové funkce jsou zde obzvláště důležité. Zaprvé, vložené příspěvky a reposty jsou podporovány ve značkách fór a otázek a odpovědí, což umožňuje přesnější sémantickou reprezentaci diskusních struktur. Zadruhé – a to má ještě větší strategický význam – je zavedena vlastnost `so#digitalSourceType` pro explicitní identifikaci strojově generovaného obsahu.
Tento vývoj je přímou reakcí na záplavu obsahu generovaného umělou inteligencí na platformách, jako jsou fóra a stránky s otázkami a odpověďmi. Správci webů nyní mohou deklarovat, zda byl příspěvek generován algoritmicky nebo jazykovým modelem. Ti, kteří tuto možnost neuvedou, jsou Googlem implicitně považováni za lidské autory – toto pravidlo podporuje transparentní označování. Vlastnost `digitalSourceType` je založena na kódech IPTC pro digitální zdroje a rozlišuje mimo jiné mezi algoritmicky generovaným a modelově generovaným obsahem.
Výběr obrázku: Schéma předčí Open Graph
Méně pozorovaná, ale prakticky účinná aktualizace se týká logiky výběru obrázků v Googlu. Systém je interně konsolidován s jasnou hierarchií priorit: přednost má kódování Schema.org, konkrétně vlastnosti `primaryImageOfPage` a `mainEntity → image`. Teprve poté následuje meta tag `og:image` z Open Graphu. Tato změna znamená, že pro provozovatele webových stránek čistá implementace hlavního obrázku ve schema.org přímo ovlivňuje jeho zobrazení ve výsledcích vyhledávání Google a v přehledech AI – což je konkrétní a měřitelná výhoda.
Schema.org sama o sobě přijímá investice
Za zmínku stojí také oznámená reinvestice společnosti Google do schema.org jako otevřené specifikace. Byla zmíněna tři konkrétní opatření: zveřejnění statistik o četnosti používání jednotlivých termínů schématu (data o prevalenci, jak ukazuje prezentace, jsou již k dispozici pro jednotlivé termíny, jako je `digitalSourceType` s informacemi o přibližně 10 000 doménách), zveřejnění vlastních ověřovacích pravidel společnosti Google ve strojově čitelných standardních formátech, jako je SHACL nebo ShEx, a vylepšená podpora pravidel pořadí. To je významné, protože by to externím vývojářům umožnilo vytvářet si vlastní ověřovací nástroje založené na standardech společnosti Google – nezávisle na oficiálních testovacích nástrojích, které občas při zátěži havarují.
Validace: Dva nástroje, jeden cíl
Levering představil dva validační nástroje, které se vzájemně doplňují, ale používají různá testovací kritéria. Nástroj pro testování rozšířených výsledků vyhledávání (Rich Results Test Tool) na adrese `search.google.com/test/rich-results` přijímá URL adresy nebo čistý JSON a kontroluje, zda je kódování vhodné pro rozšířené výsledky vyhledávání Google – je tedy založen na specifických požadavcích Googlu, nikoli na samotném standardu schema.org. Nástroj `validator.schema.org` naopak kontroluje, zda je kódování kompatibilní se schema.org, tj. zda dodržuje otevřenou slovní zásobu, bez ohledu na to, zda z něj Google generuje rozšířené výsledky. To vede k jasnému doporučení pro webové vývojáře: měly by se používat oba nástroje, protože kódování může být kompatibilní se schématem, ale nemusí být schopné rozšířených výsledků vyhledávání – a naopak.
Širší kontext: Strukturovaná data jako infrastruktura umělé inteligence
Při pohledu na událost v Torontu jako celek je patrný posun, který sahá daleko za hranice tradiční SEO optimalizace. Strukturovaná data se vyvíjejí z nástroje pro získávání bohatých úryvků na základní standard datové vrstvy pro systémy umělé inteligence. Přehledy AI a režim AI od Googlu aktivně používají značkování schema.org jako kontext pro generování odpovědí a ověřování entit. Ti, kteří implementují správná, úplná a přesná strukturovaná data, nejen zvyšují své šance na dosažení vizuálního zvýraznění ve výsledcích vyhledávání, ale také pozicionují svůj obsah jako spolehlivý primární zdroj odpovědí s využitím umělé inteligence.
Zmínka o Universal Commerce Protocol (UCP) a WebMCP v této souvislosti není náhodná. Oba standardy komunikace založené na agentech, které Google v raných verzích vydal v roce 2026, vyžadují, aby webové stránky byly sémanticky popsány. Základem pro to je Schema.org. Ve světě, kde agenti umělé inteligence jednají na webu autonomně, vyhledávají, porovnávají a iniciují transakce, strojová čitelnost obsahu již není volitelná, ale předpokladem pro ekonomickou relevanci. Prezentace Ryana Leveringa v Torontu proto nebyla jen technickou aktualizací – byl to letmý pohled do infrastruktury příštího webu.
Zjistíte to sami za 10 sekund
Pokud chcete vědět, jak dobře a komplexně váš nebo jiný web využívá strukturovaná data, můžete použít přesně ty dva nástroje, které doporučil Ryan Levering z Googlu (z našeho textu výše):
Test rozšířených výsledků vyhledávání Google (se zaměřením na viditelnost na Googlu):
Přejděte na search.google.com/test/rich-results, zkopírujte URL libovolného článku z xpert.digital a klikněte na „Test URL“. Nástroj vám přesně ukáže, které kódy Google na dané stránce rozpoznává a zda neobsahují chyby.
Validátor schémat (zaměření na čistou shodu se standardy):
Přejděte na validator.schema.orga vložte stejnou URL adresu. Zde můžete přímo ve zdrojovém kódu, barevně zvýrazněném, vidět, které JSON-LD skripty (strukturovaná data) xpert.digital začlenil.
Váš globální partner pro marketing a rozvoj obchodu
☑️ Naším obchodním jazykem je angličtina nebo němčina
☑️ NOVINKA: Korespondence ve vašem rodném jazyce!

Konrad Wolfenstein
Já a můj tým jsme rádi, že vám můžeme být k dispozici jako váš osobní poradce.
Můžete mě kontaktovat vyplněním kontaktního formuláře zde jednoduše zavolat na číslo +49 7348 4088 965. Moje e-mailová adresa je [email protected]:nebo
Těším se na náš společný projekt.
☑️ Podpora malých a středních podniků v oblasti strategie, poradenství, plánování a implementace
☑️ Vytvoření nebo restrukturalizace digitální strategie a digitalizace
☑️ Rozšíření a optimalizace mezinárodních prodejních procesů
☑️ Globální a digitální B2B obchodní platformy
☑️ Průkopnický rozvoj podnikání / Marketing / PR / Veletrhy
Kombinace podpory B2B a SaaS pro SEO a GEO (vyhledávání s využitím umělé inteligence): Komplexní řešení pro B2B společnosti

Kombinace podpory B2B a SaaS pro SEO a GEO (vyhledávání s umělou inteligencí): Řešení typu „vše v jednom“ pro B2B společnosti – Obrázek: Xpert.Digital
Vyhledávání s umělou inteligencí mění všechno: Jak toto SaaS řešení navždy zrevolucionizuje vaše umístění v B2B segmentu.
Digitální prostředí pro B2B společnosti prochází rychlými změnami. Pod vlivem umělé inteligence se přepisují pravidla online viditelnosti. Pro firmy bylo vždy výzvou nejen být viditelné v digitální masě, ale také být relevantní pro ty správné osoby s rozhodovací pravomocí. Tradiční SEO strategie a řízení lokální přítomnosti (geomarketing) jsou složité, časově náročné a často představují boj s neustále se měnícími algoritmy a intenzivní konkurencí.
Ale co kdyby existovalo řešení, které by tento proces nejen zjednodušilo, ale také ho učinilo chytřejším, prediktivnějším a mnohem efektivnějším? A právě zde přichází na řadu kombinace specializované podpory B2B s výkonnou platformou SaaS (Software as a Service), která je speciálně navržena pro požadavky SEO a GEO ve věku vyhledávání s využitím umělé inteligence.
Tato nová generace nástrojů se již nespoléhá pouze na manuální analýzu klíčových slov a strategie zpětných odkazů. Místo toho využívá umělou inteligenci k přesnějšímu pochopení záměru vyhledávání, automatické optimalizaci lokálních faktorů hodnocení a provádění konkurenční analýzy v reálném čase. Výsledkem je proaktivní strategie založená na datech, která dává společnostem B2B rozhodující výhodu: jsou nejen nalezeny, ale také vnímány jako přední autorita ve svém oboru a lokalitě.
Zde je symbióza podpory B2B a SaaS technologie s umělou inteligencí, která transformuje SEO a GEO marketing, a jak z ní může vaše společnost těžit k udržitelnému růstu v digitálním prostoru.
Více informací zde:

















