
KI en SEO met BERT – Bidirectional Encoder Representations from Transformers – model in die veld van natuurlike taalverwerking (NLP)

Taalkeuse 📢
Gepubliseer op: 4 Oktober 2024 / Update van: 4 Oktober 2024 - Skrywer: Konrad Wolfenstein

KI en SEO met BERT – Bidirectional Encoder Representations from Transformers – Model in the field of natural language processing (NLP) – Image: Xpert.Digital
🚀💬 Ontwikkel deur Google: BERT en die belangrikheid daarvan vir NLP - Waarom bidirectionele teksbegrip noodsaaklik is
🔍🗣️ BERT, kort vir Bidirectional Encoder Representations from Transformers, is 'n belangrike model op die gebied van natuurlike taalverwerking (NLP) wat deur Google ontwikkel is. Dit het die manier waarop masjiene taal verstaan, 'n rewolusie verander. Anders as vorige modelle wat teks opeenvolgend van links na regs of andersom ontleed het, maak BERT tweerigtingverwerking moontlik. Dit beteken dat dit die konteks van 'n woord van beide die voorafgaande en daaropvolgende teksreeks vasvang. Hierdie vermoë verbeter die begrip van komplekse linguistiese kontekste aansienlik.
🔍 Die argitektuur van BERT
In onlangse jare het een van die belangrikste ontwikkelings op die gebied van Natuurlike Taalverwerking (NLP) plaasgevind met die bekendstelling van die Transformer-model, soos aangebied in die PDF 2017 - Aandag is al wat jy nodig het - vraestel ( Wikipedia ). Hierdie model het die veld fundamenteel verander deur die strukture wat voorheen gebruik is, soos masjienvertaling, weg te gooi. In plaas daarvan maak dit uitsluitlik staat op aandagmeganismes. Sedertdien het die ontwerp van die Transformer die basis gevorm vir baie modelle wat die stand van die kuns verteenwoordig op verskeie gebiede soos taalgenerering, vertaling en verder.
'n Illustrasie van die hoofkomponente van die Transformer-model - Beeld: Google
BERT is gebaseer op hierdie Transformer-argitektuur. Hierdie argitektuur gebruik sogenaamde self-aandagmeganismes om die verwantskappe tussen woorde in 'n sin te ontleed. Aandag word geskenk aan elke woord in die konteks van die hele sin, wat lei tot 'n meer presiese begrip van sintaktiese en semantiese verwantskappe.
Die skrywers van die artikel “Aandag is alles wat u nodig het” is:
- Ashish Vaswani (Google Brain)
- Noam Shazeer (Google Brain)
- Niki Parmar (Google Navorsing)
- Jakob Uszkoreit (Google Navorsing)
- Lion Jones (Google Navorsing)
- Aidan N. Gomez (Universiteit van Toronto, werk gedeeltelik gedoen by Google Brain)
- Lukasz Kaiser (Google Brain)
- Illia Polosukhin (Onafhanklik, vorige werk by Google Research)
Hierdie skrywers het aansienlik bygedra tot die ontwikkeling van die Transformer-model wat in hierdie artikel aangebied word.
🔄 Tweerigtingverwerking
'n Opvallende kenmerk van BERT is sy tweerigtingverwerkingsvermoë. Terwyl tradisionele modelle soos herhalende neurale netwerke (RNN'e) of lang korttermyngeheue (LSTM) netwerke slegs teks in een rigting verwerk, ontleed BERT die konteks van 'n woord in beide rigtings. Dit laat die model toe om subtiele nuanses van betekenis beter vas te lê en dus meer akkurate voorspellings te maak.
🕵️♂️ Gemaskerde taalmodellering
Nog 'n innoverende aspek van BERT is die Masked Language Model (MLM) tegniek. Dit behels die maskering van ewekansige geselekteerde woorde in 'n sin en die opleiding van die model om hierdie woorde op grond van die omliggende konteks te voorspel. Hierdie metode dwing BERT om 'n diepgaande begrip van die konteks en betekenis van elke woord in die sin te ontwikkel.
🚀 Opleiding en aanpassing van BERT
BERT gaan deur 'n twee-fase opleidingsproses: vooropleiding en fyn instel.
📚 Vooraf opleiding
In vooropleiding word BERT opgelei met groot hoeveelhede teks om algemene taalpatrone aan te leer. Dit sluit Wikipedia-tekste en ander uitgebreide tekskorpusse in. In hierdie fase leer die model basiese linguistiese strukture en kontekste.
🔧 Fyninstelling
Na voorafopleiding word BERT aangepas vir spesifieke NLP-take, soos teksklassifikasie of sentimentanalise. Die model is opgelei met kleiner, taakverwante datastelle om sy werkverrigting vir spesifieke toepassings te optimaliseer.
🌍 Toepassingsgebiede van BERT
BERT het bewys dat dit uiters nuttig is in talle gebiede van natuurlike taalverwerking:
Soekenjinoptimalisering
Google gebruik BERT om soeknavrae beter te verstaan en meer relevante resultate te wys. Dit verbeter die gebruikerservaring aansienlik.
Teksklassifikasie
BERT kan dokumente volgens onderwerp kategoriseer of die stemming in tekste ontleed.
Benoemde entiteitserkenning (NER)
Die model identifiseer en klassifiseer benoemde entiteite in tekste, soos persoonlike, plek- of organisasiename.
Vraag en antwoord stelsels
BERT word gebruik om presiese antwoorde te verskaf op vrae wat gevra word.
🧠 Die belangrikheid van BERT vir die toekoms van KI
BERT het nuwe standaarde vir NLP-modelle gestel en die weg gebaan vir verdere innovasies. Deur sy tweerigtingverwerkingsvermoë en diepgaande begrip van taalkonteks het dit die doeltreffendheid en akkuraatheid van KI-toepassings aansienlik verhoog.
🔜 Toekomstige ontwikkelings
Verdere ontwikkeling van BERT en soortgelyke modelle sal waarskynlik daarop gemik wees om selfs kragtiger stelsels te skep. Dit kan meer komplekse taaltake hanteer en in 'n verskeidenheid nuwe toepassingsgebiede gebruik word. Die integrasie van sulke modelle in alledaagse tegnologieë kan die manier waarop ons met rekenaars omgaan, fundamenteel verander.
🌟 Mylpaal in die ontwikkeling van kunsmatige intelligensie
BERT is 'n mylpaal in die ontwikkeling van kunsmatige intelligensie en het 'n omwenteling in die manier waarop masjiene natuurlike taal verwerk. Die tweerigting-argitektuur daarvan maak 'n dieper begrip van linguistiese verhoudings moontlik, wat dit onontbeerlik maak vir 'n verskeidenheid toepassings. Soos navorsing vorder, sal modelle soos BERT voortgaan om 'n sentrale rol te speel in die verbetering van KI-stelsels en die opening van nuwe moontlikhede vir die gebruik daarvan.
📣 Soortgelyke onderwerpe
- 📚 Bekendstelling van BERT: The Breakthrough NLP Model
- 🔍 BERT en die rol van tweerigting in NLP
- 🧠 Die Transformer-model: hoeksteen van BERT
- 🚀 Gemaskerde taalmodellering: BERT se sleutel tot sukses
- 📈 Aanpassing van BERT: van vooropleiding tot fynafstelling
- 🌐 Die toepassingsgebiede van BERT in moderne tegnologie
- 🤖 BERT se invloed op die toekoms van kunsmatige intelligensie
- 💡 Toekomsvooruitsigte: Verdere ontwikkelings van BERT
- 🏆 BERT as 'n mylpaal in KI-ontwikkeling
- 📰 Skrywers van die Transformer-artikel "Attention Is All You Need": Die gedagtes agter BERT
#️⃣ Hashtags: #NLP #Kunsmatige Intelligensie #Taalmodellering #Transformator #Masjineleer
🎯🎯🎯 Vind voordeel uit Xpert.Digital se uitgebreide, vyfvoudige kundigheid in 'n omvattende dienspakket | R&D, XR, PR & SEM

KI & XR 3D-weergawemasjien: Vyfvoudige kundigheid van Xpert.Digital in 'n omvattende dienspakket, R&D XR, PR & SEM - Beeld: Xpert.Digital
Xpert.Digital het diepgaande kennis van verskeie industrieë. Dit stel ons in staat om pasgemaakte strategieë te ontwikkel wat presies aangepas is vir die vereistes en uitdagings van jou spesifieke marksegment. Deur voortdurend markneigings te ontleed en bedryfsontwikkelings te volg, kan ons met versiendheid optree en innoverende oplossings bied. Deur die kombinasie van ervaring en kennis, genereer ons toegevoegde waarde en gee ons kliënte 'n beslissende mededingende voordeel.
Meer daaroor hier:
BERT: Revolusionêre 🌟 NLP-tegnologie
🚀 BERT, kort vir Bidirectional Encoder Representations from Transformers, is 'n gevorderde taalmodel wat deur Google ontwikkel is wat sedert die bekendstelling in 2018 'n beduidende deurbraak op die gebied van Natural Language Processing (NLP) geword het. Dit is gebaseer op die Transformer-argitektuur, wat 'n rewolusie in die manier waarop masjiene teks verstaan en verwerk, verander het. Maar wat presies maak BERT so spesiaal en waarvoor word dit presies gebruik? Om hierdie vraag te beantwoord, moet ons dieper in die tegniese beginsels, funksionaliteit en toepassingsareas van BERT delf.
📚 1. Die basiese beginsels van natuurlike taalverwerking
Om die betekenis van BERT ten volle te begryp, is dit nuttig om die basiese beginsels van natuurlike taalverwerking (NLP) kortliks te hersien. NLP handel oor die interaksie tussen rekenaars en menslike taal. Die doel is om masjiene te leer om teksdata te ontleed, te verstaan en daarop te reageer. Voor die bekendstelling van modelle soos BERT, het masjienverwerking van taal dikwels beduidende uitdagings gebied, veral as gevolg van die dubbelsinnigheid, konteksafhanklikheid en komplekse struktuur van menslike taal.
📈 2. Die ontwikkeling van NLP-modelle
Voordat BERT op die toneel gekom het, was die meeste NLP-modelle gebaseer op sogenaamde eenrigting-argitekture. Dit beteken dat hierdie modelle slegs teks van links na regs of regs na links lees, wat beteken het dat hulle slegs 'n beperkte hoeveelheid konteks in ag kon neem wanneer 'n woord in 'n sin verwerk word. Hierdie beperking het dikwels daartoe gelei dat die modelle nie die volle semantiese konteks van 'n sin volledig vasvang nie. Dit het dit moeilik gemaak om dubbelsinnige of kontekssensitiewe woorde akkuraat te interpreteer.
Nog 'n belangrike ontwikkeling in NLP-navorsing voor BERT was die word2vec-model, wat rekenaars toegelaat het om woorde in vektore te vertaal wat semantiese ooreenkomste weerspieël. Maar ook hier was die konteks beperk tot die onmiddellike omgewing van 'n woord. Later is Herhalende Neurale Netwerke (RNN'e) en veral Lang Korttermyn Geheue (LSTM) modelle ontwikkel, wat dit moontlik gemaak het om teksreekse beter te verstaan deur inligting oor veelvuldige woorde te stoor. Hierdie modelle het egter ook hul beperkings gehad, veral wanneer dit met lang tekste handel en konteks in beide rigtings gelyktydig verstaan.
🔄 3. Die rewolusie deur Transformator-argitektuur
Die deurbraak het gekom met die bekendstelling van die Transformer-argitektuur in 2017, wat die basis vir BERT vorm. Transformatormodelle is ontwerp om parallelle verwerking van teks moontlik te maak, met inagneming van die konteks van 'n woord uit beide die voorafgaande en daaropvolgende teks. Dit word gedoen deur middel van sogenaamde self-aandagmeganismes, wat 'n gewigswaarde aan elke woord in 'n sin toeken gebaseer op hoe belangrik dit is in verhouding tot die ander woorde in die sin.
In teenstelling met vorige benaderings, is transformatormodelle nie eenrigting nie, maar tweerigting. Dit beteken dat hulle inligting uit beide die linker- en regterkonteks van 'n woord kan haal, wat 'n meer volledige en akkurate voorstelling van die woord en die betekenis daarvan lewer.
🧠 4. BERT: 'n Tweerigtingmodel
BERT neem die prestasie van die Transformer-argitektuur na 'n nuwe vlak. Die model is ontwerp om die konteks van 'n woord vas te vang, nie net van links na regs of regs na links nie, maar in beide rigtings gelyktydig. Dit laat BERT toe om die volle konteks van 'n woord binne 'n sin te oorweeg, wat lei tot aansienlik verbeterde akkuraatheid in taalverwerkingstake.
'n Sentrale kenmerk van BERT is die gebruik van die sogenaamde Masked Language Model (MLM). In opleiding BERT word woorde in 'n sin wat ewekansig gekies is, vervang met 'n masker, en die model word opgelei om hierdie gemaskerde woorde op grond van die konteks te raai. Hierdie tegniek laat BERT toe om dieper en meer presiese verhoudings tussen die woorde in 'n sin te leer.
Daarbenewens gebruik BERT 'n metode genaamd Next Sentence Prediction (NSP), waar die model leer om te voorspel of een sin op 'n ander volg of nie. Dit verbeter BERT se vermoë om langer tekste te verstaan en meer komplekse verwantskappe tussen sinne te herken.
🌐 5. Toepassing van BERT in die praktyk
BERT het bewys dat dit uiters nuttig is vir 'n verskeidenheid NLP-take. Hier is 'n paar van die hoofareas van toepassing:
📊 a) Teksklassifikasie
Een van die mees algemene gebruike van BERT is teksklassifikasie, waar tekste in voorafbepaalde kategorieë verdeel word. Voorbeelde hiervan sluit in sentimentanalise (bv. om te erken of 'n teks positief of negatief is) of die kategorisering van klantterugvoer. BERT kan meer presiese resultate as vorige modelle verskaf deur sy diepgaande begrip van die konteks van woorde.
❓ b) Vraag-antwoord-stelsels
BERT word ook in vraag-antwoordstelsels gebruik, waar die model antwoorde op gestelde vrae uit 'n teks onttrek. Hierdie vermoë is veral belangrik in toepassings soos soekenjins, chatbots of virtuele assistente. Danksy sy tweerigtingargitektuur kan BERT relevante inligting uit 'n teks onttrek, selfs al word die vraag indirek geformuleer.
🌍 c) Teksvertaling
Alhoewel BERT self nie direk as 'n vertaalmodel ontwerp is nie, kan dit in kombinasie met ander tegnologieë gebruik word om masjienvertaling te verbeter. Deur die semantiese verwantskappe in 'n sin beter te verstaan, kan BERT help om meer akkurate vertalings te genereer, veral vir dubbelsinnige of komplekse bewoording.
🏷️ d) Benoemde entiteitserkenning (NER)
Nog 'n toepassingsgebied is Named Entity Recognition (NER), wat die identifisering van spesifieke entiteite soos name, plekke of organisasies in 'n teks behels. BERT het besonder effektief in hierdie taak bewys omdat dit die konteks van 'n sin ten volle in ag neem, wat dit beter maak om entiteite te herken, selfs al het hulle verskillende betekenisse in verskillende kontekste.
✂️ e) Teksopsomming
BERT se vermoë om die hele konteks van 'n teks te verstaan maak dit ook 'n kragtige hulpmiddel vir outomatiese teksopsomming. Dit kan gebruik word om die belangrikste inligting uit 'n lang teks te onttrek en 'n bondige opsomming te skep.
🌟 6. Die belangrikheid van BERT vir navorsing en industrie
Die bekendstelling van BERT het 'n nuwe era in NLP-navorsing ingelui. Dit was een van die eerste modelle wat die krag van die tweerigting-transformator-argitektuur ten volle benut het, wat die lat gestel het vir baie daaropvolgende modelle. Baie maatskappye en navorsingsinstellings het BERT in hul NLP-pyplyne geïntegreer om die werkverrigting van hul toepassings te verbeter.
Boonop het BERT die weg gebaan vir verdere innovasies op die gebied van taalmodelle. Modelle soos GPT (Generative Pretrained Transformer) en T5 (Text-to-Text Transfer Transformer) is byvoorbeeld daarna ontwikkel, wat op soortgelyke beginsels gebaseer is, maar spesifieke verbeterings vir verskillende gebruiksgevalle bied.
🚧 7. Uitdagings en beperkings van BERT
Ten spyte van sy vele voordele, het BERT ook 'n paar uitdagings en beperkings. Een van die grootste struikelblokke is die hoë berekeningspoging wat nodig is om die model op te lei en toe te pas. Omdat BERT 'n baie groot model met miljoene parameters is, vereis dit kragtige hardeware en aansienlike rekenaarhulpbronne, veral wanneer groot hoeveelhede data verwerk word.
Nog 'n probleem is die potensiële vooroordeel wat in die opleidingsdata kan bestaan. Omdat BERT op groot hoeveelhede teksdata opgelei is, weerspieël dit soms die vooroordele en stereotipes wat in daardie data voorkom. Navorsers werk egter voortdurend daaraan om hierdie kwessies te identifiseer en aan te spreek.
🔍 Noodsaaklike hulpmiddel vir moderne taalverwerkingstoepassings
BERT het die manier waarop masjiene menslike taal verstaan aansienlik verbeter. Met sy tweerigtingargitektuur en innoverende opleidingsmetodes is dit in staat om die konteks van woorde in 'n sin diep en akkuraat vas te vang, wat lei tot hoër akkuraatheid in baie NLP-take. Hetsy in teksklassifikasie, vraag-antwoordstelsels of entiteitsherkenning – BERT het homself gevestig as 'n onontbeerlike hulpmiddel vir moderne taalverwerkingstoepassings.
Navorsing in natuurlike taalverwerking sal ongetwyfeld voortgaan om te vorder, en BERT het die grondslag gelê vir baie toekomstige innovasies. Ten spyte van die bestaande uitdagings en beperkings, wys BERT op indrukwekkende wyse hoe ver die tegnologie in 'n kort tydjie gekom het en watter opwindende geleenthede nog in die toekoms sal oopmaak.
🌀 Die transformator: 'n revolusie in natuurlike taalverwerking
🌟 In onlangse jare was een van die belangrikste ontwikkelings op die gebied van Natuurlike Taalverwerking (NLP) die bekendstelling van die Transformer-model, soos beskryf in die 2017-artikel "Aandag is al wat jy nodig het." Hierdie model het die veld fundamenteel verander deur die voorheen gebruikte herhalende of konvolusionele strukture vir volgordetransduksietake soos masjienvertaling weg te gooi. In plaas daarvan maak dit uitsluitlik staat op aandagmeganismes. Sedertdien het die ontwerp van die Transformer die basis gevorm vir baie modelle wat die stand van die kuns verteenwoordig op verskeie gebiede soos taalgenerering, vertaling en verder.
🔄 Die Transformer: 'n Paradigmaskuif
Voor die bekendstelling van die Transformator was die meeste modelle vir volgordebepaling van take gebaseer op herhalende neurale netwerke (RNN's) of lang korttermyngeheuenetwerke (LSTM's), wat inherent opeenvolgend is. Hierdie modelle verwerk insetdata stap vir stap, wat verborge toestande skep wat langs die volgorde gepropageer word. Alhoewel hierdie metode doeltreffend is, is dit rekenkundig duur en moeilik om te paralleliseer, veral vir lang rye. Daarbenewens sukkel RNN'e om langtermyn-afhanklikhede te leer as gevolg van die sogenaamde "verdwynende gradiënt"-probleem.
Die Transformator se sentrale innovasie lê in die gebruik van self-aandagmeganismes, wat die model toelaat om die belangrikheid van verskillende woorde in 'n sin relatief tot mekaar te weeg, ongeag hul posisie. Dit stel die model in staat om verwantskappe tussen wydgespasieerde woorde meer effektief as RNN'e of LSTM'e vas te lê, en om dit op 'n parallelle wyse eerder as opeenvolgend te doen. Dit verbeter nie net opleidingsdoeltreffendheid nie, maar ook prestasie op take soos masjienvertaling.
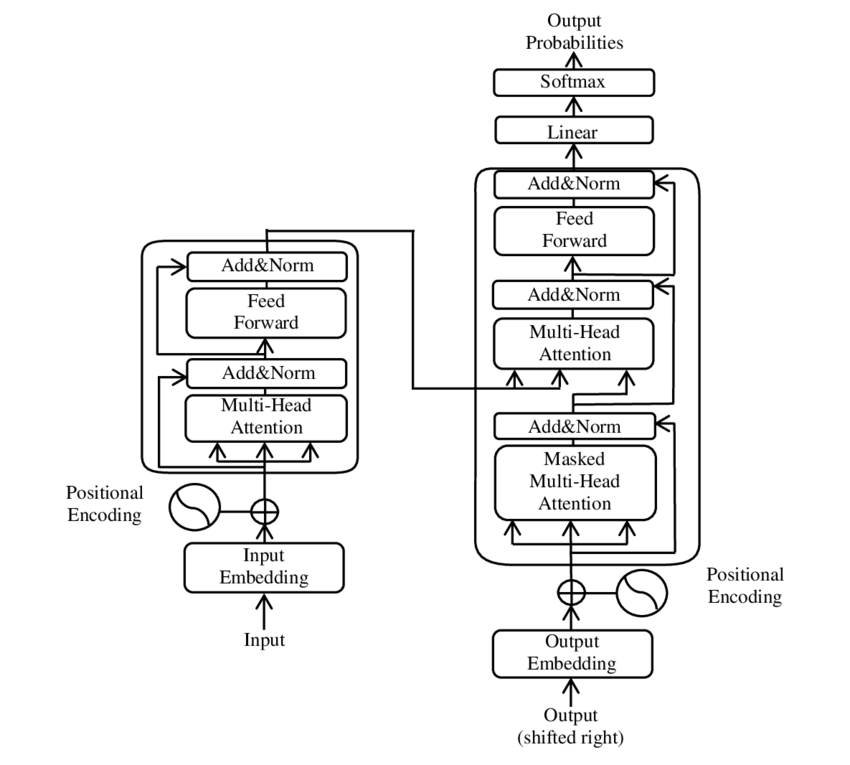
🧩 Model argitektuur
Die Transformator bestaan uit twee hoofkomponente: 'n enkodeerder en 'n dekodeerder, wat albei uit veelvuldige lae bestaan en sterk staatmaak op meerkoppige aandagmeganismes.
⚙️ Enkodeerder
Die enkodeerder bestaan uit ses identiese lae, elk met twee sublae:
1. Meerkoppige Selfaandag
Hierdie meganisme laat die model toe om op verskillende dele van die insetsin te fokus terwyl dit elke woord verwerk. In plaas daarvan om aandag in 'n enkele spasie te bereken, projekteer meerkoppige aandag die insette in verskeie verskillende ruimtes, wat toelaat dat verskillende tipes verhoudings tussen woorde vasgelê kan word.
2. Posisiegewys volledig gekoppelde terugvoernetwerke
Na die aandaglaag word 'n volledig gekoppelde terugvoernetwerk onafhanklik by elke posisie toegepas. Dit help die model om elke woord in konteks te verwerk en die inligting van die aandagmeganisme te benut.
Om die struktuur van die invoerreeks te bewaar, bevat die model ook posisionele insette (posisionele enkoderings). Aangesien die Transformator nie die woorde opeenvolgend verwerk nie, is hierdie enkoderings van kardinale belang om die model inligting oor die volgorde van die woorde in 'n sin te gee. Die posisie-insette word by die woordinbeddings gevoeg sodat die model tussen die verskillende posisies in die ry kan onderskei.
🔍 Dekodeerders
Soos die enkodeerder, bestaan die dekodeerder ook uit ses lae, met elke laag wat 'n bykomende aandagmeganisme het wat die model in staat stel om op relevante dele van die invoerreeks te fokus terwyl die uitset gegenereer word. Die dekodeerder gebruik ook 'n maskeringstegniek om te verhoed dat dit toekomstige posisies oorweeg, wat die outoregressiewe aard van reeksgenerering behou.
🧠 Meerkoppige aandag en kolletjie produk aandag
Die hart van die transformator is die Multi-Head Attention-meganisme, wat 'n uitbreiding is van die eenvoudiger kolletjieproduk-aandag. Die aandagfunksie kan beskou word as 'n kartering tussen 'n navraag en 'n stel sleutel-waarde-pare (sleutels en waardes), waar elke sleutel 'n woord in die ry verteenwoordig en die waarde die geassosieerde kontekstuele inligting verteenwoordig.
Die meerkoppige aandagmeganisme laat die model toe om tegelykertyd op verskillende dele van die volgorde te fokus. Deur die insette in verskeie subruimtes te projekteer, kan die model 'n ryker stel verwantskappe tussen woorde vasvang. Dit is veral nuttig in take soos masjienvertaling, waar die verstaan van 'n woord se konteks baie verskillende faktore vereis, soos sintaktiese struktuur en semantiese betekenis.
Die formule vir kolletjieproduk aandag is:

Hier is (Q) die navraagmatriks, (K) is die sleutelmatriks en (V) is die waardematriks. Die term (sqrt{d_k}) is 'n skaalfaktor wat verhoed dat die kolletjieprodukte te groot word, wat sal lei tot baie klein gradiënte en stadiger leer. Die softmax-funksie word toegepas om te verseker dat die aandaggewigte een optel.
🚀 Voordele van die transformator
Die transformator bied verskeie sleutelvoordele bo tradisionele modelle soos RNN'e en LSTM'e:
1. Parallellisering
Omdat die Transformator alle tokens gelyktydig in 'n volgorde verwerk, kan dit hoogs geparalleliseer word en is dit dus baie vinniger om op te lei as RNN's of LSTM's, veral op groot datastelle.
2. Langtermyn afhanklikhede
Die self-aandagmeganisme laat die model toe om verwantskappe tussen verre woorde meer effektief vas te lê as RNN'e, wat beperk word deur die opeenvolgende aard van hul berekeninge.
3. Skaalbaarheid
Die transformator kan maklik skaal tot baie groot datastelle en langer rye sonder om te ly aan die prestasie-knelpunte wat met RNN'e geassosieer word.
🌍 Toepassings en effekte
Sedert sy bekendstelling het die Transformer die basis geword vir 'n wye reeks NLP-modelle. Een van die mees noemenswaardige voorbeelde is BERT (Bidirectional Encoder Representations from Transformers), wat 'n gewysigde Transformer-argitektuur gebruik om die nuutste in baie NLP-take te bereik, insluitend vraagbeantwoording en teksklassifikasie.
Nog 'n belangrike ontwikkeling is GPT (Generative Pretrained Transformer), wat 'n dekodeerder-beperkte weergawe van die Transformer vir teksgenerering gebruik. GPT-modelle, insluitend GPT-3, word nou vir 'n verskeidenheid toepassings gebruik, van inhoudskepping tot kodevoltooiing.
🔍 'n Kragtige en buigsame model
Die transformator het die manier waarop ons NLP-take benader, fundamenteel verander. Dit bied 'n kragtige en buigsame model wat op 'n verskeidenheid probleme toegepas kan word. Sy vermoë om langtermyn-afhanklikhede en opleidingsdoeltreffendheid te hanteer, het dit die voorkeur-argitektoniese benadering vir baie van die modernste modelle gemaak. Soos navorsing vorder, sal ons waarskynlik verdere verbeterings en aanpassings aan die Transformator sien, veral op gebiede soos beeld- en taalverwerking, waar aandagmeganismes belowende resultate toon.
Ons is daar vir jou - advies - beplanning - implementering - projekbestuur
☑️ Bedryfskenner, hier met sy eie Xpert.Digital industrie-spilpunt met meer as 2 500 spesialisartikels

Konrad Wolfenstein
Ek sal graag as jou persoonlike adviseur dien.
Jy kan my kontak deur die kontakvorm hieronder in te vul of my eenvoudig by +49 89 89 674 804 (München) .
Ek sien uit na ons gesamentlike projek.
Skryf aan my

Xpert.Digital - Konrad Wolfenstein
Xpert.Digital is 'n spilpunt vir die industrie met 'n fokus op digitalisering, meganiese ingenieurswese, logistiek/intralogistiek en fotovoltaïese.
Met ons 360° besigheidsontwikkelingsoplossing ondersteun ons bekende maatskappye van nuwe besigheid tot naverkope.
Markintelligensie, smarketing, bemarkingsoutomatisering, inhoudontwikkeling, PR, posveldtogte, persoonlike sosiale media en loodversorging is deel van ons digitale hulpmiddels.
Jy kan meer uitvind by: www.xpert.digital - www.xpert.solar - www.xpert.plus
Behou kontak




















