


الذكاء الاصطناعي وتحسين محركات البحث باستخدام BERT - تمثيلات المشفر ثنائي الاتجاه من المحولات - نموذج في مجال معالجة اللغة الطبيعية (NLP) - الصورة: Xpert.Digital
🚀💬 من تطوير جوجل: BERT وأهميته في معالجة اللغات الطبيعية - لماذا يُعدّ فهم النصوص ثنائي الاتجاه أمرًا بالغ الأهمية
🔍🗣️ يُعدّ BERT، اختصارًا لـ Bidirectional Encoder Representations from Transformers (تمثيلات المشفر ثنائي الاتجاه من المحولات)، نموذجًا هامًا في مجال معالجة اللغات الطبيعية (NLP) طوّرته جوجل. وقد أحدث ثورة في طريقة فهم الآلات للغة. على عكس النماذج السابقة التي كانت تحلل النصوص بشكل تسلسلي من اليسار إلى اليمين أو العكس، يُمكّن BERT من المعالجة ثنائية الاتجاه. وهذا يعني أنه يستوعب سياق الكلمة من كلٍّ من تسلسلات النصوص السابقة واللاحقة. تُحسّن هذه القدرة بشكلٍ كبير فهم العلاقات اللغوية المعقدة.
🔍 هندسة BERT
شهدت السنوات الأخيرة تطوراً بالغ الأهمية في مجال معالجة اللغات الطبيعية، تمثل في ظهور نموذج Transformer، كما ورد في ورقة بحثية بعنوان "الانتباه هو كل ما تحتاجه" (ويكيبيديا) نُشرت عام ٢٠١٧. أحدث هذا النموذج نقلة نوعية في هذا المجال، إذ استغنى عن البنى المستخدمة سابقاً، كالترجمة الآلية، واعتمد بدلاً من ذلك بشكل حصري على آليات الانتباه. ومنذ ذلك الحين، شكّل تصميم Transformer أساساً للعديد من النماذج التي تُعدّ من أحدث ما توصل إليه العلم في مجالات متنوعة، تشمل توليد الكلام والترجمة وغيرها.
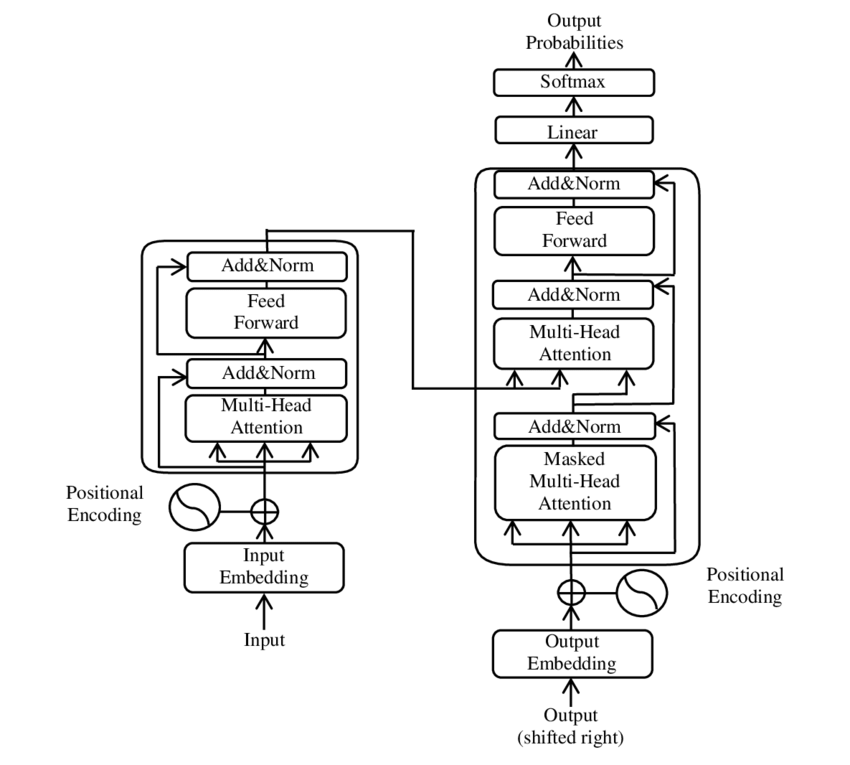
رسم توضيحي للمكونات الرئيسية لنموذج المحول - الصورة: جوجل
يعتمد نموذج BERT على بنية المحولات هذه. تستخدم هذه البنية ما يُسمى بآليات الانتباه الذاتي لتحليل العلاقات بين الكلمات في الجملة. تُعطى كل كلمة اهتمامًا ضمن سياق الجملة بأكملها، مما يؤدي إلى فهم أدق للعلاقات النحوية والدلالية.
مؤلفو الورقة البحثية بعنوان "الانتباه هو كل ما تحتاجه" هم:
- أشيش فاسواني (جوجل برين)
- نعوم شازير (جوجل برين)
- نيكي بارمار (باحثة في جوجل)
- جاكوب أوزكوريت (باحث في جوجل)
- ليون جونز (أبحاث جوجل)
- أيدان ن. غوميز (جامعة تورنتو، تم تنفيذ جزء من العمل في جوجل برين)
- لوكاس كايزر (جوجل برين)
- إيليا بولوسوخين (مستقل، عمل سابقاً في قسم الأبحاث في جوجل)
لقد قدم هؤلاء المؤلفون مساهمات كبيرة في تطوير نموذج المحول المعروض في هذه الورقة.
🔄 معالجة ثنائية الاتجاه
من أبرز ميزات نموذج BERT قدرته على معالجة النصوص في كلا الاتجاهين. فبينما تعالج النماذج التقليدية، مثل الشبكات العصبية المتكررة (RNNs) أو شبكات الذاكرة طويلة المدى (LSTM)، النصوص في اتجاه واحد فقط، يحلل BERT سياق الكلمة في كلا الاتجاهين. وهذا ما يسمح للنموذج بفهم أدقّ الفروق الدقيقة في المعنى، وبالتالي تقديم تنبؤات أكثر دقة.
🕵️♂️ نمذجة الكلام المقنّع
من الجوانب المبتكرة الأخرى لنموذج BERT تقنية نموذج اللغة المقنّع (MLM). في هذه التقنية، تُقنّع كلمات مختارة عشوائيًا من الجملة، ويُدرّب النموذج على التنبؤ بهذه الكلمات بناءً على السياق المحيط. تُجبر هذه الطريقة نموذج BERT على تطوير فهم عميق لسياق ومعنى كل كلمة في الجملة.
🚀 تدريب وتكييف BERT
يخضع نموذج BERT لعملية تدريب من مرحلتين: التدريب المسبق والضبط الدقيق.
📚 ما قبل التدريب
في مرحلة التدريب المسبق، يتم تدريب نموذج BERT باستخدام كميات كبيرة من النصوص لتعلم أنماط اللغة العامة. يشمل ذلك مقالات ويكيبيديا ومجموعات نصوص أخرى واسعة النطاق. خلال هذه المرحلة، يتعلم النموذج البنى اللغوية الأساسية والسياقات.
🔧 ضبط دقيق
بعد التدريب المسبق، يتم تكييف نموذج BERT لمهام معالجة اللغة الطبيعية المحددة، مثل تصنيف النصوص أو تحليل المشاعر. ويتم تدريب النموذج باستخدام مجموعات بيانات أصغر حجماً ومرتبطة بالمهام لتحسين أدائه في تطبيقات محددة.
🌍 مجالات تطبيق BERT
أثبت نموذج BERT فائدته الكبيرة في العديد من مجالات معالجة اللغة الطبيعية:
تحسين محركات البحث
تستخدم جوجل تقنية BERT لفهم استعلامات البحث بشكل أفضل وعرض نتائج أكثر صلة. وهذا يحسن تجربة المستخدم بشكل ملحوظ.
تصنيف النصوص
يستطيع برنامج BERT تصنيف المستندات حسب الموضوع أو تحليل الحالة المزاجية في النصوص.
التعرف على الكيانات المسماة (NER)
يقوم النموذج بتحديد وتصنيف الكيانات المسماة في النصوص، مثل أسماء الأشخاص أو الأماكن أو المنظمات.
أنظمة الأسئلة والأجوبة
يُستخدم برنامج BERT لتقديم إجابات دقيقة على الأسئلة المطروحة.
🧠 أهمية نموذج BERT لمستقبل الذكاء الاصطناعي
وضع نموذج BERT معايير جديدة لنماذج معالجة اللغة الطبيعية، ومهّد الطريق لمزيد من الابتكارات. وبفضل قدرته على المعالجة ثنائية الاتجاه وفهمه العميق لسياقات اللغة، فقد زاد بشكل ملحوظ من كفاءة ودقة تطبيقات الذكاء الاصطناعي.
🔜 التطورات المستقبلية
من المتوقع أن يهدف التطوير المستمر لنموذج BERT والنماذج المشابهة إلى ابتكار أنظمة أكثر قوة. هذه الأنظمة قادرة على التعامل مع مهام لغوية أكثر تعقيدًا، ويمكن استخدامها في مجالات تطبيقية جديدة ومتنوعة. إن دمج هذه النماذج في التقنيات اليومية من شأنه أن يُحدث تغييرًا جذريًا في كيفية تفاعلنا مع أجهزة الحاسوب.
🌟 علامة فارقة في تطور الذكاء الاصطناعي
يُعدّ BERT علامة فارقة في تطور الذكاء الاصطناعي، وقد أحدث ثورة في طريقة معالجة الآلات للغة الطبيعية. تُمكّن بنيته ثنائية الاتجاه من فهم أعمق للعلاقات اللغوية، مما يجعله لا غنى عنه في طيف واسع من التطبيقات. ومع تقدّم الأبحاث، ستستمر نماذج مثل BERT في لعب دور محوري في تحسين أنظمة الذكاء الاصطناعي وفتح آفاق جديدة لاستخدامها.
📣 مواضيع مشابهة
- 📚 مقدمة إلى BERT: نموذج معالجة اللغة الطبيعية الرائد
- 🔍 BERT ودور ثنائية الاتجاه في معالجة اللغة الطبيعية
- 🧠 نموذج المتحول: أساس بيرت
- 🚀 نمذجة اللغة المقنعة: مفتاح نجاح BERT
- 📈 تخصيص نموذج BERT: من التدريب المسبق إلى الضبط الدقيق
- 🌐 مجالات تطبيق BERT في التكنولوجيا الحديثة
- 🤖 تأثير BERT على مستقبل الذكاء الاصطناعي
- 💡 الآفاق المستقبلية: المزيد من التطورات في برنامج BERT
- 🏆 بيرت كمعلم بارز في تطوير الذكاء الاصطناعي
- 📰 مؤلفو ورقة بحثية بعنوان "الانتباه هو كل ما تحتاجه" من مجلة Transformer: العقول التي تقف وراء BERT
#️⃣ الوسوم: معالجة اللغة الطبيعية الذكاء الاصطناعي نمذجة اللغة المحولات التعلم الآلي
🎯🎯🎯 استفد من خبرة Xpert.Digital الواسعة والمتعددة الجوانب في باقة خدمات شاملة واحدة | تطوير الأعمال، البحث والتطوير، الواقع الممتد، العلاقات العامة، وتحسين الظهور الرقمي


استفد من خبرة Xpert.Digital الواسعة والمتعددة الجوانب في باقة خدمات شاملة | البحث والتطوير، والواقع الممتد، والعلاقات العامة، وتحسين الظهور الرقمي - الصورة: Xpert.Digital
تتمتع شركة Xpert.Digital بمعرفة متعمقة في مختلف القطاعات، مما يُمكّننا من تطوير استراتيجيات مُصممة خصيصًا لتتوافق بدقة مع متطلبات وتحديات قطاع السوق الخاص بكم. ومن خلال التحليل المستمر لاتجاهات السوق ومتابعة تطورات القطاع، نستطيع اتخاذ إجراءات استباقية وتقديم حلول مبتكرة. إن الجمع بين الخبرة والكفاءة يُولّد قيمة مضافة ويمنح عملاءنا ميزة تنافسية حاسمة.
للمزيد من المعلومات، انقر هنا:
بيرت: تقنية معالجة اللغة الطبيعية الثورية 🌟
🚀 BERT، اختصارًا لـ Bidirectional Encoder Representations from Transformers، هو نموذج لغوي متطور طورته جوجل، وقد حقق طفرة نوعية في معالجة اللغات الطبيعية (NLP) منذ إطلاقه عام ٢٠١٨. يعتمد BERT على بنية Transformer، التي أحدثت ثورة في كيفية فهم الآلات للنصوص ومعالجتها. ولكن ما الذي يميز BERT تحديدًا، وما هي استخداماته؟ للإجابة على هذا السؤال، نحتاج إلى إلقاء نظرة فاحصة على الأسس التقنية لـ BERT، وكيفية عمله، وتطبيقاته.
📚 1. أساسيات معالجة اللغة الطبيعية
لفهم أهمية BERT بشكل كامل، من المفيد استعراض أساسيات معالجة اللغة الطبيعية (NLP) بإيجاز. تتناول معالجة اللغة الطبيعية التفاعل بين الحواسيب واللغة البشرية، وتهدف إلى تعليم الآلات تحليل البيانات النصية وفهمها والاستجابة لها. قبل ظهور نماذج مثل BERT، كانت معالجة اللغة الآلية تواجه تحديات كبيرة، لا سيما بسبب غموض اللغة البشرية، واعتمادها على السياق، وبنيتها المعقدة.
📈 2. تطوير نماذج معالجة اللغة الطبيعية
قبل ظهور BERT، كانت معظم نماذج معالجة اللغة الطبيعية تعتمد على ما يُسمى بالبنى أحادية الاتجاه. هذا يعني أن هذه النماذج كانت تقرأ النص إما من اليسار إلى اليمين أو من اليمين إلى اليسار، مما يعني أنها لا تستطيع مراعاة سوى قدر محدود من السياق عند معالجة كلمة في جملة. غالبًا ما أدى هذا القيد إلى فشل النماذج في استيعاب السياق الدلالي للجملة بشكل كامل، مما صعّب التفسير الدقيق للكلمات الغامضة أو الحساسة للسياق.
كان نموذج word2vec تطورًا هامًا آخر في أبحاث معالجة اللغات الطبيعية قبل ظهور BERT، حيث مكّن الحواسيب من ترجمة الكلمات إلى متجهات تعكس أوجه التشابه الدلالي. مع ذلك، حتى في هذه الحالة، كان السياق محصورًا في المحيط المباشر للكلمة. لاحقًا، طُوّرت الشبكات العصبية المتكررة (RNNs)، ولا سيما نماذج الذاكرة طويلة المدى (LSTM)، مما أتاح فهمًا أفضل لتسلسلات النصوص من خلال تخزين المعلومات عبر كلمات متعددة. لكن هذه النماذج لم تخلُ من القيود، خاصةً عند التعامل مع النصوص الطويلة وفهم السياق في كلا الاتجاهين في آنٍ واحد.
🔄 3. الثورة من خلال الهندسة المعمارية التحويلية
حدث التطور الكبير مع ظهور بنية Transformer في عام 2017، والتي تُشكل أساس نموذج BERT. صُممت نماذج Transformer لتمكين معالجة النصوص المتوازية، مع مراعاة سياق الكلمة من النص السابق واللاحق. ويتحقق ذلك من خلال ما يُسمى بآليات الانتباه الذاتي، التي تُخصص قيمة وزن لكل كلمة في الجملة بناءً على أهميتها النسبية مقارنةً بالكلمات الأخرى فيها.
بخلاف الأساليب السابقة، فإن نماذج المحولات ليست أحادية الاتجاه بل ثنائية الاتجاه. وهذا يعني أنها تستطيع استخلاص المعلومات من السياقين الأيمن والأيسر للكلمة لإنشاء تمثيل أكثر اكتمالاً ودقة للكلمة ومعناها.
🧠 4. بيرت: نموذج ثنائي الاتجاه
يرتقي نموذج BERT بأداء بنية Transformer إلى مستوى جديد. صُمم هذا النموذج لالتقاط سياق الكلمة ليس فقط من اليسار إلى اليمين أو من اليمين إلى اليسار، بل في كلا الاتجاهين في آن واحد. وهذا يُمكّن BERT من مراعاة السياق الكامل للكلمة ضمن الجملة، مما يُحسّن دقة معالجة اللغة الطبيعية بشكل ملحوظ.
من أبرز سمات نموذج BERT استخدامه لما يُعرف بنموذج اللغة المقنّع (MLM). خلال تدريب BERT، تُستبدل كلمات مختارة عشوائيًا في الجملة بقناع، ويُدرَّب النموذج على تخمين هذه الكلمات المقنّعة بناءً على السياق. تُمكّن هذه التقنية BERT من تعلّم علاقات أعمق وأكثر دقة بين كلمات الجملة.
بالإضافة إلى ذلك، يستخدم نموذج BERT أسلوبًا يُسمى التنبؤ بالجملة التالية (NSP)، حيث يتعلم النموذج التنبؤ بما إذا كانت جملة ما تتبع جملة أخرى. وهذا يُحسّن قدرة BERT على فهم النصوص الطويلة والتعرف على العلاقات الأكثر تعقيدًا بين الجمل.
🌐 5. التطبيق العملي لـ BERT
أثبت نموذج BERT فائدته الكبيرة في مجموعة واسعة من مهام معالجة اللغة الطبيعية. فيما يلي بعض أهم مجالات التطبيق:
📊 أ) تصنيف النصوص
يُعدّ تصنيف النصوص أحد أكثر تطبيقات BERT شيوعًا، حيث تُقسّم النصوص إلى فئات مُحدّدة مسبقًا. ومن الأمثلة على ذلك تحليل المشاعر (مثل تحديد ما إذا كان النص إيجابيًا أم سلبيًا) أو تصنيف تعليقات العملاء. وبفضل فهمه العميق لسياق الكلمات، يُمكن لـ BERT تقديم نتائج أكثر دقة من النماذج السابقة.
❓ ب) أنظمة الأسئلة والأجوبة
يُستخدم نموذج BERT أيضًا في أنظمة الإجابة على الأسئلة، حيث يستخلص النموذج إجابات للأسئلة المطروحة من النص. وتكتسب هذه الميزة أهمية خاصة في تطبيقات مثل محركات البحث، وبرامج الدردشة الآلية، والمساعدين الافتراضيين. وبفضل بنيته ثنائية الاتجاه، يستطيع BERT استخلاص المعلومات ذات الصلة من النص حتى لو كان السؤال مُصاغًا بشكل غير مباشر.
🌍 ج) ترجمة النص
على الرغم من أن نموذج BERT ليس مصممًا بشكل مباشر كنموذج ترجمة، إلا أنه يمكن استخدامه بالتزامن مع تقنيات أخرى لتحسين الترجمة الآلية. فمن خلال فهم أفضل للعلاقات الدلالية داخل الجملة، يُمكن لـ BERT المساعدة في توليد ترجمات أكثر دقة، لا سيما مع العبارات الغامضة أو المعقدة.
🏷️ د) التعرف على الكيانات المسماة (NER)
يُعدّ التعرّف على الكيانات المسماة (NER) مجالًا آخر للتطبيقات، حيث يتضمن تحديد كيانات محددة مثل الأسماء أو الأماكن أو المنظمات داخل النص. وقد أثبت نموذج BERT فعاليته بشكل خاص في هذه المهمة لأنه يأخذ سياق الجملة بعين الاعتبار بشكل كامل، وبالتالي يمكنه التعرّف على الكيانات بشكل أفضل، حتى لو كانت لها معانٍ مختلفة في سياقات مختلفة.
✂️ هـ) ملخص نصي
إن قدرة BERT على فهم السياق الكامل للنص تجعله أداةً فعّالةً لتلخيص النصوص تلقائيًا. إذ يُمكن استخدامه لاستخلاص أهم المعلومات من نص طويل وإنشاء ملخص موجز.
🌟 6. أهمية BERT للبحث والصناعة
شكّل إدخال نموذج BERT بداية حقبة جديدة في أبحاث معالجة اللغات الطبيعية. فقد كان من أوائل النماذج التي استغلت قوة بنية المحوّل ثنائي الاتجاه استغلالاً كاملاً، واضعاً بذلك معياراً للعديد من النماذج اللاحقة. وقد قامت العديد من الشركات والمؤسسات البحثية بدمج نموذج BERT في مسارات معالجة اللغات الطبيعية الخاصة بها لتحسين أداء تطبيقاتها.
علاوة على ذلك، مهد نموذج BERT الطريق لمزيد من الابتكارات في مجال نماذج اللغة. فعلى سبيل المثال، تم تطوير نماذج لاحقة مثل GPT (المحول التوليدي المدرب مسبقًا) وT5 (محول نقل النص إلى النص)، والتي تستند إلى مبادئ مماثلة ولكنها تقدم تحسينات محددة لحالات استخدام مختلفة.
🚧 7. تحديات وقيود نموذج BERT
على الرغم من مزاياها العديدة، تواجه BERT بعض التحديات والقيود. من أبرز هذه التحديات الجهد الحسابي الكبير المطلوب لتدريب النموذج وتطبيقه. ولأن BERT نموذج ضخم يحتوي على ملايين المعاملات، فإنه يتطلب أجهزة قوية وموارد حاسوبية هائلة، خاصةً عند معالجة مجموعات البيانات الكبيرة.
تتمثل مشكلة أخرى في التحيز المحتمل الموجود في بيانات التدريب. فنظرًا لأن نموذج BERT يُدرَّب على كميات هائلة من البيانات النصية، فإنه يعكس أحيانًا الأحكام المسبقة والصور النمطية الموجودة في تلك البيانات. ومع ذلك، يعمل الباحثون باستمرار على تحديد هذه المشكلات ومعالجتها.
🔍 أداة لا غنى عنها لتطبيقات معالجة الكلام الحديثة
لقد حسّن نموذج BERT بشكلٍ ملحوظ طريقة فهم الآلات للغة البشرية. فبفضل بنيته ثنائية الاتجاه وأساليب التدريب المبتكرة، يستطيع BERT استيعاب سياق الكلمات داخل الجملة بدقةٍ وعمق، مما يُؤدي إلى دقةٍ أكبر في العديد من مهام معالجة اللغة الطبيعية. وسواءً في تصنيف النصوص، أو أنظمة الإجابة على الأسئلة، أو التعرف على الكيانات، فقد رسّخ BERT مكانته كأداةٍ لا غنى عنها في تطبيقات معالجة اللغة الطبيعية الحديثة.
لا شك أن الأبحاث في مجال معالجة اللغات الطبيعية ستواصل تطورها، وقد أرست BERT الأساس للعديد من الابتكارات المستقبلية. ورغم التحديات والقيود الحالية، تُظهر BERT بوضوح مدى التقدم الذي أحرزته هذه التقنية في فترة وجيزة، والفرص الواعدة التي ستُتاح في المستقبل.
🌀 المحول: ثورة في معالجة اللغة الطبيعية
🌟 في السنوات الأخيرة، كان من أبرز التطورات في مجال معالجة اللغات الطبيعية (NLP) ظهور نموذج Transformer، كما ورد في ورقة بحثية نُشرت عام 2017 بعنوان "الانتباه هو كل ما تحتاجه". أحدث هذا النموذج نقلة نوعية في هذا المجال، إذ استغنى عن البنى المتكررة أو الالتفافية المستخدمة سابقًا في مهام تحويل التسلسل، مثل الترجمة الآلية. وبدلاً من ذلك، يعتمد النموذج كليًا على آليات الانتباه. ومنذ ذلك الحين، شكّل تصميم Transformer أساسًا للعديد من النماذج التي تُعدّ من أحدث التقنيات في مجالات متنوعة، تشمل توليد الكلام والترجمة وغيرها.
🔄 المُحوِّل: نقلة نوعية
قبل ظهور نموذج Transformer، كانت معظم نماذج مهام التسلسل تعتمد على الشبكات العصبية المتكررة (RNNs) أو شبكات الذاكرة طويلة المدى (LSTM)، والتي تعمل بطبيعتها بشكل تسلسلي. تعالج هذه النماذج بيانات الإدخال خطوة بخطوة، مُنشئةً حالات مخفية تنتشر على طول التسلسل. ورغم فعالية هذه الطريقة، إلا أنها مكلفة حسابيًا ويصعب موازاتها، خاصةً مع التسلسلات الطويلة. علاوة على ذلك، تواجه الشبكات العصبية المتكررة صعوبة في تعلم التبعيات طويلة المدى بسبب مشكلة تلاشي التدرج.
يكمن الابتكار الرئيسي لنموذج Transformer في استخدامه لآليات الانتباه الذاتي، التي تُمكّنه من تقييم أهمية الكلمات المختلفة في الجملة بالنسبة لبعضها البعض، بغض النظر عن موقعها. وهذا يُتيح للنموذج استيعاب العلاقات بين الكلمات المتباعدة بشكل أكثر فعالية من الشبكات العصبية المتكررة (RNNs) أو شبكات الذاكرة طويلة المدى (LSTMs)، والقيام بذلك بالتوازي بدلاً من التتابع. وهذا لا يُحسّن كفاءة التدريب فحسب، بل يُحسّن أيضاً الأداء في مهام مثل الترجمة الآلية.
🧩 هندسة النموذج
يتكون المحول من مكونين رئيسيين: جهاز التشفير وجهاز فك التشفير، وكلاهما يتكون من عدة طبقات ويعتمد بشكل كبير على آليات الانتباه متعددة الرؤوس.
⚙️ مُشفِّر
يتكون جهاز التشفير من ست طبقات متطابقة، كل منها تحتوي على طبقتين فرعيتين:
1. الانتباه الذاتي متعدد الرؤوس
تُمكّن هذه الآلية النموذج من التركيز على أجزاء مختلفة من الجملة المدخلة عند معالجة كل كلمة. فبدلاً من حساب الانتباه في حيز واحد، يقوم الانتباه متعدد الرؤوس بإسقاط المدخلات على عدة حيزات مختلفة، وبالتالي التقاط أنواع مختلفة من العلاقات بين الكلمات.
2. شبكات التغذية الأمامية المتصلة بالكامل من حيث الموقع
بعد طبقة الانتباه، يتم تطبيق شبكة تغذية أمامية متصلة بالكامل بشكل مستقل في كل موضع. يساعد هذا النموذج على معالجة كل كلمة في سياقها والاستفادة من المعلومات المستقاة من آلية الانتباه.
للحفاظ على بنية تسلسل الإدخال، يتضمن النموذج أيضًا ترميزات موضعية. ولأن المحول لا يعالج الكلمات بالتسلسل، فإن هذه الترميزات ضرورية لتزويد النموذج بمعلومات حول ترتيب الكلمات في الجملة. تُضاف الترميزات الموضعية إلى تضمينات الكلمات لكي يتمكن النموذج من التمييز بين المواضع المختلفة في التسلسل.
🔍 جهاز فك التشفير
على غرار المُشفِّر، يتكون المُفكِّك أيضًا من ست طبقات، تحتوي كل منها على آلية انتباه إضافية تُمكِّن النموذج من التركيز على الأجزاء ذات الصلة من تسلسل الإدخال أثناء توليد المُخرَج. كما يستخدم المُفكِّك تقنية إخفاء لمنعه من النظر في المواضع المستقبلية، وبالتالي الحفاظ على الطبيعة التراجعية الذاتية لتوليد التسلسل.
🧠 الانتباه متعدد الرؤوس والانتباه القياسي للمنتج
جوهر نموذج Transformer هو آلية الانتباه متعددة الرؤوس، وهي امتداد لآلية الانتباه القياسية الأبسط. يمكن النظر إلى دالة الانتباه على أنها ربط بين استعلام ومجموعة من أزواج المفاتيح والقيم، حيث يمثل كل مفتاح كلمة في التسلسل، وتمثل القيمة المعلومات السياقية المقابلة.
تتيح آلية الانتباه متعدد الرؤوس للنموذج التركيز على أجزاء مختلفة من التسلسل في آنٍ واحد. ومن خلال إسقاط المدخلات على فضاءات فرعية متعددة، يستطيع النموذج استيعاب مجموعة أوسع من العلاقات بين الكلمات. وهذا مفيدٌ بشكل خاص لمهام مثل الترجمة الآلية، حيث يتطلب فهم سياق الكلمة مراعاة عوامل عديدة، كالبنية النحوية والمعنى الدلالي.
صيغة الانتباه الناتج عن الضرب القياسي هي:
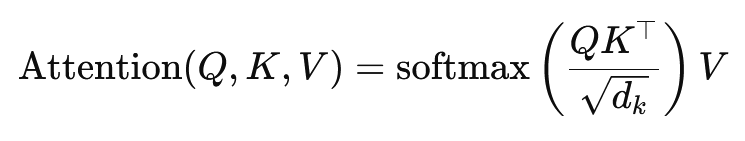
هنا، (Q) هي مصفوفة الاستعلام، و(K) مصفوفة المفاتيح، و(V) مصفوفة القيم. يُمثل الحد (√d_k) عامل قياس يمنع حاصل الضرب القياسي من أن يصبح كبيرًا جدًا، مما قد يؤدي إلى تدرجات صغيرة جدًا وبطء في التعلم. تُستخدم دالة softmax لضمان أن يكون مجموع أوزان الانتباه مساويًا للواحد.
🚀 مزايا المحول
يوفر نموذج Transformer العديد من المزايا الحاسمة مقارنة بالنماذج التقليدية مثل RNNs وLSTMs:
1. التوازي
بما أن المحول يعالج جميع رموز التسلسل في وقت واحد، فإنه يمكن أن يكون متوازيًا للغاية وبالتالي يكون تدريبه أسرع بكثير من الشبكات العصبية المتكررة أو الشبكات العصبية طويلة المدى، خاصة مع مجموعات البيانات الكبيرة.
2. الاعتمادات طويلة الأجل
تسمح آلية الانتباه الذاتي للنموذج بالتقاط العلاقات بين الكلمات البعيدة بشكل أكثر فعالية من الشبكات العصبية المتكررة، والتي تقتصر على الطبيعة التسلسلية لحساباتها.
3. قابلية التوسع
يمكن للمحول أن يتوسع بسهولة ليشمل مجموعات بيانات كبيرة جدًا وتسلسلات أطول دون أن يعاني من اختناقات الأداء المرتبطة بالشبكات العصبية المتكررة.
🌍 التطبيقات والآثار
منذ ظهورها، أصبحت تقنية Transformer أساسًا لمجموعة واسعة من نماذج معالجة اللغة الطبيعية. ومن أبرز الأمثلة على ذلك نموذج BERT (تمثيلات المشفر ثنائي الاتجاه من Transformers)، الذي يستخدم بنية Transformer معدلة لتحقيق أداء متميز في العديد من مهام معالجة اللغة الطبيعية، بما في ذلك الإجابة على الأسئلة وتصنيف النصوص.
ومن التطورات الهامة الأخرى تقنية GPT (المحولات التوليدية المدربة مسبقًا)، التي تستخدم نسخة محدودة من المحولات لتوليد النصوص. وتُستخدم نماذج GPT، بما في ذلك GPT-3، حاليًا في العديد من التطبيقات، بدءًا من إنشاء المحتوى وصولًا إلى إكمال التعليمات البرمجية.
🔍 نموذج قوي ومرن
لقد غيّر نموذج Transformer جذريًا طريقة تعاملنا مع مهام معالجة اللغة الطبيعية. فهو يوفر نموذجًا قويًا ومرنًا يُمكن تطبيقه على نطاق واسع من المشكلات. وقد جعلته قدرته على التعامل مع التبعيات طويلة المدى وكفاءته في التدريب النهج المعماري المفضل للعديد من النماذج الحديثة. ومع تقدم الأبحاث، من المرجح أن نشهد المزيد من التحسينات والتعديلات على نموذج Transformer، لا سيما في مجالات مثل معالجة الصور والكلام، حيث تُظهر آليات الانتباه نتائج واعدة.
نحن هنا لخدمتكم - الاستشارات - التخطيط - التنفيذ - إدارة المشاريع
☑️ خبير في هذا المجال، هنا مع مركز Xpert.Digital الخاص به والذي يضم أكثر من 2500 مقال متخصص

Konrad Wolfenstein
يسعدني أن أكون مستشارك الشخصي.
يمكنك الاتصال بي عن طريق ملء نموذج الاتصال أدناه أو ببساطة الاتصال بي على الرقم +49 7348 4088 965 .
أتطلع إلى مشروعنا المشترك.
راسلني




إكسبرت ديجيتال - Konrad Wolfenstein
Xpert.Digital هو مركز صناعي يركز على الرقمنة والهندسة الميكانيكية والخدمات اللوجستية/الخدمات اللوجستية الداخلية والخلايا الكهروضوئية.
بفضل حلولنا الشاملة لتطوير الأعمال، ندعم الشركات المرموقة من الأعمال الجديدة إلى خدمات ما بعد البيع.
تُعدّ معلومات السوق، والتسويق الموجه، وأتمتة التسويق، وتطوير المحتوى، والعلاقات العامة، وحملات البريد، ووسائل التواصل الاجتماعي الشخصية، ورعاية العملاء المحتملين جزءًا من أدواتنا الرقمية.
يمكنكم الاطلاع على المزيد من المعلومات على المواقع التالية: www.xpert.digital - www.xpert.solar - www.xpert.plus
أبق على اتصال











