
Опит за обяснение на изкуствения интелект: Как работи и функционира изкуственият интелект – как се обучава?

Available in 27 languages 📢
Предпочитайте Xpert.Digital в GoogleⓘПубликувано на: 8 септември 2024 г. / Актуализирано на: 9 септември 2024 г. – Автор: Konrad Wolfenstein

Опит за обяснение на изкуствения интелект: Как работи изкуственият интелект и как се обучава? – Изображение: Xpert.Digital
📊 От въвеждане на данни до прогнозиране на модела: Процесът на изкуствения интелект
Как работи изкуственият интелект (ИИ)? 🤖
Функционирането на изкуствения интелект (ИИ) може да бъде разделено на няколко ясно дефинирани стъпки. Всяка от тези стъпки е от решаващо значение за крайния резултат, постигнат от ИИ. Процесът започва с въвеждане на данни и завършва с прогнозиране на модела и евентуална обратна връзка или допълнителни обучителни кръгове. Тези фази описват процеса, през който преминават почти всички модели на ИИ, независимо дали са прости набори от правила или силно сложни невронни мрежи.
1. Въвеждането на данни 📊
Основата на всеки изкуствен интелект са данните, с които той работи. Тези данни могат да съществуват в различни форми, като изображения, текст, аудио файлове или видеоклипове. Изкуственият интелект използва тези сурови данни, за да разпознава модели и да взема решения. Качеството и количеството на данните играят решаваща роля тук, тъй като те значително влияят върху това колко добре или зле ще се представи моделът в крайна сметка.
Колкото по-изчерпателни и точни са данните, толкова по-добре може да учи ИИ. Например, когато се обучава ИИ за обработка на изображения, той се нуждае от голямо количество данни за изображения, за да идентифицира правилно различни обекти. При езиковите модели текстовите данни помагат на ИИ да разбира и генерира човешка реч. Въвеждането на данни е първата и една от най-важните стъпки, тъй като качеството на прогнозите може да бъде толкова добро, колкото и основните данни. Известен принцип в компютърните науки описва това с поговорката „боклук вътре, боклук навън“ – лошите данни водят до лоши резултати.
2. Предварителна обработка на данни 🧹
След като данните бъдат въведени, те трябва да бъдат подготвени, преди да могат да бъдат въведени в действителния модел. Този процес се нарича предварителна обработка на данни. Целта тук е данните да се трансформират във формат, който моделът може да обработи оптимално.
Често срещана стъпка в предварителната обработка е нормализирането на данните. Това означава привеждане на данните в еднакъв диапазон от стойности, така че те да бъдат третирани последователно от модела. Пример за това е мащабирането на всички стойности на пикселите на изображението до диапазон от 0 до 1, вместо от 0 до 255.
Друга важна част от предварителната обработка е извличането на характеристики. Това включва извличане на специфични характеристики от суровите данни, които са особено важни за модела. При обработката на изображения това могат да бъдат ръбове или специфични цветови модели, докато при обработката на текст се извличат подходящи ключови думи или изречения. Предварителната обработка е от решаващо значение за по-ефективен и прецизен процес на обучение на изкуствения интелект.
3. Моделът 🧩
Моделът е ядрото на всеки изкуствен интелект. Тук данните се анализират и обработват въз основа на алгоритми и математически изчисления. Моделът може да съществува в различни форми. Един от най-известните модели е невронната мрежа, която се основава на работата на човешкия мозък.
Невронните мрежи се състоят от множество слоеве изкуствени неврони, които обработват и предават информация. Всеки слой взема изходите от предишния слой и ги обработва допълнително. Процесът на обучение на невронната мрежа включва регулиране на теглата на връзките между тези неврони, така че мрежата да може да прави все по-точни прогнози или класификации. Това регулиране се постига чрез обучение, при което мрежата осъществява достъп до големи количества примерни данни и итеративно подобрява вътрешните си параметри (тегла).
Освен невронните мрежи, в моделите на изкуствен интелект се използват много други алгоритми. Те включват дървета на решенията, случайни гори, машини с опорни вектори и много други. Кой алгоритъм се използва зависи от конкретната задача и наличните данни.
4. Прогнозата на модела 🔍
След като моделът е обучен с данни, той е в състояние да прави прогнози. Тази стъпка се нарича прогнозиране на модела. Изкуственият интелект получава входни данни и въз основа на моделите, които е научил досега, връща изход, т.е. прогноза или решение.
Това предсказание може да приеме различни форми. В модел за класификация на изображения, например, изкуственият интелект може да предвиди кой обект е показан на снимка. В езиков модел може да предвиди коя дума ще дойде следващата в изречението. Във финансовите прогнози изкуственият интелект може да предвиди как ще се представи фондовият пазар.
Важно е да се подчертае, че точността на прогнозите зависи силно от качеството на обучителните данни и архитектурата на модела. Модел, обучен върху недостатъчни или пристрастни данни, е много вероятно да прави неправилни прогнози.
5. Обратна връзка и обучение (по избор) ♻️
Друг важен аспект от начина, по който работи изкуственият интелект, е механизмът за обратна връзка. Тук моделът редовно се проверява и допълнително оптимизира. Този процес се осъществява или по време на обучението, или след прогнозата на модела.
Ако моделът прави неправилни прогнози, той може да се научи чрез обратна връзка да разпознава тези грешки и съответно да коригира вътрешните си параметри. Това се прави чрез сравняване на прогнозите на модела с действителните резултати (например с известни данни, за които вече съществуват правилните отговори). Типичен метод в този контекст е така нареченото контролирано обучение, при което изкуственият интелект се учи от примерни данни, които вече съдържат правилните отговори.
Често срещан метод за обратна връзка е алгоритъмът за обратно разпространение (backpropagation), използван в невронните мрежи. При него грешките, направени от модела, се разпространяват назад през мрежата, за да се коригират теглата на невронните връзки. По този начин моделът се учи от грешките си и става все по-точен в своите прогнози.
Ролята на обучението 🏋️♂️
Обучението на изкуствен интелект е итеративен процес. Колкото повече данни вижда моделът и колкото по-често се обучава върху тези данни, толкова по-точни стават неговите прогнози. Има обаче ограничения: Преобученият модел може да развие така наречените проблеми с „преобучение“. Това означава, че той запомня обучителните данни толкова добре, че дава по-лоши резултати върху нови, непознати данни. Следователно е важно моделът да се обучава по такъв начин, че да може да обобщава, което означава, че може да прави добри прогнози и върху нови данни.
В допълнение към редовното обучение, съществуват и методи като трансферно обучение. При него модел, който вече е обучен върху голям набор от данни, се използва за нова, подобна задача. Това спестява време и изчислителна мощност, тъй като моделът не е необходимо да се обучава изцяло от нулата.
Възползвайте се максимално от силните си страни 🚀
Работата на изкуствения интелект (ИИ) се основава на сложно взаимодействие от различни стъпки. От въвеждането на данни и предварителната им обработка до обучението на модели, прогнозирането и обратната връзка, много фактори влияят върху точността и ефективността на ИИ. Добре обученият ИИ може да предложи огромни предимства в много области на живота – от автоматизиране на прости задачи до решаване на сложни проблеми. Също толкова важно е обаче да се разберат ограниченията и потенциалните капани на ИИ, за да се използват максимално неговите силни страни.
🤖📚 Просто обяснено: Как се обучава изкуствен интелект?
🤖📊 Процес на обучение с изкуствен интелект: Заснемане, свързване и съхранение
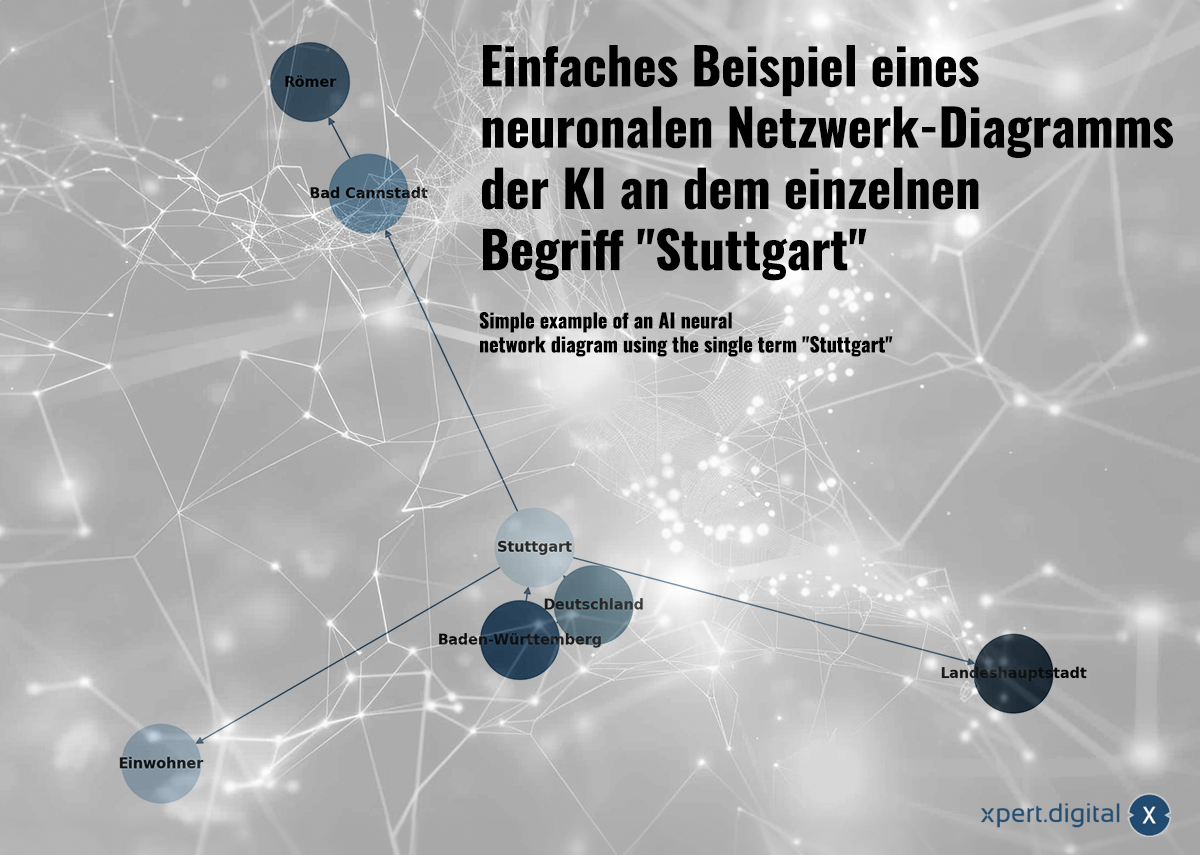
Прост пример за диаграма на невронна мрежа с изкуствен интелект, използваща единствения термин „Щутгарт“ – Изображение: Xpert.Digital
🌟 Събиране и подготовка на данни
Първата стъпка в процеса на обучение на изкуствения интелект е събирането и подготовката на данните. Тези данни могат да идват от различни източници, като бази данни, сензори, текстове или изображения.
🌟 Данни за взаимоотношения (невронна мрежа)
Събраните данни се свързват помежду си в невронна мрежа. Всеки пакет данни е представен от връзки в мрежа от „неврони“ (възли). Един прост пример, използващ град Щутгарт, може да изглежда така:
а) Щутгарт е град в Баден-Вюртемберг
б) Баден-Вюртемберг е федерална провинция в Германия
в) Щутгарт е град в Германия
г) Щутгарт е имал население от 633 484 души през 2023 г.
д) Бад Канщат е област на Щутгарт
е) Бад Канщат е основан от римляните
ж) Щутгарт е столица на провинция Баден-Вюртемберг
В зависимост от размера на обема данни, параметрите за потенциалните изходи се генерират с помощта на AI модела. Например, GPT-3 има приблизително 175 милиарда параметъра!
🌟 Запазване и персонализиране (обучение)
Данните се подават в невронната мрежа. Те преминават през AI модела и се обработват чрез връзки (подобно на синапсите). Теглата (параметрите) между невроните се коригират, за да се обучи моделът или да се изпълни задача.
За разлика от конвенционалните методи за съхранение, като директен достъп, индексиран достъп, последователно или пакетно съхранение, невронните мрежи съхраняват данни по нетрадиционен начин. „Данните“ се съхраняват в теглата и отклоненията на връзките между невроните.
Действителното „съхранение“ на информация в невронна мрежа се осъществява чрез регулиране на теглата на връзките между невроните. Моделът на изкуствения интелект „се учи“, като непрекъснато коригира тези тегла и отклонения въз основа на входните данни и дефиниран алгоритъм за обучение. Това е непрекъснат процес, при който моделът може да прави по-точни прогнози чрез многократни корекции.
Моделът на изкуствения интелект може да се разглежда като вид програмиране, тъй като се създава чрез дефинирани алгоритми и математически изчисления, а настройката на неговите параметри (тегла) се подобрява непрекъснато, за да се правят точни прогнози. Това е непрекъснат процес.
Отклоненията са допълнителни параметри в невронните мрежи, които се добавят към претеглените входни стойности на неврона. Те позволяват параметрите да бъдат претеглени (важни, по-маловажни и т.н.), което прави изкуствения интелект по-гъвкав и точен.
Невронните мрежи могат не само да съхраняват отделни факти, но и да разпознават връзки между данните чрез разпознаване на образи. Примерът със Щутгарт илюстрира как знанията могат да бъдат въведени в невронна мрежа, но невронните мрежи не учат чрез изрично знание (както в този прост пример), а по-скоро чрез анализ на модели на данни. Следователно, невронните мрежи могат не само да съхраняват отделни факти, но и да учат тегла и връзки между входните данни.
Този процес предоставя разбираемо въведение в това как работят изкуственият интелект и по-специално невронните мрежи, без да се навлиза твърде дълбоко в технически подробности. Той демонстрира, че информацията не се съхранява в невронните мрежи, както в конвенционалните бази данни, а по-скоро чрез настройване на връзките (теглата) в мрежата.
🤖📚 По-подробно: Как се обучава изкуствен интелект?
🏋️♂️ Обучението на изкуствен интелект, особено на модел за машинно обучение, включва няколко стъпки. Обучението на изкуствен интелект се основава на непрекъсната оптимизация на параметрите на модела чрез обратна връзка и корекция, докато моделът не се представи най-добре с предоставените данни. Ето подробно обяснение как работи този процес:
1. 📊 Събиране и подготовка на данни
Данните са основата на обучението на ИИ. Те обикновено се състоят от хиляди или милиони примери, които системата е предназначена да анализира. Примерите включват изображения, текст или данни от времеви серии.
Данните трябва да бъдат почистени и нормализирани, за да се избегнат ненужни източници на грешки. Често данните се трансформират във характеристики, които съдържат съответната информация.
2. 🔍 Дефинирайте модел
Моделът е математическа функция, която описва връзките в данните. В невронните мрежи, които често се използват за изкуствен интелект, моделът се състои от множество слоеве от неврони, които са свързани помежду си.
Всеки неврон извършва математическа операция за обработка на входните данни и след това предава сигнал на следващия неврон.
3. 🔄 Инициализирайте теглата
Връзките между невроните имат тегла, които първоначално се задават на случаен принцип. Тези тегла определят колко силно невронът реагира на сигнал.
Целта на обучението е да се коригират тези тегла, така че моделът да прави по-добри прогнози.
4. ➡️ Разпространение напред
По време на прехода напред, входните данни се обработват от модела, за да се получи прогноза.
Всеки слой обработва данните и ги предава на следващия слой, докато последният слой не предостави резултата.
5. ⚖️ Изчислете функцията на загубата
Функцията на загубата измерва доколко добре прогнозите на модела съвпадат с действителните стойности (етикетите). Често срещана мярка е грешката между прогнозирания и действителния отговор.
Колкото по-голяма е загубата, толкова по-лоша е прогнозата на модела.
6. 🔙 Обратно разпространение
При обратна итерация грешката се проследява от изхода на модела до предишните слоеве.
Грешката се преразпределя към теглата на връзките и моделът коригира теглата, така че грешките да станат по-малки.
Това се прави с помощта на градиентен спускащ метод: Изчислява се градиентният вектор, който показва как трябва да се променят теглата, за да се минимизира грешката.
7. 🔧 Актуализирайте теглата
След като грешката е изчислена, теглата на връзките се актуализират с малка корекция, базирана на скоростта на обучение.
Скоростта на обучение определя с колко се променят теглата на всяка стъпка. Твърде големите промени могат да направят модела нестабилен, докато твърде малките промени водят до бавен процес на обучение.
8. 🔁 Повторение (Епохи)
Този процес на предварително предаване, изчисляване на грешки и актуализиране на теглото се повтаря, често в продължение на няколко епохи (преминава през целия набор от данни), докато моделът постигне приемлива точност.
С всяка епоха моделът научава малко повече и допълнително коригира теглата си.
9. 📉 Валидиране и тестване
След като моделът е обучен, той се тества върху валидиран набор от данни, за да се провери колко добре обобщава. Това гарантира, че той не само е „запомнил“ данните за обучение, но и прави добри прогнози върху неизвестни данни.
Тестовите данни помагат да се измери крайната производителност на модела, преди той да бъде използван на практика.
10. 🚀 Оптимизация
Допълнителни стъпки за подобряване на модела включват настройване на хиперпараметри (напр. коригиране на скоростта на обучение или структурата на мрежата), регуларизация (за да се избегне пренареждане) или увеличаване на количеството данни.
📊🔙 Изкуствен интелект: Превръщане на черната кутия на изкуствения интелект в разбираема, разбираема и обяснима с помощта на обясним изкуствен интелект (XAI), топлинни карти, сурогатни модели или други решения

Изкуствен интелект: Да направим черната кутия на изкуствения интелект разбираема, разбираема и обяснима с обясним изкуствен интелект (XAI), топлинни карти, сурогатни модели или други решения – Изображение: Xpert.Digital
Така наречената „черна кутия“ на изкуствения интелект (ИИ) представлява сериозен и належащ проблем. Дори експертите често се сблъскват с предизвикателството да не могат напълно да разберат как системите с ИИ стигат до своите решения. Тази липса на прозрачност може да причини значителни проблеми, особено в критични области като икономика, политика и медицина. Лекар или терапевт, който разчита на система с ИИ за диагностика и препоръки за лечение, трябва да има доверие във взетите решения. Ако обаче процесът на вземане на решения от ИИ не е достатъчно прозрачен, възниква несигурност, която потенциално води до липса на доверие – и това в ситуации, в които човешки животи могат да бъдат застрашени.
Повече информация тук:
Тук сме за Вас - Консултации - Планиране - Внедряване - Управление на проекти
☑️ Подкрепа за МСП в стратегията, консултирането, планирането и внедряването
☑️ Създаване или пренасочване на дигиталната стратегия и дигитализация
☑️ Разширяване и оптимизиране на международните процеси на продажби
☑️ Глобални и дигитални B2B търговски платформи
☑️ Pioneer Business Development

Konrad Wolfenstein
С удоволствие бих служел като ваш личен съветник.
Можете да се свържете с мен, като попълните формата за контакт по-долу или просто ми се обадите на +49 89 89 674 804 (Мюнхен) .
Очаквам с нетърпение нашия съвместен проект.
Пиши ми

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital е индустриален център, фокусиран върху дигитализацията, машиностроенето, логистиката/интралогистиката и фотоволтаиката.
С нашето 360° решение за бизнес развитие, ние подкрепяме известни компании от нов бизнес до следпродажбено обслужване.
Пазарно разузнаване, маркетинг, маркетингова автоматизация, разработване на съдържание, PR, имейл кампании, персонализирани социални медии и подхранване на лийдове са част от нашите дигитални инструменти.
Можете да намерите повече информация на: www.xpert.digital - www.xpert.solar - www.xpert.plus
Поддържайте връзка


















