الأشخاص والعمليات التي تقف وراء الذكاء الاصطناعي – @shutterstock | Zapp2Photo
يتمتع الذكاء الاصطناعي بسمعة سيئة باعتباره قاتلاً للوظائف وبديلاً للعمال البشريين. هذا هو الحال في بعض المجالات، ولكن في مناطق أخرى، لا سيما عندما يتعلق الأمر بتنظيف البيانات ومعالجتها، يقود الذكاء الاصطناعي الطريق في الوظائف الجديدة.
" وضع علامات البيانات والشرح" هي صناعة ناشئة ظهرت من الذكاء الاصطناعي. يتم تسمية سجلات البيانات غير المهيكلة من مصادر مثل الكاميرات وبيانات الوسائط الاجتماعية أو المصادر المهيكلة مثل قواعد البيانات أو وضع علامة عليها أو تلوينها أو تسليط الضوء عليها من أجل إظهار الاختلافات والتشابهات من الناس. لتدريب آلة لمعرفة ماهية علامة التوقف ، يتعين على الشخص الذهاب إلى مادة الكاميرا في الشارع وتمييز جميع علامات التوقف في الصورة. ثم تتم إضافة الجهاز إلى البيانات التي تحدد الآلاف من هذه الصور. بمرور الوقت ، يمكن للنظام التعرف بشكل أكثر دقة من خلال معالجة البيانات المحددة ما هي علامة التوقف. هذا النوع من التعلم الآلي ، الذي يصبح فيه النظام أكثر دقة من خلال تلقي المزيد من البيانات ، يسمى التعلم العميق.
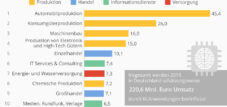
وبما أن هذه العملية ضرورية للخوارزميات لأداء الوظائف الأساسية بدقة، فإن صناعة تصنيف البيانات ستزداد أهمية على مدى السنوات الخمس المقبلة. في عام 2018، بلغت قيمة سوق إعداد بيانات الذكاء الاصطناعي والتعلم الآلي، وهي عملية تعتمد بشكل كبير على الأشخاص الذين يقومون بتسمية البيانات يدويًا، 500 مليون دولار. ومن المتوقع أن يتضاعف هذا المبلغ ليصل إلى 1.2 مليار دولار بحلول عام 2023، وفقًا لشركة Cognilytica ويتوقع مقدمو الطرف الثالث أن يزداد هذا النمو بشكل ملحوظ، حيث يرتفع من 150 مليون دولار أمريكي من السوق إلى 1 مليار دولار أمريكي خلال نفس الفترة. يعد تصنيف البيانات مهمًا بشكل خاص للذكاء الاصطناعي، الذي يتعامل مع التعرف على الأشياء والصور، والمركبات الذاتية، ووضع العلامات على النصوص والصور.
يحظى الذكاء الاصطناعي بسمعة سيئة باعتباره يقتل الوظائف ويحل محل العامل البشري. وهذا صحيح في بعض المجالات، ولكن في مجالات أخرى، لا سيما فيما يتعلق بكيفية تنظيف البيانات ومعالجتها، يقود الذكاء الاصطناعي وظائف جديدة.
تصنيف البيانات والتعليقات التوضيحية صناعة مزدهرة نشأت من الذكاء الاصطناعي. يتم تصنيف مجموعات البيانات غير المنظمة من مصادر مثل الكاميرات وبيانات وسائل التواصل الاجتماعي أو المصادر المنظمة، مثل قواعد البيانات، أو تمييزها، أو تلوينها، أو تمييزها لإظهار الاختلافات أو أوجه التشابه بين الأشخاص. لتدريب آلة على معرفة ما هي علامة التوقف، يجب على الشخص الدخول إلى لقطات الكاميرا للشارع ووضع علامات على جميع علامات التوقف في الصورة. يتم بعد ذلك تغذية الجهاز بالبيانات التي تحدد الآلاف من هذه الصور. مع مرور الوقت، يمكن للنظام تحديد علامة التوقف بدقة أكبر من خلال معالجة البيانات المصنفة. يُطلق على هذا النوع من التعلم الآلي، حيث يصبح النظام أكثر دقة من خلال تغذية المزيد من البيانات، اسم التعلم العميق.
وبما أن هذه العملية ضرورية للخوارزميات لأداء الأجزاء الأساسية من وظيفتها بدقة، فمن المقرر أن تنطلق صناعة تصنيف البيانات خلال السنوات الخمس المقبلة. في عام 2018، بلغ سوق إعداد بيانات الذكاء الاصطناعي والتعلم الآلي، وهي عملية تعتمد بشكل كبير على الأشخاص لتسمية البيانات يدويًا، 500 مليون دولار. وفقًا لـ Cognilytica ، من المتوقع أن يتضاعف هذا المبلغ ليصل إلى 1.2 مليار دولار بحلول عام 2023. ويتوقع مقدمو الطرف الثالث أن يشهدوا زيادة كبيرة في هذا النمو، حيث ينتقل من 150 مليون دولار من السوق إلى 1 مليار دولار خلال نفس الإطار الزمني. يعد تصنيف البيانات ضروريًا بشكل خاص للذكاء الاصطناعي الذي يتعامل مع التعرف على الأشياء والصور، والمركبات الذاتية، والتعليقات التوضيحية على النصوص والصور.


أبق على اتصال