


Nová digitální viditelnost – Dekódování SEO, LLMO, GEO, AIO a AEO – Samotné SEO už nestačí – Obrázek: Xpert.Digital
Strategický průvodce generativní optimalizací pro enginy (GEO) a optimalizací velkých jazykových modelů (LLMO) (Doba čtení: 30 min / Bez reklamy / Bez paywallu)
Změna paradigmatu: Od optimalizace pro vyhledávače k generativní optimalizaci
Nová definice digitální viditelnosti ve věku umělé inteligence
Digitální informační krajina v současné době prochází nejhlubší transformací od zavedení grafického webového vyhledávání. Tradiční mechanismus, kdy vyhledávače prezentují seznam potenciálních odpovědí ve formě modrých odkazů a nechávají na uživateli, aby si relevantní informace prohledal, porovnal a syntetizoval, je stále více nahrazován novým paradigmatem. To je nahrazováno modelem „zeptej se a přijmi“ poháněným generativními systémy umělé inteligence. Tyto systémy provádějí syntézu za uživatele a poskytují přímou, kurátorovanou a přirozeně řečenou odpověď na položenou otázku.
Tato zásadní změna má dalekosáhlé důsledky pro definici digitální viditelnosti. Úspěch již neznamená pouze zobrazení na první stránce výsledků; je stále více definován jako nedílná součást odpovědi generované umělou inteligencí – ať už jako přímo citovaný zdroj, zmíněná značka nebo základ pro syntetizované informace. Tento vývoj urychluje stávající trend směrem k „vyhledávání s nulovým kliknutím“, kdy uživatelé uspokojují své informační potřeby přímo na stránce s výsledky vyhledávání, aniž by museli navštívit webové stránky. Je proto nezbytné, aby firmy a tvůrci obsahu pochopili nová pravidla hry a podle toho přizpůsobili své strategie.
Souvisí s tím:


Nová slovní zásoba optimalizace: Rozluštění SEO, LLMO, GEO, AIO a AEO
S příchodem těchto nových technologií se vyvinula složitá a často matoucí slovní zásoba. Jasná definice těchto pojmů je nezbytná pro cílenou strategii.
SEO (optimalizace pro vyhledávače): Toto je zavedená, základní disciplína optimalizace webového obsahu pro tradiční vyhledávače, jako jsou Google a Bing. Hlavním cílem je dosáhnout vysokého umístění v tradičních stránkách s výsledky vyhledávání založených na odkazech (SERP). SEO zůstává klíčové i ve věku umělé inteligence, protože tvoří základ pro veškerou další optimalizaci.
LLMO (Large Language Model Optimization): Tento přesný technický termín popisuje optimalizaci obsahu konkrétně tak, aby mohl být efektivně pochopen, zpracován a citován textovými modely velkých jazyků (LLM), jako je ChatGPT od OpenAI nebo Gemini od Googlu. Cílem již není umístění ve výsledcích vyhledávání, ale spíše zahrnutí jako důvěryhodného zdroje v odpovědích generovaných umělou inteligencí.
GEO (Generativní optimalizace pro enginy): Poněkud širší pojem, často používaný jako synonymum pro LLMO. GEO se zaměřuje na optimalizaci celého generativního systému nebo „enginu“ (např. Perplexity, Google AI Overviews), který generuje odpověď, spíše než pouze samotného jazykového modelu. Jde o zajištění toho, aby sdělení značky bylo přesně reprezentováno a šířeno napříč těmito novými kanály.
AIO (optimalizace pomocí AI): Toto je zastřešující termín s více významy, což může vést k nejasnostem. V kontextu optimalizace obsahu se AIO vztahuje k obecné strategii pro přizpůsobení obsahu pro jakýkoli typ systému AI. Termín se však může také vztahovat na technickou optimalizaci samotných modelů AI nebo na využití AI k automatizaci obchodních procesů. Tato nejednoznačnost jej činí méně přesným pro konkrétní obsahovou strategii.
AEO (Optimalizace pro vyhledávače odpovědí): Specializovaná podoblast GEO/LLMO, která se zaměřuje na optimalizaci funkcí pro přímé odpovědi ve vyhledávacích systémech, jako jsou ty, které se nacházejí v přehledech AI od Googlu.
Pro účely této zprávy se jako primární termíny pro nové strategie optimalizace obsahu používají termíny GEO a LLMO, protože nejpřesněji popisují daný jev a stále více se stávají průmyslovým standardem.
Proč je tradiční SEO základní, ale už nestačí
Častým omylem je, že nové optimalizační disciplíny nahradí SEO. Ve skutečnosti LLMO a GEO doplňují a rozšiřují tradiční optimalizaci pro vyhledávače. Tento vztah je symbiotický: bez solidního základu SEO je efektivní optimalizace pro generativní umělou inteligenci sotva možná.
SEO jako základ: Klíčové aspekty technického SEO – jako je rychlé načítání, čistá architektura webu a zajištění procházitelnosti – jsou naprosto nezbytné pro to, aby systémy umělé inteligence vůbec našly, přečetly a zpracovaly webovou stránku. Stejně tak zavedené signály kvality, jako je vysoce kvalitní obsah a tematicky relevantní zpětné odkazy, zůstávají klíčové pro to, aby byl web považován za důvěryhodný zdroj.
Spojení s RAG: Mnoho generativních vyhledávačů používá technologii zvanou Retrieval-Augmented Generation (RAG) k obohacení svých odpovědí o aktuální informace z webu. Často čerpají z nejlepších výsledků tradičních vyhledávačů. Vysoké umístění v tradičním vyhledávání tak přímo zvyšuje pravděpodobnost, že umělá inteligence použije daný zdroj pro vygenerovanou odpověď.
Mezera samotného SEO: Navzdory svému zásadnímu významu již samotné SEO nestačí. Nejvyšší umístění již není zárukou viditelnosti ani návštěvnosti, protože odpověď generovaná umělou inteligencí často zastiňuje tradiční výsledky a přímo odpovídá na dotaz uživatele. Novým cílem je řešit a syntetizovat relevantní informace v rámci této odpovědi generované umělou inteligencí. To vyžaduje další vrstvu optimalizace zaměřenou na strojovou čitelnost, kontextovou hloubku a prokazatelnou autoritu – aspekty, které jdou nad rámec tradiční optimalizace klíčových slov.
Fragmentace terminologie je více než jen sémantická debata; je to symptom paradigmatického posunu v jeho raných fázích. Různé zkratky odrážejí různé perspektivy, které se soupeří o definování nového oboru – od technického hlediska (AIO, LLMO) až po marketingově orientované (GEO, AEO). Tato nejednoznačnost a absence pevně zavedeného standardu vytvářejí strategické okno příležitostí. Zatímco větší a oddělenější organizace stále diskutují o terminologii a strategii, agilnější společnosti mohou přijmout základní principy strojově čitelného a autoritativního obsahu a zajistit si významnou výhodu prvního tahu. Současná nejistota není překážkou, ale příležitostí.
Srovnání optimalizačních disciplín
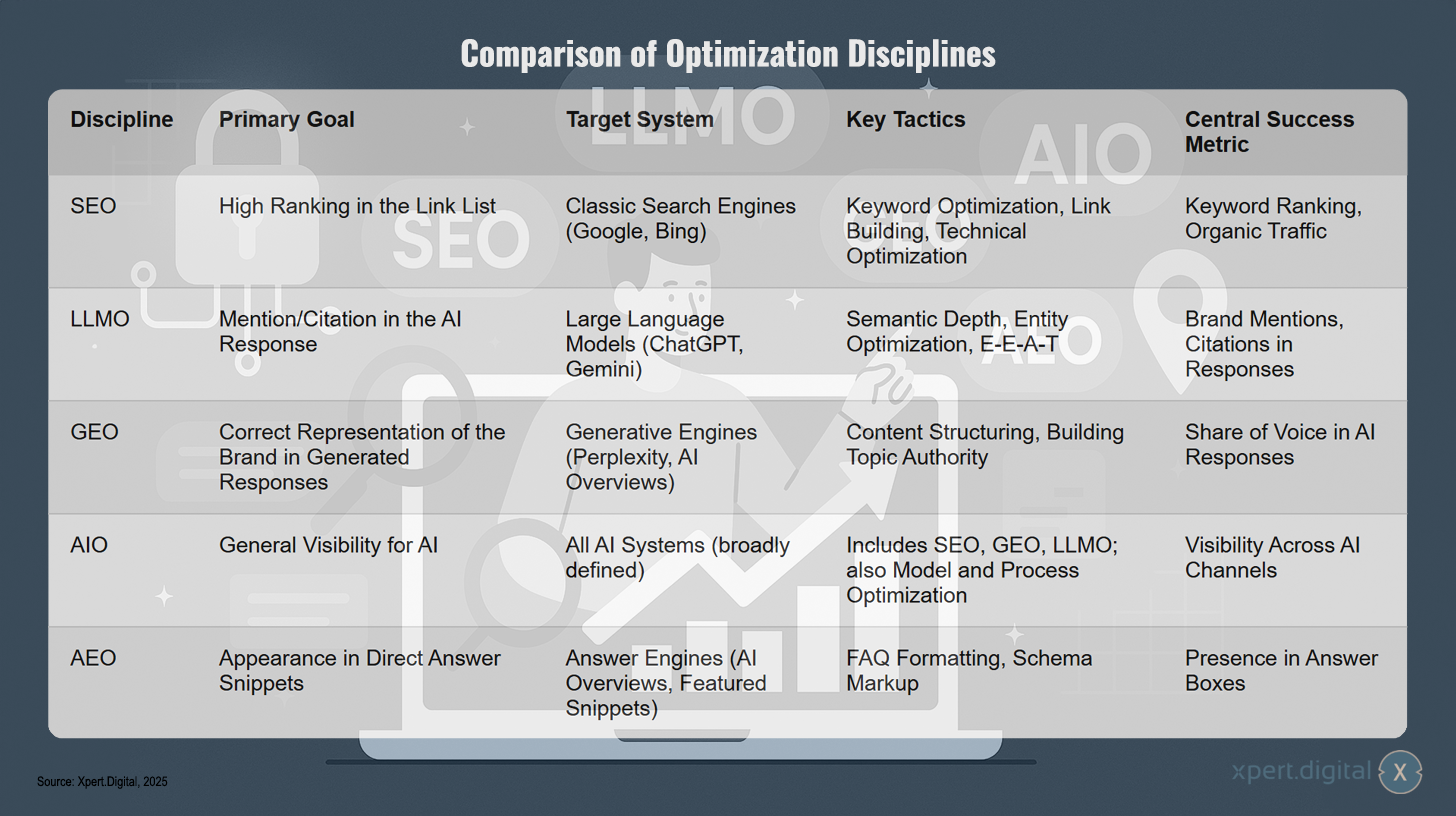
Porovnání optimalizačních oborů – Obrázek: Xpert.Digital
Různé optimalizační disciplíny sledují různé cíle a strategie. SEO se zaměřuje na dosažení vysokého umístění v tradičních vyhledávačích, jako jsou Google a Bing, prostřednictvím optimalizace klíčových slov, budování odkazů a technických vylepšení, přičemž úspěch se měří hodnocením klíčových slov a organickou návštěvností. LLMO se naopak snaží být zmíněno nebo citováno v odpovědích AI z hlavních jazykových modelů, jako je ChatGPT nebo Gemini, a to využitím sémantické hloubky, optimalizace entit a faktorů EEAT – úspěch se odráží ve zmínkách a citacích značky. GEO usiluje o správnou reprezentaci značky v odpovědích generovaných vyhledávači, jako jsou Perplexity nebo AI Overviews, přičemž upřednostňuje strukturování obsahu a budování autority tématu, přičemž podíl hlasu v odpovědích AI slouží jako měřítko úspěchu. AIO sleduje nejkomplexnější cíl: obecnou viditelnost napříč všemi systémy AI. Kombinuje SEO, GEO a LLMO s další optimalizací modelů a procesů, měřenou viditelností napříč různými kanály AI. AEO se v konečném důsledku zaměřuje na objevování se v úryvcích přímých odpovědí z vyhledávačů odpovědí prostřednictvím formátování FAQ a schématického značení, přičemž přítomnost v polích odpovědí definuje úspěch.
Strojovna: Pohled na technologii, která stojí za vyhledáváním pomocí umělé inteligence
Pro efektivní optimalizaci obsahu pro systémy umělé inteligence je nezbytné základní pochopení základních technologií. Tyto systémy nejsou magickými černými skříňkami, ale jsou založeny na specifických technických principech, které určují jejich funkčnost a v důsledku toho i požadavky na zpracovávaný obsah.
Velké jazykové modely (LLM): Základní mechanismy
Generativní umělá inteligence se zaměřuje na modely velkých jazyků (LLM).
- Předběžné trénování s masivními datovými sadami: Modely LLM jsou trénovány na obrovských textových sadách dat získaných ze zdrojů, jako je Wikipedie, celý veřejně dostupný internet (např. prostřednictvím datové sady Common Crawl) a digitální sbírky knih. Analýzou bilionů slov se tyto modely učí statistické vzorce, gramatické struktury, faktické znalosti a sémantické vztahy v lidském jazyce.
- Problém s omezením znalostí: Zásadním omezením LLM je, že jejich znalosti jsou zmrazeny na úrovni trénovacích dat. Mají takzvané „datum omezení znalostí“ a nemají přístup k informacím vytvořeným po tomto datu. LLM trénovaný do roku 2023 neví, co se stalo včera. Toto je základní problém, který je třeba u vyhledávacích aplikací vyřešit.
- Tokenizace a pravděpodobnostní generování: LLM nezpracovávají text slovo po slově, ale rozdělují ho na menší jednotky zvané „tokeny“. Jejich hlavní funkcí je předpovědět nejpravděpodobnější další token na základě existujícího kontextu, a tak sekvenčně generovat souvislý text. Jsou to vysoce sofistikované statistické rozpoznávače vzorů a nemají lidské vědomí ani chápání.
Generování rozšířeného vyhledávání (RAG): Most k živému webu
Generování rozšířeného vyhledávání (RAG) je klíčová technologie, která umožňuje LLM fungovat jako moderní vyhledávače. Překlenuje propast mezi statickými, předtrénovanými znalostmi modelu a dynamickými informacemi internetu.
Proces RAG lze rozdělit do čtyř kroků:
- Dotaz: Uživatel položí systému otázku.
- Vyhledávání: Místo okamžité reakce systém aktivuje komponentu „vyhledávač“. Tato komponenta, často sémantický vyhledávač, prohledává externí znalostní bázi – obvykle index významného vyhledávače, jako je Google nebo Bing – a hledá dokumenty relevantní pro daný dotaz. Zde se projevuje důležitost vysokého tradičního SEO hodnocení: Obsah, který se dobře umisťuje ve výsledcích klasického vyhledávání, je s větší pravděpodobností nalezen systémem RAG a vybrán jako potenciální zdroj.
- Augmentace: Nejrelevantnější informace z načtených dokumentů jsou extrahovány a přidány k původnímu uživatelskému požadavku jako další kontext. Tím se vytvoří „obohacená výzva“.
- Generování: Tato obohacená výzva je přeposlána do LLM. Model nyní generuje svou odpověď, která již není založena pouze na zastaralých trénovacích znalostech, ale na aktuálních, načtených faktech.
Tento proces snižuje riziko „halucinací“ (vymýšlení si faktů), umožňuje citování zdrojů a zajišťuje, že odpovědi jsou aktuálnější a věcně přesnější.
Sémantické vyhledávání a vkládání vektorů: Jazyk umělé inteligence
Abychom pochopili, jak krok „Vyhledávání“ funguje v RAG, musíme pochopit koncept sémantického vyhledávání.
- Od klíčových slov k významu: Tradiční vyhledávání je založeno na porovnávání klíčových slov. Sémantické vyhledávání se naopak snaží pochopit záměr a kontext dotazu. Například vyhledávání výrazu „teplé zimní rukavice“ může také vrátit výsledky pro výraz „vlněné palčáky“, protože systém rozpoznává sémantický vztah mezi těmito pojmy.
- Vektorové vkládání jako základní mechanismus: Technickým základem je vektorové vkládání. Speciální „model vkládání“ převádí textové jednotky (slova, věty, celé dokumenty) do numerické reprezentace – vektoru ve vícerozměrném prostoru.
- Prostorová blízkost jako sémantická podobnost: V tomto vektorovém prostoru jsou sémanticky podobné koncepty reprezentovány jako body umístěné blízko sebe. Vektor představující „krále“ má podobný vztah k vektoru pro „královnu“, jako má vektor pro „muže“ k vektoru pro „ženu“.
- Aplikace v procesu RAG: Uživatelský požadavek je také převeden do vektoru. Systém RAG poté prohledává svou vektorovou databázi a hledá vektory dokumentů, které jsou nejblíže vektoru požadavku. Tímto způsobem jsou získány sémanticky nejrelevantnější informace pro obohacení výzvy.
Myšlenkové modely a myšlenkové procesy: Další fáze evoluce
V popředí vývoje LLM jsou tzv. kognitivní modely, které slibují ještě pokročilejší formu zpracování informací.
- Více než jen jednoduché odpovědi: Zatímco standardní LLM generují odpověď v jednom kroku, myšlenkové modely rozkládají složité problémy do série logických mezikroků, tzv. „řetězce myšlenek“.
- Jak to funguje: Tyto modely jsou trénovány pomocí posilovacího učení, kde jsou úspěšné vícestupňové cesty řešení odměňovány. V podstatě „myslí nahlas“ interně, formulují a zahazují různé přístupy, než dospějí ke konečné, často robustnější a přesnější odpovědi.
- Důsledky pro optimalizaci: Ačkoli je tato technologie stále v plenkách, naznačuje, že budoucí vyhledávače budou schopny zpracovávat mnohem složitější a mnohostrannější dotazy. Obsah, který nabízí jasné a logické pokyny krok za krokem, podrobné popisy procesů nebo dobře strukturované argumentační linie, je ideálně umístěn pro použití těmito pokročilými modely jako vysoce kvalitní zdroj informací.
Technologická architektura moderního vyhledávání s využitím umělé inteligence – kombinace LLM, RAG a sémantického vyhledávání – vytváří silnou, sebeposilující zpětnovazební smyčku mezi „starou sítí“ hodnocených stránek a „novou sítí“ odpovědí generovaných umělou inteligencí. Vysoce kvalitní a autoritativní obsah, který si v tradičním SEO vede dobře, je prominentně indexován a hodnocen. Toto vysoké umístění z něj činí hlavního kandidáta pro vyhledávání systémy RAG. Když umělá inteligence tento obsah cituje, dále posiluje svou autoritu, což může vést ke zvýšenému zapojení uživatelů, většímu počtu zpětných odkazů a v konečném důsledku k ještě silnějším signálům tradičního SEO. Vytváří se tak „ctnostný kruh autority“. Naopak, nekvalitní obsah je tradičními vyhledávacími i RAG systémy ignorován a stává se stále více neviditelným. Propast mezi digitálními „majetnými“ a „nemajícími“ se tak exponenciálně zvětší. Strategickým důsledkem je, že investice do základního SEO a budování autority obsahu se již nezaměřují pouze na umístění v žebříčku; zajišťují trvalé místo u jednacího stolu pro budoucnost informační syntézy řízenou umělou inteligencí.
🎯🎯🎯 Využijte rozsáhlé pětinásobné odborné znalosti společnosti Xpert.Digital v jednom komplexním balíčku služeb | BD, výzkum a vývoj, XR, PR a optimalizace digitální viditelnosti

Využijte rozsáhlé, pětinásobné odborné znalosti společnosti Xpert.Digital v komplexním balíčku služeb | Výzkum a vývoj, XR, PR a optimalizace digitální viditelnosti - Obrázek: Xpert.Digital
Společnost Xpert.Digital disponuje hlubokými znalostmi napříč různými odvětvími. To nám umožňuje vyvíjet strategie na míru, které přesně odpovídají požadavkům a výzvám vašeho specifického segmentu trhu. Díky neustálé analýze tržních trendů a sledování vývoje v odvětví můžeme jednat proaktivně a nabízet inovativní řešení. Kombinace zkušeností a odborných znalostí vytváří přidanou hodnotu a poskytuje našim klientům rozhodující konkurenční výhodu.
Více informací zde:
Budování digitální autority: Proč tradiční SEO již nestačí pro vyhledávače řízené umělou inteligencí
Tři pilíře generativní optimalizace motorů
Technické znalosti z první části tvoří základ pro konkrétní a proveditelný strategický rámec. Aby bylo možné v nové éře vyhledávání s využitím umělé inteligence uspělo, musí se optimalizační úsilí opírat o tři ústřední pilíře: strategický obsah pro porozumění strojům, pokročilá technická optimalizace pro roboty s využitím umělé inteligence a proaktivní správa digitální autority.
Souvisí s tím:


Pilíř 1: Strategický obsah pro porozumění strojům
Způsob, jakým je obsah vytvářen a strukturován, se musí zásadně změnit. Cílem již není jen přesvědčit lidského čtenáře, ale také poskytnout stroji co nejlepší základ pro extrakci a syntézu informací.
Autorita tématu jako nová hranice
Zaměření obsahové strategie se přesouvá od optimalizace jednotlivých klíčových slov k budování komplexní tematické autority.
- Budování center znalostí: Místo vytváření izolovaných článků pro jednotlivá klíčová slova je cílem vytvořit holistické „tematické shluky“. Ty se skládají z centrálního, komplexního článku s „pilířovým obsahem“ pokrývajícího široké téma a četných propojených podčlánků, které se zabývají specifickými aspekty a podrobnými otázkami. Taková struktura signalizuje systémům umělé inteligence, že webová stránka je autoritativním a vyčerpávajícím zdrojem pro danou oblast.
- Komplexní pokrytí: LLM zpracovávají informace v sémantických kontextech. Webové stránky, které komplexně pokrývá dané téma – včetně všech relevantních aspektů, uživatelských otázek a souvisejících konceptů – zvyšují pravděpodobnost, že je umělá inteligence použije jako primární zdroj. Systém najde všechny potřebné informace na jednom místě a nemusí je skládat dohromady z více méně komplexních zdrojů.
- Praktické využití: Výzkum klíčových slov se již nepoužívá k nalezení jednotlivých vyhledávacích výrazů, ale k zmapování celého spektra otázek, dílčích aspektů a souvisejících témat, která patří do klíčové oblasti kompetence.
EEAT jako algoritmický signál
Koncept EEAT (zkušenost, odbornost, autoritativita, důvěryhodnost) od Googlu se vyvíjí z pouhého vodítka pro lidské posuzovatele kvality na soubor strojově čitelných signálů používaných k hodnocení zdrojů obsahu.
Strategické budování důvěry: Společnosti musí aktivně implementovat a zviditelnit tyto signály na svých webových stránkách:
- Zkušenosti a odbornost: Autoři musí být jasně identifikováni, ideálně s podrobnými biografiemi, které prokazují jejich kvalifikaci a praktické zkušenosti. Obsah by měl nabízet jedinečné poznatky z reálné praxe, které jdou nad rámec pouhých faktických znalostí.
- Autorita (autoritativita): Budování kontextově relevantních zpětných odkazů z jiných renomovaných webových stránek je i nadále důležité. Na důležitosti však nabývají i nepropojené zmínky o značkách v autoritativních zdrojích.
- Důvěryhodnost: Jasné a snadno dostupné kontaktní informace, citování důvěryhodných zdrojů, publikování původních dat nebo studií a pravidelná aktualizace a oprava obsahu jsou klíčovými signály důvěry.
Strategie obsahu založená na entitech: Optimalizace pro věci, ne pro řetězce
Moderní vyhledávače zakládají své chápání světa na „grafu znalostí“. Tento graf se neskládá ze slov, ale ze skutečných entit (lidí, míst, značek, konceptů) a vztahů mezi nimi.
- Povýšení vaší značky na entitu: Strategickým cílem je etablovat vaši značku jako jasně definovanou a rozpoznatelnou entitu v rámci tohoto grafu, která je jednoznačně spojena s konkrétní oblastí. Toho je dosaženo konzistentním pojmenováváním, používáním strukturovaných dat (viz část 4) a častým společným výskytem s dalšími relevantními entitami.
- Praktické využití: Obsah by měl být strukturován kolem jasně definovaných entit. Důležité technické pojmy lze vysvětlit v glosářích nebo definičních rámečcích. Odkazy na uznávané zdroje entit, jako je Wikipedie nebo Wikidata, mohou Googlu pomoci navázat správná propojení a upevnit tematickou klasifikaci.
Umění úryvku: strukturování obsahu pro přímou extrakci
Obsah musí být formátován tak, aby jej stroje mohly snadno rozebrat a znovu použít.
- Optimalizace na úrovni pasáží: Systémy umělé inteligence často neextrahují celé články, ale spíše jednotlivé, dokonale formulované „kusy“ nebo sekce – odstavec, položku seznamu, řádek tabulky – aby odpověděly na konkrétní část dotazu. Webové stránky by proto měly být navrženy jako soubor takových snadno extrahovatelných informačních úryvků.
- Osvědčené postupy pro strukturální řešení:
- Psaní s odpovědí na první otázku: Odstavce by měly začínat stručnou a přímou odpovědí na implicitní otázku, po níž by následovaly vysvětlující podrobnosti.
- Použití seznamů a tabulek: Složité informace by měly být prezentovány ve výčtech, číslovaných seznamech a tabulkách, protože tyto formáty jsou pro systémy umělé inteligence obzvláště snadno analyzovatelné.
- Strategické využití nadpisů: Jasné a popisné nadpisy H2 a H3, často formulované jako otázky, by měly logicky strukturovat obsah. Každá sekce by se měla zaměřit na jednu, cílenou myšlenku.
- Sekce s často kladenými otázkami: Sekce s často kladenými otázkami (FAQ) jsou ideální, protože přímo odrážejí konverzační formát otázek a odpovědí v chatech s umělou inteligencí.
Multimodalita a přirozený jazyk
- Konverzační tón: Obsah by měl být psán přirozeným, lidským stylem. Modely umělé inteligence jsou trénovány s využitím autentického, lidského jazyka a preferují texty, které se čtou jako skutečná konverzace.
- Optimalizace vizuálního obsahu: Moderní umělá inteligence dokáže zpracovávat i vizuální informace. Obrázky proto potřebují smysluplný alternativní text a popisky. Videa by měla být doprovázena přepisy. Díky tomu je multimediální obsah pro umělou inteligenci indexovatelný a citovatelný.
Konvergence těchto obsahových strategií – autority tématu, EEAT, optimalizace entit a strukturování úryvků – vede k hlubokému poznatku: nejefektivnější obsah pro umělou inteligenci je zároveň nejužitečnějším, nejjasnějším a nejdůvěryhodnějším obsahem pro lidi. Éra „psaní pro algoritmus“, která často vedla k nepřirozeně znějícím textům, se chýlí ke konci. Nový algoritmus vyžaduje osvědčené postupy zaměřené na člověka. Strategickým důsledkem je, že investice do skutečných odborných znalostí, vysoce kvalitního psaní, jasného informačního designu a transparentních citací zdrojů již není jen „osvědčeným postupem“ – je to nejpřímější a nejudržitelnější forma technické optimalizace pro generativní věk.
Pilíř 2: Pokročilá technická optimalizace pro roboty s umělou inteligencí
Zatímco strategický obsah definuje „co“ optimalizace, technická optimalizace zajišťuje „jak“ – zaručuje, že systémy umělé inteligence mohou k tomuto obsahu přistupovat, interpretovat a správně zpracovávat. Bez solidního technického základu zůstává i ten nejlepší obsah neviditelný.
Znovu prozkoumání technického SEO: Trvalý význam klíčových ukazatelů (Cree Vitals)
Základy technické optimalizace pro vyhledávače nejsou relevantní pouze pro GEO, ale stávají se ještě důležitějšími.
- Prohledávatelnost a indexovatelnost: Toto je naprosto zásadní. Pokud robot s umělou inteligencí – ať už je to známý Googlebot nebo specializovaní boti jako ClaudeBot a GPTBot – nemůže přistupovat ke stránce nebo ji vykreslit, pro systém umělé inteligence tato stránka neexistuje. Musí být zajištěno, aby relevantní stránky vracely stavový kód HTTP 200 a nebyly (neúmyslně) blokovány souborem robots.txt.
- Rychlost načítání stránky a časové limity vykreslování: Prohledávače s umělou inteligencí často pracují s velmi krátkými časy vykreslování stránky, někdy pouze 1–5 sekund. Pomalu načítající stránky, zejména ty s vysokým obsahem JavaScriptu, riskují, že budou přeskočeny nebo zpracovány pouze částečně. Optimalizace klíčových webových ukazatelů a celkové rychlosti načítání stránky je proto zásadní.
- Vykreslování JavaScriptu: Zatímco prohledávač Google je nyní velmi dobrý ve vykreslování stránek náročných na JavaScript, u mnoha jiných prohledávačů s umělou inteligencí to neplatí. Aby byla zajištěna univerzální přístupnost, měl by být kritický obsah již zahrnut v původním HTML kódu stránky a neměl by být načítán na straně klienta.
Strategický imperativ Schema.org: Vytvořit síťový znalostní diagram
Schema.org je standardizovaný slovník pro strukturovaná data. Umožňuje provozovatelům webových stránek explicitně sdělit vyhledávačům, o čem je jejich obsah a jak spolu různé informace souvisejí. Webová stránka označená pomocí Schema se v podstatě stává strojově čitelnou databází.
- Proč je schéma pro umělou inteligenci klíčové: Strukturovaná data eliminují nejednoznačnost. Umožňují systémům umělé inteligence extrahovat fakta, jako jsou ceny, data, lokality, hodnocení nebo kroky v průvodci, s vysokou mírou jistoty. Díky tomu je obsah mnohem spolehlivějším zdrojem pro generování odpovědí než nestrukturovaný text.
- Klíčové typy schémat pro GEO:
- Organizace a osoba: Jasně definovat vlastní značku a autory jako entity.
- Stránka s nejčastějšími dotazy a návody: Pro strukturování obsahu pro přímé odpovědi a podrobné pokyny, které systémy umělé inteligence preferují.
- Článek: Přenášet důležitá metadata, jako je autor a datum publikace, a tím posílit signály EEAT.
- Produkt: Nezbytný pro elektronické obchodování, aby byly údaje o ceně, dostupnosti a hodnocení strojově čitelné.
- Nejlepší postup – Propojené entity: Optimalizace by měla jít nad rámec pouhého přidávání izolovaných bloků schématu. Pomocí atributu @id lze propojit různé entity na stránce a napříč celým webem (např. propojením článku s jeho autorem a vydavatelem). Tím se vytvoří ucelený interní graf znalostí, který explicitně zobrazuje sémantické vztahy pro stroje.
Vznikající standard llms.txt: Přímá komunikační linka k modelům umělé inteligence
llms.txt je navrhovaný nový standard, jehož cílem je umožnit přímou a efektivní komunikaci s modely umělé inteligence.
- Účel a funkce: Jedná se o jednoduchý textový soubor napsaný ve formátu Markdown, umístěný v kořenovém adresáři webových stránek. Poskytuje upravenou „mapu“ nejdůležitějšího obsahu webových stránek, očištěnou od rušivého HTML, JavaScriptu a reklamních bannerů. Díky tomu je pro modely umělé inteligence extrémně efektivní najít a zpracovat nejrelevantnější informace.
- Rozdíl oproti souborům robots.txt a sitemap.xml: Zatímco soubor robots.txt říká robotům, které oblasti by neměli navštívit, a sitemap.xml poskytuje neanotovaný seznam všech URL adres, soubor llms.txt nabízí strukturovaného a kontextového průvodce nejcennějšími obsahovými zdroji webu.
- Specifikace a formát: Soubor používá jednoduchou syntaxi Markdownu. Obvykle začíná nadpisem H1 (název stránky), po kterém následuje krátké shrnutí v bloku citací. Nadpisy H2 pak seskupují seznamy odkazů na důležité zdroje, jako je dokumentace nebo pokyny. Existují také varianty, jako je llms-full.txt, které kombinují veškerý textový obsah webových stránek do jednoho souboru.
- Implementace a nástroje: Tvorbu lze provádět ručně nebo s podporou rostoucího počtu generátorových nástrojů, jako jsou FireCrawl, Markdowner nebo specializované pluginy pro systémy správy obsahu, jako jsou WordPress a Shopify.
- Debata o jeho přijetí: Pochopení současné kontroverze kolem tohoto standardu je klíčové. Oficiální dokumentace společnosti Google uvádí, že takové soubory nejsou nezbytné pro viditelnost v přehledech AI. Přední odborníci společnosti Google, jako je John Mueller, vyjádřili skepsi a přirovnali jeho užitečnost k zastaralému meta tagu keyword. Další velké společnosti zabývající se AI, jako je Anthropic, však tento standard již aktivně používají na svých webových stránkách a jeho přijetí v komunitě vývojářů roste.
Debata o souboru llms.txt a pokročilých schématech odhaluje kritické strategické napětí: napětí mezi optimalizací pro jednu dominantní platformu (Google) a optimalizací pro širší, heterogenní ekosystém umělé inteligence. Spoléhání se výhradně na pokyny Googlu („Nepotřebujete to“) je riskantní strategie, která ztrácí kontrolu a potenciální viditelnost na jiných rychle rostoucích platformách, jako jsou ChatGPT, Perplexity a Claude. Nejodolnějším přístupem je progresivní „polygamní“ optimalizační strategie, která dodržuje základní principy Googlu a zároveň implementuje standardy pro celý ekosystém, jako je llms.txt a komplexní schéma. Zachází s Googlem jako s primárním, ale nikoli jediným strojovým spotřebitelem obsahu společnosti. Jedná se o formu strategické diverzifikace a zmírňování rizik pro digitální aktiva společnosti.
Pilíř 3: Řízení digitálních úřadů
Vznik nové disciplíny
Třetí a možná nejstrategičtější pilíř generativní optimalizace pro vyhledávače jde nad rámec pouhé optimalizace obsahu a technické optimalizace. Zaměřuje se na budování a správu celkové digitální autority značky. Ve světě, kde se systémy umělé inteligence snaží posoudit důvěryhodnost zdrojů, se algoritmicky měřitelná autorita stává klíčovým faktorem hodnocení.
Koncept „řízení digitální autority“ významně formoval odborník z oboru Olaf Kopp a popisuje novou, nezbytnou disciplínu v digitálním marketingu.
Most mezi sily
V době EEAT a umělé inteligence jsou signály, které budují algoritmickou důvěru – jako je reputace značky, zmínky v médiích a důvěryhodnost autora – generovány činnostmi tradičně spadajícími do samostatných oddělení, jako jsou PR, marketing značky a sociální média. SEO samo o sobě má často omezený dopad na tyto oblasti. Správa digitálních autorit tuto propast překlenuje spojením těchto snah se SEO pod jeden strategický deštník.
Hlavním cílem je vědomý a proaktivní rozvoj digitálně rozpoznatelné a autoritativní značky, kterou lze snadno identifikovat algoritmy a klasifikovat jako důvěryhodnou.
Více než jen zpětné odkazy: Měna zmínek a jejich společný výskyt
- Zmínky jako signál: Nepropojené zmínky o značkách v autoritativních kontextech nabývají na obrovském významu. Systémy umělé inteligence tyto zmínky shromažďují z celého webu, aby posoudily povědomí o značce a její reputaci.
- Společný výskyt a kontext: Systémy umělé inteligence analyzují, které entity (značky, lidé, témata) jsou často zmiňovány společně. Strategickým cílem musí být vytvoření silného a konzistentního spojení mezi značkou a jejími klíčovými kompetenčními tématy v celém digitálním prostoru.
Budování digitálně rozpoznatelné značky
- Konzistence je klíčová: Naprostá konzistence v pravopisu názvu značky, jmen autorů a popisů společností napříč všemi digitálními kontaktními body je nezbytná – od vašich vlastních webových stránek a profilů na sociálních sítích až po oborové adresáře. Nekonzistence vytvářejí pro algoritmy nejednoznačnost a oslabují entitu.
- Autorita napříč platformami: Generativní vyhledávače holisticky hodnotí přítomnost značky. Jednotný hlas a konzistentní sdělení napříč všemi kanály (web, LinkedIn, příspěvky hostů, fóra) posilují vnímanou autoritu. Klíčovou taktikou je zde opětovné použití a přizpůsobení úspěšného obsahu pro různé formáty a platformy.
Role digitálního PR a managementu reputace
- Strategické vztahy s veřejností: Úsilí v oblasti digitálního PR se musí zaměřit na dosažení zmínek v publikacích, které jsou nejen relevantní pro cílové publikum, ale jsou také klasifikovány jako autoritativní zdroje modely umělé inteligence.
- Správa reputace: Je zásadní aktivně propagovat a sledovat pozitivní recenze na renomovaných platformách. Stejně důležitá je aktivní účast v relevantních diskusích na komunitních platformách, jako jsou Reddit a Quora, protože ty systémy umělé inteligence často využívají jako zdroje autentických názorů a zkušeností.
Nová role SEO
- Správa digitálních autorit zásadně mění roli SEO v organizaci. Povyšuje SEO z taktické funkce zaměřené na optimalizaci jednoho kanálu (webových stránek) na strategickou funkci zodpovědnou za orchestrování celé digitální stopy společnosti pro algoritmickou interpretaci.
- To znamená významný posun v organizační struktuře a požadovaných dovednostech. „Manažer digitální autority“ je nová hybridní role, která kombinuje analytickou důslednost SEO s narativními a vztahovými dovednostmi stratéga značky a PR profesionála. Společnosti, které nedokážou vytvořit tuto integrovanou funkci, zjistí, že jejich fragmentované digitální signály nemohou konkurovat rivalům, kteří systémům umělé inteligence prezentují jednotnou a autoritativní identitu.
Zadávání veřejných zakázek B2B: Dodavatelské řetězce, obchod, tržiště a sourcing s využitím umělé inteligence

B2B zadávání veřejných zakázek: Dodavatelské řetězce, obchod, tržiště a sourcing s využitím umělé inteligence s ACCIO.com - Obrázek: Xpert.Digital
Více informací zde:
Od SEO k GEO: Nové metriky pro měření úspěchu v éře umělé inteligence
Konkurenční prostředí a měření výkonnosti
Jakmile jsou definovány strategické pilíře optimalizace, pozornost se přesouvá k praktické aplikaci v současném konkurenčním prostředí. To vyžaduje analýzu nejdůležitějších vyhledávacích platforem s využitím umělé inteligence založenou na datech a také zavedení nových metod a nástrojů pro měření výkonnosti.
Souvisí s tím:

Dekonstrukce výběru zdrojů: Srovnávací analýza
Různé vyhledávací platformy s umělou inteligencí nefungují stejně. Pro generování výsledků používají různé zdroje dat a algoritmy. Pochopení těchto rozdílů je klíčové pro stanovení priorit optimalizačních opatření. Následující analýza je založena na syntéze předních oborových studií, zejména komplexní studie SE Ranking, doplněné o kvalitativní analýzy a dokumentaci specifickou pro danou platformu.
Přehledy umělé inteligence Google: Výhoda zavedeného systému
- Profil zdroje: Google zaujímá poměrně konzervativní přístup. Přehledy AI se silně spoléhají na stávající Knowledge Graph, zavedené signály EEAT a nejlepší výsledky organického vyhledávání. Studie ukazují významnou, i když ne úplnou, korelaci s prvními 10 pozicemi tradičního vyhledávání.
- Datové body: Google uvádí průměrně 9,26 odkazů na odpověď a vykazuje vysokou diverzitu s 2 909 unikátními doménami v analyzované studii. Existuje jasná preference starších, zavedených domén (49 % citovaných domén je starších 15 let), zatímco velmi mladé domény jsou zvažovány méně často.
- Strategické důsledky: Úspěch v přehledech umělé inteligence Google je neoddělitelně spjat se silnou, tradiční autoritou v oblasti SEO. Je to ekosystém, kde úspěch plodí další úspěch.
Vyhledávání ChatGPT: Vyzyvatel se zaměřením na uživatelsky generovaný obsah a Bing
- Profil zdroje: ChatGPT používá pro webové vyhledávání index Microsoft Bing, ale pro filtrování a řazení výsledků používá vlastní logiku. Platforma vykazuje jasnou preferenci pro obsah generovaný uživateli (UGC), zejména z YouTube, který je jedním z nejčastěji citovaných zdrojů, a také pro komunitní platformy, jako je Reddit.
- Datové body: ChatGPT cituje nejvíce odkazů (průměrně 10,42) a odkazuje na největší počet unikátních domén (4 034). Zároveň platforma vykazuje nejvyšší míru vícenásobných zmínek stejné domény v rámci jedné odpovědi (71 %), což naznačuje strategii hloubkové analýzy s využitím jediného důvěryhodného zdroje.
- Strategické důsledky: Viditelnost v ChatGPT vyžaduje multiplatformní strategii, která zahrnuje nejen optimalizaci pro index Bing, ale také aktivní budování přítomnosti na důležitých platformách pro obsah generovaný uživateli.
Perplexity.ai: Transparentní výzkumník v reálném čase
- Profil zdroje: Perplexity je navržena tak, aby pro každý dotaz prováděla vyhledávání na webu v reálném čase a zajistila tak aktuálnost informací. Platforma je vysoce transparentní a v odpovědích poskytuje jasné citace. Unikátní funkcí je funkce „Focus“, která uživatelům umožňuje omezit vyhledávání na předem definovaný výběr zdrojů (např. pouze akademické práce, Reddit nebo konkrétní webové stránky).
- Datové body: Výběr zdrojů je velmi konzistentní; téměř všechny odpovědi obsahují přesně 5 odkazů. Odpovědi Perplexity vykazují nejvyšší sémantickou podobnost s odpověďmi ChatGPT (0,82), což naznačuje podobné preference výběru obsahu.
- Strategický důsledek: Klíčem k úspěchu na Perplexity je stát se „cílovým zdrojem“ – webovou stránkou natolik autoritativní, že ji uživatelé vědomě zahrnují do svých cílených vyhledávání. Platforma se také zaměřuje na aktuálnost obsahu v reálném čase, který je obzvláště aktuální a fakticky přesný.
Různé strategie získávání zdrojů hlavních platforem umělé inteligence vytvářejí novou formu „algoritmické arbitráže“. Značka, která se snaží prosadit ve vysoce konkurenčním ekosystému Google AI Overview, zaměřeném na autority, by mohla najít snazší cestu k viditelnosti prostřednictvím ChatGPT zaměřením se na Bing SEO a silnou přítomností na YouTube a Redditu. Podobně může expert na danou oblast obejít mainstreamovou konkurenci tím, že se stane nezbytným zdrojem pro cílené vyhledávání na Perplexity. Strategickým ponaučením není bojovat v každé bitvě na všech frontách, ale spíše analyzovat různé „bariéry vstupu“ každé platformy umělé inteligence a sladit tvorbu obsahu a budování autority s platformou, která nejlépe odpovídá silným stránkám značky.
Srovnávací analýza vyhledávacích platforem s umělou inteligencí

Srovnávací analýza vyhledávacích platforem s umělou inteligencí – Obrázek: Xpert.Digital
Srovnávací analýza vyhledávacích platforem s využitím umělé inteligence odhaluje významné rozdíly mezi Google AI Overviews, ChatGPT Search a Perplexity.ai. Google AI Overviews používá jako primární zdroj dat Google Index a Knowledge Graph, poskytuje průměrně 9,26 citací a vykazuje nízké překrývání zdrojů s Bingem a střední překrývání s ChatGPT. Platforma vykazuje mírnou preferenci pro obsah generovaný uživateli, jako je Reddit a Quora, ale upřednostňuje zavedené, starší domény. Její jedinečnou prodejní výhodou je integrace s dominantním vyhledávačem a silný důraz na hodnocení EEAT (Ever After Appearance) se strategickým zaměřením na budování EEAT a silné tradiční SEO autority.
Vyhledávání ChatGPT využívá jako primární zdroj dat index Bing a generuje nejvíce citací, v průměru 10,42. Platforma vykazuje vysoký stupeň překrývání s Perplexity a mírný překrývání s Googlem. Obzvláště pozoruhodná je její silná preference obsahu generovaného uživateli, zejména z YouTube a Redditu. Hodnocení věku domény ukazuje smíšené výsledky s jasnou preferencí mladších domén. Její jedinečnou prodejní výhodou je vysoký počet citací a silná integrace UGC, zatímco její strategické zaměření je na Bing SEO a přítomnost na platformách UGC.
Perplexity.ai se odlišuje tím, že jako primární zdroj dat používá vyhledávání na webu v reálném čase a poskytuje nejméně citací, v průměru 5,01. Překrytí zdrojů je vysoké u ChatGPT, ale nízké u Google a Bingu. Platforma vykazuje mírnou preferenci obsahu generovaného uživateli, přičemž v režimu Focus upřednostňuje Reddit a YouTube. Stáří domény hraje menší roli kvůli zaměření na relevanci v reálném čase. Mezi jedinečné prodejní argumenty Perplexity.ai patří transparentnost prostřednictvím vložených citací a přizpůsobitelný výběr zdrojů pomocí funkce Focus. Její strategické zaměření je na budování specializované autority a zajištění aktuálnosti obsahu.
Nová analytika: Měření a monitorování viditelnosti LLM
Paradigmatický posun od vyhledávání k odezvě vyžaduje zásadní úpravu způsobu měření úspěchu. Tradiční SEO metriky ztrácejí svůj význam, když kliknutí na webové stránky již nejsou primárním cílem. Pro kvantifikaci vlivu a přítomnosti značky v generativním prostředí umělé inteligence jsou zapotřebí nové metriky a nástroje.
Změna paradigmatu v měření: Od kliknutí k vlivu
- Staré metriky: Úspěch tradičního SEO se primárně hodnotí pomocí přímo měřitelných metrik, jako je umístění klíčových slov ve vyhledávání, organická návštěvnost a míra prokliku (CTR).
- Nové metriky: Úspěch GEO/LLMO bude měřen metrikami vlivu a přítomnosti, které jsou často nepřímé povahy:
- Viditelnost LLM / Zmínky o značce: Měří, jak často je značka zmiňována v relevantních odpovědích umělé inteligence. Toto je nejzákladnější nová metrika.
- Podíl hlasu / Podíl modelu: Kvantifikuje procento zmínek o vlastní značce v porovnání s konkurencí pro definovanou skupinu vyhledávacích dotazů (výzev).
- Citace: Sleduje, jak často je váš web odkazován jako zdroj.
- Sentiment a kvalita zmínek: Analyzuje tón (pozitivní, neutrální, negativní) a faktickou přesnost zmínek.
Vznikající sada nástrojů: Platformy pro sledování zmínek o umělé inteligenci
- Jak to funguje: Tyto nástroje automaticky a ve velkém měřítku dotazují různé modely umělé inteligence pomocí předdefinovaných výzev. Zaznamenávají, které značky a zdroje se v odpovědích objevují, analyzují sentiment a sledují vývoj v čase.
- Přední nástroje: Trh je mladý a fragmentovaný, ale několik specializovaných platforem se již etablovalo. Patří mezi ně nástroje jako Profound, Peec.ai, RankScale a Otterly.ai, které se liší rozsahem funkcí a cílovou skupinou (od malých a středních podniků až po velké podniky).
- Adaptace tradičních nástrojů: Zavedení poskytovatelé softwaru pro monitorování značek (např. Sprout Social, Mention) a komplexních SEO balíčků (např. Semrush, Ahrefs) také začínají integrovat funkce analýzy viditelnosti s využitím umělé inteligence do svých produktů.
Odstranění mezery v atribuci: Integrace analytiky LLM do reportingu
Jednou z největších výzev je přiřazení obchodních výsledků zmínce v odpovědi umělé inteligence, protože to často nevede k přímému kliknutí. Je vyžadována vícestupňová metoda analýzy:
- Sledování návštěvnosti z odkazů: Prvním a nejjednodušším krokem je analýza přímé návštěvnosti z platforem umělé inteligence pomocí nástrojů pro webovou analýzu, jako je Google Analytics 4. Vytvořením vlastních skupin kanálů na základě zdrojů odkazů (např. perplexity.ai, bing.com pro vyhledávání ChatGPT) lze tuto návštěvnost izolovat a vyhodnotit.
- Monitorování nepřímých signálů: Pokročilejší přístup zahrnuje korelační analýzu. Analytici musí sledovat trendy v nepřímých ukazatelích, jako je nárůst přímé návštěvnosti webových stránek a nárůst vyhledávacích dotazů týkajících se značek v Google Search Console. Tyto trendy pak musí být korelovány s vývojem viditelnosti LLM, měřenou novými monitorovacími nástroji.
- Analýza protokolů botů: Pro technicky zdatné týmy nabízí analýza souborů protokolů serveru cenné poznatky. Identifikací a monitorováním aktivit robotů s umělou inteligencí (např. GPTBot, ClaudeBot) je možné určit, které stránky systémy umělé inteligence používají ke shromažďování informací.
Vývoj klíčových ukazatelů výkonnosti

Vývoj klíčových ukazatelů výkonnosti – Obrázek: Xpert.Digital
Vývoj klíčových ukazatelů výkonnosti (KPI) odhaluje jasný posun od tradičních SEO metrik k metrikám řízeným umělou inteligencí. Viditelnost se odklání od klasického hodnocení klíčových slov směrem k podílu hlasu a podílu modelu, měřenému specializovanými nástroji pro monitorování LLM, jako jsou Peec.ai nebo Profound. Pokud jde o návštěvnost, doporučující návštěvnost z platforem s umělou inteligencí doplňuje organickou návštěvnost a míru prokliku, přičemž nástroje pro webovou analytiku, jako je Google Analytics 4 (GA4), využívají vlastní skupiny kanálů. Autorita webových stránek již není určena pouze autoritou domény a zpětnými odkazy, ale také citacemi a kvalitou zmínek v systémech s umělou inteligencí, měřitelnou pomocí nástrojů pro monitorování LLM a analýzy zpětných odkazů citovaných zdrojů. Vnímání značky se rozšiřuje z vyhledávacích dotazů souvisejících se značkou a zahrnuje sentiment zmínek s umělou inteligencí, zachycený nástroji pro monitorování LLM a sociálními nástroji. Na technické úrovni existuje kromě tradiční míry indexování také míra vyhledávání pomocí AI boty, která se určuje pomocí analýzy souborů protokolu serveru.
Přední nástroje pro monitorování a analýzu GEO/LLMO

Přední nástroje pro monitorování a analýzu GEO/LLMO – Obrázek: Xpert.Digital
Široká škála předních nástrojů pro monitorování a analýzu GEO/LLMO nabízí různá specializovaná řešení pro různé cílové skupiny. Profound představuje komplexní podnikové řešení, které poskytuje monitorování, sdílení hlasu, analýzu sentimentu a analýzu zdrojů pro ChatGPT, Copilot, Perplexity a Google AIO. Peec.ai se také zaměřuje na marketingové týmy a podnikové zákazníky a nabízí řídicí panel pro prezentaci značky, benchmarking konkurence a analýzu mezer v obsahu pro ChatGPT, Perplexity a Google AIO.
Pro malé a střední podniky (MSP) a SEO profesionály nabízí RankScale analýzu hodnocení v reálném čase v odpovědích generovaných umělou inteligencí, analýzu sentimentu a analýzu citací na ChatGPT, Perplexity a Bing Chat. Otterly.ai se zaměřuje na zmínky a zpětné odkazy s upozorněními na změny a slouží malým a středním podnikům a agenturám prostřednictvím ChatGPT, Claude a Gemini. Goodie AI se prezentuje jako komplexní platforma pro monitorování, optimalizaci a tvorbu obsahu na stejných platformách a cílí na malé a střední podniky a agentury.
Hall nabízí specializované řešení pro podnikové a produktové týmy s konverzační inteligencí, měřením návštěvnosti na základě doporučení umělé inteligence a sledováním agentů pro různé chatboty. Pro začátečníky jsou k dispozici bezplatné nástroje: HubSpot AI Grader poskytuje bezplatnou kontrolu podílu hlasu a sentimentu na GPT-4 a Perplexity, zatímco Mangools AI Grader nabízí bezplatnou kontrolu viditelnosti umělé inteligence a porovnání konkurence na ChatGPT, Google AIO a Perplexity pro začátečníky a SEO specialisty.
Kompletní rámec GEO akcí: 5 fází k optimální viditelnosti AI
Budování autority pro budoucnost umělé inteligence: Proč je EEAT klíčem k úspěchu
Po podrobné analýze technologických základů, strategických pilířů a konkurenčního prostředí tato závěrečná část shrnuje zjištění v praktickém rámci pro akci a zaměřuje se na budoucí vývoj vyhledávání.
Funkční rámec pro akci
Složitost generativní optimalizace motorů vyžaduje strukturovaný a iterativní přístup. Následující kontrolní seznam shrnuje doporučení z předchozích částí do praktického pracovního postupu, který může sloužit jako vodítko pro implementaci.
Fáze 1: Audit a základní posouzení
- Proveďte technický SEO audit: Zkontrolujte základní technické požadavky, jako je procházitelnost, indexovatelnost, rychlost načítání stránek (Core Web Vitals) a optimalizace pro mobilní zařízení. Identifikujte problémy, které by mohly blokovat prohledávače s umělou inteligencí (např. pomalé načítání, závislosti na JavaScriptu).
- Kontrola kódu Schema.org: Prověřte stávající kód strukturovaných dat z hlediska úplnosti, správnosti a použití síťových entit (@id).
- Proveďte audit obsahu: Vyhodnoťte existující obsah s ohledem na signály EEAT (jsou autoři identifikováni, jsou citovány zdroje?), sémantickou hloubku a autoritu tématu. Identifikujte mezery v tematických seskupeních.
- Určete základní úroveň viditelnosti LLM: Použijte specializované monitorovací nástroje nebo manuální dotazy na relevantních platformách umělé inteligence (Google AIO, ChatGPT, Perplexity) k zachycení aktuálního stavu viditelnosti vaší vlastní značky a značky vašich hlavních konkurentů.
Fáze 2: Strategie a optimalizace obsahu
- Vytvořte mapu tematických shluků: Na základě výzkumu klíčových slov a témat vytvořte strategickou mapu témat a podtémat, která mají být pokryta, a která bude odrážet vaši vlastní odbornost.
- Vytvářejte a optimalizujte obsah: Vytvářejte nový obsah a upravujte stávající obsah s jasným zaměřením na optimalizaci pro extrakci (struktura úryvků, seznamy, tabulky, nejčastější dotazy) a pokrytí entit.
- Posílení signálů EEAT: Implementace nebo vylepšení stránek autorů, přidávání odkazů a citací, začlenění unikátních referencí a originálních dat.
Fáze 3: Technická implementace
- Zavedení/aktualizace značkování Schema.org: Implementace relevantního a propojeného značkování Schema na všech důležitých stránkách, zejména u produktů, často kladených otázek, průvodců a článků.
- Vytvořte a poskytněte soubor llms.txt: Vytvořte soubor llms.txt, který odkazuje na nejdůležitější a nejrelevantnější obsah pro systémy umělé inteligence, a umístěte jej do kořenového adresáře webu.
- Řešení problémů s výkonem: Odstraňte problémy zjištěné v rámci technického auditu týkající se doby načítání a vykreslování.
Fáze 4: Stavební úřad a propagace
- Provádějte digitální PR a oslovování: Cílené kampaně pro generování vysoce kvalitních zpětných odkazů a, co je důležitější, nepropojených zmínek o značce v autoritativních publikacích relevantních k danému tématu.
- Zapojte se do komunitních platforem: Aktivně a ochotně se zapojujte do diskusí na platformách, jako jsou Reddit a Quora, abyste prezentovali značku jako užitečný a kompetentní zdroj.
Fáze 5: Měření a iterace
- Nastavení analytických nástrojů: Konfigurace nástrojů pro webovou analytiku pro sledování referenční návštěvnosti ze zdrojů umělé inteligence a pro monitorování nepřímých signálů, jako je přímá návštěvnost a vyhledávání značek.
- Průběžně sledujte viditelnost LLM: Pravidelně používejte monitorovací nástroje ke sledování vývoje vlastní viditelnosti a viditelnosti vašich konkurentů.
- Strategie adaptace: Využijte získaná data k neustálému zdokonalování strategie obsahu a autorit a k reakci na změny v prostředí umělé inteligence.
Budoucnost vyhledávání: Od shromažďování informací k interakci znalostí
Integrace generativní umělé inteligence není pomíjivý trend, ale začátek nové éry interakce člověka s počítačem. Tento vývoj přesáhne dnešní systémy a zásadně změní způsob, jakým přistupujeme k informacím.
Vývoj umělé inteligence ve vyhledávání
- Hyperpersonalizace: Budoucí systémy umělé inteligence budou přizpůsobovat odpovědi nejen explicitnímu požadavku, ale také implicitnímu kontextu uživatele – jeho historii vyhledávání, poloze, preferencím a dokonce i jeho předchozím interakcím se systémem.
- Pracovní postupy podobné agentům: Umělá inteligence se vyvine z pouhého poskytovatele odpovědí na proaktivního asistenta schopného provádět vícestupňové úkoly jménem uživatele – od výzkumu a shrnutí až po rezervaci nebo nákup.
- Konec „hledání“ jako metafory: Koncept aktivního „hledání“ je stále více nahrazován nepřetržitou, na dialog orientovanou interakcí s všudypřítomným, inteligentním asistentem. Hledání se stává konverzací.
Příprava na budoucnost: Budování odolné a budoucnost obstojné strategie
Závěrečným sdělením je, že principy uvedené v této zprávě – budování skutečné autority, tvorba vysoce kvalitního a strukturovaného obsahu a správa jednotné digitální přítomnosti – nejsou krátkodobými taktikami pro současnou generaci umělé inteligence. Jsou to základní principy pro budování značky, která může prosperovat v jakékoli budoucí krajině, kde jsou informace poskytovány prostřednictvím inteligentních systémů.
Důraz musí být kladen na to, abychom se stali zdrojem pravdy, ze kterého se chtějí učit jak lidé, tak i jejich asistenti s umělou inteligencí. Společnosti, které investují do znalostí, empatie a jasnosti, budou nejen viditelné ve výsledcích vyhledávání dnes, ale také budou významně formovat narativy svého odvětví v zítřejším světě řízeném umělou inteligencí.
Jsme tu pro vás - Poradenství - Plánování - Implementace - Projektový management
☑️ Podpora malých a středních podniků v oblasti strategie, poradenství, plánování a implementace
☑️ Vytvoření nebo restrukturalizace digitální strategie a digitalizace
☑️ Rozšíření a optimalizace mezinárodních prodejních procesů
☑️ Globální a digitální B2B obchodní platformy
☑️ Průkopnický rozvoj podnikání

Konrad Wolfenstein
Rád/a bych sloužil/a jako váš osobní poradce.
Můžete mě kontaktovat vyplněním níže uvedeného kontaktního formuláře nebo mi jednoduše zavolat na číslo +49 7348 4088 965 .
Těším se na náš společný projekt.
Napiš mi




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital je centrum pro průmysl se zaměřením na digitalizaci, strojírenství, logistiku/intralogistiku a fotovoltaiku.
S naším komplexním řešením pro rozvoj podnikání 360° podporujeme renomované společnosti od nových obchodů až po poprodejní služby.
Součástí našich digitálních nástrojů jsou analýzy trhu, s-marketing, marketingová automatizace, vývoj obsahu, PR, mailové kampaně, personalizované sociální sítě a péče o leady.
Více informací naleznete na: www.xpert.digital - www.xpert.solar - www.xpert.plus
Zůstaňte v kontaktu











