


KI und SEO mit BERT – Bidirectional Encoder Representations from Transformers – Modell im Bereich der natürlichen Sprachverarbeitung (NLP) – Bild: Xpert.Digital
🚀💬 Von Google entwickelt: BERT und seine Bedeutung für NLP - Warum bidirektionales Textverständnis entscheidend ist
🔍🗣️ BERT, kurz für Bidirectional Encoder Representations from Transformers, ist ein bedeutendes Modell im Bereich der natürlichen Sprachverarbeitung (NLP), das von Google entwickelt wurde. Es hat die Art und Weise, wie Maschinen Sprache verstehen, revolutioniert. Im Gegensatz zu früheren Modellen, die Texte sequenziell von links nach rechts oder umgekehrt analysierten, ermöglicht BERT eine bidirektionale Verarbeitung. Dies bedeutet, dass es den Kontext eines Wortes sowohl aus der vorhergehenden als auch aus der nachfolgenden Textsequenz erfasst. Diese Fähigkeit verbessert das Verständnis komplexer sprachlicher Zusammenhänge erheblich.
🔍 Die Architektur von BERT
In den vorangegangenen Jahren gab es eine der bedeutendsten Entwicklungen im Bereich der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) durch die Einführung des Transformer-Modells, wie es im PDF 2017 – Attention is all you need – Paper wurde (Wikipedia). Dieses Modell hat das Feld grundlegend verändert, indem es die zuvor verwendeten Strukturen, wie die maschinelle Übersetzung, verworfen hat. Stattdessen setzt es ausschließlich auf Aufmerksamkeitsmechanismen. Das Design des Transformers bildet seitdem die Grundlage für viele Modelle, die in verschiedenen Bereichen wie der Sprachgenerierung, Übersetzung und darüber hinaus den Stand der Technik darstellen.
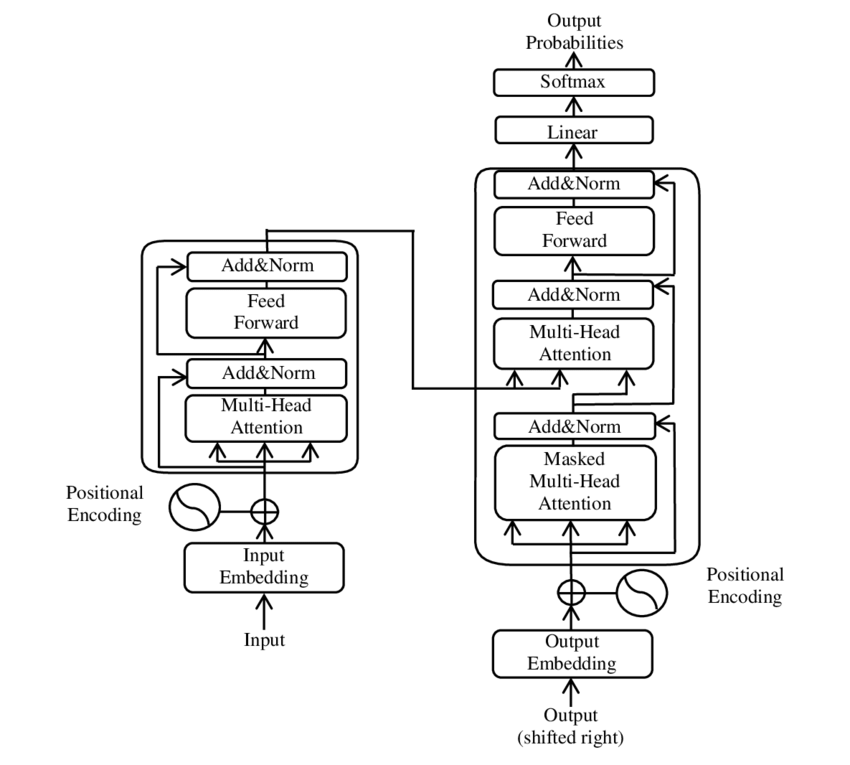
Eine Abbildung der Hauptkomponenten des Transformer-Modells – Bild: Google
BERT basiert auf dieses Transformer-Architektur. Diese Architektur nutzt sogenannte Selbstaufmerksamkeitsmechanismen (Self-Attention), um die Beziehungen zwischen den Wörtern in einem Satz zu analysieren. Dabei wird jedem Wort im Kontext des gesamten Satzes Aufmerksamkeit gewidmet, was zu einem präziseren Verständnis syntaktischer und semantischer Beziehungen führt.
Die Autoren des Papers “Attention Is All You Need” sind:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Research)
- Jakob Uszkoreit (Google Research)
- Llion Jones (Google Research)
- Aidan N. Gomez (University of Toronto, Arbeit teilweise bei Google Brain durchgeführt)
- Łukasz Kaiser (Google Brain)
- Illia Polosukhin (Unabhängig, frühere Arbeit bei Google Research)
Diese Autoren haben maßgeblich zur Entwicklung des Transformer-Modells beigetragen, das in diesem Paper vorgestellt wurde.
🔄 Bidirektionale Verarbeitung
Ein herausragendes Merkmal von BERT ist seine Fähigkeit zur bidirektionalen Verarbeitung. Während traditionelle Modelle wie rekurrente neuronale Netze (RNNs) oder Long Short-Term Memory (LSTM) Netzwerke Texte nur in eine Richtung verarbeiten, analysiert BERT den Kontext eines Wortes in beiden Richtungen. Dies ermöglicht es dem Modell, subtile Bedeutungsnuancen besser zu erfassen und somit genauere Vorhersagen zu treffen.
🕵️♂️ Maskierte Sprachmodellierung
Ein weiterer innovativer Aspekt von BERT ist die Technik der Masked Language Model (MLM). Dabei werden zufällig ausgewählte Wörter in einem Satz maskiert und das Modell wird trainiert, diese Wörter basierend auf dem umgebenden Kontext vorherzusagen. Diese Methode zwingt BERT dazu, ein tiefes Verständnis für den Kontext und die Bedeutung jedes Wortes im Satz zu entwickeln.
🚀 Training und Anpassung von BERT
BERT durchläuft einen zweistufigen Trainingsprozess: das Pre-Training und das Fine-Tuning.
📚 Pre-Training
Im Pre-Training wird BERT mit großen Textmengen trainiert, um allgemeine Sprachmuster zu lernen. Dazu gehören Wikipedia-Texte und andere umfangreiche Textkorpora. In dieser Phase lernt das Modell grundlegende sprachliche Strukturen und Kontexte kennen.
🔧 Fine-Tuning
Nach dem Pre-Training wird BERT für spezifische NLP-Aufgaben angepasst, wie etwa Textklassifikation oder Sentimentanalyse. Hierbei wird das Modell mit kleineren, aufgabenbezogenen Datensätzen trainiert, um seine Leistung für bestimmte Anwendungen zu optimieren.
🌍 Anwendungsbereiche von BERT
BERT hat sich in zahlreichen Bereichen der natürlichen Sprachverarbeitung als äußerst nützlich erwiesen:
Suchmaschinenoptimierung
Google verwendet BERT, um Suchanfragen besser zu verstehen und relevantere Ergebnisse anzuzeigen. Dies verbessert die Benutzererfahrung erheblich.
Textklassifikation
BERT kann Dokumente nach Themen kategorisieren oder die Stimmung in Texten analysieren.
Named Entity Recognition (NER)
Das Modell identifiziert und klassifiziert benannte Entitäten in Texten, wie Personen-, Orts- oder Organisationsnamen.
Frage-Antwort-Systeme
BERT wird genutzt, um präzise Antworten auf gestellte Fragen zu liefern.
🧠 Die Bedeutung von BERT für die Zukunft der KI
BERT hat neue Maßstäbe für NLP-Modelle gesetzt und den Weg für weitere Innovationen geebnet. Durch seine Fähigkeit zur bidirektionalen Verarbeitung und sein tiefes Verständnis für Sprachkontexte hat es die Effizienz und Genauigkeit von KI-Anwendungen erheblich gesteigert.
🔜 Zukünftige Entwicklungen
Die Weiterentwicklung von BERT und ähnlichen Modellen wird voraussichtlich darauf abzielen, noch leistungsfähigere Systeme zu schaffen. Diese könnten komplexere Sprachaufgaben bewältigen und in einer Vielzahl neuer Anwendungsbereiche eingesetzt werden. Die Integration solcher Modelle in alltägliche Technologien könnte unsere Interaktion mit Computern grundlegend verändern.
🌟 Meilenstein in der Entwicklung der künstlichen Intelligenz
BERT ist ein Meilenstein in der Entwicklung der künstlichen Intelligenz und hat die Art und Weise revolutioniert, wie Maschinen natürliche Sprache verarbeiten. Seine bidirektionale Architektur ermöglicht ein tieferes Verständnis sprachlicher Zusammenhänge, was es für eine Vielzahl von Anwendungen unverzichtbar macht. Mit fortschreitender Forschung werden Modelle wie BERT weiterhin eine zentrale Rolle bei der Verbesserung von KI-Systemen spielen und neue Möglichkeiten für deren Einsatz eröffnen.
📣 Ähnliche Themen
- 📚 Einführung in BERT: Das bahnbrechende NLP-Modell
- 🔍 BERT und die Rolle der Bidirektionalität in NLP
- 🧠 Das Transformer-Modell: Grundstein von BERT
- 🚀 Maskierte Sprachmodellierung: BERTs Schlüssel zum Erfolg
- 📈 Anpassung von BERT: Von Pre-Training bis Fine-Tuning
- 🌐 Die Anwendungsbereiche von BERT in der modernen Technologie
- 🤖 BERTs Einfluss auf die Zukunft der Künstlichen Intelligenz
- 💡 Zukunftsperspektiven: Weiterentwicklungen von BERT
- 🏆 BERT als Meilenstein in der KI-Entwicklung
- 📰 Autoren des Transformer-Papiers „Attention Is All You Need“: Die Köpfe hinter BERT
#️⃣ Hashtags: #NLP #KünstlicheIntelligenz #Sprachmodellierung #Transformer #MaschinellesLernen
🎯🎯🎯 Profitieren Sie von der umfangreichen, fünffachen Expertise von Xpert.Digital in einem umfassenden Servicepaket | BD, R&D, XR, PR & Digitale Sichtbarkeitsoptimierung


Profitieren Sie von der umfangreichen, fünffachen Expertise von Xpert.Digital in einem umfassenden Servicepaket | R&D, XR, PR & Digitale Sichtbarkeitsoptimierung - Bild: Xpert.Digital
Xpert.Digital verfügt über tiefgehendes Wissen in verschiedenen Branchen. Dies erlaubt es uns, maßgeschneiderte Strategien zu entwickeln, die exakt auf die Anforderungen und Herausforderungen Ihres spezifischen Marktsegments zugeschnitten sind. Indem wir kontinuierlich Markttrends analysieren und Branchenentwicklungen verfolgen, können wir vorausschauend agieren und innovative Lösungen anbieten. Durch die Kombination aus Erfahrung und Wissen generieren wir einen Mehrwert und verschaffen unseren Kunden einen entscheidenden Wettbewerbsvorteil.
Mehr dazu hier:
BERT: Revolutionäre 🌟 NLP-Technologie
🚀 BERT, kurz für Bidirectional Encoder Representations from Transformers, ist ein fortschrittliches Sprachmodell, das von Google entwickelt wurde und sich seit seiner Einführung im Jahr 2018 zu einem bedeutenden Durchbruch im Bereich der natürlichen Sprachverarbeitung (Natural Language Processing, NLP) entwickelt hat. Es basiert auf der Transformer-Architektur, die die Art und Weise, wie Maschinen Text verstehen und verarbeiten, revolutioniert hat. Doch was genau macht BERT so besonders, und wofür wird es konkret eingesetzt? Um diese Frage zu beantworten, müssen wir uns eingehend mit den technischen Grundlagen, der Funktionsweise und den Anwendungsbereichen von BERT befassen.
📚 1. Die Grundlagen der natürlichen Sprachverarbeitung
Um die Bedeutung von BERT vollständig zu erfassen, ist es hilfreich, kurz auf die Grundlagen der natürlichen Sprachverarbeitung (NLP) einzugehen. NLP beschäftigt sich mit der Interaktion zwischen Computern und menschlicher Sprache. Das Ziel ist es, Maschinen beizubringen, Textdaten zu analysieren, zu verstehen und darauf zu reagieren. Vor der Einführung von Modellen wie BERT war die maschinelle Verarbeitung von Sprache oft mit erheblichen Herausforderungen verbunden, insbesondere aufgrund der Vieldeutigkeit, Kontextabhängigkeit und der komplexen Struktur menschlicher Sprache.
📈 2. Die Entwicklung von NLP-Modellen
Bevor BERT auf der Bildfläche erschien, basierten die meisten NLP-Modelle auf sogenannten unidirektionalen Architekturen. Das bedeutet, dass diese Modelle den Text entweder nur von links nach rechts oder von rechts nach links lasen, was bedeutete, dass sie nur eine begrenzte Menge an Kontext bei der Verarbeitung eines Wortes in einem Satz berücksichtigen konnten. Diese Einschränkung führte oft dazu, dass die Modelle den vollen semantischen Kontext eines Satzes nicht vollständig erfassten. Dies erschwerte die akkurate Interpretation von mehrdeutigen oder kontextsensitiven Wörtern.
Eine weitere wichtige Entwicklung in der NLP-Forschung vor BERT war das word2vec-Modell, das es Computern ermöglichte, Wörter in Vektoren zu übersetzen, die semantische Ähnlichkeiten widerspiegelten. Doch auch hier war der Kontext auf das unmittelbare Umfeld eines Wortes begrenzt. Später wurden Recurrent Neural Networks (RNNs) und insbesondere Long Short-Term Memory (LSTM)-Modelle entwickelt, die es ermöglichten, Textsequenzen besser zu verstehen, indem sie Informationen über mehrere Wörter hinweg speicherten. Diese Modelle hatten jedoch ebenfalls ihre Grenzen, insbesondere im Umgang mit langen Texten und dem gleichzeitigen Verständnis von Kontext in beide Richtungen.
🔄 3. Die Revolution durch die Transformer-Architektur
Der Durchbruch kam mit der Einführung der Transformer-Architektur im Jahr 2017, die die Grundlage für BERT bildet. Transformer-Modelle sind darauf ausgelegt, parallele Verarbeitungen von Text zu ermöglichen und dabei den Kontext eines Wortes sowohl aus dem vorausgehenden als auch aus dem nachfolgenden Text zu berücksichtigen. Dies geschieht durch sogenannte Selbstaufmerksamkeitsmechanismen (Self-Attention Mechanisms), die jedem Wort in einem Satz einen Gewichtungswert zuweisen, basierend darauf, wie wichtig es im Verhältnis zu den anderen Wörtern im Satz ist.
Im Gegensatz zu vorherigen Ansätzen sind Transformer-Modelle nicht unidirektional, sondern bidirektional. Dies bedeutet, dass sie Informationen sowohl aus dem linken als auch aus dem rechten Kontext eines Wortes ziehen können, um so eine vollständigere und genauere Repräsentation des Wortes und seiner Bedeutung zu erzeugen.
🧠 4. BERT: Ein Bidirektionales Modell
BERT hebt die Leistungsfähigkeit der Transformer-Architektur auf eine neue Ebene. Das Modell ist darauf ausgelegt, den Kontext eines Wortes nicht nur von links nach rechts oder von rechts nach links, sondern in beide Richtungen gleichzeitig zu erfassen. Dies ermöglicht es BERT, den vollständigen Kontext eines Wortes innerhalb eines Satzes zu berücksichtigen, was zu einer deutlich verbesserten Genauigkeit bei Aufgaben der Sprachverarbeitung führt.
Ein zentrales Merkmal von BERT ist der Einsatz des sogenannten Maskierten Sprachmodells (Masked Language Model, MLM). Im Training von BERT werden zufällig ausgewählte Wörter in einem Satz durch eine Maske ersetzt, und das Modell wird darauf trainiert, diese maskierten Wörter basierend auf dem Kontext zu erraten. Diese Technik ermöglicht es BERT, tiefere und präzisere Beziehungen zwischen den Wörtern in einem Satz zu lernen.
Zusätzlich verwendet BERT eine Methode namens Next Sentence Prediction (NSP), bei der das Modell lernt, vorherzusagen, ob ein Satz auf einen anderen folgt oder nicht. Dies verbessert die Fähigkeit von BERT, längere Texte zu verstehen und komplexere Beziehungen zwischen Sätzen zu erkennen.
🌐 5. Anwendung von BERT in der Praxis
BERT hat sich als äußerst nützlich für eine Vielzahl von NLP-Aufgaben erwiesen. Hier sind einige der wichtigsten Anwendungsbereiche:
📊 a) Textklassifikation
Einer der häufigsten Einsatzzwecke von BERT ist die Textklassifikation, bei der Texte in vordefinierte Kategorien eingeteilt werden. Beispiele hierfür sind die Sentimentanalyse (z.B. Erkennen, ob ein Text positiv oder negativ ist) oder die Kategorisierung von Kundenfeedback. BERT kann durch sein tiefes Verständnis des Kontextes von Wörtern präzisere Ergebnisse liefern als frühere Modelle.
❓ b) Frage-Antwort-Systeme
BERT wird auch in Frage-Antwort-Systemen eingesetzt, bei denen das Modell Antworten auf gestellte Fragen aus einem Text extrahiert. Diese Fähigkeit ist besonders in Anwendungen wie Suchmaschinen, Chatbots oder virtuellen Assistenten von großer Bedeutung. Dank seiner bidirektionalen Architektur kann BERT relevante Informationen aus einem Text extrahieren, auch wenn die Frage indirekt formuliert ist.
🌍 c) Textübersetzung
Während BERT selbst nicht direkt als Übersetzungsmodell konzipiert ist, kann es in Kombination mit anderen Technologien verwendet werden, um die maschinelle Übersetzung zu verbessern. Durch das bessere Verständnis der semantischen Beziehungen in einem Satz kann BERT dazu beitragen, präzisere Übersetzungen zu generieren, insbesondere bei mehrdeutigen oder komplexen Formulierungen.
🏷️ d) Named Entity Recognition (NER)
Ein weiterer Anwendungsbereich ist die Named Entity Recognition (NER), bei der es darum geht, bestimmte Entitäten wie Namen, Orte oder Organisationen in einem Text zu identifizieren. BERT hat sich bei dieser Aufgabe als besonders effektiv erwiesen, da es den Kontext eines Satzes vollständig berücksichtigt und so Entitäten besser erkennen kann, auch wenn sie in verschiedenen Kontexten unterschiedliche Bedeutungen haben.
✂️ e) Textzusammenfassung
Die Fähigkeit von BERT, den gesamten Kontext eines Textes zu verstehen, macht es auch zu einem leistungsstarken Werkzeug für die automatische Textzusammenfassung. Es kann verwendet werden, um die wichtigsten Informationen aus einem langen Text zu extrahieren und eine prägnante Zusammenfassung zu erstellen.
🌟 6. Die Bedeutung von BERT für die Forschung und Industrie
Die Einführung von BERT hat in der NLP-Forschung eine neue Ära eingeläutet. Es war eines der ersten Modelle, das die Leistungsfähigkeit der bidirektionalen Transformer-Architektur in vollem Umfang nutzte und damit die Messlatte für viele nachfolgende Modelle legte. Viele Unternehmen und Forschungsinstitute haben BERT in ihre NLP-Pipelines integriert, um die Leistung ihrer Anwendungen zu verbessern.
Darüber hinaus hat BERT den Weg für weitere Innovationen im Bereich der Sprachmodelle geebnet. Beispielsweise wurden daraufhin Modelle wie GPT (Generative Pretrained Transformer) und T5 (Text-to-Text Transfer Transformer) entwickelt, die auf ähnlichen Prinzipien basieren, jedoch spezifische Verbesserungen für verschiedene Anwendungsfälle bieten.
🚧 7. Herausforderungen und Grenzen von BERT
Trotz seiner vielen Vorteile hat BERT auch einige Herausforderungen und Einschränkungen. Eine der größten Hürden ist der hohe Rechenaufwand, der für das Training und die Anwendung des Modells erforderlich ist. Da BERT ein sehr großes Modell mit Millionen von Parametern ist, benötigt es leistungsstarke Hardware und erhebliche Rechenressourcen, insbesondere bei der Verarbeitung großer Datenmengen.
Ein weiteres Problem ist die potenzielle Voreingenommenheit (Bias), die in den Trainingsdaten vorhanden sein kann. Da BERT auf großen Mengen an Textdaten trainiert wird, spiegelt es manchmal die Vorurteile und Stereotypen wider, die in diesen Daten vorhanden sind. Forscher arbeiten jedoch kontinuierlich daran, diese Probleme zu identifizieren und zu beheben.
🔍 Unverzichtbares Werkzeug für moderne Sprachverarbeitungsanwendungen
BERT hat die Art und Weise, wie Maschinen menschliche Sprache verstehen, erheblich verbessert. Mit seiner bidirektionalen Architektur und den innovativen Trainingsmethoden ist es in der Lage, den Kontext von Wörtern in einem Satz tief und genau zu erfassen, was zu einer höheren Genauigkeit bei vielen NLP-Aufgaben führt. Ob bei der Textklassifikation, in Frage-Antwort-Systemen oder bei der Erkennung von Entitäten – BERT hat sich als unverzichtbares Werkzeug für moderne Sprachverarbeitungsanwendungen etabliert.
Die Forschung im Bereich der natürlichen Sprachverarbeitung wird zweifellos weiter voranschreiten, und BERT hat den Grundstein für viele zukünftige Innovationen gelegt. Trotz der bestehenden Herausforderungen und Grenzen zeigt BERT eindrucksvoll, wie weit die Technologie in kurzer Zeit gekommen ist und welche spannenden Möglichkeiten sich in der Zukunft noch eröffnen werden.
🌀 Der Transformer: Eine Revolution im Bereich der Verarbeitung natürlicher Sprache
🌟 In den letzten Jahren war eine der bedeutendsten Entwicklungen im Bereich der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) die Einführung des Transformer-Modells, wie es im 2017 erschienenen Papier „Attention Is All You Need“ beschrieben wird. Dieses Modell hat das Feld grundlegend verändert, indem es die zuvor verwendeten rekurrenten oder konvolutionalen Strukturen für Aufgaben der Sequenztransduktion, wie die maschinelle Übersetzung, verworfen hat. Stattdessen setzt es ausschließlich auf Aufmerksamkeitsmechanismen. Das Design des Transformers bildet seitdem die Grundlage für viele Modelle, die in verschiedenen Bereichen wie der Sprachgenerierung, Übersetzung und darüber hinaus den Stand der Technik darstellen.
🔄 Der Transformer: Ein Paradigmenwechsel
Vor der Einführung des Transformers basierten die meisten Modelle für Sequenzaufgaben auf rekurrenten neuronalen Netzwerken (RNNs) oder „Long Short-Term Memory“-Netzwerken (LSTMs), die von Natur aus sequenziell arbeiten. Diese Modelle verarbeiten Eingabedaten Schritt für Schritt und erzeugen dabei versteckte Zustände, die entlang der Sequenz weitergegeben werden. Obwohl diese Methode effektiv ist, ist sie rechnerisch aufwendig und schwer zu parallelisieren, insbesondere bei langen Sequenzen. Zudem haben RNNs Schwierigkeiten, langfristige Abhängigkeiten zu lernen, da das sogenannte „Vanishing Gradient“-Problem auftritt.
Die zentrale Innovation des Transformers liegt in der Verwendung von Self-Attention-Mechanismen, die es dem Modell ermöglichen, die Wichtigkeit verschiedener Wörter in einem Satz zueinander zu gewichten, unabhängig von ihrer Position. Dies erlaubt es dem Modell, Beziehungen zwischen weit auseinanderliegenden Wörtern effektiver zu erfassen als RNNs oder LSTMs, und dies auf parallele Weise anstatt sequenziell. Dadurch wird nicht nur die Trainingseffizienz verbessert, sondern auch die Leistung bei Aufgaben wie der maschinellen Übersetzung.
🧩 Modellarchitektur
Der Transformer besteht aus zwei Hauptkomponenten: einem Encoder und einem Decoder, die beide aus mehreren Schichten bestehen und stark auf Multi-Head-Attention-Mechanismen angewiesen sind.
⚙️ Encoder
Der Encoder besteht aus sechs identischen Schichten, die jeweils zwei Unterschichten haben:
1. Multi-Head-Self-Attention
Dieser Mechanismus ermöglicht es dem Modell, sich beim Verarbeiten jedes Wortes auf verschiedene Teile des Eingangssatzes zu konzentrieren. Anstatt die Aufmerksamkeit in einem einzigen Raum zu berechnen, projiziert die Multi-Head-Attention die Eingabe in mehrere verschiedene Räume, wodurch verschiedene Arten von Beziehungen zwischen Wörtern erfasst werden können.
2. Positionsweise vollständig verbundene Feedforward-Netzwerke
Nach der Attention-Schicht wird ein vollständig verbundenes Feedforward-Netzwerk unabhängig an jeder Position angewendet. Dies hilft dem Modell, jedes Wort im Kontext zu verarbeiten und die Informationen aus dem Aufmerksamkeitsmechanismus zu nutzen.
Um die Struktur der Eingabesequenz zu bewahren, enthält das Modell auch Positionseingaben (Positional Encodings). Da der Transformer die Wörter nicht sequenziell verarbeitet, sind diese Encodings entscheidend, um dem Modell Informationen über die Reihenfolge der Wörter in einem Satz zu geben. Die Positionseingaben werden zu den Wort-Einbettungen hinzugefügt, sodass das Modell zwischen den verschiedenen Positionen in der Sequenz unterscheiden kann.
🔍 Decoder
Wie der Encoder besteht auch der Decoder aus sechs Schichten, wobei jede Schicht über einen zusätzlichen Aufmerksamkeitsmechanismus verfügt, der es dem Modell ermöglicht, sich auf relevante Teile der Eingabesequenz zu konzentrieren, während es die Ausgabe generiert. Der Decoder verwendet zudem eine Maskierungstechnik, um zu verhindern, dass er zukünftige Positionen berücksichtigt, was die autoregressive Natur der Sequenzgenerierung beibehält.
🧠 Multi-Head-Attention und Skalarprodukt-Attention
Das Herzstück des Transformers ist der Multi-Head-Attention-Mechanismus, der eine Erweiterung der einfacheren Skalarprodukt-Attention ist. Die Attention-Funktion kann als eine Abbildung zwischen einer Abfrage (Query) und einem Satz von Schlüssel-Wert-Paaren (Keys und Values) betrachtet werden, wobei jeder Schlüssel ein Wort in der Sequenz repräsentiert und der Wert die dazugehörige kontextuelle Information darstellt.
Der Multi-Head-Attention-Mechanismus ermöglicht es dem Modell, sich gleichzeitig auf verschiedene Teile der Sequenz zu konzentrieren. Durch die Projektion der Eingabe in mehrere Teilräume kann das Modell eine reichhaltigere Menge an Beziehungen zwischen Wörtern erfassen. Dies ist besonders nützlich bei Aufgaben wie der maschinellen Übersetzung, bei denen das Verständnis des Kontextes eines Wortes viele verschiedene Faktoren erfordert, wie zum Beispiel die syntaktische Struktur und die semantische Bedeutung.
Die Formel für die Skalarprodukt-Attention lautet:
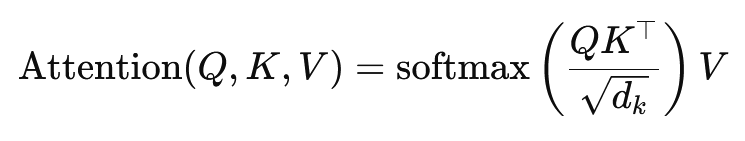
Hierbei ist (Q) die Abfragematrix, (K) die Schlüsselmatrix und (V) die Wertematrix. Der Term (sqrt{d_k}) ist ein Skalierungsfaktor, der verhindert, dass die Skalarprodukte zu groß werden, was zu sehr kleinen Gradienten und langsamerem Lernen führen würde. Die Softmax-Funktion wird angewendet, um sicherzustellen, dass die Aufmerksamkeitsgewichte eine Summe von eins ergeben.
🚀 Vorteile des Transformers
Der Transformer bietet gegenüber traditionellen Modellen wie RNNs und LSTMs mehrere entscheidende Vorteile:
1. Parallelisierung
Da der Transformer alle Tokens einer Sequenz gleichzeitig verarbeitet, lässt er sich stark parallelisieren und ist damit viel schneller zu trainieren als RNNs oder LSTMs, insbesondere bei großen Datensätzen.
2. Langfristige Abhängigkeiten
Der Self-Attention-Mechanismus ermöglicht es dem Modell, Beziehungen zwischen weit entfernten Wörtern effektiver zu erfassen als RNNs, die durch die sequenzielle Natur ihrer Berechnungen eingeschränkt sind.
3. Skalierbarkeit
Der Transformer kann problemlos auf sehr große Datensätze und längere Sequenzen skaliert werden, ohne unter den Leistungsengpässen zu leiden, die mit RNNs verbunden sind.
🌍 Anwendungen und Auswirkungen
Seit seiner Einführung ist der Transformer die Grundlage für eine breite Palette von NLP-Modellen geworden. Eines der bemerkenswertesten Beispiele ist BERT (Bidirectional Encoder Representations from Transformers), das eine modifizierte Transformer-Architektur verwendet, um in vielen NLP-Aufgaben, einschließlich Fragebeantwortung und Textklassifikation, den Stand der Technik zu erreichen.
Eine weitere bedeutende Entwicklung ist GPT (Generative Pretrained Transformer), das eine auf Decoder beschränkte Version des Transformers zur Textgenerierung verwendet. GPT-Modelle, einschließlich GPT-3, werden mittlerweile für zahlreiche Anwendungen genutzt, von der Inhaltserstellung bis hin zur Codevervollständigung.
🔍 Ein leistungsstarkes und flexibles Modell
Der Transformer hat die Art und Weise, wie wir NLP-Aufgaben angehen, grundlegend verändert. Er bietet ein leistungsstarkes und flexibles Modell, das auf eine Vielzahl von Problemen angewendet werden kann. Seine Fähigkeit, langfristige Abhängigkeiten zu behandeln, und seine Effizienz beim Training haben ihn zum bevorzugten Architekturansatz für viele der modernsten Modelle gemacht. Mit fortschreitender Forschung werden wir wahrscheinlich weitere Verbesserungen und Anpassungen des Transformers sehen, insbesondere in Bereichen wie Bild- und Sprachverarbeitung, wo Aufmerksamkeitsmechanismen vielversprechende Ergebnisse zeigen.
Wir sind für Sie da - Beratung - Planung - Umsetzung - Projektmanagement
☑️ Branchenexperte, hier mit einem eigenen Xpert.Digital Industrie-Hub von über 2.500 Fachbeiträgen

Konrad Wolfenstein
Gerne stehe ich Ihnen als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie unten das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 7348 4088 965 an.
Ich freue mich auf unser gemeinsames Projekt.
Schreiben Sie mir




Xpert.Digital - Konrad Wolfenstein
Xpert.Digital ist ein Hub für die Industrie mit den Schwerpunkten, Digitalisierung, Maschinenbau, Logistik/Intralogistik und Photovoltaik.
Mit unserer 360° Business Development Lösung unterstützen wir namhafte Unternehmen vom New Business bis After Sales.
Market Intelligence, Smarketing, Marketing Automation, Content Development, PR, Mail Campaigns, Personalized Social Media und Lead Nurturing sind ein Teil unserer digitalen Werkzeuge.
Mehr finden Sie unter: www.xpert.digital - www.xpert.solar - www.xpert.plus
In Kontakt bleiben











