البيانات المنظمة (الترميز) في عصر الذكاء الاصطناعي مع Schema.org: ما يفكر فيه مهندسو جوجل حقًا – الصورة: Xpert.Digital
سر جوجل في تحسين محركات البحث: لماذا يفشل الذكاء الاصطناعي بدون بيانات منظمة
على الرغم من ChatGPT وشركائها: لماذا لا يزال مهندسو جوجل يعتمدون على Schema.org؟
تحديثات تحسين محركات البحث: لماذا يحل Schema.org الآن محل Open Graph على جوجل؟
تنتشر خرافة شائعة في عالم تحسين محركات البحث: في عصر نماذج اللغة الذكية المدعومة بالذكاء الاصطناعي، والتي تفهم النصوص غير المنظمة بسهولة، أصبحت البيانات المنظمة التي تُصان بعناية، مثل Schema.org، متقادمة. لكن الحقيقة مختلفة تمامًا. ففي فعالية Google Search Central Live، فند مهندس جوجل، رايان ليفرينغ، هذا المفهوم الخاطئ، وأوضح بجلاء: أن الترميز المنظم ليس من مخلفات الماضي، بل هو الركيزة الأساسية للبحث الجديد المدعوم بالذكاء الاصطناعي.
من استعراضات الذكاء الاصطناعي الجديدة إلى وكلاء التسوق الآليين، تحتاج نماذج اللغة إلى إرشادات دقيقة قابلة للقراءة آليًا لتجنب التشويش والعمل بكفاءة حسابية عالية. يجب على الراغبين في البقاء حاضرين على الإنترنت الحديث مساعدة الآلات على فهم السياق بوضوح تام. تتناول هذه المقالة إعادة هيكلة جوجل الاستراتيجية، وتقدم ابتكارات ثورية للتجارة الإلكترونية والمحتوى الذي ينشئه المستخدمون، وتوضح لماذا أصبح تحسين محركات البحث التقني الآن هو الميزة التنافسية الحاسمة في معركة الظهور أمام الآلات.
تستطيع الآلات قراءة الويب - ولكن فقط إذا ساعدتها على فهمه
في 21 أبريل 2026، عُقد أول حدث مباشر لمركز جوجل للبحث على الأراضي الكندية في تورنتو، ولم يكن مجرد تجمع عادي في هذا المجال. قدّم ريان ليفرينغ، مهندس في قسم هندسة البحث في جوجل، عرضًا يُمكن القول إنه الأكثر كثافةً من الناحية التقنية والأكثر أهميةً من الناحية الاستراتيجية في ذلك اليوم، بعنوان: "البيانات المنظمة، والجودة، والذكاء الاصطناعي". لم يكن ما قدّمه مجرد استعراض تقني، بل كان بيانًا واضحًا حول مستقبل الويب الدلالي في عصر يتزايد فيه دور الذكاء الاصطناعي كوسيط بين المستخدمين والمعلومات.
بين طرفين متناقضين: الخيار الخاطئ بين أمرين
في بداية عرضه، قارن رايان ليفرينغ بين رأيين متناقضين تمامًا شائعين في أوساط خبراء تحسين محركات البحث. فمن جهة، هناك قناعة بأن البيانات المنظمة أصبحت زائدة عن الحاجة في عصر نماذج اللغة القوية: إذا كانت نماذج الذكاء الاصطناعي قادرة على تفسير النصوص غير المنظمة بسهولة، فلماذا عناء إضافة ترميز schema.org إلى شفرة المصدر؟ ومن جهة أخرى، يروج بعض المتحمسين لفكرة أن البيانات المنظمة هي مستقبل الإنترنت - بروتوكول اتصال دلالي عالمي بين وكلاء الذكاء الاصطناعي المستقلين، والذي سيحل إلى حد كبير محل الويب التقليدي.
رفض ليفرينغ كلا الطرفين المتطرفين، وقدم بدلاً من ذلك منظوراً دقيقاً قائماً على الأدلة التجريبية. وخلص إلى أن كلا الموقفين يحملان في طياتهما شيئاً من الحقيقة، لكن لا يصف أي منهما الواقع وصفاً كاملاً. هذا التباين الدقيق هو سمة مميزة لنهج جوجل الحالي في هذا الموضوع: فهو لا يتعلق بالجمود الفكري، بل بالكفاءة العملية.
أربع حجج تفسر كل شيء
يمكن تلخيص الحجة الرئيسية لليفرينغ في أربع نقاط أساسية، شرحها بالتفصيل تحت عنوان "قيمة البيانات المهيكلة". النقطة الأولى هي الدقة: توفر البيانات المهيكلة دقة أعلى بكثير للمخططات المعقدة، مثل أسعار البيع أو برامج الولاء، مقارنةً بالاستخراج القائم على نماذج اللغة من النصوص الحرة. قد تكون نماذج اللغة مُضللة، إذ تُكمل السمات المفقودة، أو تُرتب البيانات بشكل غير صحيح، أو تصل إلى المعلومات خارج سياقها. عند استخراج أسعار المنتجات من موقع تجارة إلكترونية ضخم يحتوي على عشرات المنتجات المتشابهة، يكون معدل الخطأ أعلى بكثير مع الاستدلال بالذكاء الاصطناعي مقارنةً بالترميز المهيكل المُنفذ بدقة.
تتعلق النقطة الثانية بالمحتوى الإضافي: غالبًا ما تحتوي البيانات المنظمة على بيانات وصفية غير مرئية لا تظهر في صفحة HTML المعروضة. تنسيقات تواريخ ISO الكاملة، والمعرفات الثابتة للمحتوى الذي ينشئه المستخدم، أو معرفات الكيانات الداخلية - هذه المعلومات موجودة حصريًا في ترميز HTML. لا يمكن لأي نموذج لغوي استخراج ما ليس موجودًا في النص.
ثالثًا، الكفاءة: يُعدّ تحليل الترميز المهيكل أرخص بكثير من معالجة نموذج لغوي ضخم لاستخراج بيانات معقدة. تُفهرس جوجل مليارات الصفحات يوميًا. الحساب بسيط: يستهلك محلل عادي يُعالج JSON-LD جزءًا ضئيلاً من موارد الحوسبة التي تستهلكها خطوة استدلال نموذج لغوي ضخم. لذا، لا تتفوق البيانات المهيكلة دلاليًا فحسب، بل إنها أيضًا أكثر كفاءة بشكل ملحوظ من منظور الأعمال. هذه النقطة ذات صلة مباشرة ببنية جوجل التحتية.
الجانب الرابع، وربما الأكثر استهانةً به، هو التركيز: تُبرز البيانات المنظمة بوضوح المعلومات ذات الصلة في الصفحة، مما يمنع أنظمة الذكاء الاصطناعي من التقاط بيانات غير ذات صلة. ففي صفحة منتج تحتوي على مقال رئيسي، وعدة منتجات ذات صلة، وشريط تنقل مليء بالأسعار، لا يستطيع نموذج اللغة، بدون شرح واضح، تحديد السعر الصحيح. يحل الترميز المنظم هذه المشكلة من خلال التعيين غير المبهم.
كيف تتم معالجة البيانات المنظمة فعلياً
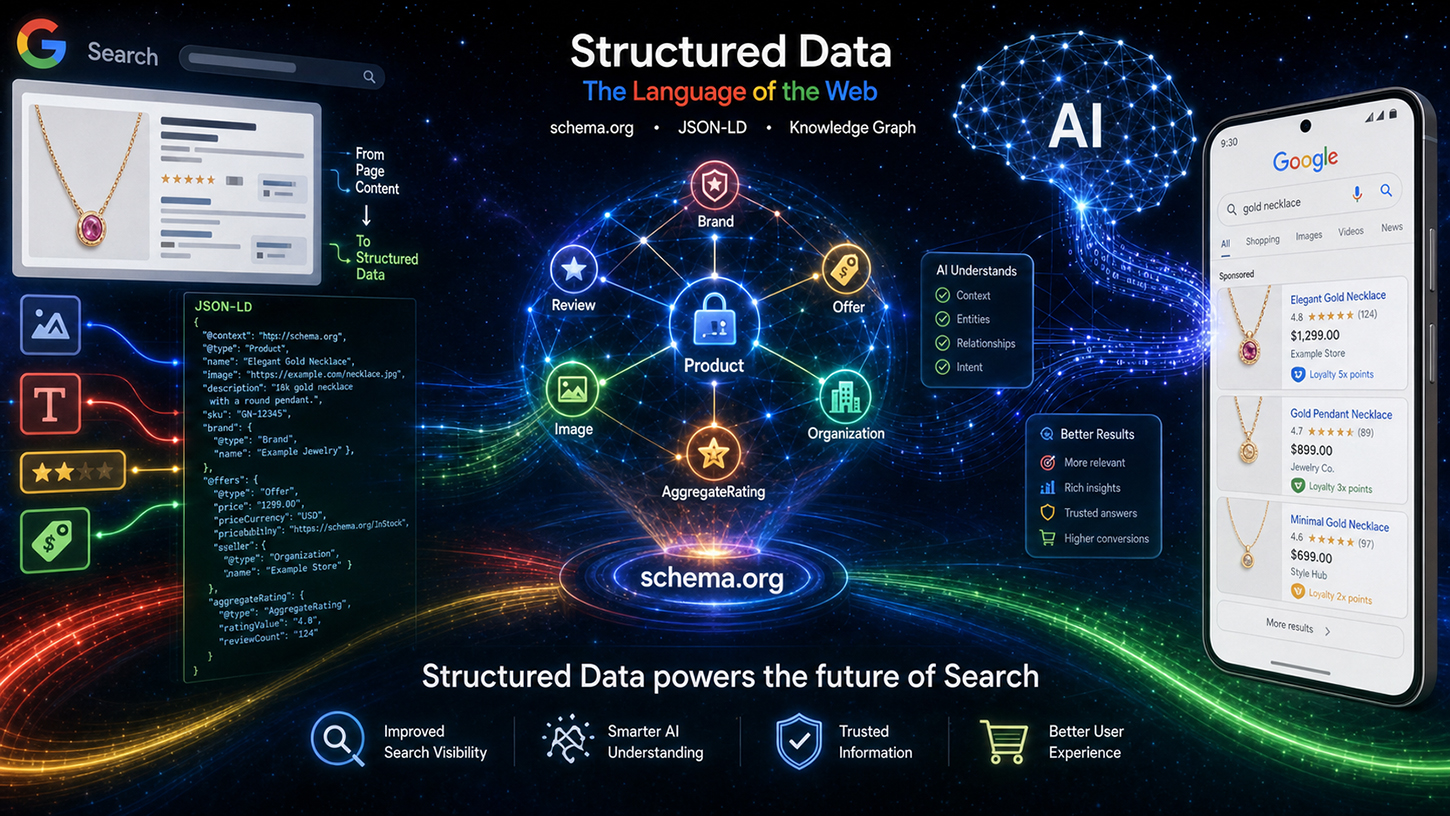
ساهمت الاستفادة من البيانات المنظمة في جعل عملية المعالجة التقنية أكثر شفافية. تُعالج بيانات Schema.org أولاً من خلال عمليات تنظيف وتصفية محددة قبل تصنيفها كبيانات مفهرسة، مقسمة إلى مجالات مثل الأحداث والتسوق والتقييمات. ثم تتدفق هذه البيانات المُجهزة إلى قناتين إخراج مختلفتين: الأولى هي صفحة نتائج البحث التقليدية، والثانية هي سياق أنظمة جوجل القائمة على الذكاء الاصطناعي، وتحديداً ما يُعرف بنظرة عامة على الذكاء الاصطناعي (AIO) ووضع الذكاء الاصطناعي (AIM). وبذلك، لم تعد البيانات المنظمة مجرد أداة لعرض نتائج غنية، بل أصبحت مدخلاً مباشراً لاستجابات الذكاء الاصطناعي التوليدية. يُمثل هذا تحولاً جذرياً في الأهمية الاستراتيجية لعلامات Schema.org.
🎯🎯🎯 مركز صناعي قائم على البيانات بين الشركات كحل شبه داخلي


الحل شبه الداخلي: كيف تسدّ Xpert.Digital الثغرات التشغيلية في التسويق والمبيعات بين الشركات - أعمال ذكية قائمة على المحتوى - الصورة: Xpert.Digital
Xpert.Digital هي منصة صناعية B2B تعتمد على البيانات بقيادة Konrad Wolfenstein . تعمل الشركة كحل خارجي شبه داخلي للشركاء الصناعيين، حيث تسد الثغرات التشغيلية في التسويق والمحتوى والمبيعات - دون الحاجة إلى موارد إضافية من جانب العميل.
للمزيد من المعلومات، انقر هنا:
لماذا أصبحت البيانات المنظمة البنية التحتية لوكلاء الذكاء الاصطناعي؟
التسوق تحت المجهر: الشحن، وبرامج الولاء، والخيارات المتنوعة
ركز جزء كبير من العرض التقديمي على الابتكارات في التجارة الإلكترونية. وأوضح ليفرينغ أنه وفقًا لبيانات معهد بايمارد، تأتي معلومات الشحن غير المتوقعة في المرتبتين الثانية والثالثة بين أكثر الأسباب شيوعًا للتخلي عن سلة التسوق. ويمكن للترميز المنظم لخدمات الشحن أن يعالج هذه المشكلة مباشرةً: إذ يُمكن للتجار الآن تحديد مناطق المنشأ والوجهة، والأبعاد والأوزان، وحدود قيمة الطلب، وأوقات المعالجة، وانتماءات برامج الولاء بدقة مباشرةً في الكود.
ينقسم نموذج وقت الشحن الذي تستخدمه جوجل إلى مرحلتين: وقت المعالجة، أي الوقت من استلام الطلب حتى تسليمه إلى شركة الشحن، ووقت التسليم الفعلي. يمكن إضافة تعليقات توضيحية لكلتا المرحلتين بشكل منفصل وبدقة عالية، وصولاً إلى مواعيد إغلاق الطلبات وما إذا كانت المعالجة تتم خلال أيام الأسبوع. توضح أمثلة JSON-LD المقابلة كيفية استخدام نوع `ShippingConditions` لتحديد الشحن المجاني لبعض الدول (مثل فرنسا وألمانيا) والحد الأدنى لقيمة الطلب (مثل 50 يورو).
يُعدّ دمج خدمات الشحن مع برامج الولاء ابتكارًا فريدًا. فباستخدام خاصية `validForMemberTier`، يُمكن ربط خدمة الشحن بشكلٍ مباشر ببرنامج عضوية ومستوى مُحدد. وهذا يُتيح إمكانية تحديد مزايا الشحن للأعضاء المميزين مباشرةً في ترميز الصفحة، وهي ميزة كانت سابقًا مُتاحة فقط عبر مركز Google Merchant Center. ويتم تعريف برنامج الولاء المُرتبط ككائن `MemberProgram` ضمن كيان `Organization`، مع مستويات مثل "الذهبي" أو "الفضي" ومزايا مُرتبطة بها مثل جوائز الولاء أو نقاط المكافآت.
برامج الولاء ككيانات دلالية
يُعدّ إدخال ترميز برامج الولاء ذا أهمية اقتصادية بالغة. إذ يُمكن للمؤسسات تعريف برامج عضوية مستقلة متعددة، لكل منها مستويات ومزايا مختلفة - نقاط، وأسعار خاصة بالأعضاء، وسياسات إرجاع، ومكافآت شحن. وتظهر هذه المعلومات مباشرةً في نتائج بحث جوجل، كما أوضح ليفرينغ بأمثلة واقعية، منها عرض سيفورا الذي عرض خصمًا بنسبة 30% للأعضاء مباشرةً في مقتطف التسوق. ووفقًا لليفرينغ، فإنّ ربط معرّفات الصفحات، أي إمكانية الربط بتعريفات برامج الولاء من صفحات أخرى، هو الخطوة التالية المُخطط لها، والتي تحمل حاليًا عنوان "تمهيد الطريق لربط معرّفات الصفحات". والهدف هو تعزيز الروابط التنظيمية بين صفحات المنتجات وسياسات الشركة.
المحتوى الذي ينشئه المستخدمون: مشكلة تصنيف الذكاء الاصطناعي
كان من المواضيع المهمة الأخرى تطوير أنواع المخططات الخاصة بالمحتوى الذي ينشئه المستخدمون. وتبرز هنا ميزتان جديدتان بشكل خاص. أولاً، يدعم هذا التحديث تضمين المنشورات وإعادة نشرها في ترميز المنتديات وأسئلة وأجوبة، مما يتيح تمثيلاً دلالياً أدق لهياكل النقاش. ثانياً، وهو أمر ذو أهمية استراتيجية أكبر، تم تقديم خاصية `so#digitalSourceType` لتحديد المحتوى الذي يتم إنشاؤه آلياً بشكل صريح.
يُعدّ هذا التطور استجابةً مباشرةً لتدفق المحتوى المُنشأ بواسطة الذكاء الاصطناعي على منصات مثل المنتديات ومواقع الأسئلة والأجوبة. يُمكن لمشرفي المواقع الآن تحديد ما إذا كان المنشور قد أُنشئ بواسطة خوارزمية أو نموذج لغوي. أما المنشورات التي لا تُحدد ذلك، فتفترض جوجل ضمنيًا أنها من تأليف بشري، وهو ما يُشجع على وضع علامات شفافة. تعتمد خاصية `digitalSourceType` على رموز IPTC للمصادر الرقمية، وتُميز، من بين أمور أخرى، بين المحتوى المُنشأ بواسطة خوارزمية والمحتوى المُنشأ بواسطة نموذج.
اختيار الصورة: المخطط يتفوق على الرسم البياني المفتوح
هناك تحديث أقل شهرة ولكنه فعال عمليًا يتعلق بمنطق اختيار الصور في جوجل. يجري توحيد النظام داخليًا، مع تسلسل هرمي واضح للأولويات: حيث تُعطى الأولوية لعلامات Schema.org، وتحديدًا الخاصيتين `primaryImageOfPage` و`mainEntity → image`. بعد ذلك فقط تأتي علامة `og:image` الوصفية من Open Graph. هذا التغيير يعني أنه بالنسبة لمشغلي المواقع الإلكترونية، فإن تطبيقًا نظيفًا لـ Schema.org للصورة الرئيسية يؤثر بشكل مباشر على عرضها في نتائج بحث جوجل ومراجعات الذكاء الاصطناعي - وهي ميزة ملموسة وقابلة للقياس.
تتلقى Schema.org نفسها استثمارات
ومن الجدير بالذكر أيضًا إعلان جوجل عن إعادة استثمارها في schema.org كمواصفة مفتوحة المصدر. وقد ذُكرت ثلاثة إجراءات ملموسة: نشر إحصائيات حول معدل استخدام مصطلحات المخطط الفردية (كما هو موضح في العرض التقديمي، تتوفر بالفعل بيانات الانتشار لمصطلحات فردية مثل `digitalSourceType` مع معلومات عن حوالي 10000 نطاق)، ونشر قواعد التحقق الخاصة بجوجل بتنسيقات قياسية قابلة للقراءة آليًا مثل SHACL أو ShEx، وتحسين دعم قواعد الترتيب. وهذا أمر بالغ الأهمية لأنه سيتيح للمطورين الخارجيين بناء أدوات التحقق الخاصة بهم استنادًا إلى معايير جوجل، بشكل مستقل عن أدوات الاختبار الرسمية التي قد تتعطل أحيانًا تحت الضغط.
التحقق: أداتان، هدف واحد
قدمت شركة Levering أداتين للتحقق من صحة البيانات، تُكمل كل منهما الأخرى، لكنهما تطبقان معايير اختبار مختلفة. تقبل أداة اختبار النتائج المنسقة (Rich Result Test Tool) الموجودة على الرابط `search.google.com/test/rich-results` عناوين URL أو بيانات JSON، وتتحقق من مدى ملاءمة ترميز البيانات لنتائج البحث المنسقة في جوجل، وبالتالي فهي تعتمد على متطلبات جوجل الخاصة، وليس على معيار schema.org نفسه. أما أداة `validator.schema.org`، فتتحقق من توافق ترميز البيانات مع معيار schema.org، أي مدى التزامه بالمفردات المفتوحة، بغض النظر عما إذا كانت جوجل ستُنشئ نتائج منسقة أم لا. وهذا يقودنا إلى توصية واضحة لمطوري الويب: يجب استخدام كلتا الأداتين، لأن ترميز البيانات قد يكون متوافقًا مع معيار schema.org ولكنه غير قادر على إنشاء نتائج منسقة، والعكس صحيح.
الصورة الأوسع: البيانات المنظمة كبنية تحتية للذكاء الاصطناعي
بالنظر إلى حدث تورنتو ككل، يتضح تحولٌ يتجاوز بكثير تحسين محركات البحث التقليدي. فالبيانات المنظمة تتطور من مجرد أداة للحصول على مقتطفات غنية إلى معيار أساسي لطبقة البيانات لأنظمة الذكاء الاصطناعي. تستخدم كل من نظرة عامة على الذكاء الاصطناعي ووضع الذكاء الاصطناعي من جوجل ترميز schema.org بشكل فعال كسياق لتوليد الإجابات والتحقق من الكيانات. إن من يطبقون بيانات منظمة صحيحة وكاملة ودقيقة لا يحسنون فقط فرصهم في الحصول على نقاط بارزة في نتائج البحث، بل يجعلون محتواهم مصدرًا أساسيًا موثوقًا لإجابات الذكاء الاصطناعي.
إن ذكر بروتوكول التجارة العالمية (UCP) وبروتوكول WebMCP في هذا السياق ليس من قبيل المصادفة. فكلاهما معياران للاتصال قائمان على الوكلاء، واللذان أطلقتهما جوجل في نسخ مبكرة عام 2026، يشترطان وصف مواقع الويب دلاليًا. ويُشكّل Schema.org الأساس لهذا الوصف. في عالمٍ تعمل فيه وكلاء الذكاء الاصطناعي بشكل مستقل على الإنترنت، حيث يبحثون ويقارنون ويبدأون المعاملات، لم تعد قابلية قراءة المحتوى آليًا أمرًا اختياريًا، بل شرطًا أساسيًا للجدوى الاقتصادية. ولذلك، لم يكن عرض ريان ليفرينغ في تورنتو مجرد تقرير تقني، بل كان بمثابة لمحة عن بنية الويب المستقبلية.
يمكنك معرفة ذلك بنفسك في غضون 10 ثوانٍ
إذا كنت ترغب في معرفة مدى جودة وشمولية استخدام موقعك الإلكتروني أو موقع آخر للبيانات المنظمة، فيمكنك استخدام الأداتين اللتين أوصى بهما ريان ليفرينغ من جوجل (من النص أعلاه):
اختبار نتائج البحث الغنية من جوجل (التركيز على الظهور في جوجل):
انتقل إلى search.google.com/test/rich-results، وانسخ عنوان URL لأي مقال من xpert.digital، وانقر على "اختبار عنوان URL". ستوضح لك الأداة بالضبط العلامات التي يتعرف عليها Google في تلك الصفحة وما إذا كانت خالية من الأخطاء.
مدقق المخططات (التركيز على الامتثال التام للمعايير):
انتقل إلى validator.schema.orgوالصق نفس الرابط. هنا يمكنك رؤية نصوص JSON-LD (البيانات المهيكلة) التي أدرجها xpert.digital مباشرةً في شفرة المصدر، مُظللةً بالألوان.
شريكك العالمي في التسويق وتطوير الأعمال
☑️ لغة أعمالنا هي الإنجليزية أو الألمانية
☑️ جديد: مراسلات بلغتك الأم!

Konrad Wolfenstein
يسعدني أنا وفريقي أن نكون متاحين لكم بصفتنا مستشاركم الشخصي.
يمكنكم التواصل معي عبر ملء نموذج الاتصال هنا wolfenstein@xpert.digital:أو الاتصال بي مباشرةً على الرقم +49 7348 4088 965. عنوان بريدي الإلكتروني هو
أتطلع إلى مشروعنا المشترك.
☑️ دعم الشركات الصغيرة والمتوسطة في مجالات الاستراتيجية والاستشارات والتخطيط والتنفيذ
☑️ إنشاء أو إعادة تنظيم الاستراتيجية الرقمية والتحول الرقمي
☑️ توسيع وتحسين عمليات المبيعات الدولية
☑️ منصات التداول العالمية والرقمية بين الشركات
☑️ تطوير الأعمال الرائدة / التسويق / العلاقات العامة / المعارض التجارية
دعم B2B وبرمجيات كخدمة (SaaS) لتحسين محركات البحث (SEO) والبحث الجغرافي (البحث المدعوم بالذكاء الاصطناعي): الحل الشامل لشركات B2B


دعم B2B وبرمجيات كخدمة (SaaS) لتحسين محركات البحث (SEO) والبحث الجغرافي (البحث المدعوم بالذكاء الاصطناعي): الحل الشامل لشركات B2B - الصورة: Xpert.Digital
البحث بالذكاء الاصطناعي يغير كل شيء: كيف سيُحدث هذا الحل البرمجي ثورة في تصنيفك في مجال الأعمال بين الشركات إلى الأبد.
يشهد المشهد الرقمي لشركات B2B تحولاً سريعاً. فبفضل الذكاء الاصطناعي، تُعاد صياغة قواعد الظهور على الإنترنت. لطالما شكل الظهور في هذا العالم الرقمي تحدياً للشركات، فضلاً عن الوصول إلى صناع القرار المناسبين. تتسم استراتيجيات تحسين محركات البحث التقليدية وإدارة الحضور المحلي (التسويق الجغرافي) بالتعقيد والاستهلاك للوقت، وغالباً ما تكون بمثابة معركة ضد خوارزميات متغيرة باستمرار ومنافسة شديدة.
لكن ماذا لو كان هناك حل لا يُبسّط هذه العملية فحسب، بل يجعلها أيضًا أكثر ذكاءً وقدرةً على التنبؤ وأكثر فعالية؟ هنا يأتي دور الجمع بين دعم متخصص للشركات (B2B) ومنصة SaaS (البرمجيات كخدمة) قوية، مصممة خصيصًا لتلبية متطلبات تحسين محركات البحث (SEO) والبحث الجغرافي (GEO) في عصر البحث المدعوم بالذكاء الاصطناعي.
لم يعد هذا الجيل الجديد من الأدوات يعتمد فقط على التحليل اليدوي للكلمات المفتاحية واستراتيجيات الروابط الخلفية، بل يستفيد من الذكاء الاصطناعي لفهم نوايا البحث بدقة أكبر، وتحسين عوامل الترتيب المحلي تلقائيًا، وإجراء تحليل تنافسي فوري. والنتيجة هي استراتيجية استباقية قائمة على البيانات تمنح شركات B2B ميزة حاسمة: فهي لا تظهر فقط في نتائج البحث، بل تُعتبر أيضًا مرجعًا رائدًا في مجال تخصصها وموقعها الجغرافي.
إليكم التكافل بين دعم الشركات (B2B) وتقنية SaaS المدعومة بالذكاء الاصطناعي التي تُحدث تحولاً في تحسين محركات البحث والتسويق الجغرافي، وكيف يمكن لشركتك الاستفادة منها لتحقيق نمو مستدام في المجال الرقمي.
للمزيد من المعلومات، انقر هنا: