


AI a SEO s BERT – Obousměrné reprezentace enkodéru z transformátorů – Model v oblasti zpracování přirozeného jazyka (NLP) – Obrázek: Xpert.Digital
🚀💬 Vyvinuto společností Google: BERT a jeho význam pro NLP - Proč je obousměrné porozumění textu klíčové
🔍🗣️ BERT, zkratka pro Bidirectional Encoder Representations od Transformers, je významný model v oblasti zpracování přirozeného jazyka (NLP) vyvinutý společností Google. Způsobil revoluci ve způsobu, jakým stroje rozumí jazyku. Na rozdíl od předchozích modelů, které analyzovaly text postupně zleva doprava nebo naopak, BERT umožňuje obousměrné zpracování. To znamená, že zachycuje kontext slova z předchozí i následující textové sekvence. Tato schopnost výrazně zlepšuje porozumění složitým jazykovým vztahům.
🔍 Architektura BERTu
V posledních letech došlo k jednomu z nejvýznamnějších pokroků v oblasti zpracování přirozeného jazyka (NLP) se zavedením modelu Transformer, jak je popsáno v PDF článku z roku 2017 „Attention is all you need“ (Wikipedie). Tento model zásadně změnil obor tím, že opustil dříve používané struktury, jako je strojový překlad. Místo toho se spoléhá výhradně na mechanismy pozornosti. Model Transformer od té doby tvořil základ pro mnoho modelů, které představují nejmodernější technologie v různých oblastech, včetně generování řeči, překladu a dalších.
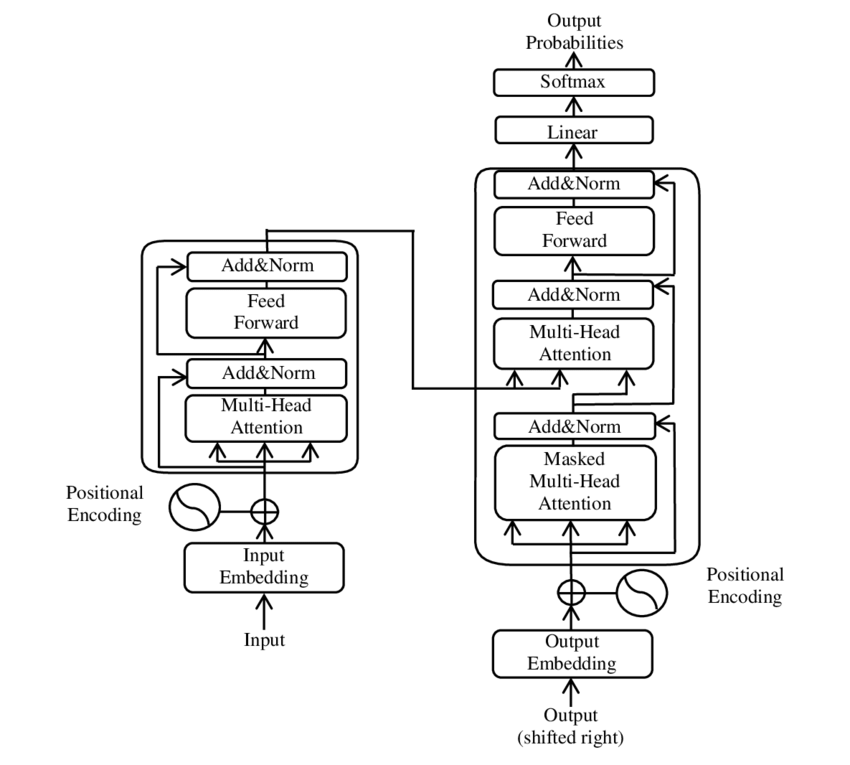
Ilustrace hlavních součástí modelu Transformer – Obrázek: Google
BERT je založen na této transformační architektuře. Tato architektura využívá tzv. mechanismy vlastní pozornosti k analýze vztahů mezi slovy ve větě. Každému slovu je věnována pozornost v kontextu celé věty, což vede k přesnějšímu pochopení syntaktických a sémantických vztahů.
Autoři článku „Pozornost je vše, co potřebujete“ jsou:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Lion Jones (Google Research)
- Aidan N. Gomez (Univerzita v Torontu, práce částečně prováděná v Google Brain)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (nezávislý, předchozí práce ve společnosti Google Research)
Tito autoři významně přispěli k vývoji modelu Transformer prezentovaného v tomto článku.
🔄 Obousměrné zpracování
Klíčovou vlastností BERT je jeho schopnost zpracovávat text obousměrně. Zatímco tradiční modely, jako jsou rekurentní neuronové sítě (RNN) nebo sítě s dlouhou krátkodobou pamětí (LSTM), zpracovávají text pouze jedním směrem, BERT analyzuje kontext slova v obou směrech. To umožňuje modelu lépe zachytit jemné významové nuance a tím vytvářet přesnější předpovědi.
🕵️♂️ Modelování maskované řeči
Dalším inovativním aspektem BERTu je technika maskovaného jazykového modelu (MLM). Zde jsou náhodně vybraná slova ve větě maskována a model je trénován k předpovídání těchto slov na základě okolního kontextu. Tato metoda nutí BERT rozvíjet hluboké porozumění kontextu a významu každého slova ve větě.
🚀 Školení a adaptace BERT
BERT prochází dvoufázovým tréninkovým procesem: předtréninkem a dolaďováním.
📚 Předtrénink
V předběžné fázi se BERT trénuje s velkým množstvím textu, aby se naučil obecné jazykové vzory. To zahrnuje články z Wikipedie a další rozsáhlé textové korpusy. Během této fáze se model učí základní jazykové struktury a kontexty.
🔧 Jemné doladění
Po předběžném trénování je BERT adaptován pro specifické úlohy NLP, jako je klasifikace textu nebo analýza sentimentu. Model je trénován s menšími, s úlohami souvisejícími datovými sadami, aby se optimalizoval jeho výkon pro konkrétní aplikace.
🌍 Oblasti použití BERTu
BERT se ukázal jako mimořádně užitečný v mnoha oblastech zpracování přirozeného jazyka:
Optimalizace pro vyhledávače
Google používá BERT k lepšímu pochopení vyhledávacích dotazů a zobrazování relevantnějších výsledků. To výrazně zlepšuje uživatelský zážitek.
Klasifikace textu
BERT dokáže kategorizovat dokumenty podle tématu nebo analyzovat náladu v textech.
Rozpoznávání pojmenovaných entit (NER)
Model identifikuje a klasifikuje pojmenované entity v textech, jako jsou jména lidí, míst nebo organizací.
Systémy otázek a odpovědí
BERT se používá k poskytování přesných odpovědí na kladené otázky.
🧠 Význam BERT pro budoucnost umělé inteligence
BERT stanovil nové standardy pro modely NLP a vydláždil cestu pro další inovace. Díky své schopnosti obousměrného zpracování a hlubokému porozumění jazykovým kontextům výrazně zvýšil efektivitu a přesnost aplikací umělé inteligence.
🔜 Budoucí vývoj
Očekává se, že další vývoj BERT a podobných modelů směřuje k vytvoření ještě výkonnějších systémů. Ty by mohly zvládat složitější jazykové úlohy a být použity v široké škále nových aplikačních oblastí. Integrace takových modelů do každodenních technologií by mohla zásadně změnit způsob, jakým interagujeme s počítači.
🌟 Milník ve vývoji umělé inteligence
BERT je milníkem ve vývoji umělé inteligence a způsobil revoluci ve způsobu, jakým stroje zpracovávají přirozený jazyk. Jeho obousměrná architektura umožňuje hlubší pochopení jazykových vztahů, což ho činí nepostradatelným pro širokou škálu aplikací. S postupujícím výzkumem budou modely jako BERT i nadále hrát ústřední roli ve zlepšování systémů umělé inteligence a otevírání nových možností jejich využití.
📣 Podobná témata
- 📚 Úvod do BERT: Průlomový model NLP
- 🔍 BERT a role obousměrnosti v NLP
- 🧠 Model Transformer: Základy BERTu
- 🚀 Modelování maskovaného jazyka: Klíč k úspěchu BERTu
- 📈 Přizpůsobení BERT: Od předtréninku až po jemné doladění
- 🌐 Oblasti použití BERT v moderních technologiích
- 🤖 Vliv BERTu na budoucnost umělé inteligence
- 💡 Budoucí vyhlídky: Další vývoj BERTu
- 🏆 BERT jako milník ve vývoji umělé inteligence
- 📰 Autoři článku Transformer „Pozornost je vše, co potřebujete“: Mozky stojící za BERT
#️⃣ Hashtagy: #NLP #UměláInteligence #ModelováníJazyka #Transformer #StrojovéUčení
🎯🎯🎯 Využijte rozsáhlé pětinásobné odborné znalosti společnosti Xpert.Digital v jednom komplexním balíčku služeb | BD, výzkum a vývoj, XR, PR a optimalizace digitální viditelnosti


Využijte rozsáhlé, pětinásobné odborné znalosti společnosti Xpert.Digital v komplexním balíčku služeb | Výzkum a vývoj, XR, PR a optimalizace digitální viditelnosti - Obrázek: Xpert.Digital
Společnost Xpert.Digital disponuje hlubokými znalostmi napříč různými odvětvími. To nám umožňuje vyvíjet strategie na míru, které přesně odpovídají požadavkům a výzvám vašeho specifického segmentu trhu. Díky neustálé analýze tržních trendů a sledování vývoje v odvětví můžeme jednat proaktivně a nabízet inovativní řešení. Kombinace zkušeností a odborných znalostí vytváří přidanou hodnotu a poskytuje našim klientům rozhodující konkurenční výhodu.
Více informací zde:
BERT: Revoluční 🌟 NLP technologie
🚀 BERT, zkratka pro Bidirectional Encoder Representations from Transformers, je pokročilý jazykový model vyvinutý společností Google, který se od svého uvedení na trh v roce 2018 stal významným průlomem ve zpracování přirozeného jazyka (NLP). Je založen na architektuře Transformer, která způsobila revoluci v tom, jak stroje rozumí a zpracovávají text. Ale co přesně dělá BERT tak výjimečným a k čemu se používá? Abychom na tuto otázku odpověděli, musíme se blíže podívat na technické základy BERTu, jak funguje a jaké aplikace má.
📚 1. Základy zpracování přirozeného jazyka
Abychom plně pochopili význam BERT, je užitečné stručně si zopakovat základy zpracování přirozeného jazyka (NLP). NLP se zabývá interakcí mezi počítači a lidským jazykem. Jeho cílem je naučit stroje analyzovat, rozumět textovým datům a reagovat na ně. Před zavedením modelů, jako je BERT, bylo zpracování strojového jazyka často spojeno s značnými problémy, zejména kvůli nejednoznačnosti, závislosti na kontextu a složité struktuře lidského jazyka.
📈 2. Vývoj NLP modelů
Před vznikem BERT byla většina modelů NLP založena na tzv. jednosměrných architekturách. To znamenalo, že tyto modely četly text buď zleva doprava, nebo zprava doleva, což znamenalo, že při zpracování slova ve větě mohly zohledňovat pouze omezené množství kontextu. Toto omezení často vedlo k tomu, že modely nedokázaly plně zachytit sémantický kontext věty. To ztěžovalo přesnou interpretaci nejednoznačných nebo kontextově citlivých slov.
Dalším důležitým vývojem ve výzkumu NLP před BERT byl model word2vec, který umožňoval počítačům překládat slova do vektorů odrážejících sémantické podobnosti. I zde však byl kontext omezen na bezprostřední okolí slova. Později byly vyvinuty rekurentní neuronové sítě (RNN) a zejména modely dlouhé krátkodobé paměti (LSTM), které umožnily lépe porozumět textovým sekvencím ukládáním informací napříč více slovy. Tyto modely však měly i svá omezení, zejména při práci s dlouhými texty a současném porozumění kontextu v obou směrech.
🔄 3. Revoluce skrze transformátorovou architekturu
Průlom nastal s uvedením architektury Transformer v roce 2017, která tvoří základ pro BERT. Modely Transformer jsou navrženy tak, aby umožňovaly paralelní zpracování textu s ohledem na kontext slova z předchozího i následujícího textu. Toho je dosaženo pomocí tzv. mechanismů vlastní pozornosti, které přiřazují váhu každému slovu ve větě na základě jeho důležitosti ve vztahu k ostatním slovům ve větě.
Na rozdíl od předchozích přístupů nejsou transformační modely jednosměrné, ale obousměrné. To znamená, že mohou čerpat informace z levého i pravého kontextu slova a vytvořit tak úplnější a přesnější reprezentaci slova a jeho významu.
🧠 4. BERT: Obousměrný model
BERT posouvá výkon architektury Transformer na novou úroveň. Model je navržen tak, aby zachytil kontext slova nejen zleva doprava nebo zprava doleva, ale v obou směrech současně. To umožňuje BERTu zohlednit kompletní kontext slova ve větě, což vede k výrazně vyšší přesnosti při zpracování přirozeného jazyka.
Klíčovou vlastností BERTu je použití tzv. modelu maskovaného jazyka (MLM). Během trénování BERTu jsou náhodně vybraná slova ve větě nahrazena maskou a model je trénován tak, aby tato maskovaná slova uhádl na základě kontextu. Tato technika umožňuje BERTu učit se hlouběji a přesněji vztahy mezi slovy ve větě.
BERT navíc používá metodu zvanou Next Sentence Prediction (NSP), ve které se model učí předpovídat, zda jedna věta následuje po druhé. To zlepšuje schopnost BERT rozumět delším textům a rozpoznávat složitější vztahy mezi větami.
🌐 5. Praktické využití BERTu
BERT se ukázal jako mimořádně užitečný pro širokou škálu úkolů NLP. Zde jsou některé z nejdůležitějších oblastí použití:
📊 a) Klasifikace textu
Jednou z nejběžnějších aplikací BERTu je klasifikace textu, kde jsou texty rozděleny do předem definovaných kategorií. Mezi příklady patří analýza sentimentu (např. rozpoznání, zda je text pozitivní nebo negativní) nebo kategorizace zpětné vazby od zákazníků. Díky hlubokému pochopení kontextu slov může BERT poskytovat přesnější výsledky než předchozí modely.
❓ b) Systémy otázek a odpovědí
BERT se také používá v systémech pro odpovídání na otázky, kde model extrahuje odpovědi na položené otázky z textu. Tato schopnost je obzvláště důležitá v aplikacích, jako jsou vyhledávače, chatboti a virtuální asistenti. Díky své obousměrné architektuře dokáže BERT extrahovat relevantní informace z textu, i když je otázka formulována nepřímo.
🌍 c) Překlad textu
Ačkoli BERT sám o sobě není přímo navržen jako překladový model, lze jej použít v kombinaci s dalšími technologiemi ke zlepšení strojového překladu. Lepším pochopením sémantických vztahů ve větě může BERT pomoci generovat přesnější překlady, zejména u nejednoznačných nebo složitých frází.
🏷️ d) Rozpoznávání pojmenovaných entit (NER)
Další oblastí použití je rozpoznávání pojmenovaných entit (NER), které zahrnuje identifikaci specifických entit, jako jsou jména, místa nebo organizace v textu. BERT se v tomto úkolu ukázal jako obzvláště efektivní, protože plně zohledňuje kontext věty, a dokáže tak lépe rozpoznávat entity, i když mají v různých kontextech různé významy.
✂️ e) Shrnutí textu
Schopnost BERTu porozumět celému kontextu textu z něj také činí mocný nástroj pro automatické shrnutí textu. Lze jej použít k extrakci nejdůležitějších informací z dlouhého textu a vytvoření stručného shrnutí.
🌟 6. Význam BERT pro výzkum a průmysl
Zavedení BERT zahájilo novou éru ve výzkumu NLP. Byl to jeden z prvních modelů, který plně využil sílu architektury obousměrného transformátoru a nastavil standard pro mnoho následujících modelů. Řada společností a výzkumných institucí integrovala BERT do svých NLP procesů, aby zlepšila výkon svých aplikací.
BERT dále vydláždil cestu pro další inovace v oblasti jazykových modelů. Například byly následně vyvinuty modely jako GPT (Generative Pretrained Transformer) a T5 (Text-to-Text Transfer Transformer), které jsou založeny na podobných principech, ale nabízejí specifická vylepšení pro různé případy použití.
🚧 7. Výzvy a omezení BERTu
Navzdory mnoha výhodám má BERT také určité výzvy a omezení. Jednou z největších překážek je vysoká výpočetní náročnost potřebná pro trénování a aplikaci modelu. Protože BERT je velmi rozsáhlý model s miliony parametrů, vyžaduje výkonný hardware a značné výpočetní zdroje, zejména při zpracování velkých datových sad.
Dalším problémem je potenciální zkreslení, které může být přítomno v trénovacích datech. Protože je BERT trénován na velkém množství textových dat, někdy odráží předsudky a stereotypy v těchto datech. Výzkumníci však neustále pracují na identifikaci a řešení těchto problémů.
🔍 Nepostradatelný nástroj pro moderní aplikace pro zpracování řeči
BERT výrazně zlepšil způsob, jakým stroje rozumí lidskému jazyku. Díky své obousměrné architektuře a inovativním metodám trénování je schopen hluboce a přesně pochopit kontext slov ve větě, což vede k větší přesnosti v mnoha úlohách NLP. Ať už se jedná o klasifikaci textu, systémy otázek a odpovědí nebo rozpoznávání entit, BERT se etabloval jako nepostradatelný nástroj pro moderní aplikace zpracování přirozeného jazyka.
Výzkum v oblasti zpracování přirozeného jazyka bude nepochybně i nadále pokračovat a BERT položil základy pro mnoho budoucích inovací. Navzdory stávajícím výzvám a omezením BERT působivě ukazuje, jak daleko se technologie v krátkém čase dostala a jaké vzrušující příležitosti se v budoucnu ještě otevřou.
🌀 Transformátor: Revoluce ve zpracování přirozeného jazyka
🌟 V posledních letech bylo jedním z nejvýznamnějších vývojů v oblasti zpracování přirozeného jazyka (NLP) zavedení modelu Transformer, jak je popsáno v článku z roku 2017 „Attention Is All You Need“ (Pozornost je vše, co potřebujete). Tento model zásadně změnil obor tím, že opustil dříve používané rekurentní nebo konvoluční struktury pro úlohy převodu sekvencí, jako je strojový překlad. Místo toho se spoléhá výhradně na mechanismy pozornosti. Model Transformer od té doby tvořil základ pro mnoho modelů, které představují nejmodernější technologie v různých oblastech, včetně generování řeči, překladu a dalších.
🔄 Transformer: Změna paradigmatu
Před zavedením Transformeru byla většina modelů pro sekvenční úlohy založena na rekurentních neuronových sítích (RNN) nebo sítích s dlouhou krátkodobou pamětí (LSTM), které ze své podstaty fungují sekvenčně. Tyto modely zpracovávají vstupní data krok za krokem a vytvářejí skryté stavy, které se šíří podél sekvence. Tato metoda je sice efektivní, ale je výpočetně nákladná a obtížně se paralelizuje, zejména u dlouhých sekvencí. RNN se navíc kvůli problému mizivého gradientu potýkají s učením dlouhodobých závislostí.
Klíčová inovace modelu Transformer spočívá v jeho použití mechanismů sebepozornosti, které umožňují modelu zvážit důležitost různých slov ve větě ve vztahu k sobě navzájem, bez ohledu na jejich pozici. To umožňuje modelu zachytit vztahy mezi slovy, která jsou navzájem velmi vzdálená, efektivněji než RNN nebo LSTM, a to paralelně, nikoli postupně. To nejen zlepšuje efektivitu trénování, ale také výkon v úlohách, jako je strojový překlad.
🧩 Architektura modelu
Transformátor se skládá ze dvou hlavních komponent: kodéru a dekodéru, které se oba skládají z několika vrstev a silně se spoléhají na mechanismy pozornosti více hlav.
⚙️ Kodér
Kodér se skládá ze šesti identických vrstev, z nichž každá má dvě podvrstvy:
1. Vícehlavá sebepozornost
Tento mechanismus umožňuje modelu zaměřit se na různé části vstupní věty při zpracování každého slova. Místo výpočtu pozornosti v jednom prostoru promítá vícehlavá pozornost vstup do několika různých prostorů, čímž zachycuje různé typy vztahů mezi slovy.
2. Polohově plně propojené sítě s dopřednou vazbou
Po vrstvě pozornosti se na každé pozici nezávisle aplikuje plně propojená dopředná síť. To pomáhá modelu zpracovat každé slovo v kontextu a využít informace z mechanismu pozornosti.
Pro zachování struktury vstupní sekvence model zahrnuje také poziční kódování. Protože transformátor nezpracovává slova postupně, jsou tato kódování klíčová pro poskytnutí informací o slovosledu ve větě modelu. Poziční kódování se přidávají k vnořením slov, aby model mohl rozlišovat mezi různými pozicemi v sekvenci.
🔍 Dekodér
Stejně jako kodér se i dekodér skládá ze šesti vrstev, z nichž každá má další mechanismus pozornosti, který umožňuje modelu zaměřit se na relevantní části vstupní sekvence při generování výstupu. Dekodér také používá techniku maskování, která mu brání v zohledňování budoucích pozic, a tím zachovává autoregresní povahu generování sekvence.
🧠 Vícehlavá pozornost a skalární pozornost produktu
Jádrem transformátoru je mechanismus vícehlavé pozornosti, který je rozšířením jednodušší skalární pozornosti s použitím součinu. Funkci pozornosti lze chápat jako mapování mezi dotazem a sadou párů klíč-hodnota, kde každý klíč představuje slovo v sekvenci a hodnota představuje odpovídající kontextovou informaci.
Mechanismus vícehlavé pozornosti umožňuje modelu soustředit se na různé části sekvence současně. Promítáním vstupu do více podprostorů může model zachytit bohatší sadu vztahů mezi slovy. To je obzvláště užitečné pro úkoly, jako je strojový překlad, kde pochopení kontextu slova vyžaduje mnoho různých faktorů, jako je syntaktická struktura a sémantický význam.
Vzorec pro výpočet pozornosti skalárního součinu je:
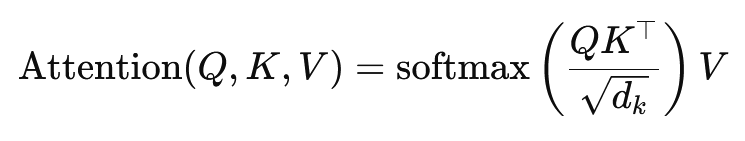
Zde (Q) je matice dotazů, (K) matice klíčů a (V) matice hodnot. Člen (sqrt{d_k}) je škálovací faktor, který zabraňuje tomu, aby se skalární součiny staly příliš velkými, což by vedlo k velmi malým gradientům a pomalejšímu učení. Funkce softmax se používá k zajištění toho, aby se váhy pozornosti součetly do jedné.
🚀 Výhody transformátoru
Transformer nabízí oproti tradičním modelům, jako jsou RNN a LSTM, několik klíčových výhod:
1. Paralelizace
Protože transformátor zpracovává všechny tokeny sekvence současně, může být vysoce paralelizován a proto se trénuje mnohem rychleji než RNN nebo LSTM, zejména u velkých datových sad.
2. Dlouhodobé závislosti
Mechanismus sebepozornosti umožňuje modelu zachytit vztahy mezi vzdálenými slovy efektivněji než RNN, které jsou omezeny sekvenční povahou jejich výpočtů.
3. Škálovatelnost
Transformátor lze snadno škálovat na velmi velké datové sady a delší sekvence, aniž by trpěl výkonnostními úzkými místy spojenými s RNN.
🌍 Aplikace a efekty
Od svého uvedení na trh se Transformer stal základem pro širokou škálu modelů NLP. Jedním z nejvýznamnějších příkladů je BERT (Bidirectional Encoder Representations from Transformers), který využívá upravenou architekturu Transformeru k dosažení špičkového výkonu v mnoha úlohách NLP, včetně odpovídání na otázky a klasifikace textu.
Dalším významným vývojem je GPT (Generativní předtrénovaný transformátor), který pro generování textu používá verzi transformátoru s omezeným dekodérem. Modely GPT, včetně GPT-3, se nyní používají v řadě aplikací, od tvorby obsahu až po dokončování kódu.
🔍 Výkonný a flexibilní model
Transformer zásadně změnil způsob, jakým přistupujeme k úkolům NLP. Nabízí výkonný a flexibilní model, který lze aplikovat na širokou škálu problémů. Jeho schopnost zvládat dlouhodobé závislosti a jeho efektivita při trénování z něj učinily preferovaný architektonický přístup pro mnoho z nejmodernějších modelů. S postupem výzkumu se pravděpodobně dočkáme dalších vylepšení a adaptací Transformeru, zejména v oblastech, jako je zpracování obrazu a řeči, kde mechanismy pozornosti vykazují slibné výsledky.
Jsme tu pro vás - Poradenství - Plánování - Implementace - Projektový management
☑️ Odborník v oboru s vlastním centrem Xpert.Digital s více než 2 500 odbornými články

Konrad Wolfenstein
Rád/a bych sloužil/a jako váš osobní poradce.
Můžete mě kontaktovat vyplněním níže uvedeného kontaktního formuláře nebo mi jednoduše zavolat na číslo +49 7348 4088 965 .
Těším se na náš společný projekt.
Napiš mi




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital je centrum pro průmysl se zaměřením na digitalizaci, strojírenství, logistiku/intralogistiku a fotovoltaiku.
S naším komplexním řešením pro rozvoj podnikání 360° podporujeme renomované společnosti od nových obchodů až po poprodejní služby.
Součástí našich digitálních nástrojů jsou analýzy trhu, s-marketing, marketingová automatizace, vývoj obsahu, PR, mailové kampaně, personalizované sociální sítě a péče o leady.
Více informací naleznete na: www.xpert.digital - www.xpert.solar - www.xpert.plus
Zůstaňte v kontaktu











