Die 57-Milliarden-Dollar-Fehlkalkulation – Ausgerechnet NVIDIA warnt: Die KI-Branche hat auf das falsche Pferd gesetzt – Bild: Xpert.Digital
Vergessen Sie die KI-Giganten: Warum die Zukunft klein, dezentral und viel billiger ist
### Small Language Models: Der Schlüssel zu echter Unternehmensautonomie ### Von Hyperscalern zurück zu den Anwendern: Machtwechsel in der KI-Welt ### Der 57-Milliarden-Dollar-Fehler: Warum die wahre KI-Revolution nicht in der Cloud stattfindet ### Die stille KI-Revolution: Dezentral statt zentral ### Tech-Giganten auf dem Holzweg: Die Zukunft der KI ist schlank und lokal ### Von Hyperscalern zurück zu den Anwendern: Machtwechsel in der KI-Welt ###
Milliarden-Fehlinvestition: Warum kleine KI-Modelle die Großen überholen
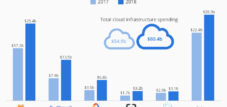
Die Welt der künstlichen Intelligenz steht vor einem Beben, das in seiner Tragweite an die Korrekturen der Dotcom-Ära erinnert. Im Zentrum dieser Erschütterung steht eine gigantische Fehlkalkulation: Während Tech-Giganten wie Microsoft, Google und Meta Hunderte von Milliarden in zentralisierte Infrastrukturen für riesige Sprachmodelle (Large Language Models, LLMs) investieren, bleibt der tatsächliche Markt für deren Anwendung dramatisch zurück. Eine aufsehenerregende Analyse, unter anderem vom Branchenprimus NVIDIA selbst, beziffert die Lücke auf 57 Milliarden Dollar an Infrastruktur-Investitionen gegenüber einem realen Markt von nur 5,6 Milliarden Dollar – eine Diskrepanz um den Faktor zehn.
Dieser strategische Irrtum wurzelt in der Annahme, die Zukunft der KI liege allein in immer größeren, rechenintensiveren und zentral gesteuerten Modellen. Doch nun bricht dieses Paradigma. Eine stille Revolution, angetrieben von dezentralisierten, kleineren Sprachmodellen (Small Language Models, SLMs), stellt die etablierte Ordnung auf den Kopf. Diese Modelle sind nicht nur um ein Vielfaches günstiger und effizienter, sondern ermöglichen Unternehmen auch eine neue Autonomie, Datensouveränität und Agilität – fernab der kostspieligen Abhängigkeit von wenigen Hyperscalern. Der vorliegende Text analysiert die Anatomie dieser milliardenschweren Fehlinvestition und zeigt auf, warum die wahre KI-Revolution nicht in gigantischen Rechenzentren, sondern dezentral und auf schlanker Hardware stattfindet. Es ist die Geschichte eines fundamentalen Machtwechsels von den Anbietern der Infrastruktur zurück zu den Anwendern der Technologie.
Passend dazu:


NVIDIA-Forschungsarbeit zur KI-Kapitalfehlallokation
Die von Ihnen beschriebenen Daten stammen aus einer NVIDIA-Forschungsarbeit, die im Juni 2025 veröffentlicht wurde. Die vollständige Quellenangabe lautet:
“Small Language Models are the Future of Agentic AI”
- Autoren: Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
- Veröffentlichung: 2. Juni 2025 (Version 1), letzte Überarbeitung 15. September 2025 (Version 2)
- Publikationsort: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- Offizielle NVIDIA Research Seite: https://research.nvidia.com/labs/lpr/slm-agents/
Die Kernaussage zur Kapitalfehlallokation
Die Forschungsarbeit dokumentiert eine fundamentale Diskrepanz zwischen Infrastrukturinvestitionen und tatsächlichem Marktvolumen: Im Jahr 2024 investierte die Industrie 57 Milliarden US-Dollar in Cloud-Infrastruktur zur Unterstützung von Large Language Model (LLM) API-Diensten, während der tatsächliche Markt für diese Dienste lediglich 5,6 Milliarden US-Dollar betrug. Diese Zehn-zu-Eins-Diskrepanz wird in der Studie als Hinweis auf eine strategische Fehleinschätzung interpretiert, da die Industrie massiv in zentralisierte Infrastruktur für großskalige Modelle investierte, obwohl 40-70% der aktuellen LLM-Arbeitslasten durch kleinere, spezialisierte Small Language Models (SLMs) ersetzt werden könnten – und das bei 1/30 der Kosten.
Forschungskontext und Autorenschaft
Die Studie ist eine Position Paper des Deep Learning Efficiency Research Group bei NVIDIA Research. Hauptautor Peter Belcak ist KI-Forscher bei NVIDIA mit Fokus auf die Zuverlässigkeit und Effizienz von agentischen Systemen. Die Arbeit argumentiert auf drei Säulen:
SLMs sind
- ausreichend leistungsfähig,
- operativ geeigneter und
- ökonomisch notwendiger
für viele Anwendungsfälle in agentischen KI-Systemen.
Die Forschenden betonen ausdrücklich, dass die in der Arbeit geäußerten Ansichten die der Autoren sind und nicht zwingend die Position von NVIDIA als Unternehmen widerspiegeln. NVIDIA lädt zur kritischen Diskussion ein und verpflichtet sich, entsprechende Korrespondenz auf der begleitenden Website zu veröffentlichen.
Warum dezentralisierte Small Language Models die zentralisierte Infrastruktur-Wette obsolet machen
Die künstliche Intelligenz steht an einem Wendepunkt, der in seiner Tragweite an die Umbrüche der Dotcom-Blase erinnert. NVIDIA hat in einer Forschungsarbeit eine fundamentale Fehlallokation von Kapital offengelegt, die das Fundament der bisherigen KI-Strategie erschüttert. Während die Technologiebranche 57 Milliarden Dollar in zentralisierte Infrastruktur für großskalige Sprachmodelle investierte, entwickelte sich der tatsächliche Markt für deren Nutzung auf lediglich 5,6 Milliarden Dollar. Diese Diskrepanz von zehn zu eins markiert nicht nur eine Überschätzung der Nachfrage, sondern offenbart einen grundlegenden strategischen Irrtum über die Zukunft der künstlichen Intelligenz.
Fehlinvestition? Milliarden in KI‑Infrastruktur — wohin mit der Überkapazität?
Die Zahlen sprechen eine unmissverständliche Sprache. Im Jahr 2024 erreichten die globalen Ausgaben für KI-Infrastruktur nach verschiedenen Analysen zwischen 80 und 87 Milliarden Dollar, wobei Rechenzentren und Beschleuniger den überwiegenden Anteil ausmachten. Microsoft kündigte für das Geschäftsjahr 2025 Investitionen von 80 Milliarden Dollar an, Google erhöhte seine Prognose auf 91 bis 93 Milliarden Dollar, Meta plant bis zu 70 Milliarden Dollar. Allein diese drei Hyperscaler repräsentieren ein Investitionsvolumen von über 240 Milliarden Dollar. Die Gesamtausgaben für KI-Infrastruktur könnten bis 2030 nach McKinsey-Schätzungen zwischen 3,7 und 7,9 Billionen Dollar erreichen.
Dem gegenüber steht eine ernüchternde Realität auf der Nachfrageseite. Der Markt für Enterprise Large Language Models wurde für 2024 auf lediglich 4 bis 6,7 Milliarden Dollar geschätzt, mit Projektionen für 2025 zwischen 4,8 und 8 Milliarden Dollar. Selbst großzügigste Schätzungen für den Generative AI Markt insgesamt liegen für 2024 bei 28 bis 44 Milliarden Dollar. Die fundamentale Diskrepanz wird deutlich: Die Infrastruktur wurde für einen Markt gebaut, der in dieser Form und diesem Umfang nicht existiert.
Diese Fehlinvestition wurzelt in einer Annahme, die sich zunehmend als falsch erweist: dass die Zukunft der KI in immer größeren, zentralisierten Modellen liegt. Die Hyperscaler setzten auf eine Strategie massiver Skalierung, getrieben von der Überzeugung, dass Parameterzahl und Rechenkapazität die entscheidenden Wettbewerbsfaktoren darstellen. GPT-3 mit 175 Milliarden Parametern galt 2020 als Durchbruch, GPT-4 setzte mit über einer Billion Parametern neue Maßstäbe. Die Branche folgte dieser Logik blind und investierte in eine Infrastruktur, die ausgelegt ist auf die Bedürfnisse von Modellen, die für die meisten Anwendungsfälle überdimensioniert sind.
Die Investitionsstruktur zeigt die Fehlallokation deutlich. Im zweiten Quartal 2025 entfielen 98 Prozent der 82 Milliarden Dollar AI-Infrastrukturausgaben auf Server, davon 91,8 Prozent auf GPU- und XPU-beschleunigte Systeme. Die Hyperscaler und Cloud-Builder absorbierten 86,7 Prozent dieser Ausgaben, etwa 71 Milliarden Dollar in einem einzigen Quartal. Diese Konzentration von Kapital in hochspezialisierte, extrem energieintensive Hardware für Training und Inferenz massiver Modelle ignorierte eine fundamentale ökonomische Realität: Die meisten Unternehmensanwendungen benötigen diese Kapazität nicht.
Das Paradigma bricht: Von zentralisiert zu dezentralisiert
NVIDIA selbst, Hauptnutznießer des bisherigen Infrastruktur-Booms, liefert nun die Analyse, die dieses Paradigma in Frage stellt. Die Forschungsarbeit zu Small Language Models als Zukunft der agentischen KI argumentiert, dass Modelle unter 10 Milliarden Parametern für die überwiegende Mehrheit der KI-Anwendungen nicht nur ausreichend, sondern operational überlegen sind. Die Untersuchung dreier großer Open-Source-Agentensysteme ergab, dass 40 bis 70 Prozent der Aufrufe an große Sprachmodelle durch spezialisierte kleine Modelle ersetzt werden könnten, ohne Leistungseinbußen.
Diese Erkenntnisse erschüttern die Grundannahmen der bisherigen Investitionsstrategie. Wenn MetaGPT 60 Prozent seiner LLM-Aufrufe, Open Operator 40 Prozent und Cradle 70 Prozent durch SLMs ersetzen kann, dann wurde Infrastrukturkapazität für Anforderungen aufgebaut, die in dieser Größenordnung nicht existieren. Die Wirtschaftlichkeit verschiebt sich dramatisch: Ein Llama 3.1B Small Language Model kostet im Betrieb zehn bis dreißig Mal weniger als sein größerer Verwandter Llama 3.3 405B. Fine-Tuning kann in wenigen GPU-Stunden statt in Wochen erfolgen. Viele SLMs laufen auf Consumer-Hardware, elimieren Cloud-Abhängigkeiten vollständig.
Der strategische Shift ist fundamental. Die Kontrolle verschiebt sich von den Infrastruktur-Anbietern zu den Betreibern. Während die bisherige Architektur Unternehmen in eine Position der Abhängigkeit von wenigen Hyperscalern zwang, ermöglicht die Dezentralisierung durch SLMs eine neue Autonomie. Modelle können lokal betrieben werden, Daten bleiben im Unternehmen, API-Kosten entfallen, Vendor Lock-in wird aufgebrochen. Dies ist nicht nur eine technologische, sondern eine machtpolitische Transformation.
Die bisherige Wette auf zentralisierte Großmodelle basierte auf der Annahme exponentieller Skalierungseffekte. Doch die empirischen Daten widersprechen zunehmend. Microsoft Phi-3 mit 7 Milliarden Parametern erreicht Code-Generierungsleistung vergleichbar mit 70-Milliarden-Parameter-Modellen. NVIDIA Nemotron Nano 2 mit 9 Milliarden Parametern übertrifft Qwen3-8B in Reasoning-Benchmarks bei sechsfach höherem Durchsatz. Die Effizienz pro Parameter steigt bei kleineren Modellen, während große Modelle oft nur einen Bruchteil ihrer Parameter für eine gegebene Eingabe aktivieren, eine inhärente Ineffizienz.
Die ökonomische Überlegenheit kleiner Sprachmodelle
Die Kostenstruktur offenbart die ökonomische Realität mit brutaler Klarheit. Training von GPT-4-Klasse-Modellen wird auf über 100 Millionen Dollar geschätzt, Gemini Ultra möglicherweise bei 191 Millionen Dollar. Selbst Fine-Tuning großer Modelle für spezifische Domänen kann Zehntausende Dollar an GPU-Zeit kosten. Dem gegenüber stehen SLMs, deren Training und Fine-Tuning mit wenigen Tausend Dollar möglich ist, oft auf einer einzigen High-End-GPU durchführbar.
Die Inferenzkosten zeigen noch drastischere Unterschiede. GPT-4 kostet etwa 0,03 Dollar pro 1000 Input-Tokens und 0,06 Dollar pro 1000 Output-Tokens, insgesamt 0,09 Dollar pro durchschnittlicher Anfrage. Mistral 7B als SLM-Beispiel liegt bei 0,0001 Dollar pro 1000 Input-Tokens und 0,0003 Dollar pro 1000 Output-Tokens, also 0,0004 Dollar pro Anfrage. Das entspricht einer Kostenreduktion um den Faktor 225. Bei Millionen von Anfragen summiert sich diese Differenz zu substantiellen Beträgen, die direkt die Profitabilität beeinflussen.
Die Total Cost of Ownership zeigt weitere Dimensionen. Self-Hosting eines 7-Milliarden-Parameter-Modells auf Bare-Metal-Servern mit L40S GPUs kostet etwa 953 Dollar monatlich. Cloud-basiertes Fine-Tuning mit AWS SageMaker auf g5.2xlarge Instanzen liegt bei 1,32 Dollar pro Stunde, mit potenziellen Trainingskosten ab 13 Dollar für kleinere Modelle. 24/7 Inferenz-Deployment würde etwa 950 Dollar monatlich kosten. Verglichen mit API-Kosten für ständige Nutzung großer Modelle, die leicht Zehntausende Dollar monatlich erreichen können, erschließt sich die wirtschaftliche Überlegenheit.
Die Geschwindigkeit der Implementierung stellt einen oft unterschätzten wirtschaftlichen Faktor dar. Während Fine-Tuning eines Large Language Models Wochen in Anspruch nehmen kann, sind SLMs in Stunden oder wenigen Tagen einsatzbereit. Die Agilität, schnell auf neue Anforderungen zu reagieren, neue Fähigkeiten hinzuzufügen oder Verhalten anzupassen, wird zum Wettbewerbsvorteil. In schnelllebigen Märkten kann diese Zeitdifferenz über Erfolg oder Misserfolg entscheiden.
Die Skalierungsökonomie kehrt sich um. Traditionell galten Größenvorteile als Argument für Hyperscaler, die enorme Kapazitäten vorhalten und über viele Kunden verteilen. Bei SLMs können jedoch auch kleinere Organisationen effizient skalieren, da die Hardware-Anforderungen drastisch geringer sind. Ein Startup kann mit begrenztem Budget ein spezialisiertes SLM aufbauen, das für seine spezifische Aufgabe ein großes generalistisches Modell übertrifft. Die Demokratisierung der KI-Entwicklung wird wirtschaftliche Realität.
Technische Fundamentaldaten der Disruption
Die technologischen Innovationen, die SLMs ermöglichen, sind ebenso bedeutsam wie ihre wirtschaftlichen Implikationen. Knowledge Distillation, eine Technik bei der ein kleineres Schülermodell das Wissen eines größeren Lehrermodells absorbiert, hat sich als hocheffektiv erwiesen. DistilBERT komprimierte BERT erfolgreich, TinyBERT folgte ähnlichen Prinzipien. Moderne Ansätze destillieren Capabilities von generativen Großmodellen wie GPT-3 in deutlich kleinere Versionen, die in spezifischen Aufgaben vergleichbare oder bessere Leistung zeigen.
Der Prozess nutzt sowohl die soft labels, also Wahrscheinlichkeitsverteilungen des Lehrermodells, als auch die hard labels der Originaldaten. Diese Kombination ermöglicht es dem kleineren Modell, nuancierte Muster zu erfassen, die in simplen Ein-Ausgabe-Paaren verloren gehen würden. Fortschrittliche Distillationsverfahren wie step-by-step distillation haben gezeigt, dass kleine Modelle sogar mit weniger Trainingsdaten bessere Ergebnisse als LLMs erzielen können. Dies verschiebt die Economics fundamental: Statt teurer, langer Trainingsläufe auf tausenden GPUs genügen gezielte Destillationsprozesse.
Quantisierung reduziert die Präzision der numerischen Darstellung von Modellgewichten. Statt 32-Bit oder 16-Bit Floating-Point-Zahlen verwenden quantisierte Modelle 8-Bit oder sogar 4-Bit Integer-Repräsentationen. Der Speicherbedarf sinkt proportional, die Inferenzgeschwindigkeit steigt, der Energieverbrauch fällt. Moderne Quantisierungstechniken minimieren den Genauigkeitsverlust, oft bleibt die Leistung praktisch unverändert. Dies ermöglicht Deployment auf Edge-Geräten, Smartphones und eingebetteten Systemen, die mit vollpräzisen großen Modellen unmöglich wären.
Pruning entfernt redundante Verbindungen und Parameter aus neuronalen Netzen. Wie das Editieren eines überlangen Textes, werden nicht-essentielle Elemente identifiziert und eliminiert. Strukturiertes Pruning entfernt ganze Neuronen oder Layer, unstrukturiertes Pruning einzelne Gewichte. Die resultierende Netzwerkstruktur ist effizienter, benötigt weniger Speicher und Rechenleistung, behält aber die Kernfähigkeiten. Kombiniert mit anderen Kompressionstechniken erreichen geprunte Modelle beeindruckende Effizienzgewinne.
Low-Rank Factorization zerlegt große Gewichtsmatrizen in Produkte kleinerer Matrizen. Statt einer Matrix mit Millionen Elementen speichert und prozessiert das System zwei deutlich kleinere Matrizen. Die mathematische Operation bleibt approximativ gleich, der Rechenaufwand sinkt dramatisch. Diese Technik ist besonders effektiv in Transformer-Architekturen, wo Attention-Mechanismen große Matrizenmultiplikationen dominieren. Die Speichereinsparungen erlauben größere Kontextfenster oder Batch-Größen bei gleichem Hardware-Budget.
Die Kombination dieser Techniken in modernen SLMs wie Microsoft Phi-Serie, Google Gemma oder NVIDIA Nemotron demonstriert das Potenzial. Phi-2 mit nur 2,7 Milliarden Parametern übertrifft Mistral und Llama-2 Modelle mit 7 und 13 Milliarden Parametern in aggregierten Benchmarks und erreicht bessere Leistung als das 25-mal größere Llama-2-70B in Multi-Step-Reasoning-Tasks. Dies wurde erreicht durch strategische Datenselektion, synthetische Datengenerierung hoher Qualität und innovative Skalierungstechniken. Die Botschaft ist klar: Größe ist kein Proxy für Fähigkeit mehr.
Marktdynamik und Substitutionspotenzial
Die empirischen Befunde aus real-world Anwendungen untermauern die theoretischen Überlegungen. NVIDIAs Analyse von MetaGPT, einem Multi-Agenten-Softwareentwicklungsframework, identifizierte dass etwa 60 Prozent der LLM-Anfragen ersetzbar sind. Die Aufgaben umfassen Boilerplate-Code-Generierung, Dokumentationserstellung und strukturierte Ausgaben, alles Bereiche, in denen spezialisierte SLMs schneller und günstiger arbeiten als universelle Großmodelle.
Open Operator, ein Workflow-Automatisierungssystem, zeigt mit 40 Prozent Substitutionspotenzial dass selbst in komplexen Orchestrierungsszenarien viele Teilaufgaben nicht die volle Kapazität von LLMs erfordern. Intent-Parsing, Template-basierte Ausgaben und Routing-Entscheidungen können von fein abgestimmten kleinen Modellen effizienter gehandhabt werden. Die verbleibenden 60 Prozent, die tatsächlich tiefes Reasoning oder breites Weltwissen erfordern, rechtfertigen den Einsatz großer Modelle.
Cradle, ein GUI-Automatisierungssystem, weist mit 70 Prozent das höchste Substitutionspotenzial auf. Repetitive UI-Interaktionen, Klick-Sequenzen und Formulareingaben sind prädestiniert für SLMs. Die Aufgaben sind eng definiert, die Variabilität begrenzt, die Anforderungen an kontextuelles Verständnis gering. Ein spezialisiertes Modell, trainiert auf GUI-Interaktionen, übertrifft ein generalistisches LLM in Geschwindigkeit, Zuverlässigkeit und Kosten.
Diese Muster wiederholen sich über Anwendungsbereiche hinweg. Customer Service Chatbots für FAQs, Dokumentenklassifikation, Sentiment-Analyse, Named Entity Recognition, einfache Übersetzungen, Datenbankabfragen in natürlicher Sprache – all diese Aufgaben profitieren von SLMs. Eine Studie schätzt, dass in typischen Enterprise-KI-Deployments 60 bis 80 Prozent der Anfragen in Kategorien fallen, für die SLMs ausreichend sind. Die Implikationen für die Infrastruktur-Nachfrage sind gravierend.
Das Konzept des Model Routing gewinnt an Bedeutung. Intelligente Systeme analysieren eingehende Anfragen und routen sie zum passenden Modell. Simple Queries gehen an kostengünstige SLMs, komplexe Aufgaben an leistungsfähige LLMs. Dieser hybride Ansatz optimiert die Balance zwischen Qualität und Kosten. Frühe Implementierungen berichten von Kosteneinsparungen bis zu 75 Prozent bei gleichbleibender oder besserer Gesamt-Performance. Die Routing-Logik selbst kann ein kleines Machine-Learning-Modell sein, das Query-Komplexität, Kontext und Nutzer-Präferenzen berücksichtigt.
Die Verbreitung von fine-tuning-as-a-service Plattformen beschleunigt die Adoption. Unternehmen ohne tiefe ML-Expertise können spezialisierte SLMs erstellen, die ihre proprietären Daten und Domain-Spezifika inkorporieren. Die Zeitinvestition beträgt Tage statt Monate, die Kosten Tausende statt Hunderttausende Dollar. Diese Zugänglichkeit demokratisiert KI-Innovation fundamental und verschiebt Wertschöpfung von Infrastruktur-Providern zu Anwendungsentwicklern.
Neue Dimension der digitalen Transformation mit der 'Managed KI' (Künstliche Intelligenz) - Plattform & B2B Lösung | Xpert Beratung

Neue Dimension der digitalen Transformation mit der 'Managed KI' (Künstliche Intelligenz) – Plattform & B2B Lösung | Xpert Beratung - Bild: Xpert.Digital
Hier erfahren Sie, wie Ihr Unternehmen maßgeschneiderte KI-Lösungen schnell, sicher und ohne hohe Einstiegshürden realisieren kann.
Eine Managed AI Platform ist Ihr Rundum-Sorglos-Paket für künstliche Intelligenz. Anstatt sich mit komplexer Technik, teurer Infrastruktur und langwierigen Entwicklungsprozessen zu befassen, erhalten Sie von einem spezialisierten Partner eine fertige, auf Ihre Bedürfnisse zugeschnittene Lösung – oft innerhalb weniger Tage.
Die zentralen Vorteile auf einen Blick:
⚡ Schnelle Umsetzung: Von der Idee zur einsatzbereiten Anwendung in Tagen, nicht Monaten. Wir liefern praxisnahe Lösungen, die sofort Mehrwert schaffen.
🔒 Maximale Datensicherheit: Ihre sensiblen Daten bleiben bei Ihnen. Wir garantieren eine sichere und konforme Verarbeitung ohne Datenweitergabe an Dritte.
💸 Kein finanzielles Risiko: Sie zahlen nur für Ergebnisse. Hohe Vorabinvestitionen in Hardware, Software oder Personal entfallen komplett.
🎯 Fokus auf Ihr Kerngeschäft: Konzentrieren Sie sich auf das, was Sie am besten können. Wir übernehmen die gesamte technische Umsetzung, den Betrieb und die Wartung Ihrer KI-Lösung.
📈 Zukunftssicher & Skalierbar: Ihre KI wächst mit Ihnen. Wir sorgen für die laufende Optimierung, Skalierbarkeit und passen die Modelle flexibel an neue Anforderungen an.
Mehr dazu hier:
Wie dezentrale KI Unternehmen Milliarden an Kosten spart
Die verborgenen Kosten zentralisierter Architekturen
Die Fokussierung auf direkte Compute-Kosten unterschätzt die Gesamtkosten zentralisierter LLM-Architekturen. API-Abhängigkeiten schaffen strukturelle Nachteile. Jede Anfrage generiert Kosten, die mit Nutzung skalieren. Bei erfolgreichen Anwendungen mit Millionen Nutzern werden API-Gebühren zum dominierenden Kostenfaktor, der die Marge erodiert. Unternehmen sind gefangen in einer Kostenstruktur, die proportional zum Erfolg wächst, ohne entsprechende Größenvorteile.
Die Pricing-Volatilität von API-Anbietern stellt ein Geschäftsrisiko dar. Preiserhöhungen, Quotenlimitierungen oder Änderungen der Nutzungsbedingungen können über Nacht die Wirtschaftlichkeit einer Anwendung zerstören. Die kürzlich angekündigten Kapazitätsbeschränkungen großer Anbieter, die Nutzer zur Rationierung zwingen, illustrieren die Verwundbarkeit dieser Abhängigkeit. Eigene SLMs eliminieren dieses Risiko vollständig.
Datensouveränität und Compliance gewinnen an Bedeutung. GDPR in Europa, vergleichbare Regulierungen weltweit und zunehmende Datenlokalisierungsanforderungen schaffen komplexe rechtliche Rahmenbedingungen. Das Senden sensibler Unternehmensdaten an externe APIs, die möglicherweise in fremden Jurisdiktionen operieren, birgt regulatorische und rechtliche Risiken. Healthcare, Finance und Government Sektor haben oft strikte Anforderungen, die externe API-Nutzung ausschließen oder stark einschränken. On-Premise SLMs lösen diese Probleme grundsätzlich.
Intellectual Property Bedenken sind real. Jede an einen API-Anbieter gesendete Anfrage gibt potenziell proprietäre Information preis. Geschäftslogik, Produktentwicklungen, Kundeninformationen – all dies könnte theoretisch vom Anbieter extrahiert und genutzt werden. Vertragsklauseln bieten begrenzten Schutz gegen versehentliche Leaks oder böswillige Akteure. Die einzige sichere Lösung ist, Daten nie zu externalisieren.
Latenz und Zuverlässigkeit leiden unter Netzwerkabhängigkeiten. Jede Cloud-API-Anfrage durchläuft Internet-Infrastruktur, unterliegt Netzwerk-Jitter, Packet Loss und variablen Round-Trip-Zeiten. Für Echtzeitanwendungen wie Konversations-KI oder Steuerungssysteme sind diese Verzögerungen inakzeptabel. Lokale SLMs antworten in Millisekunden statt Sekunden, unabhängig von Netzwerkbedingungen. Die User Experience verbessert sich qualitativ.
Die strategische Abhängigkeit von wenigen Hyperscalern konzentriert Macht und schafft systemische Risiken. AWS, Microsoft Azure, Google Cloud und einige weitere dominieren den Markt. Ausfälle dieser Dienste haben kaskadierende Effekte über tausende abhängige Anwendungen. Die Illusion von Redundanz verschwindet, wenn man bedenkt, dass die meisten alternativen Services letztlich auf derselben begrenzten Menge an Modell-Anbietern zurückgreifen. Echte Resilienz erfordert Diversifikation, idealerweise inklusive eigener Kapazitäten.
Passend dazu:

Edge Computing als strategischer Wendepunkt
Die Konvergenz von SLMs und Edge Computing schafft eine transformative Dynamik. Edge-Deployment bringt Berechnung dorthin, wo Daten entstehen – IoT-Sensoren, mobile Geräte, industrielle Steuerungen, Fahrzeuge. Die Latenzreduktion ist dramatisch: Von Sekunden auf Millisekunden, von Cloud-Roundtrip zu lokaler Verarbeitung. Für autonome Systeme, Augmented Reality, industrielle Automation und medizinische Geräte ist dies nicht nur wünschenswert, sondern notwendig.
Die Bandbreiteneinsparungen sind substantiell. Statt kontinuierlicher Datenströme in die Cloud, wo sie verarbeitet und Ergebnisse zurückgesendet werden, erfolgt Verarbeitung lokal. Nur relevante, aggregierte Information wird übertragen. In Szenarien mit tausenden Edge-Geräten reduziert dies Netzwerk-Traffic um Größenordnungen. Die Infrastruktur-Kosten sinken, Netzwerküberlastung wird vermieden, Ausfallsicherheit steigt.
Die Privatsphäre wird inhärent geschützt. Daten verlassen das Gerät nicht mehr. Kamera-Feeds, Audio-Aufnahmen, biometrische Informationen, Standortdaten – all dies kann lokal verarbeitet werden, ohne zentrale Server zu erreichen. Dies löst fundamentale Privacy-Bedenken, die Cloud-basierte KI-Lösungen aufwerfen. Für Consumer-Anwendungen wird dies zum Differenzierungsmerkmal, für regulierte Industrien zur Voraussetzung.
Die Energieeffizienz verbessert sich auf mehreren Ebenen. Spezialisierte Edge-AI-Chips, optimiert für Inferenz kleiner Modelle, verbrauchen einen Bruchteil der Energie von Datacenter-GPUs. Die Elimination von Datenübertragung spart Energie in Netzwerkinfrastruktur. Für batteriebetriebene Geräte wird dies zur Kernfunktion. Smartphones, Wearables, Drohnen und IoT-Sensoren können KI-Funktionen ausführen, ohne Akkulaufzeit dramatisch zu beeinträchtigen.
Die Offline-Fähigkeit schafft Robustheit. Edge-AI funktioniert auch ohne Internetverbindung. In abgelegenen Regionen, kritischen Infrastrukturen oder Katastrophenszenarien bleibt Funktionalität erhalten. Diese Unabhängigkeit von Netzwerkverfügbarkeit ist für viele Anwendungen essentiell. Ein autonomes Fahrzeug kann nicht auf Cloud-Connectivity angewiesen sein, ein medizinisches Gerät darf nicht ausfallen, weil WLAN instabil ist.
Kostenmodelle verschieben sich von Operational zu Capital Expenditure. Statt kontinuierlicher Cloud-Kosten eine einmalige Investition in Edge-Hardware. Für Anwendungen mit langer Lebensdauer und hohem Volumen wird dies wirtschaftlich attraktiv. Die Predictability von Kosten verbessert Budgetplanung und reduziert finanzielle Risiken. Unternehmen gewinnen Kontrolle über ihre KI-Infrastruktur-Ausgaben zurück.
Beispiele demonstrieren das Potenzial. NVIDIA ChatRTX ermöglicht lokale LLM-Inferenz auf Consumer-GPUs. Apple integriert on-device KI in iPhones und iPads, wobei kleinere Modelle direkt auf dem Gerät laufen. Qualcomm entwickelt NPUs für Smartphones speziell für Edge-AI. Google Coral und ähnliche Plattformen zielen auf IoT und industrielle Anwendungen. Die Marktdynamik zeigt klaren Trend zu Dezentralisierung.
Heterogene KI-Architekturen als Zukunftsmodell
Die Zukunft liegt nicht in absoluter Dezentralisierung, sondern in intelligenten hybriden Architekturen. Heterogene Systeme kombinieren Edge-SLMs für routinemäßige, latenz-sensitive Aufgaben mit Cloud-LLMs für komplexe Reasoning-Anforderungen. Diese Komplementarität maximiert Effizienz bei gleichzeitiger Bewahrung von Flexibilität und Capability.
Die Systemarchitektur umfasst mehrere Schichten. Auf Edge-Ebene laufen hoch-optimierte SLMs für unmittelbare Antworten. Diese handlen voraussichtlich 60 bis 80 Prozent der Anfragen selbstständig. Für ambigue oder komplexe Queries, die lokale Konfidenzthresholds nicht erreichen, erfolgt Eskalation an Fog-Computing-Layer – regionale Server mit mittleren Modellen. Nur wirklich schwierige Fälle erreichen zentrale Cloud-Infrastruktur mit großen generalistischen Modellen.
Das Model Routing wird zur kritischen Komponente. Machine-Learning-basierte Router analysieren Anfrage-Charakteristika: Textlänge, Komplexitätsindikatoren, Domain-Signale, Nutzer-Historie. Basierend auf diesen Features wird die Anfrage dem passenden Modell zugewiesen. Moderne Router erreichen 95+ Prozent Genauigkeit in der Komplexitätsschätzung. Sie optimieren kontinuierlich basierend auf tatsächlicher Performance und Cost-Quality-Tradeoffs.
Cross-Attention-Mechanismen in fortgeschrittenen Routing-Systemen modellieren Query-Model-Interaktionen explizit. Dies ermöglicht nuancierte Entscheidungen: Ist Mistral-7B ausreichend oder wird GPT-4 benötigt? Kann Phi-3 dies handlen oder braucht es Claude? Die Feinkörnigkeit dieser Entscheidungen, multipliziert über Millionen Anfragen, generiert substantielle Kosteneinsparungen bei gleichbleibender oder verbesserter Nutzer-Satisfaction.
Die Workload-Charakterisierung ist fundamental. Agentic AI Systeme bestehen aus Orchestrierung, Reasoning, Tool Calls, Memory Operations und Output-Generierung. Nicht alle Komponenten benötigen gleiche Compute-Kapazität. Orchestrierung und Tool Calls sind oft regelbasiert oder benötigen minimale Intelligenz – prädestiniert für SLMs. Reasoning kann hybrid erfolgen: Simple Inferenz auf SLMs, komplexe Multi-Step-Reasoning auf LLMs. Output-Generierung für Templates nutzt SLMs, kreative Textgenerierung LLMs.
Die Total Cost of Ownership Optimierung berücksichtigt Hardware-Heterogenität. High-End H100 GPUs für kritische LLM-Workloads, Mid-Tier A100 oder L40S für mittelgroße Modelle, kosteneffiziente T4 oder Inferenz-optimierte Chips für SLMs. Die Granularität erlaubt Präzisions-Matching von Workload-Anforderungen zu Hardware-Capabilities. Erste Studien zeigen 40 bis 60 Prozent TCO-Reduktion gegenüber homogenen High-End-Deployments.
Die Orchestrierung erfordert sophistizierte Software-Stacks. Kubernetes-basierte Cluster-Management-Systeme, ergänzt durch AI-spezifische Scheduler, die Modell-Charakteristika verstehen. Load-Balancing berücksichtigt nicht nur Anfragen-pro-Sekunde, sondern auch Token-Längen, Modell-Memory-Footprints und Latenzziele. Autoscaling reagiert auf Demand-Patterns, provisioned zusätzliche Kapazität oder scaled down bei niedriger Auslastung.
Nachhaltigkeit und Energieeffizienz
Die Umweltauswirkungen der KI-Infrastruktur werden zum zentralen Thema. Training eines einzigen großen Sprachmodells kann so viel Energie verbrauchen wie eine Kleinstadt in einem Jahr. Die Rechenzentren, die KI-Workloads ausführen, könnten bis 2028 20 bis 27 Prozent des globalen Rechenzentrum-Energiebedarfs ausmachen. Projektionen schätzen, dass bis 2030 KI-Datacenter 8 Gigawatt für einzelne Trainingsläufe benötigen könnten. Der Carbon-Footprint wird vergleichbar mit der Luftfahrtindustrie.
Die Energieintensität großer Modelle steigt überproportional. GPU-Leistungsaufnahme verdoppelte sich von 400 auf über 1000 Watt in drei Jahren. NVIDIA GB300 NVL72 Systeme, trotz innovativer Power-Smoothing-Technologie, die Spitzenlast um 30 Prozent reduziert, benötigen enorme Energiemengen. Die Kühlinfrastruktur addiert weitere 30 bis 40 Prozent zum Energiebedarf. Die gesamte CO2-Emission von KI-Infrastruktur könnte um 220 Millionen Tonnen bis 2030 steigen, selbst mit optimistischen Annahmen über Grid-Dekarbonisierung.
Small Language Models bieten fundamentale Effizienzgewinne. Training benötigt 30 bis 40 Prozent der Rechenleistung vergleichbarer LLMs. Ein BERT-Training kostet etwa 10.000 Euro, verglichen mit hunderten Millionen für GPT-4-Klasse-Modelle. Die Inferenz-Energie ist proportional geringer. Ein SLM-Query kann 100 bis 1000 Mal weniger Energie verbrauchen als ein LLM-Query. Über Millionen Anfragen summiert sich dies zu gigantischen Einsparungen.
Edge Computing potenziert diese Vorteile. Lokale Verarbeitung eliminiert Energie für Datenübertragung über Netzwerke und Backbone-Infrastruktur. Spezialisierte Edge-AI-Chips erreichen Energie-Effizienz-Faktoren um Größenordnungen besser als Datacenter-GPUs. Smartphones und IoT-Devices mit milli-Watt NPUs statt hunderte-Watt Server illustrieren die Skalendifferenz.
Die Nutzung erneuerbarer Energien wird zur Priorität. Google verpflichtet sich zu 100 Prozent CO2-freier Energie bis 2030, Microsoft zu Carbon-Negativität. Doch die schiere Größenordnung des Energiebedarfs stellt Herausforderungen dar. Selbst mit erneuerbaren Quellen bleibt die Frage der Grid-Kapazität, Speicherung und Intermittenz. SLMs reduzieren den absoluten Bedarf, machen die Transition zu grüner AI praktikabler.
Carbon-Aware Computing optimiert Workload-Scheduling basierend auf Grid-Carbon-Intensität. Trainingsläufe werden zu Zeiten gestartet, wenn der Anteil erneuerbarer Energie im Grid maximal ist. Inferenz-Requests werden zu Regionen mit cleaner Energy geroutet. Diese zeitliche und geografische Flexibilität, kombiniert mit der Effizienz von SLMs, könnte CO2-Emissionen um 50 bis 70 Prozent reduzieren.
Die regulatorische Landschaft verschärft sich. Der EU AI Act inkludiert verpflichtende Umweltfolgeabschätzungen für bestimmte KI-Systeme. Carbon-Reporting wird Standard. Unternehmen mit ineffizienten, energie-intensiven Infrastrukturen riskieren Compliance-Probleme und Reputationsschäden. Die Adoption von SLMs und Edge-Computing wird von Nice-to-have zu Necessity.
Demokratisierung versus Konzentration
Die bisherige Entwicklung konzentrierte KI-Macht bei wenigen Akteuren. Die Magnificent Seven – Microsoft, Google, Meta, Amazon, Apple, NVIDIA, Tesla – dominieren. Diese Hyperscaler kontrollieren Infrastruktur, Modelle und zunehmend die gesamte Wertschöpfungskette. Ihre kombinierte Marktkapitalisierung übersteigt 15 Billionen Dollar. Sie repräsentieren fast 35 Prozent der S&P 500 Marktkapitalisierung, ein historisch beispielloses Konzentrationsrisiko.
Diese Konzentration hat systemische Implikationen. Wenige Unternehmen setzen Standards, definieren APIs, kontrollieren Zugang. Kleinere Akteure und Entwicklungsländer werden abhängig. Die Digitale Souveränität von Nationen wird herausgefordert. Europa, Asien, Lateinamerika reagieren mit nationalen KI-Strategien, doch die Dominanz US-basierter Hyperscaler bleibt überwältigend.
Small Language Models und Dezentralisierung verschieben diese Dynamik. Open-Source-SLMs wie Phi-3, Gemma, Mistral, Llama demokratisieren Zugang zu State-of-the-Art-Technologie. Universitäten, Startups, Mittelständler können competitive Anwendungen entwickeln ohne Hyperscaler-Ressourcen. Die Innovationsbarriere senkt sich dramatisch. Ein kleines Team kann ein spezialisiertes SLM erstellen, das in seiner Nische Google oder Microsoft übertrifft.
Die Wirtschaftlichkeit verschiebt sich zu Gunsten kleinerer Akteure. Während LLM-Entwicklung Budgets von hunderten Millionen erfordert, sind SLMs mit fünf- bis sechsstelligen Beträgen machbar. Cloud-demokratisierung ermöglicht Zugang zu Training-Infrastruktur on-demand. Fine-Tuning-Services abstrahieren Komplexität. Die Eintrittsbarriere zur KI-Innovation sinkt von prohibitiv zu handhabbar.
Die Datensouveränität wird realisierbar. Unternehmen und Regierungen können Modelle hosten, die niemals externe Server erreichen. Sensitive Daten bleiben unter eigener Kontrolle. GDPR-Compliance wird vereinfacht. Der EU AI Act, der strenge Anforderungen an Transparenz und Accountability stellt, wird handhabbarer mit eigenen Modellen statt Black-Box-APIs.
Die Innovationsdiversität steigt. Statt Monokultur von GPT-ähnlichen Modellen entstehen tausende spezialisierte SLMs für spezifische Domänen, Sprachen, Tasks. Diese Vielfalt ist robust gegen systematische Fehler, erhöht Wettbewerb, beschleunigt Fortschritt. Die Innovationslandschaft wird polyzentrisch statt hierarchisch.
Die Risiken der Konzentration werden evident. Die Abhängigkeit von wenigen Anbietern schafft Single Points of Failure. Ausfälle bei AWS oder Azure lähmen globale Services. Politische Entscheidungen eines Hyperscalers, etwa Nutzungsbeschränkungen oder Regionen-Lockouts, haben kaskadierende Effekte. Die Dezentralisierung durch SLMs reduziert diese systemischen Risiken fundamental.
Die strategische Neuausrichtung
Für Unternehmen impliziert diese Analyse grundlegende strategische Anpassungen. Die Investitionspriorität verschiebt sich von zentraler Cloud-Infrastruktur zu heterogenen, verteilten Architekturen. Statt maximaler Abhängigkeit von Hyperscaler-APIs wird Autonomie durch eigene SLMs zum Ziel. Die Kompetenzentwicklung fokussiert auf Model Fine-Tuning, Edge-Deployment und hybride Orchestrierung.
Die Build-versus-Buy-Entscheidung kippt. Während zuvor kauf von API-Zugang als rational galt, wird Eigenentwicklung spezialisierter SLMs zunehmend attraktiv. Die Total Cost of Ownership über drei bis fünf Jahre favorisiert eigene Modelle deutlich. Die strategische Kontrolle, Datensicherheit und Anpassungsfähigkeit addieren qualitative Vorteile.
Für Investoren signalisiert die Fehlallokation Vorsicht gegenüber reiner Infrastruktur-Plays. Datacenter-REITs, GPU-Hersteller und Hyperscaler könnten Überkapazitäten und sinkende Auslastung erleben, wenn Nachfrage nicht materialisiert wie prognostiziert. Die Value Migration geschieht zu Anbietern von SLM-Technologie, Edge-AI-Chips, Orchestrierungssoftware und spezialisierten KI-Anwendungen.
Die geopolitische Dimension ist bedeutsam. Länder, die auf nationale KI-Souveränität setzen, profitieren von der SLM-Wende. China investiert 138 Milliarden Dollar in heimische Technologie, Europa 200 Milliarden in InvestAI. Diese Investments werden effektiver, wenn nicht mehr absolute Scale entscheidend ist, sondern smarte, effiziente, spezialisierte Lösungen. Die multipolare KI-Welt wird Realität.
Die regulatorischen Rahmenbedingungen entwickeln sich parallel. Datenschutz, Algorithmic Accountability, Environmental Standards – all dies favorisiert dezentralisierte, transparente, effiziente Systeme. Unternehmen, die frühzeitig auf SLMs und Edge-Computing setzen, positionieren sich compliance-positiv für kommende Regulierungen.
Die Talentlandschaft transformiert sich. Während zuvor nur Eliteuniversitäten und Top-Tech-Firmen Ressourcen für LLM-Forschung hatten, kann jetzt praktisch jede Organisation SLMs entwickeln. Der Fachkräftemangel, der 87 Prozent der Organisationen bei KI-Einstellungen behindert, wird durch niedrigere Komplexität und bessere Tools gemildert. Produktivitätssteigerungen durch AI-unterstützte Entwicklung potenzieren diesen Effekt.
Die Messung des ROI von KI-Investitionen verschiebt sich. Statt Fokus auf Raw Compute Capacity wird Effizienz pro Task zur Kernmetrik. Enterprises berichten 5,9 Prozent durchschnittlichen ROI auf AI-Initiativen, deutlich unter Erwartungen. Die Ursache liegt oft in der Verwendung überdimensionierter, teurer Lösungen für einfache Probleme. Der Shift zu task-optimierten SLMs kann diesen ROI dramatisch verbessern.
Die Analyse zeigt eine Branche an einem Wendepunkt. Die 57-Milliarden-Dollar-Fehlinvestition ist mehr als eine Überschätzung der Nachfrage. Sie repräsentiert einen fundamentalen strategischen Irrtum über die Architektur künstlicher Intelligenz. Die Zukunft gehört nicht zentralisierten Giganten, sondern dezentralen, spezialisierten, effizienten Systemen. Small Language Models sind nicht inferior gegenüber Large Language Models – sie sind für die überwiegende Mehrheit realer Anwendungen überlegen. Die ökonomischen, technischen, ökologischen und strategischen Argumente konvergieren zu einem klaren Befund: Die KI-Revolution wird dezentralisiert sein.
Die Machtverschiebung von Anbietern zu Betreibern, von Hyperscalern zu Anwendungsentwicklern, von Zentralisierung zu Distribution markiert eine neue Phase der KI-Evolution. Diejenigen, die diese Transition frühzeitig erkennen und vollziehen, werden die Gewinner sein. Diejenigen, die an der alten Logik festhalten, riskieren, dass ihre teuren Infrastrukturen zu Stranded Assets werden, überholt von agileren, effizienteren Alternativen. Die 57 Milliarden Dollar sind nicht nur verschwendet – sie markieren den Anfang vom Ende eines Paradigmas, das schon jetzt obsolet ist.
Ihr globaler Marketing und Business Development Partner
☑️ Unsere Geschäftssprache ist Englisch oder Deutsch
☑️ NEU: Schriftverkehr in Ihrer Landessprache!

Konrad Wolfenstein
Gerne stehe ich Ihnen und mein Team als persönlicher Berater zur Verfügung.
Sie können mit mir Kontakt aufnehmen, indem Sie hier das Kontaktformular ausfüllen oder rufen Sie mich einfach unter +49 7348 4088 965 an. Meine E-Mail Adresse lautet: wolfenstein∂xpert.digital
Ich freue mich auf unser gemeinsames Projekt.
☑️ KMU Support in der Strategie, Beratung, Planung und Umsetzung
☑️ Erstellung oder Neuausrichtung der Digitalstrategie und Digitalisierung
☑️ Ausbau und Optimierung der internationalen Vertriebsprozesse
☑️ Globale & Digitale B2B-Handelsplattformen
☑️ Pioneer Business Development / Marketing / PR / Messen
🎯🎯🎯 Profitieren Sie von der umfangreichen, fünffachen Expertise von Xpert.Digital in einem umfassenden Servicepaket | BD, R&D, XR, PR & Digitale Sichtbarkeitsoptimierung

Profitieren Sie von der umfangreichen, fünffachen Expertise von Xpert.Digital in einem umfassenden Servicepaket | R&D, XR, PR & Digitale Sichtbarkeitsoptimierung - Bild: Xpert.Digital
Xpert.Digital verfügt über tiefgehendes Wissen in verschiedenen Branchen. Dies erlaubt es uns, maßgeschneiderte Strategien zu entwickeln, die exakt auf die Anforderungen und Herausforderungen Ihres spezifischen Marktsegments zugeschnitten sind. Indem wir kontinuierlich Markttrends analysieren und Branchenentwicklungen verfolgen, können wir vorausschauend agieren und innovative Lösungen anbieten. Durch die Kombination aus Erfahrung und Wissen generieren wir einen Mehrwert und verschaffen unseren Kunden einen entscheidenden Wettbewerbsvorteil.
Mehr dazu hier: