
Pokus o vysvětlení AI: Jak funguje a funguje umělá inteligence – jak se trénuje?

Výběr hlasu 📢
Publikováno dne: 8. září 2024 / Aktualizace od: 9. září 2024 - Autor: Konrad Wolfenstein

Pokus o vysvětlení AI: Jak umělá inteligence funguje a jak se trénuje? – Obrázek: Xpert.Digital
📊 Od vstupu dat po predikci modelu: Proces AI
Jak funguje umělá inteligence (AI)? 🤖
Jak umělá inteligence (AI) funguje, lze rozdělit do několika jasně definovaných kroků. Každý z těchto kroků je rozhodující pro konečný výsledek, který AI přináší. Proces začíná zadáním dat a končí predikcí modelu a případnou zpětnou vazbou nebo dalšími tréninkovými koly. Tyto fáze popisují proces, kterým procházejí téměř všechny modely umělé inteligence, bez ohledu na to, zda se jedná o jednoduché sady pravidel nebo vysoce složité neuronové sítě.
1. Vstup dat 📊
Základem veškeré umělé inteligence jsou data, se kterými pracuje. Tato data mohou mít různé formy, například obrázky, text, zvukové soubory nebo videa. AI používá tato nezpracovaná data k rozpoznání vzorců a rozhodování. Kvalita a kvantita dat zde hraje ústřední roli, protože mají významný vliv na to, jak dobře či špatně bude model později fungovat.
Čím rozsáhlejší a přesnější data, tím lépe se může AI učit. Například, když je AI trénována pro zpracování obrazu, vyžaduje velké množství obrazových dat ke správné identifikaci různých objektů. U jazykových modelů jsou to textová data, která pomáhají umělé inteligenci porozumět a generovat lidský jazyk. Zadávání dat je prvním a jedním z nejdůležitějších kroků, protože kvalita předpovědí může být pouze tak dobrá, jak dobrá jsou podkladová data. Slavný princip v informatice to popisuje rčením „Garbage in, garbage out“ – špatná data vedou ke špatným výsledkům.
2. Předzpracování dat 🧹
Jakmile jsou data zadána, je třeba je připravit, než je lze vložit do skutečného modelu. Tento proces se nazývá předzpracování dat. Cílem je dát data do formy, která může být modelem optimálně zpracována.
Běžným krokem předzpracování je normalizace dat. To znamená, že data jsou převedena do jednotného rozsahu hodnot, aby s nimi model zacházel rovnoměrně. Příkladem může být měřítko všech hodnot pixelů obrázku na rozsah 0 až 1 namísto 0 až 255.
Další důležitou součástí předzpracování je tzv. extrakce rysů. Z nezpracovaných dat jsou extrahovány určité funkce, které jsou pro model obzvláště relevantní. Při zpracování obrazu to mohou být například okraje nebo určité barevné vzory, zatímco v textech se extrahují příslušná klíčová slova nebo větné struktury. Předzpracování je zásadní pro to, aby byl proces učení AI efektivnější a přesnější.
3. Modelka 🧩
Model je srdcem každé umělé inteligence. Zde jsou data analyzována a zpracovávána na základě algoritmů a matematických výpočtů. Model může existovat v různých podobách. Jedním z nejznámějších modelů je neuronová síť, která je založena na tom, jak funguje lidský mozek.
Neuronové sítě se skládají z několika vrstev umělých neuronů, které zpracovávají a předávají informace. Každá vrstva přebírá výstupy předchozí vrstvy a dále je zpracovává. Proces učení neuronové sítě spočívá v úpravě vah spojení mezi těmito neurony tak, aby síť mohla provádět stále přesnější předpovědi nebo klasifikace. K této adaptaci dochází prostřednictvím tréninku, při kterém síť přistupuje k velkému množství vzorových dat a iterativně zlepšuje své vnitřní parametry (váhy).
Kromě neuronových sítí se v modelech AI používá také mnoho dalších algoritmů. Patří mezi ně rozhodovací stromy, náhodné lesy, podpůrné vektorové stroje a mnoho dalších. Který algoritmus se použije, závisí na konkrétní úloze a dostupných datech.
4. Předpověď modelu 🔍
Poté, co je model trénován s daty, je schopen provádět předpovědi. Tento krok se nazývá predikce modelu. Umělá inteligence přijímá vstup a vrací výstup, tj. předpověď nebo rozhodnutí, na základě vzorců, které se dosud naučila.
Tato předpověď může mít různé podoby. Například v modelu klasifikace obrázků by umělá inteligence mohla předvídat, který objekt je na obrázku viditelný. V jazykovém modelu by mohl předpovědět, které slovo je ve větě další. Ve finančních předpovědích by umělá inteligence mohla předvídat, jak si povede akciový trh.
Je důležité zdůraznit, že přesnost předpovědí silně závisí na kvalitě trénovacích dat a architektuře modelu. Model trénovaný na nedostatečných nebo zkreslených datech pravděpodobně vytvoří nesprávné předpovědi.
5. Zpětná vazba a školení (volitelné) ♻️
Další důležitou součástí práce AI je mechanismus zpětné vazby. Model je pravidelně kontrolován a dále optimalizován. K tomuto procesu dochází buď během tréninku nebo po predikci modelu.
Pokud model provede nesprávné předpovědi, může se pomocí zpětné vazby naučit tyto chyby detekovat a podle toho upravit své vnitřní parametry. To se provádí porovnáním modelových předpovědí se skutečnými výsledky (např. se známými údaji, pro které již existují správné odpovědi). Typickým postupem v této souvislosti je tzv. supervised learning, ve kterém se AI učí z příkladových dat, která jsou již opatřena správnými odpověďmi.
Běžnou metodou zpětné vazby je algoritmus zpětného šíření používaný v neuronových sítích. Chyby, kterých se model dopustí, se šíří zpět sítí, aby se upravily váhy neuronových spojení. Model se učí ze svých chyb a ve svých předpovědích je stále přesnější.
Role tréninku 🏋️♂️
Výcvik AI je iterativní proces. Čím více dat model vidí a čím častěji je na základě těchto dat trénován, tím přesnější jsou jeho předpovědi. Existují však také limity: příliš trénovaný model může mít problémy s takzvaným „overfitingem“. To znamená, že si trénovací data zapamatuje tak dobře, že na nových, neznámých datech produkuje horší výsledky. Je proto důležité model trénovat tak, aby zobecňoval a dělal dobré predikce i na nových datech.
Kromě běžného školení existují i postupy jako transfer learning. Zde se pro nový podobný úkol používá již natrénovaný model na velkém množství dat. To šetří čas a výpočetní výkon, protože model nemusí být trénován od začátku.
Využijte své přednosti na maximum 🚀
Práce umělé inteligence je založena na komplexní interakci různých kroků. Od zadávání dat, předzpracování, trénování modelu, predikce a zpětné vazby existuje mnoho faktorů, které ovlivňují přesnost a efektivitu AI. Dobře vyškolená umělá inteligence může poskytnout obrovské výhody v mnoha oblastech života – od automatizace jednoduchých úkolů až po řešení složitých problémů. Ale stejně tak je důležité porozumět omezením a potenciálním úskalím umělé inteligence, abyste mohli co nejlépe využít její silné stránky.
🤖📚 Jednoduše vysvětleno: Jak se trénuje AI?
🤖📊 Proces učení AI: zachytit, propojit a uložit
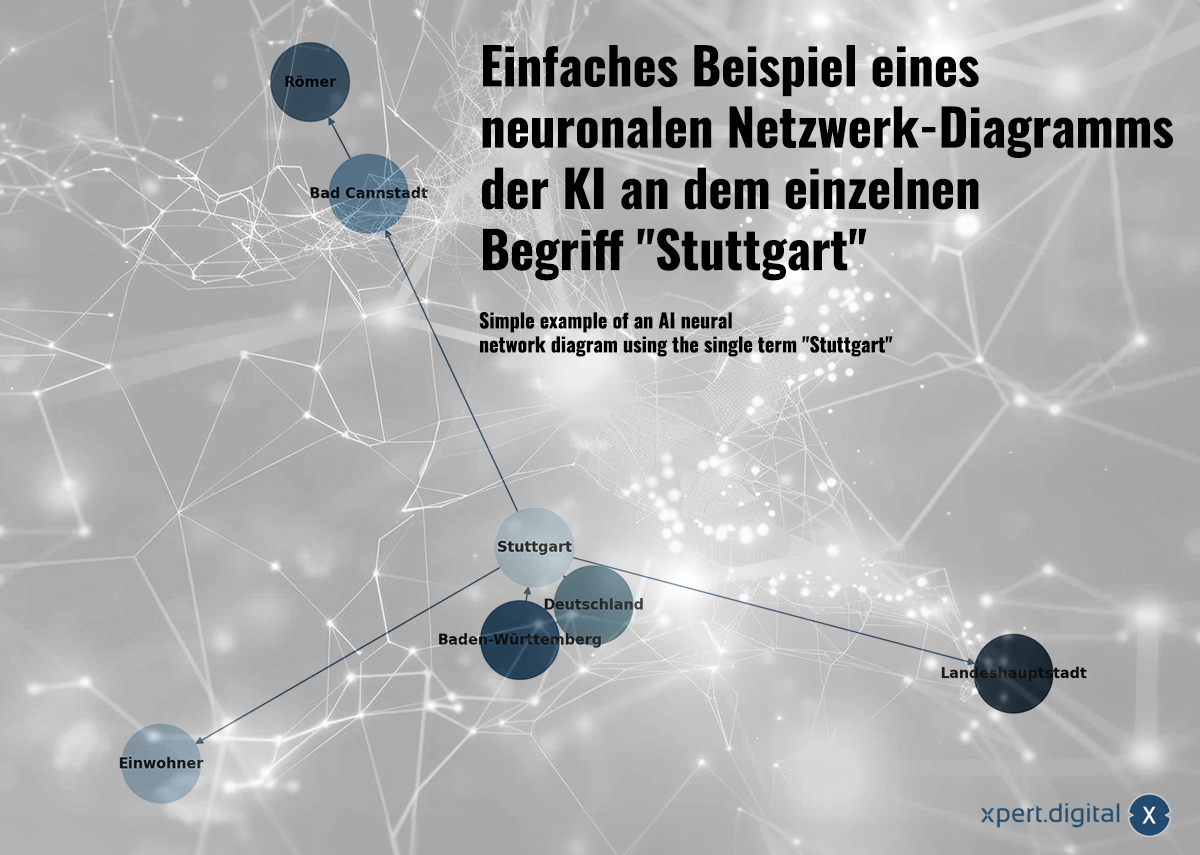
Jednoduchý příklad diagramu neuronální sítě AI na individuálním termínu „Stuttgart“-Image: xpert.digital
🌟 Sbírejte a připravujte data
Prvním krokem v procesu učení AI je sběr a příprava dat. Tato data mohou pocházet z různých zdrojů, jako jsou databáze, senzory, texty nebo obrázky.
🌟 Související data (neuronová síť)
Shromážděná data jsou vzájemně spojena v neuronové síti. Každý datový balíček je zobrazen připojením v síti „neuronů“ (uzel). Jednoduchý příklad s městem Stuttgart by mohl vypadat takto:
a) Stuttgart je město v Bádensku-Württembersku
b) Bádensko-Württembersko je spolková země v Německu
c) Stuttgart je město v Německu
d) Stuttgart má v roce 2023 633 484 obyvatel
e) Bad Cannstatt je okres Stuttgartu
f) Bad Cannstatt byl založen Římany
g) Stuttgart je hlavním městem spolkové země Bádensko-Württembersko
V závislosti na velikosti objemu dat jsou pomocí použitého modelu AI vytvářeny parametry pro potenciální výdaje. Jako příklad: GPT-3 má přibližně 175 miliard parametrů!
🌟 Úložiště a přizpůsobení (učení)
Data jsou přiváděna do neuronové sítě. Procházejí modelem AI a jsou zpracovávány prostřednictvím připojení (podobně jako synapse). Váhy (parametry) mezi neurony jsou upraveny tak, aby trénovaly model nebo vykonávaly nějaký úkol.
Na rozdíl od konvenčních forem paměti, jako je přímý přístup, označený přístup, sekvenční nebo zásobní ukládání, neuronové sítě ukládají data nekonvenčním způsobem. „Data“ jsou uložena ve hmotnostech a zkreslení spojení mezi neurony.
Skutečné „ukládání“ informací v neuronální síti dochází k přizpůsobení hmotností spojení mezi neurony. Model AI „se učí“ neustálým přizpůsobováním těchto hmotností a zkreslení na základě vstupních dat a definovaného algoritmu učení. Jedná se o nepřetržitý proces, ve kterém může model provádět přesné předpovědi v důsledku opakujících se úprav.
Model AI lze považovat za typ programování, protože je vytvořen pomocí definovaných algoritmů a matematických výpočtů a neustále zlepšuje nastavení svých parametrů (váh) pro přesné předpovědi. Toto je pokračující proces.
Zkreslení jsou další parametry v neuronových sítích, které se přidávají k váženým vstupním hodnotám neuronu. Umožňují vážení parametrů (důležité, méně důležité, důležité atd.), díky čemuž je AI flexibilnější a přesnější.
Neuronové sítě dokážou nejen ukládat jednotlivá fakta, ale také rozpoznávat spojení mezi daty pomocí rozpoznávání vzorů. Stuttgartský příklad ilustruje, jak lze znalosti zavést do neuronové sítě, ale neuronové sítě se neučí prostřednictvím explicitních znalostí (jako v tomto jednoduchém příkladu), ale prostřednictvím analýzy datových vzorů. Neuronové sítě dokážou nejen ukládat jednotlivá fakta, ale také se učit váhy a vztahy mezi vstupními daty.
Tento tok poskytuje srozumitelný úvod do toho, jak AI a zejména neuronové sítě fungují, aniž by se příliš hluboce ponořovaly do technických detailů. Ukazuje, že ukládání informací v neuronových sítích neprobíhá jako v tradičních databázích, ale úpravou spojení (vah) v rámci sítě.
🤖📚 Podrobněji: Jak se trénuje AI?
🏋️♂️ Školení AI, zejména modelu strojového učení, probíhá v několika krocích. Trénink AI je založen na neustálé optimalizaci parametrů modelu prostřednictvím zpětné vazby a úprav, dokud model nevykazuje nejlepší výkon na poskytnutých datech. Zde je podrobné vysvětlení, jak tento proces funguje:
1. 📊 Sbírejte a připravujte data
Data jsou základem školení AI. Obvykle se skládají z tisíců nebo milionů příkladů, které má systém analyzovat. Příkladem jsou obrázky, texty nebo údaje z časových řad.
Data musí být vyčištěna a normalizována, aby se předešlo zbytečným zdrojům chyb. Často se data převádějí na prvky, které obsahují relevantní informace.
2. 🔍 Definujte model
Model je matematická funkce, která popisuje vztahy v datech. V neuronových sítích, které se často používají pro AI, se model skládá z více vrstev neuronů spojených dohromady.
Každý neuron provede matematickou operaci pro zpracování vstupních dat a poté předá signál dalšímu neuronu.
3. 🔄 Inicializujte váhy
Spojení mezi neurony mají váhy, které jsou zpočátku nastaveny náhodně. Tyto váhy určují, jak silně neuron reaguje na signál.
Cílem tréninku je upravit tyto váhy tak, aby model dělal lepší předpovědi.
4. ➡️ Propagace vpřed
Dopředný průchod prochází vstupní data modelem za účelem vytvoření predikce.
Každá vrstva zpracovává data a předává je další vrstvě, dokud poslední vrstva nedoručí výsledek.
5. ⚖️ Vypočítejte ztrátovou funkci
Funkce ztráty měří, jak dobré jsou předpovědi modelu ve srovnání se skutečnými hodnotami (štítky). Běžným měřítkem je chyba mezi předpokládanou a skutečnou odezvou.
Čím vyšší ztráta, tím horší byla předpověď modelu.
6. 🔙 Zpětná propagace
Při zpětném průchodu je chyba vrácena zpět z výstupu modelu do předchozích vrstev.
Chyba se přerozdělí na váhy spojů a model upraví váhy tak, aby se chyby zmenšily.
To se provádí pomocí sestupu gradientu: vypočítá se vektor gradientu, který udává, jak by se měly váhy změnit, aby se minimalizovala chyba.
7. 🔧 Aktualizujte váhy
Po výpočtu chyby se váhy spojení aktualizují s malou úpravou na základě rychlosti učení.
Rychlost učení určuje, jak moc se váhy mění s každým krokem. Změny, které jsou příliš velké, mohou způsobit nestabilitu modelu a změny, které jsou příliš malé, vedou k pomalému procesu učení.
8. 🔁 Opakovat (Epocha)
Tento proces dopředného průchodu, výpočtu chyb a aktualizace hmotnosti se opakuje, často ve více epochách (prochází celým souborem dat), dokud model nedosáhne přijatelné přesnosti.
S každou epochou se model učí trochu víc a dále upravuje své váhy.
9. 📉 Validace a testování
Poté, co je model trénován, je testován na ověřeném souboru dat, aby se zjistilo, jak dobře zobecňuje. To zajišťuje, že si nejen „zapamatoval“ trénovací data, ale také dobře předpovídá neznámá data.
Testovací data pomáhají měřit konečný výkon modelu před jeho použitím v praxi.
10. 🚀 Optimalizace
Mezi další kroky ke zlepšení modelu patří ladění hyperparametrů (např. úprava rychlosti učení nebo struktury sítě), regularizace (aby se předešlo nadměrnému přizpůsobení) nebo zvýšení množství dat.
📊🔙 Umělá inteligence: Udělejte z černé skříňky AI srozumitelnou, srozumitelnou a vysvětlitelnou pomocí Explainable AI (XAI), teplotních map, náhradních modelů nebo jiných řešení

Umělá inteligence: Učinit černou skříňku umělé inteligence srozumitelnou, srozumitelnou a vysvětlitelnou pomocí Explainable AI (XAI), teplotních map, náhradních modelů nebo jiných řešení - Obrázek: Xpert.Digital
Takzvaná „černá skříňka“ umělé inteligence (AI) představuje významný a aktuální problém I odborníci se často potýkají s problémem, že nejsou schopni plně porozumět tomu, jak systémy umělé inteligence dospívají ke svým rozhodnutím. Tento nedostatek transparentnosti může způsobit značné problémy, zejména v kritických oblastech, jako je ekonomika, politika nebo medicína. Lékař nebo lékař, který spoléhá na systém umělé inteligence při diagnostice a doporučování terapie, musí mít důvěru v přijatá rozhodnutí. Pokud však rozhodování AI není dostatečně transparentní, vzniká nejistota a potenciálně nedostatek důvěry – v situacích, kdy by mohlo jít o lidské životy.
Více o tom zde:
Jsme tu pro Vás - poradenství - plánování - realizace - projektové řízení
☑️ Podpora MSP ve strategii, poradenství, plánování a implementaci
☑️ Vytvoření nebo přeladění digitální strategie a digitalizace
☑️ Rozšíření a optimalizace mezinárodních prodejních procesů
☑️ Globální a digitální obchodní platformy B2B
☑️ Pioneer Business Development

Konrad Wolfenstein
Rád posloužím jako váš osobní poradce.
Můžete mě kontaktovat vyplněním kontaktního formuláře níže nebo mi jednoduše zavolejte na číslo +49 89 89 674 804 (Mnichov) .
Těším se na náš společný projekt.
Napište mi

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital je centrum pro průmysl se zaměřením na digitalizaci, strojírenství, logistiku/intralogistiku a fotovoltaiku.
S naším 360° řešením pro rozvoj podnikání podporujeme známé společnosti od nových obchodů až po poprodejní služby.
Market intelligence, smarketing, automatizace marketingu, vývoj obsahu, PR, e-mailové kampaně, personalizovaná sociální média a péče o potenciální zákazníky jsou součástí našich digitálních nástrojů.
Více se dozvíte na: www.xpert.digital - www.xpert.solar - www.xpert.plus
Zůstaňte v kontaktu


















