Die $57 miljard-foutberekening – NVIDIA van alle maatskappye waarsku: Die KI-bedryf het die verkeerde perd gesteun – Beeld: Xpert.Digital
Vergeet die KI-reuse: Waarom die toekoms klein, gedesentraliseerd en baie goedkoper is
### Klein Taalmodelle: Die Sleutel tot Ware Besigheidsoutonomie ### Van Hiperskalers Terug na Gebruikers: Magsverskuiwing in die KI-wêreld ### Die Fout van $57 Miljard: Waarom die Ware KI-Revolusie Nie in die Wolk Gebeur Nie ### Die Stille KI-Revolusie: Gedesentraliseerd In Plaas van Gesentraliseerd ### Tegnologiereuse op die Verkeerde Spoor: Die Toekoms van KI Is Maer en Plaaslik ### Van Hiperskalers Terug na Gebruikers: Magsverskuiwing in die KI-wêreld ###
Miljarde dollars vermorste belegging: Waarom klein KI-modelle die grotes verbysteek
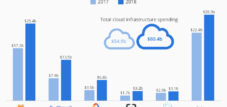
Die wêreld van kunsmatige intelligensie staar 'n aardbewing in die gesig waarvan die omvang herinner aan die regstellings van die dot-com-era. In die hart van hierdie omwenteling lê 'n kolossale wanberekening: Terwyl tegnologiereuse soos Microsoft, Google en Meta honderde miljarde belê in gesentraliseerde infrastruktuur vir massiewe taalmodelle (Groot Taalmodelle, LLM's), is die werklike mark vir hul toepassing dramaties agter. 'n Baanbrekende analise, wat gedeeltelik deur die bedryfsleier NVIDIA self uitgevoer is, kwantifiseer die gaping op $57 miljard in infrastruktuurbeleggings in vergelyking met 'n werklike mark van slegs $5,6 miljard - 'n tienvoudige verskil.
Hierdie strategiese fout spruit uit die aanname dat die toekoms van KI uitsluitlik in steeds groter, meer berekeningsintensiewe en sentraal beheerde modelle lê. Maar nou verkrummel hierdie paradigma. 'n Stil rewolusie, gedryf deur gedesentraliseerde, kleiner taalmodelle (Klein Taalmodelle, SLM's), keer die gevestigde orde op sy kop. Hierdie modelle is nie net baie keer goedkoper en meer doeltreffend nie, maar hulle stel maatskappye ook in staat om nuwe vlakke van outonomie, datasoewereiniteit en ratsheid te bereik – ver verwyderd van duur afhanklikheid van 'n paar hiperskalers. Hierdie teks analiseer die anatomie van hierdie multi-miljard dollar wanbelegging en demonstreer waarom die ware KI-rewolusie nie in reuse-datasentrums plaasvind nie, maar desentraal en op skraal hardeware. Dit is die verhaal van 'n fundamentele magsverskuiwing van die infrastruktuurverskaffers terug na die gebruikers van die tegnologie.
Geskik vir:


NVIDIA-navorsing oor KI-kapitaalwanallokasie
Die data wat jy beskryf het, kom uit 'n NVIDIA-navorsingsartikel wat in Junie 2025 gepubliseer is. Die volledige bron is:
“Klein Taalmodelle is die Toekoms van Agentiese KI”
- Skrywers: Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, Pavlo Molchanov
- Uitgawedatum: 2 Junie 2025 (Weergawe 1), laaste hersiening 15 September 2025 (Weergawe 2)
- Publikasieligging: arXiv:2506.02153 [cs.AI]
- DOI: https://doi.org/10.48550/arXiv.2506.02153
- Amptelike NVIDIA Navorsingsbladsy: https://research.nvidia.com/labs/lpr/slm-agents/
Die kernboodskap rakende kapitaalwanallokasie
Die navorsing dokumenteer 'n fundamentele verskil tussen infrastruktuurbeleggings en werklike markvolume: In 2024 het die bedryf $57 miljard in wolkinfrastruktuur belê om Large Language Model (LLM) API-dienste te ondersteun, terwyl die werklike mark vir hierdie dienste slegs $5,6 miljard was. Hierdie tien-tot-een-verskil word in die studie geïnterpreteer as 'n aanduiding van 'n strategiese wanberekening, aangesien die bedryf swaar belê het in gesentraliseerde infrastruktuur vir grootskaalse modelle, alhoewel 40-70% van die huidige LLM-werkladings teen 1/30ste van die koste deur kleiner, gespesialiseerde Small Language Models (SLM's) vervang kon word.
Navorsingskonteks en outeurskap
Hierdie studie is 'n posisievraestel van die Deep Learning Efficiency Research Group by NVIDIA Research. Hoofskrywer Peter Belcak is 'n KI-navorser by NVIDIA wat fokus op die betroubaarheid en doeltreffendheid van agent-gebaseerde stelsels. Die artikel argumenteer op drie pilare:
SLM's is
- voldoende kragtig
- chirurgies geskik en
- ekonomies noodsaaklik
vir baie gebruiksgevalle in agentiese KI-stelsels.
Die navorsers beklemtoon uitdruklik dat die menings wat in hierdie artikel uitgespreek word, dié van die outeurs is en nie noodwendig die posisie van NVIDIA as 'n maatskappy weerspieël nie. NVIDIA nooi kritiese bespreking uit en verbind hulle daartoe om enige verwante korrespondensie op die meegaande webwerf te publiseer.
Waarom gedesentraliseerde klein taalmodelle die gesentraliseerde infrastruktuurweddenskap verouderd maak
Kunsmatige intelligensie is op 'n keerpunt, waarvan die implikasies herinner aan die omwentelinge van die dot-com-borrel. 'n Navorsingsartikel deur NVIDIA het 'n fundamentele wanallokasie van kapitaal aan die lig gebring wat die fondamente van sy huidige KI-strategie skud. Terwyl die tegnologiebedryf $57 miljard in gesentraliseerde infrastruktuur vir grootskaalse taalmodelle belê het, het die werklike mark vir hul gebruik tot slegs $5,6 miljard gegroei. Hierdie tien-tot-een-verskil dui nie net op 'n oorskatting van vraag nie, maar lê ook 'n fundamentele strategiese fout rakende die toekoms van kunsmatige intelligensie bloot.
’n Slegte belegging? Miljarde bestee aan KI-infrastruktuur – wat om met die oortollige kapasiteit te doen?
Die syfers spreek vanself. In 2024 het wêreldwye besteding aan KI-infrastruktuur tussen $80 en $87 miljard bereik, volgens verskeie ontledings, met datasentrums en versnellers wat die oorgrote meerderheid uitmaak. Microsoft het beleggings van $80 miljard vir fiskale jaar 2025 aangekondig, Google het sy voorspelling verhoog tot tussen $91 en $93 miljard, en Meta beplan om tot $70 miljard te belê. Hierdie drie hiperskalers alleen verteenwoordig 'n beleggingsvolume van meer as $240 miljard. Totale besteding aan KI-infrastruktuur kan teen 2030 tussen $3,7 en $7,9 triljoen bereik, volgens McKinsey-ramings.
In teenstelling hiermee is die realiteit aan die vraagkant ontnugterend. Die mark vir Groot Taalmodelle vir Ondernemings is geraam op slegs $4 tot $6,7 miljard vir 2024, met projeksies vir 2025 wat wissel van $4,8 tot $8 miljard. Selfs die vrygewigste ramings vir die Generatiewe KI-mark as geheel is tussen $28 en $44 miljard vir 2024. Die fundamentele verskil is duidelik: die infrastruktuur is gebou vir 'n mark wat nie in hierdie vorm en omvang bestaan nie.
Hierdie wanbelegging spruit voort uit 'n aanname wat toenemend vals blyk te wees: dat die toekoms van KI in steeds groter, gesentraliseerde modelle lê. Hiperskaleraars het 'n strategie van massiewe skalering gevolg, gedryf deur die oortuiging dat parametertelling en rekenaarkrag die deurslaggewende mededingende faktore was. GPT-3, met 175 miljard parameters, is in 2020 as 'n deurbraak beskou, en GPT-4, met meer as 'n triljoen parameters, het nuwe standaarde gestel. Die bedryf het hierdie logika blindelings gevolg en belê in 'n infrastruktuur wat ontwerp is vir die behoeftes van modelle wat vir die meeste gebruiksgevalle oorgroot is.
Die beleggingstruktuur illustreer die wanallokasie duidelik. In die tweede kwartaal van 2025 het 98 persent van die $82 miljard wat aan KI-infrastruktuur bestee is, na bedieners gegaan, met 91,8 persent daarvan na GPU- en XPU-versnelde stelsels. Hiperskalers en wolkbouers het 86,7 persent van hierdie uitgawes geabsorbeer, ongeveer $71 miljard in 'n enkele kwartaal. Hierdie konsentrasie van kapitaal in hoogs gespesialiseerde, uiters energie-intensiewe hardeware vir die opleiding en afleiding van massiewe modelle het 'n fundamentele ekonomiese werklikheid geïgnoreer: die meeste ondernemingstoepassings benodig nie hierdie kapasiteit nie.
Die paradigma breek: Van gesentraliseerd na gedesentraliseerd
NVIDIA self, die hoofbegunstigde van die onlangse infrastruktuur-oplewing, verskaf nou die analise wat hierdie paradigma uitdaag. Navorsing oor klein taalmodelle as die toekoms van agent-gebaseerde KI voer aan dat modelle met minder as 10 miljard parameters nie net voldoende is nie, maar ook operasioneel beter is vir die oorgrote meerderheid van KI-toepassings. Die studie van drie groot oopbron-agentstelsels het aan die lig gebring dat 40 tot 70 persent van oproepe na groot taalmodelle vervang kan word deur gespesialiseerde klein modelle sonder enige prestasieverlies.
Hierdie bevindinge skud die fundamentele aannames van die bestaande beleggingstrategie. As MetaGPT 60 persent van sy LLM-oproepe, Open Operator 40 persent en Cradle 70 persent met SLM'e kan vervang, dan is infrastruktuurkapasiteit gebou vir eise wat nie op hierdie skaal bestaan nie. Die ekonomie verander dramaties: 'n Llama 3.1B Small Language Model kos tien tot dertig keer minder om te bedryf as sy groter eweknie, Llama 3.3 405B. Fyn afstemming kan binne 'n paar GPU-ure in plaas van weke bewerkstellig word. Baie SLM'e loop op verbruikershardeware, wat wolkafhanklikhede heeltemal uitskakel.
Die strategiese verskuiwing is fundamenteel. Beheer skuif van infrastruktuurverskaffers na operateurs. Terwyl die vorige argitektuur maatskappye in 'n posisie van afhanklikheid van 'n paar hiperskalers gedwing het, maak desentralisasie deur middel van SLM's nuwe outonomie moontlik. Modelle kan plaaslik bedryf word, data bly binne die maatskappy, API-koste word uitgeskakel en verskaffersbinding word verbreek. Dit is nie net 'n tegnologiese transformasie nie, maar 'n transformasie van magspolitiek.
Die vorige weddenskap op gesentraliseerde grootskaalse modelle was gebaseer op die aanname van eksponensiële skaleringseffekte. Empiriese data weerspreek dit egter toenemend. Microsoft Phi-3, met 7 miljard parameters, behaal kodegenereringsprestasie vergelykbaar met modelle van 70 miljard parameters. NVIDIA Nemotron Nano 2, met 9 miljard parameters, oortref Qwen3-8B in redenasiemaatstawwe met ses keer die deurset. Doeltreffendheid per parameter neem toe met kleiner modelle, terwyl groot modelle dikwels slegs 'n fraksie van hul parameters vir 'n gegewe invoer aktiveer - 'n inherente ondoeltreffendheid.
Die ekonomiese meerderwaardigheid van klein taalmodelle
Die kostestruktuur onthul die ekonomiese realiteit met brutale helderheid. Die opleiding van GPT-4-klasmodelle word op meer as $100 miljoen geraam, met Gemini Ultra wat moontlik $191 miljoen kos. Selfs die fyn afstelling van groot modelle vir spesifieke domeine kan tienduisende dollars in GPU-tyd kos. In teenstelling hiermee kan SLM's vir slegs 'n paar duisend dollar opgelei en fyn afgestel word, dikwels op 'n enkele hoë-end GPU.
Die inferensiekoste toon selfs meer drastiese verskille. GPT-4 kos ongeveer $0,03 per 1 000 invoertokens en $0,06 per 1 000 uitvoertokens, wat altesaam $0,09 per gemiddelde navraag is. Mistral 7B, as 'n SLM-voorbeeld, kos $0,0001 per 1 000 invoertokens en $0,0003 per 1 000 uitvoertokens, of $0,0004 per navraag. Dit verteenwoordig 'n kostevermindering met 'n faktor van 225. Met miljoene navrae tel hierdie verskil op tot aansienlike bedrae wat 'n direkte impak op winsgewendheid het.
Die totale koste van eienaarskap onthul verdere dimensies. Die selfhosting van 'n 7-miljard-parametermodel op kaalmetaalbedieners met L40S GPU's kos ongeveer $953 per maand. Wolkgebaseerde fyn afstemming met AWS SageMaker op g5.2xlarge-instansies kos $1.32 per uur, met potensiële opleidingskoste wat begin by $13 vir kleiner modelle. 24/7-inferensie-ontplooiing sou ongeveer $950 per maand kos. In vergelyking met API-koste vir deurlopende gebruik van groot modelle, wat maklik tienduisende dollars per maand kan bereik, word die ekonomiese voordeel duidelik.
Die spoed van implementering is 'n dikwels onderskatte ekonomiese faktor. Terwyl die fyn afstelling van 'n Groot Taalmodel weke kan neem, is SLM'e binne ure of 'n paar dae gereed vir gebruik. Die ratsheid om vinnig op nuwe vereistes te reageer, nuwe vermoëns by te voeg of gedrag aan te pas, word 'n mededingende voordeel. In vinnig ontwikkelende markte kan hierdie tydsverskil die verskil tussen sukses en mislukking wees.
Die ekonomie van skaal is besig om om te keer. Tradisioneel is skaalvoordele gesien as die voordeel van hiperskalers, wat enorme kapasiteite handhaaf en dit oor baie kliënte versprei. Met SLM'e kan selfs kleiner organisasies egter doeltreffend skaal omdat die hardewarevereistes drasties laer is. 'n Opstartonderneming kan 'n gespesialiseerde SLM met 'n beperkte begroting bou wat 'n groot, generalistiese model vir sy spesifieke taak oortref. Die demokratisering van KI-ontwikkeling word 'n ekonomiese werklikheid.
Tegniese grondbeginsels van ontwrigting
Die tegnologiese innovasies wat SLM'e moontlik maak, is net so betekenisvol soos hul ekonomiese implikasies. Kennisdistillasie, 'n tegniek waarin 'n kleiner studentemodel die kennis van 'n groter onderwysermodel absorbeer, het bewys dat dit hoogs effektief is. DistilBERT het BERT suksesvol saamgepers, en TinyBERT het soortgelyke beginsels gevolg. Moderne benaderings distilleer die vermoëns van groot generatiewe modelle soos GPT-3 in aansienlik kleiner weergawes wat vergelykbare of beter prestasie in spesifieke take toon.
Die proses gebruik beide die sagte etikette (waarskynlikheidsverspreidings) van die onderwysermodel en die harde etikette van die oorspronklike data. Hierdie kombinasie laat die kleiner model toe om genuanseerde patrone vas te lê wat verlore sou gaan in eenvoudige invoer-uitvoerpare. Gevorderde distillasietegnieke, soos stap-vir-stap distillasie, het getoon dat klein modelle beter resultate as LLM's kan behaal, selfs met minder opleidingsdata. Dit verander die ekonomie fundamenteel: in plaas van duur, langdurige opleidingslopies op duisende GPU's, is geteikende distillasieprosesse voldoende.
Kwantisering verminder die akkuraatheid van die numeriese voorstelling van modelgewigte. In plaas van 32-bis of 16-bis drywende kommagetalle, gebruik gekwantiseerde modelle 8-bis of selfs 4-bis heelgetalvoorstellings. Geheuevereistes neem proporsioneel af, inferensiespoed neem toe en kragverbruik daal. Moderne kwantiseringstegnieke verminder die verlies aan akkuraatheid, wat dikwels prestasie feitlik onveranderd laat. Dit maak ontplooiing op randtoestelle, slimfone en ingebedde stelsels moontlik wat onmoontlik sou wees met volledig presiese groot modelle.
Snoei verwyder oorbodige verbindings en parameters van neurale netwerke. Soortgelyk aan die redigering van 'n te lang teks, word nie-essensiële elemente geïdentifiseer en uitgeskakel. Gestruktureerde snoei verwyder hele neurone of lae, terwyl ongestruktureerde snoei individuele gewigte verwyder. Die gevolglike netwerkstruktuur is meer doeltreffend, benodig minder geheue en verwerkingskrag, maar behou sy kernvermoëns. Gekombineer met ander kompressietegnieke behaal gesnoeide modelle indrukwekkende doeltreffendheidswinste.
Lae-rang faktorisering ontbind groot gewigsmatrikse in produkte van kleiner matrikse. In plaas van 'n enkele matriks met miljoene elemente, stoor en verwerk die stelsel twee aansienlik kleiner matrikse. Die wiskundige bewerking bly ongeveer dieselfde, maar die berekeningspoging word dramaties verminder. Hierdie tegniek is veral effektief in transformatorargitekture, waar aandagmeganismes groot matriksvermenigvuldigings oorheers. Die geheuebesparing maak voorsiening vir groter konteksvensters of bondelgroottes met dieselfde hardewarebegroting.
Die kombinasie van hierdie tegnieke in moderne SLM'e soos die Microsoft Phi-reeks, Google Gemma of NVIDIA Nemotron demonstreer die potensiaal. Die Phi-2, met slegs 2,7 miljard parameters, oortref Mistral- en Llama-2-modelle met onderskeidelik 7 en 13 miljard parameters in geaggregeerde maatstawwe en behaal beter werkverrigting as die 25 keer groter Llama-2-70B in meerstap-redeneringstake. Dit is bereik deur strategiese dataseleksie, hoëgehalte-sintetiese datagenerering en innoverende skaleringstegnieke. Die boodskap is duidelik: grootte is nie meer 'n plaasvervanger vir vermoë nie.
Markdinamika en vervangingspotensiaal
Empiriese bevindinge van werklike toepassings ondersteun die teoretiese oorwegings. NVIDIA se analise van MetaGPT, 'n multi-agent sagteware-ontwikkelingsraamwerk, het geïdentifiseer dat ongeveer 60 persent van LLM-versoeke vervangbaar is. Hierdie take sluit in standaardkodegenerering, dokumentasie-skepping en gestruktureerde uitvoer – alles gebiede waar gespesialiseerde SLM'e vinniger en meer koste-effektief presteer as algemene, grootskaalse modelle.
Open Operator, 'n werkvloei-outomatiseringstelsel, demonstreer met sy 40 persent vervangingspotensiaal dat selfs in komplekse orkestreringscenario's, baie subtake nie die volle kapasiteit van LLM's vereis nie. Intentie-ontleding, sjabloongebaseerde uitvoer en roeteringsbesluite kan meer doeltreffend hanteer word deur fyn afgestelde, klein modelle. Die oorblywende 60 persent, wat eintlik diepgaande redenasie of breë wêreldkennis vereis, regverdig die gebruik van groot modelle.
Cradle, 'n GUI-outomatiseringstelsel, toon die hoogste vervangingspotensiaal teen 70 persent. Herhalende UI-interaksies, klikreekse en vorminskrywings is ideaal geskik vir SLM'e. Die take is eng gedefinieer, die veranderlikheid is beperk en die vereistes vir kontekstuele begrip is laag. 'n Gespesialiseerde model wat op GUI-interaksies opgelei is, oortref 'n generalistiese LLM in spoed, betroubaarheid en koste.
Hierdie patrone herhaal hulself oor toepassingsgebiede. Kliëntediens-kletsbots vir algemene vrae, dokumentklassifikasie, sentimentanalise, benoemde entiteitsherkenning, eenvoudige vertalings, natuurliketaaldatabasisnavrae – al hierdie take trek voordeel uit SLM'e. Een studie skat dat in tipiese ondernemings-KI-implementerings 60 tot 80 persent van navrae in kategorieë val waarvoor SLM'e voldoende is. Die implikasies vir infrastruktuurvraag is beduidend.
Die konsep van modelroetering word al hoe belangriker. Intelligente stelsels analiseer inkomende navrae en roeteer dit na die toepaslike model. Eenvoudige navrae gaan na koste-effektiewe SLM'e, terwyl komplekse take deur hoëprestasie-LLM'e hanteer word. Hierdie hibriede benadering optimaliseer die balans tussen kwaliteit en koste. Vroeë implementerings rapporteer kostebesparings van tot 75 persent met dieselfde of selfs beter algehele prestasie. Die roeteerlogika self kan 'n klein masjienleermodel wees wat navraagkompleksiteit, konteks en gebruikersvoorkeure in ag neem.
Die verspreiding van fyn-afstemming-as-'n-diens-platforms versnel die aanvaarding daarvan. Maatskappye sonder diepgaande masjienleerkundigheid kan gespesialiseerde SLM'e bou wat hul eie data en domeinspesifieke inligting insluit. Die tydsbelegging word verminder van maande na dae, en die koste van honderdduisende dollars na duisende. Hierdie toeganklikheid demokratiseer fundamenteel KI-innovasie en verskuif waardeskepping van infrastruktuurverskaffers na toepassingsontwikkelaars.
'n Nuwe dimensie van digitale transformasie met 'Bestuurde KI' (Kunsmatige Intelligensie) - Platform & B2B-oplossing | Xpert Consulting


'n Nuwe dimensie van digitale transformasie met 'Bestuurde KI' (Kunsmatige Intelligensie) – Platform & B2B-oplossing | Xpert Consulting - Beeld: Xpert.Digital
Hier sal jy leer hoe jou maatskappy pasgemaakte KI-oplossings vinnig, veilig en sonder hoë toetreehindernisse kan implementeer.
’n Bestuurde KI-platform is jou allesomvattende, sorgvrye pakket vir kunsmatige intelligensie. In plaas daarvan om met komplekse tegnologie, duur infrastruktuur en lang ontwikkelingsprosesse te sukkel, ontvang jy ’n kant-en-klare oplossing wat op jou behoeftes afgestem is van ’n gespesialiseerde vennoot – dikwels binne ’n paar dae.
Die belangrikste voordele in 'n oogopslag:
⚡ Vinnige implementering: Van idee tot operasionele toepassing in dae, nie maande nie. Ons lewer praktiese oplossings wat onmiddellike waarde skep.
🔒 Maksimum datasekuriteit: Jou sensitiewe data bly by jou. Ons waarborg veilige en voldoenende verwerking sonder om data met derde partye te deel.
💸 Geen finansiële risiko: Jy betaal slegs vir resultate. Hoë voorafbeleggings in hardeware, sagteware of personeel word heeltemal uitgeskakel.
🎯 Fokus op jou kernbesigheid: Konsentreer op wat jy die beste doen. Ons hanteer die hele tegniese implementering, bedryf en instandhouding van jou KI-oplossing.
📈 Toekomsbestand en skaalbaar: Jou KI groei saam met jou. Ons verseker voortdurende optimalisering en skaalbaarheid, en pas die modelle buigsaam aan by nuwe vereistes.
Meer daaroor hier:
Hoe gedesentraliseerde KI maatskappye miljarde in koste bespaar
Die verborge koste van gesentraliseerde argitekture
Deur slegs op direkte berekeningskoste te fokus, word die totale koste van gesentraliseerde LLM-argitekture onderskat. API-afhanklikhede skep strukturele nadele. Elke versoek genereer koste wat met gebruik skaal. Vir suksesvolle toepassings met miljoene gebruikers word API-fooie die dominante kostefaktor, wat marges erodeer. Maatskappye is vasgevang in 'n kostestruktuur wat proporsioneel tot sukses groei, sonder ooreenstemmende skaalvoordele.
Die pryswisselvalligheid van API-verskaffers hou 'n sakerisiko in. Prysverhogings, kwotabeperkings of veranderinge aan diensbepalings kan 'n toepassing se winsgewendheid oornag vernietig. Die onlangs aangekondigde kapasiteitsbeperkings deur groot verskaffers, wat gebruikers dwing om hul hulpbronne te rantsoeneer, illustreer die kwesbaarheid van hierdie afhanklikheid. Toegewyde SLM'e elimineer hierdie risiko heeltemal.
Datasoewereiniteit en -nakoming word al hoe belangriker. GDPR in Europa, vergelykbare regulasies wêreldwyd en toenemende datalokaliseringsvereistes skep komplekse wetlike raamwerke. Die stuur van sensitiewe korporatiewe data na eksterne API's wat in buitelandse jurisdiksies mag werk, hou regulatoriese en wetlike risiko's in. Gesondheidsorg-, finansie- en regeringsektore het dikwels streng vereistes wat die gebruik van eksterne API's uitsluit of ernstig beperk. On-premise SLM's los hierdie probleme fundamenteel op.
Intellektuele eiendomsbekommernisse is werklik. Elke versoek wat na 'n API-verskaffer gestuur word, kan moontlik eiendomsinligting blootstel. Besigheidslogika, produkontwikkelings, kliëntinligting – dit alles kan teoreties onttrek en deur die verskaffer gebruik word. Kontrakklousules bied beperkte beskerming teen toevallige lekkasies of kwaadwillige akteurs. Die enigste werklik veilige oplossing is om nooit data te eksternaliseer nie.
Latensie en betroubaarheid ly onder netwerkafhanklikhede. Elke wolk-API-versoek deurkruis internetinfrastruktuur, onderhewig aan netwerkjitter, pakkieverlies en veranderlike heen-en-weer-tye. Vir intydse toepassings soos gespreks-KI of beheerstelsels, is hierdie vertragings onaanvaarbaar. Plaaslike SLM'e reageer in millisekondes in plaas van sekondes, ongeag die netwerktoestande. Die gebruikerservaring word aansienlik verbeter.
Strategiese afhanklikheid van 'n paar hiperskalers konsentreer mag en skep sistemiese risiko's. AWS, Microsoft Azure, Google Cloud en 'n paar ander oorheers die mark. Onderbrekings van hierdie dienste het waterval-effekte oor duisende afhanklike toepassings. Die illusie van oortolligheid verdwyn wanneer jy in ag neem dat die meeste alternatiewe dienste uiteindelik op dieselfde beperkte stel modelverskaffers staatmaak. Ware veerkragtigheid vereis diversifikasie, ideaal gesproke insluitend interne kapasiteit.
Geskik vir:

Randrekenaars as 'n strategiese keerpunt
Die konvergensie van SLM'e en randrekenaars skep 'n transformerende dinamiek. Randontplooiing bring berekening na waar data ontstaan – IoT-sensors, mobiele toestelle, industriële beheerders en voertuie. Die latensievermindering is dramaties: van sekondes tot millisekondes, van wolk-heen-en-weer-reis tot plaaslike verwerking. Vir outonome stelsels, toegevoegde realiteit, industriële outomatisering en mediese toestelle is dit nie net wenslik nie, maar noodsaaklik.
Die bandwydtebesparings is aansienlik. In plaas van deurlopende datastrome na die wolk, waar dit verwerk word en resultate teruggestuur word, vind verwerking plaas. Slegs relevante, geaggregeerde inligting word oorgedra. In scenario's met duisende randtoestelle verminder dit netwerkverkeer met ordes van grootte. Infrastruktuurkoste verminder, netwerkopeenhoping word vermy en betroubaarheid neem toe.
Privaatheid word inherent beskerm. Data verlaat nie meer die toestel nie. Kameravoere, klankopnames, biometriese inligting, liggingsdata – dit alles kan plaaslik verwerk word sonder om sentrale bedieners te bereik. Dit los fundamentele privaatheidskwessies op wat deur wolkgebaseerde KI-oplossings geopper word. Vir verbruikerstoepassings word dit 'n onderskeidende faktor; vir gereguleerde nywerhede word dit 'n vereiste.
Energie-doeltreffendheid verbeter op verskeie vlakke. Gespesialiseerde rand-KI-skyfies, geoptimaliseer vir die afleiding van klein modelle, verbruik 'n fraksie van die energie van datasentrum-GPU's. Die uitskakeling van data-oordrag bespaar energie in netwerkinfrastruktuur. Vir battery-aangedrewe toestelle word dit 'n kernfunksie. Slimfone, draagbare toestelle, hommeltuie en IoT-sensors kan KI-funksies verrig sonder om die batterylewe dramaties te beïnvloed.
Vanlynvermoë skep robuustheid. Edge KI werk ook sonder 'n internetverbinding. Funksionaliteit word gehandhaaf in afgeleë streke, kritieke infrastruktuur of rampscenario's. Hierdie onafhanklikheid van netwerkbeskikbaarheid is noodsaaklik vir baie toepassings. 'n Outonome voertuig kan nie op wolkkonnektiwiteit staatmaak nie, en 'n mediese toestel moet nie faal as gevolg van onstabiele Wi-Fi nie.
Kostemodelle verskuif van operasionele na kapitaaluitgawes. In plaas van deurlopende wolkkoste, is daar 'n eenmalige belegging in randhardeware. Dit word ekonomies aantreklik vir langdurige, hoëvolume-toepassings. Voorspelbare koste verbeter begrotingsbeplanning en verminder finansiële risiko's. Maatskappye herwin beheer oor hul KI-infrastruktuurbesteding.
Voorbeelde demonstreer die potensiaal. NVIDIA ChatRTX maak plaaslike LLM-inferensie op verbruikers-GPU's moontlik. Apple integreer KI op toestelle in iPhones en iPads, met kleiner modelle wat direk op die toestel loop. Qualcomm ontwikkel NPU's vir slimfone spesifiek vir rand-KI. Google Coral en soortgelyke platforms teiken IoT- en industriële toepassings. Markdinamika toon 'n duidelike neiging tot desentralisasie.
Heterogene KI-argitekture as 'n toekomstige model
Die toekoms lê nie in absolute desentralisasie nie, maar in intelligente hibriede argitekture. Heterogene stelsels kombineer rand-SLM's vir roetine, latensie-sensitiewe take met wolk-LLM's vir komplekse redenasievereistes. Hierdie komplementariteit maksimeer doeltreffendheid terwyl buigsaamheid en vermoë behoue bly.
Die stelselargitektuur bestaan uit verskeie lae. Aan die randlaag bied hoogs geoptimaliseerde SLM'e onmiddellike reaksies. Daar word verwag dat hierdie 60 tot 80 persent van versoeke outonoom sal hanteer. Vir dubbelsinnige of komplekse navrae wat nie aan plaaslike vertrouensdrempels voldoen nie, vind eskalasie plaas na die misrekenaarlaag – streeksbedieners met middelreeksmodelle. Slegs werklik moeilike gevalle bereik die sentrale wolkinfrastruktuur met groot, algemene modelle.
Modelroetering word 'n kritieke komponent. Masjienleer-gebaseerde routers analiseer versoekkenmerke: tekslengte, kompleksiteitsaanwysers, domeinseine en gebruikersgeskiedenis. Gebaseer op hierdie kenmerke word die versoek aan die toepaslike model toegeken. Moderne routers bereik meer as 95% akkuraatheid in kompleksiteitsberaming. Hulle optimaliseer voortdurend gebaseer op werklike werkverrigting en koste-kwaliteit-afwegings.
Kruis-aandagmeganismes in gevorderde roetestelsels modelleer eksplisiet navraag-model-interaksies. Dit maak genuanseerde besluite moontlik: Is Mistral-7B voldoende, of is GPT-4 nodig? Kan Phi-3 dit hanteer, of is Claude nodig? Die fynkorrelige aard van hierdie besluite, vermenigvuldig oor miljoene navrae, genereer aansienlike kostebesparings terwyl gebruikerstevredenheid gehandhaaf of verbeter word.
Werklaskarakterisering is fundamenteel. Agentiese KI-stelsels bestaan uit orkestrering, redenasie, gereedskapoproepe, geheuebewerkings en uitvoergenerering. Nie alle komponente benodig dieselfde berekeningskapasiteit nie. Orkestrering en gereedskapoproepe is dikwels reëlgebaseerd of vereis minimale intelligensie – ideaal vir SLM'e. Redenering kan hibriede wees: eenvoudige afleiding op SLM'e, komplekse meerstap-redenasie op LLM'e. Uitvoergenerering vir sjablone gebruik SLM'e, kreatiewe teksgenerering gebruik LLM'e.
Totale Koste van Eienaarskap (TCO) optimalisering neem hardeware-heterogeniteit in ag. Hoë-end H100 GPU's word gebruik vir kritieke LLM-werkladings, middelvlak A100 of L40S vir middelreeksmodelle, en koste-effektiewe T4- of inferensie-geoptimaliseerde skyfies vir SLM's. Hierdie granulariteit maak voorsiening vir presiese ooreenstemming van werkladingvereistes met hardewarevermoëns. Aanvanklike studies toon 'n vermindering van 40 tot 60 persent in TCO in vergelyking met homogene hoë-end ontplooiings.
Orkestrering vereis gesofistikeerde sagtewarestapels. Kubernetes-gebaseerde klusterbestuurstelsels, aangevul deur KI-spesifieke skeduleerders wat modelkenmerke verstaan, is noodsaaklik. Lasbalansering oorweeg nie net versoeke per sekonde nie, maar ook tekenlengtes, modelgeheue-voetspore en latensieteikens. Outomatiese skalering reageer op vraagpatrone, voorsien addisionele kapasiteit of skaal af gedurende periodes van lae gebruik.
Volhoubaarheid en energiedoeltreffendheid
Die omgewingsimpak van KI-infrastruktuur word 'n sentrale kwessie. Die opleiding van 'n enkele groot taalmodel kan soveel energie verbruik as 'n klein dorpie in 'n jaar. Datasentrums wat KI-werkladings bedryf, kan teen 2028 20 tot 27 persent van die wêreldwye energievraag van datasentrums uitmaak. Projeksies beraam dat KI-datasentrums teen 2030 8 gigawatt vir individuele opleidingslopies kan benodig. Die koolstofvoetspoor sal vergelykbaar wees met dié van die lugvaartbedryf.
Die energie-intensiteit van groot modelle neem oneweredig toe. GPU-kragverbruik het in drie jaar verdubbel van 400 tot meer as 1000 watt. NVIDIA GB300 NVL72-stelsels benodig enorme hoeveelhede energie, ten spyte van innoverende kragversagtingstegnologie wat pieklas met 30 persent verminder. Verkoelingsinfrastruktuur voeg nog 30 tot 40 persent by die energievraag. Totale CO2-uitlatings van KI-infrastruktuur kan teen 2030 met 220 miljoen ton toeneem, selfs met optimistiese aannames oor netwerkdekarbonisering.
Klein Taalmodelle (SLM's) bied fundamentele doeltreffendheidswinste. Opleiding vereis 30 tot 40 persent van die rekenaarkrag van vergelykbare LLM's. BERT-opleiding kos ongeveer €10 000, in vergelyking met honderde miljoene vir GPT-4-klasmodelle. Inferensie-energie is proporsioneel laer. 'n SLM-navraag kan 100 tot 1 000 keer minder energie verbruik as 'n LLM-navraag. Oor miljoene navrae tel dit op tot enorme besparings.
Randrekenaars versterk hierdie voordele. Plaaslike verwerking elimineer die energie wat benodig word vir data-oordrag oor netwerke en ruggraatinfrastruktuur. Gespesialiseerde rand-KI-skyfies bereik energie-doeltreffendheidsfaktore ordes van grootte beter as datasentrum-GPU's. Slimfone en IoT-toestelle met milliwatt-NPU's in plaas van honderde watt bedieners illustreer die verskil in skaal.
Die gebruik van hernubare energie word 'n prioriteit. Google is verbind tot 100 persent koolstofvrye energie teen 2030, en Microsoft tot koolstofnegatiwiteit. Die blote omvang van energievraag bied egter uitdagings. Selfs met hernubare bronne bly die vraag na netwerkkapasiteit, berging en intermittensie. SLM'e verminder die absolute vraag, wat die oorgang na groen KI meer haalbaar maak.
Koolstofbewuste berekening optimaliseer werkladingskedulering gebaseer op die koolstofintensiteit van die netwerk. Opleidingslopies word begin wanneer die aandeel hernubare energie in die netwerk op sy maksimum is. Inferensieversoeke word na streke met skoner energie gestuur. Hierdie temporale en geografiese buigsaamheid, gekombineer met die doeltreffendheid van SLM'e, kan CO2-uitlatings met 50 tot 70 persent verminder.
Die regulatoriese landskap word strenger. Die EU-KI-wet sluit verpligte omgewingsimpakstudies vir sekere KI-stelsels in. Koolstofverslagdoening word standaard. Maatskappye met ondoeltreffende, energie-intensiewe infrastruktuur loop die risiko van nakomingsprobleme en reputasieskade. Die aanvaarding van SLM'e en randrekenaars ontwikkel van 'n lekker-om-te-hê na 'n noodsaaklikheid.
Demokratisering teenoor konsentrasie
Vorige ontwikkelings het KI-mag in die hande van 'n paar sleutelspelers gekonsentreer. Die Magnificent Seven – Microsoft, Google, Meta, Amazon, Apple, NVIDIA en Tesla – oorheers. Hierdie hiperskalers beheer infrastruktuur, modelle en toenemend die hele waardeketting. Hul gekombineerde markkapitalisasie oorskry $15 triljoen. Hulle verteenwoordig byna 35 persent van die S&P 500-markkapitalisasie, 'n konsentrasierisiko van ongekende historiese betekenis.
Hierdie konsentrasie het sistemiese implikasies. 'n Paar maatskappye stel standaarde, definieer API's en beheer toegang. Kleiner spelers en ontwikkelende lande word afhanklik. Die digitale soewereiniteit van nasies word uitgedaag. Europa, Asië en Latyns-Amerika reageer met nasionale KI-strategieë, maar die oorheersing van VSA-gebaseerde hiperskalers bly oorweldigend.
Klein Taalmodelle (SLM's) en desentralisasie verskuif hierdie dinamiek. Oopbron-SLM's soos Phi-3, Gemma, Mistral en Llama demokratiseer toegang tot die nuutste tegnologie. Universiteite, opstartondernemings en mediumgrootte besighede kan mededingende toepassings ontwikkel sonder hiperskaalhulpbronne. Die innovasieversperring word dramaties verlaag. 'n Klein span kan 'n gespesialiseerde SLM skep wat Google of Microsoft in sy nis oortref.
Ekonomiese lewensvatbaarheid verskuif ten gunste van kleiner spelers. Terwyl LLM-ontwikkeling begrotings van honderde miljoene vereis, is SLM's haalbaar met vyf- tot sessyferbedrae. Wolkdemokratisering maak toegang tot opleidingsinfrastruktuur op aanvraag moontlik. Fyn afstemming van dienste abstraheer kompleksiteit. Die toetredeversperring vir KI-innovasie neem af van onbetaalbaar hoog tot hanteerbaar.
Datasoewereiniteit word 'n realiteit. Maatskappye en regerings kan modelle huisves wat nooit eksterne bedieners bereik nie. Sensitiewe data bly onder hul eie beheer. GDPR-nakoming word vereenvoudig. Die EU-KI-wet, wat streng vereistes vir deursigtigheid en verantwoordbaarheid stel, word meer hanteerbaar met eie modelle in plaas van swartboks-API's.
Innovasiediversiteit neem toe. In plaas van 'n monokultuur van GPT-agtige modelle, ontstaan duisende gespesialiseerde SLM'e vir spesifieke domeine, tale en take. Hierdie diversiteit is bestand teen sistematiese foute, verhoog mededinging en versnel vordering. Die innovasielandskap word polisentries eerder as hiërargies.
Die risiko's van konsentrasie word duidelik. Afhanklikheid van 'n paar verskaffers skep enkele punte van mislukking. Onderbrekings by AWS of Azure verlam globale dienste. Politieke besluite deur 'n hiperskaler, soos gebruiksbeperkings of streeksuitsluitings, het waterval-effekte. Desentralisasie deur SLM'e verminder hierdie sistemiese risiko's fundamenteel.
Die strategiese herbelyning
Vir maatskappye impliseer hierdie analise fundamentele strategiese aanpassings. Beleggingsprioriteite verskuif van gesentraliseerde wolkinfrastruktuur na heterogene, verspreide argitekture. In plaas van maksimum afhanklikheid van hiperskaal-API's, is die doel outonomie deur interne SLM'e. Vaardigheidsontwikkeling fokus op modelverfyning, randontplooiing en hibriede orkestrering.
Die bou-versus-koop-besluit is besig om te verskuif. Terwyl die aankoop van API-toegang voorheen as rasioneel beskou is, word die ontwikkeling van interne, gespesialiseerde SLM'e toenemend aantreklik. Die totale koste van eienaarskap oor drie tot vyf jaar bevoordeel duidelik interne modelle. Strategiese beheer, datasekuriteit en aanpasbaarheid voeg verdere kwalitatiewe voordele by.
Vir beleggers dui hierdie wanallokasie op versigtigheid rakende suiwer infrastruktuurbeleggings. Datasentrum-REIT's, GPU-vervaardigers en hiperskalers kan oorkapasiteit en dalende benutting ervaar as die vraag nie soos voorspel realiseer nie. Waardemigrasie vind plaas na verskaffers van SLM-tegnologie, rand-KI-skyfies, orkestrasiesagteware en gespesialiseerde KI-toepassings.
Die geopolitieke dimensie is beduidend. Lande wat nasionale KI-soewereiniteit prioritiseer, trek voordeel uit die SLM-verskuiwing. China belê $138 miljard in binnelandse tegnologie, en Europa belê $200 miljard in InvestAI. Hierdie beleggings sal meer effektief wees wanneer absolute skaal nie meer die beslissende faktor is nie, maar eerder slim, doeltreffende en gespesialiseerde oplossings. Die multipolêre KI-wêreld word 'n werklikheid.
Die regulatoriese raamwerk ontwikkel parallel. Databeskerming, algoritmiese verantwoordbaarheid, omgewingstandaarde – al hierdie dinge bevoordeel gedesentraliseerde, deursigtige en doeltreffende stelsels. Maatskappye wat SLM'e en randrekenaars vroegtydig aanneem, posisioneer hulself gunstig vir voldoening aan toekomstige regulasies.
Die talentlandskap is besig om te transformeer. Terwyl voorheen slegs elite-universiteite en top-tegnologiemaatskappye die hulpbronne vir LLM-navorsing gehad het, kan feitlik enige organisasie nou SLM'e ontwikkel. Die vaardigheidstekort wat 87 persent van organisasies verhinder om KI aan te stel, word getemper deur laer kompleksiteit en beter gereedskap. Produktiwiteitswinste uit KI-gesteunde ontwikkeling versterk hierdie effek.
Die manier waarop ons die opbrengs op belegging (ROI) van KI-beleggings meet, is besig om te verander. In plaas daarvan om op rou berekeningskapasiteit te fokus, word doeltreffendheid per taak die kernmaatstaf. Ondernemings rapporteer 'n gemiddelde opbrengs op belegging (ROI) van 5,9 persent op KI-inisiatiewe, aansienlik onder verwagtinge. Die rede lê dikwels in die gebruik van oorgroot, duur oplossings vir eenvoudige probleme. Die verskuiwing na taakgeoptimaliseerde SLM'e kan hierdie opbrengs op belegging dramaties verbeter.
Die ontleding onthul 'n bedryf op 'n keerpunt. Die wanbelegging van $57 miljard is meer as net 'n oorskatting van vraag. Dit verteenwoordig 'n fundamentele strategiese wanberekening oor die argitektuur van kunsmatige intelligensie. Die toekoms behoort nie aan gesentraliseerde reuse nie, maar aan gedesentraliseerde, gespesialiseerde, doeltreffende stelsels. Klein taalmodelle is nie minderwaardig as groot taalmodelle nie – hulle is beter vir die oorgrote meerderheid van werklike toepassings. Die ekonomiese, tegniese, omgewings- en strategiese argumente kom saam op 'n duidelike gevolgtrekking: Die KI-rewolusie sal gedesentraliseerd wees.
Die verskuiwing in mag van verskaffers na operateurs, van hiperskalers na toepassingsontwikkelaars, van sentralisasie na verspreiding, dui op 'n nuwe fase in KI-evolusie. Diegene wat hierdie oorgang vroegtydig herken en omhels, sal die wenners wees. Diegene wat aan die ou logika vasklou, loop die risiko dat hul duur infrastruktuur gestrande bates word, oorgeneem deur meer rats, doeltreffende alternatiewe. Die $57 miljard is nie net vermors nie - dit dui op die begin van die einde vir 'n paradigma wat reeds verouderd is.
Jou globale bemarkings- en besigheidsontwikkelingsvennoot
☑️ Ons besigheidstaal is Engels of Duits
☑️ NUUT: Korrespondensie in jou landstaal!

Konrad Wolfenstein
Ek sal graag jou en my span as 'n persoonlike adviseur dien.
Jy kan my kontak deur die kontakvorm hier in te vul of bel my eenvoudig by +49 89 89 674 804 (München) . My e-posadres is: wolfenstein ∂ xpert.digital
Ek sien uit na ons gesamentlike projek.
☑️ KMO-ondersteuning in strategie, konsultasie, beplanning en implementering
☑️ Skep of herbelyning van die digitale strategie en digitalisering
☑️ Uitbreiding en optimalisering van internasionale verkoopsprosesse
☑️ Globale en digitale B2B-handelsplatforms
☑️ Pionier Besigheidsontwikkeling / Bemarking / PR / Handelskoue
🎯🎯🎯 Benut Xpert.Digital se uitgebreide, vyfvoudige kundigheid in 'n omvattende dienspakket | BD, O&O, XR, PR & Digitale Sigbaarheidsoptimalisering

Trek voordeel uit Xpert.Digital se uitgebreide, vyfvoudige kundigheid in 'n omvattende dienspakket | O&O, XR, PR & Digitale Sigbaarheidsoptimalisering - Beeld: Xpert.Digital
Xpert.Digital het diepgaande kennis van verskeie industrieë. Dit stel ons in staat om pasgemaakte strategieë te ontwikkel wat presies aangepas is vir die vereistes en uitdagings van jou spesifieke marksegment. Deur voortdurend markneigings te ontleed en bedryfsontwikkelings te volg, kan ons met versiendheid optree en innoverende oplossings bied. Deur die kombinasie van ervaring en kennis, genereer ons toegevoegde waarde en gee ons kliënte 'n beslissende mededingende voordeel.
Meer daaroor hier: